📊 対象級:2級 | 重要度:A(頻出)
仮説検定の枠組み(帰無仮説・対立仮説・p値・有意水準)
要点(BLUF)
- 仮説検定:母集団についての主張(例「この薬は効く」)が正しいかを、標本データだけから確率の言葉で判定する手続き。直接「効く」を証明するのではなく、「効かない(差がない)」という仮説を立て、それが観測データと矛盾するかを調べます。要するに背理法です。
- 立てる仮説は2つ。帰無仮説 (無に帰したい・否定したい仮説。例「差はない 」)と、対立仮説 (本当に主張したい仮説。例「差がある 」)。
- 手順は4ステップ:①仮説を立てる → ②検定統計量を計算 → ③ のもとでそれが「滅多に起きない」値か判定(p値 or 棄却域)→ ④判断。判定の基準が有意水準 (ふつう0.05)です。
| 用語 | ひとことで | 記号・条件 |
|---|---|---|
| 帰無仮説 | 否定したい仮説(差がない) | など等号 |
| 対立仮説 | 主張したい仮説(差がある) | |
| 有意水準 | 棄却の基準確率(誤って棄却する確率の上限) | ふつう |
| 棄却域 | を棄却する統計量の領域 | 確率が の「滅多にない」域 |
| p値 | 観測値以上に極端な値が出る確率( 仮定下) | で棄却 |
- 最重要の誤解:p値は「 が正しい確率」ではない。p値は「 が正しいと仮定したうえで、いま観測されたより極端なデータが出る確率」です。後述の⚠️とQ&Aで徹底的に潰します。
- もう1つの非対称性: を棄却できなかったとき「 が正しい」とは言えない。証拠不十分であって肯定ではない。検定は を「積極的に否定する」ためだけの道具です。
本文
1. なぜ「無に帰したい仮説」を立てるのか:背理法の論理
私たちが本当に主張したいのは「新薬は効く」「コインは歪んでいる」といった前向きの主張です。ところが仮説検定は、それを直接証明しません。逆に**「効かない」「歪んでいない」という否定形の仮説を立てて、それを棄却する形で間接的に主張します。なぜこんな回りくどいことをするのか。理由は「ある」の証明は難しいが、「ない」の反証は易しい**からです。
数学の背理法を思い出してください。「 が無理数である」を直接示すのは難しいので、「 は有理数である」と仮定して矛盾を導きました。仮説検定も同じ構造です。
graph LR
A["主張したいこと<br/>薬は効く"] --> B["否定形を仮説に置く<br/>H0:薬は効かない"]
B --> C["H0 が正しいと仮定して<br/>データの起こりやすさを計算"]
C --> D{"観測データは<br/>H0 のもとで<br/>滅多に起きない?"}
D -->|滅多に起きない| E["H0 を棄却<br/>=薬は効くと主張"]
D -->|ありえなくはない| F["H0 を棄却できない<br/>=証拠不十分"]
style B fill:#ffe8e8
style E fill:#e8f4ff
ポイントは、「 が正しい」という仮定を出発点に置くと、検定統計量の分布が1つに定まることです。「差がない()」と決め打てば、標本平均がどんな分布に従うかを計算できる(標本平均・標本比率の標本分布(標準誤差))。その分布のもとで観測データが「滅多に起きない」端っこに来たなら、最初の仮定()が疑わしい、と結論する。これが仮説検定のエンジンです。
逆に対立仮説(:差がある)を出発点にすると、「どれくらい差があるか」が定まらず分布を1つに描けません。だから確率を計算できる の側を仮定する。これが「無に帰したい仮説」を主役に据える理論的理由です。
