← 統計検定テキスト 一覧
📊 対象級:準1級 ・ 1級 | 重要度:A(頻出)
確率変数の変換・モーメント母関数・積率 ── 変数変換公式/MGFで積率を生む/独立和はMGFの積
要点(BLUF)
連続の変数変換公式 :Z = g ( X ) Z=g(X) Z = g ( X ) g g g f Z ( z ) = f X ( g − 1 ( z ) ) ∣ d g − 1 d z ∣ \boxed{f_Z(z)=f_X\big(g^{-1}(z)\big)\left|\dfrac{d g^{-1}}{dz}\right|} f Z ( z ) = f X ( g − 1 ( z ) ) d z d g − 1 CDF法 (F Z ( z ) = P ( g ( X ) ≤ z ) F_Z(z)=P(g(X)\le z) F Z ( z ) = P ( g ( X ) ≤ z ) z z z ヤコビアン になる。積率(モーメント) :原点まわり μ k ′ = E [ X k ] \mu_k'=E[X^k] μ k ′ = E [ X k ] μ k = E [ ( X − μ ) k ] \mu_k=E[(X-\mu)^k] μ k = E [( X − μ ) k ] 1次=平均、2次中心=分散、3次(標準化)=歪度、4次(標準化)=尖度 。モーメント母関数 MGF(本トピックの主役) M X ( t ) = E [ e t X ] \boxed{M_X(t)=E[e^{tX}]} M X ( t ) = E [ e tX ] 積率を生む M X ( k ) ( 0 ) = E [ X k ] \boxed{M_X^{(k)}(0)=E[X^k]} M X ( k ) ( 0 ) = E [ X k ] e t X e^{tX} e tX 独立和はMGFの積 M X + Y ( t ) = M X ( t ) M Y ( t ) \boxed{M_{X+Y}(t)=M_X(t)M_Y(t)} M X + Y ( t ) = M X ( t ) M Y ( t ) 期待値・分散の性質(線形性・和の分散・共分散) の独立和の母関数版)。性質③一意性 (MGFが一致すれば分布が一致=分布の「指紋」)。正規のMGF M ( t ) = e μ t + σ 2 t 2 / 2 M(t)=e^{\mu t+\sigma^2 t^2/2} M ( t ) = e μ t + σ 2 t 2 /2 e t 2 / 2 e^{t^2/2} e t 2 /2 中心極限定理(CLT) の証明の核。特性関数 φ X ( t ) = E [ e i t X ] \varphi_X(t)=E[e^{itX}] φ X ( t ) = E [ e i tX ]
本文
1. 確率変数の変換とは
確率変数 X X X g g g Z = g ( X ) Z=g(X) Z = g ( X )
離散:Z = g ( X ) Z=g(X) Z = g ( X )
Z = g ( X ) Z=g(X) Z = g ( X ) z z z g ( x ) = z g(x)=z g ( x ) = z x x x
P ( Z = z ) = ∑ x : g ( x ) = z P ( X = x ) . P(Z=z)=\sum_{x:\ g(x)=z} P(X=x). P ( Z = z ) = x : g ( x ) = z ∑ P ( X = x ) . 要するに「同じ z z z x x x 」。例:X X X 1 ∼ 6 1\sim6 1 ∼ 6 1 / 6 1/6 1/6 Z = ( X − 3.5 ) 2 Z=(X-3.5)^2 Z = ( X − 3.5 ) 2 Z = 6.25 Z=6.25 Z = 6.25 X ∈ { 1 , 6 } X\in\{1,6\} X ∈ { 1 , 6 } P ( Z = 6.25 ) = 1 6 + 1 6 = 1 3 P(Z=6.25)=\frac16+\frac16=\frac13 P ( Z = 6.25 ) = 6 1 + 6 1 = 3 1 g g g x x x
連続:変数変換公式(本トピックの最重要公式の1つ)
X X X f X f_X f X Z = g ( X ) Z=g(X) Z = g ( X ) f Z f_Z f Z g g g 単調(1対1)で微分可能 、逆関数 x = g − 1 ( z ) x=g^{-1}(z) x = g − 1 ( z )
f Z ( z ) = f X ( g − 1 ( z ) ) ∣ d g − 1 ( z ) d z ∣ \boxed{\,f_Z(z)=f_X\big(g^{-1}(z)\big)\left|\frac{d\,g^{-1}(z)}{dz}\right|\,} f Z ( z ) = f X ( g − 1 ( z ) ) d z d g − 1 ( z ) 要するに「元の密度の高さ f X ( g − 1 ( z ) ) f_X(g^{-1}(z)) f X ( g − 1 ( z )) ∣ d g − 1 / d z ∣ |dg^{-1}/dz| ∣ d g − 1 / d z ∣ 」。導出(CDF法)と絶対値の意味は「数式の直観的意味」で完全に示す。
