🎓 レベル:標準 | 重要度:B(標準)
📎 前提:汎化と過学習・バイアスバリアンス分解 | 関連:評価指標(分類)とROC・AUC
要点(BLUF)
- 次元の呪いとは、特徴量(次元)が増えると空間の体積が指数的に膨らみ、データが急速に**疎(スカスカ)**になって、低次元での直観がことごとく崩れる現象の総称です。
- 代表的な症状は3つ:①体積が「隅」や「表面」に集中する、②点どうしの距離が一様に近づき(距離の集中)最近傍が意味を失う、③同じ密度を保つのに必要なサンプル数が次元に対して指数的に増える。
- だからこそ高次元では過学習しやすく、次元削減・特徴選択・正則化が効いてきます(Phase 5・6への橋渡し)。
1. 高次元では空間が「ほとんど隅」になる
直観を裏切る最初の事実から始めます。一辺 1 の超立方体()に内接する球(半径 )を考えると、その体積比は次元 とともにこうなります。
| 次元 | 球 / 立方体の体積比 |
|---|---|
| 2 | 0.785 |
| 3 | 0.524 |
| 5 | 0.164 |
| 10 | 0.0025 |
| 20 | ≈ 0 |
立方体の体積は常に 1 のままなのに、内接球の体積は とともに 0 へ落ちていきます。
xychart-beta
title "内接球の体積比は次元とともに0へ"
x-axis ["d=2", "d=3", "d=5", "d=10", "d=20"]
y-axis "球/立方体 の体積比" 0 --> 1
line [0.785, 0.524, 0.164, 0.0025, 0]
要するに:高次元の立方体は、体積のほぼすべてが球に入らない「隅っこ」に偏っている、ということです。ランダムに点を打つと、そのほとんどが中心から離れた角の領域に落ちます。
似た現象が「表面への集中」です。半径 の球の体積は に比例するので、外殻の薄い層(半径 から まで)が占める体積比は
となります。要するに:高次元の球は中身が空っぽで、体積のほぼ全部が「薄皮(表面付近)」に張り付いています。
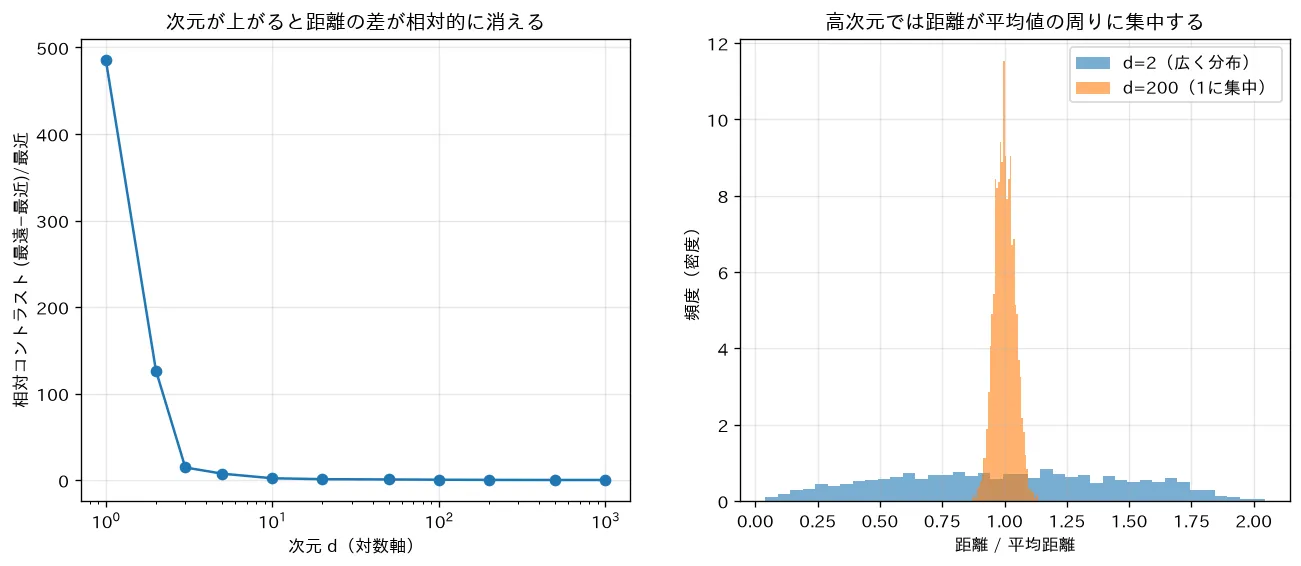
2. 距離の集中:最近傍と最遠傍の差が消える
ここが機械学習に直接効く症状です。点を無作為に多数打ったとき、ある基準点から見た最も近い点までの距離 D_\min と最も遠い点までの距離 D_\max の比に注目します。広い条件下で、次元 が大きくなると
\frac{D_\max - D_\min}{D_\min} \xrightarrow{d\to\infty} 0 \qquad\Longleftrightarrow\qquad \frac{D_\max}{D_\min} \to 1が成り立つことが知られています(Beyer ら 1999)。
直観的な理由はこうです。2点間のユークリッド距離の二乗は各次元の差の二乗の和 です。各次元の寄与を独立な確率変数とみなすと、和の平均は に比例して増える一方、標準偏差(ばらつき)は 程度でしか増えません。したがって相対的なばらつき(変動係数)は に縮みます。
xychart-beta
title "距離の相対ばらつきは次元とともに縮む"
x-axis ["d=1", "d=4", "d=16", "d=64", "d=256"]
y-axis "距離の相対ばらつき (1/√d)" 0 --> 1
line [1.0, 0.5, 0.25, 0.125, 0.0625]
要するに:高次元では「どの点も、どの点ともだいたい同じくらい遠い」状態になります。
この帰結として、距離(近さ)に依存するアルゴリズムが軒並み効かなくなります。
- k近傍法(k-NN):最近傍が最遠傍とほぼ同距離なら「近い=似ている」という前提が崩れ、分類・回帰の精度が落ちる。
- クラスタリング(k-means など):点間距離で塊を見分けられなくなる。
- 半径・しきい値ベースの探索:近傍とそれ以外を分ける半径が引けなくなる。
補足:ただしこれは「無情報な次元が等方的に増える」場合の話です。実データが低次元の多様体に乗っている(有効次元が小さい)なら、見かけの次元が高くても近傍は意味を保ちます。距離指標の選び方(コサイン類似度など)や、後述の次元削減で症状は緩和できます。
