📊 対象級:2級 | 重要度:A(頻出)
標準化(z得点)・偏差値・チェビシェフの不等式 ── 標準化≠正規化/偏差値に上限なし/どんな分布でも成り立つ歯止め
要点(BLUF)
- 標準化 =「平均から 何個ぶん離れているか」。標準化後は必ず平均0・標準偏差1。線形変換なので分布の形は変えない(最頻出誤解:標準化≠正規化。歪んだ分布は標準化しても歪んだまま)。単位の違うデータを共通のものさしで比較(→ 散らばり(ばらつき)の指標 ── 範囲・四分位範囲・分散・標準偏差・変動係数(なぜ偏差を2乗するか/なぜn−1で割るか))。3級。
- 偏差値 。を平均50・標準偏差10に目盛り替え(線形変換)。60=、70=、80=。上限・下限なし(100超・負あり)。「偏差値70=上位約2.3%」は正規分布前提のみ。
- チェビシェフの不等式 ()=平均± の中に少なくとも (k=2→75%、k=3→88.9%)。最大の価値=分布不問(distribution-free)。経験則(正規前提・95%)と違い緩いが必ず成り立つ。2級。
対象級について:標準化(得点)と偏差値は統計検定3級が中心です。チェビシェフの不等式は2級の頻出論点で、準1級以降(大数の法則の証明など)にもつながります。前トピック 散らばり(ばらつき)の指標 ── 範囲・四分位範囲・分散・標準偏差・変動係数(なぜ偏差を2乗するか/なぜn−1で割るか) でそろえた標準偏差 ・変動係数を土台に、ここでは「データを共通のものさしに乗せ替える」発想を扱います。さらに、正規分布を前提とする経験則(68-95-99.7)と、分布の形を一切仮定しないチェビシェフの不等式の違いを、不等式の導出まで踏み込んで整理します。
結論:標準化は「ものさしの貼り替え」、偏差値はその目盛り替え、チェビシェフは「どんな分布でも効く歯止め」
最初に結論です。本記事の3つの主役を一言ずつで。
| 概念 | 式 | 一言でいうと |
|---|---|---|
| 標準化(得点) | 平均を0・標準偏差を1にそろえる「ものさしの貼り替え」。は「平均から 何個ぶん離れているか」 | |
| 偏差値 | を「平均50・標準偏差10」に目盛り替えしただけ。偏差値60=、70= | |
| チェビシェフの不等式 | $P( | X-\mu |
そして本記事で絶対に外してほしくない核心を、先に3つ挙げます。
- 標準化 ≠ 正規化(標準化しても正規分布にはならない)。標準化は位置(平均)と尺度(標準偏差)を動かすだけの線形変換で、分布の形は変えません。歪んだ分布は標準化しても歪んだまま。最頻出の誤解です。
- 偏差値に上限・下限はありません。偏差値100超も、負の偏差値もあり得ます。「偏差値70=上位約2.3%」は正規分布を仮定したときだけ成り立つ話です(条件付き)。
- 経験則(68-95-99.7)は正規分布前提、チェビシェフはどんな分布でもOK。そのかわりチェビシェフの保証は緩い(±2で「75%以上」しか言えない。正規分布なら実際は約95%)。「形がわかれば正確に、わからなければ緩くても確実に」という使い分けです。
標準化(z得点)── データを共通のものさしに乗せ替える
定義と意味
**標準化(standardization)**とは、データから平均 を引き、標準偏差 で割る操作です。変換後の値を 得点(z-score、標準得点) と呼びます。
要するに「そのデータが、平均から標準偏差何個ぶん離れているか」を表す数です。 なら「平均より 上」、 なら「平均より 下」。
標準化すると、変換後のデータは必ず平均0・標準偏差1になります。これはあとで証明しますが、直観的には「平均を引いて中心を0に移し、 で割って単位を にそろえた」だけなので当然です。
なぜ標準化するのか ── 単位・スケールの違うものを比較するため
標準化の最大の用途は、単位やスケールの違うデータを同じ土俵で比較することです。
たとえば「国語のテスト(平均60点・=10点)で70点」と「数学のテスト(平均50点・=20点)で74点」、どちらが相対的に優秀でしょうか。素点(70 vs 74)では数学のほうが高く見えますが、標準化すると:
