📊 対象級:2級 | 重要度:A(頻出)
区間推定(母平均・母比率・母分散の信頼区間)
要点(BLUF)
- 区間推定:母数 (母平均・母比率・母分散など)を1つの値ではなく幅のある区間 で見積もること。点推定(点推定(推定量の良さ:不偏性・一致性・有効性・十分性))が「母平均は52.3」と言い切るのに対し、区間推定は「母平均は の範囲にありそう」と不確かさを区間の幅で表現します。この区間を**信頼区間(confidence interval, CI)**と呼びます。
- 信頼係数 の正しい意味(最重要・最頻出の誤解):信頼係数95%とは「同じ手順で標本抽出と区間計算を何度も繰り返すと、作られる区間の95%が母数を含む」という頻度論的な意味です。「母数が区間に入る確率が95%」は誤り。母数 は未知だが定数で、ランダムに動くのは区間の方。これをⓆ&Aと⚠️で徹底的に潰します。
- 3つの基本ケースの公式:
| 推定対象 | 条件 | 信頼区間(信頼係数 ) | 使う分布 |
|---|---|---|---|
| 母平均 | 既知 | 標準正規 | |
| 母平均 | 未知 | 分布(自由度 ) | |
| 母比率 | 大(正規近似) | 標準正規 | |
| 母分散 | 母集団が正規 | カイ二乗分布(非対称) |
- 共通の骨格:すべて「点推定値 ± (臨界値)×(標準誤差)」の形(母分散だけ非対称なので例外)。標準誤差 等が推定量のばらつきを表し、臨界値が信頼係数を決めます。
- 検定との双対性:信頼区間に含まれない値は、対応する両側検定で有意水準 で棄却される。区間推定と仮説検定(仮説検定の枠組み(帰無仮説・対立仮説・p値・有意水準))はコインの裏表です。
本文
1. 区間推定とは何か:点推定の不確かさを区間で表す
点推定(点推定(推定量の良さ:不偏性・一致性・有効性・十分性))は母数 を1つの値で言い当てます。標本平均 、標本比率 など。しかし点推定値は標本ごとに変わる確率変数の実現値なので、「ピッタリ当たっている保証」はどこにもありません。標本を取り直せば違う値が出る。
そこで「真値はこの範囲にありそうだ」と、幅のある区間で見積もるのが区間推定です。
- 点推定:(1点。当たり外れの不確かさが見えない)
- 区間推定:(区間。幅が不確かさの大きさを表す)
区間が狭いほど精密な推定、広いほど不確かさが大きい。区間推定の値打ちは、点推定が捨ててしまう「どれくらい確からしいか」を区間の幅と信頼係数という形で定量化するところにあります。
graph LR
A["標本<br/>X₁,…,Xₙ"] --> B["点推定<br/>θ̂ = 52.3<br/>1つの値"]
A --> C["区間推定<br/>θ ∈ [50.1, 54.5]<br/>幅のある区間"]
B -.->|不確かさが<br/>見えない| D["?"]
C -->|幅 = 不確かさ<br/>信頼係数 = 確からしさ| E["不確かさを<br/>定量化"]
style B fill:#fff0e8
style C fill:#e8f4ff
style E fill:#e8f4ff
2. 信頼区間と信頼係数の定義
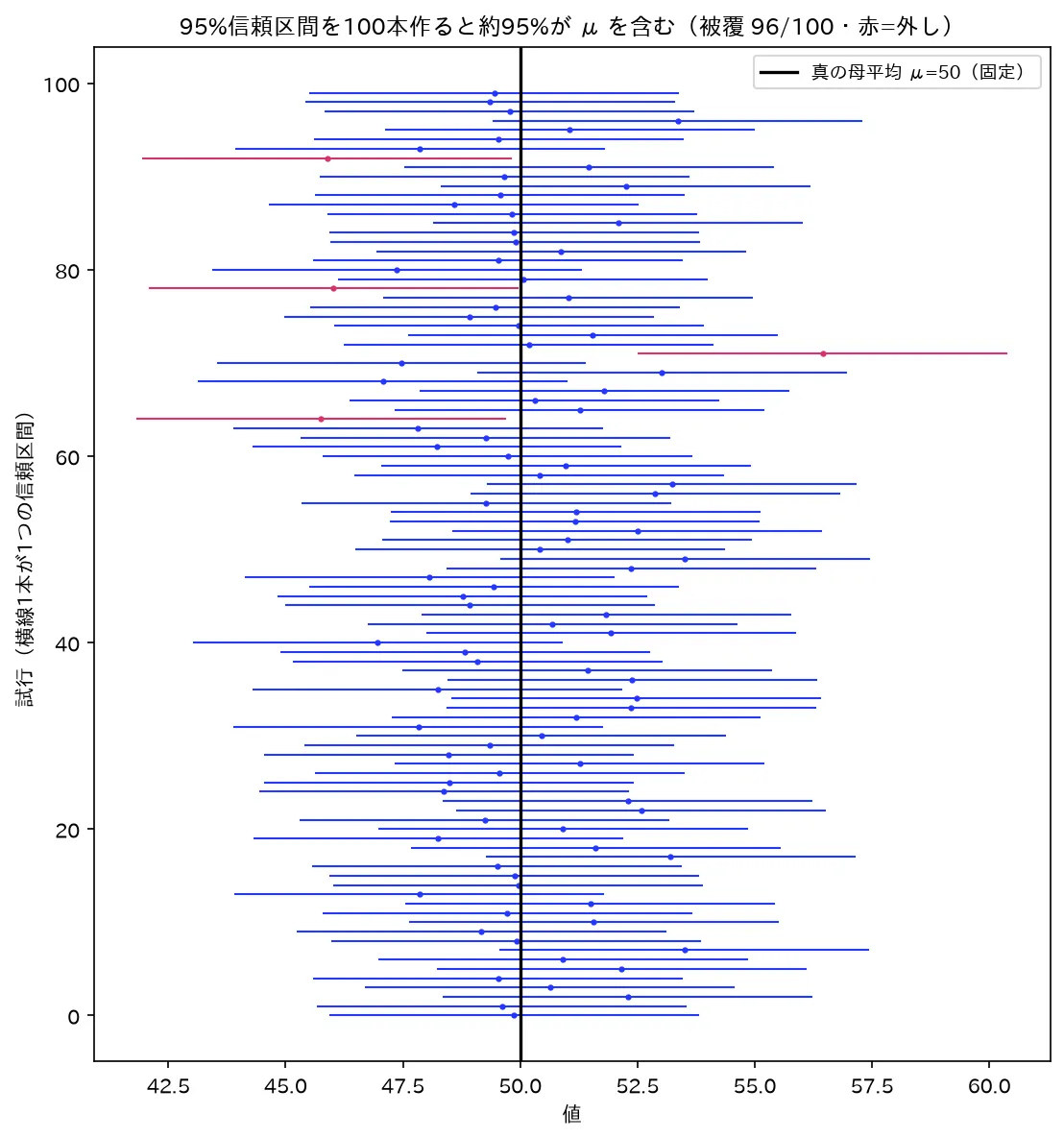
μ=50・σ=10既知・n=25 で95%区間を100本作ると約95%が真値 μ を含む(赤=外し)。ランダムに動くのは区間の方で μ は固定。図は simulations/shinrai_kukan_hifuku.py で生成。
定義:母数 の 信頼係数(confidence level) の信頼区間とは、標本から計算される2つの統計量 、 で作る区間 であって、 を満たすもの。 を 有意水準(または危険率)と呼び、典型的には (信頼係数95%)や (99%)。
要するに:「区間が母数 を捕まえる確率が 」になるように、区間の端 を標本から作る。ここで確率の意味を正確に読む必要があります(次節)。
2.1 確率は「区間の方」にかかっている(決定的に重要)
上の式 でランダムなのはどれか。これが区間推定の最大の急所です。
