🎓 レベル:標準 | 重要度:B(標準)
📎 前提:訓練・検証・テストと交差検証(探索は検証データで評価する)
要点(BLUF)
- ハイパーパラメータ最適化(HPO)は「学習では決まらない外側のつまみ(学習率・正則化 ・木の深さ・ など)を、検証性能が最良になるよう自動で選ぶ」探索問題です。中身が見えないブラックボックス関数の最大化として定式化します。
- 手法は探索効率の順に グリッド探索 → ランダム探索 → ベイズ最適化。ランダム探索は「効くつまみが少数のとき格子より当たりやすい」、ベイズ最適化は「代理モデルで関数の形を推定し、獲得関数で次の一点を賢く選ぶ」ことで少ない試行で良い点へ到達します。
- 評価は必ず交差検証で行い(訓練・検証・テストと交差検証)、テストデータは探索に一切使わない。やりすぎると検証セットに過適合するので、過剰チューニングも警戒します。
1. ハイパーパラメータとは — 「学習で決まらない」つまみ
機械学習には2種類の量があります。
| パラメータ | ハイパーパラメータ | |
|---|---|---|
| 何 | モデルの重み( など) | モデル/学習の設定(学習率・・木の深さ・) |
| 誰が決める | データから学習(勾配降下・正規方程式) | 学習の外側で人/探索が指定 |
| いつ決まる | 訓練中 | 訓練を始める前 |
| 例 | 線形回帰の係数 | リッジの正則化強度 、SGD の学習率 、決定木の最大深さ、k-NN の |
要するに:パラメータは「損失を最小化して自動で求まる」中身、ハイパーパラメータは「損失最小化の条件そのものを決める外側のつまみ」です。 を学習で決めようとすると「正則化を消した()方が訓練損失は必ず下がる」ので、訓練データだけでは決められない——だから検証データで別建てに選ぶ必要があります。
2. 最適化問題としての定式化
ハイパーパラメータの組を (学習率・・深さ…をまとめたベクトル)とします。各 に対して、その設定でモデルを訓練し直し、検証性能を測る関数
を最大化したい、というのが HPO です。ここで には厄介な性質があります。
- ブラックボックス: の数式も勾配も分からない(中で1回まるまる訓練が走るだけ)。勾配降下が使えません。
- 高コスト: の1回の評価=モデルを1回フル訓練。深層学習なら数時間〜数日。評価回数をケチりたい。
- ノイジー:データ分割や乱数で同じ でもスコアが揺れる。
要するに:HPO は「勾配なし・評価が高価・少しノイズあり」のブラックボックス最大化。だから「いかに少ない試行で良い に当てるか」が勝負になります。
3. 評価の作法 — 交差検証で測り、テストは触らない
の「検証スコア」は、原則交差検証で測ります(訓練・検証・テストと交差検証)。単一の検証分割だと、たまたまの分割運でスコアが揺れて、運の良い を選んでしまうからです。-fold の平均スコアで評価すれば、その揺れがならされます。
決定的に重要なルール:テストデータは HPO に1度も使わない。
flowchart LR
A["全データ"] --> B["訓練+検証<br/>(HPOに使う)"]
A --> C["テスト<br/>(最後に1回だけ)"]
B --> D["交差検証で f(λ)を評価<br/>→ 最良の λ* を探索"]
D --> E["λ* で全訓練データ再学習"]
E --> F["テストで最終評価<br/>(汚染なしの実力値)"]
C --> F
テストを探索に混ぜると、テストスコアが「実力」ではなく「テストに合わせ込んだ結果」になり、本番性能を楽観的に見積もってしまいます(第8章で詳述)。テストは最後の最後、 を決めきった後に1回だけ触る封印データです。
4. グリッド探索 — 全組合せを総当たり
