← 統計検定テキスト 一覧
📊 対象級:2級 ・ 準1級 | 重要度:A(頻出)
期待値・分散の性質(線形性・和の分散・共分散)
要点(BLUF)
- 期待値の加法性 E[X+Y]=E[X]+E[Y] は独立性を一切仮定せず常に成立(同時分布の和から導出、p(x,y)=pXpY を使わない)。線形性 E[aX+bY]=aE[X]+bE[Y]。分散は V[aX+b]=a2V[X](b は消える=平行移動で散らばり不変、a は2乗で出る)。
- 共分散 Cov(X,Y)=E[(X−μX)(Y−μY)]=E[XY]−E[X]E[Y](標本共分散 sxy の母集団版・2変数の記述(散布図・共分散・相関係数)── 相関≠因果/rは直線関係しか測れない/外れ値1点で激変)。和の分散 V[X+Y]=V[X]+V[Y]+2Cov(X,Y)、差でも +V[Y] で引かれるのは共分散だけ。母相関 ρ=Cov/(σXσY)∈[−1,1]。
- 核心の非対称性:期待値の加法性は独立不要/分散の加法性は無相関(独立)が必要。独立 ⟹ 無相関 ⟹ V[X+Y]=V[X]+V[Y]。逆は不成立(Y=X2 は無相関だが従属)。応用:二項分布 V=np(1−p)、標本平均 V[Xˉ]=σ2/n は独立和の分散。
このトピックで一番大事なのは、たった1つの非対称性です。「期待値の足し算は独立を仮定せずいつでも成り立つ/分散の足し算は無相関(独立)のときだけ成り立つ」── 期待値には余計な項が出ませんが、分散には 2Cov(X,Y)(2変数が一緒に動く度合い)の項が出ます。これが本トピックの山です。
本文
1. 期待値の線形性
定数倍・定数足し(1変数)
E[aX+b]=aE[X]+b(a,b は定数)
要するに**「定数倍は外に出せて、足した定数はそのまま足される」**。これは X がどんな分布でも成り立つ(導出は「数式の直観的意味」)。
和の期待値(2変数)── 独立を仮定しないのが最重要
E[X+Y]=E[X]+E[Y](独立でなくてもつねに成立)
要するに**「和の期待値=期待値の和。2変数が絡んでいても無条件でOK」**。ここが期待値の最大の強み。独立の仮定 p(x,y)=pX(x)pY(y) を1度も使わずに導ける(「数式の直観的意味」)。これが「分散の加法性」と決定的に違う点。
一般形(まとめて使う形)
E[aX+bY]=aE[X]+bE[Y](つねに成立)
さらに n 個でも E[∑i=1naiXi]=∑i=1naiE[Xi]。期待値は完全に線形で、独立性に一切依存しない。
2. 分散の性質:V[aX+b]=a2V[X]
V[aX+b]=a2V[X](σ[aX+b]=∣a∣σ[X])
要するに**「足した定数 b は分散に効かない(散らばりは平行移動で変わらない)。掛けた定数 a は2乗で効く」**。
3. 共分散:定義と計算公式
Cov(X,Y)=E[(X−μX)(Y−μY)]=E[XY]−E[X]E[Y]
要するに**「X が平均からズレる向き × Y が平均からズレる向き、の平均」=「積の期待値 − 期待値の積」**。2変数が一緒に同じ向きに動くか、逆向きに動くかを測る。
- 両方とも平均より上(または両方とも下)になりやすい → 積が正 → Cov>0(正の相関)
- 片方が上のとき他方が下になりやすい → 積が負 → Cov<0(負の相関)
- どちらでもなくバラバラ → 打ち消し合って Cov≈0(無相関)
