📊 対象級:2級 ・ 準1級 | 重要度:A(頻出)
大数の法則(大数の弱法則・強法則)── チェビシェフによる証明/確率収束・概収束/統計的確率の正当化
要点(BLUF)
- 大数の弱法則(WLLN):独立同分布 (平均 、分散 )の標本平均 は母平均 に確率収束する。。要するに「データを増やすほど標本平均が真の平均から外れる確率がいくらでも小さくなる」。
- 証明の山=チェビシェフ + :チェビシェフの不等式(標準化(z得点)・偏差値・チェビシェフの不等式 ── 標準化≠正規化/偏差値に上限なし/どんな分布でも成り立つ歯止め)に (期待値・分散の性質(線形性・和の分散・共分散))を代入するだけで 。Phase 1のチェビシェフと⑥の がここで合流して大数の法則を生む。
- 大数の強法則(SLLN): が概収束(確率1で各パスが収束)。強法則 ⟹ 弱法則(逆は一般に不成立)。収束先は1点 (中心極限定理 中心極限定理(CLT) が扱う「分布の形(正規)」とは別の話)。統計的確率(相対頻度 、確率の基本(定義・加法定理・乗法定理))の正当化はこれ。分散が無い分布(コーシー)では成り立たない。
本文
0. まず日常のイメージ:野球の打率
シーズン序盤、3打数2安打の選手は打率.667。でも「この選手は7割打つ」とは誰も思わない。打席が少ないと、たまたまの好調・不調で打率が大きくブレるから。ところが数百打席を重ねると打率はその選手の「真の実力(真の確率 )」、たとえば.280あたりに落ち着いていく。試行(打席)を増やすほど、観測した割合(打率)が真の確率に近づく——これがまさに大数の法則。逆に言うと少ないデータの平均はあてにならない、たくさん集めれば平均は信頼できる。統計でサンプルを多く取る理由そのもの。
1. 大数の法則とは何を言っているか
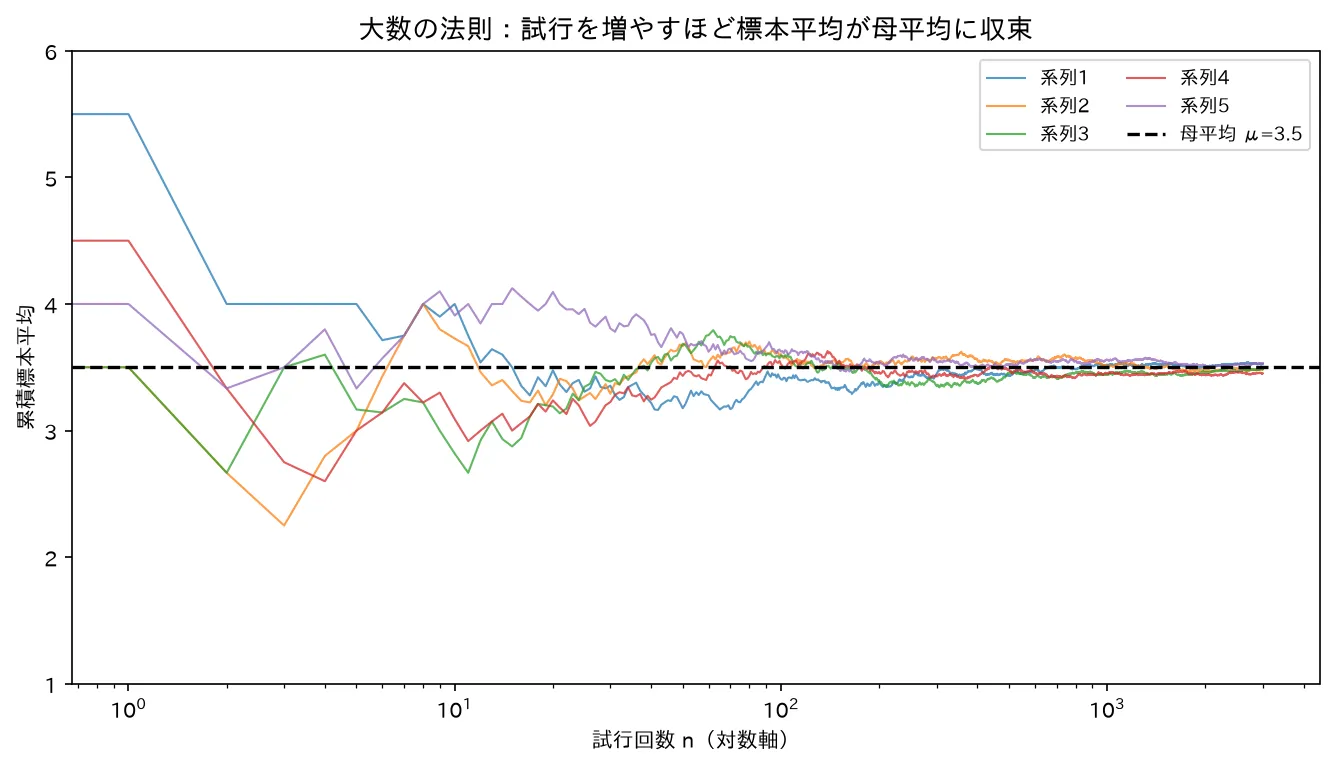
サイコロ(μ=3.5)の累積標本平均。試行を増やすほど各系列が母平均に収束する(散らばり σ²/n が0へ潰れる)。収束先は1点 μ。図は simulations/taisuu_housoku_shusoku.py で生成。
直観:「試行回数を増やすほど、標本平均は母平均(真の平均)に近づいていく」。サイコロを多く振るほど出目の平均が3.5に近づく、コインを多く投げるほど表の割合が0.5に近づく、というあの現象を厳密に述べたもの。
ただし「近づく」を数学的に詰めると 2通りの強さがある。これが弱法則と強法則の違いで、準1級ではこの区別が問われる。
- 弱法則(WLLN, weak law):標本平均が母平均に 確率収束する
- 強法則(SLLN, strong law):標本平均が母平均に 概収束する(弱法則より強い主張)
設定はどちらも 独立同分布(i.i.d.)の確率変数列 で、母平均 が存在すること(弱法則の標準的証明ではさらに分散 を仮定)。
2. 大数の弱法則(WLLN)
