← 統計検定テキスト 一覧
📊 対象級:準1級 | 重要度:A(頻出)
同時分布・周辺分布・条件付き分布 ── 周辺化(足し潰す)/条件付け(割って正規化)/全分散の法則
要点(BLUF)
同時分布 =2つの確率変数 ( X , Y ) (X,Y) ( X , Y ) p ( x , y ) = P ( X = x , Y = y ) p(x,y)=P(X=x,Y=y) p ( x , y ) = P ( X = x , Y = y ) f ( x , y ) f(x,y) f ( x , y ) ∬ f d x d y = 1 \iint f\,dx\,dy=1 ∬ f d x d y = 1 確率は領域の体積 )。周辺分布 =相手の変数を足し潰す/積分で潰す 。p X ( x ) = ∑ y p ( x , y ) p_X(x)=\sum_y p(x,y) p X ( x ) = ∑ y p ( x , y ) f X ( x ) = ∫ f ( x , y ) d y f_X(x)=\int f(x,y)\,dy f X ( x ) = ∫ f ( x , y ) d y 期待値・分散の性質(線形性・和の分散・共分散) の E [ X + Y ] E[X+Y] E [ X + Y ] ∑ y p ( x , y ) = p X ( x ) \sum_y p(x,y)=p_X(x) ∑ y p ( x , y ) = p X ( x ) 条件付き分布 =同時を周辺で割って正規化。p ( y ∣ x ) = p ( x , y ) p X ( x ) p(y\mid x)=\dfrac{p(x,y)}{p_X(x)} p ( y ∣ x ) = p X ( x ) p ( x , y ) f ( y ∣ x ) = f ( x , y ) f X ( x ) f(y\mid x)=\dfrac{f(x,y)}{f_X(x)} f ( y ∣ x ) = f X ( x ) f ( x , y ) 条件付き確率・独立性・全確率の定理 の P ( B ∣ A ) = P ( A ∩ B ) P ( A ) P(B\mid A)=\dfrac{P(A\cap B)}{P(A)} P ( B ∣ A ) = P ( A ) P ( A ∩ B ) 確率変数版 。独立 ⟺ p ( x , y ) = p X ( x ) p Y ( y ) ⟺ \iff p(x,y)=p_X(x)p_Y(y) \iff ⟺ p ( x , y ) = p X ( x ) p Y ( y ) ⟺ (p ( y ∣ x ) = p Y ( y ) p(y\mid x)=p_Y(y) p ( y ∣ x ) = p Y ( y ) 全分散の法則(準1級の山) V [ Y ] = E [ V [ Y ∣ X ] ] + V [ E [ Y ∣ X ] ] \boxed{V[Y]=E\big[V[Y\mid X]\big]+V\big[E[Y\mid X]\big]} V [ Y ] = E [ V [ Y ∣ X ] ] + V [ E [ Y ∣ X ] ] 級内変動の平均+級間(条件付き期待値の)変動 」。全期待値の法則 E [ Y ] = E [ E [ Y ∣ X ] ] E[Y]=E[E[Y\mid X]] E [ Y ] = E [ E [ Y ∣ X ]] 2変量正規 :⑥で予告した「無相関 ⟺ \iff ⟺ 」が成り立つ特例。ρ = 0 \rho=0 ρ = 0
本文
同時分布(joint distribution)
2つの確率変数 X , Y X,Y X , Y 同時に 見たときの確率を表すのが同時分布 。
離散:同時確率質量関数(同時PMF)
p ( x , y ) = P ( X = x , Y = y ) p(x,y)=P(X=x,\ Y=y) p ( x , y ) = P ( X = x , Y = y ) 要するに「X X X x x x かつ Y Y Y y y y
∑ x ∑ y p ( x , y ) = 1 , p ( x , y ) ≥ 0. \sum_x\sum_y p(x,y)=1,\qquad p(x,y)\ge 0. x ∑ y ∑ p ( x , y ) = 1 , p ( x , y ) ≥ 0. 連続:同時確率密度関数(同時PDF)
P ( ( X , Y ) ∈ A ) = ∬ A f ( x , y ) d x d y , ∬ R 2 f ( x , y ) d x d y = 1 , f ( x , y ) ≥ 0. P\big((X,Y)\in A\big)=\iint_A f(x,y)\,dx\,dy,\qquad \iint_{\mathbb{R}^2} f(x,y)\,dx\,dy=1,\qquad f(x,y)\ge 0. P ( ( X , Y ) ∈ A ) = ∬ A f ( x , y ) d x d y , ∬ R 2 f ( x , y ) d x d y = 1 , f ( x , y ) ≥ 0. 要するに「確率は同時PDF f f f 」。1変数で「確率=面積」だったのが、2変数では「確率=体積」に上がる。f ( x , y ) f(x,y) f ( x , y ) 確率変数(離散・連続)と期待値・分散 。値が1を超えることもある)。
同時CDF(参考) :F ( x , y ) = P ( X ≤ x , Y ≤ y ) F(x,y)=P(X\le x,\ Y\le y) F ( x , y ) = P ( X ≤ x , Y ≤ y ) f ( x , y ) = ∂ 2 F ∂ x ∂ y f(x,y)=\dfrac{\partial^2 F}{\partial x\,\partial y} f ( x , y ) = ∂ x ∂ y ∂ 2 F
周辺分布(marginal distribution)=相手を足し潰す/積分で潰す
同時分布から、片方の変数だけ の分布を取り出す操作が周辺化(marginalization) 。
p X ( x ) = ∑ y p ( x , y ) f X ( x ) = ∫ − ∞ ∞ f ( x , y ) d y \boxed{\,p_X(x)=\sum_y p(x,y)\,}\qquad
\boxed{\,f_X(x)=\int_{-\infty}^{\infty} f(x,y)\,dy\,} p X ( x ) = y ∑ p ( x , y ) f X ( x ) = ∫ − ∞ ∞ f ( x , y ) d y 要するに「相手の変数 Y Y Y Y Y Y 」。残った x x x X X X Y Y Y p Y ( y ) = ∑ x p ( x , y ) p_Y(y)=\sum_x p(x,y) p Y ( y ) = ∑ x p ( x , y ) f Y ( y ) = ∫ f ( x , y ) d x f_Y(y)=\int f(x,y)\,dx f Y ( y ) = ∫ f ( x , y ) d x
名前の由来:離散の同時分布を表にすると、各行・各列の合計を**表の余白(margin)**に書く。その余白の数値こそが周辺分布。
