📊 対象級:4級 ・ 3級 | 重要度:A(頻出)
代表値 ── 平均・中央値・最頻値の定義と使い分け(外れ値への強さ・歪んだ分布での大小関係)
要点(BLUF)
- 代表値はデータの中心を1つの数値で表すもの。3種類:平均(全部足して で割る)/中央値(並べた真ん中、偶数個なら中央2つの平均)/最頻値(最も多い値・階級)。
- 外れ値への強さが決定的に違う:平均は弱い(値の大きさを合計に入れるので1つの極端値で激変)、中央値は強い(順位しか使わないので動きにくい=頑健)。
- 歪んだ分布(単峰連続のおおむねの目安):右に裾→最頻値<中央値<平均/左に裾→平均<中央値<最頻値/左右対称→3つほぼ一致。直感は「平均が裾に引っ張られて飛び出す」。
対象級について:4級〜3級が中心です。4級では「平均・中央値・最頻値の意味」「どれを使うのが適切か」が問われます。3級では一歩進んで「度数分布表から平均を概算する」「歪んだ分布での3つの大小関係」「外れ値に強い/弱い代表値の区別」が問われます。記事の最後で、2級につながる加重平均・幾何平均・調和平均にも軽く触れます。前トピック 度数分布表とヒストグラム ── 階級・相対度数・累積度数とスタージェスの公式 では「右に裾を引くと平均が中央値より大きくなる」と予告だけしました。ここでその伏線を数式付きで回収します。
結論:代表値はデータの中心を1つの数値で表す。3つあり、外れ値への強さが違う
最初に結論です。たくさんの数値データを**「結局どのあたりが中心か」を1つの数値で要約**したものが代表値です。代表値には3つあり、それぞれ計算法も性質も違います。
| 代表値 | 定義(求め方) | 外れ値への強さ | 主に使う尺度 |
|---|---|---|---|
| 平均(算術平均) | 全部の値を足してデータ数で割る | 弱い(1つの極端な値で大きく動く) | 間隔・比率尺度 |
| 中央値(メジアン) | データを大きさ順に並べた真ん中の値 | 強い(順位だけ使うので動きにくい) | 順序・間隔・比率尺度 |
| 最頻値(モード) | 最も多く現れた値(度数が最大の値・階級) | 強い(頻度しか見ない) | すべての尺度(名義尺度でも可) |
そして本記事の核心を先に言います。平均は「値の大きさそのもの」を全部足すので、たった1つの極端な値(外れ値)に引っ張られます。中央値は「順位」しか使わないので外れ値に強い。 この一点を理解すれば、「歪んだ分布で3つがどう並ぶか」も「どの場面でどれを使うべきか」も全部つながります。
直感をつかむ日常例を1つ。ある居酒屋に年収300万円の客が9人いるとします。平均年収も中央値も300万円です。そこへ年収10億円の社長が1人入ってきたらどうなるか。平均年収は一気に約1億円に跳ね上がりますが、中央値は300万円のまま(並べた真ん中はやはり300万円付近)。「平均年収1億円の店」と聞くと豪華に思えますが、実態は「ほとんどが年収300万円」です。外れ値1つで平均は嘘をつくが、中央値は実態を守る ── これが代表値を使い分ける一番の理由です。
3つの代表値の定義と計算
平均(算術平均・相加平均)
データ の算術平均(arithmetic mean) は、全部足してデータ数 で割ったものです。
要するに「全員の値を平等にならして1人あたりにしたら何になるか」です。最もよく使われる代表値ですが、後で見るとおり外れ値に最も弱いのが弱点です。
中央値(メジアン)
データを小さい順(または大きい順)に並べたときの真ん中の値が中央値(median)です。データ数 が奇数か偶数かで求め方が分かれます。
- が奇数のとき:ちょうど真ん中が1つに決まります。並べて 番目の値です。
- 例:データが (5個)なら、真ん中は3番目の 9。
- が偶数のとき:真ん中が2つあるので、その2つの平均を中央値とします。 番目と 番目の平均です。
- 例:データが (4個)なら、真ん中の2つ(2番目の7と3番目の9)の平均で 。
⚠️ 偶数個のときの処理は試験で頻出の引っかけです。「真ん中2つの平均をとる」を忘れて、片方だけ(7だけ、または9だけ)を答えると誤りです。必ず2つの平均をとります。
最頻値(モード)
最も多く現れた値が最頻値(mode)です。
