🎓 レベル:標準 | 重要度:A(必須)
📎 前提:勾配降下法
要点(BLUF)
- 素のSGDは「谷(細長い損失曲面)」で振動して遅くなります。モーメンタムは過去の勾配を指数移動平均した速度で慣性を持たせ、振動を打ち消して加速します。
- 適応的学習率(AdaGrad → RMSProp)は座標ごとに学習率を自動調整します。勾配が大きい方向は控えめに、小さい方向は大胆に動きます。
- Adam はモーメンタム(1次モーメント )と RMSProp(2次モーメント )を合体し、初期の0バイアスを補正したもの。実務のデファルト。重み減衰を切り離した AdamW が現在の標準です(要最新確認)。
1. なぜ素のSGDでは不十分か
勾配降下法 の更新 は、損失曲面が「等方的(どの方向も同じ曲率)」なら素直に底へ向かいます。問題は病的な曲率(ill-conditioning)、つまり方向によって曲率が極端に違う細長い谷です。
イメージは、左右の壁が急で前後がゆるやかな峡谷です。勾配は最も急な「壁を登る/降りる方向(左右)」を強く指すので、SGDは谷底に沿って進みたいのに壁を左右にジグザグ反射してしまい、本当に進みたい谷の方向(前後)にはなかなか進みません。
これを定量化するのが 条件数 です(損失をヘッセ行列 で2次近似したときの固有値の最大/最小比)。
- 固有値が大きい方向(曲率が急=壁):少し動くだけで損失が大きく変わる
- 固有値が小さい方向(曲率がゆるい=谷底):動いても損失があまり減らない
要するに:学習率 は「最も急な方向で発散しない」上限に縛られるのに、進みたいのは「最もゆるい方向」。 が大きい(曲率の差が激しい)ほど、両者の板挟みで収束が遅くなります。素のSGDの最大の弱点はこれです。
graph LR SGD["素のSGD(θ ← θ − η∇L)"] MOM["モーメンタム(速度で慣性)"] NAG["Nesterov(先読み勾配)"] ADAG["AdaGrad(座標ごと適応)"] RMS["RMSProp(指数移動平均で枯れ回避)"] ADAM["Adam(モーメンタム+RMSProp+バイアス補正)"] ADAMW["AdamW(重み減衰を切り離し)"] SGD --> MOM MOM --> NAG SGD --> ADAG ADAG --> RMS MOM --> ADAM RMS --> ADAM ADAM --> ADAMW
ここから「振動を抑える方向(モーメンタム系)」と「座標ごとに学習率を変える方向(適応系)」の2系統に分かれ、最終的に Adam で合流します。
2. モーメンタム(Momentum)
過去の勾配を蓄えた速度 を導入し、それで更新します:
はモーメンタム係数(典型的に )。 から始めます。
漸化式を展開すると、速度は**過去の勾配の指数移動平均(EMA)**だとわかります:
古い勾配ほど で軽く重み付けされます。要するに:「これまで進んできた方向」をボールの慣性のように引き継ぎます。
なぜ振動が消えるのかが本質です。谷の壁方向では、勾配が一歩ごとに符号反転(右→左→右…)するので、和を取ると正負が打ち消し合って速度が小さくなります。逆に谷底方向では勾配が毎回同じ符号なので足し合わさって速度が育ちます。結果、ジグザグは抑制され、進みたい方向は加速されます。
実効ステップの上限も直観的です。同符号の勾配 が続くと速度は等比級数で
に収束します。 なら 、つまり実質10倍の歩幅でゆるい方向を進めるイメージです。
が大きいほど加速は強いが慣性で行き過ぎ(オーバーシュート)やすい。 で素のSGDに戻ります。
3. Nesterov加速勾配(NAG)
モーメンタムの改良で、勾配を「先読み位置」で評価します。
通常のモーメンタムは「今いる場所 」で勾配を測ってから速度を足します。Nesterov は「速度の分だけ先に進んだ場所 」で勾配を測ります:
要するに:「どうせ慣性でそこまで進むのだから、進んだ先で勾配を測ろう」という先読み(lookahead)です。
利点はブレーキの早さです。谷底に近づいて行き過ぎそうなとき、通常モーメンタムは現在地で勾配を測るので反応が一歩遅れますが、Nesterov は「進んだ先」で坂の登り返しを先に感じ取り、早めに減速します。理論的にも、滑らかな凸関数で素の勾配法の収束レート を に改善する加速法として知られます(ただし確率的・非凸な深層学習で常に効くとは限らない)。
4. AdaGrad
ここから「座標ごとに学習率を変える」適応系です。AdaGrad は各パラメータごとに、過去の勾配の二乗を累積し、その平方根で学習率を割ります。
