📊 対象級:4級 ・ 3級 | 重要度:A(頻出)
度数分布表とヒストグラム ── 階級・相対度数・累積度数とスタージェスの公式
要点(BLUF)
- 度数分布表=量的データを階級(区間)に区切り各階級の度数(個数)を数えた表。階級値=区間の真ん中、相対度数=度数/、累積(相対)度数=下から足し上げた合計(累積相対度数の最後は必ず1)。
- ヒストグラム ≠ 棒グラフ:横軸が数値の区間か/カテゴリーか、棒に隙間がないか/あるかの2点で見分ける。ヒストグラムは散らばりの形、棒グラフは量の大小を見る。
- 階級数の目安がスタージェスの公式 (データ2倍で階級+1)。ただし目安であり大標本では少なすぎる欠点あり。
対象級について:4級〜3級が中心です。4級では「ヒストグラムから何が読み取れるか」「分布の形の違い」が問われます。3級では一歩進んで「度数分布表を自分で作る」「相対度数・累積度数を計算する」「適切な階級の取り方」が問われます。相対度数・累積度数の考え方は2級(確率分布の累積分布関数)にもつながる土台なので、後半でその接続も示します。前トピック 統計グラフの読み方(棒・折れ線・円・帯)と誤解を招くグラフ では「棒グラフとヒストグラムは別物」とだけ予告しました。ここでその”別物”の中身、つまり量的データを階級に区切って分布の形を見るという記述統計の根幹を固めます。
結論:度数分布表は「区間ごとに数を数えた表」、ヒストグラムはそれを「隙間なしの柱」で描いた図
最初に結論です。連続的な数値データ(身長・点数・売上など)は、一つひとつの値をそのまま眺めても全体像がつかめません。そこで値の範囲(階級)に区切って、各範囲に何個入るか(度数)を数えた表が度数分布表、それを柱の高さで表した図がヒストグラムです。
| 用語 | 意味 | 一言でいうと |
|---|---|---|
| 階級(かいきゅう) | データを区切る区間(例:150以上160未満cm) | 「箱」 |
| 階級幅 | 1つの階級の幅(上の例なら10cm) | 「箱の大きさ」 |
| 階級値 | 階級を代表する値=階級の真ん中 | 「箱の代表選手」 |
| 度数(どすう) | 各階級に入ったデータの個数 | 「箱の中身の数」 |
| 相対度数 | 度数 ÷ 全データ数(=その階級が占める割合) | 「全体に対する割合」 |
| 累積度数 | その階級までの度数を下から足し上げた合計 | 「ここまでで何個」 |
| 累積相対度数 | その階級までの相対度数の合計(最後は必ず1) | 「ここまでで何割」 |
そして最大の注意点を先に言います。ヒストグラムは棒グラフではありません。 見た目はそっくりですが、横軸の意味も棒の隙間も別物です。ここを混同すると4級でも3級でも失点します。本記事はこの2つの違いを軸に進めます。
度数分布表をつくる ── 5つのステップ
身長や点数のような量的データが手元にあるとして、度数分布表を作る手順は決まっています。「いきなり表を埋める」のではなく、範囲を決める → 区切る → 数える → 割合を出すの順です。
flowchart TD
A["生データを集める"] --> B["最大値と最小値を見る<br/>(範囲を把握)"]
B --> C["階級数・階級幅を決める"]
C --> D["各階級に度数を数える"]
D --> E["相対度数・累積度数を計算"]
E --> F["度数分布表の完成"]
↑ 度数分布表づくりの流れ。山場は「階級をどう区切るか(ステップC)」と「数えて割合に直す(D〜E)」の2か所です。
ステップ1:データの範囲(レンジ)をつかむ
まず最大値と最小値を見ます。この差を**範囲(レンジ, range)**と呼びます。
要するに「データが端から端まで、どれだけ広がっているか」です。この幅をいくつの箱に分けるかを次で決めます。
ステップ2:階級数を決める(スタージェスの公式)
箱をいくつ用意するか(=階級数 )の目安が、有名な**スタージェスの公式(Sturges’ rule)**です。
ここで はデータの個数です。これは要するに「データが2倍になるごとに、箱を1個増やせばよい」という目安です( がそれを表しています)。なぜこの式になるのかは後半の「数式の直観」で導出します。