- 生データなら「いちばん回数の多い値」。例: なら 3(3回で最多)。
- 度数分布表なら「度数が最大の階級」、その階級値を最頻値とすることが多いです。例:「131以上154未満」の度数が最大なら、最頻値はその階級値 142.5。
- 最頻値は2つ以上になることもあります(同じ最大度数が複数あれば二峰型・多峰型)。
度数分布表から平均を概算する
生データが手元になく、度数分布表とヒストグラム ── 階級・相対度数・累積度数とスタージェスの公式 で作ったような度数分布表だけがある場合でも、平均を概算できます。各階級の階級値(区間の真ん中)を「その階級の代表値」とみなし、度数で重みづけして足します。
要するに「各階級のみんなが階級値の位置にいると見なして平均をとる」だけです。前トピックの営業30人の売上で実際にやってみます。
| 階級(万円) | 階級値 | 度数 | |
|---|---|---|---|
| 85以上 108未満 | 96.5 | 5 | 482.5 |
| 108以上 131未満 | 119.5 | 8 | 956.0 |
| 131以上 154未満 | 142.5 | 8 | 1140.0 |
| 154以上 177未満 | 165.5 | 5 | 827.5 |
| 177以上 200未満 | 188.5 | 4 | 754.0 |
| 合計 | ― | 30 | 4160.0 |
平均の概算は 万円。
⚠️ これはあくまで近似です。「各階級のデータは全員ちょうど階級値にいる」と仮定しているため、元の生データから計算した本当の平均とは微妙にズレます。試験では「度数分布表から平均を求めよ」と来たら、この階級値 × 度数の総和 ÷ を使います(→ 階級値の意味は 度数分布表とヒストグラム ── 階級・相対度数・累積度数とスタージェスの公式 参照)。
歪んだ分布での3つの大小関係(前トピックの伏線回収)
ここが3級の最頻出論点です。分布の形(歪み方)によって、平均・中央値・最頻値の並ぶ順番が変わります。単峰でなめらかな分布であれば、おおむね次のようになります。
| 分布の形 | 大小関係 | 直感 | 例 |
|---|---|---|---|
| 左右対称 | 平均 ≈ 中央値 ≈ 最頻値 | 3つがほぼ一致 | 身長、測定誤差 |
| 右に裾を引く(正の歪度) | 最頻値 < 中央値 < 平均 | 平均が右の裾に引っ張られる | 年収、売上、貯蓄 |
| 左に裾を引く(負の歪度) | 平均 < 中央値 < 最頻値 | 平均が左の裾に引っ張られる | 満点が多い簡単なテスト |
覚え方はシンプルです。「平均は裾(しっぽ)の方に引っ張られて飛び出す」。
- 右に裾を引く(右に長い尾)→ 平均がその尾に引きずられて右端に出る → だから3つの中で平均が最大。
- 左に裾を引く(左に長い尾)→ 平均が尾に引きずられて左端に出る → だから平均が最小。
- 最頻値は山のてっぺん(最も人が多い位置)なので、裾の影響を受けず山側に残る。
- 中央値はその中間(順位の真ん中)にくる。
なぜ「平均だけが裾に飛び出す」のか。平均は値の大きさをそのまま合計に反映するからです。右の裾にある「年収10億円」のような極端に大きい値は、合計を大きく押し上げ、平均を右へ動かします。一方、最頻値は「いちばん人数が多い場所」しか見ないので裾は無関係。中央値は「人数の半分の位置」なので、極端な値が何個あるかではなく順位でしか効かず、平均ほどは動きません。結果として、裾を引く側に平均が飛び出し、最頻値が反対側に残り、中央値が間に挟まる並びになります。
xychart-beta
title "右に裾を引く分布(正の歪度)のイメージ:山は左、尾が右に長い"
x-axis "値(小 → 大)" [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
y-axis "度数" 0 --> 30
bar [4, 18, 28, 22, 14, 9, 6, 4, 2, 1]
↑ 右に裾を引く分布の形だけを示したイメージ(最頻値は左の山、平均は右の尾に引っ張られて山より右に出る)。ただしこのMermaid棒グラフには平均・中央値・最頻値の位置を示す縦線を引けません。 その位置関係こそが本トピックの主役なので、下の「手描き推奨」の図で押さえてください。
