← 統計検定テキスト 一覧
📊 対象級:2級 | 重要度:A(頻出)
確率変数(離散・連続)と期待値・分散 ── PMF/PDF・E[X]・V[X]・分散公式の導出
要点(BLUF)
確率変数 X X X = 標本空間 Ω \Omega Ω 写像(関数) 。離散型 は確率質量関数 PMF p ( x ) = P ( X = x ) p(x)=P(X=x) p ( x ) = P ( X = x ) ∑ x p ( x ) = 1 \sum_x p(x)=1 ∑ x p ( x ) = 1 連続型 は確率密度関数 PDF f ( x ) f(x) f ( x ) ∫ f ( x ) d x = 1 \int f(x)\,dx=1 ∫ f ( x ) d x = 1 P ( a ≤ X ≤ b ) = ∫ a b f d x P(a\le X\le b)=\int_a^b f\,dx P ( a ≤ X ≤ b ) = ∫ a b f d x 1点の確率0 、f ( x ) f(x) f ( x ) F ( x ) = P ( X ≤ x ) F(x)=P(X\le x) F ( x ) = P ( X ≤ x ) 期待値 E [ X ] = ∑ x x p ( x ) E[X]=\sum_x x\,p(x) E [ X ] = ∑ x x p ( x ) ∫ x f ( x ) d x \int x f(x)\,dx ∫ x f ( x ) d x 確率で重みづけた平均=分布の重心=長期平均 。記述統計の平均(代表値 ── 平均・中央値・最頻値の定義と使い分け(外れ値への強さ・歪んだ分布での大小関係) )の母集団・理論版。分散 V [ X ] = E [ ( X − μ ) 2 ] = E [ X 2 ] − ( E [ X ] ) 2 V[X]=E[(X-\mu)^2]=E[X^2]-(E[X])^2 V [ X ] = E [( X − μ ) 2 ] = E [ X 2 ] − ( E [ X ] ) 2 σ = V [ X ] \sigma=\sqrt{V[X]} σ = V [ X ] 散らばり(ばらつき)の指標 ── 範囲・四分位範囲・分散・標準偏差・変動係数(なぜ偏差を2乗するか/なぜn−1で割るか) )の母集団・理論版。線形性・和の分散・共分散は次トピック 期待値・分散の性質(線形性・和の分散・共分散) (本ノートは1変数の基本まで)。
本文
確率変数とは(標本空間 → 実数の写像)
確率変数 X X X 標本空間 Ω \Omega Ω ω \omega ω X ( ω ) X(\omega) X ( ω ) X : Ω → R X:\Omega\to\mathbb{R} X : Ω → R X X X
flowchart LR
subgraph S["標本空間 Ω(偶然の結果)"]
a["表・表"]
b["表・裏"]
c["裏・裏"]
end
a -->|"X = 2"| R["実数 ℝ"]
b -->|"X = 1"| R
c -->|"X = 0"| R
例:コイン2回で表の回数 X X X ↦ 2 \mapsto2 ↦ 2 ↦ 1 \mapsto1 ↦ 1 ↦ 0 \mapsto0 ↦ 0
離散型確率変数 連続型確率変数 とりうる値 とびとび(0 , 1 , 2 , … 0,1,2,\dots 0 , 1 , 2 , … 連続(区間の実数すべて) 例 サイコロの目・表の回数・不良品数 身長・待ち時間・測定値 確率の与え方 PMF p ( x ) p(x) p ( x ) PDF f ( x ) f(x) f ( x )
離散:確率質量関数 PMF
p ( x ) = P ( X = x ) , p ( x ) ≥ 0 , ∑ x p ( x ) = 1 p(x)=P(X=x),\qquad p(x)\ge0,\quad \sum_{x}p(x)=1 p ( x ) = P ( X = x ) , p ( x ) ≥ 0 , x ∑ p ( x ) = 1 離散では p ( x ) p(x) p ( x ) p ( 1 ) = ⋯ = p ( 6 ) = 1 6 p(1)=\cdots=p(6)=\frac16 p ( 1 ) = ⋯ = p ( 6 ) = 6 1 = 1 =1 = 1
連続:確率密度関数 PDF(ここが最大の関門)
身長がぴったり170.000…cmになる確率は? 値が連続無限にあるので1点の確率は0。だから「1点の確率」ではなく「区間の確率」を考える。それを与えるのが PDF f ( x ) f(x) f ( x )
f ( x ) ≥ 0 , ∫ − ∞ ∞ f ( x ) d x = 1 , P ( a ≤ X ≤ b ) = ∫ a b f ( x ) d x f(x)\ge0,\quad \int_{-\infty}^{\infty}f(x)\,dx=1,\qquad P(a\le X\le b)=\int_a^b f(x)\,dx f ( x ) ≥ 0 , ∫ − ∞ ∞ f ( x ) d x = 1 , P ( a ≤ X ≤ b ) = ∫ a b f ( x ) d x 確率は密度のグラフとx軸が囲む面積(積分) 。1点の確率は ∫ a a f d x = 0 \int_a^a f\,dx=0 ∫ a a f d x = 0 。f ( x ) f(x) f ( x ) [ 0 , 0.5 ] [0,0.5] [ 0 , 0.5 ] f = 2 f=2 f = 2