⚠️ 帰無仮説には必ず等号が入る(、 など)。「差がぴったり0」のように1点(または境界)に定めるからこそ分布が1つに決まり、確率計算ができます。対立仮説は等号なし()。試験で「 と のどちらに等号を入れるか」を問われたら、等号は必ず 側。
2. 帰無仮説 と対立仮説 の立て方
定義:
- 帰無仮説 (null hypothesis):否定・棄却したい仮説。「効果がない」「差がない」「母数がある特定の値に等しい」という主張。
- 対立仮説 (alternative hypothesis、 とも): が棄却されたときに採択される、本当に主張したい仮説。
要するに: が「言いたいこと」、 が「言いたいことの否定(=とりあえず信じておく現状維持の立場)」。検定は を守る側に立ち、データが を覆すだけの強い証拠を出せたときだけ を捨てます。
具体例で対応を見ます。
| 場面 | 主張したいこと | 帰無仮説 | 対立仮説 |
|---|---|---|---|
| 新薬の薬効 | 平均血圧が下がる | (変わらない) | (下がる)または |
| コインの公平性 | 表が出やすい/歪んでいる | (公平) | (歪んでいる) |
| 製品の改良 | 不良率が下がった | (変わらない) | (下がった) |
2.1 片側検定と両側検定の使い分け
対立仮説の形で検定の「向き」が決まります。
- 両側検定:。「どちらの向きでもいいから差がある」を検出したいとき。棄却域は分布の両端に置く。
- 片側検定:(右片側)または (左片側)。「特定の向きの差だけ」を検出したいとき。棄却域は分布の片方の端だけ。
graph TD
A{"対立仮説 H1 の形は?"} -->|μ ≠ μ0| B["両側検定<br/>棄却域は両端<br/>各端に α/2 ずつ"]
A -->|μ > μ0| C["右片側検定<br/>棄却域は右端のみ<br/>右端に α"]
A -->|μ < μ0| D["左片側検定<br/>棄却域は左端のみ<br/>左端に α"]
style B fill:#e8f4ff
style C fill:#fff0e8
style D fill:#fff0e8
両側検定では有意水準 を両端に半分ずつ(各 )配分します。 なら各端2.5%。片側検定では片端に をまとめて置きます(5%)。
要するに:両側は「上振れも下振れも異常とみなす」ので5%を2.5%ずつ両端に分ける。片側は「片方向だけ異常とみなす」ので5%を片端に集中させる。同じ なら片側のほうが棄却域が端に深く取れる(臨界値が手前にくる)ぶん、その向きの差を検出しやすくなります。
⚠️ 片側か両側かはデータを見る前に決める。統計量を計算してから「両側で有意にならなかったので片側に変えよう」は禁止。これをやると第一種過誤の確率が を超えてしまい、検定が成立しません。向きは問題設定(何を主張したいか)だけで決めます。迷ったら両側が無難(より保守的)。
3. 検定統計量・棄却域・有意水準
3.1 検定統計量
定義:検定統計量(test statistic)とは、標本から計算する量で、 が正しいと仮定したときの分布(帰無分布)が分かっているもの。
代表例は、母平均の検定(分散既知)で使う標準化された量です。 のもとで、標本平均 を標準化すると(標本平均・標本比率の標本分布(標準誤差)):
要するに:「観測された標本平均 が、 の主張する中心 から、標準誤差 何個ぶん離れているか」。 が正しければ は の近くに来るはずなので は0付近。 が0から大きく離れるほど が疑わしい。中心極限定理(正規分布(標準正規・標準化))により、 のもとで は標準正規分布 に従います ── これが「帰無分布が分かっている」の意味です。
3.2 棄却域と臨界値
定義:棄却域(rejection region / critical region)とは、検定統計量がその範囲に入ったら を棄却する領域。臨界値(critical value)は棄却域の境界値。