これは要するに「許容幅 をどんなに小さく決めても、 を十分大きくすれば、標本平均が母平均から 以上ズレる確率をいくらでも0に近づけられる」。収束しているのは『確率』であって、個々のパスが必ず収束するとは(弱法則だけからは)言っていない点に注意(これが強法則との差)。
3. 弱法則の証明(チェビシェフ + )── 本トピックの山
たった2つの道具で証明できる。Phase 1とPhase 2で別々に学んだものがここで合流する。
【道具1】標本平均の期待値と分散(期待値・分散の性質(線形性・和の分散・共分散)) i.i.d. なら
( の と独立和の が約分。独立だから共分散の項が消えて 。)要するに標本平均の散らばりは が増えると で縮む。
【道具2】チェビシェフの不等式(標準化(z得点)・偏差値・チェビシェフの不等式 ── 標準化≠正規化/偏差値に上限なし/どんな分布でも成り立つ歯止め) 平均 ・分散 をもつ任意の確率変数 に対し
(分布の形を一切仮定しない=distribution-free。だから i.i.d. ならどんな母分布でも使える。)
【合流】 チェビシェフを 、、 に適用:
右辺は を固定すれば で 。確率は0以上なので、左辺は0と右辺の間に挟まれて(はさみうち)
要するに**「散らばりが で0に潰れる + チェビシェフでそれを確率の上限に翻訳」**の2行。これが大数の弱法則の証明のすべて。
論理の流れを図にすると次のとおり。
flowchart LR A["i.i.d. の標本平均 X̄n"] --> B["V[X̄n] = σ²/n<br/>(散らばりが 1/n で縮む)"] A --> C["チェビシェフの不等式<br/>P(ズレ≥ε) ≤ 分散/ε²"] B --> D["P(|X̄n−μ|≥ε) ≤ σ²/(nε²)"] C --> D D --> E["n→∞ で右辺→0<br/>= 確率収束(弱法則)"]
4. 大数の強法則(SLLN)と収束の強さの違い
強法則は同じ i.i.d.( が存在すれば分散の有限性すら不要)で、より強い結論を出す:
弱法則と強法則の差(準1級の山):
| 弱法則(WLLN) | 強法則(SLLN) | |
|---|---|---|
| 収束の種類 | 確率収束 | 概収束 |
| 主張の形 | 各 で「外れる確率」が0に近づく | パスそのものが(確率1で) に収束する |
| 直観 | 「ある で外れている割合」が0へ | 「十分先では、ほぼすべてのパスが に張り付いて二度と離れない」 |
| 必要な仮定(標準) | (チェビシェフ証明の場合) | が存在すれば可(分散不要) |
| 強さ | 弱い | 強い(強法則 ⟹ 弱法則、逆は一般に不成立) |
| 証明の難度 | チェビシェフで易しい | 難しい(1級範囲。本ノートは主張と直観まで) |
含意の向き:強法則 ⟹ 弱法則。「各パスがほぼ確実に収束する」(概収束)なら「外れる確率も0に近づく」(確率収束)が従う。逆は一般に成り立たない(確率収束しても、特定のパスが無限回外れ続けることはありうる)。
強法則の証明は1級範囲なので本ノートでは扱わない。主張(概収束)と弱法則との違い(確率収束 vs 概収束、強⟹弱)が言えれば準1級は十分。