最も素朴な方法です。各ハイパーパラメータについて候補値のリストを用意し、その**直積(全組合せ)**を一つずつ試します。
- 例:学習率 、、深さ なら 通り。
- 長所:単純・再現性が高い・並列化が容易・「格子の上は確実に全部見た」と言える。
- 短所:次元の呪い。次元(つまみの種類)が 、各軸 点なら試行は で指数増加。つまみ5個×各5点で 回フル訓練——深層学習では非現実的です。
要するに:グリッドは「漏れなく全部見る」安心感と引き換えに、つまみが増えると爆発します。低次元(2〜3個)でなら今でも実用的です。
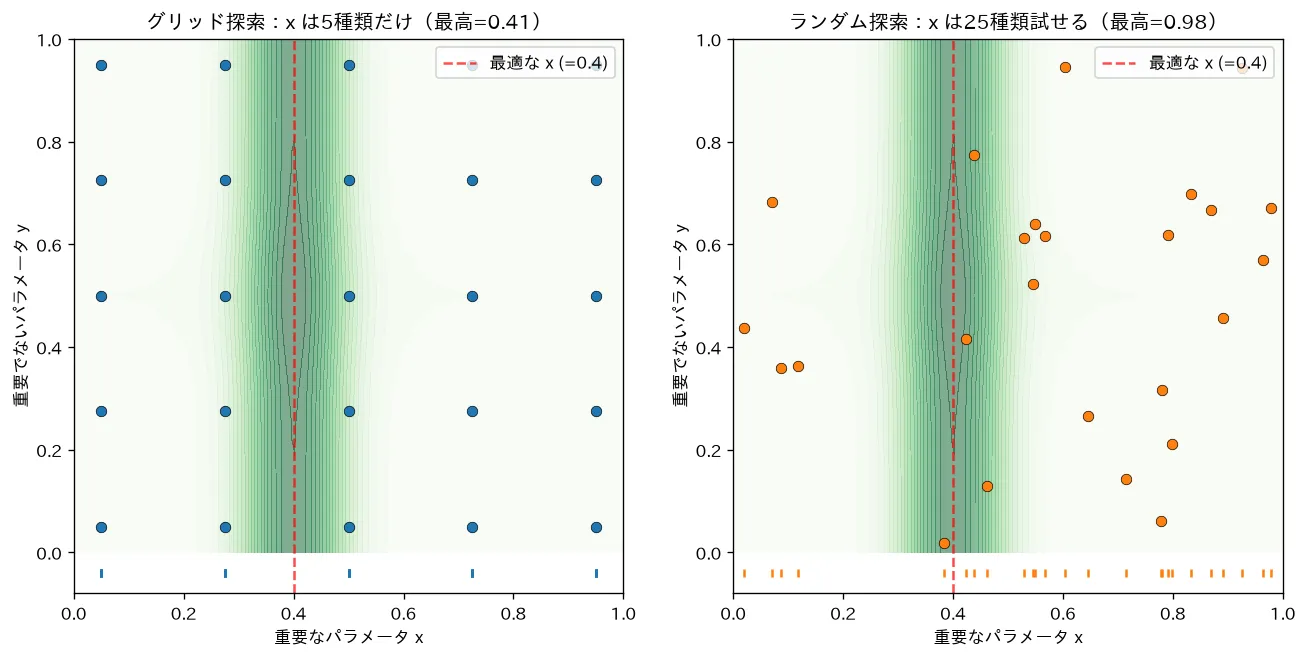
5. ランダム探索 — 同じ予算ならこちらが当たりやすい
各ハイパーパラメータを分布(連続なら一様や対数一様、離散なら候補集合)からランダムに引いて指定回数だけ試します。Bergstra & Bengio(2012)が、同じ試行回数ならランダム探索はグリッド探索と同等以上だと理論・実験で示しました。直観に反しますが理由は明快です。
なぜランダムが効くのか — 「効くつまみは少数」
実問題では、性能に効くつまみはごく一部で、残りはほとんど効かないことが多い(しかも「どれが効くか」は事前に分からない)。
graph TD
A["2つのつまみ・予算9回"] --> B["グリッド:3×3<br/>効く軸(横)は3点しか見ない<br/>残り6回は効かない軸に浪費"]
A --> C["ランダム:9点バラまき<br/>効く軸(横)に9点ぶんの解像度<br/>無駄な軸に格子を割かない"]
B --> D["効く軸の探索解像度=3"]
C --> E["効く軸の探索解像度=9"]
グリッドは「効かない軸」にも律儀に格子点を割り当てるため、9回中3回ぶんしか「効く軸」を動かせません(効く軸の値は3種類だけ)。一方ランダムは9点を投げるので、効く軸については9通りの値を試せます——同じ予算で効く軸の解像度が3倍。次元が増えるほどこの差は開きます。
「60回ルール」(理論的裏付け)
ランダム探索の心強い目安があります。良い設定が探索空間の上位 5% に入っていると仮定すると、1回の試行でそこに当たる確率は 。 回引いて1回も当たらない確率は なので、少なくとも1回当たる確率は
で 。要するに:上位5%の当たり領域があるなら、ランダムに60回投げれば約95%の確率でそこに刺さる。次元数に依存しないのが効く点です(グリッドは次元が増えると同じ網羅に指数回かかる)。
6. ベイズ最適化 — 過去の試行から「次の一点」を賢く選ぶ
グリッドもランダムも過去の結果を次の選択に活かしません(毎回独立に投げるだけ)。ベイズ最適化(Bayesian Optimization, BO)は「これまで試した の履歴から の形を推測し、次に試すと最も得な一点を選ぶ」逐次戦略です。評価が高価な を最小回数で攻めるのに向きます。部品は2つ。
(1) 代理モデル(surrogate)— の形を確率で近似
本物の (フル訓練)は高価なので、安く評価できる代理モデルで「まだ試していない での の予測」を作ります。定番は**ガウス過程(Gaussian Process, GP)**で、各点 について
- 予測平均 :そこの はだいたいこのくらい、という見込み
- 予測分散 :その見込みの自信のなさ(近くに観測がなければ大きい)
を同時に返します。観測点の近くは が小さく、未探索の遠い場所は が大きい——「分かっている所」と「まだ分からない所」を確率で表現できるのが GP の強みです。GP の数理(多変量正規・カーネルによる事後分布)は統計側の話なので深入りはここではしません。
(2) 獲得関数(acquisition function)— どこを次に試すか
