🎓 レベル:標準 | 重要度:A(必須)
📎 前提:決定木・アンサンブルの原理 | 関連:訓練・検証・テストと交差検証(OOB)
要点(BLUF)
- バギング(Bagging) は、元データからブートストラップ標本(復元抽出で作り直したデータ)を何セットも作り、それぞれで学習器を独立に育て、回帰なら平均・分類なら多数決をとる手法です。狙いはバリアンスを下げること(アンサンブルの原理 の「平均すれば散らばりが減る」を具体化したもの)。
- ランダムフォレスト(Random Forest) は、バギングに「各分割で使える特徴をランダムに絞る」を足したものです。これがないと、強い特徴があると全部の木が似てしまい(相関が高い)、平均してもバリアンスが下がりません。特徴を絞ると木どうしが脱相関し、効きます。
- バギングはOOB(Out-of-Bag)誤差という、交差検証なしで汎化性能を測れる仕組みをタダで手に入れられます。約**63.2%のデータで各木を学習し、残り約37%**で評価します。
1. バギング:ブートストラップして平均する
決定木(決定木)の最大の弱点は「不安定」、つまり高バリアンスでした。データがちょっと変わるだけで木の形がガラッと変わります。アンサンブルの原理 で見たとおり、散らばるものは平均すれば散らばりが減る——これを決定木に適用したのがバギングです。
バギングの手順はとてもシンプルです。
flowchart TB
D["元の訓練データ(n件)"]
D --> B1["ブートストラップ標本1<br/>復元抽出でn件"]
D --> B2["ブートストラップ標本2<br/>復元抽出でn件"]
D --> Bdots["..."]
D --> BM["ブートストラップ標本M<br/>復元抽出でn件"]
B1 --> T1["木1を育てる"]
B2 --> T2["木2を育てる"]
Bdots --> Tdots["..."]
BM --> TM["木Mを育てる"]
T1 --> Agg["集約:回帰は平均 / 分類は多数決"]
T2 --> Agg
Tdots --> Agg
TM --> Agg
Agg --> Pred["最終予測"]
ここで ブートストラップ標本 とは、元のデータ( 件)から1件取っては戻し、また取っては戻しを 回くりかえして作った 件のデータです(=復元抽出による再標本化)。同じデータが何度も選ばれることもあれば、一度も選ばれないこともあります。これを セット作り、それぞれで木を1本ずつ育てます。
なぜ平均でバリアンスが下がるのか
回帰を例にします。 番目のブートストラップ標本で育てた木の予測を とすると、バギングの予測は
です。各木の予測が分散 を持つとき、もし木どうしが完全に独立なら 個の平均の分散は
となり、木を増やすほど に近づきます。
要するに:似たような予測を何本も平均すれば、たまたま上振れ・下振れした木が打ち消し合い、予測が安定する(バリアンスが減る)ということです。一方でバイアスはほとんど変わりません(各木が低バイアスなら平均も低バイアスのまま)。だからバギングは「低バイアス・高バリアンス」な決定木と相性が抜群なのです。
⚠️ ただし「完全に独立なら」は理想論です。実際の木どうしは同じ元データから作るので相関します。この相関こそがランダムフォレストの出発点で、3節で正面から扱います。
2. OOB(Out-of-Bag)誤差:タダで手に入る検証
バギングには「おまけ」があります。各ブートストラップ標本には、元データの一部が選ばれずに余るのです。この余り(袋の外=Out-of-Bag)を使うと、別途データを取り分けなくても汎化性能を見積もれます。
約37%が余る理由
データ1件が、 回の復元抽出で一度も選ばれない確率を考えます。1回の抽選で「選ばれない」確率は 。これが 回連続で起きる確率は
です。 は指数関数の定義そのものから来ます。
要するに:データが十分大きいと、各ブートストラップ標本には元データの約 63.2% しか入らず、残り約 36.8% はその木の学習に使われません。この「使われなかった約37%」が、その木にとっての未知データとして使えるわけです。
flowchart LR