なぜ補正項が要るか(直観):密度は「単位幅あたりの確率」。変換で横軸が2倍に引き伸ばされる場所では、同じ確率が2倍の幅にばらまかれるので密度は 1 / 2 1/2 1/2 ∣ d g − 1 / d z ∣ |dg^{-1}/dz| ∣ d g − 1 / d z ∣
多変数への一般化(ヤコビアン)── 概要
( X 1 , X 2 ) → ( Z 1 , Z 2 ) (X_1,X_2)\to(Z_1,Z_2) ( X 1 , X 2 ) → ( Z 1 , Z 2 ) ∣ d g − 1 / d z ∣ |dg^{-1}/dz| ∣ d g − 1 / d z ∣ ヤコビアン行列式の絶対値 に置き換わる:
f Z 1 , Z 2 ( z 1 , z 2 ) = f X 1 , X 2 ( x 1 , x 2 ) ∣ det J ∣ , J = ( ∂ x 1 ∂ z 1 ∂ x 1 ∂ z 2 ∂ x 2 ∂ z 1 ∂ x 2 ∂ z 2 ) . f_{Z_1,Z_2}(z_1,z_2)=f_{X_1,X_2}\big(x_1,x_2\big)\,\big|\det J\big|,\qquad
J=\begin{pmatrix}\dfrac{\partial x_1}{\partial z_1}&\dfrac{\partial x_1}{\partial z_2}\\[6pt]\dfrac{\partial x_2}{\partial z_1}&\dfrac{\partial x_2}{\partial z_2}\end{pmatrix}. f Z 1 , Z 2 ( z 1 , z 2 ) = f X 1 , X 2 ( x 1 , x 2 ) det J , J = ∂ z 1 ∂ x 1 ∂ z 1 ∂ x 2 ∂ z 2 ∂ x 1 ∂ z 2 ∂ x 2 . 要するに「∣ det J ∣ |\det J| ∣ det J ∣ X / ( X + Y ) X/(X+Y) X / ( X + Y )
和の分布(畳み込み convolution)
独立な X , Y X,Y X , Y 和 Z = X + Y Z=X+Y Z = X + Y 同時分布・周辺分布・条件付き分布 )から導かれる畳み込み積分 :
f X + Y ( z ) = ∫ − ∞ ∞ f X ( x ) f Y ( z − x ) d x \boxed{\,f_{X+Y}(z)=\int_{-\infty}^{\infty} f_X(x)\,f_Y(z-x)\,dx\,} f X + Y ( z ) = ∫ − ∞ ∞ f X ( x ) f Y ( z − x ) d x 要するに「和が z z z ( x , z − x ) (x,\ z-x) ( x , z − x ) x x x 」。離散版は P ( X + Y = z ) = ∑ x P ( X = x ) P ( Y = z − x ) P(X+Y=z)=\sum_x P(X=x)P(Y=z-x) P ( X + Y = z ) = ∑ x P ( X = x ) P ( Y = z − x ) f X ( x ) f Y ( z − x ) f_X(x)f_Y(z-x) f X ( x ) f Y ( z − x ) z z z ただの掛け算 に変わる(そこがMGFの嬉しさ)。
2. 積率(モーメント)
分布の形を数値で要約する量。k k k と k k k
定義 意味 原点まわり k k k μ k ′ \mu_k' μ k ′ E [ X k ] E[X^k] E [ X k ] X k X^k X k 中心 k k k μ k \mu_k μ k E [ ( X − μ ) k ] E[(X-\mu)^k] E [( X − μ ) k ] 平均 μ \mu μ k k k
主要な対応(準1級・2級で頻出の表 ):
次数 量 式 表すもの 1次(原点) 平均 μ = E [ X ] \mu=E[X] μ = E [ X ] 中心位置 2次(中心) 分散 σ 2 = E [ ( X − μ ) 2 ] \sigma^2=E[(X-\mu)^2] σ 2 = E [( X − μ ) 2 ] 散らばり 3次(標準化) 歪度 skewness E [ ( X − μ ) 3 ] σ 3 \dfrac{E[(X-\mu)^3]}{\sigma^3} σ 3 E [( X − μ ) 3 ] 左右の非対称(正=右に裾) 4次(標準化) 尖度 kurtosis E [ ( X − μ ) 4 ] σ 4 \dfrac{E[(X-\mu)^4]}{\sigma^4} σ 4 E [( X − μ ) 4 ] − 3 -3 − 3 山の尖り・裾の重さ
要するに「1次で位置、2次で広がり、3次で左右の偏り、4次で尖り 」を測る。標準化(σ k \sigma^k σ k − 3 -3 − 3 μ k ′ \mu_k' μ k ′ μ k \mu_k μ k 変換を一気にやってくれるのが次のMGF 。
3. モーメント母関数 MGF(本トピックの主役)
