🎓 レベル:発展 | 重要度:B(標準)
📎 前提:勾配降下法 | 応用:サポートベクターマシン(SVM)(KKT・双対の実例)
要点(BLUF)
- 凸最適化とは「凸集合の上で凸関数を最小化する」問題で、ここでは局所最適がそのまま大域最適になります。だから安心して勾配を下れます。
- 制約付きになると、制約をペナルティとして目的関数に混ぜ込むラグランジュ関数で扱い、その双対問題とKKT条件が最適性の特徴づけを与えます。
- SVM(サポートベクターマシン(SVM))やRidge/Lasso(正則化(Ridge・Lasso・Elastic Net))は、この枠組みのど真ん中の応用例です。
なぜ凸性が機械学習で嬉しいのか
機械学習の学習は、結局「損失(経験リスク)を最小化する」最適化問題です(学習問題の定式化(仮説・損失・経験リスク))。最適化が難しいのは局所最適に捕まるから。勾配を下っても、それが谷底(大域最適)とは限りません。
ところが目的関数が凸なら、この心配が消えます。**「見つけた局所最適は、必ず大域最適」**が保証されるからです。これが凸最適化を学ぶ最大の動機です。順に、凸集合 → 凸関数 → その嬉しい性質、と積み上げます。
凸集合
定義:集合 が凸集合であるとは、 内の任意の2点 と任意の について
が成り立つこと。
要するに、集合内の2点を結ぶ線分が、はみ出さずに丸ごと集合に収まるということです。 は と を結ぶ線分上の点( で 、 で )を表します。
- 凸な例:球(ノルム球 )、超平面 、半空間 、それらの共通部分。線形不等式 で定義される領域(多面体)も凸です。
- 凸でない例:ドーナツ型(穴があり線分が外を通る)、三日月型、離散点の集合。
制約 がどれも凸関数なら、実行可能領域 は凸集合の共通部分なので凸になります。これが後で効きます。
凸関数
定義:関数 (定義域は凸集合)が凸関数であるとは、任意の と について
が成り立つこと。
要するに、2点を結んだ「弦(直線)」が、関数のグラフより上にあるということです。左辺は2点の中間(線分上の点)での関数値、右辺はその弦の高さ。弦が常にグラフを上から押さえているのが凸です。不等号が常に真の不等号 (、)なら狭義凸といいます。
一次条件(微分可能なとき)
が微分可能なら、凸性は次と同値です:
要するに、関数が自分の接平面より常に上にあるということです。右辺は点 での一次近似(接平面)。凸関数は接線(接平面)が必ず下から支える「お椀型」だと言っています。
この条件の重要な帰結:もし なら、任意の で 。つまり勾配がゼロになる点は、それだけで大域最適です(無制約のとき)。非凸では「勾配ゼロ=停留点」止まりで、極小・極大・鞍点の区別がつかないのと対照的です。
二次条件(2回微分可能なとき)
が2回微分可能なら、凸性はヘッセ行列 が半正定値であることと同値です:
ここで は「任意の に対し 」、同値に「全固有値が非負」。要するに、どの方向に動いても曲率が下に凸(上に反らない)ということです。固有値がすべて正(正定値 )なら狭義凸になります(十分条件)。
⚠️ 逆は成り立ちません。 は狭義凸ですが で正定値ではありません。「狭義凸 ⇒ ヘッセ正定値」は偽、「ヘッセ正定値 ⇒ 狭義凸」が真です。
