📊 対象級:2級 ・ 準1級 | 重要度:A(頻出)
第一種の過誤・第二種の過誤・検出力(2種類の誤りとトレードオフ・サンプルサイズ設計)
要点(BLUF)
- 仮説検定は「真実」と「判断」の食い違いで2種類の誤りを犯しうる。真実( が真/ が真)と判断(棄却/非棄却)を掛け合わせた 2×2の表が出発点です。
| を棄却(差ありと判断) | を非棄却(差なしと判断) | |
|---|---|---|
| が真(本当は差なし) | 第一種の過誤 確率 (あわてんぼう) | 正しい判断 確率 |
| が真(本当は差あり) | 正しい判断=検出力 確率 | 第二種の過誤 確率 (ぼんやり) |
- 第一種の過誤 : が真なのに棄却してしまう(無い差を「ある」と言う)。確率は有意水準 そのもの。
- 第二種の過誤 : が真なのに棄却できない(有る差を見逃す)。
- 検出力(power): が真のとき正しく棄却できる確率。「有る差をちゃんと検出する力」。
- 最重要のトレードオフ:棄却域を広げると かつ 、狭めるとその逆。 と を同時に下げる唯一の方法は標本サイズ を増やすこと。
- 検出力 を上げる4要因:効果量 が大・ が大・ が大・ が小。準1級では目標検出力(例 )から必要 を逆算します。
本文
1. 仮説検定は必ず誤りうる:2×2の枠組み
仮説検定(仮説検定の枠組み(帰無仮説・対立仮説・p値・有意水準))は、標本という有限の偶然の産物から母集団について白黒つける手続きです。標本はばらつくので、正しい手続きを踏んでも一定確率で結論を間違えます。間違い方は真実と判断の組み合わせで4通り、うち誤りは2種類です。
graph TD
R["検定の結論を出す"] --> H0T["真実:H0が真<br/>(本当は差なし)"]
R --> H1T["真実:H1が真<br/>(本当は差あり)"]
H0T --> A1["H0を棄却 → 第一種過誤 α<br/>無い差を『ある』と誤認"]
H0T --> A2["H0を非棄却 → 正解 1−α"]
H1T --> B1["H0を棄却 → 正解=検出力 1−β"]
H1T --> B2["H0を非棄却 → 第二種過誤 β<br/>有る差を見逃す"]
style A1 fill:#ffe0e0
style B2 fill:#fff0d0
style B1 fill:#e0ffe0
- 赤=第一種の過誤(あわてて誤検出)、黄=第二種の過誤(ぼんやり見逃し)、緑=検出力(正しく検出)。
- 真実は1列( 真なら左列、 真なら右列)しか起きていない点に注意。 は「 が真という前提のもとでの」棄却確率、 は「 が真という前提のもとでの」非棄却確率で、条件付き確率です。だから と は足して1にはなりません(別々の前提のもとの確率)。各列の中でだけ和が1になります(、)。
📊 級差:2級は上の2×2の表・ の定義・トレードオフ・検出力の概念まで(4節まで)。準1級は検出力の計算・効果量・サンプルサイズ設計まで(5〜7節)。迷ったら本文の節冒頭の注記に従ってください。
2. 第一種の過誤 :あわてんぼうの誤り
定義:第一種の過誤(Type I error) とは、帰無仮説 が真であるのに棄却してしまうこと。その確率を と書く。
要するに:「本当は差が無い」のに「差がある」と早とちりする誤り。無実の人を有罪にするタイプのミスです。
この は検定の有意水準そのものです。検定では「 が真なら検定統計量がこの値より極端になる確率は 以下」となるように棄却域を決めます。つまり はこちらが事前に設定するもので、慣例は や 。設定した瞬間に第一種の過誤の確率が決まる、というのが検定の設計思想です。