定義
M X ( t ) = E [ e t X ] { ∑ x e t x p ( x ) ( 離散 ) ∫ − ∞ ∞ e t x f ( x ) d x ( 連続 ) \boxed{\,M_X(t)=E\big[e^{tX}\big]\,}\qquad
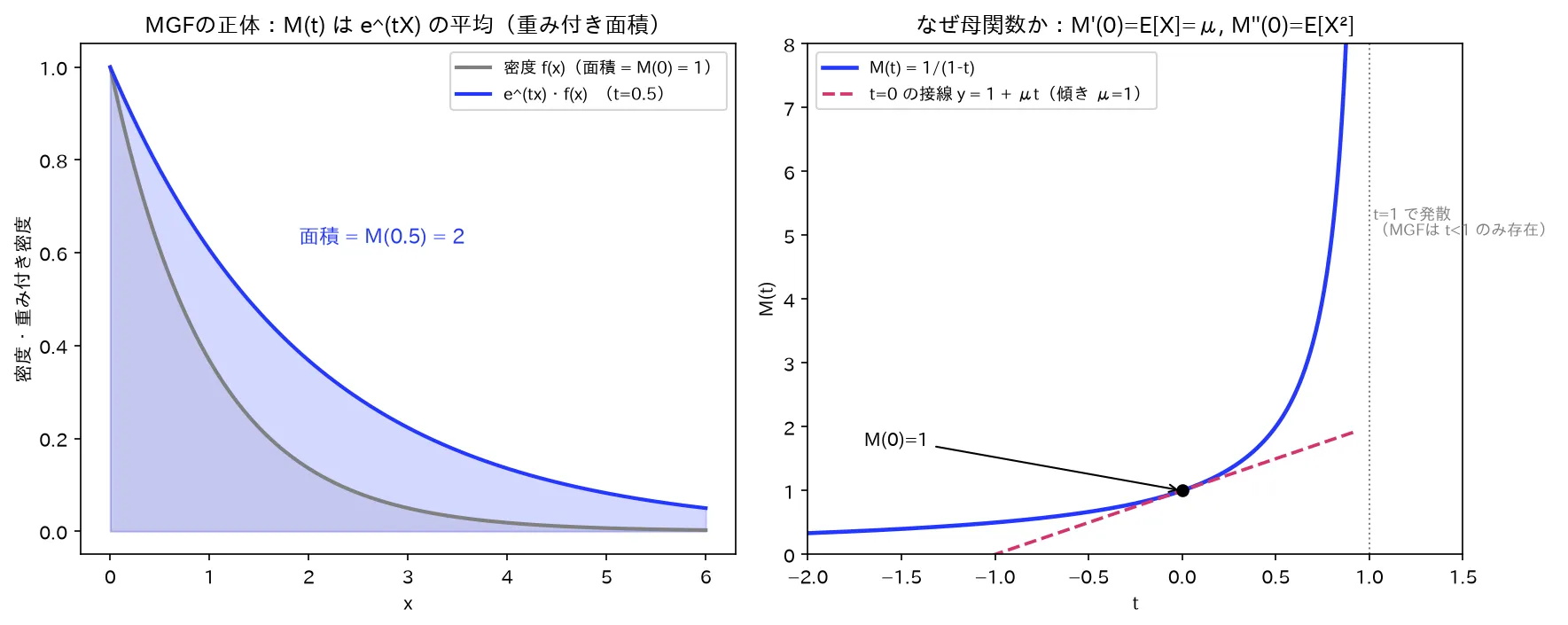
\begin{cases}\displaystyle\sum_x e^{tx}p(x) & (\text{離散})\\[4pt]\displaystyle\int_{-\infty}^{\infty} e^{tx}f(x)\,dx & (\text{連続})\end{cases} M X ( t ) = E [ e tX ] ⎩ ⎨ ⎧ x ∑ e t x p ( x ) ∫ − ∞ ∞ e t x f ( x ) d x ( 離散 ) ( 連続 ) t = 0 t=0 t = 0 t t t M X ( 0 ) = E [ e 0 ] = E [ 1 ] = 1 M_X(0)=E[e^0]=E[1]=1 M X ( 0 ) = E [ e 0 ] = E [ 1 ] = 1 分布の全情報を1つの関数 M X ( t ) M_X(t) M X ( t ) 」。なぜ「母関数(生成関数)」かは次の性質①が答え。
左=MGFの正体(e^(tx)で重み付けした密度の面積)、右=t=0で微分すると積率が出る(M’(0)=μ、M”(0)=E[X²]、t=1で発散=MGFはt<1のみ)。図は simulations/moment_bokansu_keijou.py で生成。
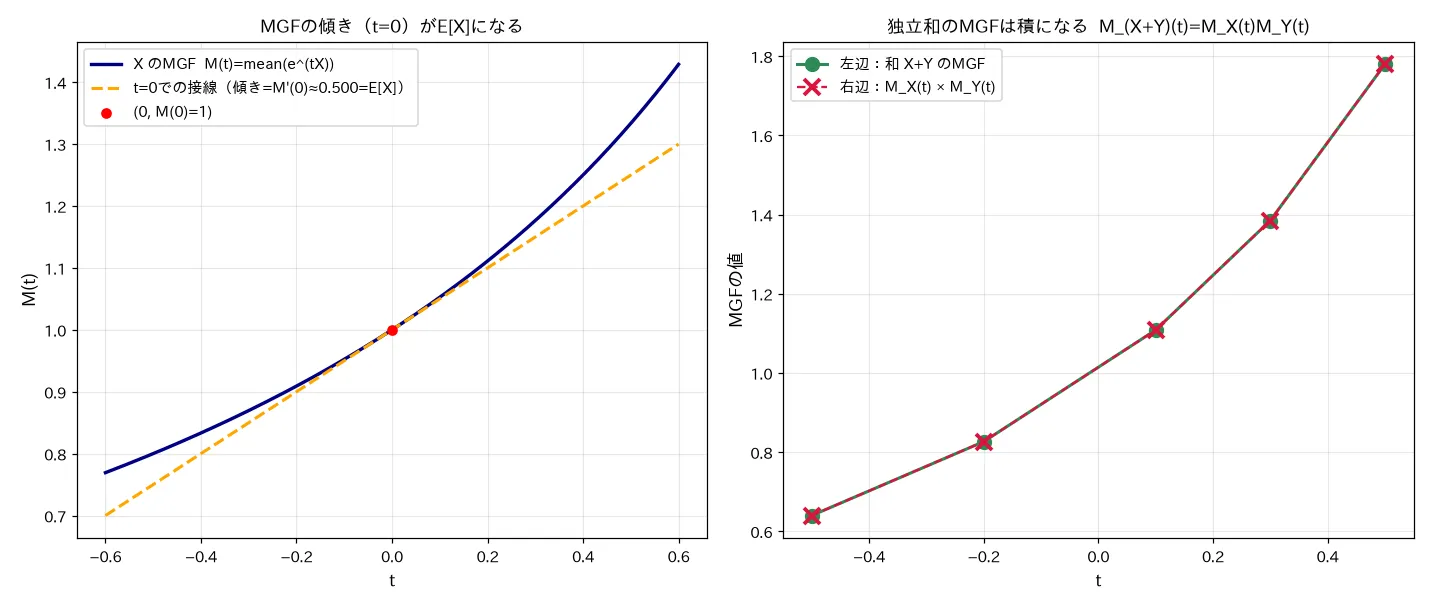
性質①:積率を生成する(MGFの名前の由来)
M X ( k ) ( 0 ) = E [ X k ] ( k 回微分して t = 0 を代入 ) \boxed{\,M_X^{(k)}(0)=E[X^k]\,}\quad(\text{$k$ 回微分して $t=0$ を代入}) M X ( k ) ( 0 ) = E [ X k ] ( k 回微分して t = 0 を代入 ) 要するに「MGFを k k k t = 0 t=0 t = 0 k k k E [ X k ] E[X^k] E [ X k ] 」。だから平均は M ′ ( 0 ) M'(0) M ′ ( 0 ) M ′ ′ ( 0 ) − ( M ′ ( 0 ) ) 2 M''(0)-\big(M'(0)\big)^2 M ′′ ( 0 ) − ( M ′ ( 0 ) ) 2 なぜ微分で積率が出るのか の導出は「数式の直観的意味」で完全に示す(テイラー展開が鍵)。
性質②:独立和はMGFの積(⑥の母関数版・最重要の実用性)
X , Y X,Y X , Y 独立 なら
M X + Y ( t ) = M X ( t ) M Y ( t ) \boxed{\,M_{X+Y}(t)=M_X(t)\,M_Y(t)\,} M X + Y ( t ) = M X ( t ) M Y ( t ) 要するに「独立な確率変数を足すと、MGFは掛け算になる 」。畳み込み積分(和の分布)は計算が重いが、MGFの世界ではただの掛け算 に変わる。これが ⑥ 期待値・分散の性質(線形性・和の分散・共分散) の「独立和の分散=分散の和」を、分布まるごと扱えるよう一般化した母関数版。導出は「数式の直観的意味」へ。
性質③:一意性(分布の「指紋」)
MGFが(t = 0 t=0 t = 0 その2つの分布は同一 。要するに「MGFは分布を一意に決める指紋 」。だから「和のMGFを計算したら、それが正規のMGFの形だった→和は正規分布だ」と逆向きに分布を同定 できる(性質②と組み合わせて使うのが定番)。
MGFと積率・独立和の関係(図)
ここだけ図にすると流れが見える。
flowchart LR
X["確率変数 X"] --> M["MGF M(t)=E(e^tX)"]
M -->|"k回微分してt=0"| MOM["積率 E(X^k)<br/>1次=平均 2次=分散"]
M -->|"独立な和 X+Y"| PROD["MGFの積<br/>M_X(t)·M_Y(t)"]
PROD -->|"一意性で分布を同定"| DIST["和の分布が決まる"]
「X X X
主要分布のMGF一覧(準1級は導出練習が要る)
分布 パラメータ MGF M X ( t ) M_X(t) M X ( t ) 平均(M ′ ( 0 ) M'(0) M ′ ( 0 ) 分散 ベルヌーイ p p p 1 − p + p e t 1-p+pe^{t} 1 − p + p e t p p p p ( 1 − p ) p(1-p) p ( 1 − p ) 二項 B i n ( n , p ) \mathrm{Bin}(n,p) Bin ( n , p ) n , p n,p n , p ( 1 − p + p e t ) n (1-p+pe^{t})^{n} ( 1 − p + p e t ) n n p np n p n p ( 1 − p ) np(1-p) n p ( 1 − p ) ポアソン P