V[X]=E[X2]−(E[X])2 の2変数版で、Y=X とすれば Cov(X,X)=E[X2]−(E[X])2=V[X] に戻る。
Phase 1 の標本共分散とのつながり:記述統計の標本共分散 sxy=n1∑i=1n(xi−xˉ)(yi−yˉ)(2変数の記述(散布図・共分散・相関係数)── 相関≠因果/rは直線関係しか測れない/外れ値1点で激変)は、この Cov(X,Y) の標本版。xˉ→μX、n1∑→E[⋅] と置き換えれば母集団・理論版になる。
共分散の双線形性(準1級の共分散行列計算で効く):
Cov(aX+b, cY+d)=acCov(X,Y),Cov(X, Y+Z)=Cov(X,Y)+Cov(X,Z)
定数足し b,d は共分散に効かない、定数倍 a,c は掛かって出る。Cov(X,X)=V[X] も基本性質。
4. 和の分散:V[X+Y]=V[X]+V[Y]+2Cov(X,Y)
V[X+Y]=V[X]+V[Y]+2Cov(X,Y)
要するに**「和の分散=各分散の和+一緒に動く度合いの2倍」**。期待値と違って、ここに Cov という余計な項が出る(導出は「数式の直観的意味」)。
差の分散(Y→−Y とすると Cov(X,−Y)=−Cov(X,Y)、V[−Y]=V[Y]):
V[X−Y]=V[X]+V[Y]−2Cov(X,Y)
⚠️ 差でも分散は足し算が基本(+V[Y])。引かれるのは共分散の項だけ。「差だから V[X]−V[Y]」は誤り。
一般形:
V[aX+bY]=a2V[X]+b2V[Y]+2abCov(X,Y),V[i=1∑nXi]=i=1∑nV[Xi]+2i<j∑Cov(Xi,Xj)
n 変数だと、すべてのペア (i,j) の共分散が効く。全ペアが無相関なら第2項が消えて、分散はきれいに足し算になる(次節)。
5. 独立性との関係 ── 本トピック最大の引っかけ
独立 ⟹ 無相関(共分散ゼロ)
X,Y が独立なら E[XY]=E[X]E[Y] が成り立つ(導出は「数式の直観的意味」)。したがって
Cov(X,Y)=E[XY]−E[X]E[Y]=0(独立 ⇒ 無相関).
独立なら分散は足し算(分散の加法性)
Cov=0 なら V[X+Y]=V[X]+V[Y]+2⋅0。つまり
X,Y が独立(無相関)⇒V[X+Y]=V[X]+V[Y]
n 個でも、互いに独立なら全ペアの共分散が0なので V[∑Xi]=∑V[Xi]。これが後の二項分布・標本平均の計算の土台(第7節)。
逆は成り立たない ── 無相関でも独立とは限らない
独立⇒無相関だが無相関⇒独立
Cov=0(無相関)は直線的な関係がないことしか言わない。非線形な依存があっても共分散は0になりえる(2変数の記述(散布図・共分散・相関係数)── 相関≠因果/rは直線関係しか測れない/外れ値1点で激変 の「r≈0 でもU字の強い関係がありうる」と同じ話)。
反例:X を −1,0,1 が等確率 31 の確率変数、Y=X2 とおく。Y は完全に X で決まる(強い依存=独立でない)のに:
- E[X]=3−1+0+1=0
- E[XY]=E[X⋅X2]=E[X3]=3(−1)3+03+13=0
- よって Cov(X,Y)=E[XY]−E[X]E[Y]=0−0⋅E[Y]=0(無相関)
Y=X2 という完全な依存関係があるのに共分散は0。「無相関だから独立」は誤り。
例外:X,Y が二変量正規分布に従う場合に限り「無相関 ⟺ 独立」が成り立つ(準1級)。一般には片方向だけ。
期待値の加法性 vs 分散の加法性(核心の対比)