3. 必要サンプル数が指数的に増える(データが疎になる)
各次元を 0.1 刻みのグリッドで埋め尽くしたいとします。必要な点数は 1 次元で 10、2 次元で 、 次元では です。
| 次元 | 必要点数(0.1刻みで充填) |
|---|---|
| 1 | 10 |
| 2 | 100 |
| 3 | 1,000 |
| 10 | 100億() |
次元が1つ増えるたびに必要データ量が桁で跳ね上がる。逆に言えば、サンプル数 を固定したまま次元だけ増やすと、空間に対して点がどんどんスカスカになります。これが**データの疎性(sparsity)**です。
経験則として「特徴量1つにつき訓練例が最低でも数件(よく言われるのは5件以上)」と言われますが、これは厳密な定理ではなく目安です(要最新確認)。
4. 過学習との関係、そして対策へ
次元の呪いは 汎化と過学習・バイアスバリアンス分解 と直結します。次元(特徴量)が増えるとモデルのパラメータ・自由度が増え、仮説集合の表現力が上がります。一方でサンプルは相対的に疎になるため、訓練データの偶然のパターンまで拾いやすく=バリアンスが増大します。高次元・少データはまさに過学習の温床です。
対策は「有効な次元を減らす/自由度を抑える」方向に集約されます。
flowchart TD CD["次元の呪い<br/>(高次元・疎・距離集中)"] --> P1["過学習しやすい<br/>(高バリアンス)"] CD --> P2["距離ベース手法が劣化<br/>(k-NN・クラスタリング)"] P1 --> S1["次元削減<br/>(PCA・特徴抽出)"] P2 --> S1 P1 --> S2["特徴選択<br/>(無情報な特徴を捨てる)"] P1 --> S3["正則化<br/>(Ridge・Lasso で自由度を抑制)"] S1 --> G["有効次元を下げ<br/>汎化を取り戻す"] S2 --> G S3 --> G
- 次元削減:PCA などで情報を保ったまま少数の軸に圧縮する(→ 機械学習の基礎枠組み 目次 から Phase 5「教師なし学習」へ)。
- 特徴選択:予測に効かない特徴を落とし、無情報な次元が距離を薄める害を断つ。
- 正則化:Ridge・Lasso でパラメータの自由度に罰則をかけ、高次元でもバリアンスを抑える(Phase 6)。特に Lasso は係数を 0 にして実質的な特徴選択も兼ねます。
なお、すべてが「呪い」ではありません。次元が高いほどデータが線形分離しやすくなる(カーネル法・SVM が依拠する性質)など、高次元が味方になる側面もあります。次元の呪いは「等方的に無情報な次元が増えるとき」の話だと押さえておくと混乱しません。
⚠️ よくある誤解
- 「特徴量は多いほど良い」ではない。情報を持たない特徴を足すと距離を薄め、過学習を招き、性能を下げることがあります。効く特徴を選ぶことが先です。
- 「高次元では必ず近傍法がダメ」ではない。実データが低次元多様体に乗っている(有効次元が小さい)場合や、適切な距離指標を使えば近傍は意味を保ちます。崩れるのは「無情報な次元が等方的に増える」理想化された場合です。
- 「距離が無意味化する=すべての距離が完全に等しい」ではない。なくなるのは相対的な差(D_\max/D_\min \to 1)であって、絶対距離は次元とともにむしろ増えます。
- 次元削減すれば情報は失わない、わけではない。PCA などは「分散の大きい方向を残す」近似であり、捨てた軸に予測情報があれば性能は落ちます。何を残すかが本質です。
対応するシミュレーション
simulations/curse_of_dimensionality.py:次元 を から まで上げながら、ランダムな点どうしの「最遠距離と最近距離の相対差」を測ります。次元が上がるとこの相対コントラストが へ近づき、距離の分布が平均値の周りに鋭く集中する(どの点もほぼ等距離に見える)ことを可視化します。距離ベースの手法(k近傍法)が高次元で無力化する理由が見て取れます。