📊 対象級:3級 ・ 2級 | 重要度:A(頻出)
散らばり(ばらつき)の指標 ── 範囲・四分位範囲・分散・標準偏差・変動係数(なぜ偏差を2乗するか/なぜn−1で割るか)
要点(BLUF)
- 代表値(中心)だけでは不十分。平均が同じでもばらつきが違うデータは別物(前トピック 代表値 ── 平均・中央値・最頻値の定義と使い分け(外れ値への強さ・歪んだ分布での大小関係))。散らばりを1数値にする指標が必要。
- 2系統:順位ベース(範囲・四分位)と平均からの距離ベース(分散・標準偏差・変動係数)。四分位は外れ値に強く、分散・標準偏差・範囲は弱い。
- 3つの「なぜ」が肝:偏差を2乗する理由(単純和は0で消える→正に。2乗は微分可・大ズレ重視・L2整合)/n−1で割る理由(基準が μ でなく なので過小評価→不偏補正、)/変動係数が無次元な理由( と が同単位で約分)。
対象級について:4級〜3級が中心です。4級では「範囲(レンジ)」とばらつきの考え方を扱います。3級では「四分位範囲・四分位偏差」「分散・標準偏差」「変動係数」が問われます。記事の途中で、2級につながる標本分散の n−1(不偏分散)の理由にも踏み込みます(ここは「なぜ n−1 なのか」を数式で納得したい人向けの山場です)。前トピック 代表値 ── 平均・中央値・最頻値の定義と使い分け(外れ値への強さ・歪んだ分布での大小関係) では「中心(代表値)が同じでも散らばり方が全然違うデータがある」と予告しました。ここでその散らばりを測る道具を一通りそろえます。
結論:中心が同じでもばらつきは別物。散らばりの指標は「順位ベース(外れ値に強い)」と「平均ベース(外れ値に弱い)」の2系統
最初に結論です。データを要約するには中心(代表値)だけでは足りません。平均が同じでも、ぎゅっと固まっているデータと、広くばらけているデータは「別物」だからです。そのばらけ具合を1つの数値にしたものが散らばり(ばらつき)の指標です。
主な指標は次の5つ。大きく**「順位ベース(外れ値に強い)」と「平均からの距離ベース(外れ値に弱い)」**の2系統に分かれます。
| 指標 | 定義(求め方) | 単位 | 外れ値への強さ | 主な級 |
|---|---|---|---|---|
| 範囲(レンジ) | 最大値 − 最小値 | 元データと同じ | 弱い(両端しか見ない) | 4級 |
| 四分位範囲 IQR | 第3四分位数 Q3 − 第1四分位数 Q1 | 元データと同じ | 強い(順位ベース) | 3級 |
| 四分位偏差 | IQR ÷ 2 | 元データと同じ | 強い(順位ベース) | 3級 |
| 分散 | 平均からのズレ(偏差)の2乗の平均 | 元データの2乗 | 弱い(2乗するので極端値に過敏) | 3級〜 |
| 標準偏差 | 分散の平方根 | 元データと同じ | 弱い(分散と同じ) | 3級〜 |
| 変動係数 CV | 標準偏差 ÷ 平均 | 無次元(単位なし) | 弱い(分散ベース) | 3級 |
本記事の核心を先に3つ言っておきます。
- 分散はなぜ偏差を「2乗」するのか ── ただ足すと で消えてしまうから。2乗(または絶対値)で正にする。2乗を選ぶのは「微分しやすく・大きなズレを重く見て・正規分布や分散分解と整合する」ため。
- 標本分散はなぜ「n−1」で割るのか ── 偏差を測る基準が真の平均 ではなく、手元データに最もフィットする標本平均 だから。 で測ると偏差の2乗和が小さめに出る → n で割ると母分散を過小評価 → n−1 で割って補正する。
- 変動係数はなぜ単位が消えるのか ── 標準偏差 と平均 が同じ単位なので、比をとると単位が約分されて消える。だから単位や桁が違うデータ同士のばらつきを比べられる。
