📊 対象級:3級 ・ 2級 | 重要度:A(頻出)
箱ひげ図と外れ値 ── 5数要約・ひげの2流派・1.5×IQRルール(なぜ係数が1.5なのか/約2.7σ・0.7%)
要点(BLUF)
- 箱ひげ図=5数要約(最小・・中央値・・最大)を1枚にした図。箱=〜(長さ=IQR)/箱の中の線=中央値/ひげ/外れ値の点。読み取りは4級、外れ値判定は3級〜2級。
- ひげの2流派:素朴版(最小〜最大)とTukey版(ひげ=フェンス内の最端データ、フェンス外=外れ値の点)。試験はTukey版。ひげの先=フェンスではなく実データの最端(頻出誤解)。
- 外れ値= 未満/ 超。なぜ1.5か:正規分布でフェンス≒±2.7σ=外れ値約0.7%(拾いすぎず見逃しすぎない)。四分位ベースは順位なので外れ値に強い(→ 散らばり(ばらつき)の指標 ── 範囲・四分位範囲・分散・標準偏差・変動係数(なぜ偏差を2乗するか/なぜn−1で割るか))。
対象級について:3級が中心です。箱ひげ図の読み取りそのものは4級でも触れます。外れ値の1.5×IQR判定は3級〜2級にまたがる頻出論点です。前トピック 散らばり(ばらつき)の指標 ── 範囲・四分位範囲・分散・標準偏差・変動係数(なぜ偏差を2乗するか/なぜn−1で割るか) でそろえた四分位数()と四分位範囲 IQR を、ここで1枚の図に落とし込みます。さらに「なぜ外れ値の係数が 1.5 なのか」を、正規分布での計算(約±2.7σ・全体の約0.7%)まで踏み込んで説明します。
結論:箱ひげ図は「5数要約を1枚にした図」。外れ値は IQR/IQR の外側
最初に結論です。**箱ひげ図(box-and-whisker plot)は、データを5つの数(5数要約)**に圧縮して1枚の図にしたものです。5数要約とは次の5つ。
| 5数要約 | 記号 | 箱ひげ図での位置 |
|---|---|---|
| 最小値 | min | ひげの左端(素朴版) |
| 第1四分位数 | 箱の左端 | |
| 中央値 | 箱の中の線 | |
| 第3四分位数 | 箱の右端 | |
| 最大値 | max | ひげの右端(素朴版) |
そして**外れ値(outlier)**は、次の境界線(フェンス)の外側にあるデータと判定します。
ここで (四分位範囲=中央50%の幅 → 散らばり(ばらつき)の指標 ── 範囲・四分位範囲・分散・標準偏差・変動係数(なぜ偏差を2乗するか/なぜn−1で割るか))です。要するに「箱(中央50%)の幅の1.5倍ぶん、箱の外側に引いた線を越えたら外れ値」ということ。本記事で深掘りする核心を先に3つ言っておきます。
- ひげには2つの流派がある ── 素朴版(最小〜最大まで伸ばす)と、現代の標準であるTukey版(ひげはフェンス内の最端データまで、フェンスを越えた点は外れ値として個別に打つ)。試験で問われるのはTukey版です。
- なぜ係数が 1.5 なのか ── 正規分布だとフェンスが約±2.7σに来て、外れ値になるのは**全体の約0.7%**だけ。「拾いすぎず・見逃しすぎない」絶妙な閾値だからです(後で数式で示します)。
- 箱ひげ図の最大の利点は複数群の一括比較。一方で二峰性など分布の細かい形は隠れる(そこはヒストグラムの出番 → 度数分布表とヒストグラム ── 階級・相対度数・累積度数とスタージェスの公式)。
箱ひげ図の構造 ── 箱・ひげ・外れ値の点
箱ひげ図は、前トピック 散らばり(ばらつき)の指標 ── 範囲・四分位範囲・分散・標準偏差・変動係数(なぜ偏差を2乗するか/なぜn−1で割るか) で求めた四分位数を数直線の上に図示したものです。構成要素は次のとおり。
- 箱(box): から まで。箱の長さ = IQR(中央50%のデータが入る幅)。