この2つの誤解(f ( x ) f(x) f ( x ) P ( X = a ) = f ( a ) P(X=a)=f(a) P ( X = a ) = f ( a ) 密度(高さ)と確率(面積)を混同している 」こと。確率は必ず「幅をもった区間の面積」で考える。
累積分布関数 CDF(離散・連続共通)
F ( x ) = P ( X ≤ x ) , 連続なら F ( x ) = ∫ − ∞ x f ( t ) d t , f ( x ) = F ′ ( x ) , P ( a ≤ X ≤ b ) = F ( b ) − F ( a ) F(x)=P(X\le x),\qquad \text{連続なら } F(x)=\int_{-\infty}^x f(t)\,dt,\ f(x)=F'(x),\ P(a\le X\le b)=F(b)-F(a) F ( x ) = P ( X ≤ x ) , 連続なら F ( x ) = ∫ − ∞ x f ( t ) d t , f ( x ) = F ′ ( x ) , P ( a ≤ X ≤ b ) = F ( b ) − F ( a ) 0 0 0 1 1 1 F ( b ) − F ( a ) F(b)-F(a) F ( b ) − F ( a )
離散↔連続の対応(∑ ↔ ∫ \sum \leftrightarrow \int ∑ ↔ ∫
概念 離散 連続 確率 PMF p ( x ) p(x) p ( x ) PDF f ( x ) f(x) f ( x ) 1点の確率 p ( x ) p(x) p ( x ) 0 全体 ∑ p ( x ) = 1 \sum p(x)=1 ∑ p ( x ) = 1 ∫ f d x = 1 \int f\,dx=1 ∫ f d x = 1 区間 ∑ a ≤ x ≤ b p ( x ) \sum_{a\le x\le b}p(x) ∑ a ≤ x ≤ b p ( x ) ∫ a b f d x \int_a^b f\,dx ∫ a b f d x 期待値 ∑ x p ( x ) \sum x\,p(x) ∑ x p ( x ) ∫ x f d x \int x f\,dx ∫ x f d x 分散 ∑ ( x − μ ) 2 p ( x ) \sum (x-\mu)^2 p(x) ∑ ( x − μ ) 2 p ( x ) ∫ ( x − μ ) 2 f d x \int (x-\mu)^2 f\,dx ∫ ( x − μ ) 2 f d x
「離散の ∑ x ⋅ p ( x ) \sum_x\,\cdot\,p(x) ∑ x ⋅ p ( x ) ∫ ⋅ f ( x ) d x \int\,\cdot\,f(x)\,dx ∫ ⋅ f ( x ) d x
期待値(平均の理論版)
E [ X ] = ∑ x x p ( x ) ( 離散 ) , E [ X ] = ∫ − ∞ ∞ x f ( x ) d x ( 連続 ) , μ : = E [ X ] E[X]=\sum_x x\,p(x)\quad(\text{離散}),\qquad E[X]=\int_{-\infty}^{\infty}x\,f(x)\,dx\quad(\text{連続}),\qquad \mu:=E[X] E [ X ] = x ∑ x p ( x ) ( 離散 ) , E [ X ] = ∫ − ∞ ∞ x f ( x ) d x ( 連続 ) , μ := E [ X ] 「値 × 確率」を全部足す=分布の重心、長期平均 。記述統計の平均 x ˉ = 1 n ∑ x i \bar{x}=\frac1n\sum x_i x ˉ = n 1 ∑ x i 1 n \frac1n n 1 p ( x ) p(x) p ( x ) 大数の法則(弱法則・強法則) )で連結(n → ∞ n\to\infty n → ∞ x ˉ → E [ X ] \bar{x}\to E[X] x ˉ → E [ X ]
サイコロ:E [ X ] = 1 + 2 + ⋯ + 6 6 = 21 6 = 3.5 E[X]=\frac{1+2+\cdots+6}{6}=\frac{21}{6}=3.5 E [ X ] = 6 1 + 2 + ⋯ + 6 = 6 21 = 3.5 期待値3.5は「サイコロの目に3.5は無い」のに出てくる のがポイント。期待値は「1回1回で必ず出る値」ではなく「何回も振って平均したら近づく値(長期平均)」だから。
分散(散らばりの理論版)
V [ X ] = E [ ( X − μ ) 2 ] , σ = V [ X ] V[X]=E[(X-\mu)^2],\qquad \sigma=\sqrt{V[X]} V [ X ] = E [( X − μ ) 2 ] , σ = V [ X ] 期待値からのズレの2乗を確率で重みづけ平均。2乗する理由・標準偏差に戻す理由は記述統計と同じ(散らばり(ばらつき)の指標 ── 範囲・四分位範囲・分散・標準偏差・変動係数(なぜ偏差を2乗するか/なぜn−1で割るか) )。標準偏差は元の単位、分散は2乗の単位。
計算公式(頻出・主役) :