直感をつかむ日常例を1つ。2つのクラスの数学のテストを考えます。A組もB組も平均点は60点で同じ。でもA組は「みんな55〜65点」に固まっていて、B組は「30点と90点に真っ二つ」。平均だけ見ると2クラスは同じですが、中身はまったく違います。A組は全員が似た理解度、B組は「できる人とできない人に割れている」。この違いを数値で捉えるのが散らばりの指標です。「平均60点」だけでは、このクラスの実態は半分しか語れない ── これが散らばりを測る一番の理由です。
この「平均は同じでも散らばりが違う」様子を図にすると一目です。下の2つはどちらも**平均が同じ(中心の位置が同じ)**ですが、片方は幅が狭く(ばらつき小)、片方は幅が広い(ばらつき大)。
xychart-beta
title "平均は同じ・散らばりが違う2つの分布(中心は同じでも別物)"
x-axis "値(中心を50とする)" [20, 30, 40, 50, 60, 70, 80]
y-axis "度数" 0 --> 40
bar [1, 6, 22, 36, 22, 6, 1]
bar [8, 14, 20, 24, 20, 14, 8]
↑ 1本目(細い山)はばらつきが小さく中心に集中、2本目(平たい山)はばらつきが大きく広がっている。山の頂点(中心)の位置は両方とも同じなのに分布の形はまるで違う。代表値だけでは捉えられないこの「広がりの差」を数値化するのが、これから扱う散らばりの指標です。
範囲(レンジ)── 一番単純だが外れ値に弱い
範囲(range, レンジ)は、データの最大値から最小値を引いたもの。一番単純なばらつきの指標です。
要するに「データが端から端まで何ぶん広がっているか」です。計算は楽ですが、弱点があります。両端の2つの値しか使わないので、その片方が外れ値だと範囲が一気に大きくなります。
例:テストの点が なら範囲は 。ここに1人だけ 点が混じると で範囲は 。たった1つの値で範囲が3倍以上に。中身(多くの人が52〜65に固まっている事実)は変わらないのに、範囲はそれを反映できません。だから範囲は「ばらつきのざっくりした目安」にはなりますが、外れ値があると当てになりません。
四分位数と四分位範囲 ── 順位ベースで外れ値に強い
範囲の「外れ値に弱い」弱点を解決するのが四分位範囲です。発想は「両端の極端な値を捨てて、**真ん中の50%**がどれくらい広がっているかを見る」こと。
四分位数(Q1・Q2・Q3)
データを小さい順に並べ、4等分する位置の値を四分位数(quartile)と呼びます。
| 名前 | 記号 | 意味 |
|---|---|---|
| 第1四分位数 | 下から 25% の位置の値(下位1/4の境目) | |
| 第2四分位数 | 下から 50% = 中央値(代表値 ── 平均・中央値・最頻値の定義と使い分け(外れ値への強さ・歪んだ分布での大小関係) の中央値と同じ) | |
| 第3四分位数 | 下から 75% の位置の値(上位1/4の境目) |
は中央値そのものです。 は「下半分のデータの中央値」、 は「上半分のデータの中央値」と考えると求めやすいです(細かい計算規約は流派が複数ありますが、3級ではこの素朴な定義で足ります)。
四分位範囲(IQR)と四分位偏差
- 四分位範囲(Interquartile Range, IQR): と の差。真ん中50%のデータが広がる幅です。
- 四分位偏差:IQR を2で割ったもの。
IQR は要するに「上下の極端な25%ずつを無視して、中央の50%だけの幅を見る」指標です。両端を捨てるので、外れ値が混じっても値がほとんど変わりません。これが順位ベースの指標が外れ値に強い理由です(中央値が外れ値に強いのと同じ理屈 → 代表値 ── 平均・中央値・最頻値の定義と使い分け(外れ値への強さ・歪んだ分布での大小関係))。
IQR と四分位数の位置関係、そして「Q1−1.5×IQR より小さい/Q3+1.5×IQR より大きい値を外れ値とみなす」という外れ値の判定ルール、それらを一目で見せる箱ひげ図は、次のトピックでまとめて扱います(→ 箱ひげ図と外れ値 ── 5数要約・ひげの2流派・1.5×IQRルール(なぜ係数が1.5なのか/約2.7σ・0.7%))。ここでは「IQR は中央50%の幅で、外れ値に強い」ことだけ押さえてください。