⑥ 期待値・分散の性質(線形性・和の分散・共分散) で E [ X + Y ] = E [ X ] + E [ Y ] E[X+Y]=E[X]+E[Y] E [ X + Y ] = E [ X ] + E [ Y ] ∑ x ∑ y x p ( x , y ) = ∑ x x ( ∑ y p ( x , y ) ) = ∑ x x p X ( x ) = E [ X ] \sum_x\sum_y x\,p(x,y)=\sum_x x\Big(\sum_y p(x,y)\Big)=\sum_x x\,p_X(x)=E[X] ∑ x ∑ y x p ( x , y ) = ∑ x x ( ∑ y p ( x , y ) ) = ∑ x x p X ( x ) = E [ X ] ∑ y p ( x , y ) = p X ( x ) \sum_y p(x,y)=p_X(x) ∑ y p ( x , y ) = p X ( x )
条件付き分布(conditional distribution)=同時を周辺で割る
「X = x X=x X = x Y Y Y 条件付き分布 。
p ( y ∣ x ) = p ( x , y ) p X ( x ) ( p X ( x ) > 0 ) f ( y ∣ x ) = f ( x , y ) f X ( x ) ( f X ( x ) > 0 ) \boxed{\,p(y\mid x)=\frac{p(x,y)}{p_X(x)}\,}\quad(p_X(x)>0)\qquad
\boxed{\,f(y\mid x)=\frac{f(x,y)}{f_X(x)}\,}\quad(f_X(x)>0) p ( y ∣ x ) = p X ( x ) p ( x , y ) ( p X ( x ) > 0 ) f ( y ∣ x ) = f X ( x ) f ( x , y ) ( f X ( x ) > 0 ) 要するに「同時分布を、条件にした側の周辺分布で割って正規化 」。これは③ 条件付き確率・独立性・全確率の定理 の条件付き確率 P ( B ∣ A ) = P ( A ∩ B ) P ( A ) P(B\mid A)=\dfrac{P(A\cap B)}{P(A)} P ( B ∣ A ) = P ( A ) P ( A ∩ B ) 確率変数版 そのもの(事象 A = { X = x } A=\{X=x\} A = { X = x } B = { Y = y } B=\{Y=y\} B = { Y = y } p X ( x ) p_X(x) p X ( x ) X = x X=x X = x
確かに y y y
∑ y p ( y ∣ x ) = ∑ y p ( x , y ) p X ( x ) = 1 p X ( x ) ∑ y p ( x , y ) = p X ( x ) p X ( x ) = 1. \sum_y p(y\mid x)=\sum_y\frac{p(x,y)}{p_X(x)}=\frac{1}{p_X(x)}\sum_y p(x,y)=\frac{p_X(x)}{p_X(x)}=1. y ∑ p ( y ∣ x ) = y ∑ p X ( x ) p ( x , y ) = p X ( x ) 1 y ∑ p ( x , y ) = p X ( x ) p X ( x ) = 1. ここまでの3つの関係を1枚にすると次の通り。
flowchart LR
J["同時分布 p(x,y)"]
M["周辺分布 p_X(x)"]
C["条件付き分布 p(y|x)"]
J -->|"Yを足し潰す(周辺化)"| M
J -->|"周辺で割って正規化"| C
M -->|"条件付けの分母に使う"| C
独立の同値条件(確率変数版)
X , Y X,Y X , Y 独立 とは、すべての ( x , y ) (x,y) ( x , y )
p ( x , y ) = p X ( x ) p Y ( y ) ( 連続なら f ( x , y ) = f X ( x ) f Y ( y ) ) \boxed{\,p(x,y)=p_X(x)\,p_Y(y)\ \ (\text{連続なら}\ f(x,y)=f_X(x)f_Y(y))\,} p ( x , y ) = p X ( x ) p Y ( y ) ( 連続なら f ( x , y ) = f X ( x ) f Y ( y )) これは次と同値(条件付き分布が周辺分布に一致=条件を付けても分布が変わらない):
p ( y ∣ x ) = p Y ( y ) ( かつ p ( x ∣ y ) = p X ( x ) ) . p(y\mid x)=p_Y(y)\quad(\text{かつ}\quad p(x\mid y)=p_X(x)). p ( y ∣ x ) = p Y ( y ) ( かつ p ( x ∣ y ) = p X ( x )) . 要するに「X X X Y Y Y 条件付き確率・独立性・全確率の定理 の事象の独立 P ( B ∣ A ) = P ( B ) P(B\mid A)=P(B) P ( B ∣ A ) = P ( B ) 期待値・分散の性質(線形性・和の分散・共分散) で「独立なら E [ X Y ] = E [ X ] E [ Y ] E[XY]=E[X]E[Y] E [ X Y ] = E [ X ] E [ Y ] C o v = 0 \mathrm{Cov}=0 Cov = 0 p ( x , y ) = p X p Y p(x,y)=p_Xp_Y p ( x , y ) = p X p Y
3つの分布と独立の対応:
用語 離散の式 連続の式 ひとことで 同時分布 p ( x , y ) p(x,y) p ( x , y ) f ( x , y ) f(x,y) f ( x , y ) 全ペアの確率(体積) 周辺分布 p X ( x ) = ∑ y p ( x , y ) p_X(x)=\sum_y p(x,y) p X ( x ) = ∑ y p ( x , y ) f X ( x ) = ∫ f d y f_X(x)=\int f\,dy f X ( x ) = ∫ f d y 相手を足し潰す 条件付き分布 p ( y ∣ x ) = p ( x , y ) p X ( x ) p(y\mid x)=\dfrac{p(x,y)}{p_X(x)} p ( y ∣ x ) = p X ( x ) p ( x , y ) f ( y ∣ x ) = f ( x , y ) f X ( x ) f(y\mid x)=\dfrac{f(x,y)}{f_X(x)} f ( y ∣ x ) = f X ( x ) f ( x , y ) 同時÷周辺で正規化 独立の同値条件 p ( x , y ) = p X p Y p(x,y)=p_X p_Y p ( x , y ) = p X p Y f ( x , y ) = f X f Y f(x,y)=f_X f_Y f ( x , y ) = f X f Y 条件付き=周辺
条件付き期待値(conditional expectation)
条件付き分布で期待値を取ったものが条件付き期待値 。