- (母数):未知だが定数。ランダムではない。
- (区間の端):標本 の関数なので確率変数。標本を取り直せば値が変わる。
つまり は、**「ランダムに動く区間 が、固定された的 を捕まえる確率」**です。的()は動かず、投げる輪(区間)の方が標本ごとに飛び散る。輪投げで、的は固定・輪の落ちる場所がランダム、というイメージです。
graph TD
T["母数 θ(固定された的・定数)"]
S1["標本①→区間 [49,53] ○含む"] -.-> T
S2["標本②→区間 [50,54] ○含む"] -.-> T
S3["標本③→区間 [55,59] ✕外す"] -.-> T
S4["標本④→区間 [48,52] ○含む"] -.-> T
S5["…多数回繰り返すと…"] -.-> T
R["作った区間の 100(1-α)% が θ を含む"]
style T fill:#ffe8e8
style S3 fill:#ffd0d0
style R fill:#e8f4ff
2.2 信頼係数95%の正しい解釈(試験で最も狙われる)
信頼係数95%の正しい読み:「母集団から標本を取り、95%信頼区間を作る」という作業を多数回(例:100回)繰り返すと、作られた区間のうち約95回(95%)が母数 を含む。
逆に約5回(5%)は外す。どの1つの区間も、母数を含むか含まないかの2択(確率ではなく、含むか含まないかが既に決まっている)であって、特定の1区間について「95%の確率で母数が入る」とは言えません。この「95%」は確率ではなく信頼率(または被覆確率)と呼ばれます。
⚠️ 最頻出の誤答:「母平均が、求めた区間 に95%の確率で入る」── これは誤り。母平均は定数なので、この特定の区間に入っているか・いないかのどちらかで、確率は0か1(既に決まっている、人間が知らないだけ)。確率95%が言えるのは区間を作る手順に対してであって、出来上がった1つの区間に対してではありません。試験では選択肢でこの違いを突いてきます。
3. 母平均の区間推定(σ既知):標準正規分布を使う
最もシンプルなケースから組み立てます。母分散 が既知(=値が分かっている)とき。
3.1 出発点:標本平均の標準化
母平均 ・母分散 の母集団から無作為標本 (i.i.d.)を取ると、標本平均 は(標本平均・標本比率の標本分布(標準誤差))
母集団が正規分布なら がそのまま成り立ち、正規でなくても が大きければ中心極限定理(中心極限定理(CLT))で近似的に成り立ちます。これを標準化すると:
要するに:標本平均 から真の中心 を引き、ばらつきの尺度 で割れば、標準正規分布に従う変数 になる。分母の を 標準誤差(standard error, SE) と呼びます。
3.2 標準誤差 の意味
標準誤差 は「標本平均 がどれくらいばらつくか」を表す標準偏差です。母集団の標準偏差 をそのまま使わず で割るのがポイント。
要するに:個々のデータは だけばらつくが、 個平均すると打ち消し合ってばらつきが に縮む。 を4倍にすれば標準誤差は半分、 を100倍にすれば になる。標本を増やすほど標本平均は安定し、信頼区間も狭くなる根拠がこの です。
3.3 区間の組み立て
標準正規分布で、中央に確率 が入るように両側を ずつ切ります。その境界を 臨界値 とすると(上側 点。例: なら ):
を代入して、不等式を について解きます:
よって母平均の信頼区間( 既知):
要するに:点推定値 を中心に、左右へ「臨界値 × 標準誤差」だけ広げた区間。この を 誤差の限界(margin of error) と呼びます。信頼係数を上げる( を小さくする)と が大きくなり区間が広がる ── 確実性と狭さはトレードオフです。
3.4 数値例(σ既知)
ある製品の重量が母標準偏差 g と分かっている。 個を測ったら標本平均 g だった。母平均の95%信頼区間は?
- 標準誤差:。
- 臨界値:。
- 誤差の限界:。
- 信頼区間:。
「母平均は95%信頼区間 」と結論します(同じ手順を繰り返せば95%の区間が真の母平均を含む、の意味)。