- 国語:(平均より 上)
- 数学:(平均より 上)
…と、どちらも「平均から 何個ぶん上か」という共通のものさしに乗ります。この例では数学のほうがやや上位、と判断できます。
これは前トピック 散らばり(ばらつき)の指標 ── 範囲・四分位範囲・分散・標準偏差・変動係数(なぜ偏差を2乗するか/なぜn−1で割るか) の変動係数(CV)と同じ「単位をなくして比較する」発想です。ただし違いがあります。変動係数はデータセット全体のばらつきを表す1つの指標()であるのに対し、得点は個々のデータ点を1つずつ変換するものです。CVは「分布の散らばり具合の比較」、は「データ点の相対的な位置の比較」に使います。
標準化は線形変換 ── だから分布の形は変わらない(標準化≠正規化)
ここが最頻出の誤解ポイントです。結論を先に。
標準化は線形変換であり、分布の形を一切変えません。標準化しても、元のデータが正規分布でなければ正規分布にはなりません。
「標準化(standardization)」と「正規化(normalization)」は名前が似ているうえ、「標準化すると標準正規分布に従う」という誤解が蔓延していますが、これは間違いです。
線形変換とは何か
を変形すると、
これは (ただし , )という**1次関数(線形変換)**です。線形変換が分布に対してやることは、たった2つだけ。
- 平行移動(:中心を0に移す)
- 拡大・縮小(:横軸の目盛りの単位を にそろえる)
つまり標準化がやるのは、グラフの横軸の原点と単位(ものさし)を貼り替えることだけです。山が右に歪んでいれば、貼り替えた後も右に歪んだまま。山が2つ(二峰性)あれば、貼り替えた後も山は2つのまま。相対的な形・順序は完全に保たれます。
flowchart LR
A["元データ(歪んだ分布)"] -->|"−μ:中心を0へ平行移動"| B["平均0の分布<br/>(形は同じ)"]
B -->|"÷σ:単位をσにそろえる"| C["平均0・標準偏差1<br/>(形は依然として歪んだまま)"]
↑ 標準化は「平行移動」と「単位の縮尺替え」の2段階。位置と尺度は動くが、分布の形(歪み・山の数)は変わらない。だから「標準化=正規分布化」ではない。
「標準化=標準正規分布化」が誤りである理由
「正規分布を標準化すると標準正規分布になる」は正しいです。しかしこれは「もともと正規分布だったものを」標準化した場合の話。逆は言えません。
- 元が正規分布 → 標準化 → 標準正規分布()になる ✓
- 元が正規分布でない(例:指数分布) → 標準化 → 平均0・標準偏差1にはなるが、標準正規分布にはならない(指数分布の形のまま、位置と尺度だけ動く) ✗
標準化が保証するのは「平均0・標準偏差1」という2つの数値(モーメント)だけであって、分布の形(全体の確率の分布のしかた)までは保証しません。「平均と標準偏差が同じでも、形が違う分布はいくらでもある」── これを押さえておけば誤解しません。
偏差値 ── z得点の目盛りを「平均50・標準偏差10」に替えただけ
定義
**偏差値(deviation value、得点)**は、得点を「平均50・標準偏差10」のスケールに変換したものです。
要するに「得点を10倍して50を足しただけ」。これも線形変換なので、当然分布の形は変わりません(偏差値の分布が正規分布になるわけではない)。
と偏差値の対応は、 から一目です。
| 得点 | 偏差値 | 意味 |
|---|---|---|
| 30 | 平均より 下 | |
| 40 | 平均より 下 | |
| 50 | ちょうど平均 | |
| 60 | 平均より 上 | |
| 70 | 平均より 上 | |
| 80 | 平均より 上 |
偏差値60=、偏差値70=、偏差値80=。この対応はそのまま覚えておくと便利です。
偏差値に上限・下限はない
よくある誤解:「偏差値は0〜100の範囲」。これは間違いです。 偏差値に上限・下限はありません。
