🎓 レベル:標準 | 重要度:A(必須)
📎 前提:決定木(束ねる部品) | 土台:汎化と過学習・バイアスバリアンス分解
要点(BLUF)
- アンサンブル学習は、1つでは弱い学習器(weak learner)を多数束ねて、単体より高精度かつ安定にする枠組みです。多数決や平均で予測をまとめます。
- 効く理由は数理で説明できます。多数決は「誤り率が 0.5 未満の独立な判定を集めると全体の誤り率が下がる」(コンドルセの陪審定理)。平均は「多数の予測を平均するとバリアンスが下がる」。どちらも誤りが相関していないこと(多様性)が源泉です。
- 整理の軸は 汎化と過学習・バイアスバリアンス分解。バギング系はバリアンスを下げ、ブースティング系はバイアスを下げる。同じ「束ねる」でも削る相手が逆です。
1. アンサンブルとは
アンサンブル(ensemble)は「合奏団」の意味で、複数のモデルを協調させて1つの予測を作る手法の総称です。個々のモデルを 弱学習器(weak learner)/基学習器(base learner) と呼びます。「弱い」とは、単体では精度がそこそこ(場合によってはランダムよりわずかに良い程度)という意味です。
flowchart LR
Data["訓練データ"] --> M1["弱学習器 1"]
Data --> M2["弱学習器 2"]
Data --> M3["弱学習器 3"]
Data --> Mdots["…"]
Data --> MM["弱学習器 M"]
M1 --> Agg["集約(多数決 / 平均)"]
M2 --> Agg
M3 --> Agg
Mdots --> Agg
MM --> Agg
Agg --> Pred["最終予測"]
直感的には「1人の専門家より、多少クセのある複数人の合議のほうが当たる」という話です。ただしただ束ねれば良いわけではありません。後で見るように、効果が出るには「メンバーがそれぞれ違う間違い方をする(多様性がある)」ことが不可欠です。同じ間違いをする人を100人集めても合議の意味がありません。
要するに:アンサンブルは「弱い部品を束ねて強い予測器を作る」枠組みで、効くかどうかは部品どうしの誤りが相関していないかにかかっています。
2. なぜ束ねると効くのか(その1:多数決の数理)
まず分類を考えます。「誤り率がそこそこ低い判定器を多数決すると、全体の誤り率はさらに下がる」ことが、コンドルセの陪審定理(Condorcet’s jury theorem, 1785) で保証されます。もとは投票の理論ですが、機械学習のアンサンブルにそのまま当てはまります。
設定と主張
個( は奇数とします)の二値判定器があり、それぞれが
- 独立に判定する
- 正解率 (誤り率 )は全員共通
とします。最終判定は単純多数決。このとき多数決が正しい確率 は、過半数 人以上が正解する確率なので、二項分布で
と書けます。コンドルセの定理が言うのは次の2点です。
- なら、 を増やすほど は単調に上がり、 で 1 に近づく
- なら逆に で 0 に近づく(下手な判定を多数決すると全滅する)
要するに:個々が「ランダムよりほんの少しでも良い()」なら、多数決で限りなく正解に近づけます。これがブースティングで「ランダムよりわずかに良いだけの弱学習器」を束ねて強くできる理論的根拠です。逆に の学習器を素直に多数決するのは有害です。
数値で見る
正解率 (ランダムよりわずかに良い)の判定器を多数決したときの全体の正解率は、 を増やすとはっきり上がります。