o ( λ ) \mathrm{Po}(\lambda) Po ( λ ) λ \lambda λ e λ ( e t − 1 ) e^{\lambda(e^{t}-1)} e λ ( e t − 1 ) λ \lambda λ λ \lambda λ 指数 E x p ( λ ) \mathrm{Exp}(\lambda) Exp ( λ ) λ \lambda λ λ λ − t ( t < λ ) \dfrac{\lambda}{\lambda-t}\ (t<\lambda) λ − t λ ( t < λ ) 1 / λ 1/\lambda 1/ λ 1 / λ 2 1/\lambda^2 1/ λ 2 正規 N ( μ , σ 2 ) N(\mu,\sigma^2) N ( μ , σ 2 ) μ , σ 2 \mu,\sigma^2 μ , σ 2 exp ( μ t + σ 2 t 2 2 ) \exp\!\Big(\mu t+\dfrac{\sigma^2 t^2}{2}\Big) exp ( μ t + 2 σ 2 t 2 ) μ \mu μ σ 2 \sigma^2 σ 2
二項のMGFがベルヌーイのMGFの n n n 独立ベルヌーイ和=二項 (性質②)そのもの。正規のMGFだけ「数式の直観的意味」で導出する。
MGFと関係の深い母関数:確率母関数 G X ( s ) = E [ s X ] G_X(s)=E[s^X] G X ( s ) = E [ s X ] s = e t s=e^t s = e t キュムラント母関数 K X ( t ) = log M X ( t ) K_X(t)=\log M_X(t) K X ( t ) = log M X ( t ) K ( t ) = μ t + σ 2 t 2 / 2 K(t)=\mu t+\sigma^2 t^2/2 K ( t ) = μ t + σ 2 t 2 /2
4. 中心極限定理への布石(MGFが効く最大の場面)
標準化した独立同分布和
Z n = 1 n ∑ i = 1 n X i − μ σ Z_n=\frac{1}{\sqrt n}\sum_{i=1}^{n}\frac{X_i-\mu}{\sigma} Z n = n 1 i = 1 ∑ n σ X i − μ のMGFが、n → ∞ n\to\infty n → ∞ e t 2 / 2 e^{t^2/2} e t 2 /2 標準正規のMGF )に収束する。一意性(性質③)から Z n Z_n Z n 中心極限定理(CLT) の証明の核。要するに「MGFの積(性質②)とテイラー展開で、和の分布が正規になることを示せる 」。深入りは ⑩ で行う。
5. 特性関数(1級の道具・簡潔に)
φ X ( t ) = E [ e i t X ] ( i = − 1 ) \varphi_X(t)=E\big[e^{itX}\big]\quad(i=\sqrt{-1}) φ X ( t ) = E [ e i tX ] ( i = − 1 ) MGF の t t t i t it i t ∣ e i t X ∣ = 1 |e^{itX}|=1 ∣ e i tX ∣ = 1 期待値が必ず収束し、どんな分布でも常に存在する (MGFはコーシー分布など裾の重い分布では存在しないことがある)。性質はMGFとほぼ並行(一意性・独立和は積・微分で積率)。要するに「MGFが存在しない分布でも使える、より頑健な指紋 」。1級の数理で道具として出るが、過去問で前面に出た実績は限定的(要最新確認)。本ノートでは存在のみ押さえる。
具体例
例1(変数変換) :X ∼ U ( 0 , 1 ) X\sim U(0,1) X ∼ U ( 0 , 1 ) Z = − ln X Z=-\ln X Z = − ln X g ( x ) = − ln x g(x)=-\ln x g ( x ) = − ln x x = g − 1 ( z ) = e − z x=g^{-1}(z)=e^{-z} x = g − 1 ( z ) = e − z d g − 1 / d z = − e − z dg^{-1}/dz=-e^{-z} d g − 1 / d z = − e − z f X = 1 f_X=1 f X = 1 0 < x < 1 0<x<1 0 < x < 1
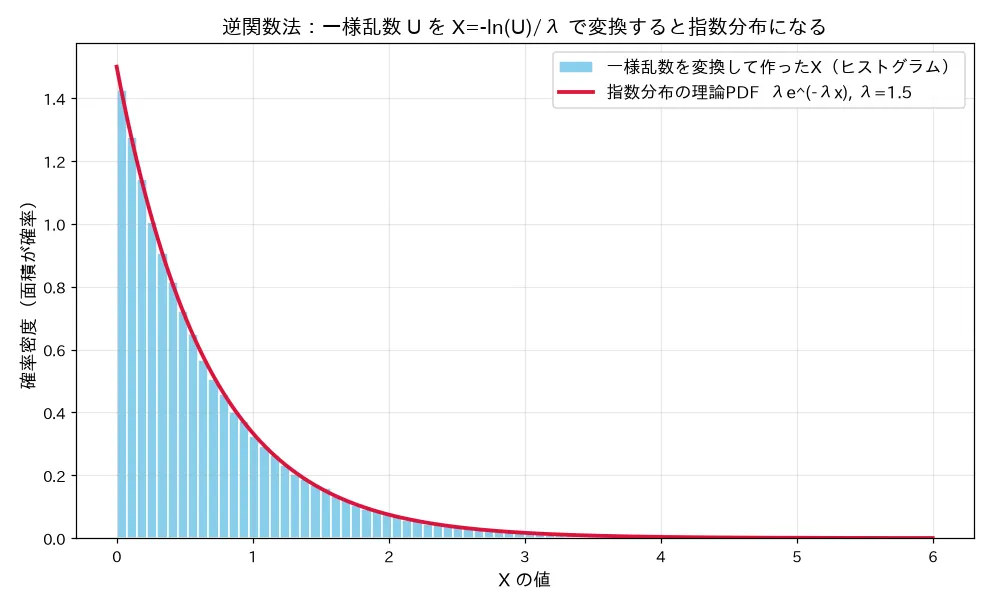
f Z ( z ) = f X ( e − z ) ∣ − e − z ∣ = 1 ⋅ e − z = e − z ( z > 0 ) . f_Z(z)=f_X(e^{-z})\,|-e^{-z}|=1\cdot e^{-z}=e^{-z}\quad(z>0). f Z ( z ) = f X ( e − z ) ∣ − e − z ∣ = 1 ⋅ e − z = e − z ( z > 0 ) . レート1の指数分布 。これが逆関数法(一様乱数から指数乱数を作る)の原理=シミュ①。