棄却域は、 が正しいときに検定統計量がそこに入る確率がちょうど になるように、分布の端に取ります。 検定・両側・ なら、標準正規分布の上側2.5%点が なので、棄却域は 。
xychart-beta
title "標準正規分布の棄却域(両側・α=0.05)"
x-axis "検定統計量 Z" [-3, -1.96, -1, 0, 1, 1.96, 3]
y-axis "確率密度" 0 --> 0.45
bar [0.004, 0.058, 0.242, 0.399, 0.242, 0.058, 0.004]
両端の低い部分( と )が棄却域。中央の高い部分が採択域(棄却できない領域)。観測した が両端の棄却域に落ちれば を棄却します。
要するに:「 が正しければ滅多に出ない(確率 しかない)端っこの値が、現実に出てしまった。なら が間違っていたと考えるほうが筋が通る」。これが棄却の論理です。 は「この程度珍しければ を疑う」という珍しさの線引きです。
3.3 有意水準 の意味
定義:有意水準(significance level) とは、検定を行う前に決める棄却の基準確率。 が本当は正しいのに誤って棄却してしまう確率の上限。
とは「 が正しいのに棄却してしまう過ち(後述の第一種過誤)を、5%まで許す」という宣言です。慣習的に0.05や0.01を使いますが、これは絶対的な基準ではなく約束事です。
⚠️ は検定の前に決める。データを見てから「0.05では有意にならないので0.10にしよう」と動かすのは禁止。 は「どれだけの誤判定リスクを事前に許容するか」の取り決めだからです。
4. p値:定義と正しい解釈(最重要)
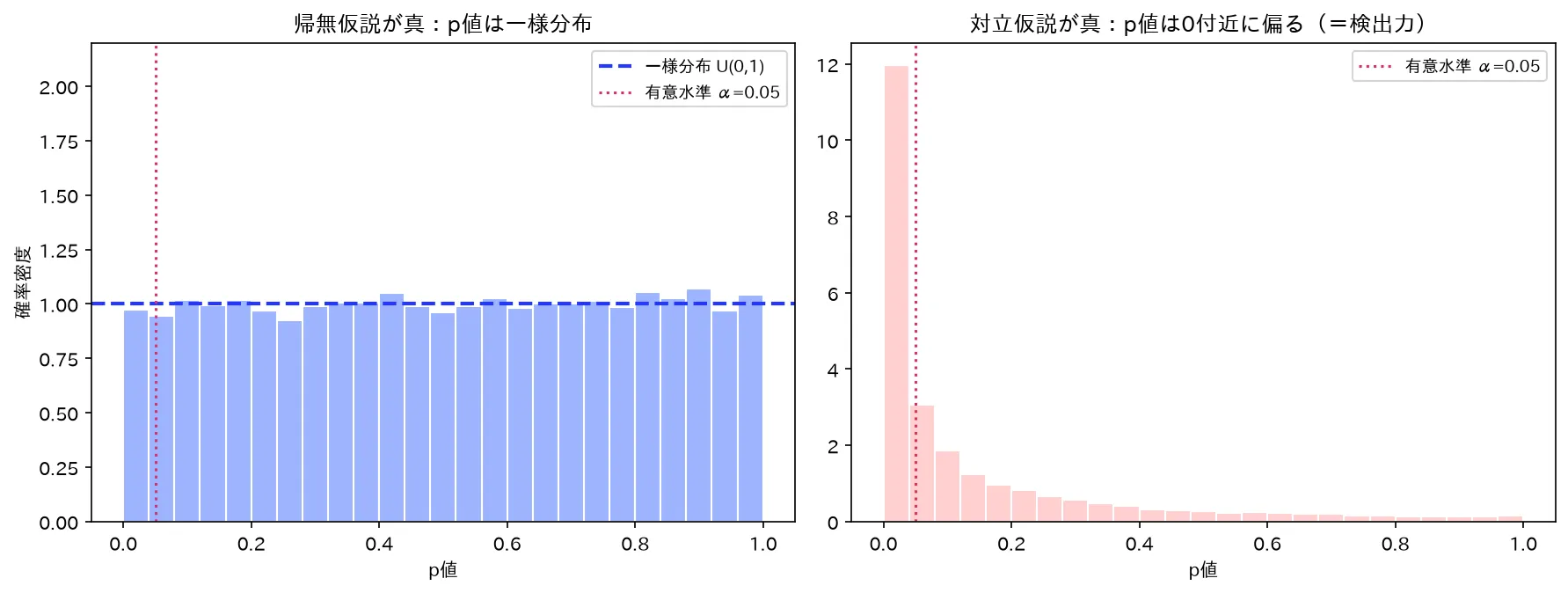
左:帰無仮説が真ならp値は一様分布(だから α で切ると α だけ誤棄却=第一種過誤)。右:対立仮説が真ならp値は0付近に偏る(=検出力)。図は simulations/pchi_bunpu_kimu.py で生成。
定義:p値(p-value)とは、「 が正しいと仮定したとき、実際に観測された検定統計量と同じかそれ以上に極端な値が得られる確率」。
式で書くと、観測された統計量の値を として、両側検定なら
要するに:「もし が本当なら、今回みたいに(あるいはもっと)極端なデータって、どれくらいの頻度で起きるの?」という確率。この値が小さいほど「 が本当ならこんなデータは滅多に出ないはず= が怪しい」となります。
4.1 p値による判定ルール
要するに:観測データの珍しさ(p値)が、あらかじめ決めた珍しさの基準()以下なら を捨てる。p値と棄却域は同じことを別の角度から見ているだけです ── 「統計量が棄却域に入る」⟺「p値が 以下」。臨界値と統計量を比べるのが棄却域方式、確率に直して と比べるのがp値方式。結論は必ず一致します。
⚠️ p値は「観測値ちょうどが出る確率」ではなく「観測値以上に極端な値が出る確率」。連続分布では「ちょうどその値」が出る確率は0なので、必ず「以上に極端」という裾の面積で測ります。「極端」の向きは対立仮説で決まる(両側なら 、右片側なら )。
4.2 p値の最大の誤解:「 が正しい確率」ではない
ここが仮説検定で最も誤解される一点です。アメリカ統計学会(ASA)が2016年に異例の声明を出して警告したほどです。
誤り:「p = 0.03 だから、 が正しい確率は3%だ」。 正しい:「 が正しいと仮定したうえで、今回観測されたより極端なデータが出る確率が3%だ」。
なぜ別物なのか。条件付き確率の向きが逆だからです。
