📊 対象級:4級 ・ 3級 ・ 2級 | 重要度:A(頻出)
クロス集計表(分割表)・行/列比率・連関 ── 同じ表でも「何で割るか」で結論が変わる
要点(BLUF)
- クロス集計表(分割表 contingency table)=2つの質的変数の同時度数を行×列のマス目に並べた表。各セルの度数のほか、行和・列和・総度数(周辺度数)を読む。4級。
- 行比率・列比率・全体比率=同じ表でも「何で割るか(行和/列和/総和)」で意味が変わる。比較したい方向に割り算の分母を合わせる。行比率と列比率は一般に別物(条件付き確率の向きが逆 )。3級。
- 連関と独立=2変数に関係があるか。独立 ⟺ どの行でも行比率が等しい ⟺ 期待度数 。観測度数 と期待度数 のズレ (χ²統計量)が連関の強さの素。クラメールの に正規化する。2級。
対象級について:4級=クロス集計表(分割表)の読み方・セル度数・周辺度数。3級=行比率・列比率・全体比率の計算と使い分け、帯グラフでの比較。2級=独立と連関、期待度数、クラメールの連関係数、シンプソンのパラドックス。独立性のカイ二乗検定そのものは「推定・検定」の単元なので、この記事では深入りせず入口(期待度数・連関の強さ)までを扱います。出題範囲は改訂されることがあるので、受験前に必ず最新の範囲表を確認してください(要最新確認)。
クロス集計表(分割表)とは(4級)
2つの**質的変数(カテゴリ)**を取り上げ、片方を行、もう片方を列にして、両方の値が一致する個体の人数(度数)を各マス(セル)に書いた表です。 行 列なら 分割表と呼びます。散布図・相関係数の「種類版(カテゴリ版)」だと思ってください。
例として「性別 × 購入したか」( 表)を見てみましょう。
| 購入した | 購入しない | 行の合計 | |
|---|---|---|---|
| 男性 | 30 | 70 | 100 |
| 女性 | 60 | 40 | 100 |
| 列の合計 | 90 | 110 | 200(全体 N) |
- 内側の数(30, 70, 60, 40)がセルの度数=各組み合わせの人数。
- 表のフチに出てくる合計が周辺度数 (marginal frequency)。行ごとの合計が行和(100, 100)、列ごとの合計が列和(90, 110)、全部の合計が総度数 (200人)です。「周辺(marginal)」は表の縁(端)に書かれるから。
4級では「この表から、男性で購入した人は何人?」のように人数を読み取れればOKです。
クロス集計表は 2変数の度数分布表。1変数の度数分布表(→ 度数分布表とヒストグラム ── 階級・相対度数・累積度数とスタージェスの公式)を2変数に拡張したもの。質的×質的版の「2変数の関係」であり、量的×量的版の散布図・相関係数(→ 2変数の記述(散布図・共分散・相関係数)── 相関≠因果/rは直線関係しか測れない/外れ値1点で激変)に対応します。
行比率・列比率・全体比率(3級)── ここが一番のつまずきどころ
セルの人数をそのまま比べても、行や列の合計が違うとフェアに比べられません。そこで割り算で割合に直します。ポイントは「何で割るか」で3種類あること。
| 種類 | 割る相手 | こう読む |
|---|---|---|
| 行比率 | その行の合計 | 各行が100%。「男女それぞれの購入率」 |
| 列比率 | その列の合計 | 各列が100%。「購入者・非購入者それぞれの男女比」 |
| 全体比率 | 全体の人数 | 表全体が100%。「各マスが全体に占める割合」 |
さっきの表を行比率(各行をその行の合計で割る)にすると:
| 購入した | 購入しない | |
|---|---|---|
| 男性 | 30÷100 = 30% | 70% |
| 女性 | 60÷100 = 60% | 40% |