E [ Y ∣ X = x ] = ∑ y y p ( y ∣ x ) ( 連続: ∫ y f ( y ∣ x ) d y ) E[Y\mid X=x]=\sum_y y\,p(y\mid x)\qquad\Big(\text{連続:}\int y\,f(y\mid x)\,dy\Big) E [ Y ∣ X = x ] = y ∑ y p ( y ∣ x ) ( 連続: ∫ y f ( y ∣ x ) d y ) これは x x x x x x x x x X X X E [ Y ∣ X ] E[Y\mid X] E [ Y ∣ X ] X X X x x x E [ Y ∣ X ] E[Y\mid X] E [ Y ∣ X ] E [ Y ∣ X = x ] E[Y\mid X=x] E [ Y ∣ X = x ] X X X E [ Y ∣ X ] E[Y\mid X] E [ Y ∣ X ]
同様に条件付き分散 V [ Y ∣ X ] = E [ Y 2 ∣ X ] − ( E [ Y ∣ X ] ) 2 V[Y\mid X]=E[Y^2\mid X]-(E[Y\mid X])^2 V [ Y ∣ X ] = E [ Y 2 ∣ X ] − ( E [ Y ∣ X ] ) 2 X X X
全期待値の法則(law of total expectation / tower property)
E [ Y ] = E [ E [ Y ∣ X ] ] \boxed{\,E[Y]=E\big[E[Y\mid X]\big]\,} E [ Y ] = E [ E [ Y ∣ X ] ] 要するに「まず X X X Y Y Y X X X 」。外側の期待値は X X X 条件付き確率・独立性・全確率の定理 の全確率の定理 P ( B ) = ∑ i P ( A i ) P ( B ∣ A i ) P(B)=\sum_i P(A_i)P(B\mid A_i) P ( B ) = ∑ i P ( A i ) P ( B ∣ A i )
例 :箱A(Y Y Y Y Y Y 0.3 0.3 0.3 0.7 0.7 0.7 E [ Y ] = 0.3 × 10 + 0.7 × 20 = 17 E[Y]=0.3\times10+0.7\times20=17 E [ Y ] = 0.3 × 10 + 0.7 × 20 = 17
全分散の法則(law of total variance)── 本トピックの山・準1級頻出
V [ Y ] = E [ V [ Y ∣ X ] ] ⏟ 級内変動の平均 + V [ E [ Y ∣ X ] ] ⏟ 級間変動 \boxed{\,V[Y]=\underbrace{E\big[V[Y\mid X]\big]}_{\text{級内変動の平均}}+\underbrace{V\big[E[Y\mid X]\big]}_{\text{級間変動}}\,} V [ Y ] = 級内変動の平均 E [ V [ Y ∣ X ] ] + 級間変動 V [ E [ Y ∣ X ] ] 要するに「Y Y Y X X X
項 名前 意味 E [ V [ Y ∣ X ] ] E\big[V[Y\mid X]\big] E [ V [ Y ∣ X ] ] 級内変動(within)の平均 同じグループ内でも Y Y Y V [ E [ Y ∣ X ] ] V\big[E[Y\mid X]\big] V [ E [ Y ∣ X ] ] 級間変動(between) グループごとの平均値がグループ間でばらつく
完全導出は「数式の直観的意味」に置く。分散分析(一元配置)の「全変動=級内変動+級間変動」、相関比 η 2 = V [ E [ Y ∣ X ] ] V [ Y ] \eta^2=\dfrac{V[E[Y\mid X]]}{V[Y]} η 2 = V [ Y ] V [ E [ Y ∣ X ]]
日常の具体例(テストの点数) :3つのクラスの数学のテストを考える。クラスごとに平均点が違う (級間変動:A組は60点中心、B組は70点中心…)うえに、同じクラスの中でも生徒ごとに点がばらつく (級内変動)。学年全体の点数のばらつきは、「クラス内のばらつきの平均」+「クラス平均どうしのばらつき」にちょうど分かれる。クラス分けが点数の差をどれだけ説明するかは相関比 η 2 \eta^2 η 2
2変量正規分布(bivariate normal)── 無相関 ⟺ 独立の特例
⑥ 期待値・分散の性質(線形性・和の分散・共分散) で「無相関でも独立とは限らない(Y = X 2 Y=X^2 Y = X 2
f ( x , y ) = 1 2 π σ X σ Y 1 − ρ 2 exp [ − 1 2 ( 1 − ρ 2 ) ( ( x − μ X ) 2 σ X 2 − 2 ρ ( x − μ X ) ( y − μ Y ) σ X σ Y + ( y − μ Y ) 2 σ Y 2 ) ] . f(x,y)=\frac{1}{2\pi\sigma_X\sigma_Y\sqrt{1-\rho^2}}\exp\!\left[-\frac{1}{2(1-\rho^2)}\!\left(\frac{(x-\mu_X)^2}{\sigma_X^2}-2\rho\frac{(x-\mu_X)(y-\mu_Y)}{\sigma_X\sigma_Y}+\frac{(y-\mu_Y)^2}{\sigma_Y^2}\right)\right]. f ( x , y ) = 2 π σ X σ Y 1 − ρ 2 1 exp [ − 2 ( 1 − ρ 2 ) 1 ( σ X 2 ( x − μ X ) 2 − 2 ρ σ X σ Y ( x − μ X ) ( y − μ Y ) + σ Y 2 ( y − μ Y ) 2 ) ] . 要するに「2つの正規分布を相関 ρ \rho ρ ρ \rho ρ
ρ = 0 \rho=0 ρ = 0 x x x y y y exp ( 和 ) = exp ⋅ exp \exp(\text{和})=\exp\cdot\exp exp ( 和 ) = exp ⋅ exp
f ( x , y ) ∣ ρ = 0 = 1 2 π σ X e − ( x − μ X ) 2 2 σ X 2 ⏟ f X ( x ) ⋅ 1 2 π σ Y e − ( y − μ Y ) 2 2 σ Y 2 ⏟ f Y ( y ) = f X ( x ) f Y ( y ) . f(x,y)\Big|_{\rho=0}=\underbrace{\frac{1}{\sqrt{2\pi}\,\sigma_X}e^{-\frac{(x-\mu_X)^2}{2\sigma_X^2}}}_{f_X(x)}\cdot\underbrace{\frac{1}{\sqrt{2\pi}\,\sigma_Y}e^{-\frac{(y-\mu_Y)^2}{2\sigma_Y^2}}}_{f_Y(y)}=f_X(x)f_Y(y). f ( x , y ) ρ = 0 = f X ( x ) 2 π σ X 1 e − 2 σ X 2 ( x − μ X ) 2 ⋅ f Y ( y ) 2 π σ Y 1 e − 2 σ Y 2 ( y − μ Y ) 2 = f X ( x ) f Y ( y ) . 同時PDFが周辺の積に分解=独立 。だから2変量正規では「無相関(ρ = 0 \rho=0 ρ = 0 ⟺ \iff ⟺ ⇒ \Rightarrow ⇒