要するに:p値は「 を真と仮定したときのデータの確率」(前向き)。一方「 が正しい確率」は「データを見たあとの の確率」(後ろ向き)。この2つは一般に一致しません。後者を計算するには の事前確率が必要で、それはベイズの土俵の話です(点推定(推定量の良さ:不偏性・一致性・有効性・十分性) で扱った頻度論の枠組みでは、 は「正しいか間違っているか」のどちらかで、それ自体に確率を割り当てません)。
graph TD
A["p値 = 0.03"] --> B["正しい読み<br/>H0 が真なら<br/>これより極端なデータは<br/>3%しか出ない"]
A --> C["誤った読み<br/>H0 が正しい確率が<br/>3%である"]
B --> D["条件:H0 を仮定<br/>P データ|H0"]
C --> E["条件が逆<br/>P H0|データ<br/>頻度論では計算不可"]
style B fill:#e8f4ff
style C fill:#ffe8e8
style E fill:#ffe8e8
5. 「 を棄却できない」≠「 が正しい」:検定の非対称性
検定の結論は2つに1つですが、その重みは対称ではありません。
- を棄却した:「 が正しければ滅多に起きないことが起きた」という積極的な証拠がある。比較的強い結論。
- を棄却できなかった:「 を覆すだけの証拠が集まらなかった」というだけ。 が正しいと証明したわけではない。
要するに:裁判の「有罪 vs 無罪」ではなく「有罪 vs 無罪を立証できず(証拠不十分)」に近い。無罪判決は「やっていない証明」ではなく「やった証拠が足りない」。検定も同じで、棄却できないのは「差がある証拠が足りない」だけで、「差がない」の証明ではありません。
なぜ非対称なのか。検定は最初から を守る側に偏って設計されているからです。 は「 が正しいのに棄却する過ち」だけを5%に抑える設計で、「 が間違っているのに棄却できない過ち」(第二種過誤、)は別途。標本が少ない・効果が小さいと、本当は差があっても棄却できないことは普通に起きます。だから「棄却できなかった=差がない」と結論するのは誤りです。
⚠️ 「有意差なし」は「差がないことの証明」ではない。「差があるとは言えなかった」が正しい言い方。差がないことを積極的に主張したい場合は、検定ではなく同等性検定など別の枠組みが必要(2級の範囲外、要最新確認)。試験では「 だから は正しい」という選択肢は誤りとして頻出します。
この「棄却する過ち(第一種過誤 )」と「棄却できない過ち(第二種過誤 )」のトレードオフは、検定の精度そのものを左右する重要テーマで、第一種の過誤・第二種の過誤・検出力(2種類の誤りとトレードオフ・サンプルサイズ設計) で本格的に扱います。ここでは、 = 第一種過誤( が真なのに棄却する)の確率という接続だけ押さえてください ── 有意水準 は、まさにこの第一種過誤を許容する上限値として設定したものです。
6. 検定の手順(意思決定フロー)
ここまでを1枚の流れにまとめます。どんな検定もこの骨格は同じで、変わるのは②で使う統計量と分布だけです。
flowchart TD
A["① 仮説を立てる<br/>H0(等号あり)と H1<br/>片側か両側かも決める"] --> B["② 有意水準 α を決める<br/>ふつう 0.05"]
B --> C["③ 検定統計量を計算<br/>例 Z=(X̄-μ0)÷標準誤差"]
C --> D["④ 帰無分布で判定<br/>p値を出す or 棄却域と比較"]
D --> E{"p ≤ α?<br/>(統計量が棄却域に入る?)"}
E -->|はい| F["H0 を棄却<br/>H1 を採択<br/>有意差あり"]
E -->|いいえ| G["H0 を棄却できない<br/>有意差ありとは言えない"]