※ここは手描きExcalidraw推奨(主役級の図)。 構図案:横軸を「値」、縦軸を「度数」とし、右に裾を引くなめらかな山型の曲線を1本描く(山のてっぺんは左寄り、右側に長い尾)。その曲線の上に、左から順に縦線を3本引く。 (1)最も左(山のてっぺん)に 最頻値(モード) の縦線、 (2)その少し右に 中央値(メジアン) の縦線、 (3)さらに右(尾の方)に 平均 の縦線。 3本が「最頻値 < 中央値 < 平均」の順で左から右に並ぶことを矢印付きで強調する。「平均は裾に引っ張られて右へ飛び出す」と吹き出しを添えると完璧。左に裾を引く版は左右を反転させるだけ(平均 < 中央値 < 最頻値)。
⚠️ 重要な注意(厳密には経験則):この「右に裾→平均>中央値>最頻値」という並びは、単峰でなめらかな(連続的な)分布についてのおおむねの目安です。実は厳密な定理ではなく、離散的な分布や「片方の尾は長いがもう片方の尾が重い」ような分布では例外が起こることが知られています(von Hippel 2005 はこの教科書ルールの例外を指摘しています)。とはいえ4級〜3級で出題されるのは典型的な単峰分布なので、試験対策としては上の表のとおりで問題ありません。「いつでも100%成り立つ法則ではない」とだけ頭の隅に置いてください。
外れ値への頑健性 ── 平均は弱く、中央値は強い
「歪んだ分布で平均が飛び出す」現象の正体は、平均が外れ値(極端に大きい/小さい値)に弱いことです。これを**頑健性(ロバストネス, robustness)**と呼びます。外れ値が混じっても結果が大きく変わらない統計量を「頑健(ロバスト)である」と言います。
冒頭の居酒屋の例を数値で確認します。
| 状況 | データ | 平均 | 中央値 |
|---|---|---|---|
| 外れ値なし | 300万 × 9人 | 300万 | 300万 |
| 外れ値1つ追加 | 300万 × 9人 + 10億円 × 1人 | 約1億円 | 300万 |
外れ値(10億円)を1つ足しただけで、平均は300万→約1億円へ激変したのに、中央値は300万のままほとんど動きません。
- 平均が弱い理由:平均は で、すべての値の大きさが合計に効く。10億円という極端な値は合計を10億近く押し上げ、それを で割っても平均を大きく動かす。
- 中央値が強い理由:中央値は「並べたときの真ん中の順位の値」。10億円を足しても、それはいちばん右端に1つ増えるだけで、真ん中の順位の値はほとんど変わらない。値がどれだけ極端でも、順位の位置は1つしか動かない。
この性質から、実務では外れ値や強い歪みがあるデータでは中央値を使うのが定石です。年収・地価・世帯資産などを「平均」で語ると一部の富裕層に引っ張られて実態とズレるため、「中央値」で語るのが普通です(ニュースで「年収の中央値」という言葉をよく聞くのはこのためです)。最頻値も頻度しか見ないので外れ値に強いですが、「中心」としては中央値の方が使いやすい場面が多いです。
尺度水準による使い分け ── どの代表値が使えるか
「平均・中央値・最頻値のどれを使ってよいか」は、データの尺度水準(データの種類と尺度水準 で扱った名義・順序・間隔・比率の4分類)で決まります。尺度のレベルが高い(情報が豊かな)ほど、使える代表値が増えます。
| 尺度水準 | 例 | 最頻値 | 中央値 | 平均 |
|---|---|---|---|---|
| 名義尺度 | 血液型、性別、都道府県 | ○ | × | × |
| 順序尺度 | 満足度(5段階)、成績の順位 | ○ | ○ | △(本来は不適切) |
| 間隔尺度 | 温度(℃)、西暦 | ○ | ○ | ○ |
| 比率尺度 | 身長、体重、金額、回数 | ○ | ○ | ○ |
理由を一言で。平均は「足し算・引き算(差)」が意味を持つ尺度でしか使えません。
- 名義尺度(血液型など)は数値の大小も差も意味がないので、「平均血液型」は無意味。最頻値だけが意味を持ちます(「いちばん多い血液型」は言える)。
- 順序尺度(満足度の1〜5など)は順番には意味があるので「真ん中=中央値」は言えますが、「満足度1と2の差」と「4と5の差」が等間隔である保証がないため、平均は本来は不適切です(実務では便宜的に平均をとることもありますが、試験では「順序尺度の平均は不適切」と問われやすい)。