xychart-beta
title "多数決の正解率(個々の正解率 p=0.6)"
x-axis "判定器の数 M" [1, 5, 11, 21, 51, 101]
y-axis "多数決の正解率" 0.5 --> 1.0
line [0.60, 0.68, 0.75, 0.83, 0.93, 0.98]
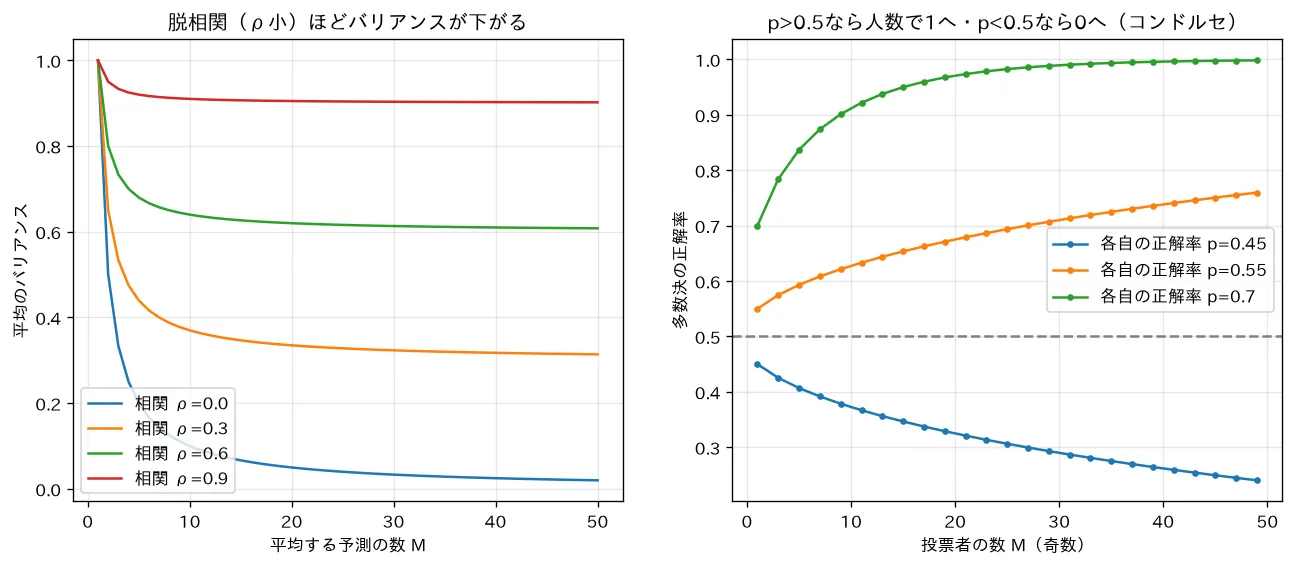
の単体が、101個束ねると正解率 0.98 まで上がります。ただしこれは「独立」という強い仮定の下の話です。現実の学習器は同じデータから作るので誤りが相関し、ここまで理想的には上がりません(だから次節の脱相関が鍵になります)。
flowchart TB
P{"個々の正解率 p"}
P -->|"p > 0.5(competent)"| Up["M を増やすと正解率 → 1<br/>束ねるほど良くなる"]
P -->|"p = 0.5(ランダム)"| Flat["束ねても 0.5 のまま<br/>情報がない"]
P -->|"p < 0.5"| Down["M を増やすと正解率 → 0<br/>束ねると悪化"]
3. なぜ束ねると効くのか(その2:平均によるバリアンス低減)
次に回帰(あるいは確率の平均) を考えます。こちらは 汎化と過学習・バイアスバリアンス分解 のバリアンスに直接効きます。結論を先に書くと、予測を平均すると、それぞれが相関していない分だけバリアンスが下がる、です。
独立な場合:1/M に下がる
個の予測 があり、それぞれ同じバリアンス を持つとします。これらを単純平均した予測 のバリアンスを考えます。
まず各予測が互いに独立なら、分散の加法性(独立なら和の分散=分散の和)から
要するに:独立な予測を 個平均すると、バリアンスは 倍まで下がります。10個平均すれば 1/10。バイアス(平均が真値からどれだけずれるか)は平均しても変わらないので、バイアスはそのまま、バリアンスだけ削れるわけです。
現実:相関があると下げ止まる
ところが現実の学習器は同じ訓練データから作るので、予測どうしは正の相関を持ちます。各ペアの相関係数を (、共通のバリアンスは )とすると、平均のバリアンスは次のようになります。
導出は分散の展開から出ます。 で、対角項が 個の 、非対角項が 個の 。よって
これを整理すると上式()に一致します。
ここで の極限を取ると、第2項は消えて
要するに:いくら学習器を増やしても、バリアンスは で下げ止まる。第1項 は に依存しないからです。 を増やして消せるのは「平均できる部分(第2項)」だけで、相関 そのものが下限を決めます。
xychart-beta
title "平均後のバリアンス(σ²=1, 相関 ρ 別)"
x-axis "学習器の数 M" [1, 2, 5, 10, 20, 50, 100]
y-axis "Var(平均予測)" 0 --> 1.0
line [1.0, 0.55, 0.28, 0.19, 0.145, 0.118, 0.109]
line [1.0, 0.5, 0.2, 0.1, 0.05, 0.02, 0.01]
上の線が (下限 0.1 で頭打ち)、下の線が (独立なので でゼロへ)。相関が残ると、いくら木を増やしても 0.1 より下げられないことが見て取れます。
だから「脱相関」が鍵
この式が、アンサンブル設計の最重要メッセージを与えます。
- を増やす効果(第2項 )には頭打ちがある