代理モデルの と をもとに「次に評価すると最も得な点」を数値化するのが獲得関数 です。これを最大化する点を次の試行に選びます。獲得関数は**活用(exploitation)と探索(exploration)**を1つの式で天秤にかけます。
UCB(Upper Confidence Bound) — 一番分かりやすい形:
第1項 は「今分かっている範囲で良さそうな所」=活用、第2項 は「自信がない=伸びしろがある所」=探索。 がその配合比で、大きいほど探索寄りになります。要するに:「期待値が高い所」か「不確かで化けるかもしれない所」を狙う、という人間の意思決定をそのまま式にしたものです。
EI(Expected Improvement) — 実務で最も使われる獲得関数。現在の最良値 をどれだけ超えられそうかの期待値です。 とおくと( のとき)
ここで は標準正規分布の累積分布関数、 はその密度関数です。第1項は「平均がすでに最良を上回っている度合い(活用)」、第2項は「不確かさが大きく上振れの余地がある度合い(探索)」を表し、両方を自動で勘案します。要するに:EI は「今のベストを更新できる見込み額」を最大化する点を選ぶ——平均が高いだけでも、不確かで上振れしそうでも高くなる、バランスの取れた基準です。
BO のループ
flowchart TD
A["初期点を数個ランダム評価<br/>(f を実測)"] --> B["代理モデル(GP)を当てはめ<br/>各点の μ・σ を得る"]
B --> C["獲得関数 a(λ)=EI / UCB を最大化<br/>→ 次に試す λ を1点選ぶ"]
C --> D["その λ で実際に訓練し f を評価<br/>(高価な1回)"]
D --> E["履歴に追加し GP を更新"]
E --> F{"予算(試行回数)を<br/>使い切ったか?"}
F -- "いいえ" --> C
F -- "はい" --> G["これまでの最良 λ* を返す"]
代理モデルへの当てはめと獲得関数の最大化は安いので、高価な本物の評価 を毎回最も得な1点に絞れます。結果として、グリッド/ランダムより少ない試行回数で良い設定に到達しやすい。代償は逐次的(前の結果を待つ)で並列化しにくいことと、GP が高次元(数十次元超)でスケールしにくいことです。
7. 早期打ち切り系 — 見込みのない設定を早く捨てる(要最新確認)
深層学習では「フル訓練して初めてスコアが分かる」のが重く、有望でない設定にも最後まで計算を払うのが無駄です。Successive Halving(SHA)/ Hyperband / ASHA は「途中経過で見込みの悪い設定を早期に打ち切り、有望なものに計算資源を集中する」多腕バンディット的アプローチです。
- Successive Halving(SHA): 個の設定をまず少ない予算(例:数エポック)で全部回し、上位 (既定 なら上位 1/3)だけを残して、生存組に 倍の予算を与えて再評価——を繰り返す。各段(rung)で約 に絞られ、計算が有望設定に集中します。
- Hyperband:SHA の弱点は「最初の予算 と打ち切りの厳しさのバランス」を決め打ちすること。早すぎる打ち切りは「序盤は遅いが後で伸びる設定」を取りこぼします。Hyperband は初期予算を変えた複数のブラケットで SHA を走らせてこのリスクをヘッジします(最も探索的なブラケットは最小予算で多数を試し、最も保守的なブラケットはほぼフル予算のランダム探索になる)。
- ASHA(Asynchronous SHA):各段の同期を待たず、空いたワーカーから非同期に昇格・打ち切りを進める版。大規模並列環境で計算機を遊ばせず、Hyperband 同等の結果をより効率的に出します。
