← 統計検定テキスト 一覧
📊 対象級:準1級 ・ 1級 | 重要度:A(頻出)
最尤法・モーメント法(推定量の作り方と最尤推定量の漸近論)
要点(BLUF)
方法 原理 ひとことで 最尤法(MLE) 観測データを最も起こりやすくする母数を選ぶ 尤度 L ( θ ) L(\theta) L ( θ ) θ ^ \hat\theta θ ^ モーメント法(MM) 標本モーメント=母モーメントを解く 1 n ∑ X i k = E [ X k ] \frac1n\sum X_i^k = E[X^k] n 1 ∑ X i k = E [ X k ]
最尤法 :データ x 1 , … , x n x_1,\dots,x_n x 1 , … , x n θ \theta θ 尤度関数 L ( θ ) = ∏ i f ( x i ; θ ) L(\theta)=\prod_i f(x_i;\theta) L ( θ ) = ∏ i f ( x i ; θ ) θ \theta θ 対数尤度 ℓ ( θ ) = ∑ i log f ( x i ; θ ) \ell(\theta)=\sum_i \log f(x_i;\theta) ℓ ( θ ) = ∑ i log f ( x i ; θ ) 尤度方程式 ∂ ℓ ∂ θ = 0 \dfrac{\partial\ell}{\partial\theta}=0 ∂ θ ∂ ℓ = 0 MLEの強力な性質(主に1級) :一致性・漸近正規性 n ( θ ^ − θ ) → d N ( 0 , 1 / I 1 ( θ ) ) \sqrt n(\hat\theta-\theta)\xrightarrow{d}N\!\left(0,\,1/I_1(\theta)\right) n ( θ ^ − θ ) d N ( 0 , 1/ I 1 ( θ ) ) 不変性 (g ( θ ) g(\theta) g ( θ ) g ( θ ^ ) g(\hat\theta) g ( θ ^ ) 有限標本では不偏とは限らない (正規分布の σ ^ 2 \hat\sigma^2 σ ^ 2 モーメント法 :計算が容易で一致性も持つが、効率(分散)で MLE に劣ることがある。最重要の誤解2つ :(1)「尤度は確率ではない 」── L ( θ ) L(\theta) L ( θ ) θ \theta θ θ \theta θ MLEは常に不偏 」── 誤り。MLE は漸近的に良いが、有限標本ではバイアスを持ちうる。
本文
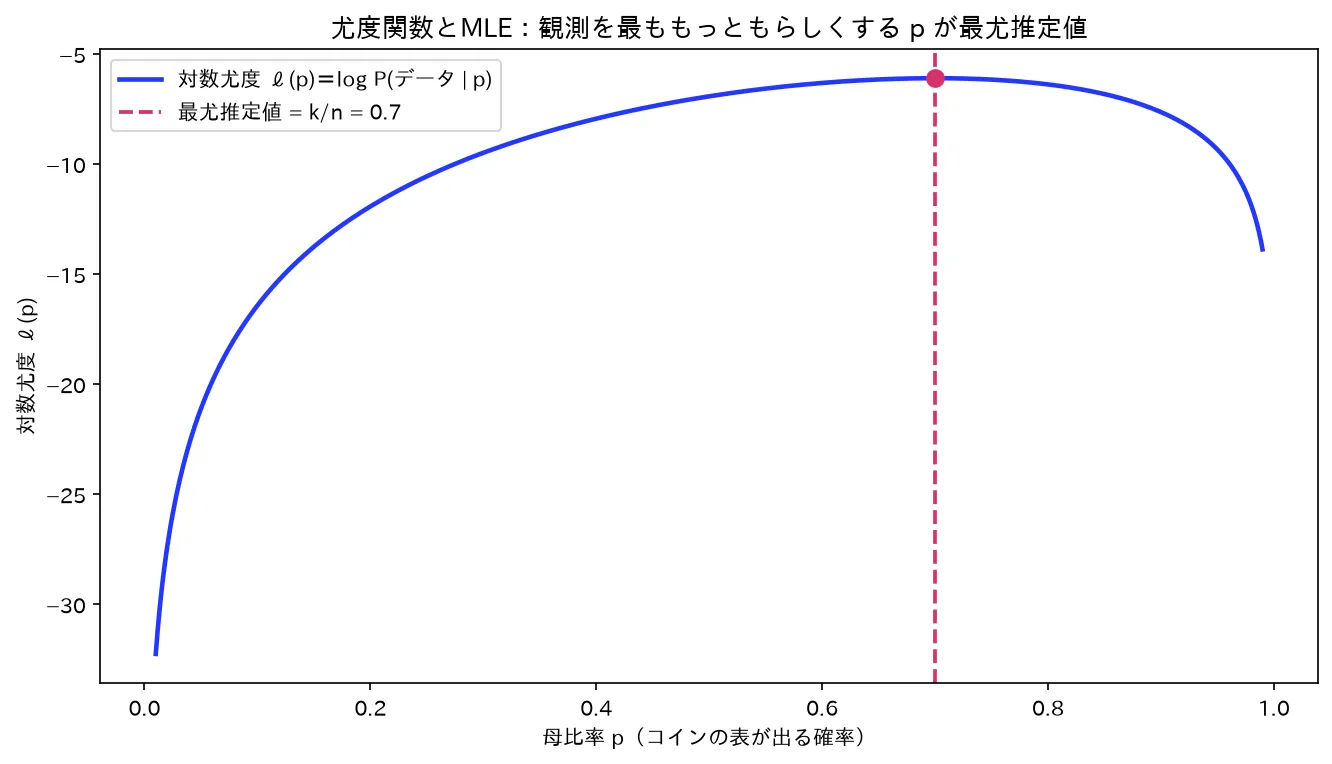
1. 最尤法の原理:データを最も起こりやすくする母数を選ぶ
コイン10回中7回表のときの対数尤度。頂点 p=0.7(=k/n)が最尤推定値。図は simulations/yuudo_mle_keijou.py で生成。
母数 θ \theta θ X 1 , … , X n X_1,\dots,X_n X 1 , … , X n x 1 , … , x n x_1,\dots,x_n x 1 , … , x n f ( x ; θ ) f(x;\theta) f ( x ; θ )
f ( x 1 , … , x n ; θ ) = ∏ i = 1 n f ( x i ; θ ) . f(x_1,\dots,x_n;\theta)=\prod_{i=1}^n f(x_i;\theta). f ( x 1 , … , x n ; θ ) = ∏ i = 1 n f ( x i ; θ ) .