5. 収束概念の整理(確率収束・概収束・分布収束)
大数の法則と中心極限定理を区別するうえで核心。3つの収束を1つの表で押さえる。
| 収束の種類 | 記号 | 定義(要点) | 何に収束するか | 代表例 |
|---|---|---|---|---|
| 概収束 | (パスがほぼ確実に各点収束) | 点(確率変数 ) | 大数の強法則 | |
| 確率収束 | $\forall\varepsilon>0:\ P( | X_n-X | \ge\varepsilon)\to0$ | |
| 分布収束(法則収束) | 累積分布関数が収束 (連続点で) | 分布(の形) | 中心極限定理 中心極限定理(CLT) |
含意の向き(強い→弱い):
要するに大数の法則は「行き先が点 」(確率収束・概収束)、中心極限定理は「行き先が分布の形(正規)」(分布収束)。同じ標本平均を扱うのに、大数の法則は「 が という1点に潰れる」ことを、中心極限定理はその先で「 という拡大して見た揺らぎが正規分布の形になる」ことを述べる。収束先が点か形かで別の定理だと理解する。
6. 統計的確率の正当化(ベルヌーイの大数の法則)
確率の基本(定義・加法定理・乗法定理)で「統計的確率=相対頻度 の極限」と定義したが、その正当化が大数の法則。
事象 が起きたら1・起きなかったら0をとる指示変数 (ベルヌーイ)を考える。 とすると、
- 各試行の指示変数の平均
- 回の相対頻度 (相対頻度はまさに指示変数の標本平均)
これに大数の法則を適用すると 、すなわち
要するに**「試行を増やせば相対頻度は真の確率に収束する」**。これが「たくさん試せば頻度=確率」と安心して言える根拠。歴史的にはヤコブ・ベルヌーイが1713年に示した(ベルヌーイの大数の法則)。指示変数の分散は なので、第3節のチェビシェフ証明がそのまま使える()。
7. 適用限界(分散・期待値が無いと成り立たない)
大数の法則は母平均 が存在することが前提。チェビシェフ証明はさらに を使う。これらが無い分布では成り立たない。
代表例がコーシー分布:期待値の定義積分 が発散して が存在せず(確率変数の変換・モーメント母関数・積率:モーメント母関数も存在しない、特性指数 の安定分布)、標本平均 は をいくら増やしても1点に収束せず、 自身がまたコーシー分布のまま(散らばりが縮まない)。
要するに**「平均が無い分布では『真の平均』という収束先がそもそも無いので、標本平均も落ち着かない」**。大数の法則は無条件の万能定理ではない、という注意。
8. 試験での問われ方
- 2級(中核):大数の法則の意味(標本平均が母平均に近づく/サンプルを増やすほど推定が正確になる)、サイコロ・コインの収束、標本平均の期待値 ・分散 。「標本平均は で母平均に近づくか」「相対頻度は確率に近づくか」の正誤・選択。
- 2級の発展的事項/準1級:チェビシェフの不等式による弱法則の証明、確率変数の収束の種類(確率収束・概収束)、大数の弱法則 vs 強法則(確率収束 vs 概収束、強⟹弱)、概収束・強法則の紹介。証明の穴埋め、収束概念の区別が問われる。