V [ X ] = E [ X 2 ] − ( E [ X ] ) 2 ( 「2乗の期待値 − 期待値の2乗」 ) \boxed{\,V[X]=E[X^2]-(E[X])^2\,}\quad(\text{「2乗の期待値 − 期待値の2乗」}) V [ X ] = E [ X 2 ] − ( E [ X ] ) 2 ( 「 2 乗の期待値 − 期待値の 2 乗」 ) 定義式 E [ ( X − μ ) 2 ] E[(X-\mu)^2] E [( X − μ ) 2 ]
代表的な確率変数
ベルヌーイ分布(離散・0/1の最小単位)
「成功なら X = 1 X=1 X = 1 p p p X = 0 X=0 X = 0 1 − p 1-p 1 − p
E [ X ] = 1 ⋅ p + 0 ⋅ ( 1 − p ) = p E[X]=1\cdot p+0\cdot(1-p)=p E [ X ] = 1 ⋅ p + 0 ⋅ ( 1 − p ) = p X X X X 2 = X X^2=X X 2 = X 0 2 = 0 , 1 2 = 1 0^2=0,\ 1^2=1 0 2 = 0 , 1 2 = 1 E [ X 2 ] = E [ X ] = p E[X^2]=E[X]=p E [ X 2 ] = E [ X ] = p
V [ X ] = E [ X 2 ] − ( E [ X ] ) 2 = p − p 2 = p ( 1 − p ) V[X]=E[X^2]-(E[X])^2 = p - p^2 = p(1-p) V [ X ] = E [ X 2 ] − ( E [ X ] ) 2 = p − p 2 = p ( 1 − p ) 要するに「成功確率 p p p p ( 1 − p ) p(1-p) p ( 1 − p ) p = 0.5 p=0.5 p = 0.5 p = 0 p=0 p = 0 p = 1 p=1 p = 1
離散一様分布(サイコロ)
1 1 1 n n n E [ X ] = n + 1 2 E[X]=\dfrac{n+1}{2} E [ X ] = 2 n + 1 V [ X ] = n 2 − 1 12 V[X]=\dfrac{n^2-1}{12} V [ X ] = 12 n 2 − 1 n = 6 n=6 n = 6 E = 3.5 E=3.5 E = 3.5 V = 35 12 V=\dfrac{35}{12} V = 12 35
連続一様分布(区間 [ a , b ] [a,b] [ a , b ]
密度は一定なので、面積1になるよう高さは f ( x ) = 1 b − a f(x)=\dfrac{1}{b-a} f ( x ) = b − a 1 a ≤ x ≤ b a\le x\le b a ≤ x ≤ b
E [ X ] = ∫ a b x ⋅ 1 b − a d x = b 2 − a 2 2 ( b − a ) = a + b 2 E[X]=\int_a^b x\cdot\frac{1}{b-a}\,dx = \frac{b^2-a^2}{2(b-a)}=\frac{a+b}{2} E [ X ] = ∫ a b x ⋅ b − a 1 d x = 2 ( b − a ) b 2 − a 2 = 2 a + b E [ X 2 ] = ∫ a b x 2 ⋅ 1 b − a d x = b 3 − a 3 3 ( b − a ) = a 2 + a b + b 2 3 ( b 3 − a 3 = ( b − a ) ( a 2 + a b + b 2 ) ) E[X^2]=\int_a^b x^2\cdot\frac{1}{b-a}\,dx=\frac{b^3-a^3}{3(b-a)}=\frac{a^2+ab+b^2}{3}\quad(b^3-a^3=(b-a)(a^2+ab+b^2)) E [ X 2 ] = ∫ a b x 2 ⋅ b − a 1 d x = 3 ( b − a ) b 3 − a 3 = 3 a 2 + ab + b 2 ( b 3 − a 3 = ( b − a ) ( a 2 + ab + b 2 )) V [ X ] = a 2 + a b + b 2 3 − ( a + b 2 ) 2 = ( b − a ) 2 12 V[X]=\frac{a^2+ab+b^2}{3}-\left(\frac{a+b}{2}\right)^2=\frac{(b-a)^2}{12} V [ X ] = 3 a 2 + ab + b 2 − ( 2 a + b ) 2 = 12 ( b − a ) 2 要するに「期待値=区間の中点 a + b 2 \frac{a+b}{2} 2 a + b ( b − a ) 2 12 \frac{(b-a)^2}{12} 12 ( b − a ) 2 n 2 − 1 12 \frac{n^2-1}{12} 12 n 2 − 1
試験での問われ方