例2(MGFで積率) :指数 E x p ( λ ) \mathrm{Exp}(\lambda) Exp ( λ ) M ( t ) = λ λ − t = λ ( λ − t ) − 1 M(t)=\dfrac{\lambda}{\lambda-t}=\lambda(\lambda-t)^{-1} M ( t ) = λ − t λ = λ ( λ − t ) − 1 M ′ ( t ) = λ ( λ − t ) − 2 M'(t)=\lambda(\lambda-t)^{-2} M ′ ( t ) = λ ( λ − t ) − 2 M ′ ( 0 ) = λ ⋅ λ − 2 = 1 / λ = E [ X ] M'(0)=\lambda\cdot\lambda^{-2}=1/\lambda=E[X] M ′ ( 0 ) = λ ⋅ λ − 2 = 1/ λ = E [ X ] M ′ ′ ( t ) = 2 λ ( λ − t ) − 3 M''(t)=2\lambda(\lambda-t)^{-3} M ′′ ( t ) = 2 λ ( λ − t ) − 3 M ′ ′ ( 0 ) = 2 λ ⋅ λ − 3 = 2 / λ 2 = E [ X 2 ] M''(0)=2\lambda\cdot\lambda^{-3}=2/\lambda^2=E[X^2] M ′′ ( 0 ) = 2 λ ⋅ λ − 3 = 2/ λ 2 = E [ X 2 ] V [ X ] = E [ X 2 ] − ( E [ X ] ) 2 = 2 λ 2 − 1 λ 2 = 1 λ 2 V[X]=E[X^2]-(E[X])^2=\dfrac{2}{\lambda^2}-\dfrac{1}{\lambda^2}=\dfrac{1}{\lambda^2} V [ X ] = E [ X 2 ] − ( E [ X ] ) 2 = λ 2 2 − λ 2 1 = λ 2 1
例3(独立和のMGFの積→分布同定) :独立 X ∼ N ( μ 1 , σ 1 2 ) , Y ∼ N ( μ 2 , σ 2 2 ) X\sim N(\mu_1,\sigma_1^2),\ Y\sim N(\mu_2,\sigma_2^2) X ∼ N ( μ 1 , σ 1 2 ) , Y ∼ N ( μ 2 , σ 2 2 )
M X + Y ( t ) = M X ( t ) M Y ( t ) = e μ 1 t + σ 1 2 t 2 / 2 ⋅ e μ 2 t + σ 2 2 t 2 / 2 = e ( μ 1 + μ 2 ) t + ( σ 1 2 + σ 2 2 ) t 2 / 2 . M_{X+Y}(t)=M_X(t)M_Y(t)=e^{\mu_1 t+\sigma_1^2 t^2/2}\cdot e^{\mu_2 t+\sigma_2^2 t^2/2}=e^{(\mu_1+\mu_2)t+(\sigma_1^2+\sigma_2^2)t^2/2}. M X + Y ( t ) = M X ( t ) M Y ( t ) = e μ 1 t + σ 1 2 t 2 /2 ⋅ e μ 2 t + σ 2 2 t 2 /2 = e ( μ 1 + μ 2 ) t + ( σ 1 2 + σ 2 2 ) t 2 /2 . これは N ( μ 1 + μ 2 , σ 1 2 + σ 2 2 ) N(\mu_1+\mu_2,\ \sigma_1^2+\sigma_2^2) N ( μ 1 + μ 2 , σ 1 2 + σ 2 2 ) X + Y ∼ N ( μ 1 + μ 2 , σ 1 2 + σ 2 2 ) X+Y\sim N(\mu_1+\mu_2,\sigma_1^2+\sigma_2^2) X + Y ∼ N ( μ 1 + μ 2 , σ 1 2 + σ 2 2 )
試験での問われ方(級ごとの差)
2級 :積率の素朴な扱いまで。平均(1次)・分散(2次中心)・歪度(3次標準化)・尖度(4次標準化)の定義と計算 は範囲(標本歪度・標本尖度の計算も出る)。MGF・確率母関数・変数変換公式・畳み込み・特性関数は2級範囲外 (モーメントという語と歪度/尖度どまり)。準1級(主) :モーメント母関数(第2章「確率分布と母関数」) =定義・M ( k ) ( 0 ) = E [ X k ] M^{(k)}(0)=E[X^k] M ( k ) ( 0 ) = E [ X k ] 確率母関数 、分布の特性値(第3章) =歪度・尖度、変数変換(第4章) =単調変換の公式・ヤコビアン(指数→指数、一様→指数、正規の2乗→カイ二乗など)。畳み込みで和の分布。公式ワークブック2〜4章が直撃。1級(統計数理) :上記をすべて記述式で。変数変換・ヤコビアンで多変数の分布を導く (ベータ・ガンマ・t t t F F F 畳み込みで和の分布 、MGFの性質(a X + b aX+b a X + b = e b t M X ( a t ) =e^{bt}M_X(at) = e b t M X ( a t ) 特性関数 (白本=現代数理統計学では前面に出るが、本試験で前面に出た実績は乏しいとの指摘あり)、漸近理論(CLT)でMGF/特性関数。※出題範囲は改訂されうる。受験前に公式最新の出題範囲表で要最新確認 (準1級は公式ワークブック準拠が直近で確認した版、1級数理範囲表も要確認)。