分散と標準偏差 ── 平均からの距離で測る主役の指標
四分位範囲が「順位」で散らばりを測るのに対し、分散と標準偏差は「平均からどれだけ離れているか(距離)」で測ります。統計学でいちばんよく使う散らばりの指標で、推定・検定・回帰すべての土台になります。
偏差 ── 平均からのズレ
まず各データ が平均 からどれだけ離れているかを偏差と呼びます。
「この値は平均より何ぶん上(下)か」です。散らばりは「偏差が全体としてどれくらい大きいか」で測りたい。ところが、偏差をそのまま全部足すと必ず 0 になります。
プラスの偏差とマイナスの偏差がちょうど打ち消し合うからです(これは平均の定義そのものから来る性質)。これでは散らばりの大きさを測れません。そこで偏差を正の値に変えてから足す必要があります。方法は2つ ──「2乗する」か「絶対値をとる」か。統計学では主に2乗を使います(理由は後の「数式の直観的意味」で詳しく述べます)。
母分散(÷ n)と標準偏差
データ全体(母集団)が手元にあるときの分散を母分散(population variance) と呼び、偏差の2乗の平均で定義します。
要するに「平均からのズレを2乗して、その平均をとった」もの。値が大きいほど散らばりが大きい。ただし偏差を2乗したので、分散の単位は元データの2乗になります(点数なら「点²」、円なら「円²」)。単位が2乗だと直感的に解釈しづらいので、平方根をとって元の単位に戻したものが標準偏差(standard deviation) です。
標準偏差は「だいたい平均からどれくらいズレているか」を、元データと同じ単位で表したものと考えてください。点数の標準偏差が8点なら「平均から上下8点くらいが標準的なバラつき」というイメージです。
分散の別公式(2乗の平均 − 平均の2乗)
分散は次の形に変形できます。試験の計算ではこちらの方が速いことが多い、頻出の公式です。
「2乗の平均」から「平均の2乗」を引くだけ。導出は定義式を展開するだけです。
ここで なので、 となり、 が出ます。偏差をいちいち計算しなくても、「値の2乗の合計」と「値の合計」さえあれば分散が出るのがこの公式の便利なところです。
標本分散(不偏分散・÷ n−1)── 2級への接続
ここが本トピックの山場です。手元のデータが「母集団の一部(標本)」で、そこから母集団の分散 を推定したいとき、さきほどの「÷ n」では母分散を小さめに見積もってしまうことが知られています。これを補正したのが標本分散(不偏分散, unbiased variance) で、n ではなく n−1 で割ります。
そして不偏分散の平方根を**(不偏)標準偏差** と呼びます。
「なぜ n ではなく n−1 なのか」は、ただ覚えるだけでは試験で取りこぼします。次のセクションで数式で導出します。ここでは用語だけ整理しておきます。
| 名前 | 割る数 | 記号 | 使う場面 |
|---|---|---|---|
| 母分散 | データ全体(母集団)が手元にある/記述統計として散らばりを述べる | ||
| 標本分散(不偏分散) | 標本から母集団の分散を推定する |
⚠️ 関数電卓には標準偏差のキーが2つあります。(または σ)が母分散ベース(÷ n)、**(または s)が不偏分散ベース(÷ n−1)**です。どちらを使うべきかは「母集団そのものか/標本からの推定か」で決まります。試験ではこの取り違えが頻出の失点ポイントです。
変動係数 ── 単位に依存しない相対的な散らばり
標準偏差は「絶対的な散らばり」を元データの単位で測ります。しかし、単位や桁がまるで違うデータ同士のばらつきを比べたいときには使えません。たとえば「成人男性の身長(cm)のばらつき」と「成人男性の体重(kg)のばらつき」、どちらが相対的に大きいか? 単位が違うので標準偏差を直接比べても無意味です。