- 箱の中の線:中央値 。箱を「中央値で2つに区切る」線です。
- ひげ(whisker):箱から左右(または上下)に伸びる線。どこまで伸ばすかが流派で違う(次節)。
- 外れ値の点:フェンスを越えたデータを、ひげとは別に**個別の点(○や*)**で打つ。
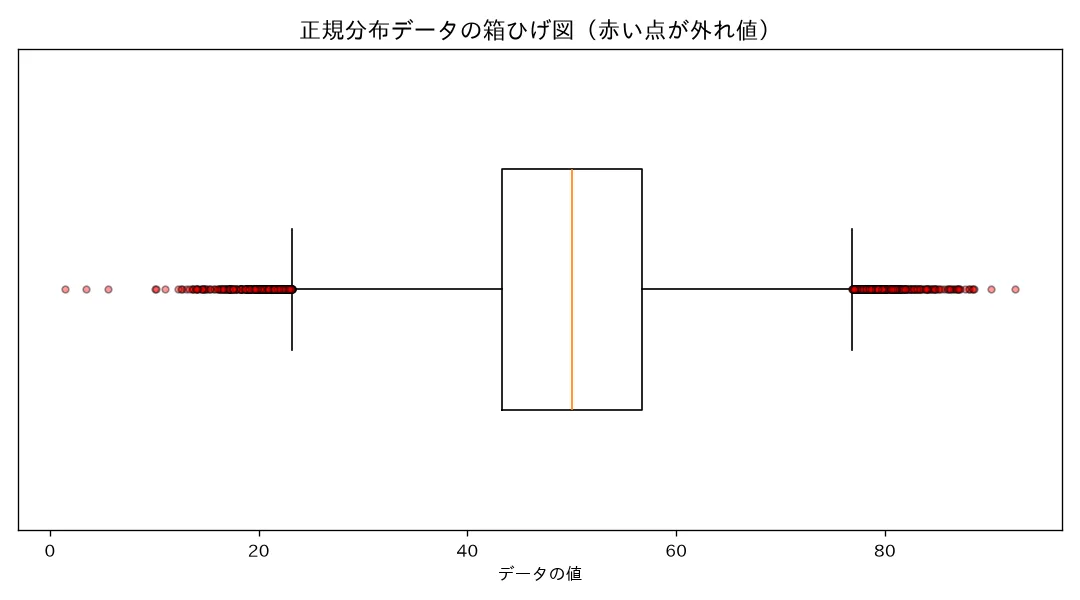
※ここは手描きExcalidraw推奨 箱ひげ図そのものの構造図は、Mermaidでは綺麗に描けない「主役級」の図です。手描きで作る場合の構図案: 数直線を1本(横向き)引く → その上に長方形の「箱」を置き、箱の左端に 、右端に のラベル → 箱の中に縦線を1本引いて「中央値 」 → 箱の左右から水平の「ひげ」を伸ばし、その先端に「フェンス内の最端データ」と注記 → ひげの外側に小さな丸を2〜3個打って「外れ値」 → 箱の外側に点線でフェンス IQR と IQR の位置を示し、フェンスとひげ先が別物であることを矢印で強調。 実際の見た目は下の「対応するシミュレーション」で出力した箱ひげ図の画像(
hakohige_iqr_hazurechi_boxplot.png)を見てください。赤い点が外れ値です。
ひげの2つの流派 ── 素朴版とTukey版(試験で問われるのはこちら)
ここが最初の引っかけポイントです。「ひげをどこまで伸ばすか」には2つの流派があります。
| 流派 | ひげの先端 | 外れ値の扱い | 使われ方 |
|---|---|---|---|
| 素朴版(skeletal) | 最小値・最大値まで伸ばす | 外れ値という概念がない(全データがひげの中) | 簡易・小学/中学の導入 |
| Tukey版(schematic・modified) | フェンス内の最も端のデータ点まで | フェンスを越えた点を外れ値として個別に打つ | 現代の標準・試験で問われる |
現代の統計やソフト(matplotlib・R・Excelなど)の箱ひげ図は、ほぼすべてTukey版です。統計検定で「外れ値」を扱う問題もTukey版が前提です。
頻出の誤解:ひげの先=フェンスではない
最も間違えやすいのがここです。**ひげの先端は「フェンスそのもの」ではなく、「フェンスの内側にある実データの最も端の点」**です。
たとえば上側フェンスが だったとして、フェンス内の最大のデータが なら、ひげの先は で止まります( まで伸びるのではない)。フェンスはあくまで「ここから外は外れ値」という判定用の見えない線であって、ひげの先がそこに来るわけではありません。「ひげの長さ = 必ず IQR」と覚えてしまうと間違えます。ひげの長さはデータ次第で、最大でも IQR ぶんですが、たいていそれより短くなります。
外れ値の判定 ── 1.5×IQRルール
外れ値の判定手順は次の3ステップだけです。
| ステップ | やること | 式 |
|---|---|---|
| 1 | IQR を求める | |
| 2 | フェンスを計算する | 下:/上: |
| 3 | フェンスの外側を外れ値とする | または |
flowchart LR
A["四分位数 Q1・Q3 を求める"] --> B["IQR = Q3 − Q1"]
B --> C["下側フェンス = Q1 − 1.5×IQR<br/>上側フェンス = Q3 + 1.5×IQR"]
C --> D{"データはフェンスの<br/>外側か?"}
D -->|外側| E["外れ値"]
D -->|内側| F["通常のデータ<br/>(ひげの中)"]
↑ 外れ値判定の流れ。四分位数 → IQR → フェンス → 範囲外を外れ値、という一直線の手順です。