数式の直観的意味
変数変換公式の完全導出(CDF法・なぜ絶対値が付くか)
連続変数の分布を直接いじるのは難しいので、いったんCDF(累積分布関数)に上げてから微分で密度に戻す のがCDF法。Z = g ( X ) Z=g(X) Z = g ( X ) F Z ( z ) = P ( Z ≤ z ) = P ( g ( X ) ≤ z ) F_Z(z)=P(Z\le z)=P(g(X)\le z) F Z ( z ) = P ( Z ≤ z ) = P ( g ( X ) ≤ z ) g g g X X X
(a) g g g :g ( X ) ≤ z ⟺ X ≤ g − 1 ( z ) g(X)\le z \iff X\le g^{-1}(z) g ( X ) ≤ z ⟺ X ≤ g − 1 ( z )
F Z ( z ) = P ( X ≤ g − 1 ( z ) ) = F X ( g − 1 ( z ) ) . F_Z(z)=P\big(X\le g^{-1}(z)\big)=F_X\big(g^{-1}(z)\big). F Z ( z ) = P ( X ≤ g − 1 ( z ) ) = F X ( g − 1 ( z ) ) . 両辺を z z z
f Z ( z ) = d d z F X ( g − 1 ( z ) ) = f X ( g − 1 ( z ) ) ⋅ d g − 1 ( z ) d z . f_Z(z)=\frac{d}{dz}F_X\big(g^{-1}(z)\big)=f_X\big(g^{-1}(z)\big)\cdot\frac{d\,g^{-1}(z)}{dz}. f Z ( z ) = d z d F X ( g − 1 ( z ) ) = f X ( g − 1 ( z ) ) ⋅ d z d g − 1 ( z ) . 増加なら g − 1 g^{-1} g − 1 d g − 1 d z > 0 \dfrac{dg^{-1}}{dz}>0 d z d g − 1 > 0 d g − 1 d z = ∣ d g − 1 d z ∣ \dfrac{dg^{-1}}{dz}=\left|\dfrac{dg^{-1}}{dz}\right| d z d g − 1 = d z d g − 1
(b) g g g :g ( X ) ≤ z ⟺ X ≥ g − 1 ( z ) g(X)\le z \iff X\ge g^{-1}(z) g ( X ) ≤ z ⟺ X ≥ g − 1 ( z ) 不等号が逆転 )。よって
F Z ( z ) = P ( X ≥ g − 1 ( z ) ) = 1 − F X ( g − 1 ( z ) ) . F_Z(z)=P\big(X\ge g^{-1}(z)\big)=1-F_X\big(g^{-1}(z)\big). F Z ( z ) = P ( X ≥ g − 1 ( z ) ) = 1 − F X ( g − 1 ( z ) ) . 微分すると先頭の 1 1 1
f Z ( z ) = − f X ( g − 1 ( z ) ) ⋅ d g − 1 ( z ) d z . f_Z(z)=-f_X\big(g^{-1}(z)\big)\cdot\frac{d\,g^{-1}(z)}{dz}. f Z ( z ) = − f X ( g − 1 ( z ) ) ⋅ d z d g − 1 ( z ) . 減少なら g − 1 g^{-1} g − 1 d g − 1 d z < 0 \dfrac{dg^{-1}}{dz}<0 d z d g − 1 < 0 − - − 正 。これは − d g − 1 d z = ∣ d g − 1 d z ∣ -\dfrac{dg^{-1}}{dz}=\left|\dfrac{dg^{-1}}{dz}\right| − d z d g − 1 = d z d g − 1
(a)(b)を1本にまとめる :どちらの場合も右辺は「f X ( g − 1 ( z ) ) f_X(g^{-1}(z)) f X ( g − 1 ( z )) ∣ d g − 1 d z ∣ \left|\dfrac{dg^{-1}}{dz}\right| d z d g − 1
f Z ( z ) = f X ( g − 1 ( z ) ) ∣ d g − 1 ( z ) d z ∣ . ■ \boxed{\,f_Z(z)=f_X\big(g^{-1}(z)\big)\left|\frac{d\,g^{-1}(z)}{dz}\right|\,}.\qquad\blacksquare f Z ( z ) = f X ( g − 1 ( z ) ) d z d g − 1 ( z ) . ■ なぜ絶対値か(要点) :密度は必ず非負。増加変換ならそのまま正、減少変換だと微分が負になるが、CDFの引き算(1 − F X 1-F_X 1 − F X 向きによらず “伸縮率の大きさ” だけが効く 。それを一手で書いたのが絶対値。∣ d g − 1 / d z ∣ |dg^{-1}/dz| ∣ d g − 1 / d z ∣ z z z x x x