機械学習での具体例:二乗誤差 はヘッセが なので凸(線形回帰(最小二乗法と確率的解釈))。 正則化項 はヘッセ で狭義凸。ロジスティック回帰の負の対数尤度も凸です。
なぜ凸だと「局所最適=大域最適」なのか(証明)
これが凸最適化の心臓です。背理法できちんと示します。
主張: が凸関数のとき、 が局所最適(ある半径 の近傍で最小)なら、 は大域最適である。
証明(背理法): を局所最適とし、これが大域最適でないと仮定します。すると、ある点 が存在して
が成り立ちます。ここで と を結ぶ線分上の点を、 に十分近い側に取ります:
凸関数の定義より、
仮定 を右辺に使うと、 なので
よって
ところが、 を 1 に十分近く取れば は の半径 の近傍に入れます( と の距離は で、 でいくらでも小さくできるため)。すると「近傍内に より小さい点 がある」ことになり、 が局所最適であることに矛盾します。
したがって、 となる は存在せず、 は大域最適です。
直観:弦がグラフを上から押さえる(凸の定義)以上、「局所的にはここが底だが、遠くにもっと低い谷がある」という状況は作れません。もっと低い点があるなら、そこへ向かう線分上を少し進むだけで必ず下がってしまうからです。だから凸では谷は1つ(連結な底)。
graph LR A["f が凸関数"] --> B["弦が常にグラフより上<br/>近傍に下がる方向が必ずある"] B --> C["局所最適より低い点 y があれば<br/>線分上の z で f が更に下がる"] C --> D["局所最適の定義に矛盾"] D --> E["局所最適 = 大域最適<br/>勾配を下るだけで谷底に届く"]
この性質のおかげで、凸問題では「勾配がゼロの点(停留点)を1つ見つける」=「大域最適を見つける」になります。勾配降下法(勾配降下法)が安心して使えるのはこのためです。
制約付き最適化とラグランジュ関数
実問題には制約が付きます。標準形は:
この最適値を (主問題の最適値)と書きます。制約付きを直接扱うのは面倒なので、制約を目的関数にペナルティとして取り込むのがラグランジュの発想です。
ラグランジュ関数:
- :不等式制約のラグランジュ乗数(KKT乗数)。 を破る()と罰金が増える向きなので符号制約 が要ります。
- :等式制約の乗数(符号自由)。
要するに、「制約を破ったらペナルティを払う」形に書き換え、ペナルティの強さ(乗数)を変数として一緒に扱うわけです。乗数は「その制約をどれだけ厳しく効かせるかの値段(影の価格)」と読めます。
ラグランジュ双対
双対関数
ラグランジュ関数を について最小化したものを双対関数と呼びます:
重要な性質:双対関数は( が何であれ)常に凹関数です。理由は、 は固定した に対して のアフィン(一次)関数であり、アフィン関数の下限(点ごとの inf)は凹関数になるから。主問題が非凸でも双対は凹なので扱いやすい、という強みがあります。
弱双対(常に成立)
双対問題は、この下界を最大化します:
弱双対定理: が常に成り立つ。
証明:任意の実行可能点 (, )と任意の について、
一方、inf の定義から 。両者を繋ぐと、任意の実行可能 で
右辺で実行可能 にわたり下限を取ると 。最後に左辺で にわたり上限を取れば 。
要するに、双対問題は主問題の「下からの最良の見積もり」を与える。差 を双対ギャップと呼びます。
強双対とスレーター条件