- 準1級(応用):推定量の一致性(標本平均が母平均の一致推定量=確率収束する)の根拠としての位置づけ、中心極限定理との対比(点への収束 vs 分布への収束)。
- ※公式の出題範囲表は改訂されうる。とくに2級の「発展的事項」の扱い・準1級範囲は受験前に最新の範囲表で要最新確認。
数式の直観的意味
なぜ が大数の法則の本体なのか
大数の法則の中身は実は 「標本平均の散らばりが0に潰れる」 ことに尽きる。標本平均の標準偏差(標準誤差)は
が増えると で縮む。たとえば を100倍にすると散らばりは 。「平均をとる個数を増やすと、たまたまの偏りが打ち消し合って標本平均がブレなくなる」——これが収束の物理的実体。チェビシェフはこの「散らばりの縮小」を「外れる確率の縮小」に翻訳する変換器にすぎない。
なぜチェビシェフで十分なのか(緩い上限でも証明になる理由)
チェビシェフの上限 は分布の形を仮定しない緩い上限で、実際の外れ確率はもっと小さい(シミュ②参照)。だが弱法則の証明に必要なのは**「上限が0に行く」ことだけ**。実際の確率はその下に挟まれるので、上限が0なら実際も0。緩くても0へ落ちれば証明として十分——ここがチェビシェフが証明道具として強力な理由。精密な収束の速さ( スケール)まで知りたいときに中心極限定理が要る。
なぜ「確率収束」と「概収束」は別物なのか(点列の比喩)
- 概収束:「ほぼすべてのパス(無限列) が、ある番号から先はずっと の近くに居続けて二度と離れない」。1本ごとの数列の収束を、確率1の について要求する。
- 確率収束:「各 という時刻のスナップショットで、 から離れているパスの割合が0に近づく」。ある特定のパスが時々遠くへ飛ぶことは許す(飛ぶパスの『割合』が小さくなればよい)。
比喩:教室で全員が席に着く過程。概収束=「ほぼ全員が、ある時刻以降ずっと着席して立たない」。確率収束=「各瞬間に立っている人の割合が0に近づく(同じ人が時々立つのは許す)」。前者の方が強い要求なので 概収束 ⟹ 確率収束。
なぜ大数の法則と中心極限定理は別の定理なのか(潰す vs 拡大する)
標本平均 をそのまま見ると、散らばり で1点 に潰れる(大数の法則・収束先は点)。これだと潰れた後は形が見えない。そこで 倍に拡大して見る: の分散は で一定に保たれ、その分布が という形に収束する(中心極限定理・収束先は分布)。要するに大数の法則は虫眼鏡なしで「点に潰れる」を、中心極限定理は の虫眼鏡で「揺らぎの形が正規」を見ている。同じ の別の側面。→ 中心極限定理(CLT)
⚠️ 引っかけポイント・頻出論点・級ごとの差
- 「標本平均が母平均に近づく」=大数の法則/「標本平均の分布が正規になる」=中心極限定理(最頻出の取り違え):前者は収束先が点 (確率/概収束)、後者は収束先が分布の形(分布収束)。混同しない。「 を増やすと が正規分布に近づく」は誤り( は に潰れる。正規に近づくのは標準化した )。
- 弱法則の証明で を と書かない:チェビシェフに代入するのは標本平均の分散 。母分散 をそのまま入れると が出ず0に行かない。 の約分が命。