これらはランダム探索(どの設定を試すか)+早期打ち切り(各設定にどれだけ予算を割くか)の組合せで、ベイズ最適化と組み合わせる実装(BOHB など)もあります。この領域は実装・ライブラリの進化が速いので要最新確認です。
8. ⚠️ よくある誤解・落とし穴
- テスト汚染(最重要):HPO の評価にテストを使うと、テストスコアが「実力」でなく「テストへの合わせ込み」になり本番性能を楽観視します。試したハイパーパラメータの組合せが多いほどこの楽観バイアスは強まる(=モデル選択段階の過学習)。厳密にやるならネスト交差検証(外側=性能評価、内側=HPO)で、汚染なしの実力推定を得ます。
- 探索空間は対数スケールで:学習率や のように桁で効くものを線形一様(例 〜)で引くと、約9割が 〜 に偏り、小さい領域がほぼ探索されません。 上で一様に引く( を取り )と、〜 と 〜 を同じ密度で探せます。「桁で効くつまみは対数スケール」が鉄則です。
- 乱数シードの扱い:ランダム探索やデータ分割のシードを固定しないと結果が再現できません。一方、シードを1個に固定したまま評価すると「その分割でたまたま良い設定」を選びがち。再現性のために記録しつつ、評価は交差検証でならすのが安全です。
- 過剰チューニングによる検証への過適合:同じ検証セットで何百通りも試すと、検証スコアを最大化する設定が「検証セットのノイズに当てた」ものになりがち(多重比較の罠)。検証スコアの僅差を真に受けず、誤差幅(fold 間のばらつき)の範囲なら単純な設定を選ぶのが賢明です。
- 「ベイズ最適化が常に最強」ではない:低次元で予算が潤沢ならグリッドで十分、並列計算機が多いなら独立に投げられるランダム探索や ASHA の方が壁時計時間で速いこともあります。予算・次元・並列度で使い分けます。
- デフォルト値を侮らない:多くのライブラリの既定値は無難に調整済み。まずデフォルト→効きそうな1〜2軸だけ対数スケールで広く振る、が費用対効果の高い順序です。
9. 手法の使い分け(まとめ)
graph TD
A["HPO したい"] --> B{"つまみは何個?"}
B -- "2〜3個・予算潤沢" --> C["グリッド探索<br/>(網羅・再現性)"]
B -- "多い・予算限られる" --> D{"並列計算機は?"}
D -- "多数あり" --> E["ランダム探索 / ASHA<br/>(独立投げ・早期打ち切り)"]
D -- "少ない・評価が高価" --> F["ベイズ最適化(EI/UCB)<br/>(少試行で良点へ)"]
C --> G["効くつまみだけ対数スケールで広く"]
E --> G
F --> G
HPO は「勾配なし・高価・ノイジーなブラックボックス最大化」。グリッドは網羅だが次元で爆発、ランダムは効くつまみが少数のとき同予算で有利(60回ルール)、ベイズ最適化は代理モデル+獲得関数で少試行に強い、Hyperband/ASHA は早期打ち切りで予算を有望設定へ集中。どの手法でも「検証で測る・テストは封印・桁で効く軸は対数スケール」は共通の作法です。
対応するシミュレーション
simulations/grid_vs_random_search.py:性能が実質1つのパラメータ だけで決まる状況で、同じ25回の試行をグリッド探索とランダム探索で行います。グリッドは を5種類しか試せず最適値が格子の隙間に落ちると近づけないのに対し、ランダムは を25通り試せて最適値を引き当てやすいこと(Bergstra & Bengio 2012)を可視化します。さらに賢いのがベイズ最適化。
関連ノート
- 最適化と学習理論 目次 — このドメインの位置づけ
- 訓練・検証・テストと交差検証 — HPO の評価基盤(探索は検証で測る)
- モーメンタムとAdam系最適化 — 学習率もハイパーパラメータ(HPO の主役の一つ)
- 機械学習テキスト 全体目次