で、 はいくらでも大きく(小さく)なれます。平均から 離れた値があれば なので偏差値は 。逆に なら偏差値 。偏差値100超も負の偏差値も理論上あり得ます(実際、極端に簡単・難しいテストや、人数が少ない試験では起こります)。「0〜100に収まる」と思い込むと失点します。
「偏差値70=上位約2.3%」は正規分布を仮定したときだけ
もう一つの重要な注意。「偏差値70は上位約2.3%」というよく聞く話は、得点の分布が正規分布だと仮定したときにだけ成り立ちます。
偏差値70は 、つまり平均より 上です。正規分布なら より上側の面積は約2.3%(後述の経験則「±2に約95%」から、外側の5%の半分=約2.5%、より正確には2.28%)。だから「偏差値70=上位約2.3%」。
しかし得点分布が正規分布でなければ、この対応は崩れます。たとえば得点が二極化している(高得点層と低得点層に割れている)テストなら、偏差値70の位置に何%いるかは分布次第で、2.3%とは限りません。「偏差値→上位何%」の換算は正規分布の仮定が前提だと必ず意識してください。
経験則(68-95-99.7ルール)── ただし正規分布前提
正規分布のデータでは、平均からの距離(単位)と、その範囲に入るデータの割合に、有名な対応があります。これを経験則(empirical rule) または 68-95-99.7ルールと呼びます。
| 範囲 | 入る割合(正規分布の場合) |
|---|---|
| 平均 ±1 | 約 68% |
| 平均 ±2 | 約 95% |
| 平均 ±3 | 約 99.7% |
要するに「正規分布なら、±1 にざっくり7割、±2 にほぼ95%、±3 にほぼ全部(99.7%)が入る」ということ。検定の信頼区間や外れ値判定(±3ルール)の感覚は、これが土台になっています。
ただし大前提として、これは分布が正規分布のときの話です。 分布が歪んでいたり山が2つあったりすると、この割合は成り立ちません。「±2なら必ず95%」と無条件に思い込まないこと。「正規分布なら」という条件が必ず付きます。ここが次のチェビシェフの不等式との決定的な違いです。
チェビシェフの不等式 ── どんな分布でも成り立つ歯止め
定義
**チェビシェフの不等式(Chebyshev’s inequality)**は、 に対して次が成り立つ、という主張です。
要するに「どんな分布でも、平均から 以上離れた値が出る確率は、 より大きくならない」。裏を返せば(余事象を取れば):
「平均± の中には、少なくとも のデータが入る」。具体的な数値は次のとおり。
| チェビシェフの下限 | 「平均±の中に少なくとも」 | (参考)正規分布での実際 | |
|---|---|---|---|
| (無意味) | — | 約68% | |
| 75%以上 | 約95% | ||
| 約88.9%以上 | 約99.7% | ||
| 約93.75%以上 | 約99.99% |
最大の価値:分布の形を仮定しない(distribution-free)
チェビシェフの不等式が経験則と決定的に違うのは、分布の形を一切仮定しないことです。正規分布だろうが、歪んだ分布だろうが、山が2つあろうが、平均 と標準偏差 さえ存在すれば、必ず成り立ちます。これを distribution-free(分布によらない) といいます。
そのかわり、保証は緩いです。 で「75%以上」しか言えません。正規分布なら実際は約95%入るのに、チェビシェフは「最低でも75%は保証する」としか言えない。この「緩いが確実」という性質が肝で、次の節で「なぜ緩いのか」を理論的に説明します。
経験則 vs チェビシェフ ── 数量比較
同じ「±の中に入る割合」を、正規前提の経験則とチェビシェフの保証下限で比べると、差が一目でわかります。
xychart-beta
title "±kσ内に入る割合:チェビシェフ下限(保証)vs 正規分布での実際"
x-axis "k(標準偏差の何倍か)" [k=2, k=3]
y-axis "範囲内に入る割合(%)" 0 --> 100
bar [75, 88.9]
bar [95, 99.7]