→「男性30%・女性60%」なので、女性のほうが購入率が高いと読めます。
同じ表を列比率(各列をその列の合計で割る)にすると:
| 購入した | 購入しない | |
|---|---|---|
| 男性 | 30÷90 ≈ 33% | 64% |
| 女性 | 60÷90 ≈ 67% | 36% |
→「購入した人のうち女性が67%」。
ここが超重要です。行比率の「女性の購入率60%」と、列比率の「購入者のうち女性が67%」は、まったく別の問いに答えています。 何で割ったかを見失うと、まるで違う結論を出してしまいます。
要するに:行比率は「女性は買うのか?」、列比率は「買う人は女性か?」。問いの向きが逆なんです。試験では「何で割るべきか」を選ばせたり、行比率と列比率を取り違えさせる選択肢がよく出ます。
連関と独立 ── 2つの変数に関係はある?(2級)
2つの種類データに「関係がある」ことを連関 (association) といいます。量的データでいう「相関」の種類版です。関係がない状態を独立と呼びます。
独立のイメージ:行を変えても列の割合(行比率)が変わらないこと。さっきの例なら「男性も女性も購入率が同じ」なら独立です。実際は30%対60%で違うので、連関ありですね。
期待度数 ── 「もし関係なかったら」の人数
もし2つの変数が完全に独立だったら、各マスに来るはずの人数を**期待度数 (expected frequency)**といいます。式はこれ。
要するに:「全体での購入率を、行の人数にそのまま当てはめたらこうなるはず」という理論値です。
さっきの例で「男性 × 購入した」マスの期待度数は 人。でも実際は30人。独立なら45人いるはずが30人しかいない=これが連関(関係がある)の証拠になります。
連関の強さ ── クラメールの連関係数
「どれくらい強く関係しているか」を測りたいときは、観測された人数()と期待度数()のズレを全マスで合計します。
要するに:「独立ならこうなるはず()から、実際()がどれだけズレているか」の合計。0なら完全に独立、大きいほど強い連関です。
ただしこの値はデータの人数 や表のサイズ(行数・列数)で膨らんでしまうので、0〜1の範囲に直したものを使います。それがクラメールの連関係数 。
(=全体の人数、=行数、=列数)。なら独立、なら完全に関係している(片方が決まればもう片方も決まる)状態。これは相関係数の種類版だと思えばOKです。
なお「このズレが偶然のものか、それとも本当に関係があると言えるのか」を確率で判定するのが独立性のカイ二乗検定(自由度 )ですが、それは検定の単元の話。この記事では「期待度数・連関の強さ」までにとどめます。
日常の具体例:性別×購入の表で考える
居酒屋のクーポンを配って、性別ごとに「使った/使わなかった」を集計したとします。
- 行比率で見ると「女性の利用率60%・男性30%」→ 女性に効くクーポンだな、と分かる。
- 列比率で見ると「使った人の67%が女性」→ 利用者の主役は女性だ、と分かる。
- 期待度数と比べると、独立なら男性の利用は45人のはずが30人。「性別と利用には連関がある」と判断できる。
同じ1枚の表から、見方を変えるだけで3つの異なる情報が引き出せるわけです。
試験での問われ方(級差)
- 4級:分割表からセル度数・行和・列和・総度数を読む。「条件Aかつ条件Bの人数」を答える。
- 3級:行比率・列比率・全体比率を計算し、帯グラフ・モザイク図(→ 統計グラフの読み方(棒・折れ線・円・帯)と誤解を招くグラフ)で群間の割合を比較する。「何で割るか」を選ぶ。
- 2級:期待度数 を計算、観測との差で連関を判断、クラメールの 、シンプソンのパラドックス。独立性のカイ二乗検定(自由度 )は検定ドメインで本格化。
シンプソンのパラドックス ── 全体で見ると逆転する罠