極端な外れ値(3×IQR)
係数を 3.0 にした / を**外側フェンス(outer fence)**と呼び、これを越える値を「極端な外れ値(far out)」とする流儀もあります。Tukey本人の用語では、IQR の内側フェンスと IQR の外側フェンスの間にある点を「外れ値(outside)」、外側フェンスを越える点を「極端な外れ値(far out)」と区別します。3級では基本の IQR を押さえれば十分ですが、「IQR はさらに極端な値だけを拾う厳しい基準」という対比だけ知っておくとよいです。
箱ひげ図からの分布の読み取り
箱ひげ図は、形から分布の特徴を読み取れます。試験でも「この箱ひげ図はどんな分布か」を問う問題が出ます。
- 散らばりの大小:箱が長いほど中央50%が広い(ばらつき大)。ひげが長いほど端のほうまでデータが伸びている。
- 歪み(左右の偏り):箱の中で中央値がどちらに寄っているかを見ます。
- 中央値が箱の下寄り(左寄り) → 上側(右側)に裾が長い → 右に歪んだ分布(右に裾が長い)
- 中央値が箱の上寄り(右寄り) → 下側(左側)に裾が長い → 左に歪んだ分布
- 中央値が箱の真ん中 → 左右対称に近い
- 複数群の一括比較(最大の利点):箱ひげ図を横に並べると、複数のグループの「中心・ばらつき・外れ値」を一目で比較できます。たとえば「クラスA・B・Cのテスト分布」を3つの箱ひげ図で並べれば、どのクラスが高めか・ばらつきが大きいか・外れ値がいるかが瞬時にわかります。ヒストグラムを3つ並べるより圧倒的に比較しやすい ── これが箱ひげ図が多用される最大の理由です。
中央値の偏りで歪みを読む直観
なぜ「中央値が箱の下寄り → 右に裾」なのか。中央値は箱をデータ数で半分ずつに区切る線です。中央値が 寄り(箱の左寄り)にあるということは、 から までの区間が から までより横に広いということ。つまり上側(大きい値の側)のデータが横に間延びして広がっている = 右側に裾が長い、というわけです。「データが詰まっている側に中央値が寄り、間延びしている側に裾ができる」と覚えてください。
箱ひげ図の限界 ── 二峰性は見えない
箱ひげ図の弱点は、5数要約に圧縮するぶん、分布の細かい形が消えることです。とくに重要なのが二峰性(山が2つある分布)を隠してしまうこと。
前トピック 散らばり(ばらつき)の指標 ── 範囲・四分位範囲・分散・標準偏差・変動係数(なぜ偏差を2乗するか/なぜn−1で割るか) の例を思い出してください。「平均60点で、30点と90点に真っ二つ」のクラス。このデータの箱ひげ図は、「ほどよく中央に中央値があり、左右にひげが伸びた、ごく普通の単峰の分布」と見分けがつきません。山が2つあるか1つあるかは、5数要約だけでは原理的に判別できないのです。
**山が2つあるか・分布が滑らかか凸凹かを見たいときは、ヒストグラム(→ 度数分布表とヒストグラム ── 階級・相対度数・累積度数とスタージェスの公式)**を使います。箱ひげ図は「複数群をざっくり一括比較する」のに強く、ヒストグラムは「1つの分布の形を細かく見る」のに強い。用途で使い分けるのが正解で、どちらが上ということはありません。
数式の直観的意味
ここからが本トピックの理論的な肝です。2つの「なぜ」を潰します。
1. なぜ係数が「1.5」なのか(約±2.7σ・全体の約0.7%)
結論:正規分布のデータだと、IQR のフェンスがちょうど約±2.7σの位置に来て、外れ値になるのは全体の約0.7%(片側約0.35%)だけ。「拾いすぎず・見逃しすぎない」絶妙なバランスだから、Tukeyはこの値を選びました。