↑ 左の棒=チェビシェフの保証下限(75%, 88.9%)、右の棒=正規分布での実際(95%, 99.7%)。チェビシェフは「最低でもこれだけは入る」という下限なので、正規分布の実際の割合はそれをずっと上回る。チェビシェフが緩い(保守的)ことが見て取れる。
| 観点 | 経験則(68-95-99.7) | チェビシェフの不等式 |
|---|---|---|
| 前提 | 正規分布であること | どんな分布でもOK(分布不問) |
| ±2 の中身 | 約95%(正確な値) | 75%以上(緩い下限) |
| 性質 | 正確だが前提が必要 | 緩いが必ず成り立つ(保証) |
| 使いどころ | 分布が正規とわかっている | 分布の形がわからない・歪んでいる |
数式の直観的意味
ここからが本トピックの理論的な肝です。3つの「なぜ」を潰します。
1. チェビシェフの不等式の導出(直接版)
結論:分散の定義 から、3行の不等式評価で導けます。 マルコフの不等式を経由する方法もありますが、まず直接版を示します。
出発点は分散の定義です。
この積分(期待値)を、「平均から 以上離れた領域 」だけに絞った積分で下から評価します。
【第1の不等号】全体の期待値 ≥ 一部の領域だけの期待値
ここで は「条件を満たすとき1、満たさないとき0」を返す指示関数です。なぜこの不等号が成り立つか: は常に0以上なので、積分範囲を全体から一部(領域 だけ)に狭めれば、足し込む量が減る(か同じ)。非負の量を一部だけ足したものは、全部足したものを超えない ── これが第1の不等号の理由です。
【第2の不等号】領域 の中では
領域 の中では、定義より 、つまり が成り立っています。だから領域 上の積分で、被積分関数 をそれより小さい定数 に置き換えても、不等式は保たれます。
最後の等号は「指示関数の期待値=その事象の確率」()という基本事実です。
【まとめ】
2つの不等号をつなぐと、
両辺を で割ると( なので割れる)、
これでチェビシェフの不等式が出ました。証明の本質は「分散(全体の散らばりの期待値)は、遠い領域の散らばりだけを取り出した量より大きい」という、たった1つの当たり前を2回使っているだけです。
マルコフの不等式経由の別証:マルコフの不等式「非負の確率変数 と に対し 」に、、 を代入すると、。左辺の事象 は と同じなので、同じ式が得られます。実は上の直接証明は、マルコフの不等式の証明をこの場合に展開したものです。
2. なぜチェビシェフは緩いのか
結論:分布の形を一切仮定しない「最悪ケース」の保証だからです。
導出を振り返ると、チェビシェフの不等式は「分散 ≥ 遠い領域の散らばり」という一番ゆるい評価しか使っていません。途中で「分布が正規である」「左右対称である」といった情報を一切使っていないのがポイントです。
だから、チェビシェフの という上限は、考えうるすべての分布の中で最悪のもの(一番外れやすい分布)でも破れないように設定された下限・上限です。実際、チェビシェフの等号が成り立つ(ぴったり になる)のは、確率が「平均1点と、 の2点」だけに集中した特殊な分布のときで、これが「最悪ケース」に当たります。
一方、正規分布のように形がわかっていれば、その情報を使ってもっと精密に評価できます。正規分布で なら実際は約95%が入る ── チェビシェフの「75%以上」という保証よりずっと多い。形を知っていれば95%と言えるのに、形を知らないと「最低75%」としか言えない。これが「チェビシェフは緩い」の正体です。
では緩いチェビシェフに何の価値があるのか。 価値は「分布の形がまったくわからなくても、確実に成り立つ歯止めを与えてくれる」ことです。現実には「データの分布が正規かどうかわからない」「むしろ歪んでいそう」という場面が山ほどあります。そういうとき、経験則(正規前提)は使えません。チェビシェフなら「形は知らないが、少なくとも±2に75%は入る」と無条件に断言できる。緩くても、どんな分布でも破れない保証であることに価値があります。これは準1級・1級で学ぶ大数の法則の証明にも、この「分布を仮定しない歯止め」として直接使われます。