条件付き分布も正規 (準1級頻出の暗記事項):
Y ∣ X = x ∼ N ( μ Y + ρ σ Y x − μ X σ X , σ Y 2 ( 1 − ρ 2 ) ) . Y\mid X=x\ \sim\ N\!\left(\ \mu_Y+\rho\,\sigma_Y\frac{x-\mu_X}{\sigma_X}\ ,\ \ \sigma_Y^2(1-\rho^2)\ \right). Y ∣ X = x ∼ N ( μ Y + ρ σ Y σ X x − μ X , σ Y 2 ( 1 − ρ 2 ) ) . 条件付き期待値 E [ Y ∣ X = x ] = μ Y + ρ σ Y x − μ X σ X E[Y\mid X=x]=\mu_Y+\rho\sigma_Y\frac{x-\mu_X}{\sigma_X} E [ Y ∣ X = x ] = μ Y + ρ σ Y σ X x − μ X x x x 1次関数 (これが回帰直線の母集団版で、Phase 5 の単回帰への布石。回帰ノートはファイル名未確定のためここではリンクを張らずテキスト言及に留める)。条件付き分散 V [ Y ∣ X = x ] = σ Y 2 ( 1 − ρ 2 ) V[Y\mid X=x]=\sigma_Y^2(1-\rho^2) V [ Y ∣ X = x ] = σ Y 2 ( 1 − ρ 2 ) x x x ∣ ρ ∣ → 1 |\rho|\to1 ∣ ρ ∣ → 1 X X X Y Y Y ρ = 0 \rho=0 ρ = 0 E [ Y ∣ X = x ] = μ Y E[Y\mid X=x]=\mu_Y E [ Y ∣ X = x ] = μ Y V [ Y ∣ X = x ] = σ Y 2 V[Y\mid X=x]=\sigma_Y^2 V [ Y ∣ X = x ] = σ Y 2 X X X
具体例(離散の同時分布表)
2枚のコインを投げ、X = X= X = Y = Y= Y = Ω = { \Omega=\{ Ω = { } \} } 1 / 4 1/4 1/4
p ( x , y ) p(x,y) p ( x , y ) y = 0 y=0 y = 0 y = 1 y=1 y = 1 周辺 p X ( x ) p_X(x) p X ( x ) x = 0 x=0 x = 0 1 / 4 1/4 1/4 0 0 0 1 / 4 1/4 1/4 x = 1 x=1 x = 1 1 / 4 1/4 1/4 1 / 4 1/4 1/4 1 / 2 1/2 1/2 x = 2 x=2 x = 2 0 0 0 1 / 4 1/4 1/4 1 / 4 1/4 1/4 周辺 p Y ( y ) p_Y(y) p Y ( y ) 1 / 2 1/2 1/2 1 / 2 1/2 1/2 1 1 1
周辺化 :右端の列 p X p_X p X p Y p_Y p Y 条件付き :X = 1 X=1 X = 1 p ( y ∣ X = 1 ) = p ( 1 , y ) p X ( 1 ) p(y\mid X=1)=\dfrac{p(1,y)}{p_X(1)} p ( y ∣ X = 1 ) = p X ( 1 ) p ( 1 , y ) y = 0 y=0 y = 0 1 / 4 1 / 2 = 1 2 \dfrac{1/4}{1/2}=\dfrac12 1/2 1/4 = 2 1 y = 1 y=1 y = 1 1 2 \dfrac12 2 1 独立でない :例えば p ( 0 , 1 ) = 0 ≠ p X ( 0 ) p Y ( 1 ) = 1 4 ⋅ 1 2 = 1 8 p(0,1)=0\neq p_X(0)p_Y(1)=\frac14\cdot\frac12=\frac18 p ( 0 , 1 ) = 0 = p X ( 0 ) p Y ( 1 ) = 4 1 ⋅ 2 1 = 8 1 y = 1 y=1 y = 1 X X X Y Y Y
試験での問われ方(級ごとの差)
2級 :離散の同時分布表からの周辺分布の計算 、独立性の判定(p ( x , y ) = p X p Y p(x,y)=p_Xp_Y p ( x , y ) = p X p Y E [ X Y ] E[XY] E [ X Y ] 期待値・分散の性質(線形性・和の分散・共分散) と一体)。範囲表は「確率変数の和と差(同時分布、和の期待値・分散)」「2変数の共分散・相関」。条件付き期待値・全分散の法則・2変量正規は基本2級範囲外 (条件付き分布の初歩に触れる教材はあるが計算問題の主役は準1級から)。準1級(主) :条件付き分布・条件付き期待値 (連続も含む、定義域の明示が要求される)、全分散の法則 V [ Y ] = E [ V [ Y ∣ X ] ] + V [ E [ Y ∣ X ] ] V[Y]=E[V[Y\mid X]]+V[E[Y\mid X]] V [ Y ] = E [ V [ Y ∣ X ]] + V [ E [ Y ∣ X ]] 2変量正規の条件付き期待値 μ Y + ρ σ Y x − μ X σ X \mu_Y+\rho\sigma_Y\frac{x-\mu_X}{\sigma_X} μ Y + ρ σ Y σ X x − μ X σ Y 2 ( 1 − ρ 2 ) \sigma_Y^2(1-\rho^2) σ Y 2 ( 1 − ρ 2 ) 、無相関⟺独立の証明。混合分布の期待値・分散を全期待値/全分散で出す問題も定番。※出題範囲は改訂されうる。受験前に公式最新の出題範囲表で要最新確認 (2級は2018年版範囲表、準1級は公式ワークブック準拠が直近で確認した版)。
数式の直観的意味
周辺化はなぜ「足す/積分する」のか
同時分布 p ( x , y ) p(x,y) p ( x , y ) X = x X=x X = x Y = y Y=y Y = y 排反な細かい事象 に確率を割り振ったもの。X = x X=x X = x Y Y Y { X = x , Y = y 1 } , { X = x , Y = y 2 } , … \{X=x,Y=y_1\},\{X=x,Y=y_2\},\dots { X = x , Y = y 1 } , { X = x , Y = y 2 } , … 排反な和 。排反な事象の確率は足せる(③ 条件付き確率・独立性・全確率の定理 の全確率の定理と同じコルモゴロフ公理3)から、
p X ( x ) = P ( X = x ) = ∑ y P ( X = x , Y = y ) = ∑ y p ( x , y ) . p_X(x)=P(X=x)=\sum_y P(X=x,Y=y)=\sum_y p(x,y). p X ( x ) = P ( X = x ) = y ∑ P ( X = x , Y = y ) = y ∑ p ( x , y ) . 連続では和が積分に変わるだけ。「相手の変数のあらゆる可能性をかき集める」=足し潰す/積分で潰す 。
全期待値の法則の完全導出(離散)
