🎓 レベル:標準 | 重要度:A(必須)
📎 前提:ロジスティック回帰・k近傍法(k-NN) | 関連:汎化と過学習・バイアスバリアンス分解
要点(BLUF)
- 決定木は「もし特徴 がしきい値 以上なら…」という if-then の質問を入れ子に重ねてデータを切り分けるモデルです。これは特徴空間を軸に平行な長方形領域へ分割することと同じです。
- 各分割は「不純度をどれだけ減らせるか(情報利得)」で選びます。分類ではジニ不純度・エントロピー、回帰では分散(二乗誤差)を不純度に使います。
- 解釈しやすく前処理も軽い反面、放っておくと過学習しやすく、データが少し変わると木の形がガラッと変わる(高バリアンス)。これを抑えるのが深さ制限・最小サンプル数・剪定で、根本的な対策が次章のアンサンブル(ランダムフォレスト・ブースティング)です。
1. 木による分割の考え方
決定木は、データに対して質問を繰り返してグループを絞り込んでいくモデルです。たとえば「年齢は40歳以上か?」→ Yes なら「年収は500万円以上か?」… と枝分かれを続け、最後にたどり着いた葉(リーフ)でクラスや数値を予測します。
flowchart TB
Root["年齢 >= 40 ?"]
Root -->|"Yes"| N1["年収 >= 500万 ?"]
Root -->|"No"| L1["予測:クラスA"]
N1 -->|"Yes"| L2["予測:クラスB"]
N1 -->|"No"| L3["予測:クラスA"]
この入れ子の if-then は、幾何的には特徴空間を軸に平行な直線で次々に切る操作にあたります。1回の分割は「ある1つの特徴 がしきい値 以上か未満か」なので、境界は必ず座標軸に垂直になります。
graph LR
A["特徴空間(2次元)"] --> B["x1 = t1 で縦に分割"]
B --> C["左側を x2 = t2 で横に分割"]
C --> D["軸平行な長方形領域に分かれる"]
要するに:決定木は特徴空間を長方形のパッチワークに分け、各パッチに一定の予測を割り当てるモデルです。ロジスティック回帰(ロジスティック回帰)の境界が斜めの直線なのに対し、決定木の境界は「階段状」になります。
2. 分割基準:不純度と情報利得
どの特徴・どのしきい値で切るかを決める基準が必要です。考え方は「分割後にできる子ノードが、できるだけ”純粋”(同じクラスばかり)になるように切る」。この「混ざり具合」を測るのが不純度(impurity) です。
ジニ不純度
ノード内のクラス の割合を (全 クラス)とすると、ジニ不純度は
要するに:「そのノードからランダムに1点取り、ランダムなラベルを当てたときに外す確率」。すべて同じクラスなら の項だけ残って (完全に純粋)。クラスが均等に混ざるほど大きくなります(2クラス均等で最大 0.5)。
エントロピー
情報理論の不確かさの尺度をそのまま使います:
要するに:「そのノードのクラスを言い当てるのに平均何ビット必要か」。純粋なら 0、混ざるほど大きい(2クラス均等で最大 1 ビット)。ジニとほぼ同じ挙動をし、実務上どちらを使っても結果は大きく変わりません。
情報利得(分割の良さ)
親ノードを左右の子に分けたとき、不純度がどれだけ減ったかが情報利得(information gain) です。子ノードはサンプル数で重み付けします:
要するに:情報利得は「この分割で混ざり具合をどれだけスッキリさせたか」。木はすべての特徴 × すべてのしきい値の候補を試し、情報利得が最大になる分割を選びます。子のサンプル数で重み付けするのは、「片方に1点だけ追い出して見かけ上純粋にする」ようなズルを防ぐためです。
回帰木:分散減少