強双対:(ギャップがゼロ)。これは一般には成り立ちませんが、凸問題では十分条件があります。
スレーター条件:主問題が凸( が凸、 がアフィン)で、すべての不等式制約を真に満たす実行可能点が存在する(ある で がすべて成立。アフィン制約は等号でよい)。
このとき強双対が成立します()。要するに、「制約の内側にちゃんと余白がある凸問題」なら、双対問題を解けば主問題の答えがそのまま得られるということ。SVMの双対形式(サポートベクターマシン(SVM))が主問題と同じ答えを返し、しかもカーネル化できるのはこの強双対のおかげです。
KKT条件
強双対が成り立つとき、最適解 は次の4条件をすべて満たします。これがKKT(Karush–Kuhn–Tucker)条件です。
各条件の意味:
- (1) 停留性:ラグランジュ関数の に関する勾配がゼロ。無制約での「」を、制約の勾配で補正した形。目的の下げたい方向が、効いている制約の壁の法線方向で完全に打ち消されている状態です。
- (2) 主実行可能性: がそもそも制約を満たす(当たり前に必要)。
- (3) 双対実行可能性:不等式乗数は非負(弱双対の証明で使った符号)。
- (4) 相補性条件:各 で「」か「」の少なくとも一方。要するに、効いていない制約(、内側で余裕あり)の乗数はゼロ、乗数が正の制約は必ず等号でアクティブ。「使っていない壁には値段が付かない」という直観です。
KKTの2つの顔(凸の場合):
- 必要条件:強双対が成り立つ凸問題では、最適解は必ずKKTを満たす。
- 十分条件:凸問題では、KKTを満たす はそれだけで大域最適。つまり凸では「KKTを満たす点を見つける = 解けた」になります(局所=大域の制約付き版)。
graph TB K["KKT条件<br/>制約付き凸最適の最適性の特徴づけ"] K --> S1["(1)停留性<br/>∇L が 0"] K --> S2["(2)主実行可能性<br/>g_i ≤ 0, h_j = 0"] K --> S3["(3)双対実行可能性<br/>λ_i ⪰ 0"] K --> S4["(4)相補性条件<br/>λ_i・g_i = 0"] S4 --> SV["効かない制約は λ_i = 0<br/>正の λ_i の制約だけアクティブ"]
SVMがKKTの実例
SVM(サポートベクターマシン(SVM))は凸(二次計画)+スレーター条件を満たすので、強双対とKKTがそのまま使えます。ハードマージンSVMの主問題は
各データ点 に乗数 が付きます。ここで相補性条件 が決定的です:
- マージンの内側でない点(、)は、相補性より 。決定境界に影響しない。
- マージン上の点(、)だけが を取りうる。これがサポートベクター。
さらに停留性条件 から が出て、 の点(サポートベクター)だけで が決まることが分かります。「決定境界が一部の点だけで決まる」というSVMの核心が、相補性条件から直接導かれるわけです。
正則化も制約付き最適化として読める
Ridge/Lasso(正則化(Ridge・Lasso・Elastic Net))は2通りに書けて、両者は等価です:
左のペナルティ形式は、まさに右の制約付き問題のラグランジュ関数( が乗数)です。各 に対応する が存在し、強双対により最適解が一致します。 がRidge(凸・狭義凸)、 がLasso(凸だが非平滑)。「正則化=係数の大きさに予算制約を課す」という見方は、ここから来ています。