ここで視点を反転させます。 いつもは「θ \theta θ x x x x x x θ \theta θ 尤度関数(likelihood function) と呼びます:
L ( θ ) = L ( θ ∣ x 1 , … , x n ) = ∏ i = 1 n f ( x i ; θ ) \boxed{\,L(\theta)=L(\theta\mid x_1,\dots,x_n)=\prod_{i=1}^n f(x_i;\theta)\,} L ( θ ) = L ( θ ∣ x 1 , … , x n ) = i = 1 ∏ n f ( x i ; θ )
定義(最尤推定量) :尤度 L ( θ ) L(\theta) L ( θ ) θ \theta θ 最尤推定量(Maximum Likelihood Estimator, MLE) と呼び、θ ^ M L \hat\theta_{\mathrm{ML}} θ ^ ML θ ^ M L = arg max θ L ( θ ) . \hat\theta_{\mathrm{ML}}=\arg\max_{\theta}\ L(\theta). θ ^ ML = arg max θ L ( θ ) .
要するに :手元のデータ x 1 , … , x n x_1,\dots,x_n x 1 , … , x n p p p p = 0.7 p=0.7 p = 0.7 p ^ = 0.7 \hat p=0.7 p ^ = 0.7
flowchart TD
A["確率分布 f(x;θ)<br/>θを固定し x を動かす<br/>(データの出方)"] -->|視点を反転| B["尤度 L(θ)=∏ f(xᵢ;θ)<br/>x を固定し θ を動かす<br/>(母数の関数)"]
B --> C["対数を取る<br/>ℓ(θ)=Σ log f(xᵢ;θ)<br/>積→和で扱いやすく"]
C --> D["尤度方程式<br/>∂ℓ/∂θ=0 を解く"]
D --> E["最尤推定量 θ̂_ML"]
style B fill:#e8f4ff
style E fill:#ffe8e8
2. 対数尤度と尤度方程式:なぜ log を取るのか
L ( θ ) L(\theta) L ( θ ) 対数 を取って積を和に変えます。対数は単調増加関数 なので、L ( θ ) L(\theta) L ( θ ) θ \theta θ log L ( θ ) \log L(\theta) log L ( θ ) θ \theta θ 完全に同じ です(最大化点は変わらない)。
定義(対数尤度) :
ℓ ( θ ) = log L ( θ ) = ∑ i = 1 n log f ( x i ; θ ) . \ell(\theta)=\log L(\theta)=\sum_{i=1}^n \log f(x_i;\theta). ℓ ( θ ) = log L ( θ ) = ∑ i = 1 n log f ( x i ; θ ) .
これを θ \theta θ 尤度方程式(likelihood equation) :
∂ ℓ ( θ ) ∂ θ = ∑ i = 1 n ∂ ∂ θ log f ( x i ; θ ) = 0 \boxed{\,\frac{\partial \ell(\theta)}{\partial\theta}=\sum_{i=1}^n \frac{\partial}{\partial\theta}\log f(x_i;\theta)=0\,} ∂ θ ∂ ℓ ( θ ) = i = 1 ∑ n ∂ θ ∂ log f ( x i ; θ ) = 0
要するに :「対数尤度のグラフの傾きが0になる点」を探す ── これが最尤推定量。ℓ \ell ℓ θ \theta θ ∂ ℓ ∂ θ \dfrac{\partial\ell}{\partial\theta} ∂ θ ∂ ℓ スコア関数(score function) と呼び、後の漸近論の主役になります。
⚠️ 尤度方程式を解いて出た点が本当に最大 かは、二階微分 ∂ 2 ℓ ∂ θ 2 < 0 \dfrac{\partial^2\ell}{\partial\theta^2}<0 ∂ θ 2 ∂ 2 ℓ < 0 端点 で達することもある(一様分布など)ので、微分が0にならない型の問題もあります。
log を取る実用的な理由は3つ:(1) 積が和になり微分が楽、(2) 指数型分布(正規・ポアソン・指数など)では exp \exp exp
3. 具体例の完全導出
最尤法の威力は手を動かすと分かります。代表的な4分布を尤度方程式から導きます。
3.1 ベルヌーイ分布・二項分布:p ^ \hat p p ^
各 X i X_i X i p p p ベルヌーイ分布・二項分布 )に従うとします。確率関数は f ( x ; p ) = p x ( 1 − p ) 1 − x ( x ∈ { 0 , 1 } ) f(x;p)=p^x(1-p)^{1-x}\ (x\in\{0,1\}) f ( x ; p ) = p x ( 1 − p ) 1 − x ( x ∈ { 0 , 1 }) ∑ x i \sum x_i ∑ x i
L ( p ) = ∏ i = 1 n p x i ( 1 − p ) 1 − x i = p ∑ x i ( 1 − p ) n − ∑ x i . L(p)=\prod_{i=1}^n p^{x_i}(1-p)^{1-x_i}=p^{\sum x_i}(1-p)^{n-\sum x_i}. L ( p ) = ∏ i = 1 n p x i ( 1 − p ) 1 − x i = p ∑ x i ( 1 − p ) n − ∑ x i .
対数尤度:
ℓ ( p ) = ( ∑ x i ) log p + ( n − ∑ x i ) log ( 1 − p ) . \ell(p)=\Big(\sum x_i\Big)\log p + \Big(n-\sum x_i\Big)\log(1-p). ℓ ( p ) = ( ∑ x i ) log p + ( n − ∑ x i ) log ( 1 − p ) .
尤度方程式 d ℓ d p = 0 \dfrac{d\ell}{dp}=0 d p d ℓ = 0
d ℓ d p = ∑ x i p − n − ∑ x i 1 − p = 0. \frac{d\ell}{dp}=\frac{\sum x_i}{p}-\frac{n-\sum x_i}{1-p}=0. d p d ℓ = p ∑ x i − 1 − p n − ∑ x i = 0.