具体的な値の早見表はこうなります。
| データ数 | 階級数 | |
|---|---|---|
| 16 | 4 | 5 |
| 32 | 5 | 6 |
| 64 | 6 | 7 |
| 128 | 7 | 8 |
| 256 | 8 | 9 |
| 512 | 9 | 10 |
が整数にならないときは四捨五入します(例: なら で 階級)。
⚠️ スタージェスの公式はあくまで目安です。「これが唯一の正解」ではありません。実務でも試験でも、問題文で階級幅が指定されることが多いです。公式を暗記するより「データが多いほど階級を増やす」という方向感を押さえてください。
ステップ3:階級幅を決める
階級数 が決まれば、階級幅の目安は範囲を で割ったものです。
要するに「データの広がりを、箱の数で等分する」だけです。実際にはキリのいい数(5刻み・10刻みなど)に丸めて使います。
ステップ4:度数を数える
各階級に入るデータの個数を数えます。ここで区間の境界の扱いが問題になります。慣習として「○以上△未満」(左を含み右を含まない)で区切ります。たとえば「150以上160未満」と「160以上170未満」なら、ちょうど160の人は**後者(160以上170未満)**に入れます。
⚠️ この「以上・未満」の境界処理は試験で狙われます。150cmの人を「140以上150未満」に入れるか「150以上160未満」に入れるかで度数が変わります。ふつうは下の階級が”未満”で切れ、上の階級が”以上”で始まると覚えてください。
ステップ5:相対度数・累積度数・累積相対度数を計算する
度数が出たら、割合と累積を計算します。
- 相対度数 → これは「その階級が全体の何割か」
- 累積度数 その階級までの度数を下から足した合計 → 「ここまでで何個たまったか」
- 累積相対度数 その階級までの相対度数の合計 → 「ここまでで何割たまったか」
検算ポイントは2つ。相対度数の合計は必ず 1(=100%)、累積相対度数の最後の階級も必ず 1になります。ここがズレていたら計算ミスです。
具体例:営業30人の売上で度数分布表を作る
営業担当30人の月間売上(万円)を、85〜200万円の範囲で5つの階級に区切った例です(範囲115を約23幅で5分割)。実際の数値で各列がどうつながるかを見てください。
| 階級(万円) | 階級値 | 度数 | 相対度数 | 累積度数 | 累積相対度数 |
|---|---|---|---|---|---|
| 85以上 108未満 | 96.5 | 5 | 0.167 | 5 | 0.167 |
| 108以上 131未満 | 119.5 | 8 | 0.267 | 13 | 0.433 |
| 131以上 154未満 | 142.5 | 8 | 0.267 | 21 | 0.700 |
| 154以上 177未満 | 165.5 | 5 | 0.167 | 26 | 0.867 |
| 177以上 200未満 | 188.5 | 4 | 0.133 | 30 | 1.000 |
| 合計 | ― | 30 | 1.000 | ― | ― |
読み取りの練習をしましょう。
- 階級値:たとえば「85以上108未満」の真ん中は 。後で平均を概算するとき、この階級値を「その階級の代表値」として使います(→ 代表値 ── 平均・中央値・最頻値の定義と使い分け(外れ値への強さ・歪んだ分布での大小関係))。
- 相対度数:「131以上154未満」は 、つまり全体の約27%がこの売上帯。
- 累積度数:「154未満は何人か」を知りたければ累積度数を見て21人。いちいち足し算しなくても表から一発でわかるのが累積度数の便利さです。
- 累積相対度数:「154未満が全体の何割か」は 0.700 = 70%。中央値(代表値 ── 平均・中央値・最頻値の定義と使い分け(外れ値への強さ・歪んだ分布での大小関係))が154万円のすぐ下あたりにある、という見当もここからつきます。
累積相対度数の最後が 1.000 になっていることを必ず確認してください。これが「全データを漏れなく数えた」という検算になります。
ヒストグラム ── 度数分布表を「隙間なしの柱」で描く
