🎓 レベル:基礎 | 重要度:A(必須)
📎 前提:学習問題の定式化(仮説・損失・経験リスク)(経験リスク最小化) | 原型:線形回帰(最小二乗法と確率的解釈)(最小二乗を勾配で解く)
要点(BLUF)
- 勾配降下法は「損失 を、勾配 の逆向きに少しずつ動かして谷を下る」最適化の最も基本的な手法です。更新式はたった一行 。
- 勾配を**全データで計算するか(バッチ)・1サンプルで計算するか(SGD)・小さな塊で計算するか(ミニバッチ)**の3版があり、「1ステップの計算コスト」と「勾配の正確さ(ノイズの少なさ)」のトレードオフになっています。実務はほぼミニバッチです。
- 凸な損失なら大域最適に収束しますが、ニューラルネットのような非凸では局所最適や鞍点が問題になります。SGD の勾配ノイズはこの鞍点脱出や汎化にむしろプラスに働きます。
1. なぜ最適化なのか — 学習=損失の最小化
機械学習の学習は、突き詰めると最適化問題です。学習問題の定式化(仮説・損失・経験リスク)で見たように、訓練データ上の平均損失(経験リスク)
を最小にするパラメータ を探すのが学習でした(経験リスク最小化, ERM)。線形回帰のように を解析的に解ける幸運な場合は線形回帰(最小二乗法と確率的解釈)の正規方程式で一発です。しかし損失が複雑(ロジスティック回帰・ニューラルネット)になると、 を閉じた式で解けません。
そこで、解けないなら「下り坂を歩いて谷に向かう」——これが勾配降下法の発想です。
2. 勾配降下法の定義
パラメータを次の規則で繰り返し更新します:
- :現在地での損失の勾配(各パラメータで偏微分したベクトル)
- :学習率(learning rate, ステップ幅)。1歩の大きさ
- マイナス符号:勾配の逆向きに進む
要するに:いまいる地点で一番きつい上り坂の方向(勾配)を調べ、その正反対の方向へ だけ足を進める。これを繰り返すと谷底(損失最小)に近づいていきます。
なぜ勾配の逆向きが「最も急な下り」なのか
ここは省略しがちですが、勾配降下法の心臓部です。現在地 から微小に へ動いたときの損失を一次のテイラー展開で近似します:
損失を最も減らしたい、つまり第2項 を最も**小さく(負に大きく)**したい。 の長さを と固定すると、内積 は
で、 は勾配と のなす角です。これが最小になるのは 、すなわち が勾配と真逆を向くとき。よって最急降下方向は
要するに:勾配は「最も急な上り坂の向き」を指すベクトル。だから損失を最速で減らすには、その真逆に歩けばよい。学習率 が一歩の長さ に対応します。
flowchart TD
A["パラメータ θ を初期化"] --> B["勾配 ∇L(θ)を計算"]
B --> C["θ ← θ − η・∇L(θ)(逆向きに一歩)"]
C --> D{"収束したか?<br/>(勾配がほぼ0 / 損失が下げ止まり)"}
D -- "いいえ" --> B
D -- "はい" --> E["最適パラメータ θ* を返す"]
3. 3つの版 — バッチ・SGD・ミニバッチ
ステップ2の勾配 は「全 サンプルの損失の平均」の勾配でした。これを毎回まじめに全データで計算すると、 が巨大なときに1ステップが重すぎます。そこで勾配を何サンプルで推定するかに3つの選択肢が生まれます。