3級 :離散型確率変数の平均・分散(2021年度〜の新出題範囲。高校数学B「統計的な推測」編入分。稀に出題 )。二項分布・正規分布の期待値・分散もここに接続。2級(主) :離散・連続両方。PMF/PDF・CDF、E [ X ] E[X] E [ X ] V [ X ] V[X] V [ X ] σ \sigma σ 分散公式 E [ X 2 ] − ( E [ X ] ) 2 E[X^2]-(E[X])^2 E [ X 2 ] − ( E [ X ] ) 2 、各種分布(ベルヌーイ・二項・ポアソン・幾何・一様・指数・正規等)の平均分散。連続型のPDFは「確率ではない(1超え可・1点0)」が頻出の理解問題。※出題範囲は改訂されうる。受験前に公式最新版で要最新確認 (2級公式範囲表は2018-12-14版が最新公開、3級新範囲は2021年度〜)。
数式の直観的意味
なぜ期待値は「値 × 確率」の和か(重心・長期平均)
期待値は物理の重心そのもの。数直線上の位置 x x x p ( x ) p(x) p ( x ) ∑ x p ( x ) \sum x\,p(x) ∑ x p ( x ) p = 1 n p=\frac1n p = n 1 X 1 , … , X n X_1,\dots,X_n X 1 , … , X n X ˉ n = 1 n ∑ X i \bar{X}_n=\frac1n\sum X_i X ˉ n = n 1 ∑ X i n → ∞ n\to\infty n → ∞ E [ X ] E[X] E [ X ]
なぜ V [ X ] = E [ X 2 ] − ( E [ X ] ) 2 V[X]=E[X^2]-(E[X])^2 V [ X ] = E [ X 2 ] − ( E [ X ] ) 2
μ = E [ X ] \mu=E[X] μ = E [ X ] 定数 。( X − μ ) 2 = X 2 − 2 μ X + μ 2 (X-\mu)^2=X^2-2\mu X+\mu^2 ( X − μ ) 2 = X 2 − 2 μ X + μ 2 E E E 期待値・分散の性質(線形性・和の分散・共分散) ):
V [ X ] = E [ X 2 ] − E [ 2 μ X ] + E [ μ 2 ] = E [ X 2 ] − 2 μ E [ X ] + μ 2 V[X]=E[X^2]-E[2\mu X]+E[\mu^2]=E[X^2]-2\mu E[X]+\mu^2 V [ X ] = E [ X 2 ] − E [ 2 μ X ] + E [ μ 2 ] = E [ X 2 ] − 2 μ E [ X ] + μ 2 E [ X ] = μ E[X]=\mu E [ X ] = μ − 2 μ ⋅ μ + μ 2 = − 2 μ 2 + μ 2 = − μ 2 -2\mu\cdot\mu+\mu^2=-2\mu^2+\mu^2=-\mu^2 − 2 μ ⋅ μ + μ 2 = − 2 μ 2 + μ 2 = − μ 2
V [ X ] = E [ X 2 ] − μ 2 = E [ X 2 ] − ( E [ X ] ) 2 . V[X]=E[X^2]-\mu^2=E[X^2]-(E[X])^2. V [ X ] = E [ X 2 ] − μ 2 = E [ X 2 ] − ( E [ X ] ) 2 . 山は中央項 − 2 μ 2 -2\mu^2 − 2 μ 2 + μ 2 +\mu^2 + μ 2 − μ 2 -\mu^2 − μ 2 V [ X ] ≥ 0 V[X]\ge0 V [ X ] ≥ 0 E [ X 2 ] ≥ ( E [ X ] ) 2 E[X^2]\ge(E[X])^2 E [ X 2 ] ≥ ( E [ X ] ) 2 X X X
サイコロの分散の2通り計算(一致確認)
公式:E [ X 2 ] = 1 + 4 + 9 + 16 + 25 + 36 6 = 91 6 E[X^2]=\frac{1+4+9+16+25+36}{6}=\frac{91}{6} E [ X 2 ] = 6 1 + 4 + 9 + 16 + 25 + 36 = 6 91 ( E [ X ] ) 2 = ( 7 2 ) 2 = 49 4 (E[X])^2=(\frac72)^2=\frac{49}{4} ( E [ X ] ) 2 = ( 2 7 ) 2 = 4 49 V = 91 6 − 49 4 = 182 − 147 12 = 35 12 ≈ 2.917 V=\frac{91}{6}-\frac{49}{4}=\frac{182-147}{12}=\frac{35}{12}\approx2.917 V = 6 91 − 4 49 = 12 182 − 147 = 12 35 ≈ 2.917
定義:∑ ( x − 3.5 ) 2 ⋅ 1 6 = ( 2.5 ) 2 + ( 1.5 ) 2 + ( 0.5 ) 2 + ( 0.5 ) 2 + ( 1.5 ) 2 + ( 2.5 ) 2 6 = 6.25 + 2.25 + 0.25 + 0.25 + 2.25 + 6.25 6 = 17.5 6 = 35 12 \sum(x-3.5)^2\cdot\frac16=\frac{(2.5)^2+(1.5)^2+(0.5)^2+(0.5)^2+(1.5)^2+(2.5)^2}{6}=\frac{6.25+2.25+0.25+0.25+2.25+6.25}{6}=\frac{17.5}{6}=\frac{35}{12} ∑ ( x − 3.5 ) 2 ⋅ 6 1 = 6 ( 2.5 ) 2 + ( 1.5 ) 2 + ( 0.5 ) 2 + ( 0.5 ) 2 + ( 1.5 ) 2 + ( 2.5 ) 2 = 6 6.25 + 2.25 + 0.25 + 0.25 + 2.25 + 6.25 = 6 17.5 = 12 35 σ = 35 / 12 ≈ 1.708 \sigma=\sqrt{35/12}\approx1.708 σ = 35/12 ≈ 1.708