| 期待値 | 分散 |
|---|
| 加法性の式 | E[X+Y]=E[X]+E[Y] | V[X+Y]=V[X]+V[Y]+2Cov(X,Y) |
| 独立は必要か | 不要(つねに成立) | 無相関(独立)が必要 |
| 独立でないとき | そのまま成立 | +2Cov の補正が必要 |
| 差のとき | E[X−Y]=E[X]−E[Y] | V[X−Y]=V[X]+V[Y]−2Cov(+のまま) |
この表が本トピックで覚える唯一にして最大のポイント。 期待値は無条件、分散は条件付き(無相関のとき)。試験はこの差を執拗に突いてくる。
下のフローは「独立性から何が言えるか」の一方向の含意(点線の「逆は不成立」が反例)。
flowchart LR
A["X, Y が独立"] --> B["E[XY]=E[X]E[Y]"]
B --> C["Cov(X,Y)=0(無相関)"]
C --> D["V[X+Y]=V[X]+V[Y]"]
C -.->|"逆は不成立"| A
6. 相関係数(母集団版)
共分散は単位に依存して大小で強さを測れない(2変数の記述(散布図・共分散・相関係数)── 相関≠因果/rは直線関係しか測れない/外れ値1点で激変 と同じ難点)。そこで標準偏差で割って無次元化したのが母相関係数:
ρ=ρXY=σXσYCov(X,Y)(−1≤ρ≤1)
要するに**「共分散を単位で割って −1∼1 に正規化したもの」**。標本相関係数 r(2変数の記述(散布図・共分散・相関係数)── 相関≠因果/rは直線関係しか測れない/外れ値1点で激変)の母集団・理論版。
- −1≤ρ≤1 の証明は標本版と同じコーシー・シュワルツ(期待値版 (E[(X−μX)(Y−μY)])2≤E[(X−μX)2]E[(Y−μY)2] から ρ2≤1)。2変数の記述(散布図・共分散・相関係数)── 相関≠因果/rは直線関係しか測れない/外れ値1点で激変 の導出をそのまま ∑→E に読み替えればよい。
- ρ=±1 ⟺ Y=aX+b の完全な直線関係(確率1で)。
- ρ=0 が無相関。ρ=0 でも独立とは限らない(第5節)。
7. 応用:級の実戦力に直結する2つの計算
二項分布の分散 np(1−p) を「独立和」で出す
二項分布 X∼B(n,p) は「成功確率 p の試行を独立に n 回やった成功回数」。これは独立なベルヌーイ変数 n 個の和として書ける:
X=X1+X2+⋯+Xn,Xi∼Bernoulli(p) (独立)
各 Xi は E[Xi]=p、V[Xi]=p(1−p)(確率変数(離散・連続)と期待値・分散 で導出済み)。
- 期待値(線形性、独立不要):E[X]=∑i=1nE[Xi]=np。
- 分散(独立だから加法性が使える):V[X]=∑i=1nV[Xi]=np(1−p)。
母関数を使わずに np(1−p) がこれだけで出る。「分散の加法性が独立で成り立つ」ことの威力がよく分かる例。
標本平均の分散 V[Xˉ]=σ2/n(大数の法則・CLTへの布石)
母平均 μ、母分散 σ2 の母集団から独立に n 個を取った標本 X1,…,Xn(独立同分布 i.i.d.)。標本平均 Xˉ=n1∑i=1nXi:
- 期待値(線形性):E[Xˉ]=n1∑E[Xi]=μ。標本平均の期待値は母平均そのもの(不偏性)。
- 分散(独立 ⟹ 加法性、さらに V[aX]=a2V[X] の a=1/n):
V[Xˉ]=V[n1i=1∑nXi]=n21i=1∑nV[Xi]=n21⋅nσ2=nσ2.