これは2級で問われる、そして実務でも一番怖い現象です。層(グループ)ごとに見るとA優勢なのに、全部まとめると逆にB優勢に見えるというもの。
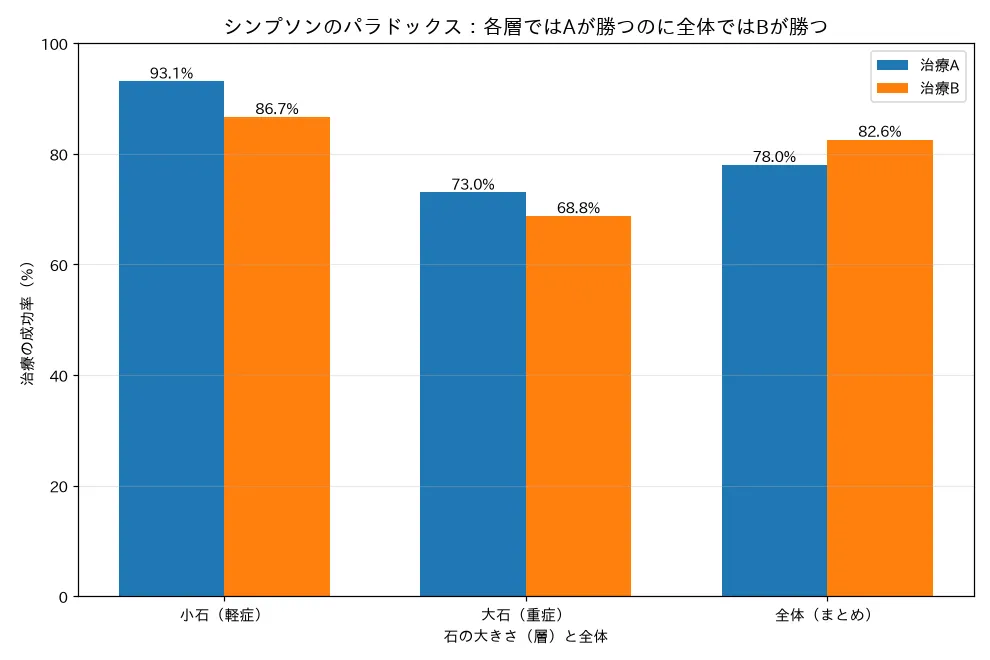
有名な腎臓結石の治療データで見てみましょう。治療法A・Bを「小さい石」「大きい石」で分けて成功率を出すと:
| 石の大きさ | 治療A | 治療B | 勝つのは |
|---|---|---|---|
| 小さい石(軽症) | 93.1%(81/87) | 86.7%(234/270) | A |
| 大きい石(重症) | 73.0%(192/263) | 68.8%(55/80) | A |
どちらの層でも治療Aが勝っています。ところが、層を無視して全部まとめると…
| 治療A | 治療B | 勝つのは | |
|---|---|---|---|
| 全体(まとめ) | 78.0%(273/350) | 82.6%(289/350) | B |
逆転しました。 各層ではAが強いのに、全体ではBが強く見える。なぜでしょう?
原因は「どんな患者に使ったかの偏り」です。治療Aは難しい大きい石(成功しにくい)に多く使われ、治療Bは簡単な小さい石(成功しやすい)に多く使われていました。全体の数字は「どの石に使ったか」という層を隠してしまうので、楽な患者ばかりだったBが見かけ上有利になるのです。
この「層と治療の両方に影響する隠れた変数(ここでは石の大きさ=重症度)」を交絡変数といいます。関係を見るときは「層を隠していないか?」を必ず疑いましょう。
graph LR
C["石の大きさ・重症度"] -->|"重症ほどAを選ぶ"| T["治療法A or B"]
C -->|"重症ほど失敗しやすい"| R["成功 or 失敗"]
T -->|"本当に見たい関係"| R
上の図のように、石の大きさが「治療の選ばれ方」と「成功率」の両方に矢印を伸ばしているのがミソ。これを無視して治療→成功だけ見ると、石の大きさの影響が紛れ込んで逆転が起きます。
シンプソンのパラドックスは量的データの相関でも起きます(層別すると相関の符号が逆転する → 2変数の記述(散布図・共分散・相関係数)── 相関≠因果/rは直線関係しか測れない/外れ値1点で激変 のシンプソン)。種類データでも数量データでも、「全体の集計は層を隠す」という教訓は共通です。
数式の直観的意味
1. 独立 ⟺ 行比率が全行で等しい ⟺ 期待度数 = 行和×列和÷総和(導出)
すべて確率の独立 から出る。表の度数を確率に直して考える。
総度数 、行 の和を 、列 の和を 、セル の度数を とする。相対度数(割合)を確率とみなすと:
(a) 独立の定義から期待度数へ。 2変数が独立なら定義より 。代入すると
要するに**「独立なら各セルの度数は になるはず」**。この理論値が期待度数。逆に観測 がこれからズレていれば連関の証拠。
(b) なぜ「行比率が揃う=独立」なのか(条件付き確率)。 行 における列 の行比率は、条件付き確率そのもの:
独立だと より なので
右辺 は行 に依存しない(どの行でも同じ)。つまり独立 ⟺ 行比率 がどの行 でも同じ 。これが「全行で行比率が揃えば独立」の正体。条件付き確率の言葉で言えば「行(条件)を変えても列の分布が変わらない」。
3つの言い換えは完全に同値:
2. 行比率と列比率は一般に違う(条件付き確率の向き )
行比率 、列比率 。これは条件と結果が逆の条件付き確率。一般に
本文の例:行比率「女性の購入率」 と、列比率「購入者中の女性割合」 は別物。両者をつなぐのがベイズの定理 (→ Phase 2 の前方リンク 条件付き確率・独立性・全確率の定理)。
実務的な含意:「女性は男性より買う」(行比率の話)と「買う人は女性が多い」(列比率の話)は結論が一致するとは限らない。問いが「どっちで割る話か」を毎回確認する。