| 版 | 1ステップの勾配 | 1ステップのコスト | 勾配ノイズ | 収束の軌跡 |
|---|---|---|---|---|
| バッチ GD | 全 サンプル | 重い() | なし(真の勾配) | 滑らかにまっすぐ下る |
| 確率的 SGD | 1サンプル | 軽い() | 大きい | ジグザグに揺れて下る |
| ミニバッチ | サンプル(例 32〜256) | 中間 | 中間 | ほどよく揺れて下る |
バッチ勾配降下(Batch GD) は真の勾配を使うので軌跡は滑らかですが、1ステップごとに全データを舐めるため大規模データでは非現実的です。
確率的勾配降下(Stochastic GD, SGD) は各ステップでランダムに1サンプル を選び、その勾配だけで更新します:
1サンプルの勾配は全体の勾配の不偏推定になっています(期待値を取ると真の勾配に一致)。だから「平均的には正しい方向」へ進みますが、1サンプルぶんなのでノイズが乗りジグザグします。
ミニバッチ勾配降下(Mini-batch GD) はその中間で、毎回 サンプルの塊で勾配を平均します。実務の標準はこれです。理由は2つ:(1) ノイズが 程度に減って軌跡が安定する、(2) GPU の行列演算は塊で計算するほど効率が良い(1サンプルずつより圧倒的に速い)。
graph LR
subgraph バッチGD
A1["全データで勾配"] --> A2["まっすぐ・遅い・重い"]
end
subgraph SGD
B1["1サンプルで勾配"] --> B2["ジグザグ・速い・ノイズ大"]
end
subgraph ミニバッチ
C1["B個で勾配"] --> C2["ほどよく安定・GPU効率◎"]
end
A2 -.-> D["実務はミニバッチが定番<br/>(速度とノイズのバランス)"]
B2 -.-> D
C2 -.-> D
用語メモ:全データを1巡することを 1エポック(epoch) と呼びます。バッチ GD は1エポック=1更新ですが、ミニバッチ/SGD は1エポックで 回(SGD なら 回)更新します。
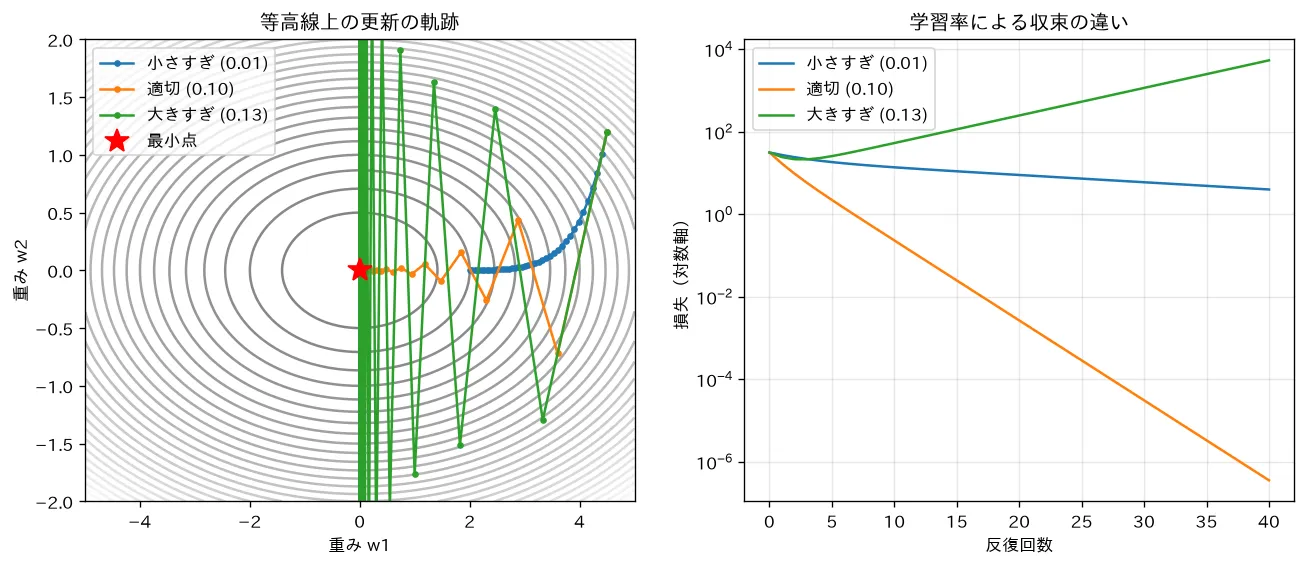
4. 学習率 η — 大きすぎても小さすぎてもダメ
学習率は勾配降下で最も重要なハイパーパラメータです。挙動は の大小で大きく変わります。
- 小さすぎる:1歩が小さく、谷底まで延々と時間がかかる(収束が遅い)。
- ちょうどよい:効率よく谷底へ向かう。
- 大きすぎる:谷を一歩で飛び越えてしまい、振動したり、最悪は損失が発散して上り続けます。
xychart-beta
title "学習率と損失の下がり方(イメージ)"
x-axis "更新回数" 0 --> 10
y-axis "損失" 0 --> 10
line [9, 8.5, 8.1, 7.8, 7.5, 7.3, 7.1, 6.9, 6.8, 6.7]
line [9, 5, 3, 1.8, 1.1, 0.7, 0.5, 0.4, 0.35, 0.3]
line [9, 4, 7, 3, 8, 2, 9, 3, 10, 4]