度数分布表を図にしたものがヒストグラムです。横軸に階級(数値の区間)、縦軸に度数を取り、各階級の度数を柱の高さで表します。先ほどの30人の売上なら、「131以上154未満」の柱が一番高く(度数8)、両端に向かって低くなる山型になります。
ここからが核心です。ヒストグラムと棒グラフは見た目が似ていますが、まったくの別物です。最頻出の混同ポイントなので、表で徹底的に整理します。
| 観点 | ヒストグラム | 棒グラフ |
|---|---|---|
| 横軸 | 数値の区間(連続量・階級) | カテゴリー(東京・大阪…) |
| 扱うデータ | 量的データ(身長・点数) | 質的データ(名義・順序) |
| 棒の間 | 隙間なし(区間が連続するから) | 隙間あり(項目が独立だから) |
| 横軸の並べ替え | 不可(数値順に固定) | 可(大小順に並べ替えてよい) |
| 見るもの | データの散らばり・分布の形 | 項目間の量の大小比較 |
覚え方は単純です。「横軸が数値の区間で、棒に隙間がなければヒストグラム」「横軸がカテゴリーで、棒に隙間があれば棒グラフ」。この2点(横軸の中身・隙間の有無)だけで確実に見分けられます。
なぜ隙間をあけないのか。ヒストグラムの横軸は「150〜160〜170…」と切れ目なく連続しているからです。160という値はどこかの階級に必ず属します。区間がつながっている以上、柱もくっつけて描くのが自然なのです。一方、棒グラフの「東京」と「大阪」の間には何もありません(連続していない)。だから隙間をあけます。
発展(2級への接続):本記事の例のように階級幅がすべて等しければ「柱の高さ=度数」で問題ありません。しかし階級幅が不揃いのときは、高さを度数のままにすると幅の広い階級が不当に大きく見えてしまいます。そこで縦軸を**度数密度(=度数 ÷ 階級幅)**にし、柱の「面積」が度数(や相対度数)に比例するように描きます。これは2級以降で確率密度関数を学ぶときの「面積=確率」という考え方に直結します。3級までは等幅が基本なので深入り不要ですが、「ヒストグラムの本質は高さでなく面積」という一段深い理解として頭の隅に置いてください。
ヒストグラムの形 ── 形から何が読めるか
ヒストグラムを描く最大のメリットは、分布の「形」が一目でわかることです。試験(特に4級)では「このヒストグラムの形は次のどれか」「2つのヒストグラムを比べて何が言えるか」が問われます。代表的な4つの形を押さえましょう。
xychart-beta
title "ヒストグラムの代表的な形(イメージ)"
x-axis "階級(小 → 大)" [1, 2, 3, 4, 5, 6, 7]
y-axis "度数" 0 --> 30
bar [2, 8, 20, 28, 20, 8, 2]
↑ これは「左右対称・単峰型」のイメージ。中央が一番高く、左右になだらかに減る。平均・中央値・最頻値がほぼ一致する、最も基本的な形です。
| 形 | 特徴 | そこから読めること | 歪度の符号 |
|---|---|---|---|
| 左右対称・単峰型 | 山が1つ、中央が最高で左右になだらか | 平均・中央値・最頻値がほぼ一致。正規分布的 | ほぼ 0 |
| 右に裾を引く型 | 山が左に寄り、右に長く尾を引く | 一部に大きな値(外れ値)。例:年収・売上 | 正(プラス) |
| 左に裾を引く型 | 山が右に寄り、左に長く尾を引く | 一部に小さな値。例:満点が多いテスト | 負(マイナス) |
| 二峰型(ふた山) | 山(ピーク)が2つ | 異質な2集団が混ざっているサイン | ― |
ここで一番の引っかけは**「右に裾を引く」と「左に裾を引く」の向き**です。
- 右に裾=山が左、尾が右に伸びる=正の歪度。「裾(しっぽ)が伸びる方向」が名前の由来です。
- 左に裾=山が右、尾が左に伸びる=負の歪度。
「右に裾を引く」のに山は左にある、というねじれが混乱の元です。“裾(尾)がどちらに伸びているか”でその名前と歪度の符号が決まる、と固定してください。「右に裾を引く=正の歪度=平均が中央値より大きい」という連鎖は2級でも頻出です(→ 代表値 ── 平均・中央値・最頻値の定義と使い分け(外れ値への強さ・歪んだ分布での大小関係) で平均と中央値の大小関係として再登場します)。
