🎓 レベル:標準 | 重要度:A(必須)
📎 前提:学習問題の定式化(仮説・損失・経験リスク) | 関連:評価指標(回帰) | 数理:第一種の過誤・第二種の過誤・検出力(2種類の誤りとトレードオフ・サンプルサイズ設計)(統計)
要点(BLUF)
- 分類の評価はすべて 混同行列(TP・FP・FN・TN) から導けます。正解率・適合率・再現率・F1 はその4数値の比に過ぎません。
- 不均衡データでは 正解率は当てにならず、目的に応じて適合率(誤検出を嫌う)か再現率(見逃しを嫌う)を選び、両者のバランスを F1 で測ります。
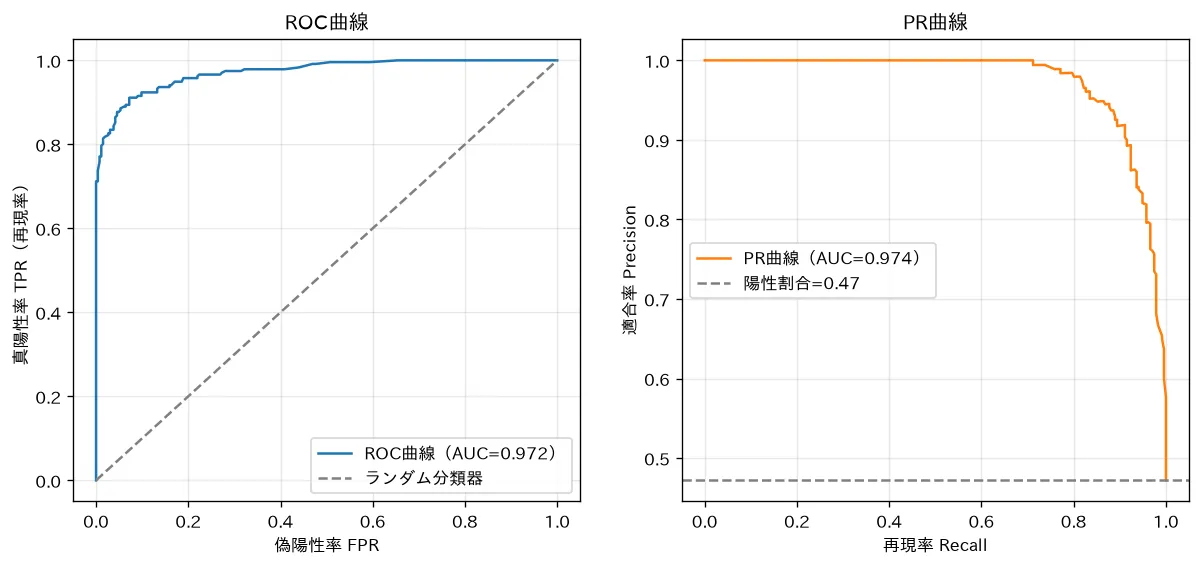
- 閾値を動かしたときの性能を一望するのが ROC曲線(横軸FPR・縦軸TPR) と PR曲線。ROCの下面積 AUC は「ランダムな正例が負例より高スコアになる確率」に一致します。
1. すべての出発点:混同行列
二値分類は「正例(positive, 1)か負例(negative, 0)か」を当てる問題です。予測と正解の組み合わせは4通りしかありません。これを並べたのが 混同行列(confusion matrix) です。
| 予測:正 | 予測:負 | |
|---|---|---|
| 実際:正 | TP(真陽性) | FN(偽陰性・見逃し) |
| 実際:負 | FP(偽陽性・誤検出) | TN(真陰性) |
- TP:正例を正しく正と当てた
- FP:負例を誤って正と言った(誤検出・第一種の過誤に対応)
- FN:正例を見逃して負と言った(見逃し・第二種の過誤に対応)
- TN:負例を正しく負と当てた
FP(偽陽性)・FN(偽陰性)という2種類の過誤の区別は、統計の検定における 第一種・第二種の過誤 と同じ考え方です。再現率は検出力(検定力)と対応します。
flowchart TD
S["1件の予測"] --> A{"実際は正例か"}
A -->|"正例"| B{"正と予測したか"}
A -->|"負例"| C{"正と予測したか"}
B -->|"はい"| TP["真陽性(TP)"]
B -->|"いいえ"| FN["偽陰性(FN)・見逃し"]
C -->|"はい"| FP["偽陽性(FP)・誤検出"]
C -->|"いいえ"| TN["真陰性(TN)"]
2. 正解率とその落とし穴
正解率(accuracy) は「全予測のうち当たった割合」です。
要するに:何件中何件当たったか。直観的ですが、クラスが不均衡だと壊れます。
たとえば正例が1%しかない病気の検査で、「全員陰性」と答えるだけのモデルは正解率99%です。しかし正例は1件も見つけられていません。多数派に張るだけで高い正解率が出てしまう ——これが正解率の落とし穴で、不均衡データで正解率だけを見てはいけない最大の理由です。
3. 適合率・再現率とトレードオフ
そこで、正例に注目した2つの指標を使います。
適合率(precision):正と予測したもののうち、本当に正だった割合。
要するに:「正だと言ったときの当たりやすさ」。誤検出(FP)を嫌うときに見ます。
再現率(recall, 感度・TPR):実際の正例のうち、拾えた割合。
要するに:「正例の取りこぼしのなさ」。見逃し(FN)を嫌うときに見ます。
両者は トレードオフ の関係にあります。閾値を下げて「少しでも怪しければ正」と判定すれば、取りこぼしは減って再現率は上がりますが、誤検出が増えて適合率は下がります。逆も同様です。どちらを重視するかは 問題のコスト で決めます。