3. 連関の強さ:χ²のズレからクラメール が に収まる理由
χ²統計量 は「独立からのズレの2乗和( で重み付け)」。これがなぜ で になるかは上限で決まる。
表の場合( 係数)。 なら で
では は2変数を にコード化したときのピアソン相関係数の絶対値に一致する(→ 2変数の記述(散布図・共分散・相関係数)── 相関≠因果/rは直線関係しか測れない/外れ値1点で激変)。相関係数が だから 、すなわち 。等号 ()は完全連関=対角だけに度数が集まり、一方が決まれば他方が確定するとき。
一般の 表。証明の要点だけ:各セルの寄与を整理すると の最大値は で抑えられる(完全連関のとき達成)。よって
分母の は「表の形(行数・列数)による の天井」を打ち消すための正規化因子。要するに ** は「サイズに依らない連関の強さ」**で、相関係数 が「単位に依らない直線関係の強さ」(→ 2変数の記述(散布図・共分散・相関係数)── 相関≠因果/rは直線関係しか測れない/外れ値1点で激変)なのと同じ発想。
厳密な一般証明は1級レベル。2級では「 は を に正規化した連関の強さ」「 独立・ 完全連関」を押さえれば十分。 自体の標本分布(自由度 のカイ二乗分布)と検定は検定ドメイン(カイ二乗独立性検定)へ。
⚠️ 引っかけポイント・頻出論点・級ごとの差
- 行比率と列比率の取り違え(最頻出):「何で割ったか」を必ず確認。「女性の購入率(行比率)」と「購入者の女性割合(列比率)」は別問題。設問が問うている方向(行か列か)に分母を合わせないと誤答する。
- 周辺度数だけ見て連関を判断しない:行和・列和(周辺)が大きい/小さいことと、連関があるかは別。連関は「セル度数が期待度数からズレているか」で見る。周辺が偏っていても独立なことはある。
- 独立でもセル度数は0ではない:「独立=関係ない=度数0」ではない。独立なら度数は期待度数 になるだけ。0連関と0度数は無関係。
- シンプソンのパラドックス(層別で逆転):全体の表では A が優勢でも、第3の変数で層別すると各層で B が優勢になりうる(逆も)。原因は交絡変数(層と行・列の両方に効く第3変数)と層ごとのサンプル数の偏り。有名な腎臓結石の例:治療Aは小石(93% vs 87%)でも大石(73% vs 69%)でも治療Bに勝つのに、全体では負ける(78% vs 83%)。Aが重症(大石)に多く使われたため。全体の表は層を隠す。量的版(→ 2変数の記述(散布図・共分散・相関係数)── 相関≠因果/rは直線関係しか測れない/外れ値1点で激変 のシンプソン)と同じ現象。
- 連関 ≠ 因果: が大きくても「行が列の原因」とは限らない。相関≠因果(→ 2変数の記述(散布図・共分散・相関係数)── 相関≠因果/rは直線関係しか測れない/外れ値1点で激変)の質的版。交絡・逆因果・偶然がありうる。連関は記述、因果は別の枠組み(実験計画・因果推論)。
- χ²の値だけで強さを比較しない: は や表のサイズで膨らむ。サンプルを2倍にすれば同じパターンでも は2倍。強さの比較は無次元の で。
- モザイク図/帯グラフは行比率の可視化:帯グラフは各行を100%に揃えて列の構成比(行比率)を比べる図。独立なら全帯が同じ模様、連関ありなら帯ごとに模様が変わる(→ 統計グラフの読み方(棒・折れ線・円・帯)と誤解を招くグラフ)。
- 級差:4級=表の読み(度数・周辺度数)/3級=行比率・列比率・全体比率の計算と帯グラフ比較/2級=期待度数・連関・クラメール ・シンプソン。独立性検定そのものは検定ドメイン。
- 出題範囲は改訂されうるため受験前に最新の範囲表で要確認(2級でクラメールの をどこまで計算させるか、3級でモザイク図をどこまで扱うかは年度により変動の可能性)。
よくある疑問
Q1. 行比率と列比率、どっちを使えばいいの?