- 確率収束 vs 概収束(準1級):確率収束は「各 で外れる確率→0」、概収束は「パスがほぼ確実に収束」。概収束⟹確率収束(強→弱)、逆は不成立。WLLN=確率収束、SLLN=概収束を取り違えない。
- 「大数の法則で1回の結果が平均に近づく」は誤り:収束するのは標本平均であって個々の試行ではない。サイコロを多く振っても1回ごとの目は1〜6でランダムなまま。近づくのは「ここまでの平均」。
- 「ギャンブラーの誤謬」との混同:「表が続いたから次は裏が出やすい」は誤り(独立試行は過去を覚えない)。大数の法則は「割合が長期的に0.5へ」と言うだけで、「埋め合わせが起きる」とは言わない。差 はむしろ増える傾向すらある(縮むのは割合 )。
- 分散(期待値)が無いと成り立たない:コーシー分布では が存在せず標本平均が収束しない。「どんな分布でも標本平均は収束する」は誤り。母平均の存在が前提(チェビシェフ証明はさらに )。
- i.i.d. の仮定:標準的な大数の法則は独立同分布が前提。独立でない・分布が違う列では別の条件が要る(弱法則は無相関+分散有界などに緩められるが、準1級では i.i.d. 版で十分)。
- チェビシェフの上限は確率なのに1を超えることがある: は が小さいと1を超える(例: で5.0)。これは「上限としての情報が無い(確率は当然1以下)」状態。 が大きくなって初めて意味のある上限になる。誤りではなく、緩い上限の性質。
- 級差:2級=意味と標本平均の収束(・、相対頻度→確率)/2級発展・準1級=チェビシェフによる弱法則の証明・確率収束/概収束の区別・強法則の紹介/準1級=一致性の根拠・中心極限定理との対比。
よくある疑問
Q1. 大数の法則と中心極限定理って、結局どう違うの?
収束する先が違います。 大数の法則は「標本平均 が点 に近づく」、中心極限定理は「標本平均(を標準化したもの)の分布の形が正規に近づく」。 そのものは に潰れていくので、「 を増やすと が正規分布になる」というのは誤りです。正規分布に近づくのは、潰れる前に 倍の虫眼鏡で拡大して見た のほうです。「点に潰れる(大数)」と「揺らぎの形が正規(中心極限)」は、同じ の別々の側面だと考えてください。
Q2. 弱法則の証明で、なぜ じゃなくて を代入するの?
チェビシェフに入れるのは「いま見ている確率変数の分散」だからです。いま見ているのは標本平均 で、その分散は (母分散 ではない)。ここで母分散 をそのまま入れてしまうと、 となり、右辺に が出てこないので で0に行きません。 の約分が証明の命です。
Q3. 「確率収束」と「概収束」の違いがピンとこない
教室で全員が席に着く過程を想像してください。概収束=「ほぼ全員が、ある時刻以降ずっと着席して二度と立たない」(1人ごとの動きが落ち着く)。確率収束=「各瞬間に立っている人の割合が0に近づく」(同じ人が時々立つのは許す)。前者のほうが強い要求なので、概収束 ⟹ 確率収束。大数の強法則は前者、弱法則は後者です。
Q4. 「表が5回続いたから次は裏が出やすい」は大数の法則で正しい?
