📊 対象級:2級 | 重要度:A(頻出)
ベイズの定理 ── 条件付き確率の向きの逆転/事前→事後の更新/陽性的中率と base rate fallacy
要点(BLUF)
- ベイズの定理 =「観測 から原因 の確率を逆算する」。**条件付き確率の定義+乗法定理+全確率の定理(分母)**の3つを組み合わせただけで、新しい公理は一切要らない。分母は前トピック 条件付き確率・独立性・全確率の定理 の全確率の定理 そのもの。
- 4つの用語:=事前確率(観測前の信念)、=尤度(その原因なら が出る確率)、=周辺尤度/正規化定数(分母)、=事後確率(観測後に更新した信念)。要するに「事後 ∝ 事前 × 尤度」、分母は合計を1に戻すための割り算。
- 医療検査(2級頻出):感度 と陽性的中率 は向きが逆で別物。有病率(事前確率)が低いと、感度が高くても陽性的中率は低い(base rate fallacy/偽陽性のパラドックス)。条件付き確率の「向きの取り違え」(条件付き確率・独立性・全確率の定理 の引っかけ)が、ここで実害になる。
本文
身近な例:迷惑メールフィルタ
ベイズの定理は迷惑メールフィルタの中身そのもの。「“無料""当選”という単語が入っているメールは迷惑メールである確率が高い」——これは「迷惑メール(原因)なら”無料”という単語が出やすい(結果)」というわかっている向きの知識を、「“無料”が入っている(結果)から、これは迷惑メールか?(原因)」という知りたい向きにひっくり返している。このひっくり返しがベイズの定理。
スマホの予測変換、病気の検査、機械学習の分類器——「観測したデータから、その裏にある原因・カテゴリを推測する」場面のほぼすべてにベイズの定理が潜んでいる。
ベイズの定理とは(条件付き確率の向きを逆転する)
ベイズの定理は「結果(観測) がわかったときに、その原因 である確率」を求める道具。前トピックの条件付き確率・乗法定理・全確率の定理を組み合わせるだけで出てくる、新しい仮定のいらない定理(公理から導かれる帰結)。
原因の候補 が標本空間 の分割(排反かつ網羅、条件付き確率・独立性・全確率の定理)であるとき、観測 に対して
要するに「知りたい向き (原因←結果)」を、「わかっている向き (結果←原因)」と「事前の確率 」だけで計算する公式。多くの場面で (原因がわかれば結果の確率は出せる)は手元にあるが、本当に知りたいのは逆向きの (結果から原因を推定したい)。その橋渡しがベイズの定理。
2分割の場合(原因が「 か 」の2通り。医療検査がこの形)はとくに頻出:
4つの用語の対応(式の各部分に名前をつける)
ベイズの定理の各部分には決まった呼び名がある。 を「仮説(原因)」、 を「観測データ」と読むと、式全体が「データを見て信念を更新する」という意味になる。
| 用語 | 式の部分 | 意味 |
|---|---|---|
| 事前確率(prior) | データ を見る前に持っている、原因 の確率(信念) | |
| 尤度(likelihood) | 原因が だとしたら、観測 がどれだけ出やすいか | |
| 周辺尤度/正規化定数(marginal likelihood, evidence) | 観測 が出る全体の確率(分母)。全確率の定理そのもの | |
| 事後確率(posterior) | データ を見た後に更新された、原因 の確率 |
この4語で書き直すと、ベイズの定理は
要するに「事後 ∝ 事前 × 尤度」。分母 は に依存しない(どの でも同じ値)ので、各 の相対的な大小には効かない。分母の役割は「事後確率を全部足したら1になるように調整する」正規化だけ。この見方が Phase 7 のベイズ統計で連続パラメータ(確率分布)に一般化される土台になる(事前分布→事後分布の更新)。
具体例:医療検査(2級頻出・感度と的中率を区別する)
ある病気の有病率が1%()。検査の感度90%(病気の人を陽性と判定 )、特異度90%(病気でない人を陰性と判定 、よって偽陽性率 )。
問:陽性と出たとき、本当に病気である確率(陽性的中率) は?