順を追って計算します。正規分布を仮定すると、四分位数は標準偏差 で次のように書けます(標準正規分布で下から25%・75%に当たる点が だから)。
これは「正規分布では は平均より 下、 は 上にある」という意味です。すると IQR は
「正規分布では IQR は標準偏差の約1.35倍」ということ。これを使って上側フェンスを計算します。
(平均 を基準にした 単位の表記です。)つまり上側フェンスは平均から約 、下側フェンスは約 の位置に来ます。正規分布で**±2.698σより外側にある確率は、両側合わせて約0.7%(片側約0.35%)**。要するに「正規分布のデータなら、IQRルールはごく一部(1%未満)だけを外れ値とみなす」ということです。
なぜ がちょうどよいか、他の係数と比べると一目です。
| 係数 | フェンスの位置(σ単位) | 性質 |
|---|---|---|
| 約 | 厳しすぎ(外れ値を拾いすぎる) | |
| 約 | ちょうどよい(正規データで約0.7%) | |
| 約 | 緩すぎ(極端な値しか拾わない・far out用) |
係数 だと (正規分布で約4.6%が外れ値)になり、正常なデータまで外れ値扱いしてしまう。係数 だと (ほぼ0%)で、よほど極端な値しか拾わない。 は両者の中間で、正規分布の常識(3σルール=約±3σにほぼ全データが入る)にも近い。これが「 は理論的にきっちり導かれた値というより、正規分布で都合のよい実用的な閾値としてTukeyが選んだ」と言われる理由です。
なお「 に厳密な必然性があるわけではない」点は誤解しないでください。 は正規分布を念頭に置いた経験的な選択であって、データが正規分布から大きくずれる(強く歪む・裾が重い)と「約0.7%」は成り立ちません。歪んだデータでは IQR が片側だけ外れ値を量産することもあります。
2. なぜ四分位ベースの判定は外れ値に強いのか
結論: はすべて順位(位置)ベースなので、判定の基準そのものが外れ値に汚染されない。 これは前トピック 散らばり(ばらつき)の指標 ── 範囲・四分位範囲・分散・標準偏差・変動係数(なぜ偏差を2乗するか/なぜn−1で割るか) で見た「中央値・四分位範囲が外れ値に強い(頑健)」性質の、外れ値判定への応用です。
対比すると分かりやすいです。外れ値判定にはもう一つ「平均 を越えたら外れ値」という方法( や )があります。しかしこの方法には自己矛盾があります。
- 判定に使う (平均)と (標準偏差)は、外れ値を含んだまま計算される。
- 外れ値が1つあると、 は2乗で効くので大きく膨らむ(→ 散らばり(ばらつき)の指標 ── 範囲・四分位範囲・分散・標準偏差・変動係数(なぜ偏差を2乗するか/なぜn−1で割るか) の「分散・標準偏差は外れ値に弱い」)。
- が膨らむと判定基準 も外側に広がってしまい、本来外れ値のはずの値が「基準の内側」に入って検出されなくなる ── 外れ値が自分自身を隠してしまう(マスキング効果)。
一方、IQRルールは (順位ベース)だけを使います。順位ベースの量は、上下25%ずつを捨てているので、極端な値が混じっても基準がほとんど動かない。だから「外れ値があっても基準が歪まず、外れ値を正しく外れ値と判定できる」。これが四分位ベースの判定が頑健(ロバスト)である理由です。「基準を測る道具が、測りたい外れ値に汚されていない」と理解してください。
⚠️ 引っかけポイント・頻出論点・級ごとの差
- ひげの先=フェンスではない(最頻出):ひげの先はフェンス内の実データの最端。「ひげ=必ずIQRの長さ」は誤り。たいていそれより短い。
- 外れ値 ≠ 異常値・誤データ:機械的に拾った「離れた値」であって間違いとは限らない。測定ミスなら除外検討、本物の珍しい値なら貴重 → 原因を調べるのが正解、自動削除は誤り。