間違いです(ギャンブラーの誤謬)。 コインは過去を覚えていないので、次が裏になりやすいことはありません(独立試行)。大数の法則が言うのは「割合 が長期的に0.5へ近づく」だけで、「これまでの偏りが埋め合わせられる」とは言っていません。実際、表と裏の回数の差 はむしろ大きくなる傾向すらあります。縮むのは差ではなく割合です。
Q5. どんな分布でも標本平均は収束するの?
いいえ。 母平均 が存在することが前提です(チェビシェフ証明はさらに分散が有限なことを使います)。コーシー分布のように平均が存在しない分布では、標本平均は収束しません。「平均という収束先がそもそも無い」からです。
まとめ
- 大数の法則=「データを増やすほど標本平均が母平均 に近づく」。収束先は点 (分布の形ではない)。
- 弱法則(確率収束)の証明は、チェビシェフの不等式に を代入して 。記述統計(チェビシェフ)と確率()の合流点。
- **強法則(概収束)**は弱法則より強く、強法則 ⟹ 弱法則。準1級は主張と違いまで。
- 統計的確率(相対頻度 → 確率)の根拠であり、コーシー分布のように平均が無い分布では成り立たない。
- 次は、収束先で止まらず「分布の形」まで述べる中心極限定理(中心極限定理(CLT))へ。
対応するシミュレーション
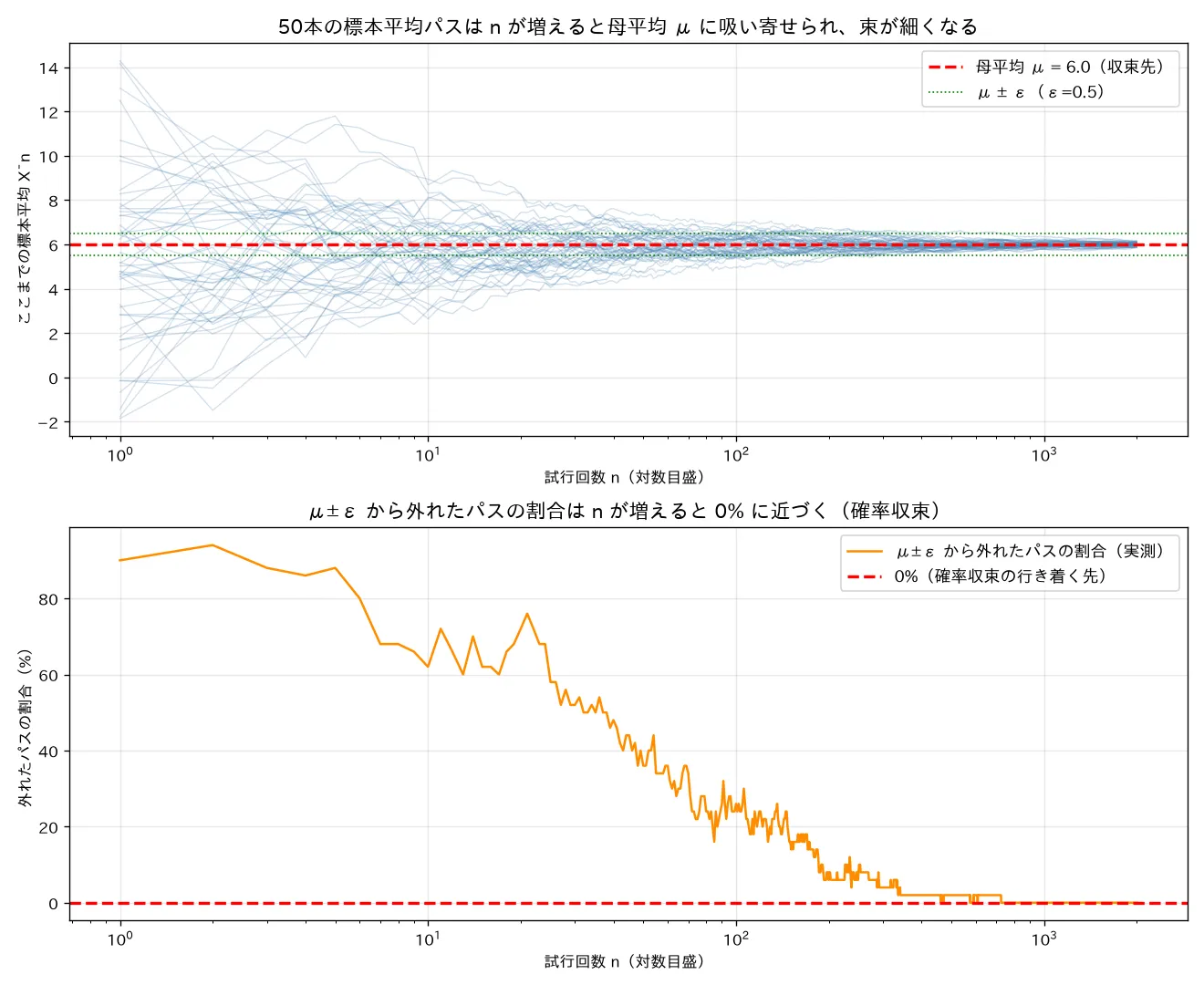