- 間隔尺度・比率尺度は差(や比)が意味を持つので、平均も含めて全部使えます。
⚠️ 試験では「このデータ(例:アンケートの5段階評価)に平均を使うのは適切か」という形で尺度と代表値の対応が問われます。**「平均は間隔・比率尺度から」「順序尺度までなら中央値」「名義尺度は最頻値のみ」**を押さえてください(→ 尺度水準そのものは データの種類と尺度水準)。
2級への接続:平均には他の種類もある(加重平均・幾何平均・調和平均)
ここまでの「平均」は算術平均(相加平均)でした。2級になると、状況に応じて使い分ける別の平均が登場します。3級ではここまで深入りしませんが、存在と用途だけ知っておくと後がスムーズです。
| 平均の種類 | いつ使うか | ざっくりした式 |
|---|---|---|
| 加重平均 | 値ごとに「重み」が違うとき(科目ごとに配点が違うテストの総合点など) | (=重み) |
| 幾何平均 | 成長率・倍率を平均するとき(売上が毎年何倍に伸びたか) | 個の値の積の 乗根 |
| 調和平均 | 速さ・レートを平均するとき(往復の平均速度) | 逆数の算術平均の逆数 |
具体例だけ示します。
- 幾何平均:ある商品の売上が1年目に2倍、2年目に8倍になったとき、「平均して毎年何倍か」は算術平均の 倍では間違い(5倍を2年で 倍にならない)。正しくは幾何平均 倍(4倍を2年で 倍 = 2×8 と一致)。掛け算で積み重なる量は幾何平均。
- 調和平均:行き40km/h・帰り60km/hで同じ道を往復したときの平均速度は km/h では間違い。正しくは調和平均 km/h。速さ(レート)の平均は調和平均。
加重平均・幾何平均・調和平均の詳しい導出と使い分けは2級トピックで扱います。ここでは「算術平均がいつも正しいわけではなく、量の性質(足し算的か・掛け算的か・逆数的か)で適切な平均が変わる」ことだけ覚えてください。
数式の直観的意味
なぜ平均は外れ値に弱く、中央値は強いのか(頑健性の本質)
平均は「値の大きさの総和」を使い、中央値は「順位」しか使わない ── これが頑健性の差の根本。
平均にデータを1つ追加したときの式で見る。元のデータ 個の平均が のとき、値 を1つ加えた新平均は
が極端に大きい(外れ値)と、分子で が支配的になり平均が大きく持ち上がる。外れ値の「大きさそのもの」がダイレクトに平均へ効く。たとえば に (万円)を足すと 万円。たった1個で平均が約34倍に。
対して中央値は順位ベース。 を足すと並びの中で1個ぶん場所が増えるだけで、真ん中の順位の値はせいぜい隣に1ステップずれる程度。外れ値がどれほど極端でも、順位という土俵では「1個ぶん」の影響しかない(値の大きさは無関係)。だから中央値は頑健。
→ 一般化すると、推定量がどれだけ外れ値に耐えるかは「破綻点(breakdown point)」で測る。中央値の破綻点は50%(半分が汚染されるまで壊れない)、平均は0%(1点で無限大に飛ばせる)。これは準1級以降のロバスト統計の入口。
なぜ歪度と「平均-中央値」の大小が連動するのか
直感の核:平均は分布の重心(てこの支点)、中央値は面積を半分に割る位置。
- 平均 は物理的には「データを数直線上の質点と見たときの重心」。右に長い裾があると、遠く右にある(少数の)質点がてこの原理で支点を右へ引っ張る → 平均が右へ。
- 中央値は「個数を半分に割る位置」なので、裾の値が何個あるかでしか効かず、どれだけ遠いかは効かない → 裾の長さの影響を受けにくい。
- 結果、右に裾を引くと平均だけが右(裾側)へ飛び出し、最頻値(山の頂点)が反対側に残り、中央値が間に入る → 最頻値 < 中央値 < 平均。
モーメントで見ると:外れ値は1次モーメント(平均)・2次モーメント(分散)・3次モーメント(歪度)すべてを動かすが、歪度は偏差を3乗するため外れ値の影響が最も大きく出る。「平均が裾へずれること」と「歪度が大きくなること」は、同じ”影響力の大きい点への感度”を別の角度から見たもの(von Hippel 2005)。