「比べたい方向」で決めます。「グループごとに(行ごとに)違いがあるか」を見たいなら行比率、「ある結果になった人たちの内訳」を見たいなら列比率です。さっきの例なら「男女で購入率が違うか」→行比率、「購入者の男女内訳」→列比率。設問が問うている向きに分母を合わせてください。
Q2. 「独立」って、人数が0ってこと?
いいえ。独立は「関係がない」であって「人数が0」ではありません。独立なら各マスには期待度数(行和×列和÷全体)ぶんの人がちゃんといます。たとえば男性で購入した人が45人いても、その45人が「全体の購入率どおり」なら独立です。0人とはまったく別の話です。
Q3. 連関があれば「原因と結果」と言っていいの?
言えません。これは「相関≠因果」の種類版です。連関が強くても、逆向きの因果や、第3の隠れた原因(交絡)や、ただの偶然のこともあります。シンプソンのパラドックスがまさにその警告で、表面の関係は層を隠した見かけにすぎないことがあります。連関は「関係がありそう」までで、因果は別の手法(実験など)で確かめる必要があります。
まとめ
- クロス集計表は2つの種類データの人数を行×列で並べた表。周辺度数(行和・列和・総度数)も読む。
- 行比率・列比率・全体比率は「何で割るか」で意味が変わる。問いの向きに分母を合わせる。行比率と列比率の取り違えが最頻出ミス。
- 独立 ⟺ どの行でも行比率が同じ ⟺ 各マスの人数が「行和×列和÷全体」(期待度数)。観測がここからズレるほど連関が強い。0〜1に直したのがクラメールの 。
- シンプソンのパラドックス:全体集計は層を隠す。層別すると関係が逆転することがある。連関も相関も「層を隠していないか」を疑うこと。
対応するシミュレーション
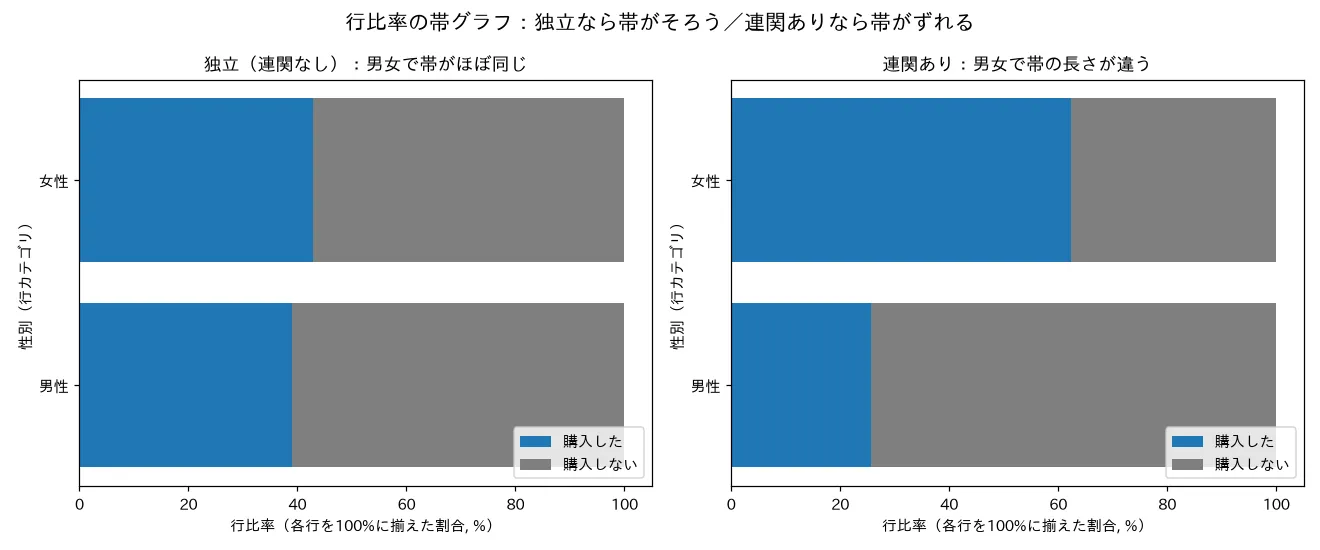
simulations/cross_gyohiritsu_kitaido.py- 何を示すか:独立なデータと連関ありデータでそれぞれクロス集計表を作り、行比率が「揃う/揃わない」を数値と帯グラフで対比。期待度数 を計算し、観測との差(独立データは差ほぼ0、連関データは差大)を見せる。