D["元データ(n件)"] -->|"復元抽出 n回"| B["ブートストラップ標本<br/>≒ 63.2% が学習に使われる"]
D -->|"選ばれず余る"| OOB["OOBサンプル<br/>≒ 36.8%(その木には未知)"]
OOB --> Eval["その木の予測精度を評価"]
OOB誤差の作り方
各データ点 について、「 を学習に使わなかった木だけ」を集めて予測させ、その集約とラベルを比べます。全データ点でこれを集計したものが OOB誤差 です。
flowchart TB
Start["データ点 i を選ぶ"] --> Find["i が OOB だった木だけ集める"]
Find --> Vote["それらの木で i を予測(平均 / 多数決)"]
Vote --> Comp["真のラベル y_i と比較"]
Comp --> Loop["全データ点で集計 → OOB誤差"]
要するに:OOB誤差は「各点を、その点を見ていない木たちだけで予測した誤差」なので、実質的にホールドアウト検証や交差検証の代わりになります(訓練・検証・テストと交差検証)。 が十分大きければ各点を平均 37% の木で評価でき、K分割交差検証のようにモデルを何度も作り直す必要がないのが利点です。木を1セット育てるだけで検証用スコアまで付いてくる、という効率の良さです。
3. ランダムフォレスト:木を脱相関させる
ここがこのノートの核心です。バギングだけでは不十分で、ランダムフォレストは「各分割で特徴をランダムに絞る」というひと工夫を加えます。なぜそれが必要かは、2節で保留した「木どうしの相関」を式で見ると一目瞭然です。
相関があると平均は効かない(04-01の式の具体化)
アンサンブルの原理 で導いた、相関を含む平均の分散の式を思い出します。各木の分散を 、木どうしのペア相関を とすると、 本の平均の分散は
になります。 の極限で第2項は消え、
が残ります。
要するに:木をいくら増やしても()、バリアンスは ではなく で頭打ちになります。下限を決めているのは木どうしの相関 。 が大きければ、何本平均しても下がりません。だからバリアンスを本気で下げたいなら、 を下げる=木どうしを似させない(脱相関させる) しかないのです。
xychart-beta
title "木の本数Mとアンサンブルのバリアンス(相関ρの効果)"
x-axis "木の本数 M" [1, 10, 50, 100, 300]
y-axis "バリアンス(相対値)" 0 --> 1.0
line "相関 高(ρ=0.6)" [1.0, 0.64, 0.61, 0.61, 0.60]
line "相関 低(ρ=0.1)" [1.0, 0.19, 0.12, 0.11, 0.10]
上のグラフが示すとおり、相関が高い()と木を増やしても約 で止まりますが、脱相関できている()と約 まで下がります。同じ本数でも下がり方がまったく違う、というのが要点です。
なぜ特徴をランダムに絞ると脱相関するのか
バギングの木が相関する元凶は、強い特徴(予測に効く特徴) の存在です。とても効く特徴が1つあると、どのブートストラップ標本で育ててもほぼ全部の木が根のところでその特徴を使って分割します。結果、木の上の方の構造がそっくりになり、予測が相関します( が高い)。
ランダムフォレストはこれを断ち切ります。各ノードの分割を決めるとき、全 個の特徴ではなく、ランダムに選んだ 個()の中からだけ分割を探すのです。
graph TB
Bag["バギング(特徴は全部使える)"] --> Strong["強い特徴を全木が根で使う"]
Strong --> HiCorr["木が似る → 相関ρが高い"]
HiCorr --> NoGain["平均してもρσ²で頭打ち"]
RF["ランダムフォレスト(各分割で m 個に絞る)"] --> Vary["強い特徴が候補に入らない木もある"]
Vary --> Diverse["木の構造がばらける → 相関ρが低い"]
Diverse --> Gain["平均でバリアンスが大きく下がる"]