⚠️ ただし「右に裾→平均>中央値」は厳密な定理ではなく経験則。単峰連続なら概ね成り立つが、離散分布や「片方の尾は長いが他方が重い」分布では反例が存在する。4〜3級の出題は典型的単峰なので試験対策上は表のとおりでよいが、「いつでも100%成立する法則ではない」と認識しておく。
⚠️ 引っかけポイント・頻出論点・級ごとの差
- 中央値の偶数個処理(頻出): 偶数なら中央2つの平均。片方だけを答えると誤り。
- 歪みでの3者の順序:右に裾=最頻値<中央値<平均/左に裾=逆。「右に裾なのに最頻値(山)は左」というねじれに注意(尾の伸びる向きで決まる、は 度数分布表とヒストグラム ── 階級・相対度数・累積度数とスタージェスの公式 と同じ論理)。
- 尺度別の可否:名義=最頻値のみ/順序=中央値・最頻値(平均は本来不適切)/間隔・比率=平均も可。「5段階評価の平均は適切か」型で問われる。
- 外れ値頑健性:平均は弱い・中央値は強い。「外れ値があるとき平均と中央値どちらが実態を表すか」型。
- 度数分布表からの平均は近似:階級値×度数の総和÷。生データの平均とは一致しない(「全員が階級値にいる」仮定のため)。
- 歪み大小関係は経験則:厳密な定理ではない(離散・変則裾で例外)。試験対策上は典型例でOKだが断定しすぎない。
- 級差:4級=代表値の意味・適切な選択 → 3級=度数分布表からの平均計算・歪みでの大小関係・頑健性。加重/幾何/調和平均は2級。
- 出題範囲は改訂されうるため受験前に最新の範囲表で要確認。
よくある疑問
Q1. 結局、平均・中央値・最頻値のどれを使えばいいの?
データの形と尺度で決めます。 目安はこうです。
- データが左右対称でなめらか(外れ値なし)→ どれを使ってもほぼ同じ。最も情報量の多い平均でよい。
- データが歪んでいる/外れ値がある(年収・地価・資産など)→ 中央値。平均は外れ値に引っ張られて実態とズレる。
- データがカテゴリー(血液型・好きな色など、名義尺度)→ 最頻値しか使えない。
- データが順序だけ(満足度の5段階など、順序尺度)→ 中央値(または最頻値)。平均は本来不適切。
「平均が一番えらい代表値」ではありません。外れ値や歪みがあると平均はむしろ誤解を招くので、場面に応じて使い分けます。
Q2. なぜ偶数個のときは「真ん中2つの平均」をとるの?
真ん中がちょうど1つに決まらないからです。
中央値は「データを順位で半分に割る境目」です。 が奇数なら境目がちょうど1つの値の上にきますが、 が偶数だと境目が2つの値のあいだにきてしまい、どちらか一方を選ぶ理由がありません。そこで**両者の平均(ちょうど真ん中の位置)**を中央値と定義します。たとえば が真ん中なら、その境目は7と9のちょうど中間 にある、という考え方です。
Q3. 「右に裾を引くと平均 > 中央値」は必ず成り立つ法則なの?
いいえ、厳密な定理ではなく”おおむねの目安(経験則)“です。
単峰でなめらか(連続的)な分布なら、ほとんどの場合この大小関係が成り立ちます。ですが、離散的な分布や、片方の尾は長いがもう片方の尾が重いような変則的な分布では例外が起こり得ます(von Hippel 2005 という論文がこの「教科書ルール」の反例を整理しています)。
ただし安心してください。4級〜3級で出題されるのは典型的な単峰分布なので、試験対策としては「右に裾→最頻値<中央値<平均」「左に裾→その逆」で押さえれば十分です。「100%必ず成り立つ法則ではない」という事実だけ、教養として知っておけば誤解せずにすみます。
Q4. 平均はなぜ外れ値にそんなに弱いの?数式で納得したい。
平均の式が「すべての値の大きさを合計に入れる」からです。
平均は 。ここに新しい値 を1つ加えると、新しい平均は
になります。 が10億円のように極端に大きいと、分子の が支配的になり、平均が一気に持ち上がります。外れ値の「大きさそのもの」がダイレクトに平均へ効くわけです。
一方、中央値は「並べたときの順位の真ん中の値」。新しい値を足しても、それは並びの中で1つ場所が増えるだけで、真ん中の順位の値はせいぜい隣の値に1ステップずれる程度です。外れ値がどれだけ極端でも、順位という土俵では1個ぶんの影響しかない。だから中央値は外れ値に強い(頑健)。この「大きさを使う平均 vs 順位を使う中央値」という違いが、頑健性の差の本質です。
Q5. 度数分布表から出した平均と、生データの平均が違うのはなぜ?