両辺に p ( 1 − p ) p(1-p) p ( 1 − p ) ( 1 − p ) ∑ x i = p ( n − ∑ x i ) (1-p)\sum x_i = p\,(n-\sum x_i) ( 1 − p ) ∑ x i = p ( n − ∑ x i ) ∑ x i = p n \sum x_i = pn ∑ x i = p n
p ^ M L = 1 n ∑ i = 1 n x i = x ˉ \boxed{\,\hat p_{\mathrm{ML}}=\frac{1}{n}\sum_{i=1}^n x_i=\bar x\,} p ^ ML = n 1 i = 1 ∑ n x i = x ˉ
要するに :成功割合(標本比率)がそのまま p p p p ^ = 0.7 \hat p=0.7 p ^ = 0.7 B i n ( n , p ) \mathrm{Bin}(n,p) Bin ( n , p ) p ^ = x / n \hat p=x/n p ^ = x / n
3.2 ポアソン分布:λ ^ \hat\lambda λ ^
各 X i X_i X i λ \lambda λ ポアソン分布 )に従うとします。f ( x ; λ ) = λ x e − λ x ! f(x;\lambda)=\dfrac{\lambda^x e^{-\lambda}}{x!} f ( x ; λ ) = x ! λ x e − λ exp \exp exp
ℓ ( λ ) = ∑ i = 1 n ( x i log λ − λ − log ( x i ! ) ) = ( ∑ x i ) log λ − n λ − ∑ log ( x i ! ) . \ell(\lambda)=\sum_{i=1}^n\Big(x_i\log\lambda - \lambda - \log(x_i!)\Big)=\Big(\sum x_i\Big)\log\lambda - n\lambda - \sum\log(x_i!). ℓ ( λ ) = ∑ i = 1 n ( x i log λ − λ − log ( x i !) ) = ( ∑ x i ) log λ − nλ − ∑ log ( x i !) .
最後の項は λ \lambda λ
d ℓ d λ = ∑ x i λ − n = 0 ⟹ λ ^ M L = 1 n ∑ i = 1 n x i = x ˉ \frac{d\ell}{d\lambda}=\frac{\sum x_i}{\lambda}-n=0\ \Longrightarrow\ \boxed{\,\hat\lambda_{\mathrm{ML}}=\frac1n\sum_{i=1}^n x_i=\bar x\,} d λ d ℓ = λ ∑ x i − n = 0 ⟹ λ ^ ML = n 1 i = 1 ∑ n x i = x ˉ
要するに :標本平均が λ \lambda λ x ˉ \bar x x ˉ
3.3 指数分布:λ ^ \hat\lambda λ ^
各 X i X_i X i λ \lambda λ 指数分布・ガンマ分布・ベータ分布 )に従うとします。f ( x ; λ ) = λ e − λ x ( x > 0 ) f(x;\lambda)=\lambda e^{-\lambda x}\ (x>0) f ( x ; λ ) = λ e − λ x ( x > 0 )
ℓ ( λ ) = ∑ i = 1 n ( log λ − λ x i ) = n log λ − λ ∑ x i . \ell(\lambda)=\sum_{i=1}^n\big(\log\lambda - \lambda x_i\big)=n\log\lambda - \lambda\sum x_i. ℓ ( λ ) = ∑ i = 1 n ( log λ − λ x i ) = n log λ − λ ∑ x i .
尤度方程式:
d ℓ d λ = n λ − ∑ x i = 0 ⟹ λ ^ M L = n ∑ x i = 1 x ˉ \frac{d\ell}{d\lambda}=\frac{n}{\lambda}-\sum x_i=0\ \Longrightarrow\ \boxed{\,\hat\lambda_{\mathrm{ML}}=\frac{n}{\sum x_i}=\frac{1}{\bar x}\,} d λ d ℓ = λ n − ∑ x i = 0 ⟹ λ ^ ML = ∑ x i n = x ˉ 1
要するに :標本平均の逆数がレートの最尤推定量。指数分布の平均は 1 / λ 1/\lambda 1/ λ x ˉ \bar x x ˉ λ = 1 / x ˉ \lambda=1/\bar x λ = 1/ x ˉ 1 / x ˉ 1/\bar x 1/ x ˉ λ \lambda λ 不偏ではない (後述。逆数という非線形変換のため E [ 1 / X ˉ ] ≠ 1 / E [ X ˉ ] E[1/\bar X]\ne 1/E[\bar X] E [ 1/ X ˉ ] = 1/ E [ X ˉ ]
3.4 正規分布 N ( μ , σ 2 ) N(\mu,\sigma^2) N ( μ , σ 2 ) μ ^ , σ ^ 2 \hat\mu,\hat\sigma^2 μ ^ , σ ^ 2
2母数の例。密度(正規分布(標準正規・標準化) )は f ( x ; μ , σ 2 ) = 1 2 π σ 2 exp ( − ( x − μ ) 2 2 σ 2 ) f(x;\mu,\sigma^2)=\dfrac{1}{\sqrt{2\pi\sigma^2}}\exp\!\left(-\dfrac{(x-\mu)^2}{2\sigma^2}\right) f ( x ; μ , σ 2 ) = 2 π σ 2 1 exp ( − 2 σ 2 ( x − μ ) 2 )
ℓ ( μ , σ 2 ) = − n 2 log ( 2 π ) − n 2 log σ 2 − 1 2 σ 2 ∑ i = 1 n ( x i − μ ) 2 . \ell(\mu,\sigma^2)=-\frac n2\log(2\pi)-\frac n2\log\sigma^2-\frac{1}{2\sigma^2}\sum_{i=1}^n (x_i-\mu)^2. ℓ ( μ , σ 2 ) = − 2 n log ( 2 π ) − 2 n log σ 2 − 2 σ 2 1 ∑ i = 1 n ( x i − μ ) 2 .
母数が2つなので、それぞれで偏微分して連立します(尤度方程式が2本 )。
μ \mu μ
∂ ℓ ∂ μ = 1 σ 2 ∑ i = 1 n ( x i − μ ) = 0 ⟹ ∑ x i = n μ ⟹ μ ^ M L = x ˉ \frac{\partial\ell}{\partial\mu}=\frac{1}{\sigma^2}\sum_{i=1}^n (x_i-\mu)=0\ \Longrightarrow\ \sum x_i=n\mu\ \Longrightarrow\ \boxed{\,\hat\mu_{\mathrm{ML}}=\bar x\,} ∂ μ ∂ ℓ = σ 2 1 ∑ i = 1 n ( x i − μ ) = 0 ⟹ ∑ x i = n μ ⟹ μ ^ ML = x ˉ
σ 2 \sigma^2 σ 2 σ 2 \sigma^2 σ 2
∂ ℓ ∂ σ 2 = − n 2 σ 2 + 1 2 ( σ 2 ) 2 ∑ i = 1 n ( x i − μ ) 2 = 0. \frac{\partial\ell}{\partial\sigma^2}=-\frac{n}{2\sigma^2}+\frac{1}{2(\sigma^2)^2}\sum_{i=1}^n (x_i-\mu)^2=0. ∂ σ 2 ∂ ℓ = − 2 σ 2 n + 2 ( σ 2 ) 2 1 ∑ i = 1 n ( x i − μ ) 2 = 0.