ベイズの定理(2分割)に代入する:
感度は90%もあるのに、陽性的中率はわずか約8.3%。「陽性なら90%病気」と思い込むのが典型的な誤りで、これが base rate fallacy(基準率の無視)/偽陽性のパラドックス。理由は分母の内訳を見ればわかる:本物の陽性は しかないのに、母数の大きい「病気でない99%」から出る偽陽性が もあり、偽陽性が本物を11倍も上回る。詳しい直観は後述「数式の直観的意味」。
人数で考えると一発(10000人で考えるのが2級の定石):
| 病気あり(100人) | 病気なし(9900人) | 計 | |
|---|---|---|---|
| 陽性 | 90(真陽性 TP) | 990(偽陽性 FP) | 1080 |
| 陰性 | 10(偽陰性 FN) | 8910(真陰性 TN) | 8920 |
| 計 | 100 | 9900 | 10000 |
陽性的中率 。表を作れば暗算で解ける。
感度・特異度・的中率の対応(混同行列)
医療検査の4つの数を混同行列で整理する。「何を分母にするか(縦に見るか横に見るか)」で指標の意味と向きが変わる。
| 病気あり | 病気なし | |
|---|---|---|
| 検査 陽性 | 真陽性 TP | 偽陽性 FP |
| 検査 陰性 | 偽陰性 FN | 真陰性 TN |
| 指標 | 定義(式) | 向き | 有病率に依存? |
|---|---|---|---|
| 感度(真陽性率) | 病気→検査 | しない(病気の列だけで決まる) | |
| 特異度(真陰性率) | 病気でない→検査 | しない | |
| 偽陽性率 | 病気でない→検査 | しない | |
| 陽性的中率 PPV | 検査→病気 | する(事前確率=有病率に引きずられる) | |
| 陰性的中率 NPV | 検査→病気でない | する |
要点は 感度・特異度は「病気→検査」の向き(検査の性能、有病率に依存しない)/的中率は「検査→病気」の向き(有病率に依存する)。ベイズの定理は、検査の性能(感度・特異度)と有病率から、知りたい的中率を計算する変換になっている。
ベイズ更新のフロー
事前確率に尤度を掛け、正規化して事後確率を得る一連の流れ。
flowchart LR A["事前確率<br/>P(A_i)"] --> C["事前 × 尤度<br/>P(A_i)P(B|A_i)"] B["尤度<br/>P(B|A_i)"] --> C C --> D["正規化<br/>÷ ΣP(A_j)P(B|A_j)"] D --> E["事後確率<br/>P(A_i|B)"] E -.->|"次の観測では<br/>これが新しい事前"| A
点線が示すように、今回の事後確率は次の観測での事前確率になる。これが逐次更新(後述)で、Phase 7 のベイズ統計の核心。
試験での問われ方
- 2級:医療検査の陽性的中率の計算(感度・特異度・有病率から を求める)が最頻出。2分割のベイズの定理、人数表(混同行列)での計算、base rate fallacy の理解。範囲表の文言は「確率(統計的推測の基礎となる確率、ベイズの定理)」。
- 準1級: 分割(3つ以上の原因)のベイズの定理、事後確率の解釈、オッズ形式・尤度比、逐次更新(独立な複数観測での更新)。過去問(2018年6月 問1)で「検査と事後確率の解釈」が出題実績あり。Phase 7 のベイズ統計の入口。
- 1級:連続パラメータの事後分布、共役事前分布など本格的なベイズ推測(Phase 7)。
- ※出題範囲は改訂されうるため受験前に公式最新の出題範囲表で要最新確認(2級は2024年9月版、準1級の範囲表は改訂されうる点に注意。本ノートは直近で確認した版にもとづく)。
数式の直観的意味
ベイズの定理の導出(定義+乗法定理+全確率の定理の3点セット)
新しい公理は一切使わない。前トピックまでの道具だけで導ける。
ステップ1:条件付き確率の定義を、知りたい向きで書く。 知りたいのは (観測 のもとでの原因 )。条件付き確率・独立性・全確率の定理 の定義そのまま:
ステップ2:分子に乗法定理を使う。 同時確率 は、確率の基本(定義・加法定理・乗法定理) の乗法定理で「わかっている向き」 を使って書ける。乗法定理は順番を入れ替えても成り立つ()から:
要するに「 がまず起きて()、その世界で が起きる()」。これを分子に代入:
ステップ3:分母 を全確率の定理で展開する。 が分割なので、条件付き確率・独立性・全確率の定理 の全確率の定理がそのまま使える:
これを代入して完成:
3つの道具の役割が明確:
- 条件付き確率の定義=知りたい向き を分数で書く出発点。