そこで使うのが変動係数(Coefficient of Variation, CV)。標準偏差を平均で割ったものです。
要するに「平均に対して、どれくらいの割合で散らばっているか」。標準偏差を「平均何個ぶんか」に換算した相対的なばらつきです。百分率(%)で表すこともあります。
変動係数は単位を持ちません(無次元)。 も も同じ単位なので、割り算で単位が約分されて消えるからです(例:cm ÷ cm = 単位なし)。だから「身長のCV」と「体重のCV」のように、単位の違うデータ同士でもばらつきの大小を比較できます。
⚠️ 変動係数が意味を持つのは「比率尺度の、正の値のデータ」だけです。平均が 0 に近いと分母が小さくなって CV が暴れますし、負の値を含むデータ(気温℃など間隔尺度)では平均が 0 や負になりCVが無意味になります。「金額・身長・回数」のような0が原点で必ず正のデータ(比率尺度 → データの種類と尺度水準)でだけ使ってください。
数式の直観的意味
ここからが本トピックの理論的な肝です。3つの「なぜ」を順に潰します。
1. なぜ偏差を「2乗」するのか(絶対値ではなく)
出発点:散らばりは「偏差 が全体としてどれくらい大きいか」で測りたい。でも前述のとおり、偏差をそのまま足すと
で必ず消える。プラスとマイナスが打ち消し合うから。だから偏差を正の量に変えてから足す必要がある。正に変える方法は2つ ──「絶対値 」か「2乗 」。
絶対値を使ったものは平均絶対偏差(MAD: Mean Absolute Deviation) と呼ばれ、これはこれで立派な散らばりの指標です。それでも統計学が2乗(分散)を主役にするのには、明確な理由があります。
- (a) 微分しやすい(数学的に扱いやすい):絶対値 は原点 で折れ曲がっていて微分できません。一方 2乗 はどこでもなめらかに微分できます。後で出てくる最小二乗法・最尤推定・分散分析など、統計の主要な手法は「ある量を微分して0と置いて最小化する」操作を多用します。2乗だとこの操作がきれいに解け、絶対値だと場合分けが必要で扱いにくい。**「平均 は偏差の2乗和 を最小にする点 」**という美しい性質( で微分して0と置くと が出る)も、2乗を使うからこそ成り立ちます。
- (b) 大きなズレをより重く評価する:2乗すると、偏差が2倍のデータは寄与が4倍、3倍なら9倍になります。「平均から大きく外れた値」を強く効かせたい場面では、この性質が望ましい(逆に外れ値に過敏になるという裏返しもある)。
- (c) 正規分布・分散分解と整合する(L2の世界):正規分布の確率密度の指数部分は偏差の2乗 で、分散がそのまま自然に現れます。また「全体の変動 = 群間変動 + 群内変動」のように変動が2乗和でピタゴラスの定理のように分解できる(分散分析・回帰の の土台)のも、2乗(ユークリッド距離=L2ノルム)を使うからです。絶対値(L1)ではこの分解は成り立ちません。
まとめると、**「2乗は数学的に扱いやすく、大きなズレを重視し、正規分布や分散分解という統計の主要な枠組みと噛み合う」**から主役に選ばれている、ということです。絶対偏差(MAD)は外れ値に強いという長所があり、ロバスト統計では使われます(→ 準1級以降)。
2. なぜ標本分散は「n−1」で割るのか(不偏性・自由度・ベッセル補正)
核心を一言で:偏差を測る基準が、真の平均 ではなく手元データから計算した標本平均 だから。 は「そのデータに最もよくフィットする点」なので、 からの偏差の2乗和は、真の からの偏差の2乗和より必ず小さくなる。だから n で割ると母分散を過小評価してしまい、n−1 で割って補正する。
なぜ からの2乗和が一番小さいか:前述の(a)の性質です。関数 を で微分して0と置くと、最小になるのは 。つまり「どの点 から測った2乗和も、 のときが最小」。真の平均 は一般に とずれているので、 となる。本来 を基準に測りたいのに、より小さく出る 基準で測っているぶん、分散が過小評価される。