上の図は、低すぎる学習率(ゆっくり下る線)・適切な学習率(すっと下る線)・高すぎる学習率(振動して下がらない線)のイメージです。
収束する学習率の条件(理論的裏付け)
「大きすぎると発散」をきちんと条件にできます。損失が -平滑(-smooth)、つまり勾配が定数 でリプシッツ連続
を満たすとします( は損失曲面の「曲がりの最大の急さ」の上限。ここでは平滑定数で、サンプル数 とは別物)。このとき、固定学習率が
を満たせば、各ステップで損失が単調に減ることが保証できます。実際、-平滑性から得られる下降補題(descent lemma)
を見ると、 なら右辺第2項の係数 が正になり、勾配が 0 でない限り損失が必ず下がります。逆に が大きすぎる()と係数が負に転じ、損失が増えて発散します。
要するに:適切な学習率の上限は損失曲面の曲がりやすさ で決まる。曲面が急( 大)なら小さく刻め、緩いなら大きく歩ける、ということです。
5. 凸 vs 非凸 — どこに収束するのか
勾配降下が「どこに」たどり着くかは、損失曲面の形(凸か非凸か)で決まります。
- 凸関数(線形回帰の二乗損失・ロジスティック回帰など):谷が1つだけ。局所最適=大域最適なので、勾配降下は大域最適に収束します。安心して回せます。
- 非凸関数(ニューラルネット):谷が多数あり、加えて鞍点(saddle point)——ある方向では谷、別の方向では尾根という、勾配が 0 だが最小ではない点——が大量に存在します。勾配降下はそこに引っかかり得ます。
graph TD
A["損失曲面の形は?"] --> B{"凸か非凸か"}
B -- "凸<br/>(線形/ロジ回帰)" --> C["谷は1つ<br/>→ 大域最適に収束"]
B -- "非凸<br/>(ニューラルネット)" --> D["谷が多数+鞍点<br/>→ 局所最適・鞍点に注意"]
D --> E["SGDのノイズが鞍点脱出に効く"]
SGD のノイズは「バグではなく機能」
ここが SGD の面白いところです。バッチ GD は真の勾配を使うので、鞍点(勾配がきれいに 0)に来るとぴたりと止まって動けなくなることがあります。一方 SGD はミニバッチごとに勾配が揺れるため、鞍点でもノイズに押されて脱出しやすい。高次元の非凸最適化では「悪い局所最適より鞍点のほうが圧倒的に多い」ことが知られており、この脱出能力は実務的に重要です。
さらに、SGD のノイズは平坦(flat)な谷を選ぶ傾向があり、平坦な谷の解はテストデータでも崩れにくい(汎化が良い)と経験的に観測されています。つまり SGD のノイズは「最適化を雑にする欠点」ではなく、鞍点脱出と汎化を助ける機能として働きます(理論的な決着はまだ研究途上で、要最新確認)。
6. 収束率と学習率スケジュール
「どれくらいの速さで谷に近づくか」を収束率で測れます。凸性の強さで速さが変わります。
- 凸 + -平滑:固定学習率 で 。 まで近づくのに ステップ。これを劣線形(sublinear)収束と呼びます。
- 強凸 + -平滑:谷が下から二次関数で押さえられるほどしっかり凸(強凸パラメータ )なら、()の線形収束になり、 まで ステップで済む——桁違いに速い。