4. 母平均の区間推定(σ未知):なぜ t 分布・自由度 n−1 なのか
現実には母分散 が分かっていることはまずありません。 を標本から推定した不偏分散 で置き換えるのが自然な発想ですが、ここで分布が正規から 分布に変わります。なぜか ── ここが2級の理論的山場です。
4.1 を に置き換えると何が起きるか
既知のときの標準化変数は でした。 を不偏分散の平方根 で置き換えた量を とします:
この は標準正規分布には従いません。なぜなら分母の 自体が標本ごとに変動する確率変数だから。 では分母 が定数だったのに対し、 では分子 も分母 も両方ランダム。分母が小さめに出た標本では が大きく振れるため、 の分布は より裾が重く(外れ値が出やすく)なります。これが 分布です。
4.2 t 分布の構成と自由度 n−1 の出どころ(完全導出)
が従う分布を厳密に特定します。母集団が正規 のとき、次の2つの事実が鍵です(t分布・カイ二乗分布・F分布(標本分布の三役))。
事実1:標準化した標本平均は標準正規。
事実2:不偏分散を母分散で割って自由度倍した量はカイ二乗分布に従う。 (この自由度 は、点推定で見た「不偏分散の自由度」── 拘束条件 が1本かかるため ── と同じ出どころです。点推定(推定量の良さ:不偏性・一致性・有効性・十分性) 参照。)
事実3:正規母集団では と は独立(正規分布に固有の性質)。
ここで 分布の定義:「標準正規 」を「独立なカイ二乗 を自由度 で割って平方根を取ったもの」で割った量は、自由度 の 分布に従う:
これに を当てはめて計算します:
分子分母の がきれいに消えて:
したがって
要するに: を で置き換えた量 は、計算すると「標準正規 ÷ √(カイ二乗/自由度)」の形になり、定義どおり自由度 の 分布に従う。途中で が約分で消えるので、 が未知でも計算できるようになったのが本質的な利得です。自由度 は不偏分散 の自由度をそのまま引き継いだもの。
4.3 区間の組み立て
既知の場合とまったく同じ要領で、 を に、 を に、 を に置き換えるだけ:
を について解いて:
要するに:構造は 既知のときと同じ「 ± 臨界値 × 標準誤差」。違いは (1) 標準誤差が (推定した を使う)、(2) 臨界値が ( より少し大きい)の2点だけ。 の臨界値が より大きいぶん、 未知の区間は既知のときより広くなる── これは「 も推定している不確かさ」が区間に上乗せされた結果で、理にかなっています。
4.4 分布と正規分布の関係(自由度で繋がる)
分布は正規分布より裾が重いですが、自由度 が大きくなる(標本が増える)と が に近づいて変動しなくなり、 分布は標準正規分布に収束します。
xychart-beta
title "t分布(自由度小)は正規分布より裾が重い"
x-axis "標準化した値" [-4, -3, -2, -1, 0, 1, 2, 3, 4]
y-axis "確率密度" 0 --> 0.45
line "標準正規 N(0,1)" [0.0001, 0.004, 0.054, 0.242, 0.399, 0.242, 0.054, 0.004, 0.0001]
line "t分布(自由度3)" [0.009, 0.023, 0.067, 0.201, 0.368, 0.201, 0.067, 0.023, 0.009]
中央が低く・両裾が高いのが 分布(自由度3)。だから同じ信頼係数でも臨界値が大きくなる(より外側まで取らないと95%入らない)。実務の目安として自由度30程度で両者はほぼ一致します。
⚠️ 試験での使い分け:「母分散 (または母標準偏差 )が与えられている」→ (正規)。「標本から を計算する/ が不明」→ (自由度 )。問題文がどちらを与えているかで一意に決まります。 が大きいからと 未知でも を使う近似は、2級では問題文の指示に従うのが安全(指示がなければ 未知は )。
4.5 数値例(σ未知)
ある成分の含有率を 個測ったら、標本平均 、不偏分散 ()だった。母平均の95%信頼区間は?