特徴を絞ると、ある分割では強い特徴が候補に入らず、別の特徴で切らざるをえません。これで木ごとに構造がばらけ、 が下がります。多少バイアスが上がる(各木が最適でない分割を強いられる)代償はありますが、 が下がることでバリアンスが大きく減り、トータルで誤差が改善する——これがランダムフォレストの取引です。
の目安
各分割で見る特徴数 (しばしば mtry と呼ぶ)の経験則は、 を全特徴数として:
| 問題 | 目安 |
|---|---|
| 分類 | |
| 回帰 |
- にすると、特徴の絞り込みがなくなりただのバギングに戻ります。
- を小さくするほど木は脱相関しますが、小さすぎると各木が弱くなりすぎてバイアスが増えます。 前後は、その綱引きのバランスが良い既定値というだけで、検証で調整してよい値です。
要するに:ランダムフォレスト = バギング + 特徴ランダム化。前者でバリアンスを平均で削り、後者で「平均が効くように木を脱相関させる」。2段構えでバリアンスを徹底的に下げます。
4. 特徴量重要度:どの特徴が効いたか
ランダムフォレストは木を何百本も束ねるので1本の木のような可読性は失いますが、どの特徴がどれだけ効いたかを測る手段があります。代表的な2つを押さえます。
(a) 不純度減少ベース(MDI, Mean Decrease in Impurity)
学習中、ある特徴で分割するたびに不純度(ジニ等、決定木 参照)が減ります。その減少量を、その特徴が使われた全分割・全木にわたって合計し、重要度とします。学習時に副産物として計算できるので速いのが利点です。
(b) Permutation Importance(並べ替え重要度)
学習後に、ある特徴の値だけをランダムにシャッフルして壊し、予測精度がどれだけ落ちるかを測ります。落ち幅が大きいほどその特徴は重要、という考え方です(OOBデータや検証データ上で測れる)。
flowchart LR
Trained["学習済みフォレスト"] --> Pick["特徴 j を選ぶ"]
Pick --> Shuffle["特徴 j の列だけシャッフルして関係を破壊"]
Shuffle --> Score["精度の低下幅を測る"]
Score --> Imp["低下が大きい = 特徴 j は重要"]
MDIには偏りがある(重要な注意)
不純度減少ベース(MDI)にはよく知られた偏りがあります:
- 高カーディナリティ(取りうる値の種類が多い)特徴や連続値の特徴を過大評価する。値の種類が多いほど分割の選択肢が増え、たまたま不純度を下げる分割が見つかりやすいため、本当は予測に無関係でも重要度が高く出てしまいます。
- MDIは訓練データ上の統計なので、過学習に使われただけの特徴にも高い値が付くことがあります。
要するに:MDIは速い反面「種類の多い特徴をひいきする」クセがあります。特徴の性質(カーディナリティ)がバラバラなときや、重要度を真剣に解釈したいときは、偏りの小さい permutation importance を併用するのが安全です。
5. 長所と短所
graph TB
RF["ランダムフォレスト"]
RF --> Pros["長所"]
RF --> Cons["短所"]
Pros --> P1["チューニングが楽(既定値で強い)"]
Pros --> P2["過学習に頑健(バリアンスを抑える)"]
Pros --> P3["並列化できる(各木は独立に学習)"]
Pros --> P4["OOBで検証がタダ/特徴量重要度が出る"]
Cons --> C1["解釈性が低い(木1本のようには読めない)"]
Cons --> C2["外挿できない(訓練範囲の外は苦手)"]
Cons --> C3["木が多いとメモリ・推論が重い"]
長所
- チューニングが楽:木の本数 は「多いほど良い(過学習しない方向)」で、 も 前後で十分強いことが多い。神経質な調整なしで高性能が出ます。
- 過学習に頑健:バリアンスを抑える設計なので、決定木1本のような暴れ方をしません。 を増やしてもテスト誤差は悪化せず頭打ちになるだけです。
- 並列化できる:各木は他の木と無関係に学習できるので、計算を並列に回せます(順番に作るブースティングとの大きな違い)。
- おまけが多い:OOB誤差で検証が要らず、特徴量重要度も出せます。
短所
