🎓 レベル:基礎 | 重要度:A(必須)
📎 前提:汎化と過学習・バイアスバリアンス分解
要点(BLUF)
- データを 訓練・検証・テスト の3つに分けるのは、汎化誤差(未知データでの誤差)を偏りなく見積もるためです。訓練で学び、検証でハイパラを選び、テストは最後に一度だけ使います。
- 検証/テストの情報が訓練に漏れ込む データリーク があると、見かけの性能は良いのに本番で崩れます。前処理を分割前にやる罠が代表例です。
- データが少ないときは1回の分割(ホールドアウト)では当たり外れが大きいので、k分割交差検証で複数回評価して平均します。
1. なぜ分けるのか
学習の目的は訓練データへの当てはめではなく、未知データでの誤差(汎化誤差)を下げることでした(学習問題の定式化(仮説・損失・経験リスク)、汎化と過学習・バイアスバリアンス分解)。ところが、学習に使ったデータでそのまま性能を測ると、モデルは「答えを知っている問題」を解くだけなので、誤差は楽観的に出ます。これは試験勉強で使った問題集をそのまま試験に出すようなもので、本当の実力は測れません。
そこで、データの一部を学習に使わずに取り分け、そこで性能を測ります。役割は3つに分かれます。
| データ | 役割 | 使うタイミング |
|---|---|---|
| 訓練(train) | モデルのパラメータを学習する | 学習中、何度でも |
| 検証(validation) | ハイパーパラメータを選ぶ・モデルを比較する | 開発中、何度でも |
| テスト(test) | 最終的な汎化性能を偏りなく報告する | 最後に一度だけ |
flowchart LR ALL["全データ"] --> TR["訓練(train)"] ALL --> VA["検証(validation)"] ALL --> TE["テスト(test)"] TR --> FIT["パラメータ学習"] VA --> SEL["ハイパラ選択・モデル比較"] TE --> REP["最終性能を1回だけ報告"]
2. パラメータとハイパーパラメータ — 検証が必要な理由
- パラメータ:データから学習で決まる値(回帰係数、ニューラルネットの重みなど)。訓練データで決めます。
- ハイパーパラメータ:学習の前に人が決める設定(正則化の強さ、木の深さ、学習率、多項式の次数など)。これは学習では決まりません。
ハイパーパラメータを「複数試して一番良いものを選ぶ」とき、その選択の良し悪しは何かのデータで測る必要があります。これに訓練データを使うと過学習側に選んでしまい、テストデータを使うと「テストに合わせて選んだ」ことになりテストが汚れます。だから検証データという第3の取り分けが要るのです。
要するに:訓練=モデルの中身を決める、検証=モデルの選び方を決める、テスト=決めたものの実力を測る。3つの役割は混ぜてはいけません。
テストは「一度だけ」が鉄則
テストデータを見て「もう少し調整しよう」と戻ると、人間を経由してテスト情報がモデル選択に漏れます。テストを何度も見るほど、テスト誤差は楽観的になり汎化性能の推定として機能しなくなります。テストは封をして最後に開けるものです。
3. データリーク — 最も多い落とし穴
データリーク(data leakage) とは、検証/テストの情報が訓練側に漏れ込むことです。これがあるとモデルは開発中だけ優秀に見え、本番で崩れます。