要するに**「標本を増やすほど標本平均のばらつきは 1/n で小さくなる」。標準偏差にすると σ/n で、これが標準誤差(standard error)。この V[Xˉ]=σ2/n が、大数の法則(大数の法則(弱法則・強法則):n→∞ で V[Xˉ]→0)と中心極限定理**(中心極限定理(CLT):Xˉ∼N(μ,σ2/n))の両方の出発点。n21 の n2 と独立和の n 個ぶんが約分して 1/n になるこの計算は推測統計のいたるところで出る。
8. 準1級への接続:共分散行列(分散共分散行列)
準1級では変数が増え、ベクトル・行列で一気に扱う。確率ベクトル X=(X1,…,Xp)⊤ に対して:
- 期待値ベクトル μ=E[X]=(E[X1],…,E[Xp])⊤
- 分散共分散行列(共分散行列)
Σ=V[X]=E[(X−μ)(X−μ)⊤],Σij=Cov(Xi,Xj)
対角に各変数の分散 Σii=V[Xi]、非対角に共分散 Σij=Cov(Xi,Xj) を並べた行列(2×2 の例):
Σ=(V[X1]Cov(X2,X1)Cov(X1,X2)V[X2])
Cov(Xi,Xj)=Cov(Xj,Xi) なので**Σ は対称行列**。さらに任意のベクトル a について a⊤Σa=V[a⊤X]≥0 なので半正定値(本節4-2の一般形 V[aX1+bX2]=a2V[X1]+b2V[X2]+2abCov が、行列で a⊤Σa とコンパクトに書ける)。この Σ が多変量正規分布・主成分分析・マハラノビス距離の中心的な道具になる(準1級・Phase 6 多変量解析。※該当ノートはファイル名未確定のため将来作成時にリンク)。
試験での問われ方
- 2級(主):E[aX+b]・E[X+Y]、V[aX+b]=a2V[X]、Cov=E[XY]−E[X]E[Y]、V[X+Y]=V[X]+V[Y]+2Cov、独立⟹Cov=0、母相関、二項分布の分散 np(1−p)、標本平均の分散 σ2/n(標準誤差 σ/n)。公式問題集に出題実績多数。
- 準1級:期待値ベクトル、分散共分散行列 Σ(対角=分散、非対角=共分散、対称・半正定値)、多変量への一般化、二変量正規での「無相関⟺独立」。
- ※出題範囲は改訂されうる。受験前に最新の範囲表で要最新確認。
数式の直観的意味
なぜ E[aX+b]=aE[X]+b か(定義の分解)
期待値の定義 E[g(X)]=∑xg(x)p(x)(連続は ∑→∫)に g(X)=aX+b を入れて和を分解する:
E[aX+b]=x∑(ax+b)p(x)=ax∑xp(x)+bx∑p(x)=aE[X]+b⋅1=aE[X]+b.
最後に ∑xp(x)=1(確率の合計は1)を使う。X がどんな分布でも成り立つ。
なぜ E[X+Y]=E[X]+E[Y] は独立不要か(導出)
2変数の期待値は同時分布 p(x,y)=P(X=x,Y=y) で E[g(X,Y)]=∑x∑yg(x,y)p(x,y) と定義(厳密化は 同時分布・周辺分布・条件付き分布)。g=X+Y を代入:
E[X+Y]=x∑y∑(x+y)p(x,y)=x∑y∑xp(x,y)+x∑y∑yp(x,y).
第1項は x を内側の ∑y の外に出すと ∑yp(x,y)=pX(x)(Y を足し潰した周辺分布・同時分布・周辺分布・条件付き分布)になり ∑xxpX(x)=E[X]。第2項も同様に E[Y]。独立の形 p(x,y)=pXpY を一度も使わない。だから常に成立。
なぜ V[aX+b]=a2V[X] か(b が消える理由)
Z=aX+b で E[Z]=aE[X]+b、ズレ Z−E[Z]=(aX+b)−(aE[X]+b)=a(X−E[X]) ── b が引き算で消える。2乗の期待値で a2 が外へ:V[aX+b]=E[a2(X−E[X])2]=a2V[X]。分散は「平均からのズレ」だけで決まる量だから、平行移動 +b では不変、a 倍はズレを2乗するので a2 倍。
なぜ Cov=E[XY]−E[X]E[Y] か(導出)
定義の中身を展開し、期待値の線形性で項ごとにバラす(μX,μY は定数):
Cov(X,Y)=E[(X−μX)(Y−μY)]=E[XY]−μXE[Y]−μYE[X]+μXμY=E[XY]−μXμY.
