🎓 レベル:発展 | 重要度:A(必須)
📎 前提:オートエンコーダとVAE(生成モデルの対比) | 関連:凸最適化の基礎(ミニマックス)
要点(BLUF)
- GAN は生成器 と識別器 を競わせる。 はノイズから偽データを作り、 は本物と偽物を見破る。両者を交互に鍛えると がデータ分布を模倣できるようになります。
- 最適識別器を代入すると、目的は JS(Jensen–Shannon)ダイバージェンスの最小化に帰着します。理論的には で大域最適です。
- 尤度 を一切計算しない暗黙的生成モデル。鮮明なサンプルが出る反面、モード崩壊・学習不安定という固有の難しさを抱えます。
発想:偽造犯 vs 鑑定士
GAN(Generative Adversarial Network, Goodfellow ら 2014)の発想は、2つのネットワークを敵対させることです。
- 生成器(Generator):ランダムなノイズ (例:標準正規分布)を入力に、偽のデータ を作る。偽造犯にあたります。
- 識別器(Discriminator):入力 が本物(データ)か偽物( の出力)かを判定し、本物である確率 を返す。鑑定士にあたります。
偽造犯はより本物そっくりの贋作を作ろうとし、鑑定士はより精度よく贋作を見破ろうとします。両者がイタチごっこで腕を上げ続けると、最終的に偽造犯の作品は本物と見分けがつかなくなる——これが GAN の学習が目指す状態です。
flowchart LR
Z["ノイズ z 〜 p_z"] --> G["生成器 G"]
G --> Fake["偽データ G(z)"]
Real["本物 x 〜 p_data"] --> D["識別器 D"]
Fake --> D
D --> Out["真偽の確率 D(・)"]
Out -. "Dを最大化(見破る)" .-> D
Out -. "Gを最小化(騙す・勾配は逆伝播で G へ)" .-> G
ポイントは、 への学習信号が識別器 を通した勾配としてのみ与えられることです。 は「本物のデータ」を直接見ません。 がどこで騙されたかという情報だけを頼りに、誤差逆伝播(誤差逆伝播法)で更新されます。
ミニマックス目的
GAN の学習は、次の価値関数 をめぐる2人ゲームとして定式化されます。
各項の意味を分解します。
- 第1項 :本物 に対して を 1 に近づけたい(本物を本物と当てる)。 はこれを大きくしたい。
- 第2項 :偽物 に対して を 0 に近づけたい(偽物を偽物と当てる)。 はこれも大きくしたい。
- :識別器は両方を当てて を最大化する。これは本物・偽物を二値分類する交差エントロピーの最大化そのものです。
- :生成器は に偽物を見破られないように、第2項を最小化する( を 1 に近づける)。第1項に は含まれないので、 は実質第2項だけに効きます。
要するに、識別器は「本物・偽物を当てるゲーム」で得点を最大化し、生成器は「識別器を騙して」その得点を最小化する、入れ子のミニマックスです。
学習は両者を交互に更新します( を ステップ、 を1ステップ、のように)。識別器を内側で最大化し、その結果を使って生成器を外側で最小化する、という二段構えがミニマックスの実装です。
最適識別器の導出
GAN の理論の核は、「 を固定したとき、最適な識別器 が閉形式で書ける」ことです。ここから目的が JS ダイバージェンスへ帰着することを示します。
ステップ1:価値関数を1つの積分にまとめる
第2項は期待値を で変数変換すると、生成分布 上の積分になります( は が従う分布)。すると は についての1本の積分にまとまります。
ステップ2:各点ごとに被積分関数を最大化
は各点 で独立に値を選べるので、 の最大化は被積分関数を ごとに最大化することと同じです。、 と置くと、最大化したいのは
です。微分してゼロと置きます。
なので、これは最大点です( は上に凸、凸最適化の基礎)。したがって最適識別器は