定義から出発し、条件付き期待値 E [ Y ∣ X = x ] = ∑ y y p ( y ∣ x ) E[Y\mid X=x]=\sum_y y\,p(y\mid x) E [ Y ∣ X = x ] = ∑ y y p ( y ∣ x ) X X X
E [ E [ Y ∣ X ] ] = ∑ x ( ∑ y y p ( y ∣ x ) ⏟ E [ Y ∣ X = x ] ) p X ( x ) . E\big[E[Y\mid X]\big]=\sum_x \Big(\underbrace{\sum_y y\,p(y\mid x)}_{E[Y\mid X=x]}\Big)\,p_X(x). E [ E [ Y ∣ X ] ] = x ∑ ( E [ Y ∣ X = x ] y ∑ y p ( y ∣ x ) ) p X ( x ) . 条件付き分布の定義 p ( y ∣ x ) = p ( x , y ) p X ( x ) p(y\mid x)=\dfrac{p(x,y)}{p_X(x)} p ( y ∣ x ) = p X ( x ) p ( x , y ) p X ( x ) p_X(x) p X ( x )
= ∑ x ∑ y y p ( x , y ) p X ( x ) p X ( x ) = ∑ x ∑ y y p ( x , y ) . =\sum_x\sum_y y\,\frac{p(x,y)}{p_X(x)}\,p_X(x)=\sum_x\sum_y y\,p(x,y). = x ∑ y ∑ y p X ( x ) p ( x , y ) p X ( x ) = x ∑ y ∑ y p ( x , y ) . x x x ∑ x p ( x , y ) = p Y ( y ) \sum_x p(x,y)=p_Y(y) ∑ x p ( x , y ) = p Y ( y )
= ∑ y y ( ∑ x p ( x , y ) ) = ∑ y y p Y ( y ) = E [ Y ] . ■ =\sum_y y\Big(\sum_x p(x,y)\Big)=\sum_y y\,p_Y(y)=E[Y].\qquad\blacksquare = y ∑ y ( x ∑ p ( x , y ) ) = y ∑ y p Y ( y ) = E [ Y ] . ■ 要するに「条件付き期待値を周辺で加重平均すると、p X p_X p X E [ Y ] E[Y] E [ Y ] 」。鍵は「条件付け(割る)→平均(掛け戻す)」で正規化定数が打ち消し合うこと。
全分散の法則の完全導出(本トピック最重要)
準備①(条件付き分散の定義) :X X X V = E [ ⋅ 2 ] − ( E [ ⋅ ] ) 2 V=E[\cdot^2]-(E[\cdot])^2 V = E [ ⋅ 2 ] − ( E [ ⋅ ] ) 2
V [ Y ∣ X ] = E [ Y 2 ∣ X ] − ( E [ Y ∣ X ] ) 2 . V[Y\mid X]=E[Y^2\mid X]-\big(E[Y\mid X]\big)^2. V [ Y ∣ X ] = E [ Y 2 ∣ X ] − ( E [ Y ∣ X ] ) 2 . 準備②(全期待値の法則を Y 2 Y^2 Y 2 :E [ Y 2 ] = E [ E [ Y 2 ∣ X ] ] E[Y^2]=E\big[E[Y^2\mid X]\big] E [ Y 2 ] = E [ E [ Y 2 ∣ X ] ]
導出開始。Y Y Y
V [ Y ] = E [ Y 2 ] − ( E [ Y ] ) 2 . V[Y]=E[Y^2]-\big(E[Y]\big)^2. V [ Y ] = E [ Y 2 ] − ( E [ Y ] ) 2 . E [ Y 2 ] = E [ E [ Y 2 ∣ X ] ] E[Y^2]=E[E[Y^2\mid X]] E [ Y 2 ] = E [ E [ Y 2 ∣ X ]] E [ Y ] = E [ E [ Y ∣ X ] ] E[Y]=E[E[Y\mid X]] E [ Y ] = E [ E [ Y ∣ X ]]
V [ Y ] = E [ E [ Y 2 ∣ X ] ] − ( E [ E [ Y ∣ X ] ] ) 2 . V[Y]=E\big[E[Y^2\mid X]\big]-\Big(E\big[E[Y\mid X]\big]\Big)^2. V [ Y ] = E [ E [ Y 2 ∣ X ] ] − ( E [ E [ Y ∣ X ] ] ) 2 . ここで準備①を変形した E [ Y 2 ∣ X ] = V [ Y ∣ X ] + ( E [ Y ∣ X ] ) 2 E[Y^2\mid X]=V[Y\mid X]+\big(E[Y\mid X]\big)^2 E [ Y 2 ∣ X ] = V [ Y ∣ X ] + ( E [ Y ∣ X ] ) 2
V [ Y ] = E [ V [ Y ∣ X ] + ( E [ Y ∣ X ] ) 2 ] − ( E [ E [ Y ∣ X ] ] ) 2 . V[Y]=E\Big[V[Y\mid X]+\big(E[Y\mid X]\big)^2\Big]-\Big(E\big[E[Y\mid X]\big]\Big)^2. V [ Y ] = E [ V [ Y ∣ X ] + ( E [ Y ∣ X ] ) 2 ] − ( E [ E [ Y ∣ X ] ] ) 2 . 期待値の線形性で第1項を割る:
V [ Y ] = E [ V [ Y ∣ X ] ] + E [ ( E [ Y ∣ X ] ) 2 ] − ( E [ E [ Y ∣ X ] ] ) 2 ⏟ これは V [ E [ Y ∣ X ] ] . V[Y]=E\big[V[Y\mid X]\big]+\underbrace{E\Big[\big(E[Y\mid X]\big)^2\Big]-\Big(E\big[E[Y\mid X]\big]\Big)^2}_{\text{これは }V[E[Y\mid X]]}. V [ Y ] = E [ V [ Y ∣ X ] ] + これは V [ E [ Y ∣ X ]] E [ ( E [ Y ∣ X ] ) 2 ] − ( E [ E [ Y ∣ X ] ] ) 2 . 最後の下線部は、確率変数 W : = E [ Y ∣ X ] W:=E[Y\mid X] W := E [ Y ∣ X ] E [ W 2 ] − ( E [ W ] ) 2 = V [ W ] E[W^2]-(E[W])^2=V[W] E [ W 2 ] − ( E [ W ] ) 2 = V [ W ]
V [ Y ] = E [ V [ Y ∣ X ] ] + V [ E [ Y ∣ X ] ] . ■ \boxed{\,V[Y]=E\big[V[Y\mid X]\big]+V\big[E[Y\mid X]\big]\,}.\qquad\blacksquare V [ Y ] = E [ V [ Y ∣ X ] ] + V [ E [ Y ∣ X ] ] . ■ 直観(級内変動+級間変動) :X X X Y Y Y 同じグループ内でも Y Y Y (級内 V [ Y ∣ X ] V[Y\mid X] V [ Y ∣ X ] グループが違えば平均も違う (級間、グループ平均 E [ Y ∣ X ] E[Y\mid X] E [ Y ∣ X ] Y Y Y η 2 = V [ E [ Y ∣ X ] ] / V [ Y ] \eta^2=V[E[Y\mid X]]/V[Y] η 2 = V [ E [ Y ∣ X ]] / V [ Y ]