度数分布表からの平均は「各階級のデータは全員ちょうど階級値(区間の真ん中)にいる」と仮定した近似だからです。
実際には「131以上154未満」の階級のデータは131〜154のあいだにバラけていますが、度数分布表には個々の値が残っていません。そこで便宜的に「全員142.5(階級値)にいる」とみなして計算します。本当は142.5より大きい人も小さい人もいるので、その仮定の分だけ近似誤差が出ます。生データがあるなら生データから で計算するのが正確で、度数分布表しかないときの妥協が階級値による概算です(→ 階級値の考え方は 度数分布表とヒストグラム ── 階級・相対度数・累積度数とスタージェスの公式)。
まとめ
- 代表値はデータの中心を1つの数値で表す。3種類:平均(全部足して で割る)/中央値(並べた真ん中、偶数個なら中央2つの平均)/最頻値(最も多い値・階級)。
- 度数分布表からの平均概算:。ただし「全員が階級値にいる」とみなす近似。
- 歪んだ分布での大小関係(単峰連続のおおむねの目安):右に裾→最頻値<中央値<平均/左に裾→平均<中央値<最頻値/左右対称→3つほぼ一致。直感は「平均が裾に引っ張られて飛び出す」。厳密には例外もある経験則。
- 外れ値への頑健性:平均は弱い(値の大きさが合計に効くので1つの極端値で激変)、中央値は強い(順位しか使わないので動きにくい)。歪み・外れ値があるデータは中央値で語るのが定石。
- 尺度による使い分け:名義→最頻値のみ/順序→中央値・最頻値/間隔・比率→平均も可。平均は「差が意味を持つ尺度」でしか使えない。
- 2級接続:算術平均のほかに**加重平均(重み付き)・幾何平均(成長率・倍率)・調和平均(速さ・レート)**がある。量の性質で適切な平均が変わる。
- 級差:4級=代表値の意味・適切な選択 → 3級=度数分布表からの平均計算・歪みでの大小関係・頑健性。出題範囲は改訂されうるため受験前に最新の範囲表で要確認。