3. 標準化が線形変換である意味 ── ものさしの貼り替え
結論:標準化は軸の原点を に移し、単位を にする「ものさしの貼り替え」。順序も相対的な形も保たれるから、異なるテスト・異なる単位を共通のものさしで比較できます。
まず、標準化後に平均0・標準偏差1になることを確認します。 について、期待値と分散の線形性を使うと:
(分散の性質 を使用。定数 の平行移動は分散を変えない、 倍は分散を 倍する。)だから標準化後は必ず平均0・標準偏差1。これは形によらず成り立ちます(だからこそ「平均0・標準偏差1になる」ことと「正規分布になる」ことは別問題なのです)。
直観的には、 は数直線に対して2つの操作をしています。
- 原点を に移す():「平均からの差」を測る基準点を平均に置く
- 単位を にする():1目盛りを「標準偏差1個ぶん」にする
つまり「そのデータ独自のものさし(cm・点・kg…)を捨てて、『平均からσ何個ぶん』という共通のものさしに貼り替える」操作です。線形変換なのでデータ点の大小関係(順序)は完全に保たれ、分布の相対的な形も保たれる。だからこそ、国語と数学のように単位やスケールの違うデータでも、 という共通の物差しに乗せれば「どちらが相対的に上か」を比較できるのです。
散らばり(ばらつき)の指標 ── 範囲・四分位範囲・分散・標準偏差・変動係数(なぜ偏差を2乗するか/なぜn−1で割るか) の変動係数(CV)と同じ「単位をなくして比較する」発想ですが、CVは分布全体のばらつきを表す1指標、は個々のデータ点を変換する点が違います。CVは「ばらつきの大小を分布間で比べる」、は「データ点の相対位置を比べる」。役割が異なります。
⚠️ 引っかけポイント・頻出論点・級ごとの差
- 標準化≠正規化(最頻出):標準化は線形変換で形を変えない。「平均0・標準偏差1」は保証するが「標準正規分布」は保証しない。正規→標準化→標準正規は○だが逆は×。検定の正規性前提の判断を誤る原因。
- 偏差値に上限・下限なし: 無制限 → 偏差値100超・負あり。「0〜100」は誤解。
- 「偏差値70=上位約2.3%」は正規前提のみ:偏差値70=。非正規(二極化等)では崩れる。「偏差値→上位何%」換算は正規仮定が必要。
- 経験則 vs チェビシェフ:経験則(68-95-99.7)は正規前提・正確/チェビシェフは分布不問・緩い(k=2で75%以上)。「±2σなら必ず95%」は正規のときだけ。チェビシェフは「最低何%」の保証下限で、実際の割合はそれ以上になる。
- でないと無意味: で下限。 は情報なし。チェビシェフが効くのは 。
- チェビシェフ導出を「自明」で済ませない:第1不等号(非負量の一部≤全部)・第2不等号(領域内で )の理由を言えること。 で割る。
- 標準化とCVの違い:CV=分布全体のばらつき1指標/=各データ点を変換。役割が違う(→ 散らばり(ばらつき)の指標 ── 範囲・四分位範囲・分散・標準偏差・変動係数(なぜ偏差を2乗するか/なぜn−1で割るか))。
- 級差:3級=標準化・偏差値(、、上限なし、標準化≠正規化) → 2級=チェビシェフ(導出・k=2,3の下限・distribution-free) → 準1級〜=大数の法則の証明への応用。
- 出題範囲は改訂されうるため受験前に最新の範囲表で要確認。
よくある疑問
Q1. 標準化すれば、どんなデータでも正規分布になるの?
いいえ。標準化しても正規分布にはなりません。これが最頻出の誤解です。
標準化()は線形変換で、データの平均を0・標準偏差を1にそろえるだけです。位置(中心)と尺度(単位)を動かすだけなので、分布の形(歪み・山の数)は一切変わりません。元が右に歪んだ分布なら、標準化後も右に歪んだまま。「標準化=標準正規分布化」と思い込むと、その後の検定の前提(正規性)の判断を誤ります。「正規分布を標準化すると標準正規分布になる」のは正しいですが、逆(標準化すれば正規分布になる)は成り立ちません。
Q2. 偏差値は0〜100の範囲じゃないの?