幾何学的直観(直交分解=ピタゴラス) :E [ Y ∣ X ] E[Y\mid X] E [ Y ∣ X ] X X X Y Y Y Y − E [ Y ∣ X ] Y-E[Y\mid X] Y − E [ Y ∣ X ] X X X C o v ( E [ Y ∣ X ] , Y − E [ Y ∣ X ] ) = 0 \mathrm{Cov}(E[Y\mid X],\ Y-E[Y\mid X])=0 Cov ( E [ Y ∣ X ] , Y − E [ Y ∣ X ]) = 0 Y − E [ Y ] = ( E [ Y ∣ X ] − E [ Y ] ) ⏟ 級間 + ( Y − E [ Y ∣ X ] ) ⏟ 級内 Y-E[Y]=\underbrace{(E[Y\mid X]-E[Y])}_{\text{級間}}+\underbrace{(Y-E[Y\mid X])}_{\text{級内}} Y − E [ Y ] = 級間 ( E [ Y ∣ X ] − E [ Y ]) + 級内 ( Y − E [ Y ∣ X ])
2変量正規で ρ = 0 \rho=0 ρ = 0
同時PDFの指数部は
− 1 2 ( 1 − ρ 2 ) ( ( x − μ X ) 2 σ X 2 − 2 ρ ( x − μ X ) ( y − μ Y ) σ X σ Y + ( y − μ Y ) 2 σ Y 2 ) . -\frac{1}{2(1-\rho^2)}\!\left(\frac{(x-\mu_X)^2}{\sigma_X^2}-2\rho\frac{(x-\mu_X)(y-\mu_Y)}{\sigma_X\sigma_Y}+\frac{(y-\mu_Y)^2}{\sigma_Y^2}\right). − 2 ( 1 − ρ 2 ) 1 ( σ X 2 ( x − μ X ) 2 − 2 ρ σ X σ Y ( x − μ X ) ( y − μ Y ) + σ Y 2 ( y − μ Y ) 2 ) . ρ \rho ρ 中央のクロス項 − 2 ρ ( ⋯ ) -2\rho(\cdots) − 2 ρ ( ⋯ ) 。ρ = 0 \rho=0 ρ = 0 ( 1 − ρ 2 ) = 1 (1-\rho^2)=1 ( 1 − ρ 2 ) = 1
− 1 2 ( ( x − μ X ) 2 σ X 2 + ( y − μ Y ) 2 σ Y 2 ) = − ( x − μ X ) 2 2 σ X 2 − ( y − μ Y ) 2 2 σ Y 2 . -\frac12\left(\frac{(x-\mu_X)^2}{\sigma_X^2}+\frac{(y-\mu_Y)^2}{\sigma_Y^2}\right)=-\frac{(x-\mu_X)^2}{2\sigma_X^2}-\frac{(y-\mu_Y)^2}{2\sigma_Y^2}. − 2 1 ( σ X 2 ( x − μ X ) 2 + σ Y 2 ( y − μ Y ) 2 ) = − 2 σ X 2 ( x − μ X ) 2 − 2 σ Y 2 ( y − μ Y ) 2 . 指数が x x x y y y になる。e a + b = e a e b e^{a+b}=e^a e^b e a + b = e a e b f ( x , y ) f(x,y) f ( x , y ) x x x y y y 1 2 π σ X σ Y \frac{1}{2\pi\sigma_X\sigma_Y} 2 π σ X σ Y 1 1 2 π σ X ⋅ 1 2 π σ Y \frac{1}{\sqrt{2\pi}\sigma_X}\cdot\frac{1}{\sqrt{2\pi}\sigma_Y} 2 π σ X 1 ⋅ 2 π σ Y 1 f X ( x ) f Y ( y ) f_X(x)f_Y(y) f X ( x ) f Y ( y ) クロス項こそが2変数を結びつける糊で、ρ = 0 \rho=0 ρ = 0 。一般の分布で無相関でも独立とは限らないのは、C o v = 0 \mathrm{Cov}=0 Cov = 0 Y = X 2 Y=X^2 Y = X 2
⚠️ 引っかけポイント・頻出論点・級ごとの差
周辺化する変数を間違える :p X ( x ) p_X(x) p X ( x ) 消したい方(Y Y Y 足す。「X X X X X X X X X Y Y Y 条件付き分布の分母を取り違える :p ( y ∣ x ) p(y\mid x) p ( y ∣ x ) p X ( x ) p_X(x) p X ( x ) p Y ( y ) p_Y(y) p Y ( y ) 条件付き確率・独立性・全確率の定理 と同じで「縦棒の右が条件」。「無相関なら独立」と即断(最頻出) :一般には独立 ⇒ \Rightarrow ⇒ (⑥)。逆が言えるのは2変量正規などの特例だけ 。試験で「2変量正規で ρ = 0 \rho=0 ρ = 0 条件付き期待値が「数」か「確率変数」か :E [ Y ∣ X = x ] E[Y\mid X=x] E [ Y ∣ X = x ] x x x E [ Y ∣ X ] E[Y\mid X] E [ Y ∣ X ] X X X V [ E [ Y ∣ X ] ] V[E[Y\mid X]] V [ E [ Y ∣ X ]] E [ Y ∣ X ] E[Y\mid X] E [ Y ∣ X ] X X X 全分散の2項の役割の混同 :E [ V [ Y ∣ X ] ] E[V[Y\mid X]] E [ V [ Y ∣ X ]] 分散を期待値 (級内)、V [ E [ Y ∣ X ] ] V[E[Y\mid X]] V [ E [ Y ∣ X ]] 期待値を分散 (級間)。順番(内側が分散か期待値か)で項が決まる。2変量正規の条件付き分散は x x x :V [ Y ∣ X = x ] = σ Y 2 ( 1 − ρ 2 ) V[Y\mid X=x]=\sigma_Y^2(1-\rho^2) V [ Y ∣ X = x ] = σ Y 2 ( 1 − ρ 2 ) x x x x x x 期待値 は x x x x x x 同時PDF f ( x , y ) f(x,y) f ( x , y ) :f ( x , y ) f(x,y) f ( x , y ) 1 1 1 ∬ f \iint f ∬ f 確率変数(離散・連続)と期待値・分散 )。級差 :2級=離散の同時分布表→周辺分布・独立判定・共分散 (条件付きは初歩まで)。準1級=条件付き分布/期待値・全分散の法則・2変量正規の条件付き分布 。同じ「同時分布」でも、2級は表の読み取りと周辺化、準1級は条件付けと変動分解まで深さが上がる。