導出スケッチ( になることの確認):偏差平方和 の期待値を計算します。 を足して引く形に分解するのがコツです。
これを展開すると(クロス項 は を使うと になり、最後の項 と合わせて整理できて)、
「 からの2乗和」は「真の からの2乗和」より、ちょうど ぶん小さいことがこの式から見えます(過小評価のぶんが定量化された)。両辺の期待値をとります。
- 第1項:(母分散の定義そのもの)なので、。
- 第2項:(標本平均の分散は母分散の 。これは独立な 個の平均をとると分散が になるという基本性質)。よって 。
したがって
偏差平方和の期待値は であって ではない。だから n で割ると で過小評価。n−1 で割れば
ぴたりと母分散に一致する。これが「期待値が真の値に一致する=不偏(unbiased)」という性質で、n−1 で割る操作を**ベッセル補正(Bessel’s correction)**と呼びます。
自由度(degrees of freedom)の視点:別の言い方をすると、偏差 には という1本の束縛(制約)がかかっています。 個の偏差のうち 個を自由に決めると、残り1個は「合計が0」から自動的に決まってしまう。つまり自由に動ける偏差は実質 個しかない。これが「自由度 」の意味です。「標本平均 を1つ推定に使ったぶん、自由度が1減った」と理解してください。分散は「平均的な散らばり」なので、自由に動ける個数 で割るのが理にかなっている、というわけです。
「n が大きければ n と n−1 の差は誤差じゃないの?」 ── そのとおりで、 が大きいと なので両者はほぼ一致します。差が効くのは が小さいとき( なら n で割ると母分散の しか見積もれず、2割も過小評価する)。だから小標本ほど不偏分散が重要になります。
3. なぜ変動係数は無次元(単位なし)なのか
と がまったく同じ単位だから、比をとると単位が約分されて消えます。
たとえば身長なら も も cm。 で単位が消える。体重なら kg ÷ kg で消える。単位が消えるからこそ、cm の世界の値と kg の世界の値を同じ土俵で比べられるわけです。これが「単位や桁が違うデータ同士の相対的なばらつきを比較できる」理由です。標準偏差そのものは単位を持つ(cm のまま、kg のまま)ので、この比較ができません。
別の見方をすると、CV は「スケール変換 ()で値が変わらない」量です。全データを2倍すれば も も2倍になり、比は不変。単位換算(m→cm は100倍)もスケール変換の一種なので、CV は単位の選び方に依らない ── これが「無次元」の数学的な意味です。
⚠️ 引っかけポイント・頻出論点・級ごとの差
- 母分散(÷n)と不偏分散(÷n−1)の混同(頻出):電卓の / を取り違える。「母集団全体か/標本からの推定か」で決まる。推定・検定の文脈はほぼ n−1。
- 標準偏差は元データと同単位・分散は2乗単位:「分散の単位は?」型。報告は標準偏差、理論計算は分散( が使える)。
- 変動係数は比率尺度の正データ限定:平均0近傍で暴れる/負を含む間隔尺度(気温℃)では無意味。「CVを使ってよいデータはどれか」型。
- 外れ値耐性の区別:範囲=弱い(両端のみ)/四分位範囲・四分位偏差=強い(順位)/分散・標準偏差=弱い(2乗で過敏)。中央値が強いのと同じ理屈(→ 代表値 ── 平均・中央値・最頻値の定義と使い分け(外れ値への強さ・歪んだ分布での大小関係))。
- 別公式 :「2乗の平均 − 平均の2乗」。順序を逆にしない。
- n−1 の理由を「自由度だから」で終わらせない:基準が で過小評価→不偏補正、という中身まで(2級で導出を問われうる)。
- 級差:4級=範囲・ばらつきの考え方 → 3級=四分位範囲・分散・標準偏差・変動係数 → 2級=不偏分散(n−1)・自由度・不偏性。
- 出題範囲は改訂されうるため受験前に最新の範囲表で要確認。
よくある疑問
Q1. 結局、分散は n で割るの? n−1 で割るの? どっちが正解?
