🎓 レベル:発展 | 重要度:A(必須)
📎 前提:オートエンコーダとVAE(潜在変数・変分の枠組み) | 数理:確率過程(マルコフ連鎖・ポアソン過程)(統計・マルコフ過程)
⚠️ 拡散モデルは現在もっとも動きの速い領域です。本ノートは廃れにくい原理(順過程・逆過程・ノイズ予測損失・スコア視点)を中心に書きます。具体的なアーキテクチャ・高速化・条件付け手法・最先端の生成品質は要最新確認とします。
要点(BLUF)
- 拡散モデルは「データに少しずつガウスノイズを足して純ノイズにする順過程」と、「それを逆にたどってノイズからデータを作る逆過程」のペアです。順過程は固定(学習なし)、逆過程だけをニューラルネットで学びます。
- 学習目標は VAE と同じ変分下界(ELBO)ですが、整理すると「足したノイズを当てる」単純な MSE 損失 に帰着します(DDPM)。これがこのモデルの核心です。
- 高品質・多様・学習が安定という強みがある一方、生成が多ステップで遅いのが弱点。これを克服する高速化と実用形(潜在拡散・条件付け)は要最新確認。
1. 発想:壊し方が分かれば、逆に作れる
考え方は驚くほど素朴です。
- きれいな画像 に、ガウスノイズをほんの少しずつ何百回も足していく。最後 はほぼ純粋なノイズ(標準正規分布)になります。これを**順過程(forward / diffusion process)**と呼びます。
- もしこの逆向きの 1 ステップ「 から少しだけノイズを取り除いて にする」を学習できたら、純ノイズ から出発して逆向きに 回たどることで、新しい画像 を生成できます。これが**逆過程(reverse process)**です。
要するに、「データの壊し方(順過程)」は人間が固定で決め、「壊れたものの直し方(逆過程)」だけを学習する、という分業です。順過程が単純なので、何を学べばいいかが数式できれいに定まります。
flowchart LR
x0["x_0 (データ)"] -->|"順過程 q:+ノイズ(学習なし)"| x1["x_1"]
x1 -->|"+ノイズ"| xdots1["…"]
xdots1 -->|"+ノイズ"| xT["x_T (ほぼ純ノイズ)"]
xT -.->|"逆過程 p_theta:-ノイズ(学習する)"| xdots2["…"]
xdots2 -.->|"-ノイズ"| x1b["x_1"]
x1b -.->|"-ノイズ"| x0b["x_0 (生成物)"]
subgraph 順方向 ["順過程:データ → ノイズ(固定)"]
x0
x1
xdots1
xT
end
subgraph 逆方向 ["逆過程:ノイズ → データ(ニューラルネット)"]
xdots2
x1b
x0b
end
2. 順過程:固定のマルコフ連鎖
順過程は、1 ステップごとに「少し縮めてノイズを足す」マルコフ連鎖です(マルコフ過程の定義は 確率過程(マルコフ連鎖・ポアソン過程))。
- はノイズスケジュール(各ステップでどれだけノイズを足すか)。 が進むほど大きくするのが普通で、 は非常に小さく、 は大きめにとります。
- で信号を少し縮め、 の分散でノイズを足す。この「縮めながら足す」設計が後で効きます。
要するに:各ステップは「元をちょっと薄め、ノイズをちょっと混ぜる」だけ。これを 回繰り返すと信号が消えて純ノイズになります。 にパラメータはなく、学習しません。
任意の への閉形式(最重要の性質)
毎回 1 ステップずつ足さなくても、 から一気に をサンプルできます。、 と置くと、
導出の骨子:ガウスノイズを足す操作の合成はまたガウスです。 を 1 段展開すると となり、独立な 2 つのガウスノイズの和は分散が足し合わさって 1 本のガウスノイズにまとまります(再パラメータ化トリックは オートエンコーダとVAE と同じ)。これを繰り返すと、係数が 、ノイズ分散が にきれいに集約されます。