- 標準誤差:。
- 臨界値:自由度 の 分布の上側2.5%点 ( 分布表より)。
- 誤差の限界:。
- 信頼区間:。
もし同じ数値で が既知なら臨界値は となり、区間は 。 を使う方( 未知)が広いことが確認できます。
5. 母比率の区間推定:正規近似を使う
母集団における「ある属性を持つ割合」(支持率・不良率など)を区間推定します。
5.1 出発点:標本比率の標本分布
個の標本のうち成功(該当)が 個なら、(二項分布)。標本比率 は(標本平均・標本比率の標本分布(標準誤差))
が十分大きいとき、二項分布は正規分布で近似でき(中心極限定理、中心極限定理(CLT)):
Z=\frac{\hat p-p}{\sqrt{p(1-p)/n}}\ \dot\sim\ N(0,1).$$ ($\dot\sim$ は「近似的に従う」の意味。) #### 5.2 分母の $p$ を $\hat p$ で置き換える 標準誤差 $\sqrt{p(1-p)/n}$ には未知の $p$ が入っています。母平均の $\sigma$ 未知のときは $t$ 分布で厳密に処理しましたが、母比率では**標準誤差の $p$ を一致推定量 $\hat p$ で置き換える**近似を使います($n$ が大きければ $\hat p\approx p$ なので近似誤差は小さい)。すると標準誤差は $\sqrt{\hat p(1-\hat p)/n}$ となり、$\sigma$ 既知の母平均とまったく同じ形($z$ を使う)に持ち込めます: $$\boxed{\ \hat p\pm z_{\alpha/2}\sqrt{\frac{\hat p(1-\hat p)}{n}}\ }$$ **要するに**:母比率の信頼区間も「点推定値 $\hat p$ ± 臨界値 $z_{\alpha/2}$ × 標準誤差」の形。標準誤差の中の未知の $p$ を観測した $\hat p$ で埋めるのがポイント(これを **Wald 信頼区間** と呼びます)。 #### 5.3 適用条件(正規近似が使える目安) 正規近似は $n$ が大きく、$p$ が極端でない(0や1に近すぎない)ときに妥当です。実務の目安: $$n\hat p\ge5\quad\text{かつ}\quad n(1-\hat p)\ge5$$ (文献により $\ge10$ とする流儀もある ── **要最新確認**)。この条件が満たされないとき($n$ が小さい・$\hat p$ が0や1に近い)は、二項分布の正確な信頼区間(Clopper–Pearson 法など)を使うべきですが、これは2級の範囲外です。 > ⚠️ 標準誤差の中身は **$\hat p(1-\hat p)$** であって $\hat p$ 単独ではない。$\hat p(1-\hat p)$ は $\hat p=0.5$ のとき最大(=0.25)になるため、**同じ $n$ でも比率が50%付近のとき区間が最も広く**なります。世論調査の「誤差±◯%」は最悪ケースの $\hat p=0.5$ で見積もることが多いのはこのため。 #### 5.4 数値例(母比率) 200人にアンケートし、70人が「賛成」と回答した。母比率(賛成率)の95%信頼区間は? - 標本比率:$\hat p=70/200=0.35$。 - 適用条件:$n\hat p=200\times0.35=70\ge5$、$n(1-\hat p)=200\times0.65=130\ge5$。OK。 - 標準誤差:$\sqrt{\hat p(1-\hat p)/n}=\sqrt{0.35\times0.65/200}=\sqrt{0.0011375}\approx0.0337$。 - 臨界値:$z_{0.025}=1.96$。 - 誤差の限界:$1.96\times0.0337\approx0.066$。 - 信頼区間:$0.35\pm0.066=[0.284,\ 0.416]$。 「賛成率の95%信頼区間は約28.4%〜41.6%」と結論します。 --- ### 6. 母分散の区間推定:カイ二乗分布で非対称になる 母集団のばらつき(母分散 $\sigma^2$)そのものを区間推定します。**母集団が正規分布に従う**ことが前提です。 #### 6.1 出発点:不偏分散のカイ二乗分布 正規母集団 $N(\mu,\sigma^2)$ から標本を取ると、4.2の事実2より: $$W=\frac{(n-1)s^2}{\sigma^2}\sim\chi^2_{n-1}\quad(\text{自由度 }n-1\text{ のカイ二乗分布}).$$ **要するに**:不偏分散 $s^2$ を母分散 $\sigma^2$ で割って $(n-1)$ 倍した量が、自由度 $n-1$ のカイ二乗分布に従う。これを使って $\sigma^2$ を挟み込みます。 #### 6.2 区間の組み立て(非対称になる理由) カイ二乗分布は**左右非対称**(0以上の値しか取らず、右に裾を引く)。だから上側・下側の臨界値を別々に取ります。