⚠️ よくある誤解・落とし穴
- 「機械学習の損失は凸」ではありません。 凸なのは線形回帰・ロジスティック回帰・SVM・線形モデル+凸正則化など浅いモデルまで。ニューラルネット(ニューラルネットワーク 目次)の損失はほぼ常に非凸で、局所最適や鞍点が無数にあります。凸最適化の保証は深層では使えず、SGD+経験則で「十分良い」局所解を狙うのが実情です。それでも凸理論は「うまくいく理想形」の基準として価値があります。
- 凸でも一発で解けるとは限りません。 「局所=大域」はどこに谷があるかを保証するだけ。閉形式解(正規方程式など)がない凸問題(Lasso、大規模ロジスティック回帰)は、結局反復解法(勾配降下・近接勾配・内点法)で近づけます。凸性は「収束先が大域最適だと保証される」という意味で効きます。
- 狭義凸 ⇔ ヘッセ正定値 は誤り。 前述の の通り、狭義凸でもヘッセが正定値とは限りません(一方向のみ)。
- 相補性は「両方ゼロ」ではない。 は「少なくとも一方がゼロ」。アクティブな制約では かつ がふつうに起こります。
- 双対ギャップはゼロとは限らない。 弱双対 は常に成立しますが、(強双対)には凸+スレーター等の条件が要ります。非凸では正のギャップが残りえます。
まとめ
凸最適化は「凸集合上で凸関数を最小化する」問題で、局所最適=大域最適という強い保証(背理法で証明)が成り立つため、勾配を下るだけで解けます。制約が付くとラグランジュ関数で扱い、双対問題が下界(弱双対は常に成立)を、強双対(凸+スレーター条件)が等号を与えます。最適性はKKT条件(停留性・主実行可能性・双対実行可能性・相補性)で特徴づけられ、凸ではKKTが必要十分。SVMのサポートベクターや正則化の予算制約は、この理論のそのままの応用です。深層学習の損失は非凸なので保証は外れますが、凸理論は「学習がうまくいく理想形」の基準として効きます。
対応するシミュレーション
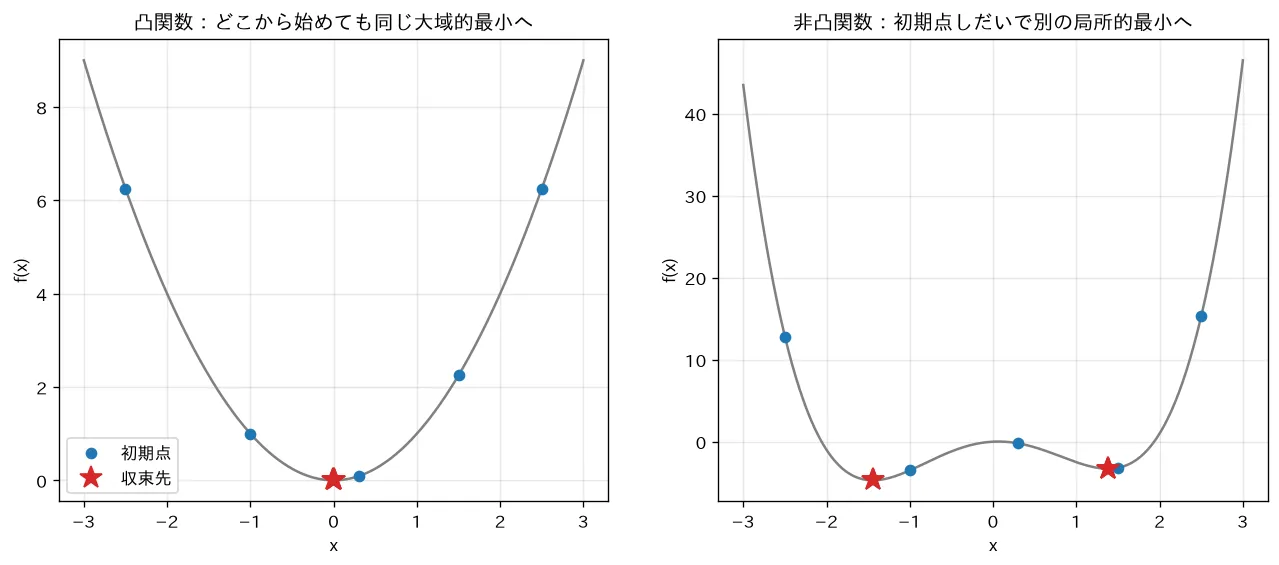
simulations/convex_nonconvex.py:凸関数 と非凸関数 (谷が2つ)に対し、複数の初期点から勾配降下を回します。凸関数ではどの初期点からも同じ大域的最小に到達するのに対し、非凸関数では初期点しだいで異なる局所的最小に捕まることを可視化します(深いネットの損失が非凸であることの含意)。
関連ノート
- 最適化と学習理論 目次 — このドメインの位置づけ
- 勾配降下法 — 凸性が効く「実際に下る」アルゴリズム
- 正則化の理論 — 正則化を制約付き最適化/MAPとして統一的に見る
- サポートベクターマシン(SVM) — KKT・強双対・相補性の代表的応用
- 正則化(Ridge・Lasso・Elastic Net) — ペナルティ形式=制約形式の等価性
- 線形回帰(最小二乗法と確率的解釈) — 二乗誤差が凸(ヘッセ )になる原型
- 学習問題の定式化(仮説・損失・経験リスク) — 学習=損失最小化という最適化問題
- 機械学習テキスト 全体目次 — 全ドメインのハブ
📌 統計の土台:正則化のベイズ的解釈(MAP推定)は統計サイトのベイズ推定・MAP推定へ繋がります。