⚠️ は「 が真」という前提つきの確率。実際に が真かどうかは分からないまま、「もし真なら誤って棄却する確率はこれだけに抑える」と宣言しているだけです。 は「 が真の世界を100回検定したら平均5回は誤って棄却する」という意味で、「いま手元の結論が95%正しい」ではありません(後者は事後確率でベイズの領域)。
3. 第二種の過誤 と検出力 :ぼんやりの誤りとその裏返し
定義:第二種の過誤(Type II error) とは、対立仮説 が真であるのに を棄却しないこと。その確率を と書く。 検出力(power) はその裏返しで、 が真のとき正しく棄却できる確率:
要するに: は「本当は差があるのに見逃す」誤り(真犯人を無罪放免にするミス)。検出力 はその逆で「有る差をちゃんと拾える力」。検定の感度(センサーの鋭さ)に当たります。
と決定的に違うのは、 は1つの数に決まらない点です。 を計算するには「 が真」だけでは足りず、 の中の具体的な値(例:母平均が ではなく )を指定しないといけません。差が大きいほど見逃しにくく は小さくなる。だから**検出力は「対立値 の関数」**であり、これを描いたものが検出力曲線(5.3)です。
graph LR
A["α(有意水準)"] -->|事前に設定する1つの値| A2["検定の設計で決まる"]
B["β・検出力1−β"] -->|対立値 μ₁ に依存する関数| B2["μ₁ を決めて初めて計算できる"]
style A fill:#ffe0e0
style B fill:#e0ffe0
4. と のトレードオフ:片方を下げると片方が上がる
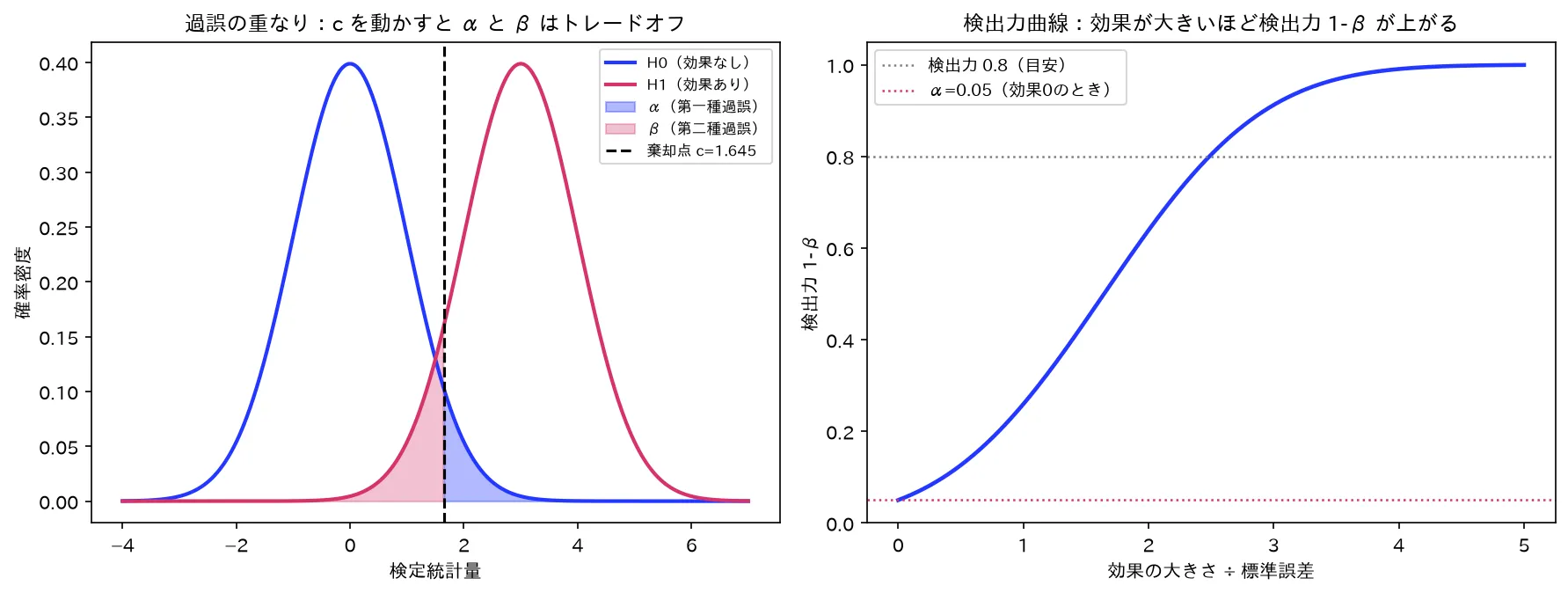
左:H0/H1 の重なり(青=α、赤=β、棄却点 c=1.645)。c を動かすと α と β はトレードオフ。右:検出力曲線(効果0で 0.05、効果が増すと S字で1へ)。図は simulations/kago_kasanari_kenshutsuryoku.py で生成。
ここが本トピックの心臓です。第一種の過誤と第二種の過誤は同時には下げられない( を固定する限り)。
4.1 なぜトレードオフが起きるのか(重なる2分布で考える)
母平均の検定(母平均の検定(1標本・2標本t検定))を例に、検定統計量(ここでは標本平均 )の分布を2つ描きます。
- の分布: が真(母平均 )のときの の分布。中心 。
- の分布:対立値(母平均 )が真のときの の分布。中心 。
両分布は標準誤差 の幅を持ち、 と が近ければ裾が重なります。棄却域の境目(臨界値) を1本引くと、面積が次のように対応します(右片側検定の場合)。
| 面積 | どちらの分布 | 領域 | 意味 |
|---|---|---|---|
| の分布 | より右 | 真なのに棄却=第一種過誤 | |
| の分布 | より左 | 真なのに非棄却=第二種過誤 | |
| の分布 | より右 | 真で正しく棄却=検出力 |
臨界値 を1本の同じ線で共有しているのがポイント。だから を動かすと両方が連動します。
graph TD
C["臨界値 c を右へ動かす<br/>(棄却域を狭める)"] --> A["H0分布の右側面積↓<br/>→ α 減る"]
C --> B["H1分布の左側面積↑<br/>→ β 増える(検出力↓)"]
D["臨界値 c を左へ動かす<br/>(棄却域を広げる)"] --> A2["α 増える"]