ここで重要な注意:SGD は固定学習率だと最適点にぴたりと収束しません。ミニバッチの勾配ノイズが谷底でも消えないため、最小値のまわりを揺れ続けるからです。これを抑えるには、学習率を時間とともに**減衰(decay)**させます:
序盤は大きく刻んで速く近づき、谷底に来たら歩幅を縮めて揺れを抑える、という戦略です。収束を保証する古典的条件(Robbins–Monro)は かつ 。実務ではこの「適切に歩幅を調整する」発想をさらに洗練させた適応的手法(モーメンタム・Adam)を使うのが普通で、それは モーメンタムとAdam系最適化 で扱います。
7. ⚠️ よくある誤解・落とし穴
- 「学習率は1個の値を決め打てばいい」ではない:最適な は問題・モデル・データのスケールで変わります。対数スケール()で複数試すのが定石です。
- 特徴量のスケーリングを忘れる:特徴ごとにスケールが違うと損失曲面が細長い谷になり、勾配降下が谷に沿ってジグザグして遅くなります。標準化(平均0・分散1)で曲面を丸くすると劇的に速くなります。これは線形回帰の正規方程式では起きない、反復解法だからこその注意点です。
- 「局所最適に必ずハマるから深層学習はダメ」は古い直観:高次元では悪い局所最適は稀で、実際の難所は鞍点や平坦領域です。SGD はそこをそこそこうまく抜けます。
- 「バッチサイズは大きいほど良い」ではない:大きいバッチはノイズが減って1ステップは安定しますが、鞍点脱出力や汎化に効くノイズも消え、テスト性能が落ちる「ジェネラリゼーションギャップ」が報告されています。むやみに大きくしないこと(要最新確認)。
- 損失が下がらない=バグとは限らない:学習率が大きすぎて振動しているだけのことが多い。まず を下げて切り分けます。
8. まとめ
勾配降下法は「損失の勾配を計算し、その逆向きに学習率ぶん歩く」を繰り返すだけの素朴な手法ですが、(1) 一次テイラー展開が最急降下方向を保証し、(2) が収束を保証し、(3) バッチ/SGD/ミニバッチの選択がコストとノイズを調整し、(4) 凸なら大域最適・非凸ではノイズが鞍点脱出を助ける——という形で、機械学習のほぼ全モデルの学習エンジンになっています。次はこの素朴な更新を加速する モーメンタムとAdam系最適化 へ進みます。
対応するシミュレーション
simulations/gradient_descent.py:細長い谷をもつ二次関数 に勾配降下を適用し、学習率を3通り(小さすぎ ・適切 ・大きすぎ )で比較します。等高線上の更新の軌跡と損失曲線(対数軸)から、学習率が小さいと収束が遅く、適切だと指数的に速く減り、安定限界 を超えると振動・発散することを確認できます。
関連ノート
- 最適化と学習理論 目次 — このドメインの位置づけ
- モーメンタムとAdam系最適化 — 勾配降下を加速・適応化する次のステップ
- 凸最適化の基礎 — 凸性・収束理論の土台
- 学習問題の定式化(仮説・損失・経験リスク) — 経験リスク最小化(ERM)という出発点
- 線形回帰(最小二乗法と確率的解釈) — 勾配を使わず解析的に解ける最適化の原型
- ニューラルネットワーク 目次 — この最適化が深層学習の学習エンジンになる
- 機械学習テキスト 全体目次