予測対象が数値の場合(回帰木)は、不純度をクラスの混ざり具合ではなくばらつき(分散・二乗誤差) で測ります。ノード内の目標値の平均を として
を不純度とし、これを最も減らす分割(分散減少, variance reduction)を選びます。葉での予測は、その葉に落ちたサンプルの平均値になります。
要するに:分類は「ラベルが混ざらないように」、回帰は「数値が散らばらないように」切る。式は違っても「不純度を最大に減らす分割を選ぶ」という原理は同じです。
3. 貪欲な再帰分割
最適な木全体を一気に求めるのは組合せ的に難しい(NP困難)ので、決定木は貪欲法(greedy) で1段ずつ作ります。
flowchart TB
S["全データを根に置く"] --> Q{"停止条件を満たす ?"}
Q -->|"Yes"| Leaf["葉にして予測値を確定"]
Q -->|"No"| Split["情報利得が最大の分割を探す"]
Split --> Apply["左右の子ノードに分ける"]
Apply --> Rec["各子ノードで同じ処理を再帰"]
Rec --> Q
各ノードで「その時点で一番良い分割」を選んで子に分け、子でも同じことを繰り返す(再帰)。停止条件(葉が純粋になった・深さ上限に達した等)を満たしたら葉にします。代表的なアルゴリズムが CART(ジニ・二分木)で、scikit-learn もこれを採用しています。
要するに:貪欲なので「今ベストな1手」を積み重ねるだけで、木全体として最適とは限りません。だからこそ後述の剪定やアンサンブルで弱点を補います。
4. 過学習しやすさと対策
決定木は何も制約しなければ、訓練データを完全に分類できるまで(各葉が1点になるまで)成長できます。これは訓練誤差ゼロですが、ノイズまで丸暗記した典型的な過学習です(汎化と過学習・バイアスバリアンス分解 の高バリアンス側)。
対策は、木を「大きくしすぎない」ことに尽きます。
| 対策 | やること | 効果 |
|---|---|---|
| 深さ制限(max_depth) | 木の高さの上限を決める | 早めに成長を止める |
| 最小サンプル数(min_samples_leaf / split) | 葉やノードに必要な最小データ数 | 細かすぎる分割を禁止 |
| 剪定(pruning) | 一度伸ばしてから枝を刈る | 過剰な枝を後から除去 |
前者2つは成長を事前に止める「事前剪定(pre-pruning)」、最後が伸ばしてから刈る**「事後剪定(post-pruning)」** です。
剪定(pruning)
事後剪定の代表が コスト複雑度剪定(cost-complexity pruning)。一度大きく育てた木に対して、
を最小化します。 は木の誤差、 は葉の数、 は「木の大きさへの罰金」です。
要するに: を上げると「葉を1枚増やすコスト」が高くなり、利得の小さい枝が刈られて木が小さくなります。 は検証データ(または交差検証)で汎化誤差が最小になる値を選びます。事前剪定が「育てる前に止める」のに対し、事後剪定は「全部育ててから無駄を削る」ので、後から効く重要な分割を取りこぼしにくい利点があります。
5. 長所と短所
graph TB
Tree["決定木"]
Tree --> Pros["長所"]
Tree --> Cons["短所"]
Pros --> P1["解釈性が高い(ルールが読める)"]
Pros --> P2["前処理が軽い(スケーリング不要・欠損や混在型に強い)"]
Pros --> P3["非線形・特徴間の相互作用を自動で表現"]
Cons --> C1["過学習しやすい"]
Cons --> C2["不安定(データ変化で木が激変)=高バリアンス"]
Cons --> C3["軸平行な境界しか引けない(斜めが苦手)"]
長所