D --> B2["β 減る(検出力↑)"]
style A fill:#e0ffe0
style B fill:#ffe0e0
style A2 fill:#ffe0e0
style B2 fill:#e0ffe0
要するに:臨界値という1本の仕切りを右へ動かせば 分布の右裾()は痩せるが、同じ線の左側に入る 分布の面積()は太る。1本の線で2つの分布を仕切っているから、片方を減らせば必然的に片方が増える ── これがトレードオフの正体です。
4.2 トレードオフを式で確認(右片側・ 既知)
母分散 既知、 vs 、 を統計量とする右片側検定で確認します。 の標準誤差は (標本平均・標本比率の標本分布(標準誤差))。
臨界値は、 のもとで右側確率が になる点。(正規分布(標準正規・標準化))なので、 を標準正規分布の上側 点()として
第一種過誤:定義どおり ( をそう決めたので当然)。
検出力:()が真なら 。棄却域 に入る確率が検出力です。 を標準化して
ここに を代入すると、
よって( を標準正規分布の累積分布関数とし、 を使うと)
要するに:検出力は (増加関数)の中身が大きいほど大きい。中身は (効果)と に比例し、 に反比例し、 を引く形になっている。この1本の式に、検出力を動かす全要因が詰まっています(次節で要因分解)。
⚠️ で、 とは符号が逆。「 と検出力どちらを問われているか」を必ず確認。検出力=棄却域側( 分布の右裾)、=非棄却側( 分布の左裾)です。
5. 検出力を上げる4要因(準1級)
ここからは主に準1級。2級では「効果量が大きいほど・ が大きいほど検出力が上がる」という方向感までで十分です。
4.2の検出力の式 から、 は増加関数なので「中身が大きくなる操作はすべて検出力を上げる」。中身を見れば4要因が読めます。
5.1 効果量 が大きいほど(分子↑)
真の差 が大きいほど中身が大きく、検出力が上がる。標準化した差
を 効果量(effect size) と呼びます(コーエンの )。 を単位にした差の大きさで、単位に依らない指標。要するに:差が大きい(=2分布が大きく離れている)ほど見逃しにくい。当然のことを式が裏づけています。
5.2 標本サイズ が大きいほど(分子に )
を増やすと中身が に比例して増え、検出力が上がる。理由は標準誤差 が縮み、2つの分布が痩せて重なりが減るから(同じ でも分布が細くなれば臨界値の右側に 分布がより多く入る)。要するに:データを増やせば小さな差でも検出できる。検出力を上げる最も実務的なレバーです。
5.3 有意水準 が大きいほど(↓)
を大きくすると上側 点 が小さくなり、 が大きくなって検出力が上がる。これは4節のトレードオフそのもの:棄却域を広げる()と (検出力↑)。要するに:誤検出を許すほど見逃しは減る。ただし を上げるのは第一種過誤を増やす代償つきで、タダで検出力を買えるわけではありません。
5.4 母標準偏差 が小さいほど(分母↓)
が小さいほど中身()が大きく検出力が上がる。母集団のばらつきが小さい=分布が細い=重なりが少ない。要するに:もともとブレが小さい現象は小さな差でも検出しやすい。 は普通こちらで操作できないので、実務で動かすのは主に と 、そして設計段階で見込む効果量です。
5.5 検出力曲線
検出力は対立値 (または効果量 )の関数。横軸に 、縦軸に検出力を取った曲線が 検出力曲線(power curve) です。式から形が読めます:
- (差なし、効果量0)のとき中身は なので検出力 。真に差が無いとき、検出力は に一致します(このとき棄却=第一種過誤なので当然)。
- が から離れるほど検出力は単調に増加し、 に漸近する。
- を大きくすると曲線全体が急峻になる(小さな差でも素早く検出力が1へ立ち上がる)。
| の位置 | 検出力 |
|---|---|
| (差なし) | (最小。例 ) |
| がやや離れる | から増加 |
| が大きく離れる | に漸近 |
要するに:検出力は「1つの値」ではなく、想定する差 ごとに決まる曲線。差が無ければ から始まり、差が開くほど へ近づきます。
6. サンプルサイズ設計:目標検出力から必要 を逆算(準1級)
準1級の頻出。「検出したい効果量 」と「目標検出力(例 )」を決めて、必要な標本サイズ を求めます。
6.1 4因子は「3つ決めれば1つ決まる」
検定の設計には4つの因子があり、3つを固定すると残り1つが決まる関係にあります:
- 有意水準
- 検出力
- 効果量 (または検出したい差 と )
- 標本サイズ
実験計画では「、検出力 、見込む効果量 」を決めて を逆算するのが定石です。
6.2 サンプルサイズ式の導出
4.2の検出力の式で、目標検出力を にしたい。 を上側 点( すなわち中身 … ここで は の上側点)とします。検出力の式
が成り立つには、 の中身が 点に等しければよい。(対称性 )なので
と置いて について解くと
\quad\Longrightarrow\quad \boxed{\,n=\left(\frac{(z_\alpha+z_\beta)\,\sigma}{\Delta}\right)^2=(z_\alpha+z_\beta)^2\left(\frac{\sigma}{\Delta}\right)^2\,}$$ 効果量 $d=\Delta/\sigma$ を使えば等価に $n=\left(\dfrac{z_\alpha+z_\beta}{d}\right)^2$。 **要するに**:必要な $n$ は $(z_\alpha+z_\beta)^2$(厳しさと検出力の要求)に比例し、効果量 $d$ の**2乗に反比例**する。検出したい差が半分になれば必要なデータは4倍 ── 小さな差を検出するのは急速に高コストになります。 > ⚠️ 上は**両片側・$\sigma$ 既知の片側検定**の最も基本の形。両側検定なら $z_\alpha$ を $z_{\alpha/2}$ に置き換える。$\sigma$ 未知で $t$ 分布を使う場合や2標本比較は係数が変わるが、**「$(z_\alpha+z_\beta)^2$ に比例・効果量の2乗に反比例」という骨格は共通**。試験ではこの片側・既知の形を確実に。 #### 6.3 数値例 $\alpha=0.05$(片側、$z_{0.05}=1.645$)、目標検出力 $0.8$($\beta=0.2$、$z_{0.2}=0.842$)、$\sigma=10$、検出したい差 $\Delta=5$(効果量 $d=0.5$)のとき: $$n=\left(\frac{(1.645+0.842)\times 10}{5}\right)^2=\left(\frac{2.487\times 10}{5}\right)^2=(4.974)^2\approx 24.7.$$ 切り上げて $n=25$。**要するに**:標準偏差の半分($d=0.5$)の差を、有意水準5%・検出力80%で検出するには約25個のデータが要る、と設計できます。