両辺に 2 ( σ 2 ) 2 2(\sigma^2)^2 2 ( σ 2 ) 2 − n σ 2 + ∑ ( x i − μ ) 2 = 0 -n\sigma^2+\sum(x_i-\mu)^2=0 − n σ 2 + ∑ ( x i − μ ) 2 = 0 μ = μ ^ = x ˉ \mu=\hat\mu=\bar x μ = μ ^ = x ˉ
σ ^ M L 2 = 1 n ∑ i = 1 n ( x i − x ˉ ) 2 \boxed{\,\hat\sigma^2_{\mathrm{ML}}=\frac1n\sum_{i=1}^n (x_i-\bar x)^2\,} σ ^ ML 2 = n 1 i = 1 ∑ n ( x i − x ˉ ) 2
要するに :平均は標本平均、分散は「n n n
⚠️ ここが頻出の落とし穴 。σ ^ M L 2 \hat\sigma^2_{\mathrm{ML}} σ ^ ML 2 n n n 点推定(推定量の良さ:不偏性・一致性・有効性・十分性) で見たとおり E [ σ ^ M L 2 ] = n − 1 n σ 2 < σ 2 E[\hat\sigma^2_{\mathrm{ML}}]=\dfrac{n-1}{n}\sigma^2<\sigma^2 E [ σ ^ ML 2 ] = n n − 1 σ 2 < σ 2 最尤推定量はバイアスを持ちます (母分散を過小評価)。不偏にするには n − 1 n-1 n − 1 s 2 s^2 s 2 MLE = 不偏」は成り立たない 。n → ∞ n\to\infty n → ∞ − σ 2 / n → 0 -\sigma^2/n\to0 − σ 2 / n → 0 漸近的には不偏 (一致性は保たれる)。この「有限標本では偏るが漸近的には消える」が MLE の典型的な振る舞いです。
分布 母数 最尤推定量 不偏か ベルヌーイ p p p x ˉ \bar x x ˉ 不偏 ポアソン λ \lambda λ x ˉ \bar x x ˉ 不偏 指数 λ \lambda λ 1 / x ˉ 1/\bar x 1/ x ˉ 不偏でない (逆数の非線形性)正規 μ \mu μ x ˉ \bar x x ˉ 不偏 正規 σ 2 \sigma^2 σ 2 1 n ∑ ( x i − x ˉ ) 2 \frac1n\sum(x_i-\bar x)^2 n 1 ∑ ( x i − x ˉ ) 2 不偏でない (n n n
4. 最尤推定量の性質(主に1級:漸近論)
MLE が広く使われる理由は、n n n 漸近的な良さ にあります。準1級では「推定量を求める計算」が中心ですが、1級ではこの漸近論そのものが問われます。
4.1 一致性
性質 :正則条件下で、MLE は一致推定量。θ ^ M L → p θ ( n → ∞ ) \hat\theta_{\mathrm{ML}}\xrightarrow{p}\theta\ (n\to\infty) θ ^ ML p θ ( n → ∞ )
要するに :データを増やせば MLE は真値に確率収束する(点推定(推定量の良さ:不偏性・一致性・有効性・十分性) の一致性)。直感的には、対数尤度の期待値 E [ ℓ ( θ ) ] / n E[\ell(\theta)]/n E [ ℓ ( θ )] / n θ 0 \theta_0 θ 0
4.2 漸近正規性(1級の核心)
性質 :正則条件下で、MLE は漸近正規。
n ( θ ^ M L − θ ) → d N ( 0 , 1 I 1 ( θ ) ) \boxed{\,\sqrt n\,(\hat\theta_{\mathrm{ML}}-\theta)\ \xrightarrow{d}\ N\!\left(0,\ \frac{1}{I_1(\theta)}\right)\,} n ( θ ^ ML − θ ) d N ( 0 , I 1 ( θ ) 1 ) I 1 ( θ ) I_1(\theta) I 1 ( θ ) 1個あたりのフィッシャー情報量 I 1 ( θ ) = E [ ( ∂ ∂ θ log f ( X ; θ ) ) 2 ] = − E [ ∂ 2 ∂ θ 2 log f ( X ; θ ) ] I_1(\theta)=E\!\left[\left(\dfrac{\partial}{\partial\theta}\log f(X;\theta)\right)^2\right]=-E\!\left[\dfrac{\partial^2}{\partial\theta^2}\log f(X;\theta)\right] I 1 ( θ ) = E [ ( ∂ θ ∂ log f ( X ; θ ) ) 2 ] = − E [ ∂ θ 2 ∂ 2 log f ( X ; θ ) ]
要するに :n n n θ ^ M L \hat\theta_{\mathrm{ML}} θ ^ ML N ( θ , 1 n I 1 ( θ ) ) N\!\left(\theta,\ \dfrac{1}{n\,I_1(\theta)}\right) N ( θ , n I 1 ( θ ) 1 ) 1 n I 1 ( θ ) \dfrac{1}{n I_1(\theta)} n I 1 ( θ ) 1 I 1 I_1 I 1 n n n この近似がそのまま MLE に基づく信頼区間・検定の根拠 になります(区間推定(母平均・母比率・母分散の信頼区間) 、尤度比検定・Wald検定・スコア検定 )。
証明スケッチ (スコア関数のテイラー展開)。なぜこの形になるかを押さえます。スコア関数 S n ( θ ) = ∂ ℓ ∂ θ = ∑ i ∂ ∂ θ log f ( X i ; θ ) S_n(\theta)=\dfrac{\partial\ell}{\partial\theta}=\sum_i \dfrac{\partial}{\partial\theta}\log f(X_i;\theta) S n ( θ ) = ∂ θ ∂ ℓ = ∑ i ∂ θ ∂ log f ( X i ; θ ) θ \theta θ θ ^ \hat\theta θ ^ θ ^ \hat\theta θ ^ S n ( θ ^ ) = 0 S_n(\hat\theta)=0 S n ( θ ^ ) = 0
0 = S n ( θ ^ ) ≈ S n ( θ ) + ( θ ^ − θ ) S n ′ ( θ ) . 0=S_n(\hat\theta)\approx S_n(\theta)+(\hat\theta-\theta)\,S_n'(\theta). 0 = S n ( θ ^ ) ≈ S n ( θ ) + ( θ ^ − θ ) S n ′ ( θ ) .