上側 $\alpha/2$ 点を $\chi^2_{\alpha/2,\,n-1}$、下側 $\alpha/2$ 点(=上側 $1-\alpha/2$ 点)を $\chi^2_{1-\alpha/2,\,n-1}$ として: $$P\!\left(\chi^2_{1-\alpha/2,\,n-1}\le W\le\chi^2_{\alpha/2,\,n-1}\right)=1-\alpha.$$ $W=\dfrac{(n-1)s^2}{\sigma^2}$ を代入し、$\sigma^2$ について解きます。各辺の逆数を取ると不等号の向きが反転する点に注意:\chi^2_{1-\alpha/2,,n-1}\le\frac{(n-1)s^2}{\sigma^2}\le\chi^2_{\alpha/2,,n-1} ;\Longleftrightarrow; \frac{(n-1)s^2}{\chi^2_{\alpha/2,,n-1}}\le\sigma^2\le\frac{(n-1)s^2}{\chi^2_{1-\alpha/2,,n-1}}.
よって母分散の信頼区間: $$\boxed{\ \frac{(n-1)s^2}{\chi^2_{\alpha/2,\,n-1}}\le\sigma^2\le\frac{(n-1)s^2}{\chi^2_{1-\alpha/2,\,n-1}}\ }$$ **要するに**:分子は共通の $(n-1)s^2$ で、左端は**大きい方の臨界値**(上側点)で割り、右端は**小さい方の臨界値**(下側点)で割る。逆数を取るので大小が入れ替わるのがポイント。カイ二乗分布が非対称なので、**点推定値 $s^2$ は区間の中央には来ません**(対称な $\pm$ 形にならない)。 > ⚠️ **左右の臨界値の取り違えが最頻出ミス**。「左端(下限)を上側点 $\chi^2_{\alpha/2}$ で、右端(上限)を下側点 $\chi^2_{1-\alpha/2}$ で割る」── 逆数を取ったせいで**大きい臨界値が下限に、小さい臨界値が上限に**回ります。$s^2$ が中央に来ない(非対称)のも母平均・母比率との決定的な違い。$\sigma$(標準偏差)の区間が欲しければ、最後に各辺の平方根を取ります。 #### 6.3 数値例(母分散) 正規母集団から $n=10$ 個取り、不偏分散 $s^2=8.0$ を得た。母分散の95%信頼区間は?(自由度 $n-1=9$、カイ二乗分布表より $\chi^2_{0.025,\,9}=19.02$、$\chi^2_{0.975,\,9}=2.70$) - 共通の分子:$(n-1)s^2=9\times8.0=72$。 - 下限:$72/\chi^2_{0.025,\,9}=72/19.02\approx3.79$。 - 上限:$72/\chi^2_{0.975,\,9}=72/2.70\approx26.67$。 - 信頼区間:$3.79\le\sigma^2\le26.67$。 点推定値 $s^2=8.0$ がこの区間の**中央(=15.23)ではない**ことに注目。非対称区間の典型です。 --- ### 7. 区間幅を決める3つの要因と標本サイズの設計 母平均($\sigma$ 既知)の区間幅 $2\,z_{\alpha/2}\,\sigma/\sqrt n$ を題材に、**何が区間の広さを決めるか**を整理します。これは「精度のいい調査を設計する」ための基礎です。 | 要因 | 大きくすると区間は | 直観 | |---|---|---| | 信頼係数 $1-\alpha$(→ $z_{\alpha/2}$) | **広がる** | 確実に当てたいほど広く取る必要がある | | 標本サイズ $n$ | **狭まる**($1/\sqrt n$) | データが多いほど標本平均が安定する | | 母標準偏差 $\sigma$ | **広がる** | 元のばらつきが大きいほど不確か | **要するに**:「確実性(信頼係数)」と「精度(区間の狭さ)」は $n$ を増やさない限りトレードオフ。確実性も精度も両方上げたいなら**標本を増やす**しかない。ただし区間幅は $1/\sqrt n$ でしか縮まないので、幅を半分にするには $n$ を**4倍**にする必要があります。 #### 7.1 必要標本サイズの逆算(設計問題) 「誤差の限界を $E$ 以下に抑えたい」という要求から必要な $n$ を逆算できます。誤差の限界は $z_{\alpha/2}\,\sigma/\sqrt n$ なので、 $$z_{\alpha/2}\frac{\sigma}{\sqrt n}\le E \;\Longleftrightarrow\; \sqrt n\ge\frac{z_{\alpha/2}\,\sigma}{E} \;\Longleftrightarrow\; \boxed{\ n\ge\left(\frac{z_{\alpha/2}\,\sigma}{E}\right)^2\ }$$ **要するに**:欲しい精度 $E$、信頼係数($z_{\alpha/2}$)、ばらつき $\sigma$ が決まれば、必要な標本数 $n$ が決まる。