🎓 レベル:基礎 | 重要度:B(標準)
📎 前提:教師あり学習・分類 目次 | 関連:汎化と過学習・バイアスバリアンス分解・次元の呪い
要点(BLUF)
- k近傍法(k-NN)は「予測したい点に最も近い訓練データを k 個探し、その多数決(回帰なら平均)で答えを決める」という、非常に素直な手法です。
- 訓練フェーズではデータを記憶するだけで何も学習しません。すべての計算を予測時に回す「怠惰学習(lazy learning)」の代表例です。
- 強力さは距離の測り方に全面依存します。特徴量の標準化が必須で、特徴が増えると距離が無意味化する「次元の呪い」に弱いのが最大の弱点です。
1. アルゴリズム:近い k 個の多数決
k-NN の手続きはこれだけです。新しい入力 が来たら、
- 訓練データの全点 との距離 を計算する
- 距離が小さい順に k 個の点(近傍)を選ぶ
- 分類ならその k 個のラベルの多数決、回帰ならその k 個の目的値の平均を予測値とする
数式で書くと、 の近傍集合を (最も近い k 点の添字集合)として、
ここで は条件が成り立てば 1、そうでなければ 0 を返す指示関数です。
要するに:「自分の近所の人たちが多数派で選んだ答えを、自分の答えにする」だけ。明示的なモデル(重みや係数)を一切持ちません。
flowchart LR
A["新しい点 x が来る"] --> B["全訓練点との距離 d(x, xi) を計算"]
B --> C["近い順に k 個を選ぶ"]
C --> D{"タスクは?"}
D -->|"分類"| E["k 個のラベルの多数決"]
D -->|"回帰"| F["k 個の目的値の平均"]
E --> G["予測 ŷ(x)"]
F --> G
重み付き k-NN(距離で重みを付ける)
単純な多数決では k 個の近傍を「全員平等」に扱いますが、改良として近い点ほど大きな重みを与える方法があります。よく使うのは距離の逆数 による加重投票・加重平均で、境界付近での安定性が増します。要するに「近所でも、より近い人の意見を重く見る」自然な拡張です。
2. 怠惰学習(lazy learning):訓練は記憶だけ
線形回帰やロジスティック回帰は、訓練時に係数を推定してモデルを作り、予測時はその式に代入するだけでした(eager learning=勤勉学習)。k-NN はこの逆です。
- 訓練フェーズ:データを保存するだけ。学習コストはほぼゼロ。
- 予測フェーズ:そのつど全訓練点との距離を計算して近傍を探す。ここに全コストが集中する。
このようにモデルを前もって作らず、予測の瞬間にデータを直接参照する方式を怠惰学習(lazy learning)、または訓練事例をそのまま使うことから**事例ベース学習(instance-based learning)**と呼びます。
要するに:k-NN は「勉強せず、テスト本番で教科書を全ページめくって似た問題を探す」タイプ。訓練は速いが本番(予測)が遅い、という珍しい性格です。
graph LR
subgraph LAZY["怠惰学習(k-NN)"]
L1["訓練:データを記憶するだけ"] --> L2["予測:その場で近傍を探索(重い)"]
end
subgraph EAGER["勤勉学習(線形・ロジスティック等)"]
E1["訓練:パラメータを推定(重い)"] --> E2["予測:式に代入するだけ(軽い)"]
end
3. 距離尺度と標準化
k-NN は「近さ」がすべてなので、距離をどう測るかで結果が変わります。連続値の特徴ベクトル に対する代表的な距離は次の2つです。