連続一様 [ a , b ] [a,b] [ a , b ]
E [ X ] = 1 b − a ∫ a b x d x = 1 b − a ⋅ b 2 − a 2 2 = a + b 2 E[X]=\frac{1}{b-a}\int_a^b x\,dx=\frac{1}{b-a}\cdot\frac{b^2-a^2}{2}=\frac{a+b}{2} E [ X ] = b − a 1 ∫ a b x d x = b − a 1 ⋅ 2 b 2 − a 2 = 2 a + b E [ X 2 ] = 1 b − a ∫ a b x 2 d x = 1 b − a ⋅ b 3 − a 3 3 = a 2 + a b + b 2 3 E[X^2]=\frac{1}{b-a}\int_a^b x^2\,dx=\frac{1}{b-a}\cdot\frac{b^3-a^3}{3}=\frac{a^2+ab+b^2}{3} E [ X 2 ] = b − a 1 ∫ a b x 2 d x = b − a 1 ⋅ 3 b 3 − a 3 = 3 a 2 + ab + b 2 b 3 − a 3 = ( b − a ) ( a 2 + a b + b 2 ) b^3-a^3=(b-a)(a^2+ab+b^2) b 3 − a 3 = ( b − a ) ( a 2 + ab + b 2 ) V [ X ] = a 2 + a b + b 2 3 − ( a + b ) 2 4 = 4 ( a 2 + a b + b 2 ) − 3 ( a 2 + 2 a b + b 2 ) 12 = ( b − a ) 2 12 V[X]=\frac{a^2+ab+b^2}{3}-\frac{(a+b)^2}{4}=\frac{4(a^2+ab+b^2)-3(a^2+2ab+b^2)}{12}=\frac{(b-a)^2}{12} V [ X ] = 3 a 2 + ab + b 2 − 4 ( a + b ) 2 = 12 4 ( a 2 + ab + b 2 ) − 3 ( a 2 + 2 ab + b 2 ) = 12 ( b − a ) 2
⚠️ 引っかけポイント・頻出論点・級ごとの差
PDFは確率ではない(最頻出の理解問題) :f ( x ) f(x) f ( x ) 1を超えてよい (制約は面積=積分が1)。1点の確率は0 (P ( X = a ) = 0 P(X=a)=0 P ( X = a ) = 0 f ( a ) f(a) f ( a ) X = a X=a X = a E [ X 2 ] ≠ ( E [ X ] ) 2 E[X^2]\ne(E[X])^2 E [ X 2 ] = ( E [ X ] ) 2 E [ X 2 ] − ( E [ X ] ) 2 E[X^2]-(E[X])^2 E [ X 2 ] − ( E [ X ] ) 2 期待値は「1回の値」ではなく「長期平均」 :3.5は出ない目。1回試行の予測値と取り違えない。離散↔連続の置き換え :∑ → ∫ \sum\to\int ∑ → ∫ p ( x ) → f ( x ) d x p(x)\to f(x)\,dx p ( x ) → f ( x ) d x ∑ \sum ∑ CDFの単調性・端の値 :F ( − ∞ ) = 0 , F ( ∞ ) = 1 F(-\infty)=0,\ F(\infty)=1 F ( − ∞ ) = 0 , F ( ∞ ) = 1 P ( a ≤ X ≤ b ) = F ( b ) − F ( a ) P(a\le X\le b)=F(b)-F(a) P ( a ≤ X ≤ b ) = F ( b ) − F ( a ) 記述統計との別物扱いに注意 :期待値・分散は母集団・理論版(代表値 ── 平均・中央値・最頻値の定義と使い分け(外れ値への強さ・歪んだ分布での大小関係) ・散らばり(ばらつき)の指標 ── 範囲・四分位範囲・分散・標準偏差・変動係数(なぜ偏差を2乗するか/なぜn−1で割るか) の標本版に対応)。標本平均・標本分散と混同せず、大数の法則で結ばれる関係を理解。スコープ外(次トピック) :E [ a X + b ] = a E [ X ] + b E[aX+b]=aE[X]+b E [ a X + b ] = a E [ X ] + b V [ a X + b ] = a 2 V [ X ] V[aX+b]=a^2V[X] V [ a X + b ] = a 2 V [ X ] E [ X + Y ] = E [ X ] + E [ Y ] E[X+Y]=E[X]+E[Y] E [ X + Y ] = E [ X ] + E [ Y ] V [ X + Y ] V[X+Y] V [ X + Y ] 期待値・分散の性質(線形性・和の分散・共分散) 級差 :3級=離散の平均・分散(稀) → 2級=離散+連続・PMF/PDF/CDF・分散公式・各種分布の平均分散・「PDFは確率でない」の理解。