- 箱ひげ図は二峰性を隠す:5数要約に圧縮するため。山が2つか1つかは判別不能 → ヒストグラム(→ 度数分布表とヒストグラム ── 階級・相対度数・累積度数とスタージェスの公式)。
- 中央値の箱内の偏りで歪み判定:下寄り→右に裾/上寄り→左に裾。「どっちに寄ると右に裾か」を逆に覚えがち。データが詰まる側に中央値が寄り、間延びする側に裾。
- 係数1.5の根拠:「正規分布で±2.7σ・約0.7%」まで。「自明・とにかく1.5」で済ませない。IQRは極端な外れ値(far out)。
- 素朴版とTukey版の区別:外れ値が問われる文脈はTukey版前提。素朴版(最小〜最大)には外れ値概念がない。
- 級差:4級=箱ひげ図の読み取り → 3級=5数要約・IQR外れ値判定 → 2級=歪んだ分布での読み取り・他手法(±3σ)との比較。
- 出題範囲は改訂されうるため受験前に最新の範囲表で要確認。
よくある疑問
Q1. ひげの先端はフェンス(IQR)と同じ位置じゃないの?
**違います。ひげの先端は「フェンスの内側にある実データの最も端の点」**です。
フェンスは「ここから外は外れ値」という判定用の見えない線で、ひげの先がそこに来るとは限りません。上側フェンスが でも、フェンス内の最大データが なら、ひげは で止まります。ひげの長さは最大でも IQR ぶんですが、たいていそれより短くなります(データがフェンスぎりぎりに無い限り)。「ひげ=必ず IQRの長さ」という思い込みが失点の原因になります。
Q2. 外れ値は「異常値(捨てるべき間違ったデータ)」ということ?
いいえ。「外れ値(outlier)」は統計的な基準で『他から離れている』というだけで、『間違っている』『捨てるべき』という意味ではありません。
IQRルールは「フェンスの外」という機械的な基準で点を拾うだけです。その点が測定ミスや入力ミスなら除外を検討すべきですが、本物の珍しい値(例:本当に身長が高い人、本当に高額な取引)なら貴重な情報で、勝手に捨ててはいけません。外れ値を見つけたら「なぜこの値が出たのか」を調べるのが正しい対応で、自動的に削除するのは誤りです。「外れ値 ≠ 異常値・誤データ」と覚えてください。
Q3. 係数の には数学的な必然性があるの?
厳密な必然性はありません。正規分布を念頭に置いたTukeyの経験的な選択です。
本文で見たとおり、正規分布だと IQR が約±2.7σ・外れ値約0.7%という「ちょうどよい」値になります。 だと拾いすぎ、 だと拾わなさすぎ。その中間で実用的だから が標準になった、という経緯です。データが強く歪んでいたり裾が重い分布だと「約0.7%」は成り立たないので、 を絶対の真理だと思わないことが大事です(歪んだデータ向けに係数を調整する手法もあります → 準1級以降のロバスト統計)。
Q4. 箱ひげ図とヒストグラム、どっちを使えばいいの?
用途が違うので使い分けます。どちらが上ということはありません。
- 箱ひげ図:複数のグループを横に並べて一括比較するのに最強。中心・ばらつき・外れ値が一目で比べられる。ただし二峰性など分布の細かい形は見えない(5数要約に圧縮するから)。
- ヒストグラム(→ 度数分布表とヒストグラム ── 階級・相対度数・累積度数とスタージェスの公式):1つの分布の形を細かく見るのに強い。山が1つか2つか、滑らかか凸凹かがわかる。ただし複数群の比較には不向き(並べると見づらい)。
「複数グループをざっくり比べたい → 箱ひげ図」「1つの分布の形を詳しく見たい → ヒストグラム」と覚えてください。実務では両方を併用することも多いです。
Q5. 「平均±3σで外れ値」と「IQR」はどう違う? どっちがいい?