これを θ ^ − θ \hat\theta-\theta θ ^ − θ n \sqrt n n n n n
n ( θ ^ − θ ) ≈ 1 n S n ( θ ) − 1 n S n ′ ( θ ) . \sqrt n\,(\hat\theta-\theta)\approx \frac{\frac{1}{\sqrt n}S_n(\theta)}{-\frac1n S_n'(\theta)}. n ( θ ^ − θ ) ≈ − n 1 S n ′ ( θ ) n 1 S n ( θ ) .
ここで分子と分母をそれぞれ評価します。
分子 1 n S n ( θ ) = 1 n ∑ i ∂ ∂ θ log f ( X i ; θ ) \dfrac{1}{\sqrt n}S_n(\theta)=\dfrac{1}{\sqrt n}\sum_i \dfrac{\partial}{\partial\theta}\log f(X_i;\theta) n 1 S n ( θ ) = n 1 ∑ i ∂ θ ∂ log f ( X i ; θ ) 期待値0 (後述)・分散 I 1 ( θ ) I_1(\theta) I 1 ( θ ) 中心極限定理 (中心極限定理(CLT) )から 1 n S n ( θ ) → d N ( 0 , I 1 ( θ ) ) \dfrac{1}{\sqrt n}S_n(\theta)\xrightarrow{d}N(0,\,I_1(\theta)) n 1 S n ( θ ) d N ( 0 , I 1 ( θ )) 分母 − 1 n S n ′ ( θ ) = − 1 n ∑ i ∂ 2 ∂ θ 2 log f ( X i ; θ ) -\dfrac1n S_n'(\theta)=-\dfrac1n\sum_i \dfrac{\partial^2}{\partial\theta^2}\log f(X_i;\theta) − n 1 S n ′ ( θ ) = − n 1 ∑ i ∂ θ 2 ∂ 2 log f ( X i ; θ ) − E [ ∂ 2 ∂ θ 2 log f ( X ; θ ) ] = I 1 ( θ ) -E\!\left[\dfrac{\partial^2}{\partial\theta^2}\log f(X;\theta)\right]=I_1(\theta) − E [ ∂ θ 2 ∂ 2 log f ( X ; θ ) ] = I 1 ( θ ) 大数の法則 (大数の法則(弱法則・強法則) )から − 1 n S n ′ ( θ ) → p I 1 ( θ ) -\dfrac1n S_n'(\theta)\xrightarrow{p}I_1(\theta) − n 1 S n ′ ( θ ) p I 1 ( θ )
スルツキーの定理で組み合わせると、N ( 0 , I 1 ) I 1 = N ( 0 , I 1 I 1 2 ) = N ( 0 , 1 I 1 ) \dfrac{N(0,\,I_1)}{I_1}=N\!\left(0,\,\dfrac{I_1}{I_1^2}\right)=N\!\left(0,\,\dfrac{1}{I_1}\right) I 1 N ( 0 , I 1 ) = N ( 0 , I 1 2 I 1 ) = N ( 0 , I 1 1 ) n ( θ ^ − θ ) → d N ( 0 , 1 / I 1 ( θ ) ) \sqrt n(\hat\theta-\theta)\xrightarrow{d}N(0,1/I_1(\theta)) n ( θ ^ − θ ) d N ( 0 , 1/ I 1 ( θ ))
要するに :MLE の漸近正規性は、「スコア(傾き)の和に中心極限定理を効かせる」ことから出てくる。分子の CLT が分散 I 1 I_1 I 1 I 1 I_1 I 1 1 / I 1 1/I_1 1/ I 1
補足(スコアの期待値が0) :∫ f ( x ; θ ) d x = 1 \displaystyle\int f(x;\theta)\,dx=1 ∫ f ( x ; θ ) d x = 1 θ \theta θ ∫ ∂ f ∂ θ d x = 0 \int \dfrac{\partial f}{\partial\theta}dx=0 ∫ ∂ θ ∂ f d x = 0 ∂ f ∂ θ = f ⋅ ∂ log f ∂ θ \dfrac{\partial f}{\partial\theta}=f\cdot\dfrac{\partial\log f}{\partial\theta} ∂ θ ∂ f = f ⋅ ∂ θ ∂ log f ∫ ∂ log f ∂ θ f d x = E [ ∂ log f ∂ θ ] = 0 \int \dfrac{\partial\log f}{\partial\theta}\,f\,dx=E\!\left[\dfrac{\partial\log f}{\partial\theta}\right]=0 ∫ ∂ θ ∂ log f f d x = E [ ∂ θ ∂ log f ] = 0 要するに 「全確率が1で一定だから、その傾きの平均は0」。これがスコアの期待値0の正体で、漸近正規性の分子に CLT を使える前提です。
4.3 漸近有効性
性質 :MLE の漸近分散 1 n I 1 ( θ ) \dfrac{1}{n I_1(\theta)} n I 1 ( θ ) 1 クラメール・ラオ下限 (点推定(推定量の良さ:不偏性・一致性・有効性・十分性) 、推定量の評価(MSE・フィッシャー情報量・クラメール・ラオの不等式) )にちょうど等しい。すなわち MLE は漸近的に有効 (漸近的に最小分散)。
要するに :不偏推定量の分散には限界 1 n I 1 ( θ ) \dfrac{1}{n I_1(\theta)} n I 1 ( θ ) 1 n n n 漸近的に 」が肝心で、有限の n n n
4.4 不変性(invariance)
性質 :θ \theta θ θ ^ \hat\theta θ ^ θ \theta θ g ( θ ) g(\theta) g ( θ ) g ( θ ^ ) g(\hat\theta) g ( θ ^ ) g ( θ ) ^ M L = g ( θ ^ M L ) . \widehat{g(\theta)}_{\mathrm{ML}}=g(\hat\theta_{\mathrm{ML}}). g ( θ ) ML = g ( θ ^ ML ) .