中央の2項 −μXμY−μYμX=−2μXμY と末尾 +μXμY が打ち消して −μXμY が残る(分散公式と同構造)。
なぜ V[X+Y]=V[X]+V[Y]+2Cov か(導出)
V[X+Y]=E[(X+Y)2]−(E[X+Y])2 を展開:
E[(X+Y)2]=E[X2]+2E[XY]+E[Y2],(E[X+Y])2=(E[X])2+2E[X]E[Y]+(E[Y])2.
引き算して {E[X2]−(E[X])2}+{E[Y2]−(E[Y])2}+2{E[XY]−E[X]E[Y]}=V[X]+V[Y]+2Cov(X,Y)。
なぜ独立で Cov=0 か(独立がここで効く)
独立 p(x,y)=pX(x)pY(y)(条件付き確率・独立性・全確率の定理)なら
E[XY]=x∑y∑xypX(x)pY(y)=(x∑xpX(x))(y∑ypY(y))=E[X]E[Y].
二重和が「x だけの和」と「y だけの和」の積に分離できるのは、p(x,y) が積の形だから。独立がここで初めて本質的に効く。よって Cov=E[XY]−E[X]E[Y]=0。
期待値の加法性 vs 分散の加法性(なぜ差が出るか)
期待値の和の導出には積 XY が現れず、周辺分布に潰すだけで済む。一方、分散の和には必ず E[XY] が現れ、これを E[X]E[Y] に分離するには独立が要る。E[XY]=E[X]E[Y] のズレがそのまま共分散として残るかどうかが両者の差。要するに**「積 XY が出るかどうか」**が分かれ目。
⚠️ 引っかけポイント・頻出論点・級ごとの差
- 期待値の加法性は独立不要/分散の加法性は無相関必要(最重要):本トピック最大の山。E[X+Y]=E[X]+E[Y] はいつでも、V[X+Y]=V[X]+V[Y] は無相関のときだけ。混同しない。
- 独立 ⟹ 無相関だが逆は不成立:Cov=0 は「直線関係なし」を言うだけ。Y=X2(X が −1,0,1 等確率)は E[XY]=E[X3]=0, E[X]=0 で Cov=0 なのに完全従属。「無相関だから独立」は誤り。例外は二変量正規(無相関⟺独立)。
- 差の分散も +V[Y]:V[X−Y]=V[X]+V[Y]−2Cov。「差だから V[X]−V[Y]」は誤り。分散本体は足し算、引かれるのは共分散だけ。独立なら V[X−Y]=V[X]+V[Y]。
- V[aX+b] で b を消し忘れ/a を1乗にする:定数足しは分散に効かない、定数倍は2乗。標準偏差なら ∣a∣ 倍。
- 標本平均の分散は σ2/n(σ2/n2 ではない):n21⋅nσ2 の約分。n を増やすとばらつきが 1/n で縮む。
- Cov(X,X)=V[X]:共分散の同変数版が分散。分散共分散行列の対角になる。
- 共分散の符号と大きさ:符号が向き、大きさは単位依存で強さを測れない(無次元化が ρ)。Cov>0 で和の分散は増、<0 で減。
- 級差:2級=線形性・V[aX+b]・共分散・V[X+Y]・独立⟹無相関・母相関・np(1−p)・σ2/n。準1級=期待値ベクトル・分散共分散行列 Σ(対称・半正定値、a⊤Σa=V[a⊤X])・多変量への一般化。
よくある疑問
Q1. なぜ期待値だけ独立がいらないのに、分散には独立がいるの?
A. 期待値の和の導出では、同時分布 p(x,y) を足し潰して周辺分布にするだけで済み、p(x,y)=pXpY という独立の形は使いませんでした。一方、分散の和には必ず E[XY] が現れ、これを E[X]E[Y] に分離するには独立が必要。E[XY]=E[X]E[Y] のズレがそのまま共分散 Cov=E[XY]−E[X]E[Y] で、これが残るかどうかが両者の差です。要するに**「積 XY が出るかどうか」**が分かれ目です。
Q2. 「無相関」と「独立」は同じ意味では?