- 解釈性:「もし〜なら〜」というルールの連なりで、なぜその予測かを人間が追えます。線形回帰のような重み解釈より直感的で、業務説明に向きます。
- 前処理が軽い:分割はしきい値の大小比較だけなので、特徴のスケーリング(標準化)が不要。距離を使う k近傍法(k-NN) がスケールに敏感なのと対照的です。数値とカテゴリの混在にも強い。
- 非線形・相互作用:領域を細かく切るので非線形な関係や「特徴Aが大きく、かつBが小さいとき」のような相互作用を自動で表現します。
短所
- 不安定(高バリアンス):データを少し変えただけで、最初の分割が変われば木全体が別物になります。低バイアス・高バリアンスな学習器の典型です。
- 過学習しやすい:制約なしでは葉が1点まで成長し、ノイズを丸暗記します。
- 境界が階段状:軸平行な分割しかできないので、斜めの境界を表すには細かい階段で近似する必要があり、その分過学習しがちです。
要するに:決定木は「読めるが、暴れる」モデル。1本だと不安定さが致命的なので、これを多数組み合わせて安定させるのが自然な発想です。
6. だからアンサンブルへ
決定木の高バリアンスは、多数の木を組み合わせる(アンサンブル) ことで劇的に改善できます。これが次章 Phase 4 の主題です。
- ランダムフォレスト:少しずつ違うデータ(ブートストラップ標本)と特徴のランダムな部分集合で多数の木を育て、予測を平均(または多数決)します。木どうしを「相関させない(脱相関)」ことでバリアンスを下げるのが要点です。バイアスはほぼそのままに、バリアンスだけ削ります。
- ブースティング(勾配ブースティング等):浅い木を順番に作り、前の木の誤りを次の木が補正していきます。こちらは主にバイアスを下げる方向に効きます。
決定木そのものは「弱いが解釈できる部品」で、その部品を束ねて強い予測器にするのがアンサンブルの考え方です(詳細は Phase 4 のアンサンブル学習の各ノートで扱います)。
⚠️ よくある誤解
- 「決定木は前処理がいらないから万能」ではない。スケーリング不要は本当ですが、過学習しやすさという別の弱点があり、深さ制限や剪定の調整は必須です。
- 「情報利得が大きい=必ず良い分割」ではない。サンプル数で重み付けしないと、片方に少数を追い出す見かけだけ純粋な分割が高評価されてしまいます(だから重み付き不純度で測る)。
- 「ジニとエントロピーは大きく違う」わけではない。挙動はほぼ同じで、結果に大差は出ません。計算が軽いジニが既定値になっていることが多いだけです。
- 「訓練誤差ゼロ=良いモデル」ではない。制約なしの木は訓練データを完全分類できますが、それは過学習で、検証誤差はむしろ悪化します(汎化と過学習・バイアスバリアンス分解)。
- 「1本の木で十分」とは限らない。単体の決定木は不安定(高バリアンス)。本番ではランダムフォレストや勾配ブースティングなどアンサンブルにするのが定石です。
対応するシミュレーション
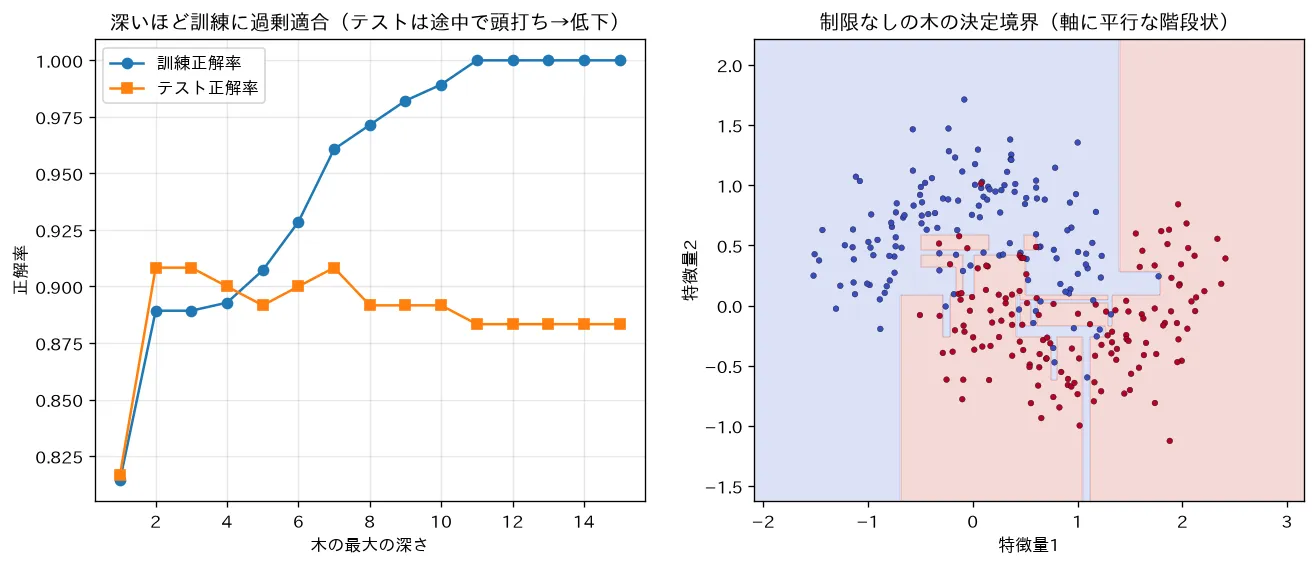
simulations/decision_tree_overfit.py:三日月データで木の最大の深さを から増やしながら訓練・テスト正解率を測り、深いほど訓練正解率は1.0へ張り付くがテストは途中で頭打ち→低下する過学習を可視化します。あわせて制限なしの木の決定境界が必ず軸に平行な階段状になることを示します(斜めの境界が引けない硬さは バギングとランダムフォレスト で補う)。
関連ノート
- 教師あり学習・分類 目次
- ロジスティック回帰(線形な決定境界との対比)
- k近傍法(k-NN)(スケール依存・非線形境界との対比)
- 汎化と過学習・バイアスバリアンス分解(高バリアンス・剪定の意味)
- 機械学習テキスト 全体目次