- 解釈性の低下:1本の木は「もし〜なら」と読めましたが、数百本の多数決は人間が直接追えません(だから特徴量重要度のような間接的な解釈に頼ります)。
- 外挿できない:木は葉の平均値を返すだけなので、訓練データの範囲外の入力に対して傾向を伸ばす(外挿する)ことができません。時系列のトレンド予測などには向きません。
- モデルが重い:木が多いとメモリを食い、推論も遅くなりがちです。
要するに:ランダムフォレストは「とりあえず強い」万能寄りのモデル。チューニングと前処理が軽く頑健な一方、可読性と外挿は捨てています。
6. バギング系とブースティング系の違い
ランダムフォレスト(バギング系)と、次章の勾配ブースティング(勾配ブースティング)は、アンサンブルでも狙いと作り方が正反対です。
| 観点 | ランダムフォレスト(バギング) | 勾配ブースティング |
|---|---|---|
| 主に下げるもの | バリアンス | バイアス |
| 木の作り方 | 並列(独立に同時に育てる) | 逐次(前の木の誤りを次が補正) |
| 個々の木 | 深い木(低バイアス・高バリアンス) | 浅い木(高バイアス・低バリアンス) |
| 木を増やすと | 頭打ちになるだけ(過学習しにくい) | 増やしすぎると過学習しうる |
| チューニング | 楽 | 学習率・本数など要調整 |
要するに:ランダムフォレストは「暴れる木をたくさん平均して落ち着かせる(バリアンス退治)」、ブースティングは「弱い木を順に積み上げて賢くする(バイアス退治)」。同じ”木のアンサンブル”でも発想が逆です。詳しくは 勾配ブースティング で扱います。
⚠️ よくある誤解
- 「バギングはバイアスも下げる」わけではない。バギングが下げるのは主にバリアンスで、バイアスはほぼそのまま。バイアスを下げたいならブースティングです(勾配ブースティング)。
- 「木を増やせば増やすほどバリアンスが0に近づく」わけではない。独立ならそうですが、実際の木は相関 を持つので で頭打ちです。だから本数だけでなく**脱相関(特徴ランダム化)**が要るのです。
- 「ランダムフォレスト=ただのバギング」ではない。各分割で特徴を 個に絞る点が決定的な違い。 にすると本当にただのバギングに退化し、木が相関してバリアンスが下がりきりません。
- 「特徴ランダム化で各木が弱くなるのは損」ではない。各木のバイアスは多少上がりますが、その代わり が下がってバリアンスが大きく減り、トータルでは得になるよう設計されています。
- 「特徴量重要度(MDI)の数字をそのまま信じてよい」わけではない。MDIは高カーディナリティ・連続値の特徴を過大評価します。重要度を真面目に解釈するなら permutation importance を併用しましょう。
- 「OOB誤差はテスト誤差より甘い/要らない」わけではない。OOBは各点を”その点を見ていない木”だけで評価するので、実質的に交差検証に近い妥当な汎化推定で、別途の検証分割なしに得られる強みがあります。
- 「ランダムフォレストは外挿もできる」と思いがち。木は葉の平均を返すだけなので訓練範囲外は予測できません。上昇トレンドのある時系列をそのまま当てるような用途は不向きです。
対応するシミュレーション
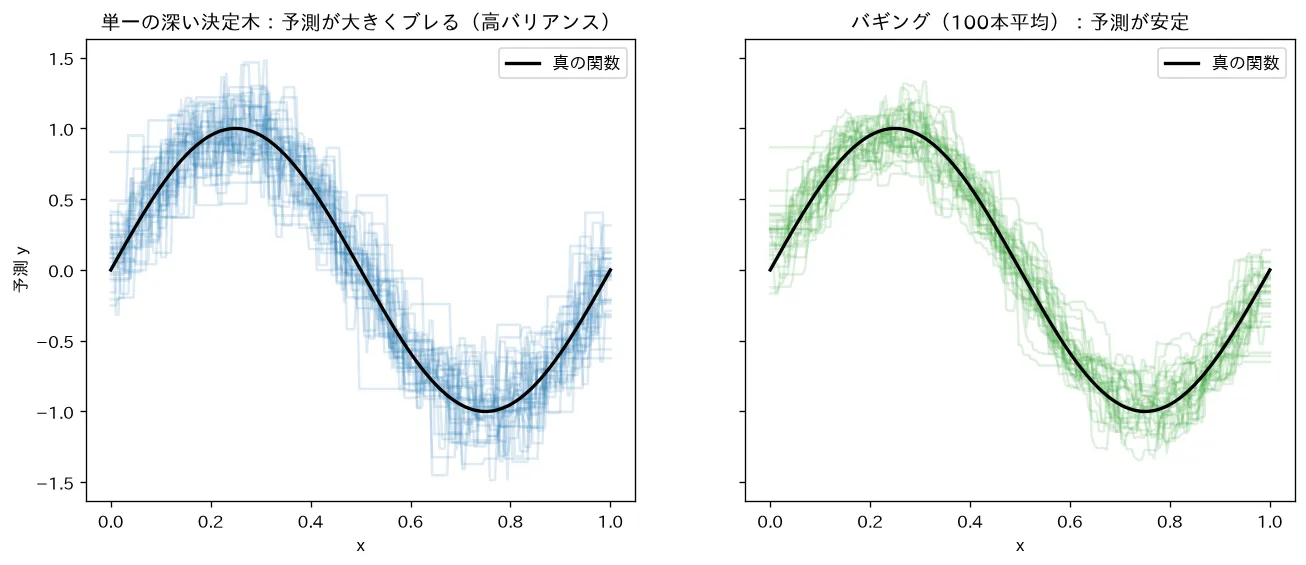
simulations/bagging_variance.py:ノイズのある1次元回帰で、訓練セットを何度も作り直しながら「単一の深い決定木」と「100本のバギング」の予測を重ねて描きます。単一の木は訓練データのわずかな違いで予測曲線が大きくブレる(高バリアンス)のに対し、バギングは木どうしのブレが打ち消し合って予測が安定することを可視化します。バイアスを変えずバリアンスを下げるバギングの効果(アンサンブルの原理 の脱相関)が見て取れます。
関連ノート
- アンサンブル学習 目次
- アンサンブルの原理(平均と相関によるバリアンス低減・ の導出)
- 決定木(束ねる部品としての決定木・高バリアンスの正体・不純度)
- 勾配ブースティング(逐次・バイアス低減型との対比)
- 訓練・検証・テストと交差検証(OOB誤差が代替する検証の枠組み)
- 機械学習テキスト 全体目次