A. 違います。独立 ⟹ 無相関は正しいですが、逆は不成立。無相関は Cov=0、つまり「直線的な関係がない」だけ。Y=X2 のような非線形の完全な依存があっても Cov=0 になりえます(反例)。「無相関だから独立、だから何でも分離できる」と進めると誤りです。ただし二変量正規分布に限れば「無相関 ⟺ 独立」が成り立ちます(準1級)。
Q3. 差の分散はなぜ V[X]−V[Y] じゃないの?
A. 分散は必ず非負で、ばらつきは引き算で減るものではないからです。V[X−Y]=V[X+(−Y)] と見て、V[−Y]=(−1)2V[Y]=V[Y](a=−1 を2乗)。共分散は Cov(X,−Y)=−Cov(X,Y) で符号が反転。結果 V[X−Y]=V[X]+V[Y]−2Cov(X,Y)。分散の本体は足し算(+V[Y])のまま、符号が変わるのは共分散の項だけです。独立なら V[X−Y]=V[X]+V[Y](和でも差でも同じ)。
Q4. 標本平均の分散がなぜ σ2/n(σ2/n2 じゃない)?
A. Xˉ=n1∑Xi で、定数 n1 は2乗で外に出るので n21V[∑Xi]。独立なので V[∑Xi]=∑V[Xi]=nσ2。よって n21⋅nσ2=nσ2。n21 の n2 と、独立和の n 個ぶんが約分して n1 が残るのがポイントです。
Q5. Cov(X,X) は何になる?
A. Cov(X,X)=E[X⋅X]−E[X]E[X]=E[X2]−(E[X])2=V[X]。共分散の特別な場合(同じ変数同士)が分散です。だから分散共分散行列の対角に分散が並びます。
まとめ
- 期待値は完全に線形:E[aX+bY]=aE[X]+bE[Y]。独立は一切不要、つねに成立。同時分布の和から導出され、独立の仮定 p(x,y)=pXpY をどこにも使わないのが理由。
- V[aX+b]=a2V[X]:足した定数 b は消える(平行移動で散らばりは不変)、掛けた定数 a は2乗で出る。
- 共分散 Cov(X,Y)=E[XY]−E[X]E[Y] は標本共分散 sxy の母集団版。Cov(X,X)=V[X]。
