🎓 レベル:標準 | 重要度:A(必須)
📎 前提:学習問題の定式化(仮説・損失・経験リスク) | 数理:点推定(推定量の良さ:不偏性・一致性・有効性・十分性)(統計・推定量のMSE分解)
要点(BLUF)
- 汎化誤差(未知データでの期待二乗誤差)は 既約誤差 + バイアス² + バリアンス に厳密に分解できます。
- バイアス=モデルが単純すぎて真の関係を捉えきれないズレ、バリアンス=訓練データの違いで予測が暴れる度合い。
- モデルを複雑にするとバイアスは減りバリアンスは増える。両者の和が最小になる「ちょうどよい複雑さ」を狙うのが汎化の核心です。
1. 汎化誤差とは
訓練データに当てはめた誤差(訓練誤差)ではなく、まだ見ていないデータでの平均的な誤差を汎化誤差と呼びます(=期待リスク 、学習問題の定式化(仮説・損失・経験リスク))。学習の目的はこれを下げることです。
データが ( は真の関数、 はノイズで )で生成されるとします。訓練データ はランダムなので、そこから学んだ予測器 もランダムです。
2. バイアスバリアンス分解(導出)
固定した点 での、データとモデルのランダム性にわたる期待二乗誤差を考えます:
予測の平均を と置きます。 を代入し、 と が独立・ を使うと、
導出の骨子: と分けて期待値を取ると、交差項がすべて 0 になり(、 の期待値が 0、)、3つの二乗項だけが残ります。
要するに:どんなに頑張っても消せないノイズ に加え、「平均的にズレているか(バイアス)」と「データ次第で暴れるか(バリアンス)」の2つが誤差を作ります。
これは統計の「推定量の平均二乗誤差 = バイアス² + 分散」(→ 点推定(推定量の良さ:不偏性・一致性・有効性・十分性))と同じ構造です。ML では予測誤差に既約ノイズ が加わる点が違いです。
3. 複雑さとの綱引き
- 単純なモデル(例:定数・直線):データが変わっても予測は安定(低バリアンス)だが、真の関係を捉えられない(高バイアス)= 未学習。
- 複雑なモデル(例:高次多項式・深い木):訓練データに密着できる(低バイアス)が、データのノイズに振り回される(高バリアンス)= 過学習。
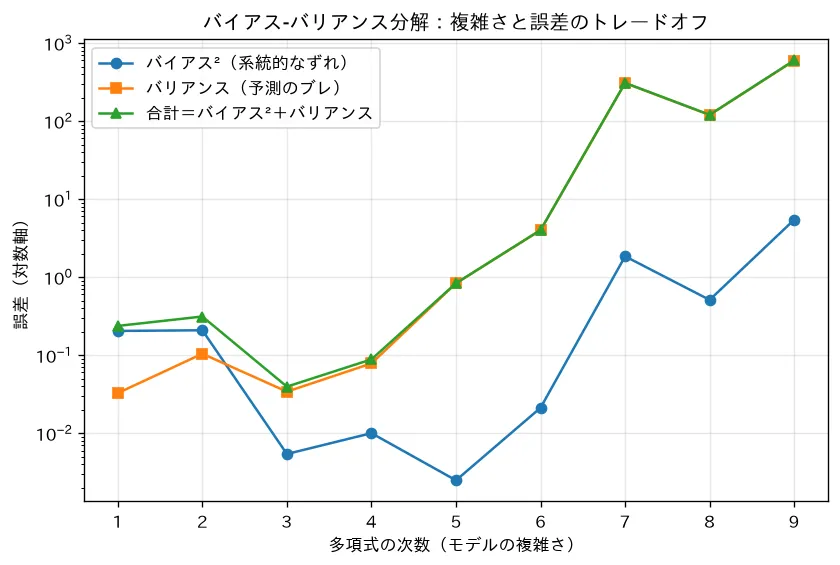
モデルの複雑さを上げていくと、バイアス²は単調に減り、バリアンスは増えるため、汎化誤差は U 字 を描きます。
xychart-beta
title "モデルの複雑さと誤差の分解"
x-axis ["単純", "やや単純", "適度", "やや複雑", "複雑"]
y-axis "誤差" 0 --> 100
line [80, 45, 22, 12, 8]
line [5, 12, 25, 48, 80]
line [85, 57, 47, 60, 88]
上から:バイアス²(右下がり)/バリアンス(右上がり)/総誤差(U字)。U字の谷が「ちょうどよい複雑さ」。
4. どう制御するか
- 複雑さを下げる/正則化する:バリアンスを抑える(→ 正則化(Ridge・Lasso・Elastic Net)、Phase 6)。
- データを増やす:バリアンスは一般に とともに減る。バイアスは減らない。
- アンサンブル:バギングはバリアンスを、ブースティングはバイアスを主に下げる(→ アンサンブルの原理)。
- 検証データで谷を探す:複雑さ(ハイパーパラメータ)は訓練誤差ではなく検証誤差で選ぶ。
対応するシミュレーション
simulations/bias_variance.py:真の関数 にノイズを足した訓練セットを多数生成し、次数の異なる多項式回帰を学習して、テスト点ごとにバイアス²・バリアンス・総誤差を数値分解します。次数を上げるとバイアスは下がるがバリアンスが急増し、合計(汎化誤差)が次数3あたりを底とする U 字を描くことを、誤差対次数のグラフ(対数軸)で再現します。
⚠️ よくある誤解
- 「訓練誤差が下がり続ける=良い」ではない。訓練誤差は複雑さとともに単調に下がるが、汎化誤差は U 字。見るべきは検証誤差。
- バイアスとバリアンスは同時に下げにくい(トレードオフ)。ただしデータ増加や良い特徴量で両方改善することもある。
- 深層学習の二重降下:非常に過剰なパラメータ領域では古典的 U 字の先で再び誤差が下がる現象(double descent)が知られる。古典論の例外として「要最新確認」。