そして**二峰型(ふた山)**は実務で特に重要なサインです。たとえば「ある工場の製品寸法」が二峰型になっていたら、2台の機械の設定がズレているといった「混ざりもの」を疑います。1つの山に見えていたデータが、実は2つの集団だったと気づける ── これがヒストグラムの読解力です。
数式の直観的意味
スタージェスの公式 はなぜこの形か(導出)
結論:データが正規分布(左右対称な山型)に近いと仮定し、その理想的な度数の並びを二項分布の度数で近似することから導かれる。
発想の核は「 個の階級の度数を、二項係数 ()の並びで表す」こと。二項係数の列 は、中央が最大で両端が小さい左右対称の山型になり、正規分布のヒストグラムの理想形そのものになっている。Sturges はこの二項係数を「各階級に入るべき理想度数」と見なした。
このとき全データ数 は、各階級の理想度数(二項係数)を全部足し合わせたものに等しいはず:
ここで二項定理 ()を使うと、右辺は になる:
要するに「 階級の理想度数を全部足すとちょうど になり、それが全データ数 に等しい」。あとはこれを について解くだけ。両辺の を取ると:
これがスタージェスの公式。**直観的には「データが2倍になる()と の指数が1増える、つまり階級を1個増やせばよい」**という意味で、 がその「2倍ごとに+1」を表している。
導出が示す前提と限界:この式は「データが正規分布的な山型」かつ「 がきれいに成り立つ」という理想化に依存する。 は が大きくてもゆっくりしか増えない( でも )ので、大標本では階級が少なすぎる。だからあくまで目安。
階級値=区間の真ん中、を代表に使う近似の意味
階級「 以上 未満」に入ったデータは本来 〜 のどこかにバラけているが、度数分布表には個々の値は残らない。そこで**「その階級のデータは全員、真ん中 にいると見なす」**のが階級値。
なぜ真ん中か:階級内でデータがほぼ一様に散らばっていると仮定すれば、その平均的な位置(区間内の期待値)は中点になるから。これにより度数分布表だけから平均を概算できる:
ただし「真ん中に全員いる」は近似なので、元の生データから計算した平均とは微妙にズレる(→ 代表値 ── 平均・中央値・最頻値の定義と使い分け(外れ値への強さ・歪んだ分布での大小関係))。
⚠️ 引っかけポイント・頻出論点・級ごとの差
- 棒グラフ ≠ ヒストグラム(最頻出)。横軸(数値区間/カテゴリー)と隙間(なし/あり)の2点で判別。
- 「以上・未満」の境界処理:慣習で下の階級が”未満”で切れ、上の階級が”以上”で始まる。ちょうど境界値(例:160)は**上の階級(160以上…)**に入れる。どちらに入れるかで度数が変わるので狙われる。
- 「右に裾=正の歪度」だが山は左というねじれ。山の位置でなく尾の伸びる向きで名前と符号が決まる。
- 累積相対度数の最後は必ず1(=全データを漏れなく数えた検算)。相対度数の合計も必ず1。
- スタージェスは目安。大標本では階級が少なすぎる欠点(導出が正規分布近似に依存するため)。問題文で階級幅が指定されればそれが優先。
- 2級への接続:累積相対度数は**累積分布関数(CDF)の離散版。階級幅が不揃いなら縦軸を度数密度(度数÷階級幅)**にして「面積=度数」で描く(確率密度の「面積=確率」に直結)。3級までは等幅が基本。
- 級差:4級=ヒストグラムの読み取り・形の比較 → 3級=度数分布表の作成・相対/累積度数の計算。
- 出題範囲・推奨公式は改訂されうるため受験前に公式最新版で要確認。
よくある疑問
Q1. 棒グラフとヒストグラム、結局どこを見れば見分けられるの?
「横軸の中身」と「棒の隙間」の2点だけで確実です。
- 横軸が数値の区間(150〜160cmなど)で、棒に隙間がないなら → ヒストグラム
- 横軸がカテゴリー名(東京・大阪など)で、棒に隙間があるなら → 棒グラフ
迷ったら「この横軸は連続した数値か?」と自問してください。連続量ならヒストグラム、バラバラのカテゴリーなら棒グラフです。意味の違いは「ヒストグラム=散らばりの形を見る」「棒グラフ=項目の大小を比べる」でした(→ 統計グラフの読み方(棒・折れ線・円・帯)と誤解を招くグラフ)。
Q2. 階級値はなぜ「区間の真ん中」なの?