$n$ は $E$ の2乗に反比例(精度を2倍にすると $n$ は4倍)、$\sigma$ の2乗に比例。**端数は切り上げ**ます(条件を「以上」で満たすため)。 **数値例**:$\sigma=10$、95%信頼($z_{0.025}=1.96$)で誤差を $E=2$ 以下にしたい。 $$n\ge\left(\frac{1.96\times10}{2}\right)^2=(9.8)^2=96.04\ \Rightarrow\ n=97\ \text{個(切り上げ)}.$$ 母比率の場合は標準誤差が $\sqrt{p(1-p)/n}$ なので、$p$ が不明なら最悪ケース $p=0.5$($p(1-p)$ が最大の0.25)で見積もって $n\ge\left(\dfrac{z_{\alpha/2}}{2E}\right)^2$ とします。 --- ### 8. 検定との双対性:信頼区間は両側検定の裏返し 区間推定と仮説検定(仮説検定の枠組み(帰無仮説・対立仮説・p値・有意水準))は**同じ理論の表と裏**です。 > **双対性**:信頼係数 $1-\alpha$ の信頼区間に**含まれない**母数の値は、その値を帰無仮説とする**両側検定**で有意水準 $\alpha$ で**棄却**される。逆に区間に含まれる値は棄却されない。 **要するに**:95%信頼区間が $[48.46,\ 51.54]$ なら、「母平均は50である($H_0:\mu=50$)」という仮説は、50が区間内なので有意水準5%で**棄却されない**。一方「母平均は48である」なら48は区間外なので**棄却される**。区間推定で「ありそうな母数の範囲」を出すことと、検定で「ある特定値を棄却するか」を判断することは、同じ臨界値($z_{\alpha/2}$ や $t_{\alpha/2,n-1}$)で繋がっています。この関係は母平均の検定(母平均の検定(1標本・2標本t検定))・母比率や母分散の検定(母比率・母分散の検定)で本格的に使います。 ```mermaid graph LR A["信頼区間<br/>θ ∈ [L, U]"] -->|双対| B["両側検定<br/>H₀: θ = θ₀"] A -->|"θ₀ が区間内"| C["H₀ を棄却しない"] A -->|"θ₀ が区間外"| D["H₀ を棄却する"] style A fill:#e8f4ff style B fill:#fff0e8 ``` --- ## ⚠️ 引っかけポイント - **「母数が区間に入る確率95%」は誤り(最頻出)**。母数 $\theta$ は定数、ランダムなのは区間の方。確率95%が言えるのは**区間を作る手順**に対してであり、出来上がった1つの区間に対してではない。正しくは「同じ手順を多数回繰り返すと95%の区間が母数を含む」。 - **$z$ と $t$ の使い分け**。母分散 $\sigma^2$(母標準偏差 $\sigma$)が与えられていれば $z$(正規)、標本から $s$ を計算する/$\sigma$ 不明なら $t$(自由度 $n-1$)。問題文がどちらを与えているかで決まる。$\sigma$ 未知で $z$ を使うのは誤り(指示がない限り)。 - **$t$ 分布の自由度は $n-1$**。標本サイズ $n$ そのものではない。不偏分散 $s^2$ の自由度(拘束条件 $\sum(X_i-\bar X)=0$ が1本)を引き継ぐ。$t$ 分布表を引くとき自由度を $n$ にしてしまうミスが多い。 - **標準誤差 $\sigma/\sqrt n$ の $\sqrt n$**。母標準偏差 $\sigma$ をそのまま使うのではなく $\sqrt n$ で割る。標準偏差 $\sigma$ をそのまま誤差の限界に使う($\sqrt n$ を忘れる)と区間が過大になる。 - **母比率の標準誤差は $\sqrt{\hat p(1-\hat p)/n}$**。$\hat p$ 単独ではなく $\hat p(1-\hat p)$。これは $\hat p=0.5$ で最大なので、比率50%付近で区間が最も広い。 - **母分散の区間は非対称・臨界値の取り違え注意**。カイ二乗分布が非対称なので $s^2$ は区間の中央に来ない。逆数を取るため、下限は**大きい方**の臨界値 $\chi^2_{\alpha/2}$ で、上限は**小さい方** $\chi^2_{1-\alpha/2}$ で割る(大小が入れ替わる)。 - **信頼係数を上げると区間は広がる**。99%は95%より広い。「信頼係数を上げれば精度も上がる」は誤り ── 確実性と精度(狭さ)はトレードオフで、両立には $n$ を増やすしかない。 - **区間幅は $1/\sqrt n$ でしか縮まない**。幅を半分にするには $n$ を4倍。「$n$ を2倍にすれば区間は半分」は誤り。 - **正規近似の適用条件**。母比率の $z$ 近似は $n\hat p\ge5$ かつ $n(1-\hat p)\ge5$(目安、文献により10。