いいえ。偏差値に上限・下限はありません。
で、 はいくらでも大きく(小さく)なれるので、偏差値100超も、負の偏差値もあり得ます。平均から 離れた値があれば偏差値110、 なら偏差値。実際、人数が少ない試験や極端な点が出たときに起こります。「0〜100に収まる」は誤解です。
Q3. 「偏差値70=上位約2.3%」はいつでも正しいの?
得点が正規分布に従うと仮定したときだけ正しいです。
偏差値70は (平均より 上)。正規分布なら より上は約2.3%なので「上位約2.3%」になります。しかし得点分布が正規分布でなければ崩れます。たとえば得点が二極化しているテストでは、偏差値70の位置に何%いるかは分布次第で2.3%とは限りません。「偏差値→上位何%」の換算は正規分布の仮定が前提です。
Q4. 経験則(68-95-99.7)とチェビシェフの不等式、どっちを使えばいいの?
分布が正規とわかっているなら経験則、形がわからない・歪んでいるならチェビシェフです。
- 経験則(68-95-99.7):正規分布前提。±2に約95%、と正確な割合が言える。前提が満たされていれば精密。
- チェビシェフの不等式:どんな分布でもOK(分布不問)。ただし保証は緩く、±2で「75%以上」しか言えない。
「形がわかれば正確に(経験則)、わからなくても確実に緩く(チェビシェフ)」と使い分けます。チェビシェフは緩いですが、どんな分布でも破れない歯止めであることに価値があります(分布の素性が不明な場面での保険)。
Q5. チェビシェフの不等式で を入れると「0以上」になって意味がないけど?
そのとおりで、チェビシェフの不等式は でないと意味がありません。
を入れると下限は 。「平均±1 の中に0%以上が入る」は何も言っていないのと同じ(どんな確率も0以上は当たり前)。 以下では下限が0かマイナスになり、情報がありません。チェビシェフが意味を持つのは のとき(で75%以上、で88.9%以上)です。「 を大きくするほど範囲は広いが、その中に入る保証割合も大きくなる」と理解してください。
Q6. 標準化と変動係数(CV)はどう違うの?
どちらも「単位をなくして比較する」発想ですが、対象が違います。
- 変動係数 CV (→ 散らばり(ばらつき)の指標 ── 範囲・四分位範囲・分散・標準偏差・変動係数(なぜ偏差を2乗するか/なぜn−1で割るか)):データセット全体のばらつきを1つの数で表す。「A社の売上のばらつき vs B社の売上のばらつき」のように分布同士のばらつきを比較する。
- 標準化 :個々のデータ点を1つずつ変換する。「太郎の国語の相対位置 vs 太郎の数学の相対位置」のようにデータ点の相対的な位置を比較する。
CVは「分布の散らばり具合の比較」、は「データ点の位置の比較」。役割が違うので使い分けます。