要するに :母数を変換しても、MLE は「変換してから推定」と「推定してから変換」が一致する。例:正規分布で σ 2 \sigma^2 σ 2 σ ^ M L 2 \hat\sigma^2_{\mathrm{ML}} σ ^ ML 2 σ = σ 2 \sigma=\sqrt{\sigma^2} σ = σ 2 σ ^ M L 2 \sqrt{\hat\sigma^2_{\mathrm{ML}}} σ ^ ML 2 λ \lambda λ 1 / x ˉ 1/\bar x 1/ x ˉ 1 / λ 1/\lambda 1/ λ x ˉ \bar x x ˉ この性質は不偏推定量にはない (不偏性は非線形変換で壊れる:E [ g ( θ ^ ) ] ≠ g ( E [ θ ^ ] ) E[g(\hat\theta)]\ne g(E[\hat\theta]) E [ g ( θ ^ )] = g ( E [ θ ^ ]) σ \sigma σ
graph LR
A["最尤推定量 θ̂_ML"] --> B["一致性<br/>θ̂ →ᵖ θ"]
A --> C["漸近正規性<br/>√n(θ̂-θ) →ᵈ N(0,1/I₁)"]
A --> D["漸近有効性<br/>分散→クラメール・ラオ下限"]
A --> E["不変性<br/>g(θ)のMLE=g(θ̂)"]
C --> D
F["⚠ 有限標本では<br/>不偏とは限らない"] -.-> A
style A fill:#ffe8e8
style C fill:#e8f4ff
style F fill:#fff0e8
5. モーメント法:標本モーメント=母モーメントを解く
最尤法と並ぶ古典的な推定法がモーメント法(積率法, Method of Moments) 。原理は素朴です。
手順 :母数が k k k k k k 母モーメント=標本モーメント 」と等式を立て、母数について解く。
E [ X j ] = 1 n ∑ i = 1 n X i j ( j = 1 , 2 , … , k ) . E[X^j]=\frac1n\sum_{i=1}^n X_i^{\,j}\qquad (j=1,2,\dots,k). E [ X j ] = n 1 ∑ i = 1 n X i j ( j = 1 , 2 , … , k ) .
ここで母モーメント E [ X j ] E[X^j] E [ X j ] θ \theta θ 確率変数の変換・モーメント母関数・積率 )。それを標本モーメント(データから計算できる数)と等しいと置いて連立し、θ \theta θ
要するに :「理論上の平均・分散などを、データの平均・分散などで置き換えて、母数を逆算する」。大数の法則で標本モーメントは母モーメントに収束するので、この置き換えは大標本で正当化され、モーメント推定量は一致性 を持ちます。
5.1 例1:正規分布 N ( μ , σ 2 ) N(\mu,\sigma^2) N ( μ , σ 2 )
母数は μ , σ 2 \mu,\sigma^2 μ , σ 2 E [ X ] = μ E[X]=\mu E [ X ] = μ V [ X ] = σ 2 V[X]=\sigma^2 V [ X ] = σ 2
1次モーメント:μ = X ˉ \mu = \bar X μ = X ˉ
2次中心モーメント:σ 2 = 1 n ∑ ( X i − X ˉ ) 2 \sigma^2 = \dfrac1n\sum (X_i-\bar X)^2 σ 2 = n 1 ∑ ( X i − X ˉ ) 2
μ ^ M M = X ˉ , σ ^ M M 2 = 1 n ∑ i = 1 n ( X i − X ˉ ) 2 \boxed{\,\hat\mu_{\mathrm{MM}}=\bar X,\qquad \hat\sigma^2_{\mathrm{MM}}=\frac1n\sum_{i=1}^n (X_i-\bar X)^2\,} μ ^ MM = X ˉ , σ ^ MM 2 = n 1 i = 1 ∑ n ( X i − X ˉ ) 2
要するに :正規分布ではモーメント法と最尤法が完全に一致 する(どちらも σ 2 \sigma^2 σ 2 n n n
5.2 例2:ガンマ分布 G a m m a ( α , λ ) \mathrm{Gamma}(\alpha,\lambda) Gamma ( α , λ )
形状 α \alpha α λ \lambda λ 指数分布・ガンマ分布・ベータ分布 )は、平均 E [ X ] = α λ E[X]=\dfrac{\alpha}{\lambda} E [ X ] = λ α V [ X ] = α λ 2 V[X]=\dfrac{\alpha}{\lambda^2} V [ X ] = λ 2 α
α λ = X ˉ , α λ 2 = S 2 ( = 1 n ∑ ( X i − X ˉ ) 2 ) . \frac{\alpha}{\lambda}=\bar X,\qquad \frac{\alpha}{\lambda^2}=S^2\ \left(=\frac1n\sum(X_i-\bar X)^2\right). λ α = X ˉ , λ 2 α = S 2 ( = n 1 ∑ ( X i − X ˉ ) 2 ) .
2式の比 α / λ 2 α / λ = 1 λ = S 2 X ˉ \dfrac{\alpha/\lambda^2}{\alpha/\lambda}=\dfrac1\lambda=\dfrac{S^2}{\bar X} α / λ α / λ 2 = λ 1 = X ˉ S 2 λ ^ M M = X ˉ S 2 \hat\lambda_{\mathrm{MM}}=\dfrac{\bar X}{S^2} λ ^ MM = S 2 X ˉ α ^ M M = X ˉ ⋅ λ ^ M M = X ˉ 2 S 2 \hat\alpha_{\mathrm{MM}}=\bar X\cdot\hat\lambda_{\mathrm{MM}}=\dfrac{\bar X^2}{S^2} α ^ MM = X ˉ ⋅ λ ^ MM = S 2 X ˉ 2
α ^ M M = X ˉ 2 S 2 , λ ^ M M = X ˉ S 2 \boxed{\,\hat\alpha_{\mathrm{MM}}=\frac{\bar X^2}{S^2},\qquad \hat\lambda_{\mathrm{MM}}=\frac{\bar X}{S^2}\,} α ^ MM = S 2 X ˉ 2 , λ ^ MM = S 2 X ˉ
要するに :ガンマ分布の MLE は α \alpha α 閉じた式で解けない (数値解が必要)。一方モーメント法なら標本平均と標本分散だけで一発で出る。ここがモーメント法の存在意義 ── MLE が解析的に解けない場面で、手早く一致推定量を与えます。
6. 両者の比較:いつどちらを使うか