よくある疑問
Q. 「確率変数」って結局、変数なんですか関数なんですか?
A. 中身は**関数(写像)**です。標本空間の各結果(偶然の出来事)に実数を1つ割り当てる関数が確率変数 X X X X X X
Q. なぜ連続型だと1点の確率が0になるんですか? おかしくないですか?
A. 連続型は値が無限に細かく存在するためです。P ( X = a ) = ∫ a a f ( x ) d x = 0 P(X=a)=\int_a^a f(x)\,dx=0 P ( X = a ) = ∫ a a f ( x ) d x = 0 区間(幅のある範囲)の確率 を考えます。確率は点ではなく面積、と覚えてください。
Q. 確率密度 f ( x ) f(x) f ( x )
A. 間違いではありません。f ( x ) f(x) f ( x ) [ 0 , 0.5 ] [0,0.5] [ 0 , 0.5 ] f ( x ) = 2 f(x)=2 f ( x ) = 2 2 × 0.5 = 1 2\times0.5=1 2 × 0.5 = 1 1を超えてはいけないのは”面積”のほう で、高さ(密度)は1を超えても全く問題ありません。これは2級で本当によく狙われる誤解です。
Q. E [ X 2 ] E[X^2] E [ X 2 ] ( E [ X ] ) 2 (E[X])^2 ( E [ X ] ) 2
A. 一般に「2乗してから平均」と「平均してから2乗」は別物だからです。サイコロなら E [ X 2 ] = 91 6 ≈ 15.17 E[X^2]=\frac{91}{6}\approx15.17 E [ X 2 ] = 6 91 ≈ 15.17 ( E [ X ] ) 2 = 3.5 2 = 12.25 (E[X])^2=3.5^2=12.25 ( E [ X ] ) 2 = 3. 5 2 = 12.25 15.17 − 12.25 = 2.92 15.17-12.25=2.92 15.17 − 12.25 = 2.92 V [ X ] = E [ X 2 ] − ( E [ X ] ) 2 V[X]=E[X^2]-(E[X])^2 V [ X ] = E [ X 2 ] − ( E [ X ] ) 2 両者が一致するのは「X X X で、ばらつきがある限り必ず E [ X 2 ] > ( E [ X ] ) 2 E[X^2]>(E[X])^2 E [ X 2 ] > ( E [ X ] ) 2
Q. 期待値3.5は実際には出ない目なのに、何の意味があるんですか?
A. 期待値は「1回で出る値」ではなく「何度も繰り返した平均の行き着く先(長期平均) 」です。サイコロを1万回振って平均を取れば3.5にとても近づきます(シミュレーション①で確認)。賭けの損得計算や保険料の設定など、「長い目で見た平均」を知りたい場面で威力を発揮します。1回ごとの結果ではなく、長期の振る舞いを表す数だと理解してください。