まとめ
- 標準化(得点):。データを「平均から 何個ぶん離れているか」に変換するものさしの貼り替え。標準化後は必ず平均0・標準偏差1(期待値・分散の線形性から導ける)。単位・スケールの違うデータを共通の土俵で比較できる(→ 散らばり(ばらつき)の指標 ── 範囲・四分位範囲・分散・標準偏差・変動係数(なぜ偏差を2乗するか/なぜn−1で割るか) のCVと同じ発想だが、CVは1指標・は各点を変換)。
- 標準化 ≠ 正規化(最頻出の誤解):標準化は線形変換(, )で、分布の形を一切変えない。歪んだ分布は標準化しても歪んだまま。「平均0・標準偏差1」は保証するが「正規分布」は保証しない。正規分布を標準化すれば標準正規分布になるが、逆は成り立たない。
- 偏差値:。を「平均50・標準偏差10」に目盛り替えしただけ(これも線形変換)。偏差値60=、70=、80=。上限・下限はない(100超・負もあり得る)。「偏差値70=上位約2.3%」は正規分布を仮定したときだけ。
- 経験則(68-95-99.7):正規分布なら ±1に約68%・±2に約95%・±3に約99.7%。ただし正規分布前提。
- チェビシェフの不等式:()。言い換えると平均± の中に少なくとも (→75%以上、→約88.9%以上)。最大の価値は**分布の形を仮定しない(distribution-free)**こと。 以下では下限が0以下になり無意味。
- チェビシェフ導出:分散 から、「全体の期待値 ≥ 遠い領域だけの期待値」「その領域では 」の2つの不等号で を得て、 で割る。当たり前を2回使うだけ。
- なぜ緩いか:分布の形を一切使わない「最悪ケース」の保証だから。形がわかる正規分布なら で実際95%なのに、チェビシェフは「最低75%」としか言えない。緩いが、どんな分布でも破れない歯止めであることに価値(大数の法則の証明にも使う)。
- 級差:3級=標準化・偏差値(、、上限なし) → 2級=チェビシェフの不等式(導出・の下限・分布不問) → 準1級〜=大数の法則の証明への応用。出題範囲は改訂されうるため受験前に最新の範囲表で要確認。
共通のものさし()と、どんな分布でも効く歯止め(チェビシェフ)がそろいました。次は、時間に沿って並ぶデータを扱う時系列データの記述へ進みます(→ 時系列データの処理 ── 指数・増減率・移動平均・成長率(なぜ成長率は幾何平均なのか))。
対応するシミュレーション
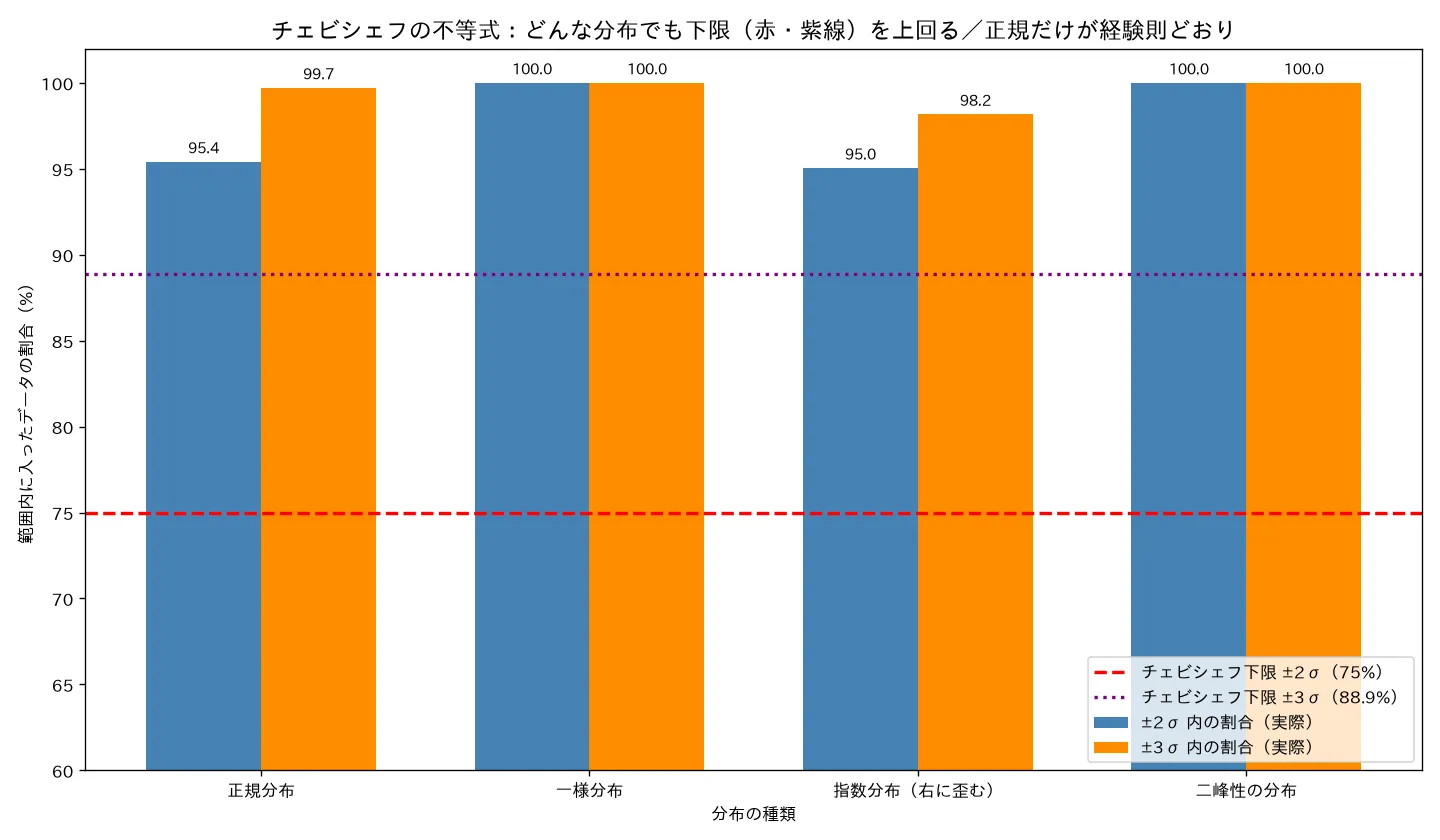