style A fill:#ffe8e8
style F fill:#e8f4ff
style G fill:#fff0e8
具体的な統計量の作り方(母平均・母比率・母分散それぞれで か か か)は 母平均の検定(1標本・2標本t検定) 以降の各論で扱います。この枠組みのノートでは「どの検定でも手順の骨格は共通」を理解するのが目的です。
7. 区間推定との双対性
仮説検定と区間推定(母平均・母比率・母分散の信頼区間)は、実はコインの裏表の関係(双対性, duality)にあります。
対応関係:母平均 の 信頼区間に、帰無仮説の値 が含まれない ⟺ 有意水準 の両側検定で が棄却される。
要するに:信頼区間は「 をこの区間内のどの値に置いても、両側検定で棄却されない の集合」。だから区間の外にある は棄却される。両側検定を について解くと、そのまま信頼区間の式になります。
なぜ成り立つのか。分散既知の 検定で見ます。両側検定で を棄却しない条件は
要するに:左の「棄却しない条件」を について変形すると、右はちょうど の 信頼区間そのもの。つまり「 が信頼区間の中」=「棄却しない」、「 が信頼区間の外」=「棄却する」。同じ不等式を、 を固定して統計量を見るか(検定)、統計量を固定して の範囲を見るか(区間推定)の違いだけです。
⚠️ この双対性が厳密に成り立つのは、検定統計量と区間推定で同じ標準誤差を使う場合(分散既知の正規分布の母平均など、対称な両側検定)。母比率の検定では、標準誤差を の値 で計算するか標本比率 で計算するかで検定と信頼区間がわずかにズレ、「信頼区間に が含まれない」と「検定で棄却」が完全には一致しないことがあります。2級では「両側検定と信頼区間は基本的に対応する」と押さえつつ、この例外があることを知っておけば十分です。
具体例で手順を通す
例1:コインは公平か(両側検定)
コインを 回投げたら表が 回出た。このコインは公平か()。
- ①仮説:(公平)、(歪んでいる)。「どちらに歪んでいるか」を問わないので両側。
- ②有意水準:。
- ③検定統計量: のもとで標本比率 は近似的に正規分布に従う(標本平均・標本比率の標本分布(標準誤差))。標準誤差は の値で 。よって
- ④判定:両側 の臨界値は 。 なので棄却域に入る。p値で見ると 。 を棄却 ── 「このコインは公平とは言えない(5%有意で歪んでいる)」。
- 要するに:(公平)が本当なら、表60回以上に偏る(または40回以下に偏る)ことは約4.6%しか起きない。それが現実に起きたので、公平という仮定を捨てる。
例2:新薬で血圧は下がるか(片側検定)
ある降圧薬を 人に投与し、血圧変化の標本平均が (mmHg、下がった方向)。母標準偏差は既知で とする。薬は血圧を下げるか()。
- ①仮説:(効果なし)、(下がる)。「下がる方向」だけを問うので左片側。
- ③検定統計量:
- ④判定:左片側 の臨界値は 。 なので棄却域に入る。 を棄却 ── 「この薬は血圧を下げると言える」。
- 要するに:効果なし()が本当なら、これほど下がる方向の結果は約0.6%しか起きない。片側にしたぶん臨界値が と手前にあり、両側()より検出しやすくなっている。
⚠️ 引っかけポイント
- p値は「 が正しい確率」ではない(最頻出の誤り)。p値は であって ではない。条件付き確率の向きが逆。「p=0.03 だから帰無仮説が正しい確率3%」は誤り。
- 「 を棄却できない」≠「 が正しい」。棄却できないのは証拠不十分であって肯定ではない。「 だから差はない/ は正しい」という選択肢は誤り。正しくは「差があるとは言えない」。
- 等号は必ず 側。 に等号()、 に等号なし()。 を1点(境界)に固定するから帰無分布が描けて確率計算ができる。逆に書くと検定が成立しない。