その階級を1つの代表値で代表させるためです。「150以上160未満」に入った人は本当は150〜160のどこかにバラけていますが、いちいち個々の値は分布表に残りません。そこで「みんな真ん中(155)にいると見なす」と便宜的に決めるのが階級値です。
真ん中を選ぶのは、階級内でデータがだいたい一様に散らばっていると仮定すれば、平均的な位置が真ん中になるからです。この階級値を使えば、度数分布表だけから平均を概算できます(各階級値 × 度数 を全部足して で割る。詳しくは 代表値 ── 平均・中央値・最頻値の定義と使い分け(外れ値への強さ・歪んだ分布での大小関係))。ただしこれは近似で、元の生データから計算した平均とは微妙にズレます。
Q3. 累積度数・累積相対度数は何の役に立つの?
「○○以下(未満)が何個・何割か」を一発で読むためです。
たとえば「154万円未満の営業は何人?」と聞かれたとき、累積度数を見れば21人と即答できます。毎回度数を足し上げる必要がありません。「下から何割の位置か」を見れば、**中央値(50%の位置)やパーセンタイル(代表値 ── 平均・中央値・最頻値の定義と使い分け(外れ値への強さ・歪んだ分布での大小関係))**の見当もつきます。
さらに2級では、この累積相対度数の考え方が**累積分布関数(CDF)**へと一般化されます。「ある値以下になる確率」を表す関数で、まさに累積相対度数の連続版です。3級で累積相対度数に慣れておくと、2級の確率分布がスムーズに入ります。
Q4. スタージェスの公式は絶対に使わなきゃダメ?大標本だと変な気がする。
いいえ、目安にすぎません。 むしろ大標本では階級が少なすぎるという欠点が知られています。
スタージェスの公式 は、後述するようにデータが正規分布に近い山型であることを前提に導かれています。 は が大きくなってもゆっくりしか増えないので、たとえば でも 程度。大きなデータに対しては階級数が少なすぎて、分布の細部がつぶれることがあります。
そのため実務では、より細かく刻むスコットの公式やフリードマン=ダイアコニスの公式なども使われます(これらは準1級以降の話で、3級では不要)。3級レベルでは「データが多いほど階級を増やす」という方向感だけ押さえ、具体的な階級は問題文の指定に従うのが正解です。なお、どの公式を使うかや出題範囲は改訂されうるので、受験前に公式の最新版で要確認です。
Q5. ヒストグラムの「右に裾を引く」と「左に裾を引く」、どっちがどっちか毎回わからなくなる。
“裾(しっぽ)が伸びている方向”が名前です。 これだけ固定すれば混乱しません。
- 右に裾を引く:山は左、尾が右に長い。→ 正の歪度。年収・売上のように「ごく一部に飛び抜けて大きい値がある」分布。平均が中央値より大きくなる。
- 左に裾を引く:山は右、尾が左に長い。→ 負の歪度。満点近くに集中するテストのように「一部に飛び抜けて小さい値がある」分布。平均が中央値より小さくなる。