座標 について、勾配を とすると:
( 程度)はゼロ割防止。 は座標ごとに別々に貯まります。
要するに:「これまでよく動いた(勾配が大きかった)方向は学習率を下げ、あまり動いていない方向は学習率を保つ」。これにより座標ごとに歩幅を自動調整し、ill-conditioning にも素のSGDより強くなります。
最大の長所は疎な特徴に強いこと。NLP のように、ほとんどゼロでたまにしか出ない特徴(レア単語)は がなかなか増えないので学習率が高く保たれ、出現したときにしっかり学習できます。頻出特徴は逆に抑えられます。
⚠️ ただし致命的な弱点があります。 は二乗和なので単調増加し、決して減りません。学習が進むほど分母 が膨らみ続け、実効学習率がゼロへ向かって枯れる(学習が止まる)。深層学習のように長く回す問題では、底に着く前に動けなくなります。
5. RMSProp
AdaGrad の「枯れ」を、累積を指数移動平均(EMA)に変えるだけで解決します。和ではなく「直近の勾配二乗の平均」にします:
(典型的に や )は減衰率。
要するに:AdaGrad が「学習開始からの全履歴」を貯めるのに対し、RMSProp は「最近どれくらい勾配が大きいか」だけを見ます。古い情報を で忘れていくので は青天井に増えず、実効学習率が枯れません。曲率が変化する非定常な損失曲面(深層学習はまさにこれ)に適応し続けられます。
6. Adam(Adaptive Moment Estimation)
モーメンタム(1次モーメント)と RMSProp(2次モーメント)の合体に、後述のバイアス補正を加えたものです。現在の深層学習で最も使われるデフォルト。
2つのEMAを座標ごとに持ちます。 は勾配そのものの平均(向き=モーメンタム)、 は勾配二乗の平均(スケール=RMSProp):
ここで は要素ごとの二乗。デフォルトは 、学習率 前後です。
バイアス補正
から始めるため、学習初期の はゼロ側に偏ります(まだ履歴が貯まっていないので過小評価)。これを補正します:
なぜ で割るのかを導出で示します。勾配が定常(期待値 が一定)と仮定し、 を展開すると:
両辺の期待値を取り、 を係数の外に出すと、等比和 より:
つまり は真の2次モーメントを 倍に過小評価しています。だから で割れば不偏に戻ります。 も同様です。
要するに:「履歴がまだ薄い初期だけ、薄まった分を割り戻して水増しする」補正です。 が大きくなると なので 、補正は自然に消えます。これが無いと初手の更新が極端に小さくなり、立ち上がりが遅れます。
Adam の更新式
補正済みモーメントで更新します:
分子 が「どっちへ進むか(モーメンタムで均された向き)」、分母 が「どれくらいの歩幅か(座標ごとのスケール調整)」。向きと歩幅を別々に、座標ごとに自動制御するのが Adam の正体です。 は次元的に無次元に近く、初期の実効ステップが概ね のオーダーに収まる設計です。
7. 使い分けと AdamW(要最新確認)
| 手法 | 強み | 弱み・注意 |
|---|---|---|
| SGD + Momentum | 谷の振動を抑え加速、汎化が良いことが多い | 学習率の手調整が要る |
| AdaGrad | 疎な特徴に強い | 学習率が枯れる(長期学習に不向き) |
| RMSProp | 枯れない適応学習率、RNN等で安定 | モーメンタム成分が無い |
| Adam | 立ち上がりが速くチューニングが楽、デフォルト | 画像分類などで汎化がSGDに劣る報告 |
| AdamW | Adam の汎化問題を緩和、Transformer系の標準 | weight decay の値は別途調整 |
実務の目安:迷ったら Adam(W) で素早く立ち上げ、最終的な汎化を詰めたい画像分類などでは SGD + Momentum をよくチューニングする、という使い分けが定石です。実際、Adam で得た解はSGDより平坦でない(sharpな)極小に落ちやすく、これが汎化差の一因と説明されます(局所幾何の議論で、結論は問題依存・要最新確認)。
L2正則化 と AdamW の違い
これが Adam で特に間違えやすい点です。SGD では「損失にL2ペナルティを足す」ことと「更新時に係数を一定割合で縮める(weight decay)」は数学的に等価ですが、Adam では等価になりません。