- 乗法定理=分子 を、手元にある「逆向き」 と事前 に変換する。これが「向きの逆転」の正体。
- 全確率の定理=分母 を計算する。前トピックの がそっくりそのままベイズの分母。だから前トピックで「ベイズの分母の準備」と繰り返した。
なぜ「向きが逆転」できるのか。分子で乗法定理を対称な形 の左側を使い、分母で を別途求めることで、 を で表せた。同時確率 がどちらの向きでも分解できる対称性が、向きの逆転を可能にしている。
なぜ事前確率(有病率)が低いと的中率が下がるのか(base rate fallacy の数式的理解)
ベイズの定理の分母を見る:
分母は「本物の陽性 + 偽陽性」。有病率 とおくと:
- 本物の陽性 → に比例して小さい(珍しい病気なら が小さい)。
- 偽陽性 → なので有病率が低いほど相対的に大きい。
つまり有病率が低いと、分母が偽陽性で埋め尽くされ、本物の陽性(分子)が埋もれる。「感度が高い」は病気の人の中での話で、母数の大きい健康な人から出る偽陽性の絶対数には勝てない。これが base rate fallacy。
数式で限界を見る。感度・特異度を固定して とすると:
有病率が0に近づくと、どんなに感度が高くても陽性的中率は0に近づく。逆に なら的中率 。的中率は事前確率 に強く引きずられる——これがベイズの定理の本質的なメッセージで、シミュ bayes_teiri_yuubyouritsu.py の曲線がまさにこれ。
なお感度・特異度は分子・分母の「率」の部分にしか現れず を含まない。だから感度・特異度は有病率に依存せず、的中率だけが依存する(混同行列の表と一致)。
オッズ形式のベイズ更新(準1級・Phase 7 への布石)
2分割( か )のとき、 と それぞれのベイズの定理は分母 が共通:
辺々を割ると、共通の分母 がきれいに消える:
要するに「事後オッズ = 事前オッズ × 尤度比」。 が**尤度比(ベイズ因子)**で、「観測 が、 のときと のときでどちらをどれだけ支持するか」を表す。面倒な分母(正規化定数)を計算せずに済むのがオッズ形式の利点。
検査の例:尤度比 。事前オッズ 。事後オッズ 。確率に戻すと で、ベイズの定理の結果と一致。
逐次更新:観測 が( のもとで・ のもとで)互いに独立なら、尤度比が掛け算でつながる:
要するに「観測を1つ得るたびに尤度比を掛けて信念を更新し、今回の事後を次回の事前にする」。前述のフロー図の点線(事後→次の事前)がこれ。Phase 7 のベイズ統計では、これが確率分布(事前分布→事後分布)の更新に一般化される。準1級では深入り不要だが、的中率の素早い計算と逐次更新の考え方を押さえておくとよい。
⚠️ 引っかけポイント・頻出論点・級ごとの差
- 感度と陽性的中率の取り違え(最頻出・最重要):感度 と的中率 は条件付き確率の向きが逆で、一般に全く違う値。「感度90%だから陽性なら90%病気」は誤り(正しくは約8.3%)。条件付き確率・独立性・全確率の定理 の「」の引っかけが、ここで実害(base rate fallacy)になる。縦棒の右が条件を常に確認。
- base rate fallacy(基準率の無視):事前確率(有病率)を無視して尤度(感度)だけで判断する誤り。珍しい事象(低い事前確率)ほど、陽性でも的中率は低い。「テロリスト判定」「迷惑メールフィルタ」「珍しい病気のスクリーニング」など、低有病率の場面で必ず効く。
- 分母を全確率の定理で正しく作れない:2分割の分母は「本物の陽性 + 偽陽性」。偽陽性の項 を忘れるのが典型ミス。分母 観測 が起こる全経路の和(全確率の定理、条件付き確率・独立性・全確率の定理)。
- 特異度と偽陽性率の混同:特異度 、偽陽性率 。ベイズの分母に入るのは偽陽性率(陽性の話だから)。特異度90%なら偽陽性率10%。
- 「事前確率は主観だから何でもいい」という誤解:事前確率は恣意的に置けるが、事後確率は事前に強く依存する(base rate fallacy がまさにそれ)。事前の選び方が結論を左右する点は、準1級・Phase 7 のベイズ統計で議論になる。
- 人数表(混同行列)を使えば暗算できるのに公式に固執して計算ミス:2級では「10000人中、病気100人・健康9900人」と具体人数に直すと、 のように四則演算だけで解ける。迷ったら人数表。
- 級差:2級=2分割の医療検査・的中率の計算・base rate fallacy の理解 → 準1級= 分割・オッズ形式と尤度比・逐次更新・事後確率の解釈 → 1級=連続パラメータの事後分布(本格ベイズ)。同じ「ベイズの定理」でも、2級は離散2分割の計算、準1級は更新の考え方、1級は分布の更新へと深さが上がる。