典型例1:前処理を分割前にやる
標準化(平均0・分散1にする)や欠損値補完、エンコーディングを分割前に全データで行うと、平均や分散といった統計量にテストデータの情報が混じり、訓練が「テストを少し覗いた」状態になります。
正しい順序は 分割 → 訓練データだけで前処理の基準(平均・分散など)を決める → その基準を検証/テストにも適用 です。
flowchart TB
subgraph BAD["やりがちな誤り"]
B1["全データで標準化"] --> B2["分割"] --> B3["学習・評価"]
end
subgraph GOOD["正しい順序"]
G1["分割"] --> G2["訓練データだけで平均・分散を決定"]
G2 --> G3["同じ基準で検証/テストを変換"]
G3 --> G4["学習・評価"]
end
典型例2:ターゲットリーク
予測時には手に入らないはずの情報が特徴量に紛れ込むケース。たとえば「退院済みフラグ」で「入院中かどうか」を予測すると、答えを言い換えた特徴で当てているだけです。本番では使えません。
典型例3:時間リーク(未来の混入)
時系列データをシャッフルして分割すると、未来のデータで過去を予測する形になり、現実にはありえない好成績が出ます(詳細は第5節)。
要するに:「本番のその瞬間に、本当にその情報を持っているか?」を問えば、多くのリークは防げます。
4. ホールドアウト vs k分割交差検証
ホールドアウト
データを1回だけ訓練/検証(/テスト)に切る方法。シンプルで速いですが、たまたまの分かれ方で評価が大きくブレます。データが少ないほどこのブレは深刻です。
k分割交差検証(k-fold cross-validation)
データを k 個のかたまり(fold) に分け、1つを検証、残り k−1 を訓練にして学習・評価。これを検証する fold を入れ替えて k 回 繰り返し、k 個のスコアを平均します。全データが「ちょうど一度ずつ」検証に回るので、ホールドアウトより安定した推定が得られます。
flowchart LR D["全データを K 個に分割"] -->|"K回繰り返す"| L["毎回1つを検証・残りで訓練"] L --> AVG["K個のスコアを平均"]
k 回分の図(k=5 の例。■=検証、□=訓練):
graph TB R1["1回目: ■ □ □ □ □"] R2["2回目: □ ■ □ □ □"] R3["3回目: □ □ ■ □ □"] R4["4回目: □ □ □ ■ □"] R5["5回目: □ □ □ □ ■"]
k の選び方
k を大きくすると訓練に使えるデータが増えて推定のバイアスは小さくなりますが、各回の訓練セットが互いに似てくるため分散が増え、計算コストも k 倍になります。経験的に k=5 または k=10 が、バイアスと分散・計算量のバランスが良いとされ広く使われます。
注意:交差検証はハイパラ選択やモデル比較のための道具です。最終報告用のテストデータは交差検証とは別に取り分けておくのが安全です(→ 第6節のネスト交差検証)。
5. 特殊な分割:LOO・層化・時系列
LOO(leave-one-out)
k=データ数 n とした極端な交差検証。毎回1サンプルだけを検証に使い、n 回繰り返します。訓練データをほぼ全部使えるのでバイアスは最小ですが、訓練セットがほとんど同じ(1点違うだけ)なので推定の分散が大きく、しかも n 回学習する計算コストが重い。少数データで使われることがあります。