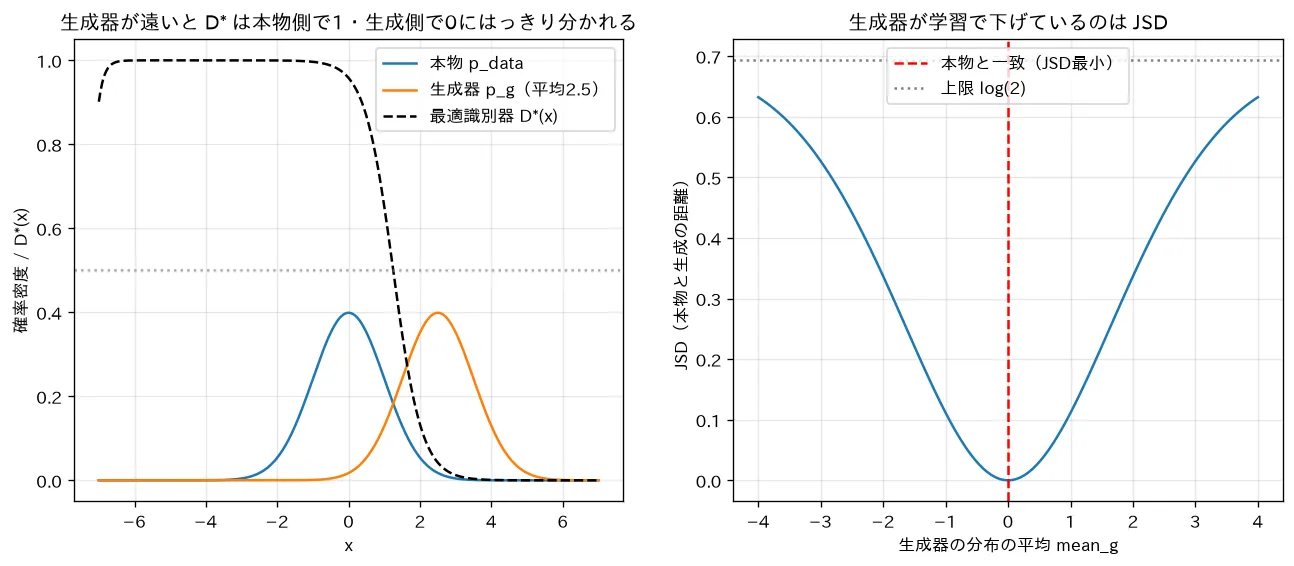
要するに、最適な鑑定士は「その点での本物の密度の、本物+偽物に対する割合」を出力します。本物だけが存在する点では 、偽物だけの点では 、両者が等しい点では です。
ステップ3: を代入して JS ダイバージェンスへ
を に戻し、生成器が最小化する仮想目的 を計算します。
分母に を作るため、各 の中を で割って外に を出します。
ここで JS ダイバージェンスの定義
を使うと、2つの KL 項はちょうど にまとまります。
要するに、最適識別器のもとで生成器が解いているのは「データ分布と生成分布の JS ダイバージェンスの最小化」です。 は知らないうちに分布間の距離を縮めています。
ステップ4:大域最適
JSD は非負で、 です。よって の大域最小は
このとき 。鑑定士がコインを投げるしかなくなった状態——本物と偽物がまったく見分けられない——が理論上のゴールです。
暗黙的生成モデル:尤度を計算しない
GAN の大きな特徴は、生成分布 を陽に計算しないことです。
- VAE(オートエンコーダとVAE):尤度の下界 ELBO を明示的に最大化する。密度を扱う。
- 自己回帰モデル: と尤度を明示的に分解する。
- GAN: でサンプリングはできるが、その の密度 を式で評価する手段を持たない。
このようなモデルを暗黙的生成モデル(implicit generative model)と呼びます。GAN は密度を測る代わりに、「サンプルが本物と区別できるか」という識別器の判定だけを頼りに学習します。これが、尤度の最大化に縛られない自由さ(鮮明な画像)と、尤度という安定した羅針盤を失った難しさ(不安定さ)の両方を生みます。
学習の難しさ
理論上は が大域最適でも、実際の学習は大きく揺れます。代表的な失敗を挙げます。
1. 勾配消失(vanishing gradient)
学習初期、 の出力は本物とかけ離れているため、 と のサポート(台)がほとんど重なりません。重ならない2分布の JSD は一定値 に飽和し、 について微分すると勾配がほぼゼロになります。識別器が強すぎて完璧に見破ると となり、 の勾配が消え、 が学習できなくなります。
対策:non-saturating loss(飽和しない損失)。 について元の の代わりに、(= の最小化)を使います。これは「偽物を本物と判定させる」よう向きを変えた同符号の目的ですが、 が小さい初期にむしろ大きな勾配を与えます。原論文も実装ではこちらを推奨しており、現在も標準です。
xychart-beta
title "識別器の出力 D(G(z)) に対する生成器の勾配の強さ(概念図)"
x-axis "D が偽物と見破る ← D(G(z)) → D が騙される" 0.05 --> 0.95
y-axis "G が受け取る勾配の大きさ" 0 --> 10
line [9.5, 3.0, 1.5, 1.0, 0.7, 0.5, 0.4, 0.3, 0.25]
line [0.3, 0.4, 0.5, 0.7, 1.0, 1.5, 2.5, 5.0, 9.5]
上図:下に凸の線(non-saturating, )は が小さい初期に強い勾配を与えます。もう一方(飽和する元の損失)は初期に勾配がほぼゼロです。
2. モード崩壊(mode collapse)
がデータ分布の一部のモード(山)だけを再現し、似たサンプルばかり出す現象です。極端には、識別器を確実に騙せる「特にもっともらしい1種類の出力」に が固着します。多様性を測る項がミニマックス目的に無いため、 は「全モードを覆う」より「1点で確実に勝つ」方に逃げられます。交互最適化で が の弱点を追いかけ、 がそれに適応し…とモード間を循環することもあります。
3. 収束しない(ナッシュ均衡の難しさ)