「何をしたいか」で決まります。 二択ではなく使い分けです。
- 手元のデータがすべて(母集団そのもの)で、その散らばりをただ記述したい → n で割る(母分散 )。例:あるクラス40人全員のテストの散らばりを述べる。
- 手元のデータは一部(標本)で、そこから母集団の分散を推定したい → n−1 で割る(不偏分散 )。例:全国の受験生から100人を抽出し、全国の散らばりを推定する。
統計検定の推定・検定の文脈ではほぼ常に「標本から母集団を推定する」ので **n−1(不偏分散)**を使います。一方、純粋に記述統計として目の前のデータの散らばりを言うだけなら n でも構いません。問題文が「標本」「推定」と言っているか「母集団全体」と言っているかを必ず確認してください。
Q2. n−1 で割る理由、結局どう理解すればいい?
**「偏差を測る基準を、真の平均 ではなく標本平均 で代用しているから」**の一点です。
は手元データに最もフィットする点なので、 からの偏差の2乗和は、本当に測りたい からの2乗和より必ず小さめに出ます。だから n で割ると母分散を小さく見積もる。その「小さめに出るぶん」がちょうど自由度1個ぶんに相当するので、n ではなく n−1 で割ると過小評価が補正され、期待値が母分散にぴたり一致します(本文の導出で を示したとおり)。**「 を1個推定に使った → 自由に動ける偏差が1個減った → だから n−1」**と覚えてください。
Q3. 分散と標準偏差、どっちを使えばいいの? 違いは?
値の意味は同じ(散らばりの大きさ)。違いは単位です。 標準偏差 = √分散 という関係で、分散の単位は元データの2乗、標準偏差は元データと同じ単位です。
- 解釈・報告には標準偏差:元データと同じ単位なので「平均60点 ± 標準偏差8点」のように直感的に読める。
- 理論計算には分散:分散には「独立な変数の和の分散は分散の和になる()」のような扱いやすい性質があり、数式の途中計算では分散のまま進めることが多い。
要するに「計算は分散で進め、最後に√して標準偏差で解釈する」のが定石です。
Q4. 変動係数はいつ使うの? 標準偏差じゃダメなの?
単位や平均の桁がまるで違うデータ同士で、ばらつきの大小を比べたいときに使います。
標準偏差は単位付きの絶対的なばらつきなので、「身長の標準偏差6cm」と「体重の標準偏差10kg」を直接比べても、どちらが相対的にばらついているかは言えません(単位が違う)。変動係数なら単位が消えるので、「身長のCV ≈ 0.035、体重のCV ≈ 0.15」のように同じ土俵で比較でき、「体重のほうが相対的にばらつきが大きい」と言えます。平均が大きく違うデータ同士でも同様です(平均1000のデータと平均10のデータでは、同じ標準偏差5でも意味がまるで違う ── 前者は相対的に小さなばらつき、後者は大きなばらつき。CVがこれを正しく捉える)。ただしQ5の注意があります。
Q5. 変動係数を使ってはいけないのはどんなとき?
平均が0に近いデータ、負の値を含むデータ、間隔尺度のデータでは使えません。
CV = 標準偏差 ÷ 平均 なので、平均(分母)が0に近いと値が爆発して無意味になります。また気温(℃)のように**負の値をとる/原点が便宜的なデータ(間隔尺度 → データの種類と尺度水準)**では、平均が0や負になりCVの符号や大きさが意味をなしません。「平均5℃のときCV」と言っても、同じ寒暖差を℉で測れば平均が変わってCVも変わってしまう(単位の取り方でCVが動く=無次元の利点が崩れる)。CVが意味を持つのは「金額・身長・重さ・回数」のように原点0が絶対的で必ず正の値をとる比率尺度のデータだけ、と覚えてください。
Q6. 範囲・四分位範囲・分散・標準偏差、外れ値に強いのはどれ?