- 実行結果(成功):独立データは男性の購入率39.0%・女性42.8% とほぼ同じで、観測と期待度数のズレは全体のわずか3.8%(標本のゆらぎの範囲)。連関データは男性25.7%・女性62.4% と大きく食い違い、ズレは全体の36.7%と桁違い。帯グラフで「独立=同じ模様の帯/連関=模様の違う帯」が一目で分かる。
- 結論:「行比率が揃う=独立」「揃わない=連関」が目で確認できる。
simulations/cross_simpson_paradox.py- 何を示すか:腎臓結石の治療A/Bの有名な数値を再現し、層別(小石・大石)では各層でAが勝つのに、全体に合算するとBが勝つ逆転を数値とグラフで実証。
- 実行結果(成功):小石 A 93.1% > B 86.7%、大石 A 73.0% > B 68.8%、なのに全体 A 78.0% < B 82.6%。各層と全体の成功率を並べた棒グラフで「層では A が上・全体では B が上」の逆転を可視化。
- 結論:全体集計は層(交絡変数=石の大きさ)を隠す。層別すると関係が逆転しうる。
関連ノート
- 2変数の記述(散布図・共分散・相関係数)── 相関≠因果/rは直線関係しか測れない/外れ値1点で激変(2変数の記述:散布図・相関係数 ── 量的×量的の関係。本トピックはその質的×質的版。相関係数 ↔ クラメール 、相関≠因果 ↔ 連関≠因果。シンプソンのパラドックスは両方に現れる。後方リンク)
- データの種類と尺度水準(データの種類と尺度水準 ── クロス集計は質的×質的(名義/順序)に使う。量的なら散布図。2級で名義×名義の連関にクラメール を選ぶ根拠。後方リンク)
- 統計グラフの読み方(棒・折れ線・円・帯)と誤解を招くグラフ(データの可視化 ── 帯グラフ・モザイク図は行比率の可視化。独立なら帯が同模様、連関ありなら帯ごとに変わる。後方リンク)
- 度数分布表とヒストグラム ── 階級・相対度数・累積度数とスタージェスの公式(度数分布表・ヒストグラム ── クロス集計表は2変数の度数分布表。1変数の度数分布を2次元に拡張したもの。後方リンク)
- 条件付き確率・独立性・全確率の定理(条件付き確率・ベイズの定理 ── 行比率 、列比率 。両者をつなぐのがベイズの定理。前方リンク・Phase 2)
- カイ二乗独立性検定(観測されたズレが偶然か母集団でも連関ありと言えるかを確率で判定。自由度 。 統計量の標本分布。検定ドメインの将来トピック)