観点 最尤法(MLE) モーメント法(MM) 原理 尤度最大化 標本=母モーメント 計算 尤度方程式。閉じた式で解けないことも(数値解) 連立を解くだけ。多くは閉じた式 一致性 あり あり 漸近有効性 あり (クラメール・ラオ下限を達成)ないことが多い (分散が大きめ)有限標本の不偏性 必ずしも不偏でない 必ずしも不偏でない 主な用途 標準的な推定。理論保証が強い MLE が解けないとき・初期値・手計算
要するに :理論的な最適性(漸近有効性)が欲しいなら MLE、計算の手軽さや MLE の解けなさを回避したいならモーメント法。実務では「モーメント法で初期値を出し、それを起点に MLE を数値最適化する」という併用も普通です。両者はしばしば一致するが一般には別 (正規分布では一致、ガンマ分布では別)。
⚠️ モーメント法は高次モーメントを使うほど推定が不安定になりやすい(標本の高次モーメントは分散が大きい)。また、推定値が母数の定義域を外れる(例:分散の推定が負になる、確率が1を超える)ことが起こりうる。MLE は通常その分布のパラメータ空間内に収まるため、この点でも MLE が安全なことが多い。
7. 試験での問われ方の差(準1級 vs 1級)
このトピックは級で問われる深さがはっきり分かれます。
準1級 :与えられた分布について尤度方程式 ∂ ℓ / ∂ θ = 0 \partial\ell/\partial\theta=0 ∂ ℓ / ∂ θ = 0 計算が中心。モーメント法で推定量を求める問題も出る。「正規分布の σ ^ 2 \hat\sigma^2 σ ^ 2 n n n 1級 :上記に加えて漸近論そのもの 。漸近正規性 n ( θ ^ − θ ) → d N ( 0 , 1 / I 1 ( θ ) ) \sqrt n(\hat\theta-\theta)\xrightarrow{d}N(0,1/I_1(\theta)) n ( θ ^ − θ ) d N ( 0 , 1/ I 1 ( θ ))
両級に共通して頻出なのは「最尤推定量を具体的に導く」計算力。1級はその上に「なぜ MLE が良いのか」の漸近的な理論武装が乗る、という関係です(年度により出題比重は変わるため要最新確認)。
⚠️ 引っかけポイント
尤度は確率ではない 。L ( θ ) L(\theta) L ( θ ) 母数 θ \theta θ であって、θ \theta θ x x x f ( x ; θ ) f(x;\theta) f ( x ; θ ) 動かしている変数が x x x θ \theta θ が決定的に違う。確率は θ \theta θ x x x x x x θ \theta θ 「MLE は常に不偏」は誤り 。正規分布の σ ^ M L 2 \hat\sigma^2_{\mathrm{ML}} σ ^ ML 2 n n n λ ^ = 1 / x ˉ \hat\lambda=1/\bar x λ ^ = 1/ x ˉ 漸近的な良さ (一致・漸近正規・漸近有効)であって、有限標本の不偏性ではない。不変性と不偏性を混同しない 。不変性(g ( θ ) g(\theta) g ( θ ) g ( θ ^ ) g(\hat\theta) g ( θ ^ ) E [ g ( θ ^ ) ] ≠ g ( E [ θ ^ ] ) E[g(\hat\theta)]\ne g(E[\hat\theta]) E [ g ( θ ^ )] = g ( E [ θ ^ ]) σ 2 \sigma^2 σ 2 σ = σ 2 \sigma=\sqrt{\sigma^2} σ = σ 2 対数尤度を取っても最大化点は変わらない が、それは log が単調増加 だから。arg max L = arg max log L \arg\max L=\arg\max\log L arg max L = arg max log L 尤度方程式の解が必ず最大とは限らない 。∂ ℓ / ∂ θ = 0 \partial\ell/\partial\theta=0 ∂ ℓ / ∂ θ = 0 ∂ 2 ℓ / ∂ θ 2 < 0 \partial^2\ell/\partial\theta^2<0 ∂ 2 ℓ / ∂ θ 2 < 0 U ( 0 , θ ) U(0,\theta) U ( 0 , θ ) θ ^ = max i x i \hat\theta=\max_i x_i θ ^ = max i x i 端点で最大 になり微分が0にならない型もある(微分して解く発想だけだと取りこぼす)。漸近正規性は「n → ∞ n\to\infty n → ∞ 。n ( θ ^ − θ ) → d N ( 0 , 1 / I 1 ) \sqrt n(\hat\theta-\theta)\xrightarrow{d}N(0,1/I_1) n ( θ ^ − θ ) d N ( 0 , 1/ I 1 ) フィッシャー情報量の n n n 。1個あたりが I 1 ( θ ) I_1(\theta) I 1 ( θ ) I n ( θ ) = n I 1 ( θ ) I_n(\theta)=nI_1(\theta) I n ( θ ) = n I 1 ( θ ) 1 n I 1 ( θ ) = 1 I n ( θ ) \dfrac{1}{nI_1(\theta)}=\dfrac{1}{I_n(\theta)} n I 1 ( θ ) 1 = I n ( θ ) 1 n ( θ ^ − θ ) \sqrt n(\hat\theta-\theta) n ( θ ^ − θ ) 1 / I 1 1/I_1 1/ I 1 θ ^ \hat\theta θ ^ 1 / ( n I 1 ) 1/(nI_1) 1/ ( n I 1 ) I I I
よくある疑問
Q1. 尤度と確率はどう違うんですか?式は同じ f ( x ; θ ) f(x;\theta) f ( x ; θ )
A. 式は同じでも、どの変数を動かすか が逆です。確率(分布)は θ \theta θ x x x x x x x x x θ \theta θ θ \theta θ N ( μ , 1 ) N(\mu,1) N ( μ , 1 ) μ = 5 \mu=5 μ = 5 x x x x = 3 x=3 x = 3 μ \mu μ μ \mu μ x = 3 x=3 x = 3 μ = 3 \mu=3 μ = 3
Q2. なぜ尤度をそのまま最大化せず、わざわざ log を取るんですか?
A. 主に計算上の都合です。理由は3つ。(1) 尤度は積 ∏ f ( x i ; θ ) \prod f(x_i;\theta) ∏ f ( x i ; θ ) ∑ log f ( x i ; θ ) \sum\log f(x_i;\theta) ∑ log f ( x i ; θ ) exp \exp exp e − λ e^{-\lambda} e − λ exp \exp exp log L \log L log L θ \theta θ L L L θ \theta θ
Q3. 最尤推定量って一番良い推定量なんですよね?なら不偏でもあるはずでは?