順位ベースの「範囲以外」── つまり四分位範囲・四分位偏差が外れ値に強いです。整理すると:
- 範囲:最大・最小という両端の極端な値そのものを使うので、外れ値に最も弱い。外れ値があると範囲はその外れ値で決まってしまう。
- 四分位範囲・四分位偏差:上下25%ずつを捨てて中央50%だけ見るので、外れ値に強い(頑健)。中央値が外れ値に強いのと同じ理屈(→ 代表値 ── 平均・中央値・最頻値の定義と使い分け(外れ値への強さ・歪んだ分布での大小関係))。
- 分散・標準偏差:偏差を2乗するので、平均から大きく離れた外れ値の寄与が極端に大きくなり、外れ値に弱い。
だから「外れ値・強い歪みのあるデータの散らばり」を語るときは、分散・標準偏差より四分位範囲のほうが実態を表します(中央値とセットで使うのが定石)。これも箱ひげ図の話につながります(→ 箱ひげ図と外れ値 ── 5数要約・ひげの2流派・1.5×IQRルール(なぜ係数が1.5なのか/約2.7σ・0.7%))。
まとめ
- 散らばりの指標はデータのばらつきを1つの数値で表す。中心(代表値)が同じでもばらつきは別物なので、代表値とセットで必要(前トピック 代表値 ── 平均・中央値・最頻値の定義と使い分け(外れ値への強さ・歪んだ分布での大小関係))。
- 範囲 = 最大 − 最小。単純だが両端しか見ないので外れ値に弱い(4級)。
- 四分位範囲 IQR = (中央50%の幅)、四分位偏差 = IQR/2。順位ベースで外れ値に強い(3級。箱ひげ図・外れ値判定は → 箱ひげ図と外れ値 ── 5数要約・ひげの2流派・1.5×IQRルール(なぜ係数が1.5なのか/約2.7σ・0.7%))。
- 分散:偏差の2乗の平均。母分散 。標準偏差 = √分散で元データと同じ単位(分散は2乗単位)。別公式 (2乗の平均 − 平均の2乗)。
- 標本分散(不偏分散) 。n−1 で割る理由:偏差の基準が真の平均 でなく標本平均 で、 基準だと2乗和が小さめに出る → n では過小評価 → n−1 で補正すると (不偏)。自由度 = 束縛 により自由に動ける偏差が 個(2級接続)。
- 偏差を2乗する理由:単純和は0で消える → 正にする。2乗を選ぶのは微分しやすい・大きなズレを重視・正規分布や分散分解と整合(L2の世界)。絶対値版(MAD)は外れ値に強いがロバスト統計向け。
- 変動係数 CV = 。無次元( と が同単位で約分)なので単位・桁が違うデータのばらつきを比較できる。ただし比率尺度の正データ限定(平均0近傍・負を含むと不適)。