simulations/chebyshev_distribution_free.py- 何を示すか:形のまったく違う4分布(正規・一様・指数・二峰性)から20万個ずつデータを取り、各分布で「平均±2σ・±3σ 内に入る割合」を明示ループで数える。チェビシェフ下限(75%・88.9%)と正規の経験則(95%・99.7%)と並べ、どの分布でも下限を割らないこと・正規だけが経験則どおりになることを確認。「チェビシェフの不等式はどんな分布でも成り立つが緩い(保証下限を実際の割合がずっと上回る)」ことを実証する。
- 実行結果(成功):
- 正規分布:±2σ=95.41%(経験則95%どおり)、±3σ=99.71%(99.7%どおり)
- 一様分布:±2σ=100%、±3σ=100%
- 指数分布(右に歪む):±2σ=95.04%、±3σ=98.17%
- 二峰性:±2σ=100%、±3σ=100%
- 全分布でチェビシェフ下限75%を上回る(最小でも95.04%)/正規が経験則どおり。
- 可視化:4分布の「±2σ内・±3σ内割合」を棒で並べ、チェビシェフ下限75%・88.9%を水平線(赤・紫)で表示。どの棒も下限線を上回る=distribution-freeだが緩い、が一目。
- 結論:チェビシェフはどんな分布でも「±2σに75%以上・±3σに88.9%以上」を保証(分布不問の歯止め)。ただし緩く、正規なら経験則で「±2σに約95%」と精密に言える。「形がわかれば正確に、わからなくても確実に緩く」の使い分けが数値で再現。
関連ノート
- 散らばり(ばらつき)の指標 ── 範囲・四分位範囲・分散・標準偏差・変動係数(なぜ偏差を2乗するか/なぜn−1で割るか)(散らばり:範囲・四分位・分散・標準偏差・変動係数 ── 本トピックの土台。標準化の はここで定義。「単位をなくして比較」する変動係数CVと は同じ発想(CVは1指標・は各点変換)。後方リンク)
- 箱ひげ図と外れ値 ── 5数要約・ひげの2流派・1.5×IQRルール(なぜ係数が1.5なのか/約2.7σ・0.7%)(箱ひげ図・外れ値 ── 外れ値判定の「平均±」はこの の発想とつながる。四分位ベース判定の頑健性 vs 平均±(σが外れ値に弱い)の対比はチェビシェフの「σ前提」を考える補助。後方リンク)
- 時系列データの処理 ── 指数・増減率・移動平均・成長率(なぜ成長率は幾何平均なのか)(時系列データの記述 ── 時間に沿って並ぶデータの扱い。記述統計ドメインの次トピック。前方リンク・次トピック)
出典・参考
- 標準得点 - Wikipedia
- 標準化してもデータは必ずしも標準正規分布に従わない - Qiita
- 2-3. チェビシェフの不等式 | 統計WEB
- チェビシェフの不等式 - Wikipedia
- 68–95–99.7 rule - Wikipedia
- Empirical Rule vs Chebyshev’s Theorem
※統計検定の出題範囲・出題傾向は改訂されうるため、受験前に必ず最新の公式範囲表で確認してください(要最新確認)。