よくある疑問
Q. 周辺分布を作るとき、どっちの変数で足すんでしたっけ?
A. 消したい方(残さない方)で足します。X X X p X p_X p X Y Y Y 足します。「残すのが X X X Y Y Y
Q. 条件付き分布 p ( y ∣ x ) p(y\mid x) p ( y ∣ x ) p X p_X p X p Y p_Y p Y
A. 条件にした側の周辺 、つまり p X ( x ) p_X(x) p X ( x ) p Y p_Y p Y
Q. 「無相関だから独立」と言ってよいのは?
A. 一般にはダメ です。言えるのは「独立 → 無相関」の一方向だけ。逆(無相関 → 独立)が成り立つのは2変量正規などの特例 だけです。問題に「2変量正規で ρ = 0 \rho=0 ρ = 0
Q. E [ Y ∣ X ] E[Y\mid X] E [ Y ∣ X ]
A. E [ Y ∣ X = x ] E[Y\mid X=x] E [ Y ∣ X = x ] x x x 数 、E [ Y ∣ X ] E[Y\mid X] E [ Y ∣ X ] X X X 確率変数 です。全分散の法則の第2項 V [ E [ Y ∣ X ] ] V[E[Y\mid X]] V [ E [ Y ∣ X ]] E [ Y ∣ X ] E[Y\mid X] E [ Y ∣ X ] X X X
Q. 全分散の2項、どっちがどっちか混乱します。
A. 順番で決まります。E [ V [ Y ∣ X ] ] E[V[Y\mid X]] E [ V [ Y ∣ X ]] 分散を期待値 」(級内=各グループ内のばらつきの平均)、V [ E [ Y ∣ X ] ] V[E[Y\mid X]] V [ E [ Y ∣ X ]] 期待値を分散 」(級間=グループ平均どうしのばらつき)。内側が分散か期待値かで項が決まります。これを取り違えると2項が入れ替わってしまうので注意です。
Q. 2変量正規の条件付き分散が x x x
A. 2変量正規の性質です。V [ Y ∣ X = x ] = σ Y 2 ( 1 − ρ 2 ) V[Y\mid X=x]=\sigma_Y^2(1-\rho^2) V [ Y ∣ X = x ] = σ Y 2 ( 1 − ρ 2 ) x x x 期待値 は x x x x x x
まとめ
同時分布 =全ペアの確率(離散はPMF、連続はPDFで体積)。周辺分布 =相手を足し潰す/積分で潰す。条件付き分布 =同時÷周辺で正規化(条件付き確率の確率変数版)。独立 =同時が周辺の積、=条件付き分布が周辺分布に一致。全期待値の法則 E [ Y ] = E [ E [ Y ∣ X ] ] E[Y]=E[E[Y\mid X]] E [ Y ] = E [ E [ Y ∣ X ]] 全分散の法則 V [ Y ] = E [ V [ Y ∣ X ] ] + V [ E [ Y ∣ X ] ] V[Y]=E[V[Y\mid X]]+V[E[Y\mid X]] V [ Y ] = E [ V [ Y ∣ X ]] + V [ E [ Y ∣ X ]] 2変量正規 は「無相関 ⟺ \iff ⟺ 2級は「離散の同時分布表→周辺化・独立判定・共分散」まで、準1級は「条件付け・全分散の法則・2変量正規」まで、と深さが上がる。
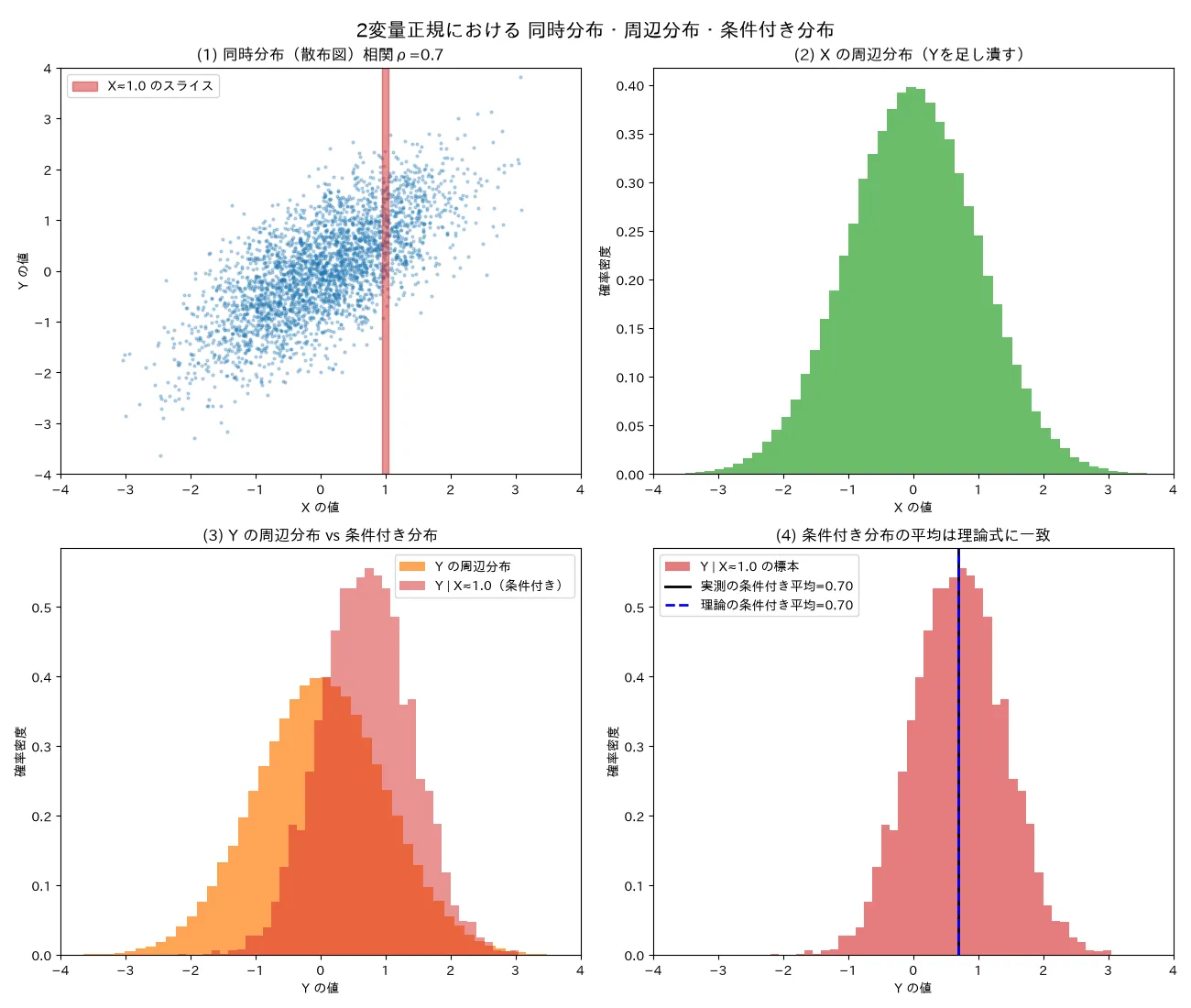
対応するシミュレーション
simulations/doujibunpu_shuhen_nihen_seiki.py