理由は Adam が勾配を で割るからです。L2ペナルティ由来の項 を勾配に混ぜ込むと、それも一緒に で割られてしまい、正則化の強さが座標ごとにバラバラになります。具体的には、勾配が小さい(=あまり更新されない)座標ほど分母が小さく 本来は強く効かせたいのに正則化が弱まる、という逆効果が起きます。weight decay は本来「全パラメータに一律に効く縮小」のはずなのに、その一律性が壊れます。
AdamW(Loshchilov & Hutter, 2017)はこれを解決します。weight decay を勾配から切り離し、適応スケールを通さずパラメータへ直接かけます:
第2項 が を通っていないのがポイントです。これで縮小が全パラメータに一律にかかり、学習率と weight decay のチューニングも分離しやすくなります。要するに:「Adam で正則化したいなら、ペナルティを勾配に混ぜず、別ルートで一律に縮める」。Transformer・大規模モデルでは AdamW が事実上の標準です(実装・既定値はフレームワークで差があるため要最新確認)。
⚠️ よくある誤解・落とし穴
- 「モーメンタムの は学習率」ではない: は過去の勾配をどれだけ引き継ぐかの慣性係数。歩幅は が決めます。両者は別物です。
- 「Adam は常にSGDより良い」ではない:収束(訓練損失の下がり方)は速いことが多いが、最終的な汎化は SGD + Momentum に劣る場面があります(特に画像分類)。「速い=良い汎化」ではありません。
- AdaGrad を長時間回すと止まる:分母が単調増加して学習率が枯れるのは仕様。長期学習には RMSProp / Adam を使います。
- バイアス補正を省くと初手が極端に小さい: なので初回は約1000倍に割り戻されます。補正を外すと立ち上がりが大きく鈍ります。
- Adam の
weight_decay引数 ≠ L2正則化:フレームワークによっては Adam の weight decay が「L2をgradに足す実装(旧来)」のことがあり、AdamW とは挙動が違います。正則化を効かせたいなら AdamW を明示的に選ぶのが安全です(要最新確認)。 - は単なるゼロ割防止ではない: を大きめにすると適応性が弱まり挙動がSGD寄りになります。極端な値はチューニング対象になり得ます。
対応するシミュレーション
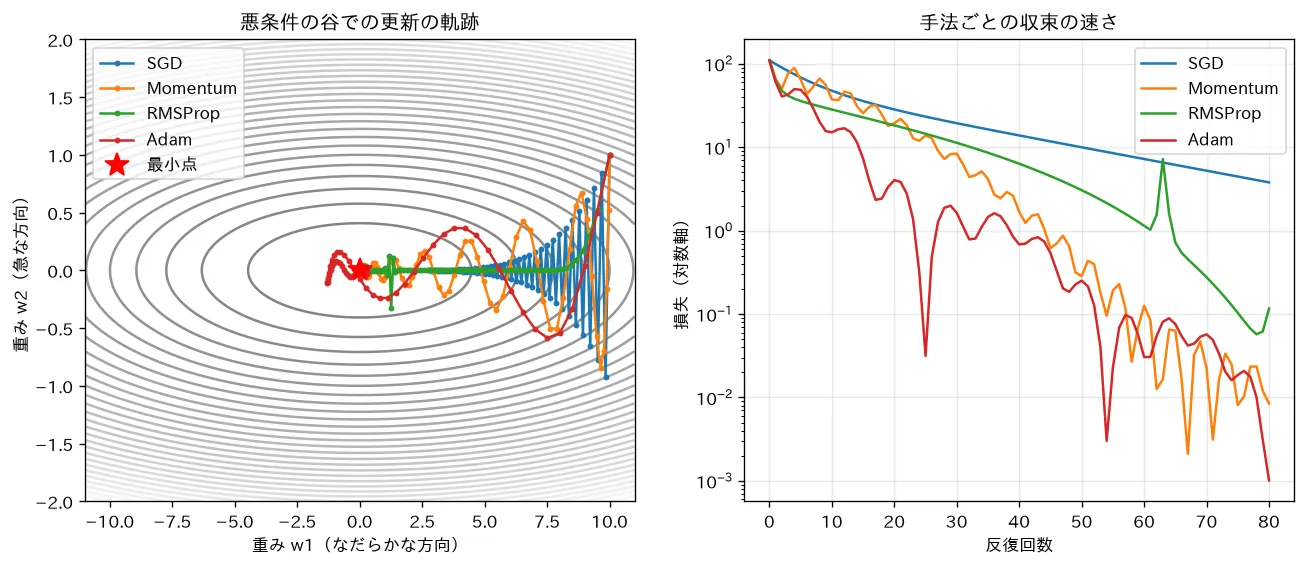
simulations/optimizer_comparison.py:細長い谷(悪条件)の二次関数で SGD・Momentum・RMSProp・Adam を手実装して比較します。素の SGD が急な方向にジグザグして遅いのに対し、Momentum は慣性で加速し、RMSProp は方向ごとに歩幅を調整し、Adam は両者の良いとこ取りで最も速く安定して収束することを、更新の軌跡と損失曲線(対数軸)で確認できます。
関連ノート
- 最適化と学習理論 目次
- 勾配降下法(本ノートの前提。バッチ/ミニバッチ/確率的勾配降下と学習率)
- ハイパーパラメータ最適化(学習率・・weight decay もハイパーパラメータ)
- ニューラルネットワーク 目次(これらの最適化器が実際に使われる場)
- 機械学習テキスト 全体目次
Sources(DeepResearchで参照):
- An overview of gradient descent optimization algorithms (Ruder, arXiv:1609.04747)
- Adam: A Method for Stochastic Optimization (Kingma & Ba, arXiv:1412.6980)
- Decoupled Weight Decay Regularization / AdamW (Loshchilov & Hutter, arXiv:1711.05101)
- Momentum & Nesterov Accelerated Gradient — TensorTonic
- Adam, AdaGrad, RMSprop: Adaptive Learning Rates — TensorTonic
- Intuitive Explanation of Exponential Moving Average — Towards Data Science
- Towards Theoretically Understanding Why SGD Generalizes Better Than ADAM (arXiv:2010.05627)