畳み込み公式の導出(同時分布→和が z z z
独立な X , Y X,Y X , Y Z = X + Y Z=X+Y Z = X + Y 同時分布・周辺分布・条件付き分布 )から書く。独立なので同時密度は積 f X ( x ) f Y ( y ) f_X(x)f_Y(y) f X ( x ) f Y ( y )
F Z ( z ) = P ( X + Y ≤ z ) = ∬ x + y ≤ z f X ( x ) f Y ( y ) d x d y . F_Z(z)=P(X+Y\le z)=\iint_{x+y\le z} f_X(x)f_Y(y)\,dx\,dy. F Z ( z ) = P ( X + Y ≤ z ) = ∬ x + y ≤ z f X ( x ) f Y ( y ) d x d y . 内側を y y y x x x y ≤ z − x y\le z-x y ≤ z − x
F Z ( z ) = ∫ − ∞ ∞ f X ( x ) ( ∫ − ∞ z − x f Y ( y ) d y ) d x = ∫ − ∞ ∞ f X ( x ) F Y ( z − x ) d x . F_Z(z)=\int_{-\infty}^{\infty} f_X(x)\left(\int_{-\infty}^{z-x} f_Y(y)\,dy\right)dx=\int_{-\infty}^{\infty} f_X(x)\,F_Y(z-x)\,dx. F Z ( z ) = ∫ − ∞ ∞ f X ( x ) ( ∫ − ∞ z − x f Y ( y ) d y ) d x = ∫ − ∞ ∞ f X ( x ) F Y ( z − x ) d x . z z z F Y ( z − x ) F_Y(z-x) F Y ( z − x ) f Y ( z − x ) f_Y(z-x) f Y ( z − x ) z z z
f Z ( z ) = d d z F Z ( z ) = ∫ − ∞ ∞ f X ( x ) f Y ( z − x ) d x . ■ f_Z(z)=\frac{d}{dz}F_Z(z)=\int_{-\infty}^{\infty} f_X(x)\,f_Y(z-x)\,dx.\qquad\blacksquare f Z ( z ) = d z d F Z ( z ) = ∫ − ∞ ∞ f X ( x ) f Y ( z − x ) d x . ■ 要するに「X = x X=x X = x Y = z − x Y=z-x Y = z − x f X ( x ) f Y ( z − x ) f_X(x)f_Y(z-x) f X ( x ) f Y ( z − x ) x x x x + y = z x+y=z x + y = z
なぜ M ( k ) ( 0 ) = E [ X k ] M^{(k)}(0)=E[X^k] M ( k ) ( 0 ) = E [ X k ]
指数関数のテイラー展開 e u = ∑ k = 0 ∞ u k k ! e^{u}=\sum_{k=0}^{\infty}\dfrac{u^k}{k!} e u = ∑ k = 0 ∞ k ! u k u = t X u=tX u = tX
e t X = ∑ k = 0 ∞ ( t X ) k k ! = ∑ k = 0 ∞ t k k ! X k . e^{tX}=\sum_{k=0}^{\infty}\frac{(tX)^k}{k!}=\sum_{k=0}^{\infty}\frac{t^k}{k!}X^k. e tX = k = 0 ∑ ∞ k ! ( tX ) k = k = 0 ∑ ∞ k ! t k X k . 両辺の期待値を取る。期待値は線形(⑥ 期待値・分散の性質(線形性・和の分散・共分散) )なので和と t k / k ! t^k/k! t k / k ! X X X
M X ( t ) = E [ e t X ] = ∑ k = 0 ∞ t k k ! E [ X k ] = 1 + E [ X ] t + E [ X 2 ] 2 ! t 2 + E [ X 3 ] 3 ! t 3 + ⋯ M_X(t)=E\big[e^{tX}\big]=\sum_{k=0}^{\infty}\frac{t^k}{k!}E[X^k]=1+E[X]\,t+\frac{E[X^2]}{2!}t^2+\frac{E[X^3]}{3!}t^3+\cdots M X ( t ) = E [ e tX ] = k = 0 ∑ ∞ k ! t k E [ X k ] = 1 + E [ X ] t + 2 ! E [ X 2 ] t 2 + 3 ! E [ X 3 ] t 3 + ⋯ ここがMGFの本質 :M X ( t ) M_X(t) M X ( t ) t k t^k t k E [ X k ] k ! \dfrac{E[X^k]}{k!} k ! E [ X k ] MGFは積率を係数として畳み込んだ母関数 。テイラー展開の一般項の係数は「k k k t = 0 t=0 t = 0 k ! k! k ! k k k t = 0 t=0 t = 0 E [ X k ] k ! ⋅ k ! = E [ X k ] \dfrac{E[X^k]}{k!}\cdot k!=E[X^k] k ! E [ X k ] ⋅ k ! = E [ X k ]