- 級差:4級=範囲・ばらつきの考え方 → 3級=四分位範囲・分散・標準偏差・変動係数 → 2級=不偏分散(n−1)の意味・自由度。出題範囲は改訂されうるため受験前に最新の範囲表で要確認。
散らばりを測る道具がそろいました。次は、四分位数を使った箱ひげ図でばらつきと外れ値を視覚化する方法へ進みます(→ 箱ひげ図と外れ値 ── 5数要約・ひげの2流派・1.5×IQRルール(なぜ係数が1.5なのか/約2.7σ・0.7%))。
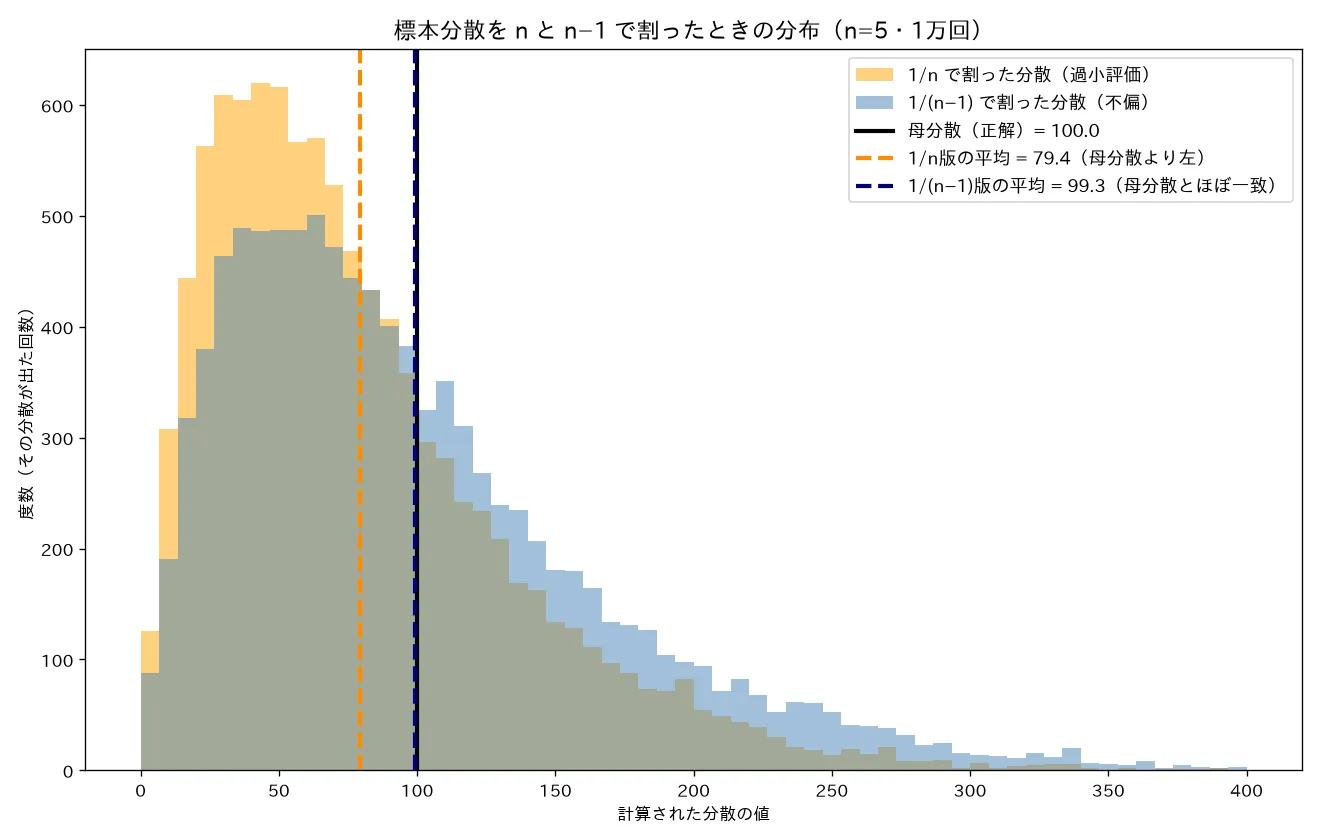
対応するシミュレーション
simulations/fuhen_bunsan_bessel.py- 何を示すか:母分散がわかっている正規分布(母分散=100)から小標本 n=5 を1万回取り、毎回「÷n の分散」と「÷(n−1) の分散」を計算してそれぞれの平均を出す。「標本分散を n で割ると母分散を過小評価し、n−1 で割ると不偏になる(ベッセル補正)」ことを数値実験で確認する。
- 実行結果:÷n版の平均 = 79.44(母分散100より小さい=過小評価。理論値 とほぼ一致)/÷(n−1)版の平均 = 99.29(母分散100にほぼ一致=不偏)/母分散(正解)= 100。2つの推定値の分布をヒストグラムで重ね、母分散の縦線に対し「÷n版の平均は左にずれ、÷(n−1)版の平均は真上に来る」ことを可視化。
- 結論:理論で導いた が数値実験で再現。n では過小評価、n−1 で不偏。差が効くのは小標本。
関連ノート
- 代表値 ── 平均・中央値・最頻値の定義と使い分け(外れ値への強さ・歪んだ分布での大小関係)(代表値:平均・中央値・最頻値 ── 中心が同じでも散らばりが違うデータは別物、という本トピックの出発点。中央値=。外れ値への頑健性の論理も共通。後方リンク・前トピック)
- 度数分布表とヒストグラム ── 階級・相対度数・累積度数とスタージェスの公式(度数分布表・ヒストグラム ── 分布の「形(広がり)」を可視化する土台。散らばりはその形を1数値に要約したもの。後方リンク)
- 箱ひげ図と外れ値 ── 5数要約・ひげの2流派・1.5×IQRルール(なぜ係数が1.5なのか/約2.7σ・0.7%)(箱ひげ図・外れ値 ── 四分位数を図で可視化し、/ で外れ値を判定する。本トピックのIQRを図に落とす次トピック。前方リンク)