**要最新確認**)。$n$ が小さい・$\hat p$ が極端なときは正確法が必要。 --- ## よくある疑問 **Q1. 「95%信頼区間に母平均が95%の確率で入る」と何が違うんですか?言い換えただけに見えます。** A. 決定的に違います。母平均 $\mu$ は**未知だが定数**で、ランダムに動きません。一方、信頼区間 $[L,\ U]$ は標本から計算するので、標本を取り直せば毎回違う区間が出る**確率変数**です。だから「$\mu$ がこの特定の区間 $[50.1,\ 54.5]$ に入る確率」は、$\mu$ が定数である以上、入っているか・いないかの**0か1**でしかない(人間が知らないだけ)。95%という数字は「**区間を作る手順**を多数回繰り返すと、作られた区間の95%が $\mu$ を捕まえる」という頻度の話で、出来上がった1つの区間の話ではありません。輪投げで「的($\mu$)は固定・輪(区間)の落ちる場所がランダム」というイメージです。試験ではこの区別が選択肢で問われます。 **Q2. なぜ $\sigma$ が未知だと $t$ 分布なんですか?$s$ を $\sigma$ の代わりに入れるだけなら正規分布のままで良くないですか?** A. 分母が確率変数になるからです。$\sigma$ 既知のとき $Z=\frac{\bar X-\mu}{\sigma/\sqrt n}$ の分母 $\sigma$ は**定数**でした。これを $s$ に置き換えると、分子 $\bar X$ だけでなく分母 $s$ も**標本ごとに変動する確率変数**になります。$s$ が小さめに出た標本では $T$ が大きく振れるので、$T$ の分布は正規分布より**裾が重く**なる ── これが $t$ 分布です。厳密には、$T=\frac{\bar X-\mu}{s/\sqrt n}$ を変形すると「標準正規 $Z$ ÷ √(自由度 $n-1$ のカイ二乗 / $n-1$)」の形になり、$t$ 分布の定義そのものになります(本文4.2で導出。途中で $\sigma$ が約分で消えるので $\sigma$ 未知でも計算できる)。標本が増えれば $s$ が $\sigma$ に近づいて変動しなくなるので、$t$ 分布は正規分布に収束します(自由度30程度でほぼ一致)。 **Q3. 自由度 $n-1$ の「$-1$」はどこから来るんですか?標本は $n$ 個あるのに。** A. 不偏分散 $s^2$ を計算するときに自由度を1つ使うからです。$s^2=\frac{1}{n-1}\sum(X_i-\bar X)^2$ には、$\bar X$ をデータから決めたせいで拘束条件 $\sum(X_i-\bar X)=0$ が1本かかります。$n$ 個のズレ $X_i-\bar X$ のうち、$n-1$ 個が決まれば最後の1個は自動的に決まる ── だから自由に動けるのは $n-1$ 個。この $n-1$ が不偏分散の自由度であり、$\frac{(n-1)s^2}{\sigma^2}\sim\chi^2_{n-1}$ のカイ二乗の自由度であり、それを引き継いだ $t$ 分布の自由度でもあります。点推定(点推定(推定量の良さ:不偏性・一致性・有効性・十分性))で「なぜ不偏分散は $n-1$ で割るか」を理解していれば、区間推定の自由度はその直接の帰結です。 **Q4. 母分散の信頼区間だけ $\pm$ の形じゃなくて、なぜ上と下で割る値が違うんですか?** A. カイ二乗分布が**左右非対称**だからです。母平均や母比率は正規分布・$t$ 分布(左右対称)を使うので、臨界値が中央から左右に同じだけ離れ、区間が「点推定値 ± 誤差」の対称形になります。一方カイ二乗分布は0以上の値しか取らず右に裾を引く非対称な形なので、上側 $\alpha/2$ 点 $\chi^2_{\alpha/2}$ と下側 $\alpha/2$ 点 $\chi^2_{1-\alpha/2}$ は中央から非対称な位置にあります。さらに $W=\frac{(n-1)s^2}{\sigma^2}$ を $\sigma^2$ について解くとき**逆数を取る**ので不等号の向きが反転し、大きい臨界値が下限側・小さい臨界値が上限側に回ります。結果として点推定値 $s^2$ は区間の中央には来ません。これが母平均・母比率との形の違いです。 **Q5. 区間が広すぎて使えないとき、どうすれば狭くできますか?信頼係数を下げればいいんですか?** A. 手は3つありますが、実質的に有効なのは標本を増やすことだけです。(1) **信頼係数を下げる**(95%→90%)と臨界値 $z_{\alpha/2}$ が小さくなり区間は狭まりますが、「外す確率」が上がるので確実性を犠牲にしているだけ ── 精度が上がったわけではありません。(2) **ばらつき $\sigma$ を下げる**のは測定方法の改善などで可能ですが母集団の性質なので自由には動かせない。(3) **標本サイズ $n$ を増やす**のが王道で、これだけが確実性を保ったまま区間を狭めます。