要するに:「時刻 のノイズ入りデータ」は、元データを 倍に薄めて、強さ のノイズ 1 発を足したもの。 が大きいと で、ほぼノイズだけになります。この閉形式があるおかげで、学習時に任意の を 1 回でサンプルでき、計算が一気に軽くなります。
3. 逆過程:直し方をニューラルネットで学ぶ
生成に使いたいのは逆向き ですが、これは厳密にはデータ分布全体に依存して計算できません(扱いにくい)。そこでガウスで近似したものをニューラルネット で表します。
生成は から始め、この 1 ステップを と適用して に到達します。問題は「(と分散)を何に合わせて学習するか」。ここで ELBO が効きます。
4. 学習目標:ELBO がノイズ予測に化ける
ステップ A:ELBO(VAE と同じ枠組み)
を潜在変数とみなせば、これは階層的な潜在変数モデルで、対数尤度の下界は オートエンコーダとVAE とまったく同じ形で書けます。
この を KL の和に整理すると、各時刻 について次の項が出ます。
ポイントは、 で条件付けた逆向き事後分布 がガウスで閉じて計算できることです(ベイズの定理で と を掛けると、指数部が の 2 次式になり正規分布になる)。
ガウス同士の KL は平均の差の二乗で書けるので、 は本質的に**「 の平均 を、正解の平均 に合わせる回帰問題」**になります。
ステップ B:平均合わせを「ノイズ当て」に読み替える
ここが DDPM の鍵です。閉形式 を使って を で書き換えると、正解の平均 は次のようにノイズ だけで表せます。
そこで も同じ形に固定し、未知なのは だけ、と決めてしまいます。
すると 2 つの平均の差は に比例し、 は**「ネットワークが予測したノイズ を、実際に足したノイズ に合わせる二乗誤差」になります。係数(時刻ごとの重み)を実用上 1 に丸めたのが DDPM の単純損失**です。
要するに:難しそうな変分下界が、結局は**「ノイズまみれの画像を見て、どれだけノイズが混ざっているかを当てる」回帰**に化けます。学習は驚くほど単純で安定です。
学習・生成の手順
flowchart TB
subgraph 学習 ["学習(1 ステップ)"]
a1["データ x_0 を 1 枚とる"] --> a2["時刻 t を一様にランダム選択"]
a2 --> a3["ノイズ ε ~ N(0,I) を引く"]
a3 --> a4["x_t = √ᾱ_t·x_0 + √(1-ᾱ_t)·ε を作る"]
a4 --> a5["ネットで ε_θ(x_t, t) を予測"]
a5 --> a6["損失 ‖ε - ε_θ‖² を下げる"]
end
subgraph 生成 ["生成(T ステップ)"]
b1["x_T ~ N(0,I)"] --> b2["t = T,…,1 で 1 ステップずつ ε_θ で除ノイズ"]
b2 --> b3["x_0 を出力"]
end
生成 1 ステップの式(逆過程のサンプリング)は、上の にノイズを足し戻したものです。
ここで はステップごとの注入ノイズ強度( など)。最後の では にします。要するに:「予測したノイズを引いて少し戻し、ほんの少し新しい揺らぎを足す」を繰り返すだけです。
5. スコアベースという別の顔
拡散モデルは、スコアベース生成モデル(score-based generative model)とまったく同じものを別角度から見たものです。スコアとは対数密度の勾配 で、「データらしくなる方向」を指すベクトル場です。これを推定するのがスコアマッチング。
閉形式 のスコアを直接計算すると、
つまりスコアは「足したノイズ 」の符号付き定数倍です。したがってノイズ予測器とスコア推定器は
で読み替えられ、ノイズを MSE で当てること=スコアを学ぶことになります。生成は「スコアの方向に少しずつ登りながら揺らぎを足す」ランジュバン動力学(連続時間では確率微分方程式)として書け、DDPM のサンプリングはその離散化に対応します。