- 和の分散 V[X+Y]=V[X]+V[Y]+2Cov(X,Y)。差でも +V[Y]、引かれるのは共分散だけ。
- 核心の非対称性:期待値の加法性は無条件、分散の加法性は無相関(独立)のときだけ。
- 独立 ⟹ 無相関だが、逆は不成立(Y=X2 が反例)。無相関は「直線関係なし」を言うだけ。
- 応用:二項分布の分散 np(1−p)、標本平均の分散 σ2/n(標準誤差 σ/n)はどちらも独立和の分散から出る。大数の法則・中心極限定理の出発点。
- 準1級:これらを期待値ベクトル・分散共分散行列 Σ(対称・半正定値)に一般化する。
対応するシミュレーション
simulations/kitaichi_bunsan_seishitsu_wa_no_bunsan.py
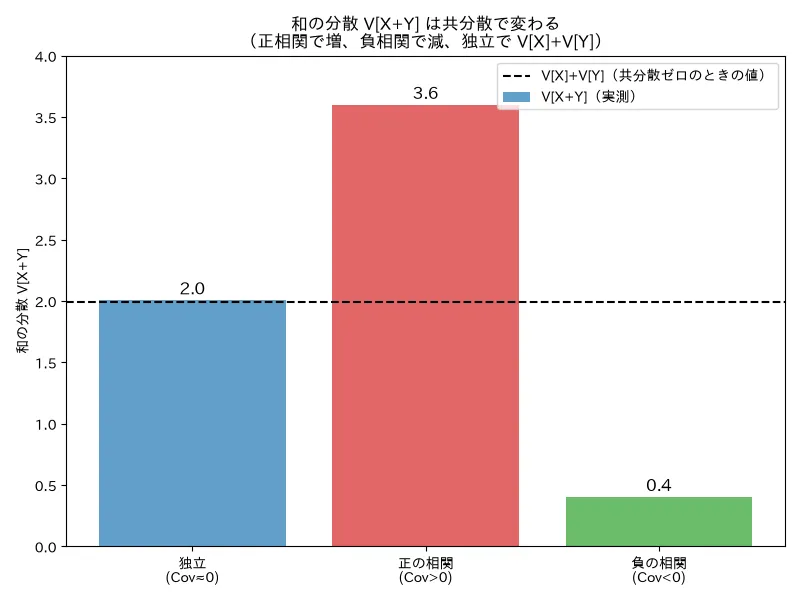
- 何を示すか:独立・正相関・負相関の3ケースで2変数を生成し、V[X+Y] の実測が公式 V[X]+V[Y]+2Cov に一致することを確認。3ケースの散布図と棒グラフも出力。
- 実行結果(seed=0、V[X]≈V[Y]≈1):独立 V[X+Y] 実測=2.005(公式2.005、分散の和1.995)/正相関 Cov=+0.799 で実測=3.598(分散の和2.0より大)/負相関 Cov=−0.800 で実測=0.401(分散の和2.0より小)。実測=公式が全ケース一致。和の分散が共分散で増減することを実証。
simulations/kitaichi_bunsan_seishitsu_nikou_bernoulli.py
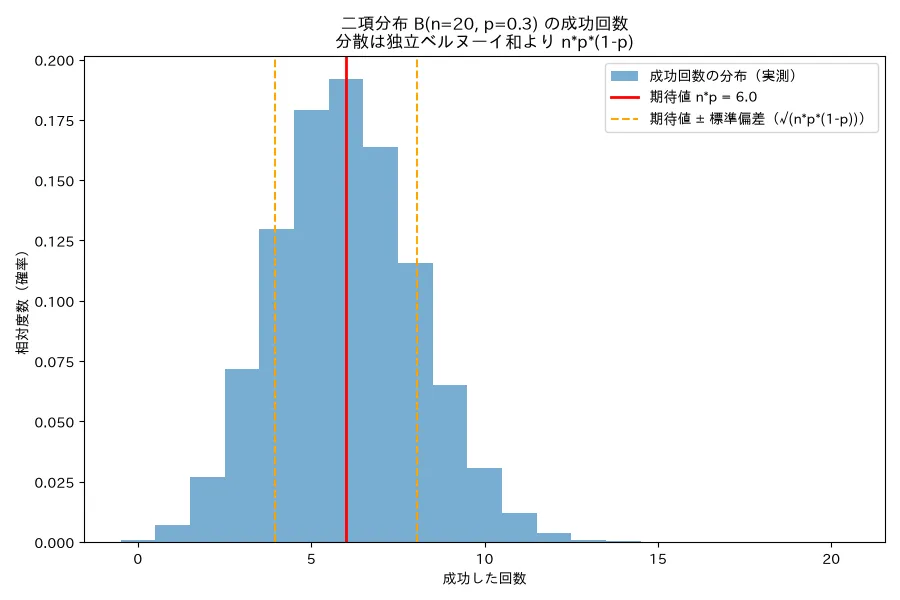
- 何を示すか:独立ベルヌーイ n 回の和(=二項分布)の分散が np(1−p) に一致することを確認。
- 実行結果(n=20,p=0.3):ベルヌーイ1回の分散 実測=0.21(理論 p(1−p)=0.21)/二項の期待値 実測=6.00(理論 np=6.0)/二項の分散 実測=4.19(理論 np(1−p)=4.2、n×ベルヌーイ分散=4.20とも一致)。独立和の分散=分散の和を二項分布で実証。
関連ノート