代表値は「分布を1つの数値に要約する」道具でした。でも中心が同じでも散らばり方が全然違う2つのデータがあり得ます(例:みんな似た点数のクラスと、できる人とできない人に割れたクラス)。次は、この**散らばり(ばらつき)**を測る分散・標準偏差へ進みます(→ 散らばり(ばらつき)の指標 ── 範囲・四分位範囲・分散・標準偏差・変動係数(なぜ偏差を2乗するか/なぜn−1で割るか))。
対応するシミュレーション
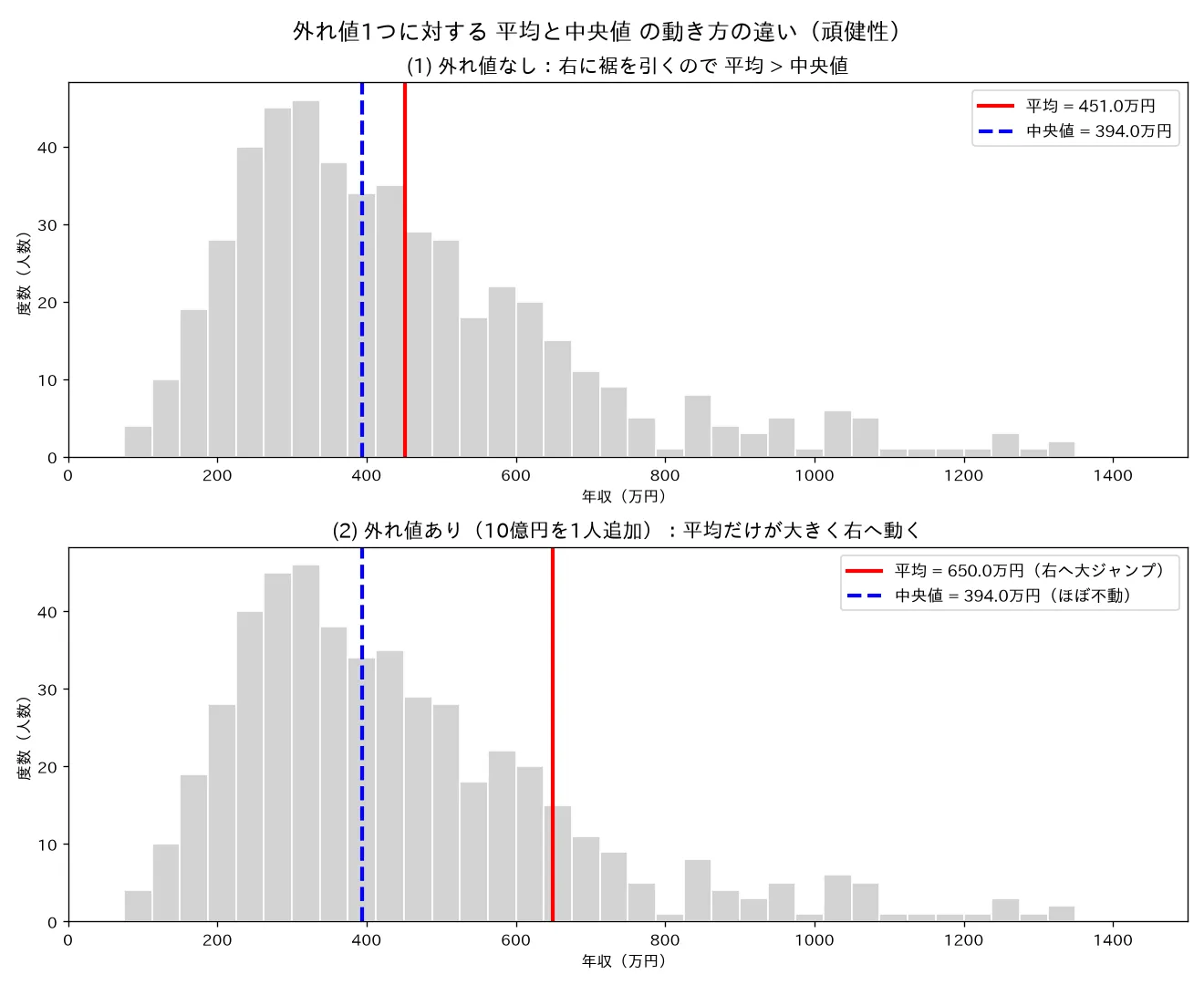
simulations/chuushin_keikou_robustness.py- 何を示すか:(1) 右に裾を引く(対数正規分布)の所得データ で平均>中央値を確認(実行結果:平均451.2万 > 中央値393.8万)。(2) そこへ外れ値10億円を1人追加すると、平均は451.2→649.9万(+198.7万ジャンプ)/中央値は393.8→394.3万(+0.5万のみ=ほぼ不動)。上下2段ヒストグラムに平均(赤実線)・中央値(青破線)の縦線を引き、外れ値で平均の縦線だけが大きく右へ動くことを視覚化。
- 結論:平均は外れ値・歪みに弱く、中央値は強い(頑健)。歪み・外れ値のあるデータは中央値が実態をよく表す。
関連ノート
- 度数分布表とヒストグラム ── 階級・相対度数・累積度数とスタージェスの公式(度数分布表・ヒストグラム ── 階級値から平均を概算する土台/「右に裾=平均が大」の伏線をここで張った。後方リンク・前トピック)
- データの種類と尺度水準(データの種類と尺度水準 ── 名義/順序/間隔/比率の区別が「どの代表値を使えるか」の根拠。後方リンク)
- 散らばり(ばらつき)の指標 ── 範囲・四分位範囲・分散・標準偏差・変動係数(なぜ偏差を2乗するか/なぜn−1で割るか)(散らばり:分散・標準偏差 ── 中心が同じでもばらつきが違うデータを区別する。次トピック・前方リンク)