よくある疑問
Q. 感度と陽性的中率って、結局どう違うんですか?
A. 向き(条件にするもの)が逆です。感度 は「病気の人を見たとき、陽性になる割合(検査の性能)」。陽性的中率 は「陽性の人を見たとき、本当に病気の割合(あなたが知りたいこと)」。縦棒の右が「条件=すでにわかっていること」です。感度は有病率に関係なく決まりますが、的中率は有病率に大きく左右されます。
Q. 事前確率(有病率)が分からないときはどうするんですか?
A. 試験では必ず与えられます。実務では、過去のデータや専門知識から見積もります。ここで大事なのは「事前確率を無視して尤度(感度)だけで判断すると base rate fallacy にハマる」ということ。「珍しいことか、ありふれたことか」という事前の情報は、結論を左右する重要な材料です。
Q. 分母が複雑で間違えそうです。コツはありますか?
A. 人数に直すのが一番確実です。「10000人いて、病気は100人、健康は9900人……」と具体的な人数で表を埋めれば、あとは足し算と割り算だけ。公式の分母を直接書くより、ミスがぐっと減ります。とくに2級では人数表が最強の武器です。
Q. 「偽陽性率」と「特異度」がこんがらがります。
A. 特異度 は「病気でない人を正しく陰性にする率」。偽陽性率 は「病気でない人を誤って陽性にする率」。両者は足すと1なので、偽陽性率 = 1 − 特異度。ベイズの分母に入るのは(陽性の話なので)偽陽性率のほうです。特異度90%なら偽陽性率は10%です。
Q. なぜ事後確率は「事前 × 尤度」に比例するんですか?
A. ベイズの定理の分母(正規化定数)は、 が何であっても同じ値です。だから各原因 の事後確率の大小関係を決めるのは分子の「事前 × 尤度」だけ。分母は「全部足して1にする」ための調整役にすぎません。だから「事後 ∝ 事前 × 尤度」と書けるのです。この見方は Phase 7 のベイズ統計でとても重要になります。
まとめ
- ベイズの定理 は、結果から原因を逆算する公式。条件付き確率の定義・乗法定理・全確率の定理の組み合わせで導けます(分母は全確率の定理そのもの)。
- 用語は「事後 ∝ 事前 × 尤度」。分母は正規化(合計を1にする調整)。
- 医療検査では感度 と陽性的中率 は向きが逆で別物。有病率が低いと、感度が高くても的中率は低い(base rate fallacy)。
- 計算に迷ったら人数表。準1級ではオッズ形式(事後オッズ=事前オッズ×尤度比)と逐次更新も。
対応するシミュレーション