- がんの見落としは致命的 → 見逃し(FN)を減らしたい → 再現率重視
- 正常メールを誤って迷惑メールに捨てると困る → 誤検出(FP)を減らしたい → 適合率重視
flowchart LR T["判定閾値"] -->|"下げる"| R1["再現率↑・適合率↓<br/>見逃し減・誤検出増"] T -->|"上げる"| R2["適合率↑・再現率↓<br/>誤検出減・見逃し増"]
4. F1スコア:適合率と再現率の調和平均
片方だけ良くても意味がないことが多いので、両者を1つにまとめます。F1スコア は適合率と再現率の 調和平均 です。
要するに:適合率と再現率の「両方が高くないと高くならない」バランス点。
なぜ算術平均でなく調和平均かというと、調和平均は 小さい方に強く引っ張られる からです。片方が極端に低い(例:再現率0.99だが適合率0.01)ときに「平均0.5」と過大評価せず、低い方に近い値(約0.02)を返します。両者を同時に高くしないと報われない設計です。
一般化した では で再現率の重みを調整できます。 で再現率重視、 で適合率重視。 は (同等の重み)の場合です。
5. 閾値を動かして全体を見る:PR曲線とROC曲線
多くの分類器は「正である確率(スコア)」を出し、それを 閾値 で正負に切ります。閾値は1つの値ではなく、0〜1まで連続的に動かせます。閾値ごとに混同行列が変わるので、閾値を全範囲で動かしたときの性能の軌跡 を曲線で描きます。
PR曲線(Precision-Recall曲線):横軸に再現率、縦軸に適合率。閾値を動かすと描かれる曲線。正例(少数派)に注目した曲線です。
ROC曲線(Receiver Operating Characteristic):横軸に FPR(偽陽性率)、縦軸に TPR(=再現率)。
要するに:FPRは「負例を誤って正と言った割合」、TPRは「正例を拾えた割合」。閾値を下げると両方上がり、点は右上へ動きます。
graph LR O["(0,0)<br/>閾値=最大<br/>全部を負と判定"] --> M["曲線が<br/>左上に張り出すほど良い"] M --> P["(1,1)<br/>閾値=最小<br/>全部を正と判定"] D["対角線=ランダム<br/>(AUC=0.5)"]
理想は左上の角 に近づくこと(誤検出ゼロで全部拾う)。対角線 は ランダム予測 で、それより下なら予測が逆効果ということです。
6. AUC:曲線を1つの数にまとめる
ROC曲線の 下の面積 が AUC(Area Under the Curve) です。(ランダム)〜(完璧)の値をとり、閾値に依存しない 単一指標としてモデル比較に使えます。
AUCには美しい確率的解釈があります。
要するに:ランダムに選んだ正例のスコア が、ランダムに選んだ負例のスコア より 高くなる確率。つまり「正例を負例より上位にランク付けできる確率」です。AUC=0.8なら、正例・負例を1つずつ取り出したとき80%の確率で正例の方が高スコアになります。
この量は統計の マン・ホイットニーのU統計量(ウィルコクソンの順位和検定)と一致します。AUCは本質的に「2群のスコア分布がどれだけ分離しているか」を順位で測る指標です。
AUCは閾値を1つに決めずに ランク付けの良さ だけを評価する点が、正解率やF1と決定的に違います。
7. 閾値の選び方
ROC・PR曲線は「全閾値の性能一覧」なので、最後に 運用する閾値を1つ選ぶ 必要があります。代表的な選び方:
- ユーデンのJ統計量: を最大化(ROC上で対角線から最も離れた点)。ただしFPとFNのコストが等しい前提。