Q. 記述統計の平均・分散と、期待値・分散はどう違うんですか?
A. **同じものの「データ版」と「理論版」**です。記述統計の平均 x ˉ \bar{x} x ˉ s 2 s^2 s 2 E [ X ] E[X] E [ X ] V [ X ] V[X] V [ X ] 期待値・分散は、無限のデータを持っていたとしたら得られる平均・分散 」と考えると接続が見えます。
まとめ
確率変数 X X X = 偶然の結果に実数を割り当てる関数。離散型はPMF p ( x ) p(x) p ( x ) f ( x ) f(x) f ( x ) で確率を与える。連続型は1点の確率0 、確率は**面積(積分)**で測る。f ( x ) f(x) f ( x ) 期待値 E [ X ] = ∑ x p ( x ) = ∫ x f ( x ) d x E[X]=\sum x\,p(x)=\int x f(x)\,dx E [ X ] = ∑ x p ( x ) = ∫ x f ( x ) d x = 確率で重みづけた平均(分布の重心、長期平均)。記述統計の平均(代表値 ── 平均・中央値・最頻値の定義と使い分け(外れ値への強さ・歪んだ分布での大小関係) )の理論版。分散 V [ X ] = E [ ( X − μ ) 2 ] = E [ X 2 ] − ( E [ X ] ) 2 V[X]=E[(X-\mu)^2]=E[X^2]-(E[X])^2 V [ X ] = E [( X − μ ) 2 ] = E [ X 2 ] − ( E [ X ] ) 2 = 散らばりの理論版。記述統計の分散(散らばり(ばらつき)の指標 ── 範囲・四分位範囲・分散・標準偏差・変動係数(なぜ偏差を2乗するか/なぜn−1で割るか) )の理論版。計算公式「2乗の期待値 − 期待値の2乗」は定義の展開で導ける。基本分布:ベルヌーイ E = p , V = p ( 1 − p ) E=p,\ V=p(1-p) E = p , V = p ( 1 − p ) /サイコロ E = 3.5 , V = 35 12 E=3.5,\ V=\frac{35}{12} E = 3.5 , V = 12 35 E = a + b 2 , V = ( b − a ) 2 12 E=\frac{a+b}{2},\ V=\frac{(b-a)^2}{12} E = 2 a + b , V = 12 ( b − a ) 2