- 片側か両側かはデータを見る前に決める。統計量を見てから有利な方に変えるのは禁止(第一種過誤が を超える)。向きは「何を主張したいか」だけで決まる。同じ なら片側のほうが棄却されやすい(臨界値が手前)ので、安易な片側化は危険。迷えば両側。
- も検定の前に決める。データを見てから「0.05では有意にならないので0.10に」と動かすのは禁止。
- 両側検定の臨界確率は 。 の両側なら各端2.5%で臨界値1.96。片側の臨界値1.645(5%)と混同しない。「両側5%=1.96」「片側5%=1.645」をセットで覚える。
- p値が小さい=効果が大きい、ではない。p値は「差の有無の証拠の強さ」であって「差の大きさ」ではない。 が巨大なら実質ゼロの差でもp値は小さくなる(ASA声明の指摘)。効果の大きさは別途、効果量や信頼区間で見る。
- 棄却域方式とp値方式は必ず一致する。「統計量が棄却域に入る」⟺「」。両者で結論が食い違ったら計算ミス。
よくある疑問
Q1. なぜ証明したい「効く」を直接検定せず、わざわざ「効かない()」を立てるんですか?回りくどくないですか? A. 「効かない(差がぴったり0)」と決め打つと、検定統計量の分布が1つに定まるからです。 と置けば がどう分布するか計算できる。一方「効く(差がある)」は「どれくらい効くか」が無数にあって分布を1本に描けません。確率計算できるのは の側だけ。だから を仮定して「もし が本当ならこのデータは滅多に出ない」を示し、背理法的に を棄却して「効く」を間接的に主張します。数学の「 が有理数と仮定して矛盾を導く」と同じ構造です。
Q2. p値が「 が正しい確率」じゃないなら、結局何を表しているんですか? A. 「 が正しいと仮定したうえで、今回観測されたのと同じかそれ以上に極端なデータが得られる確率」です。式で言えば 。 を真と仮定したときの「データの珍しさ」を測る量であって、 そのものの確率ではありません。 と は条件付き確率の向きが逆で、一般に一致しない(後者の計算には の事前確率が要り、それはベイズの領域)。頻度論では は真か偽かのどちらかで、確率を持ちません。
Q3. p = 0.04 で「有意差あり」、p = 0.06 で「有意差なし」。たった0.02差でそんなに違う結論になるのは変では? A. ご指摘は本質的で、ASAも同じ問題を指摘しています。 という境界は便宜的な約束事であって、自然界の真理の境目ではありません。p=0.04とp=0.06は証拠の強さとしてほぼ同じで、片方だけを「真」、もう片方を「無」と二分するのは過度な単純化です。だから近年は「p値だけで0/1の結論を出さず、効果の大きさ(効果量)や信頼区間も併せて報告する」のが推奨されています。試験では を基準に機械的に判定しますが、実務ではp値を「証拠の連続的な強さ」として読むのが正しい姿勢です。
Q4. 「 を棄却できなかった」とき、「 は正しい」と言ってはいけない理由をもう一度。 A. 検定は最初から を守る側に偏って設計されているからです。 は「 が正しいのに棄却する過ち」だけを抑える設計で、逆方向の過ち( が偽なのに棄却できない=第二種過誤 )は制御していません。標本が少ない・効果が小さいと、本当は差があっても棄却できないことは普通に起きます。だから棄却できないのは「差がある証拠が足りなかった」だけで、「差がない証明」ではない。裁判の無罪が「やった証拠不十分」であって「やっていない証明」ではないのと同じです。正しい言い方は「差があるとは言えない」。詳しくは 第一種の過誤・第二種の過誤・検出力(2種類の誤りとトレードオフ・サンプルサイズ設計) へ。