効果量が $d=0.25$(差が半分)なら $n$ は約4倍の $\approx99$ になります。 --- ### 7. 試験での問われ方とまとめ表 | 級 | 問われること | |---|---| | **2級** | 2×2の表の理解、$\alpha$(=有意水準)と $\beta$ の定義、検出力 $=1-\beta$、$\alpha$ と $\beta$ のトレードオフ、「$\alpha$ を下げると $\beta$ が上がる」「両方下げるには $n$ を増やす」という定性関係。第一種・第二種のどちらが起きている状況かの判別 | | **準1級** | 検出力の計算($\sigma$ 既知の片側検定で $1-\beta=\Phi(\cdots)$ を数値計算)、効果量 $d=\Delta/\sigma$、検出力曲線の理解、サンプルサイズ設計 $n=(z_\alpha+z_\beta)^2(\sigma/\Delta)^2$ による逆算 | --- ## ⚠️ 引っかけポイント - **$\alpha+\beta=1$ ではない**。$\alpha$ は「$H_0$ 真」の前提、$\beta$ は「$H_1$ 真」の前提の**別々の条件付き確率**。和に意味はない。各前提の中でだけ $\alpha+(1-\alpha)=1$、$\beta+(1-\beta)=1$ が成り立つ。 - **検出力 $=1-\alpha$ ではない**。検出力は $1-\beta$。$1-\alpha$ は「$H_0$ が真のとき正しく非棄却する確率」で別物。$\alpha$ と組むのは $1-\alpha$、$\beta$ と組むのが検出力 $1-\beta$。行(前提)をまたいで引き算しない。 - **「$\alpha$ を小さくすれば良い検定」は誤り**。$\alpha$ を下げると棄却域が狭まり $\beta$ が増える(検出力が落ちる)。$\alpha$ だけ見て検定の良し悪しは決まらない。両方を睨むか、$n$ で底上げする。 - **検出力は1つの値ではない**。対立値 $\mu_1$(効果量)に依存する**関数(曲線)**。「この検定の検出力は0.8」と言うときは必ず「どの効果量に対して」が裏にある。$\mu_1=\mu_0$(差なし)では検出力は $\alpha$ まで落ちる。 - **$\beta$ と検出力 $1-\beta$ の符号を取り違える**。検出力は $H_1$ 分布の**棄却域側(臨界値の右)**の面積、$\beta$ は**非棄却側(左)**。式でも $\Phi(\cdots-z_\alpha)$(検出力)と $\Phi(z_\alpha-\cdots)$($\beta$)で符号が逆。 - **サンプルサイズ式の依存性**。$n\propto(z_\alpha+z_\beta)^2$ かつ $n\propto 1/d^2$。**効果量の2乗に反比例**なので、検出したい差を半分にすると必要 $n$ は4倍。「差が小さいのに $n$ が少ない検定で有意でなかった」=検出力不足で見逃した可能性($\beta$ 大)を必ず疑う。 - **両側検定では $z_\alpha\to z_{\alpha/2}$**。片側の式をそのまま両側に使わない。臨界値が変わるぶん検出力もサンプルサイズも変わる。 --- ## よくある疑問 **Q1. 第一種の過誤と第二種の過誤、どっちが「悪い」んですか?** A. 状況依存で一概に決まりません。第一種(無い差をあると誤認)が深刻な例:新薬に「効果あり」と誤判定して効かない薬を世に出す。