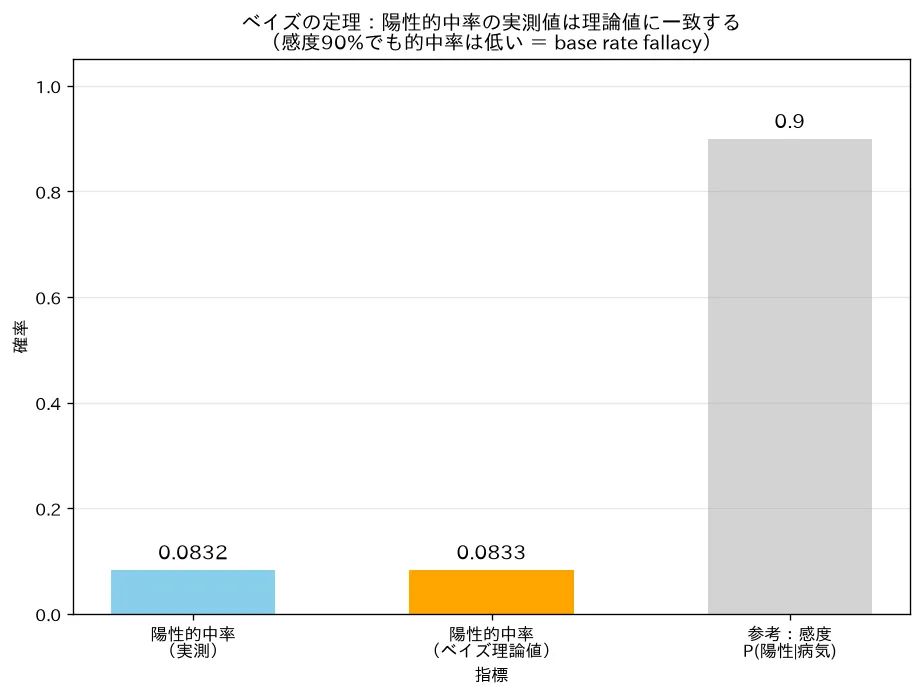
simulations/bayes_teiri_montecarlo.py- 何を示すか:100万人を有病率1%で「病気あり/なし」に振り分け、感度90%・特異度90%で検査させる。陽性者だけを集めて「そのうち本当に病気だった割合(陽性的中率)」を実測し、ベイズの定理の理論値と一致するか確認する。
- 結論:実測 vs ベイズ理論値 でほぼ一致。**感度90%なのに陽性的中率は約8.3%**しかないことを実データで実証(base rate fallacy)。分母 は前トピックの全確率の定理そのもの。
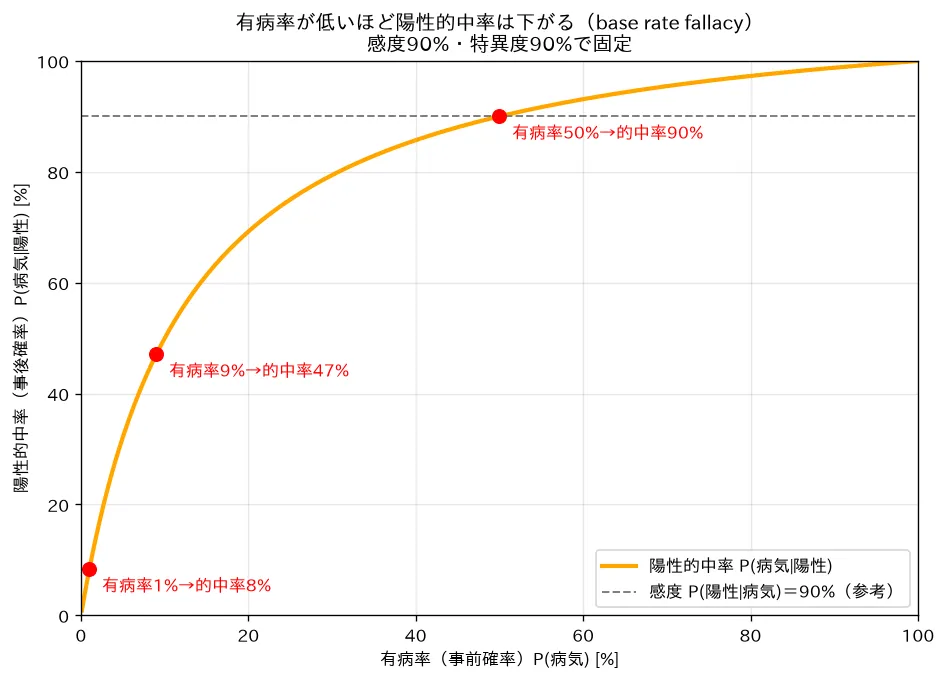
simulations/bayes_teiri_yuubyouritsu.py- 何を示すか:感度・特異度を90%に固定したまま、有病率を0%〜100%まで動かし、陽性的中率の変化を曲線で描く。
- 結論:有病率1%→的中率8.3%、9%→47.1%、50%→90.0% と、有病率が低いほど的中率が急落する。曲線が左下で寝ているのが base rate fallacy の正体。「珍しい病気は陽性でも確定できず追加検査が要る」ことの数学的根拠。
関連ノート
- 条件付き確率・独立性・全確率の定理(条件付き確率・独立性・全確率の定理 ── 全確率の定理 がベイズの分母。条件付き確率の定義 が導出の出発点。「向きの取り違え 」がここで base rate fallacy になる。前トピック)
- 確率の基本(定義・加法定理・乗法定理)(確率の定義・加法/乗法定理 ── 乗法定理 が分子の変換(向きの逆転)の核。前トピック)
- 場合の数・順列・組合せ(場合の数 ── 人数表(混同行列)で具体人数に直して的中率を四則演算で解く際の数え上げ。前トピック)
- クロス集計表・行/列比率・連関 ── 同じ表でも「何で割るか」で結論が変わる(クロス集計・行/列比率 ── 混同行列は2×2のクロス集計表。感度=行比率・的中率=列比率のように「どちらを分母にするか」で向きが変わる。Phase 1)
- 確率変数(離散・連続)と期待値・分散(確率変数と期待値・分散 ── 次トピック。離散の確率から確率変数・期待値へ。Phase 2⑤)
- ベイズ統計(事前分布・事後分布)── 本ノートの「事後 ∝ 事前 × 尤度」「逐次更新」を連続パラメータの確率分布に一般化する(Phase 7・準1級〜1級)。※ファイル名未確定のため wikilink は将来作成時に付与する。