判定基準の頑健性が違います。外れ値を含むデータでは IQR(四分位ベース)のほうが信頼できます。
「平均±」方式は、判定に使う が外れ値で膨らんでしまうため、外れ値が自分自身を隠す(マスキング)危険があります(本文「数式の直観的意味」参照)。一方 IQR は順位ベースの だけを使うので、基準が外れ値に汚染されない。だから外れ値の検出には四分位ベースのほうが向いています。ただし「データが正規分布に近い」とわかっていて外れ値も少ないなら、±3σ方式でも実用上は大きな問題は起きません。外れ値の有無や分布の素性が不明なときは IQR が安全、と覚えておきましょう。
まとめ
- 箱ひげ図は**5数要約(最小・・中央値・・最大)**を1枚の図にしたもの。箱=〜(長さ=IQR)、箱の中の線=中央値、ひげ、外れ値の点で構成される(四分位の定義は前トピック 散らばり(ばらつき)の指標 ── 範囲・四分位範囲・分散・標準偏差・変動係数(なぜ偏差を2乗するか/なぜn−1で割るか))。
- ひげの2流派:素朴版(最小〜最大まで)とTukey版(ひげはフェンス内の最端データまで、フェンス外は外れ値として個別の点)。試験で問われるのはTukey版。
- 頻出の誤解:ひげの先=フェンスではない。ひげの先はフェンス内の実データの最端。ひげの長さは最大でも IQR ぶんだが、たいていそれより短い。
- 外れ値判定(1.5×IQRルール): 未満/ 超を外れ値とする。IQR は「極端な外れ値(far out)」の基準。
- なぜ係数が1.5か:正規分布だと , , IQR なので、フェンス =約±2.7σ。外れ値になるのは**全体の約0.7%(片側約0.35%)**だけ。「拾いすぎず・見逃しすぎない」実用的閾値(=±2σで拾いすぎ、=±4.7σで拾わなすぎ)。
- なぜ四分位判定が頑健か: は順位ベースで基準が外れ値に汚染されない。平均±方式は が外れ値で膨らみ、外れ値が自分を隠す(マスキング)。
- 分布の読み取り:箱・ひげの長さ=散らばり、箱内の中央値の偏り=歪み(中央値が下寄り→右に裾/上寄り→左に裾)。複数群を横に並べて一括比較できるのが最大の利点。
- 限界:5数要約に圧縮するので二峰性など細かい形は見えない。形を詳しく見るならヒストグラム(→ 度数分布表とヒストグラム ── 階級・相対度数・累積度数とスタージェスの公式)。用途で使い分ける。
- 外れ値 ≠ 異常値:機械的に拾った「離れた値」であって、誤データとは限らない。原因を調べるのが正解、自動削除は誤り。
- 級差:4級=箱ひげ図の読み取り → 3級=5数要約・IQRによる外れ値判定 → 2級=歪んだ分布での読み取り・他手法との比較。出題範囲は改訂されうるため受験前に最新の範囲表で要確認。