第二種(有る差を見逃す)が深刻な例:本当に効く薬を「効果なし」と切り捨てる、病気を見逃す。慣習として $\alpha$(第一種)を厳しく固定する($0.05$ 等)のは「無い効果をあると主張する誤り=偽陽性を特に警戒する」という科学の保守的な立場の反映です。ただし医療スクリーニングのように見逃しが致命的な場面では $\beta$ を抑える(検出力を確保する)設計が優先されます。どちらを重く見るかは応用分野の損失で決める、というのが正しい姿勢です。 **Q2. なぜ $\alpha$ と $\beta$ を両方ゼロにできないんですか?** A. 検定統計量の分布が $H_0$ のときと $H_1$ のときで**重なっている**からです(4.1)。臨界値という1本の仕切りで2つの分布を切り分ける以上、$H_0$ 分布の裾を切り落とそう($\alpha\downarrow$)とすれば仕切りが移動して $H_1$ 分布が非棄却側に多く入り $\beta\uparrow$ になる。両方ゼロにできるのは2分布が完全に分離したときだけで、それには重なりを消す=標準誤差 $\sigma/\sqrt n$ を0にする=$n\to\infty$ が必要。有限のデータでは必ずトレードオフが残ります。 **Q3. 「$\alpha$ と $\beta$ を同時に下げるには $n$ を増やす」のはなぜですか?** A. $n$ を増やすと標準誤差 $\sigma/\sqrt n$ が縮み、$H_0$ 分布と $H_1$ 分布が**両方とも細くなって重なりが減る**からです。重なりが減れば、臨界値を動かさなくても $H_0$ 分布の右裾($\alpha$)も $H_1$ 分布の左裾($\beta$)も同時に小さくできる。トレードオフは「$n$ 固定」という土俵の上の話で、$n$ という土俵自体を広げれば両方を改善できる、という構図です。検出力の式 $\Phi\big(\frac{\Delta\sqrt n}{\sigma}-z_\alpha\big)$ で $\alpha$(つまり $z_\alpha$)を固定したまま $n$ を上げれば検出力が上がる($\beta$ が下がる)ことからも読めます。 **Q4. 検出力は「1つの数」だと思っていました。なぜ関数なんですか?** A. $\beta$(したがって $1-\beta$)の計算には「$H_1$ が真」だけでは足りず、$H_1$ の中の**具体的な対立値 $\mu_1$**が要るからです(3節)。$\mu_1$ が $\mu_0$ に近ければ2分布がほぼ重なり検出力は低く($\mu_1=\mu_0$ なら検出力 $=\alpha$)、$\mu_1$ が大きく離れれば検出力は1に近づく。だから検出力は $\mu_1$ ごとに値が決まる**曲線**(検出力曲線、5.5)。一方 $\alpha$ は「$H_0$ が真」という1点だけで決まるので1つの数。この非対称性($\alpha$ は点、$\beta$ は対立値依存)が両者の本質的な違いです。 **Q5. 有意にならなかったら「差はない」と結論していいですか?** A. ダメです。非棄却は「$H_0$ を棄却するほどの証拠が無かった」だけで、「$H_0$ が正しい(差が無い)」の証明ではありません。差を見逃した(第二種過誤 $\beta$)可能性が常に残る。特に $n$ が小さい・効果量が小さいと検出力が低く、本当に差があっても有意になりにくい。