ユークリッド距離(L2 ノルム):直線距離。差を二乗するため、大きなズレ(外れ値)の影響を強く受けます。
マンハッタン距離(L1 ノルム):各軸方向の移動量の合計(碁盤の目を歩く距離)。二乗しないぶん外れ値に頑健です。
両者はミンコフスキー距離 の (ユークリッド)・(マンハッタン)の特殊ケースです。デフォルトはユークリッド、外れ値やノイズが気になるならマンハッタンが目安です。
なぜ標準化が必須なのか
距離は各特徴の差を足し合わせて作るため、スケールの大きい特徴が距離を支配します。たとえば「年収(単位:円、数百万のオーダー)」と「年齢(単位:歳、数十のオーダー)」を一緒に使うと、距離はほぼ年収だけで決まり、年齢は無視されてしまいます。
そこで各特徴を同じ土俵に乗せる前処理が要ります。
- 標準化(z-score):。平均 0・分散 1 に揃える。
- 正規化(min-max):。0〜1 に収める。
要するに:k-NN にとって標準化は「やった方が良い」ではなく「やらないと壊れる」前処理です。単位の選び方ひとつで答えが変わる手法だからです。
graph TB
A["標準化しないと…"] --> B["スケールの大きい特徴が距離を独占"]
B --> C["他の特徴が無視され近傍がゆがむ"]
D["標準化すると…"] --> E["全特徴が平等に距離へ寄与"]
E --> F["意味のある近傍が選ばれる"]
4. k の選択とバイアスバリアンス
近傍数 k は k-NN 唯一の主要ハイパーパラメータで、バイアスとバリアンスの綱引きを直接コントロールします(→ 汎化と過学習・バイアスバリアンス分解)。
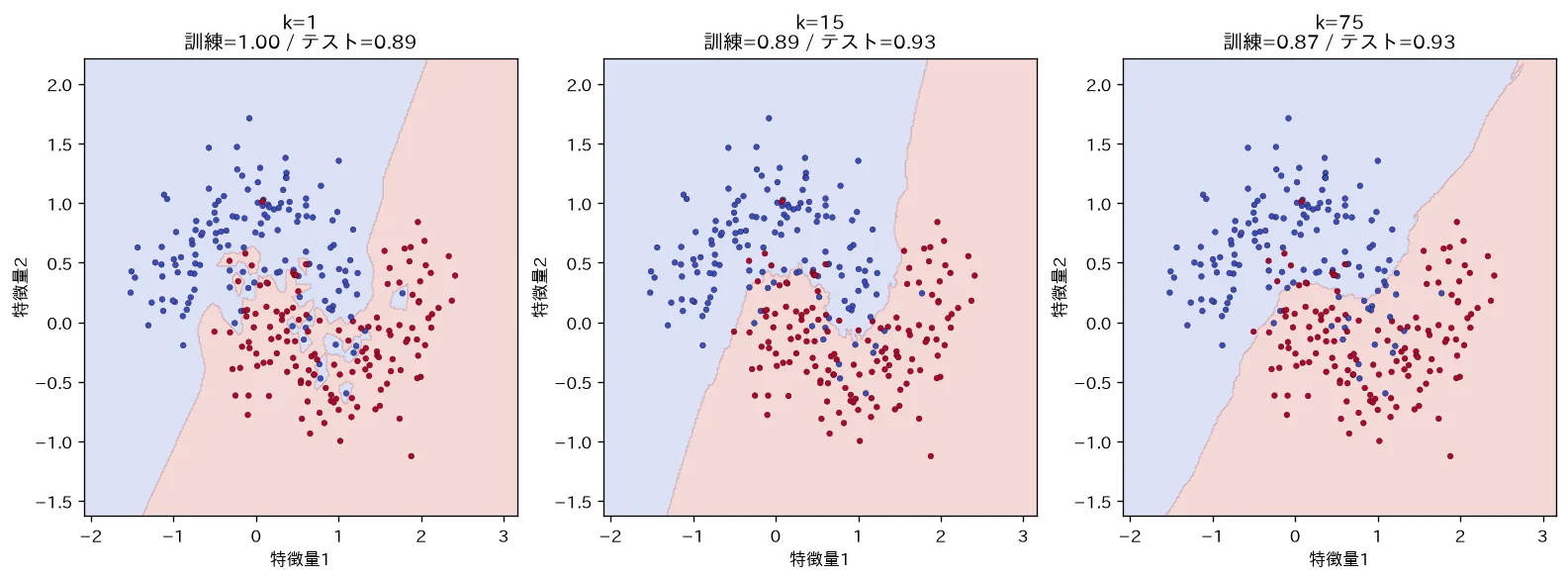
- k が小さい(極端には ):ごく近くの少数の点だけで決めるので、決定境界が非常に細かく入り組みます。ノイズや1点の外れ値に振り回されやすく、訓練データを変えると予測が暴れる。つまり低バイアス・高バリアンス(過学習寄り)。
- k が大きい:広い範囲を平均化するので境界はなめらかになり、安定します。一方、遠くの無関係な点まで投票に加わるため細かい構造を捉えられず、高バイアス・低バリアンス(未学習寄り)。極端に (全データ)なら、どの点でも常に「全体の多数派ラベル」を返すだけになります。
xychart-beta
title "k の大きさと誤差(概念図)"
x-axis ["k=1", "k=5", "k=15", "k=50", "k=n"]
y-axis "誤差" 0 --> 100
line [5, 14, 28, 52, 85]
line [82, 50, 30, 18, 10]
line [80, 40, 33, 47, 88]
上から:バイアス²(k とともに増加)/バリアンス(k とともに減少)/総誤差(U 字)。U 字の谷を与える k を選ぶのが目標です。
最適な k はデータ依存なので、交差検証で選ぶのが定石です(→ 訓練・検証・テストと交差検証)。経験則として から探索を始めることが多く、分類では同数票の引き分けを避けるため奇数の k を使います。
要するに:k は「どれくらい広い近所の意見を聞くか」のつまみ。小さすぎると神経質、大きすぎると鈍感。ちょうどよい所を交差検証で探します。
5. 次元の呪い:高次元で距離が無意味になる
k-NN の最大の弱点が次元の呪いです(→ 次元の呪い)。特徴の数 が増えると、点同士の距離がほぼ均一になり、「最も近い点」と「最も遠い点」の差が消えていきます。