- F1最大化:PR曲線上でF1が最大になる閾値。適合率と再現率を同等に扱う。
- コスト考慮(cost-sensitive):FPとFNの実コストが違うときは、期待コストを最小化する閾値を選ぶ。現実ではこれが本筋(例:見逃しの損失が誤検出の10倍なら閾値を下げる)。
flowchart TD
Q{"FPとFNのコストは<br/>同じか"}
Q -->|"同じ・均衡データ"| J["ユーデンのJ最大化<br/>またはF1最大化"]
Q -->|"違う・不均衡データ"| C["期待コスト最小化<br/>(コスト考慮の閾値)"]
8. 不均衡データでは PR を見る理由
ROCには弱点があります。FPRの分母は で、負例(多数派)が膨大だと FPが多少増えてもFPRはほとんど動きません。結果、負例だらけのデータでは ROCもAUCも楽観的に高く見える ことがあります。
一方、PR曲線の適合率 は 多数派のTNを一切含まない ため、誤検出の影響が直接効きます。少数派の正例を正しく拾えているかを正直に映すので、正例がレアな問題(異常検知・不正検知・希少疾患)ではPR曲線(PR-AUC)を主に見る のが定石です。
なお、ランダム予測のPR-AUCのベースラインは 正例の割合(有病率) です(例:正例1%ならPR-AUCのランダム値は約0.01)。ROCのランダム値が常に0.5なのと違い、PRは不均衡度で基準が変わる点に注意します。
急速に変わる論点ではありませんが、近年は「閾値選択は確率較正(calibration)を前提にすべき」という議論もあります。ROC基準だけで閾値を決めるのが万能ではない点は要最新確認です。
⚠️ よくある誤解
- 正解率が高い=良いモデル、ではない。不均衡データでは多数派に張るだけで高くなります。必ず適合率・再現率・F1かPR-AUCを併用すること。
- AUCが高い=そのまま使える、ではない。AUCはランク付けの良さであって、運用閾値での適合率・再現率は別に確認が必要です。AUC=0.9でも閾値次第で実運用は悲惨になり得ます。
- ROCとPRを混同しない。均衡データの全体比較ならROC/AUC、少数派の検出が目的の不均衡データならPR/PR-AUC。
- 損失関数と評価指標は別物。学習は微分しやすい交差エントロピーを最小化し、報告はF1やAUCで行うのが普通です(→ 学習問題の定式化(仮説・損失・経験リスク))。
- F1は適合率・再現率を同等に扱う。見逃しと誤検出のコストが違う問題では やコスト考慮の指標を検討します。
対応するシミュレーション
simulations/roc_pr_curves.py:ロジスティック回帰の出力スコアのしきい値を から まで動かしながら TPR・FPR・適合率・再現率を計算し、ROC曲線とPR曲線を描きます。曲線の下の面積(AUC)を台形則で求め、ROC-AUC と PR-AUC を比較します(不均衡では PR のほうが厳しく評価できる点は 不均衡データの扱い と対で確認できます)。
関連ノート
- 学習問題の定式化(仮説・損失・経験リスク)(損失と評価指標の違い)
- 評価指標(回帰)(回帰側の評価指標)
- 訓練・検証・テストと交差検証(どのデータで評価するか)
- 第一種の過誤・第二種の過誤・検出力(2種類の誤りとトレードオフ・サンプルサイズ設計)(統計・FP/FNと過誤の対応)
- ノンパラメトリック検定(符号・順位和・Wilcoxon)(統計・AUCとマン・ホイットニーU)
- 機械学習の基礎枠組み 目次
- 機械学習テキスト 全体目次