GAN は2プレイヤー非協力ゲームのナッシュ均衡を探す問題です。一方の損失を下げる更新が他方の損失を上げるため、勾配降下が均衡へ収束する保証はなく、振動や発散が起きます(最適化が鞍点的構造を持つため、凸最適化の基礎 の単純な凸最小化とは性質が違う)。
改善手法(⚠️ 要最新確認)
GAN の安定化は活発に研究が続く領域です。以下は代表的な方向性ですが、最新の標準は要確認です。
- WGAN / WGAN-GP:JS ダイバージェンスの代わりにWasserstein 距離を最小化する。Wasserstein は分布のサポートが重ならなくても連続でなめらかな勾配を与えるため、識別器(critic)を最適近くまで鍛えても勾配消失せず、モード崩壊も緩和されると報告されています。WGAN-GP は Lipschitz 制約を勾配ペナルティで課す方式です。
- その他、スペクトル正規化・特徴マッチング・ミニバッチ識別など多数。いずれも「勾配を健全に保つ」「多様性を促す」狙いです。
VAE との対比
同じ生成モデルでも、VAE(オートエンコーダとVAE)と GAN は性格が正反対です。
| 観点 | VAE | GAN |
|---|---|---|
| 学習の目的 | 尤度の下界 ELBO を最大化 | ミニマックス(実質 JSD 最小化) |
| 密度 | 近似的に扱える(明示的) | 扱えない(暗黙的) |
| サンプルの質 | ぼやけがち(再構成誤差・平均化) | 鮮明(識別器が細部を要求) |
| 学習の安定性 | 安定(単一目的の最適化) | 不安定(均衡探索・崩壊) |
| 潜在空間 | 構造化され滑らか(事後分布を正則化) | 構造の保証は弱い |
要するに、VAE は「ぼやけるが安定」、GAN は「鮮明だが不安定」。VAE のぼやけは尤度(平均的再構成)に最適化する代償、GAN の鮮明さは「本物と区別できないこと」を直接求める恩恵であり、不安定さはその裏返しです。
⚠️ よくある誤解
- 「GAN = 生成モデルの代表」ではない。GAN は強力な一手法にすぎません。鮮明な画像で一時代を築きましたが、近年は拡散モデルが品質・安定性の両面で多くの画像生成タスクの主流になっています(要最新確認)。GAN を生成モデル全体の同義語のように扱わないこと。
- 「識別器が最終成果物」ではない。 は を鍛えるための足場です。学習後に欲しいのは (サンプラー)であり、識別器は推論時に捨てるのが基本です(半教師あり等で再利用する派生はあります)。
- 「最適化すれば必ず に収束する」わけではない。 は理論上の大域最適点であって、勾配法がそこへ到達する保証はありません。ナッシュ均衡探索は本質的に難しく、モード崩壊・振動が実際には頻発します。理論の最適点と実際の到達可能性を混同しないこと。
- 「JSD 最小化が常に良い」わけではない。サポートが重ならない初期では JSD が飽和して勾配を出さないという欠点があり、これが WGAN(Wasserstein 距離)への動機になりました。
まとめ
- GAN は生成器 と識別器 のミニマックスゲーム。 を交互最適化します。
- 最適識別器 を代入すると、目的は 、すなわちJS ダイバージェンスの最小化。大域最適は 、そこで 。
- 暗黙的生成モデル:尤度を計算せずサンプリングのみ。鮮明さと引き換えに、勾配消失・モード崩壊・収束しないという固有の難しさを抱え、non-saturating loss や WGAN 等で対処します(要最新確認)。
対応するシミュレーション
simulations/gan_optimal_discriminator.py:本物 と生成器 (平均をずらした正規分布)に対し、最適識別器 を描きます。生成器が遠いと ははっきり見分けるが、本物に近づくとどこでも0.5に近づくこと、そして生成器が下げている量が JSD(最小0・上限 )であることを可視化します。実際の学習は不安定でモード崩壊・勾配消失が起きる点にも触れます。