何を示すか :2変量正規 ( X , Y ) (X,Y) ( X , Y ) X X X Y Y Y X ≈ x 0 X\approx x_0 X ≈ x 0 μ Y + ρ σ Y ( x − μ X ) / σ X \mu_Y+\rho\sigma_Y(x-\mu_X)/\sigma_X μ Y + ρ σ Y ( x − μ X ) / σ X σ Y 2 ( 1 − ρ 2 ) \sigma_Y^2(1-\rho^2) σ Y 2 ( 1 − ρ 2 ) 結論(seed=0, n=20万) :μ = ( 0 , 0 ) , σ = ( 1 , 1 ) , ρ = 0.7 \mu=(0,0),\sigma=(1,1),\rho=0.7 μ = ( 0 , 0 ) , σ = ( 1 , 1 ) , ρ = 0.7 X ≈ 1.0 X\approx1.0 X ≈ 1.0 0.699 (理論 0 + 0.7 ⋅ 1 ⋅ 1 = 0.700 0+0.7\cdot1\cdot1=0.700 0 + 0.7 ⋅ 1 ⋅ 1 = 0.700 0.699 (理論 1 − 0.7 2 = 0.714 \sqrt{1-0.7^2}=0.714 1 − 0. 7 2 = 0.714 X X X Y Y Y
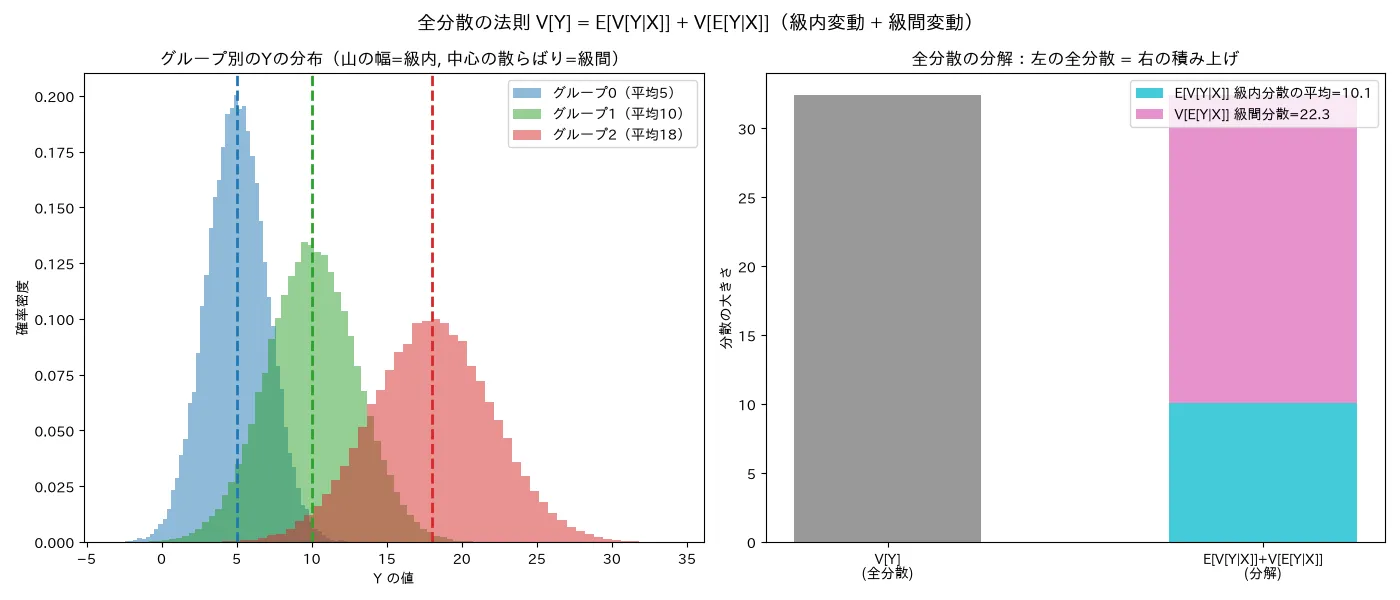
simulations/doujibunpu_shuhen_zenbunsan.py
何を示すか :全分散の法則 V [ Y ] = E [ V [ Y ∣ X ] ] + V [ E [ Y ∣ X ] ] V[Y]=E[V[Y\mid X]]+V[E[Y\mid X]] V [ Y ] = E [ V [ Y ∣ X ]] + V [ E [ Y ∣ X ]] X X X Y Y Y 結論(seed=0, n=30万, 3グループ) :全分散 実測=32.384 = 級内分散の平均=10.094 (E [ V [ Y ∣ X ] ] E[V[Y\mid X]] E [ V [ Y ∣ X ]] 22.290 (V [ E [ Y ∣ X ] ] V[E[Y\mid X]] V [ E [ Y ∣ X ]] η 2 = \eta^2= η 2 = = 0.688 =0.688 = 0.688 X X X Y Y Y
関連ノート
条件付き確率・独立性・全確率の定理 (条件付き確率・独立性 ── P ( B ∣ A ) = P ( A ∩ B ) / P ( A ) P(B\mid A)=P(A\cap B)/P(A) P ( B ∣ A ) = P ( A ∩ B ) / P ( A ) p ( y ∣ x ) = p ( x , y ) / p X ( x ) p(y\mid x)=p(x,y)/p_X(x) p ( y ∣ x ) = p ( x , y ) / p X ( x ) p ( x , y ) = p X p Y p(x,y)=p_Xp_Y p ( x , y ) = p X p Y 期待値・分散の性質(線形性・和の分散・共分散) (期待値・分散の性質 ── E [ X + Y ] E[X+Y] E [ X + Y ] ∑ y p ( x , y ) = p X \sum_y p(x,y)=p_X ∑ y p ( x , y ) = p X E [ X Y ] E[XY] E [ X Y ] 確率変数(離散・連続)と期待値・分散 (確率変数・PMF/PDF ── 1変数の確率分布・期待値・分散。同時分布はその2変数版。PDFの値は確率でない(確率は面積/体積)の注意もここ。後方リンク)2変数の記述(散布図・共分散・相関係数)── 相関≠因果/rは直線関係しか測れない/外れ値1点で激変 (2変数の記述統計・共分散・相関 ── 標本の散布図・s x y s_{xy} s x y r r r 確率変数の変換・モーメント母関数・積率 (確率変数の変換・モーメント母関数 ── 同時分布から Z = X + Y Z=X+Y Z = X + Y 大数の法則(弱法則・強法則) (大数の法則 ── 独立同分布和の挙動。前方リンク)中心極限定理(CLT) (中心極限定理 ── 独立和が正規に近づく。前方リンク)