Q5. 片側検定と両側検定、どちらを使えばいいか迷います。基準はありますか? A. 「主張したいことが向きを持つか」で決めます。「下がる」「増える」のように一方向だけ知りたいなら片側、「変わったかどうか(上下どちらでも異常)」なら両側。ただし2点注意。(1) データを見る前に決めること(後出しは禁止)。(2) 片側は同じ でも棄却されやすい(臨界値が手前)ので、根拠が弱いまま片側にすると「有意に見せかける」ことになりかねません。逆向きの結果(薬で逆に悪化)を完全に無視してよい確かな理由がある場合だけ片側、迷ったら両側(保守的)が安全です。試験問題では問題文の言い回し(「効果があるか」=両側/「下がるか」=片側)で判断します。
Q6. 検定統計量が「棄却域に入るか」と「p値が 以下か」、どちらで判定すればいいですか? A. どちらでも同じ結論になります。両者は完全に同値で、「統計量が棄却域に入る」⟺「」。臨界値(例1.96)と統計量を直接比べるのが棄却域方式、統計量を裾の確率に直して と比べるのがp値方式です。手計算で臨界値が表から引けるなら棄却域方式が速く、ソフトがp値を出してくれるならp値方式が直接的。試験ではどちらの形式でも問われるので、両方できるようにしておきます。もし両者で結論が食い違ったら、それは計算ミスのサインです。
まとめ
- 仮説検定は、母集団についての主張を標本データから確率的に判定する手続き。「差がない」という帰無仮説 を立て、それが観測データと矛盾するかを背理法的に調べる。確率計算できるのは を仮定した側だけだから、否定したい仮説を主役に据える。
- (否定したい・等号あり)と (主張したい・等号なし)。対立仮説の形で片側/両側が決まり、向きはデータを見る前に確定する。
- 手順は ①仮説 → ②有意水準 → ③検定統計量 → ④p値 or 棄却域で判定。 など、 のもとで分布が分かる量を使う。棄却域は確率 の「滅多にない」領域。
- p値=「 を仮定したとき観測値以上に極端なデータが出る確率」。 で棄却。p値は「 が正しい確率」では断じてない(条件の向きが逆)── 最重要の誤解。
- 「棄却できない」≠「 が正しい」。証拠不十分であって肯定ではない(検定の非対称性)。 は第一種過誤( が真なのに棄却)の確率の上限で、ここから 第一種の過誤・第二種の過誤・検出力(2種類の誤りとトレードオフ・サンプルサイズ設計) へつながる。
- 仮説検定と区間推定(母平均・母比率・母分散の信頼区間)は双対: 信頼区間に が含まれない ⟺ 両側検定で を棄却(対称な両側検定の場合)。
- 試験での問われ方(2級): の正しい設定、p値・有意水準・棄却域の関係、p値の誤解の指摘、片側/両側の判断、具体的な統計量の計算と判定。各検定の計算は 母平均の検定(1標本・2標本t検定) 以降の各論へ。
関連ノート
- 点推定(推定量の良さ:不偏性・一致性・有効性・十分性) … 検定統計量の材料となる推定量( など)と頻度論の枠組み(母数は定数で確率を持たない)
- 区間推定(母平均・母比率・母分散の信頼区間) … 仮説検定と双対の関係。両側検定と信頼区間の対応
- 正規分布(標準正規・標準化) … 検定統計量 の帰無分布。臨界値1.96・1.645の出どころ
- 標本平均・標本比率の標本分布(標準誤差) … 標本平均・標本比率を標準化して検定統計量を作る土台
- t分布・カイ二乗分布・F分布(標本分布の三役) … 分散未知の母平均検定(t分布)・分散の検定(カイ二乗)で使う帰無分布
- 第一種の過誤・第二種の過誤・検出力(2種類の誤りとトレードオフ・サンプルサイズ設計) … 有意水準 =第一種過誤の確率。棄却できない過ち(第二種過誤)と検出力(前方リンク)
- 母平均の検定(1標本・2標本t検定) … この枠組みを母平均の具体的な検定に適用する各論(前方リンク)