混乱の原因は「右に裾なのに山は左」というねじれです。山の位置ではなく、尾の伸びる向きで名前が決まると覚えてください。「裾を引く方向=歪度の符号の向き=平均がズレる向き」が3点セットで連動します(代表値 ── 平均・中央値・最頻値の定義と使い分け(外れ値への強さ・歪んだ分布での大小関係) で平均と中央値の大小として再確認します)。
まとめ
- 度数分布表は量的データを階級(区間)に区切り、各階級の**度数(個数)**を数えた表。階級値=区間の真ん中、相対度数=度数÷全体、累積度数・累積相対度数=下から足し上げた合計(最後は必ず度数=、累積相対度数=1)。
- 作成手順は範囲を見る→階級数・階級幅を決める→度数を数える→相対・累積を計算。境界は「以上・未満」で処理する(試験で狙われる)。
- 階級数の目安がスタージェスの公式 (データが2倍で階級+1)。ただし目安であり大標本では少なすぎる欠点あり。問題文指定が優先。
- ヒストグラム ≠ 棒グラフ:横軸が数値の区間か/カテゴリーか、棒に隙間がないか/あるかの2点で見分ける。ヒストグラムは散らばりの形、棒グラフは量の大小を見る。
- ヒストグラムの形から分布の性質が読める:左右対称・単峰/右に裾(正の歪度)/左に裾(負の歪度)/二峰型(2集団の混在)。“裾の伸びる向き”が名前と歪度の符号を決める。
- 級差:4級=ヒストグラムの読み取り・形の比較 → 3級=度数分布表の作成・相対/累積度数の計算。累積相対度数は2級の累積分布関数へつながる。
度数分布表とヒストグラムは、生のデータを「分布」として捉えるための最初の道具です。次は、この分布を1つの数値に要約する代表値(平均・中央値・最頻値)へ進みます(→ 代表値 ── 平均・中央値・最頻値の定義と使い分け(外れ値への強さ・歪んだ分布での大小関係))。「右に裾を引くと平均が中央値より大きくなる」という今回の伏線が、そこで本格的に回収されます。
対応するシミュレーション
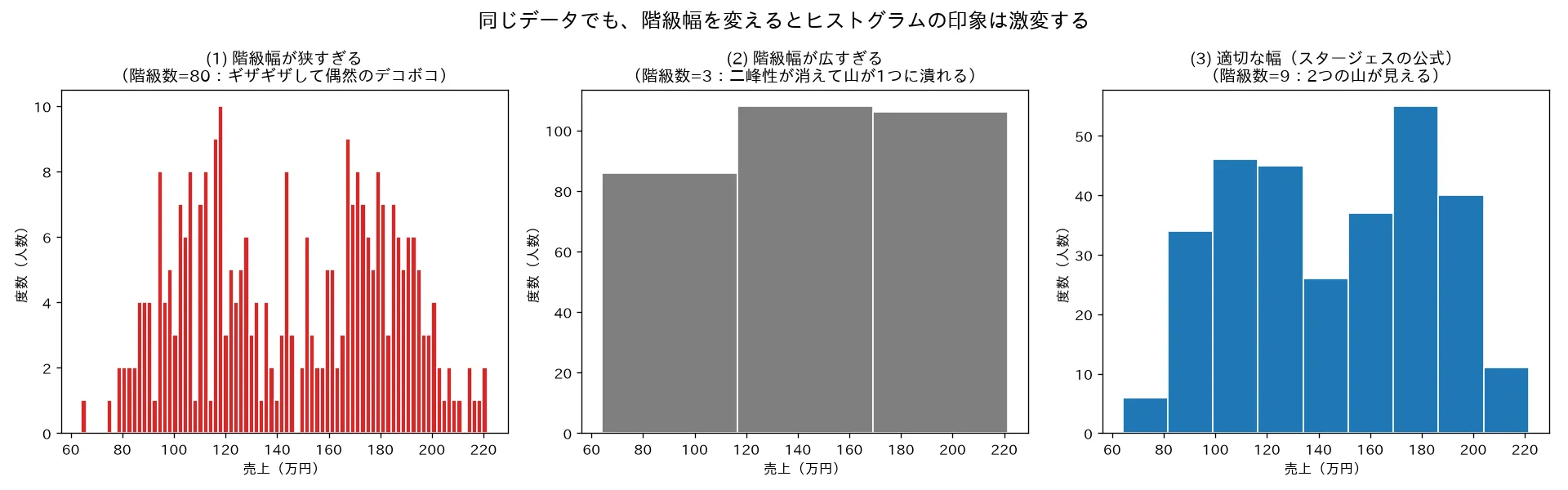
simulations/histogram_kaikyuuhaba.py- 何を示すか:平均110万円と平均180万円の2グループを混ぜた**二峰性データ(n=300)**を、(1)階級幅が狭すぎる(階級数80:ギザギザして偶然のデコボコ)、(2)広すぎる(階級数3:二峰性が消えて単峰に潰れる)、(3)スタージェスの公式どおり(:2つの山が見える)の3通りで描き分ける。
- 結論:まったく同じデータでも階級幅しだいで姿が変わる。狭すぎれば偶然のノイズに惑わされ、広すぎれば「2集団の混在」という本質的特徴が消える。「階級幅は分析者が選ぶ重要な判断」だと目で確認できる。
関連ノート
- 統計グラフの読み方(棒・折れ線・円・帯)と誤解を招くグラフ(統計グラフの読み方 ── 棒・折れ線・円・帯。本ノートの「棒グラフとの違い」はここの続き。前トピック)
- データの種類と尺度水準(データの種類と尺度水準 ── 量的/質的の区別がヒストグラム/棒グラフの使い分けの根拠)
- 代表値 ── 平均・中央値・最頻値の定義と使い分け(外れ値への強さ・歪んだ分布での大小関係)(代表値:平均・中央値・最頻値 ── 階級値から平均を概算/「右に裾=平均が中央値より大」の伏線をここで回収。次トピック)