- 本質的に効くのは相関 を下げること(第1項 を小さくする)
graph TB
Goal["平均後バリアンスを下げたい"]
Goal --> A["M を増やす<br/>(第2項を削る)"]
Goal --> B["ρ を下げる = 脱相関<br/>(第1項の下限を下げる)"]
A --> A1["頭打ちあり<br/>ρσ² より下げられない"]
B --> B1["下限そのものを引き下げる<br/>本質的に効く"]
ランダムフォレストが「ブートストラップ標本」だけでなく特徴のランダム部分集合まで使って木をバラけさせるのは、まさにこの を下げるためです(バギングとランダムフォレスト)。
4. 多様性(diversity)こそ源泉
ここまでの2つの数理は同じことを別の角度から言っています。
| 視点 | 効果の源泉 | 同じ誤りをすると |
|---|---|---|
| 多数決(コンドルセ) | 判定が独立であること | 過半数が同時に誤り、多数決が外す |
| 平均(バリアンス低減) | 相関 が小さいこと | 第1項 が大きく、下げ止まる |
どちらも結論は 「メンバーの誤りが相関していないこと(多様性, diversity)」が効果を生む、です。逆に言えば、まったく同じ学習器をコピーして束ねても無意味( なら で単体と同じ)。多様性を作る代表的な仕掛けは次のとおりです。
graph LR
Div["多様性を作る仕掛け"]
Div --> D1["データを変える<br/>(ブートストラップ標本)"]
Div --> D2["特徴を変える<br/>(ランダム部分集合)"]
Div --> D3["モデル種類を変える<br/>(スタッキング)"]
Div --> D4["重みを変えて順に作る<br/>(ブースティング)"]
ただし多様性と個々の精度はトレードオフになりがちです。バラけさせすぎると個々の学習器が弱くなりすぎ、束ねても精度が出ません。「個々がそこそこ正確で、かつ互いに違う誤りをする」バランスが理想です。なお、この「多様性」を分散・相関の言葉でどこまで厳密に分解できるかは長く研究テーマで、近年は統一的な分解理論も提案されています(A Unified Theory of Diversity in Ensemble Learning, JMLR 2023)。
要するに:アンサンブルの効き目は「束ねる数」より「束ねる相手がどれだけ違う間違いをするか」で決まります。
5. 二本柱:バギング系とブースティング系
束ね方には大きく2つの系統があり、汎化と過学習・バイアスバリアンス分解 のどちら側を削るかで対照的です。
graph TB
Ens["アンサンブルの束ね方"]
Ens --> Bag["バギング系(並列)"]
Ens --> Boost["ブースティング系(逐次)"]
Bag --> BagA["低バイアス・高バリアンスな<br/>強い学習器を独立に学習"]
BagA --> BagB["平均/多数決で<br/>バリアンスを下げる"]
Boost --> BoostA["高バイアスな<br/>弱い学習器を順番に学習"]
BoostA --> BoostB["前の誤りを次が補正し<br/>バイアスを下げる"]
バギング系(並列・バリアンスを下げる)
- 弱学習器を独立・並列に学習し、予測を平均(回帰)または多数決(分類)でまとめる
- 部品には「低バイアス・高バリアンス」な学習器(深い決定木など)を使う。3節の平均化でバリアンスを削るのが狙い