A. そこが誤解の定番です。MLE が「一番良い」のは漸近的に (n → ∞ n\to\infty n → ∞ σ ^ 2 = 1 n ∑ ( x i − x ˉ ) 2 \hat\sigma^2=\frac1n\sum(x_i-\bar x)^2 σ ^ 2 = n 1 ∑ ( x i − x ˉ ) 2 n n n E [ σ ^ 2 ] = n − 1 n σ 2 < σ 2 E[\hat\sigma^2]=\frac{n-1}{n}\sigma^2<\sigma^2 E [ σ ^ 2 ] = n n − 1 σ 2 < σ 2 n − 1 n-1 n − 1 λ ^ = 1 / x ˉ \hat\lambda=1/\bar x λ ^ = 1/ x ˉ
Q4. 漸近正規性の式 n ( θ ^ − θ ) → N ( 0 , 1 / I 1 ) \sqrt n(\hat\theta-\theta)\to N(0,1/I_1) n ( θ ^ − θ ) → N ( 0 , 1/ I 1 )
A. 証明スケッチ(本文4.2)を一言でいうと、「スコア(対数尤度の傾き)の和に中心極限定理を効かせる」からです。尤度方程式の解 θ ^ \hat\theta θ ^ n ( θ ^ − θ ) ≈ (スコア和を n で割ったもの) (ヘッシアン和を n で割ったもの) \sqrt n(\hat\theta-\theta)\approx \dfrac{\text{(スコア和を}\sqrt n\text{で割ったもの)}}{\text{(ヘッシアン和を}n\text{で割ったもの)}} n ( θ ^ − θ ) ≈ (ヘッシアン和を n で割ったもの) (スコア和を n で割ったもの) N ( 0 , I 1 ) N(0,I_1) N ( 0 , I 1 ) I 1 I_1 I 1 I 1 I_1 I 1 I 1 = − E [ ∂ 2 log f / ∂ θ 2 ] I_1=-E[\partial^2\log f/\partial\theta^2] I 1 = − E [ ∂ 2 log f / ∂ θ 2 ] N ( 0 , I 1 ) I 1 \dfrac{N(0,I_1)}{I_1} I 1 N ( 0 , I 1 ) I 1 I 1 2 = 1 I 1 \dfrac{I_1}{I_1^2}=\dfrac{1}{I_1} I 1 2 I 1 = I 1 1 I 1 I_1 I 1 I 1 I_1 I 1 1 / I 1 1/I_1 1/ I 1
Q5. モーメント法は最尤法より劣るなら、なぜ存在するんですか?
A. 計算の手軽さと、MLE が解けない場面での実用性のためです。ガンマ分布のように MLE が閉じた式で解けない(ディガンマ関数を含む方程式の数値解が必要)分布でも、モーメント法なら標本平均と標本分散だけで一発で推定量が出ます(本文5.2)。一致性も持つので大標本では真値に近づく。劣るのは主に**効率(分散)**で、漸近有効性を持つ MLE に比べると分散が大きめになりやすい、特に小標本や高次モーメントを使う場合に差が出る。実務では「モーメント法で素早く初期値を出し、それを起点に MLE を数値最適化する」という併用が定番です。教育・初期分析・MLE の足場として今も使われます。
Q6. 不変性って具体的に何が嬉しいんですか?
A. 母数を変換した量の MLE を、改めて尤度方程式を解き直さずに求められる点です。たとえば正規分布で分散 σ 2 \sigma^2 σ 2 σ ^ 2 \hat\sigma^2 σ ^ 2 σ = σ 2 \sigma=\sqrt{\sigma^2} σ = σ 2 σ ^ 2 \sqrt{\hat\sigma^2} σ ^ 2 λ \lambda λ 1 / x ˉ 1/\bar x 1/ x ˉ θ = 1 / λ \theta=1/\lambda θ = 1/ λ x ˉ \bar x x ˉ σ 2 \sigma^2 σ 2 σ \sigma σ
まとめ
最尤法 :観測データを最も起こりやすくする母数を選ぶ。x x x θ \theta θ 尤度 L ( θ ) = ∏ f ( x i ; θ ) L(\theta)=\prod f(x_i;\theta) L ( θ ) = ∏ f ( x i ; θ ) 対数尤度 ℓ ( θ ) = ∑ log f ( x i ; θ ) \ell(\theta)=\sum\log f(x_i;\theta) ℓ ( θ ) = ∑ log f ( x i ; θ ) 尤度方程式 ∂ ℓ / ∂ θ = 0 \partial\ell/\partial\theta=0 ∂ ℓ / ∂ θ = 0 で最大化する。log は単調増加なので最大化点は不変、積→和で計算が楽になる。完全導出 :ベルヌーイ p ^ = x ˉ \hat p=\bar x p ^ = x ˉ λ ^ = x ˉ \hat\lambda=\bar x λ ^ = x ˉ λ ^ = 1 / x ˉ \hat\lambda=1/\bar x λ ^ = 1/ x ˉ μ ^ = x ˉ , σ ^ 2 = 1 n ∑ ( x i − x ˉ ) 2 \hat\mu=\bar x,\ \hat\sigma^2=\frac1n\sum(x_i-\bar x)^2 μ ^ = x ˉ , σ ^ 2 = n 1 ∑ ( x i − x ˉ ) 2 正規の σ ^ 2 \hat\sigma^2 σ ^ 2 n n n (E [ σ ^ 2 ] = n − 1 n σ 2 E[\hat\sigma^2]=\frac{n-1}{n}\sigma^2 E [ σ ^ 2 ] = n n − 1 σ 2 MLE の性質(1級) :一致性、漸近正規性 n ( θ ^ − θ ) → d N ( 0 , 1 / I 1 ( θ ) ) \sqrt n(\hat\theta-\theta)\xrightarrow{d}N(0,1/I_1(\theta)) n ( θ ^ − θ ) d N ( 0 , 1/ I 1 ( θ )) 漸近有効性 (クラメール・ラオ下限を漸近的に達成)、不変性 (g ( θ ) g(\theta) g ( θ ) g ( θ ^ ) g(\hat\theta) g ( θ ^ ) モーメント法 :標本モーメント=母モーメントを解く。計算が容易で一致性あり、だが効率で MLE に劣ることが多い。MLE が解析的に解けないとき(ガンマ分布など)に有用。正規分布では MLE と一致するが一般には別物。最重要の誤解 :「尤度は確率」(誤、母数の関数で積分しても1にならない)、「MLE は常に不偏」(誤、漸近的に良いだけ)。試験での差 :準1級 =尤度方程式を解いて推定量を求める計算・フィッシャー情報量。1級 =漸近正規性・漸近有効性・不変性の漸近論まで。
関連ノート