四分位数を図に落とし込み、外れ値を判定する道具がそろいました。次は、データを共通のものさしに乗せ替える標準化(得点)・偏差値・チェビシェフの不等式へ進みます(→ 標準化(z得点)・偏差値・チェビシェフの不等式 ── 標準化≠正規化/偏差値に上限なし/どんな分布でも成り立つ歯止め)。
対応するシミュレーション
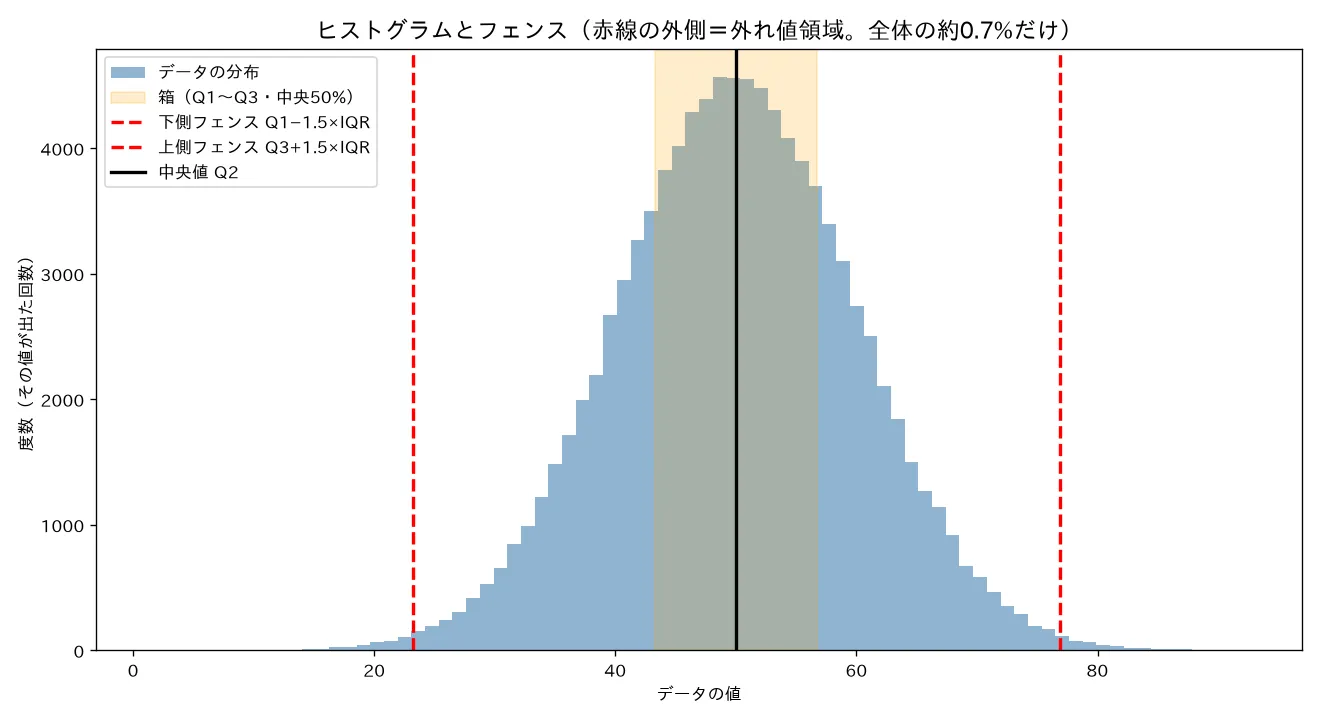
simulations/hakohige_iqr_hazurechi.py- 何を示すか:正規分布(σ=10)から10万個のデータを取り、,IQR からフェンス / を計算。フェンス外のデータ割合を明示ループで数え、約0.7%になるか・フェンスが±2.7σに来るかを確認。「IQRルールは正規分布のデータのうち約0.7%だけを外れ値とみなす」ことを数値実験で確かめる。
- 実行結果:IQR = σの約1.34倍(理論と一致)/上側フェンス = 平均から約**+2.69σ**(理論と一致)/外れ値割合 = 0.75%(理論 約0.7% と一致)/係数3.0では ±4.7σ・外れ値0.001%(far out)。
- 可視化:①箱ひげ図png(ひげがフェンス内最端まで、外れ値は赤い点)②ヒストグラムにフェンスの赤縦線(外側のごく薄い裾=約0.7%が外れ値領域)。
- 結論:理論「IQR ≒ ±2.7σ ≒ 0.7%」が数値で再現。四分位(順位)ベースなので外れ値が基準を歪めない。
関連ノート
- 散らばり(ばらつき)の指標 ── 範囲・四分位範囲・分散・標準偏差・変動係数(なぜ偏差を2乗するか/なぜn−1で割るか)(散らばり:範囲・四分位・分散・標準偏差 ── 本トピックの ・IQR の定義元。四分位が外れ値に強い=頑健の論理もここから。分散・標準偏差が外れ値に弱い理由(平均±kσ判定の弱点)もこのノートが土台。後方リンク・前トピック)
- 度数分布表とヒストグラム ── 階級・相対度数・累積度数とスタージェスの公式(度数分布表・ヒストグラム ── 箱ひげ図が隠す「分布の細かい形(二峰性など)」はヒストグラムで見える。複数群比較は箱ひげ図、形の精査はヒストグラム、と用途で使い分ける。後方リンク)
- 標準化(z得点)・偏差値・チェビシェフの不等式 ── 標準化≠正規化/偏差値に上限なし/どんな分布でも成り立つ歯止め(標準化・偏差値・チェビシェフの不等式 ── データを共通のものさし(得点)に乗せ替える次トピック。外れ値判定の「平均±kσ」もこの の発想とつながる。前方リンク・次トピック)