- 代表:バギング(bootstrap aggregating)、ランダムフォレスト(バギングとランダムフォレスト)
- バイアスはほぼ変えず、バリアンスだけ削る
ブースティング系(逐次・バイアスを下げる)
- 弱学習器を順番(逐次) に学習し、前の学習器が間違えたところを次が重点的に直す
- 部品には「高バイアス」な弱い学習器(浅い木・切り株など)を使い、足し合わせで表現力を上げてバイアスを削る
- 代表:AdaBoost(ブースティングとAdaBoost)、勾配ブースティング(XGBoost/LightGBM)
- 主にバイアスを削る(ただしやりすぎるとバリアンスが増えて過学習しうる)
| 観点 | バギング系 | ブースティング系 |
|---|---|---|
| 学習の順序 | 並列(独立) | 逐次(前の結果に依存) |
| 部品の性質 | 低バイアス・高バリアンス | 高バイアス(弱い) |
| 主に削るもの | バリアンス | バイアス |
| 過学習 | しにくい(増やしても安全) | しやすい(反復数の調整が要る) |
| 並列化 | 容易 | 難しい(逐次のため) |
要するに:同じ「アンサンブル」でも、バギングは暴れる学習器を平均でなだめ、ブースティングは鈍い学習器を重ねて鋭くする。バイアス-バリアンス分解のどちら側を攻めているかで覚えるのが一番すっきりします。
⚠️ よくある誤解
- 「学習器を増やせば増やすほど良くなる」わけではない。3節の式のとおり、相関 があるとバリアンスは で下げ止まります。 を増やす効果には頭打ちがあり、本質は を下げること(脱相関)です。
- 「同じモデルをたくさん束ねれば強くなる」は誤り。完全に同じ予測()を平均しても単体と変わりません。違う誤り方(多様性) がなければ効果ゼロです。
- 「アンサンブル=とにかく精度が上がる魔法」ではない。コンドルセの定理は が前提。ランダム未満()の学習器を素直に多数決すると、むしろ悪化します。
- 「バギングもブースティングも同じ”束ねる手法”」と混同しない。削る相手が逆です。バギングはバリアンス、ブースティングはバイアス。部品も「強い木 vs 弱い木」と逆向きに選びます。
- 「ブースティングは過学習しない」は誤り。バイアスを下げる代わりに反復を重ねるほどバリアンスが増えうるので、反復数(木の本数)や学習率の調整が必須です(ブースティングとAdaBoost)。
- 多数決の「独立」仮定は現実には成り立たない。同じデータから作る学習器の誤りは相関するので、コンドルセの理想( で正解率 1)ほどは上がりません。だからこそ多様性を稼ぐ工夫が要ります。
対応するシミュレーション
simulations/ensemble_decorrelation.py:(1) 相関 をもつ 個の予測を平均したときのバリアンス を に対して描き、 が小さい(脱相関した)ほど低い下限まで下げられることを、(2) 各自が確率 で正しい独立な投票者の多数決の正解率が なら人数とともに1へ近づく(コンドルセの陪審定理)ことを可視化します。
関連ノート
- アンサンブル学習 目次
- バギングとランダムフォレスト(バリアンスを下げる:脱相関の実装)
- ブースティングとAdaBoost(バイアスを下げる:逐次補正)
- 決定木(束ねる部品。単体は高バリアンス)
- 汎化と過学習・バイアスバリアンス分解(バギング/ブースティングが削る対象)
- 機械学習テキスト 全体目次