次回 :E [ a X + b ] E[aX+b] E [ a X + b ] V [ a X + b ] V[aX+b] V [ a X + b ] 期待値・分散の性質(線形性・和の分散・共分散) )。今回はその性質の「最小限」だけを分散公式の導出に使った。
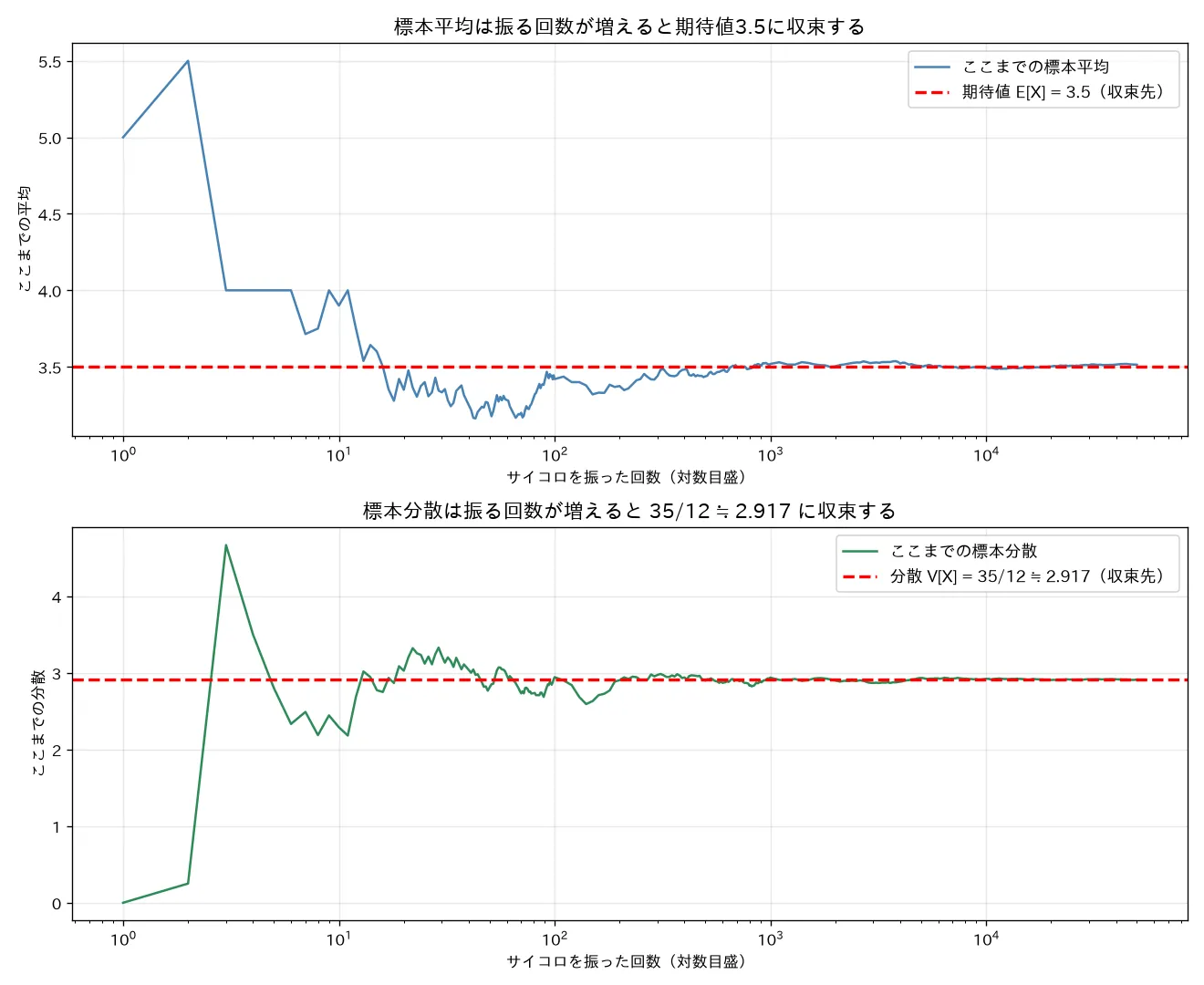
対応するシミュレーション
simulations/kakuritsu_hensuu_kitaichi_taikiheikin.py
何を示すか :サイコロを少数回〜数万回振り、「ここまでの標本平均」「ここまでの標本分散」を試行数に対して折れ線で描く。回数が増えると標本平均→期待値3.5、標本分散→35 / 12 ≈ 2.917 35/12\approx2.917 35/12 ≈ 2.917 実行結果(seed=0、5万回) :最終 標本平均 = 3.5141 (理論 3.5)/最終 標本分散 = 2.9117 (理論 2.9167)。序盤は大きく振れ、回数を重ねると理論値へ収束。期待値=長期平均 を数値で実証(大数の法則の入口)。
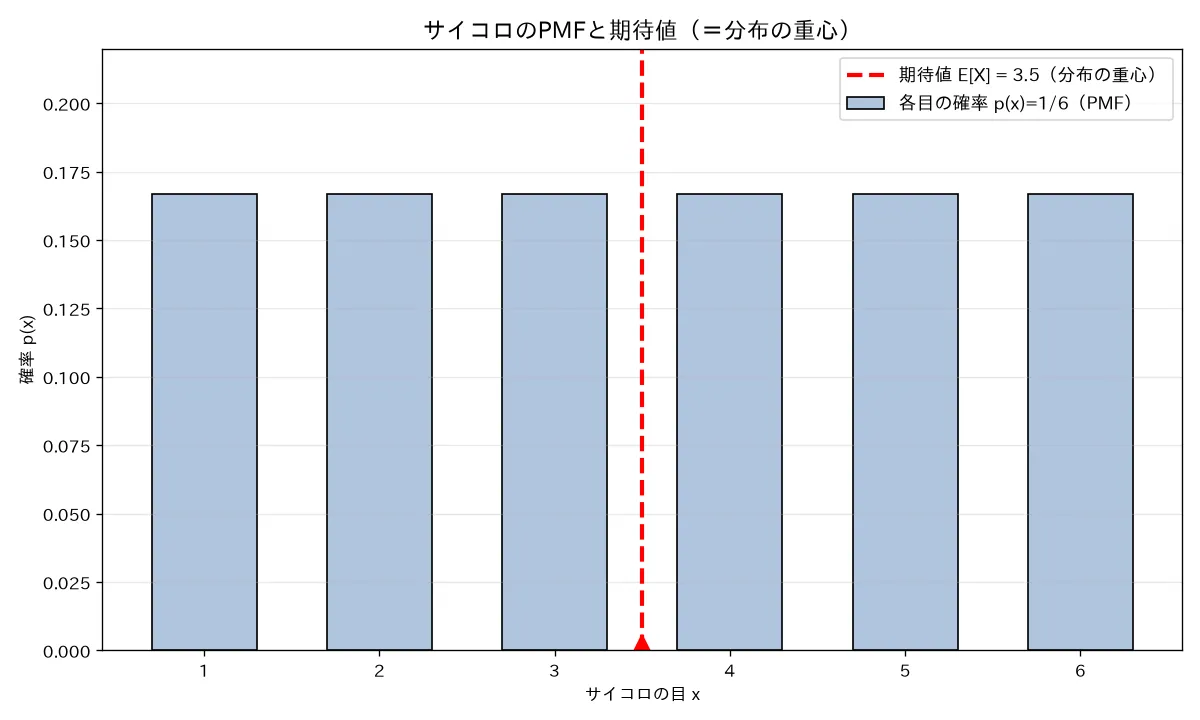
simulations/kakuritsu_hensuu_kitaichi_bunsan_koushiki.py
何を示すか :サイコロのPMF棒グラフに期待値3.5の重心線を引き、分散を定義式 E [ ( X − μ ) 2 ] E[(X-\mu)^2] E [( X − μ ) 2 ] E [ X 2 ] − ( E [ X ] ) 2 E[X^2]-(E[X])^2 E [ X 2 ] − ( E [ X ] ) 2 実行結果 :定義式 = 2.916667 、公式 = 2.916667 (完全一致、ともに 35 / 12 35/12 35/12 E [ X 2 ] = 15.1667 E[X^2]=15.1667 E [ X 2 ] = 15.1667 ( E [ X ] ) 2 = 12.25 (E[X])^2=12.25 ( E [ X ] ) 2 = 12.25
関連ノート