ただし区間幅は $1/\sqrt n$ でしか縮まないので、幅を半分にするには $n$ を4倍にする必要があります。「どれくらいの $n$ が必要か」は誤差の限界 $E$ から $n\ge(z_{\alpha/2}\sigma/E)^2$ で逆算できます(本文7.1)。 **Q6. 標本比率 $\hat p$ の信頼区間で、標準誤差の中の $p$ を $\hat p$ で置き換えていいんですか?厳密じゃない気がします。** A. 厳密ではなく近似(Wald 信頼区間)です。本来の標準誤差は $\sqrt{p(1-p)/n}$ で未知の $p$ を含みますが、$\hat p$ は $p$ の一致推定量なので $n$ が大きければ $\hat p\approx p$ となり、置き換えの誤差は小さくなります。だから適用には $n\hat p\ge5$ かつ $n(1-\hat p)\ge5$ という条件($n$ が大きく $\hat p$ が極端でない)が要ります。母平均の $\sigma$ 未知のときは $t$ 分布で厳密に処理できたのに対し、母比率では二項分布が離散なため厳密な区間(Clopper–Pearson 法)が複雑で、2級では正規近似のWald区間を使います。$n$ が小さい・$\hat p$ が0や1に近いときは近似が崩れるので、その場合は正確法が必要(2級の範囲外)。 --- ## まとめ - **区間推定**は母数 $\theta$ を1点でなく**幅のある区間**で見積もり、点推定が捨てる不確かさを区間の幅と信頼係数で定量化する。 - **信頼係数 $1-\alpha$ の正しい意味(最重要)**:「同じ手順を多数回繰り返すと作られる区間の $100(1-\alpha)\%$ が母数を含む」。**「母数が区間に入る確率」ではない**(母数は定数、ランダムなのは区間)。 - **3ケースの公式(すべて「点推定値 ± 臨界値 × 標準誤差」、母分散だけ非対称)**: - 母平均($\sigma$ 既知):$\bar X\pm z_{\alpha/2}\,\sigma/\sqrt n$ - 母平均($\sigma$ 未知):$\bar X\pm t_{\alpha/2,\,n-1}\,s/\sqrt n$($s$ が確率変数になるため $t$ 分布、自由度 $n-1$) - 母比率:$\hat p\pm z_{\alpha/2}\sqrt{\hat p(1-\hat p)/n}$(正規近似、適用条件 $n\hat p\ge5$ 等) - 母分散:$\dfrac{(n-1)s^2}{\chi^2_{\alpha/2,\,n-1}}\le\sigma^2\le\dfrac{(n-1)s^2}{\chi^2_{1-\alpha/2,\,n-1}}$(カイ二乗、非対称) - **なぜ $\sigma$ 未知で $t$ か**:$\sigma$ を $s$ に置き換えると分母が確率変数になり、$T$ は「標準正規 ÷ √(カイ二乗/自由度)」=自由度 $n-1$ の $t$ 分布に従う。自由度 $n-1$ は不偏分散の自由度を引き継いだもの。 - **区間幅を決める3要因**:信頼係数(上げると広い)・標本サイズ $n$(増やすと $1/\sqrt n$ で狭い)・ばらつき $\sigma$(大きいと広い)。確実性と精度のトレードオフは $n$ を増やして解消する。必要標本数は $n\ge(z_{\alpha/2}\sigma/E)^2$ で逆算。 - **検定との双対性**:信頼区間に含まれない値は両側検定で棄却される。区間推定と仮説検定(仮説検定の枠組み(帰無仮説・対立仮説・p値・有意水準))は同じ理論の表裏。 --- ## 関連ノート - 点推定(推定量の良さ:不偏性・一致性・有効性・十分性) … 区間推定の出発点。不偏分散がなぜ $n-1$ で割るか(区間推定の自由度 $n-1$ の根拠) - 正規分布(標準正規・標準化) … 標準正規分布と臨界値 $z_{\alpha/2}$($z_{0.025}=1.96$ など) - 標本平均・標本比率の標本分布(標準誤差) … $\bar X$・$\hat p$ の標本分布と標準誤差 $\sigma/\sqrt n$、$\sqrt{p(1-p)/n}$ - t分布・カイ二乗分布・F分布(標本分布の三役) … $\sigma$ 未知の $t$ 分布、母分散のカイ二乗分布(区間推定で使う分布の本体) - 中心極限定理(CLT) … 正規でない母集団でも $\bar X$・$\hat p$ が近似的に正規になる根拠 - 最尤法・モーメント法(推定量の作り方と最尤推定量の漸近論) … 推定量の作り方(点推定値の出どころ) - 仮説検定の枠組み(帰無仮説・対立仮説・p値・有意水準) … 区間推定と双対な仮説検定の枠組み(前方リンク) - 母平均の検定(1標本・2標本t検定) … 母平均の信頼区間と双対な $z$ 検定・$t$ 検定(前方リンク) - 母比率・母分散の検定 … 母比率・母分散の信頼区間と双対な検定(前方リンク)