simulations/taisuu_no_housoku_takipath.py- 何を示すか:独立な実験(パス)を50本同時に走らせ、各パスで「ここまでの標本平均 」を と伸ばす。50本の束が母平均 に吸い寄せられ、束の幅(標準偏差)が で細くなる「じょうご」を描く。下段で「 から外れたパスの割合」が0%へ減る(確率収束の定義そのもの)を可視化。
- 実行結果(seed=0、):束の実測SDは で3.898→で0.08、理論 (4.0→0.089)とほぼ一致。 から外れた割合は で90%→で6%→以降0%。束が点 に潰れ、外れる確率が0へ落ちることを実証。
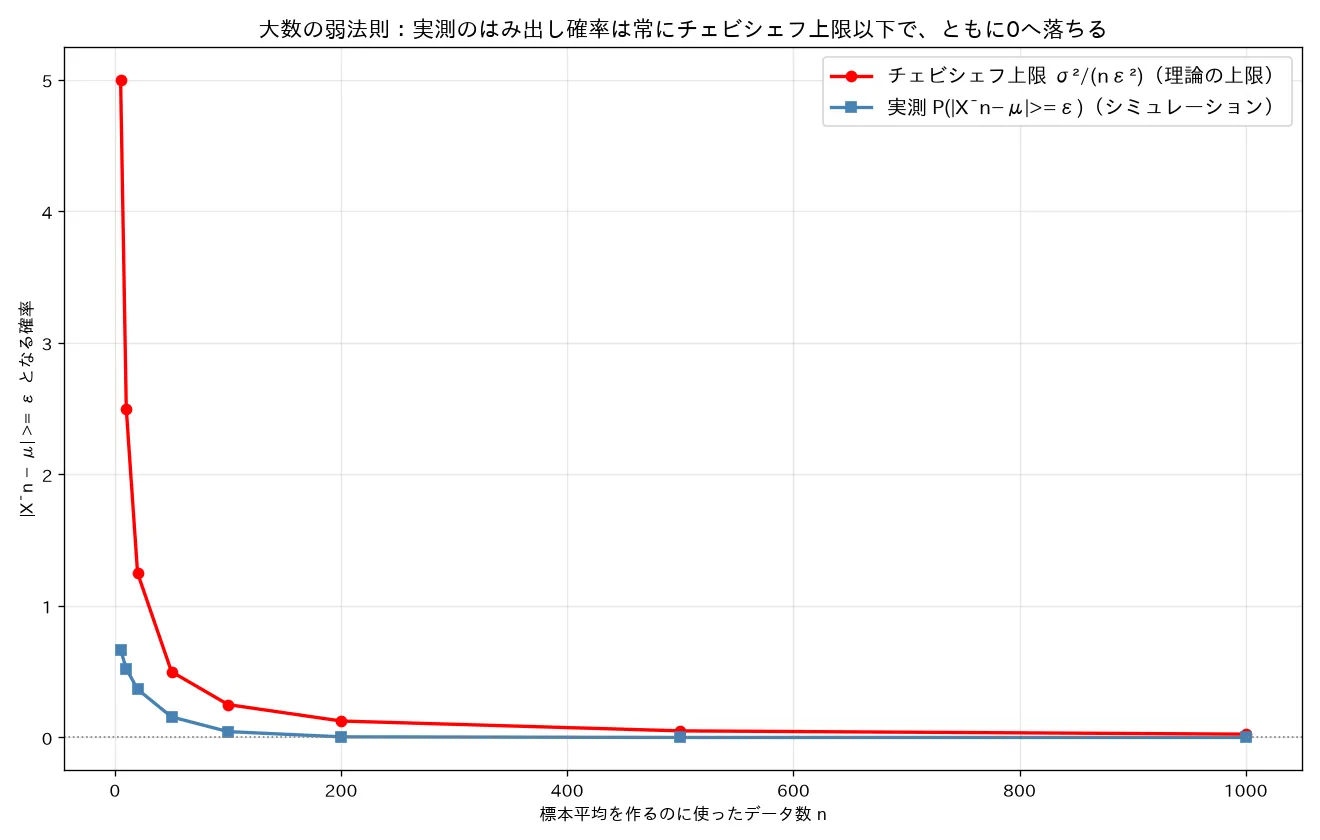
simulations/taisuu_no_housoku_chebyshev.py- 何を示すか:弱法則の証明を数値で。指数分布(右に歪む、)から 個の平均を作る実験を各 につき2万回くりかえし、実測のはみ出し確率 とチェビシェフ上限 を同じグラフに重ねる。「実測 ≤ 上限、ともに0へ」を確認。
- 実行結果(seed=0、):すべての で実測 ≤ チェビシェフ上限。:実測0.6657 ≤ 上限5.0(上限が1超=情報なし)/:実測0.0445 ≤ 上限0.25/:実測0.0046 ≤ 上限0.125/:実測0.0 ≤ 上限0.025。