だから「有意差なし」を報告するときは検出力やサンプルサイズも併記すべきで、「検出力0.3の検定で有意でなかった」は「差がない」ではなく「この検定では差を検出する力が不足していた」と読むのが正しい。 **Q6. 効果量 $d=\Delta/\sigma$ をわざわざ $\sigma$ で割るのはなぜですか?** A. 単位や尺度に依存しない「差の大きさ」を測るためです。生の差 $\Delta=5$ は、$\sigma=2$ の現象なら巨大($d=2.5$)、$\sigma=100$ の現象なら微小($d=0.05$)。検出のしやすさは生の差ではなく「ばらつきに対してどれだけ離れているか」で決まる(検出力の式の中身が $\Delta/\sigma$ の形)。だから $\sigma$ で割って標準化した $d$ が、分野をまたいで効果の大小を比較でき、サンプルサイズ設計の共通言語になります。 --- ## まとめ - 仮説検定は標本のばらつきゆえ必ず誤りうる。真実($H_0$ 真/$H_1$ 真)× 判断(棄却/非棄却)の **2×2** で、誤りは2種類。 - **第一種の過誤 $\alpha$**=$H_0$ 真なのに棄却(あわてんぼう、=有意水準、事前に設定する1つの値)。**第二種の過誤 $\beta$**=$H_1$ 真なのに見逃し。**検出力 $1-\beta$**=$H_1$ 真で正しく棄却する力。$\alpha,\beta$ は別前提の条件付き確率で和に意味はない。 - **トレードオフ**:臨界値1本で2分布を仕切るため、$\alpha\downarrow$ なら $\beta\uparrow$。両方下げる唯一の道は $n$ を増やして2分布の重なりを減らすこと。 - **検出力の式**($\sigma$ 既知・右片側):$1-\beta=\Phi\!\big(\frac{(\mu_1-\mu_0)\sqrt n}{\sigma}-z_\alpha\big)$。検出力を上げる4要因=効果量 $|\mu_1-\mu_0|$ 大・$n$ 大・$\alpha$ 大・$\sigma$ 小、はすべてこの中身を大きくする操作。検出力は対立値 $\mu_1$ の**関数(曲線)**で、差なしのとき $\alpha$ から始まり1へ漸近。 - **サンプルサイズ設計**:$n=(z_\alpha+z_\beta)^2(\sigma/\Delta)^2$。効果量の2乗に反比例(差が半分なら $n$ は4倍)。$\alpha$・検出力・効果量を決めれば $n$ が決まる。 - 試験での差:**2級**=表・定義・トレードオフ・検出力の概念。**準1級**=検出力の計算・効果量・検出力曲線・サンプルサイズ設計。 --- ## 関連ノート - 仮説検定の枠組み(帰無仮説・対立仮説・p値・有意水準) … 帰無仮説・対立仮説・棄却域・有意水準の土台。本ノートはその「誤り」の側面を深掘りしたもの - 母平均の検定(1標本・2標本t検定) … 検出力・サンプルサイズの計算を具体的に当てはめる代表例($\sigma$ 既知の $z$ 検定・$t$ 検定) - 正規分布(標準正規・標準化) … 検出力の式で使う $\bar X\sim N(\mu,\sigma^2/n)$ と標準化・$z_\alpha$ - 標本平均・標本比率の標本分布(標準誤差) … 標準誤差 $\sigma/\sqrt n$。$n$ で分布が痩せる=検出力が上がる根拠 - 区間推定(母平均・母比率・母分散の信頼区間) … 信頼区間と検定の表裏。区間幅と検出力はともに $\sigma/\sqrt n$ に支配される