直感的には、高次元空間では各点が広大な空間にスカスカに散らばり、どの点から見ても他のすべての点が同じくらい遠くなります。近さで答えを決める k-NN にとって近傍という概念そのものが意味を失うため、これは致命的です。定量的にも、データ密度を一定に保つのに必要なサンプル数が次元に対し指数的に増えます。サンプル数が固定なら、次元が上がるほど各近傍は「実は全然近くない」点で埋まり、性能が劣化します。
要するに:k-NN は特徴が少ない・サンプルが多い低次元で輝き、高次元では「近い」が嘘になって崩れます。対策は次元削減(PCA 等)や、本当に効く特徴だけに絞る特徴選択です。
6. 計算コストと近似最近傍
怠惰学習ゆえに、k-NN は予測のたびに全訓練点との距離を計算します。素朴な全探索(brute force)では1件の予測に かかり(=訓練データ数、=特徴数)、データが大きいほど予測が遅くなるスケール問題を抱えます。これを速くする工夫があります。
- 空間分割木:KD木(KD-tree)やボール木(ball tree)であらかじめ点を木構造に整理しておくと、低次元では平均 程度まで探索を短縮できます。ただし高次元では木の効果が薄れ、全探索に近づきます(ここでも次元の呪い)。
- 近似最近傍探索(ANN: Approximate Nearest Neighbor):「厳密に最も近い k 個」を少し諦め、ほぼ近い点を高速に返す手法(HNSW など)。多少の精度低下と引き換えに、大規模データで桁違いに速くなります。ベクトル検索や推薦システムの基盤技術です(この領域は実装が速く動くため、最新の手法は要最新確認)。
要するに:k-NN は小〜中規模なら全探索で十分。大規模になったら木構造や近似探索で「ほどほどに近い k 個」を高速に取りに行きます。
⚠️ よくある誤解
- 「k-NN は訓練が速いから軽い手法」は誤り。軽いのは訓練だけで、予測が重い手法です。負担が訓練から予測に移っているだけで、総コストは小さくありません。
- 標準化を省いてよい、は誤り。距離ベースなのでスケール差がそのまま結果に直結します。標準化は前提条件であり、忘れると単位の選び方で答えが変わります。
- 「k は大きいほど安定して良い」は誤り。大きすぎると遠くの無関係な点まで投票に入り、すべての点で多数派ラベルを返すだけの鈍い分類器になります。バイアスとバリアンスのトレードオフです。
- 高次元でもそのまま使える、は誤り。次元の呪いで距離が無意味化し、近傍という前提が崩れます。次元削減や特徴選択とセットで使うのが基本です。
- 「k-NN は線形分離しかできない」は誤り。むしろ逆で、明示的なモデルを持たないノンパラメトリック手法なので、複雑で非線形な決定境界も柔軟に表現できます(その柔軟さが小さい k での過学習につながる)。
対応するシミュレーション
simulations/knn_decision_boundary.py:三日月形(ノイズ多め)のデータで k を 1・15・75 と変えて決定境界を描きます。 は境界がノイズ点に振り回されてギザギザになり訓練正解率1.0なのにテストは伸びない(高バリアンス)、 を大きくすると滑らかになり、大きすぎると鈍る(高バイアス)ことを可視化します。 がバイアス-バリアンスを調整するつまみであることが見て取れます。
関連ノート
- 教師あり学習・分類 目次
- 判別分析(LDA・QDA)(こちらは分布を仮定するパラメトリック分類。k-NN はノンパラメトリックで対照的)
- 汎化と過学習・バイアスバリアンス分解(k がトレードオフを直接制御する)
- 訓練・検証・テストと交差検証(k は交差検証で選ぶ)
- 次元の呪い(k-NN が最も影響を受ける弱点)
- 機械学習テキスト 全体目次