層化 k分割(stratified k-fold)
分類で、各 fold のクラス比率を全体と同じに保つ分割。クラス不均衡のとき、普通のランダム分割だと「ある fold に陽性が1件も入らない」事故が起き、評価が壊れます。層化はこれを防ぎ、各 fold を代表的な構成に保ちます。分類のデフォルトとして推奨されます。
時系列分割(未来を使わない)
時系列データは順序と自己相関に意味があるので、シャッフルしてはいけません。未来で過去を予測する形になり(先読みバイアス)、リークします。代わりに時間順を保ち、過去で訓練 → 未来で検証を前進させます(前進検証 / walk-forward)。
graph TB W1["1回目: 訓練[1..3] → 検証[4]"] W2["2回目: 訓練[1..4] → 検証[5]"] W3["3回目: 訓練[1..5] → 検証[6]"]
要するに:分割の仕方は「本番でどう使うか」を真似る。順序や偏りに意味があるデータでは、ランダム分割が嘘の好成績を生みます。
6. ネストした交差検証
「交差検証でハイパラを選び、同じ交差検証のスコアをそのまま性能として報告する」のは楽観的すぎます。選択に使ったデータで評価しているからです(一種のリーク)。
これを避けるのが ネスト交差検証:
- 内側ループ:ハイパラを選ぶための交差検証(訓練の中だけで完結)
- 外側ループ:選んだモデルの性能を測るための交差検証(内側が触れていない fold で評価)
flowchart TB OUT["外側CV: 性能評価"] --> INNER["各外側foldの中で内側CV: ハイパラ選択"] INNER --> EVAL["選んだ設定を外側の検証foldで評価"] EVAL --> MEAN["外側スコアを平均=偏りの少ない汎化性能"]
要するに:ハイパラ選びと性能評価を別々のデータでやる。これでチューニングによる楽観バイアスを取り除けます。
⚠️ よくある誤解
- テストデータで何度も試して良くなった、は錯覚。テストを見るたびに汚染が進みます。最終チェック以外で開けないこと。
- 「分割前に標準化」は無害ではない。平均・分散にテスト情報が混じる立派なリークです。前処理は必ず分割後、訓練データの基準で。
- 交差検証のスコア=最終性能、ではない。それでハイパラを選んだなら、別のテスト(またはネストCV)で測り直すべきです。
- 分類でランダム分割すると不均衡で壊れる。少数クラスが偏ると評価が不安定。分類は層化を既定に。
- 時系列をシャッフルしてはいけない。未来→過去のリークで非現実的な好成績が出ます。
対応するシミュレーション
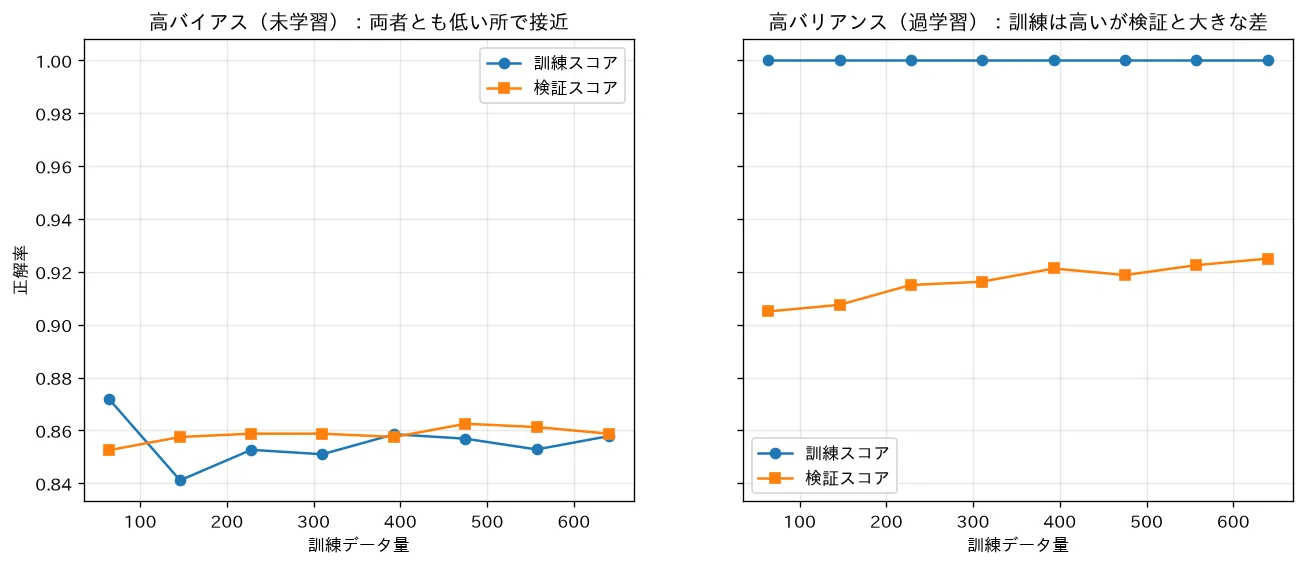
simulations/learning_curve.py:訓練データ量を増やしながら「訓練スコア」と「検証スコア(5分割交差検証)」を描く学習曲線を、高バイアスのモデル(ロジスティック回帰)と高バリアンスのモデル( の k近傍法)で比較します。高バイアスは両者が低い所で接近、高バリアンスは訓練が高く検証と大きな差、という形の違いから「データを増やすべきかモデルを変えるべきか」を診断できることを示します。