要するに:「ノイズ除去」「変分下界」「スコア推定」は別物に見えて、同じ確率構造の違う言い換えです。どの言葉で話しても同じモデルにたどり着きます。
6. 実装:何で逆過程を作るか
- ノイズ予測器 は U-Net(畳み込みの符号化・復号化に skip 接続を足した形。畳み込みは 畳み込みニューラルネットワーク)。入力画像 と同じ大きさのノイズ画像を出力するため、画素単位の予測に向いた U-Net が定番です。
- 時刻 の埋め込み:同じネットで全ての を扱うので、 を正弦波埋め込み等でベクトル化して各層に注入します。「いまどれくらいノイズが乗っている段階か」をネットに教える役割です。
- 条件付き生成(テキストや分類ラベルで内容を指定):条件 を入力に加えて とします。代表的な**分類器なしガイダンス(classifier-free guidance)**は、条件あり予測と条件なし予測を用意し、両者を外挿して条件への忠実度を強める手法です。
(ガイダンス強度)を上げると条件に忠実になる一方、多様性が落ちるトレードオフがあります。具体的な条件付けの実装・テキストエンコーダ・ガイダンス係数の最適値は要最新確認です。
7. VAE・GAN との対比
| 観点 | 拡散モデル | VAE(オートエンコーダとVAE) | GAN(敵対的生成ネットワーク) |
|---|---|---|---|
| 学習の安定性 | 高い(単純な回帰損失) | 高い | 低い(敵対的でモード崩壊しやすい) |
| サンプル品質 | 非常に高い | ぼやけがち | 高い(鋭い) |
| 多様性(モード網羅) | 高い | 高い | 低くなりがち |
| 生成速度 | 遅い(多ステップ) | 速い(1 回) | 速い(1 回) |
| 尤度の扱い | 下界を最適化(明示的に近い) | 下界(ELBO) | 明示的尤度なし |
最大の弱点は逆過程が多ステップで生成が遅いことです。サンプリングのステップ数を減らす手法(決定的サンプラーや蒸留など)や、画素ではなく VAE の潜在空間で拡散する潜在拡散で計算を軽くする方向が主流ですが、この領域は最も動きが速く、最新スペック・最良手法は要最新確認とします。
⚠️ よくある誤解・落とし穴
- 「拡散=ただのデノイジング(ノイズ除去フィルタ)」ではありません。 1 枚のノイズ除去ではなく、少量除去を多数ステップ積み重ねて分布全体をたどることで、ノイズから新規データを生成します。各ステップは弱くても、全体として複雑な分布を作れるのが本質です。
- 「ステップ数を増やすほど必ず高品質」ではありません。 多ステップは品質に効きますが、計算コストと引き換えです。少ステップでも高品質を出す改良が活発で、ステップ数と品質の関係は手法依存(要最新確認)。
- 順過程は学習対象ではありません。 は設計者が決めるハイパーパラメータで、学習されるのは逆過程 だけです。
- 実用形(潜在拡散・条件付け・ガイダンス)は原理そのものではなく実装上の工夫です。 本ノートの順過程・逆過程・ノイズ予測損失・スコア視点は廃れにくい骨格ですが、実用システムの構成は要最新確認で扱ってください。
- 予測は唯一の選択肢ではありません。 予測や速度(v)予測など別パラメータ化もあり、互いに変換可能です(要最新確認)。
対応するシミュレーション
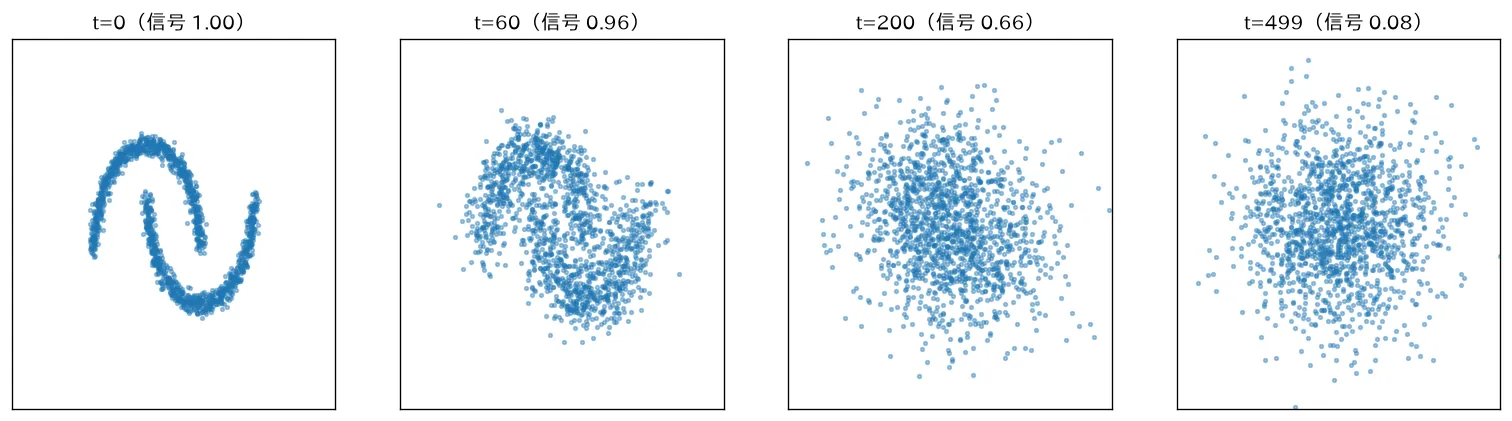
simulations/diffusion_process.py:二日月のデータに拡散の順過程を適用し、 を進めるほどデータが少しずつガウスノイズに崩れ、最後は純粋な正規分布になる様子を可視化します。任意の時刻 は閉形式 で一発サンプリングでき、信号の割合 が へ減ることを示します。拡散モデルの本体はこの崩しを逆にたどる( を最小化)部分です。
関連ノート
生成モデル 目次・オートエンコーダとVAE・敵対的生成ネットワーク・畳み込みニューラルネットワーク・確率過程(マルコフ連鎖・ポアソン過程)・機械学習テキスト 全体目次