上限が で0へ落ち、実測がその下で0へ。証明 を数値で裏づけ。実測が上限よりかなり下なのはチェビシェフが緩い(distribution-free)ため。
関連ノート
- 標準化(z得点)・偏差値・チェビシェフの不等式 ── 標準化≠正規化/偏差値に上限なし/どんな分布でも成り立つ歯止め(チェビシェフの不等式 ── 弱法則の証明の道具。 の導出はここ。後方リンク)
- 期待値・分散の性質(線形性・和の分散・共分散)(期待値・分散の性質 ── の導出はここ。弱法則の証明のもう一方の道具。後方リンク)
- 確率変数(離散・連続)と期待値・分散(確率変数・期待値・標本平均 ── 期待値=長期平均の意味、 の連結はここで予告済み。後方リンク)
- 確率の基本(定義・加法定理・乗法定理)(確率の定義 ── 統計的確率(相対頻度の極限)を大数の法則が正当化する。指示変数の標本平均=相対頻度。後方リンク)
- 確率変数の変換・モーメント母関数・積率(変換・モーメント母関数 ── コーシー分布など期待値・MGFが存在しない分布で大数の法則が破れる注意の接続先。後方リンク・ゆるく)
- 中心極限定理(CLT)(中心極限定理 ── 収束先で止まらず「分布の形」まで述べる。大数の法則=点への収束/CLT=分布への収束の対比。前方リンク・次トピック)