M X ( k ) ( 0 ) = E [ X k ] . ■ M_X^{(k)}(0)=E[X^k].\qquad\blacksquare M X ( k ) ( 0 ) = E [ X k ] . ■ 具体的に1回・2回やると:M ′ ( t ) = E [ X ] + E [ X 2 ] t + ⋯ M'(t)=E[X]+E[X^2]t+\cdots M ′ ( t ) = E [ X ] + E [ X 2 ] t + ⋯ M ′ ( 0 ) = E [ X ] M'(0)=E[X] M ′ ( 0 ) = E [ X ] M ′ ′ ( t ) = E [ X 2 ] + E [ X 3 ] t + ⋯ M''(t)=E[X^2]+E[X^3]t+\cdots M ′′ ( t ) = E [ X 2 ] + E [ X 3 ] t + ⋯ M ′ ′ ( 0 ) = E [ X 2 ] M''(0)=E[X^2] M ′′ ( 0 ) = E [ X 2 ] 微分のたびに展開が1つずつ繰り上がり、t = 0 t=0 t = 0 から積率が順に出る。
なぜ独立和のMGFは積か(独立がここで効く・完全導出)
定義に和を入れ、指数法則 e a + b = e a e b e^{a+b}=e^a e^b e a + b = e a e b
M X + Y ( t ) = E [ e t ( X + Y ) ] = E [ e t X e t Y ] . M_{X+Y}(t)=E\big[e^{t(X+Y)}\big]=E\big[e^{tX}\,e^{tY}\big]. M X + Y ( t ) = E [ e t ( X + Y ) ] = E [ e tX e t Y ] . X , Y X,Y X , Y 独立 なら e t X e^{tX} e tX e t Y e^{tY} e t Y 期待値・分散の性質(線形性・和の分散・共分散) の E [ X Y ] = E [ X ] E [ Y ] E[XY]=E[X]E[Y] E [ X Y ] = E [ X ] E [ Y ]
M X + Y ( t ) = E [ e t X ] E [ e t Y ] = M X ( t ) M Y ( t ) . ■ M_{X+Y}(t)=E\big[e^{tX}\big]\,E\big[e^{tY}\big]=M_X(t)\,M_Y(t).\qquad\blacksquare M X + Y ( t ) = E [ e tX ] E [ e t Y ] = M X ( t ) M Y ( t ) . ■ 要するに「独立だから指数の積の期待値を分離できる 」。畳み込み積分の代わりに掛け算で和の分布を扱える理由がこれ。一般化すると独立和 ∑ X i \sum X_i ∑ X i ∏ M X i ( t ) \prod M_{X_i}(t) ∏ M X i ( t ) ( M X ( t ) ) n \big(M_X(t)\big)^n ( M X ( t ) ) n n n n
正規分布のMGF e μ t + σ 2 t 2 / 2 e^{\mu t+\sigma^2 t^2/2} e μ t + σ 2 t 2 /2
まず標準正規 Z ∼ N ( 0 , 1 ) Z\sim N(0,1) Z ∼ N ( 0 , 1 ) f ( z ) = 1 2 π e − z 2 / 2 f(z)=\dfrac{1}{\sqrt{2\pi}}e^{-z^2/2} f ( z ) = 2 π 1 e − z 2 /2
M Z ( t ) = E [ e t Z ] = ∫ − ∞ ∞ 1 2 π e t z e − z 2 / 2 d z = ∫ − ∞ ∞ 1 2 π e − 1 2 ( z 2 − 2 t z ) d z . M_Z(t)=E[e^{tZ}]=\int_{-\infty}^{\infty}\frac{1}{\sqrt{2\pi}}e^{tz}e^{-z^2/2}\,dz=\int_{-\infty}^{\infty}\frac{1}{\sqrt{2\pi}}e^{-\frac12(z^2-2tz)}\,dz. M Z ( t ) = E [ e tZ ] = ∫ − ∞ ∞ 2 π 1 e t z e − z 2 /2 d z = ∫ − ∞ ∞ 2 π 1 e − 2 1 ( z 2 − 2 t z ) d z . 指数の中を平方完成 :z 2 − 2 t z = ( z − t ) 2 − t 2 z^2-2tz=(z-t)^2-t^2 z 2 − 2 t z = ( z − t ) 2 − t 2 − t 2 -t^2 − t 2 z z z
M Z ( t ) = e t 2 / 2 ∫ − ∞ ∞ 1 2 π e − 1 2 ( z − t ) 2 d z . M_Z(t)=e^{t^2/2}\int_{-\infty}^{\infty}\frac{1}{\sqrt{2\pi}}e^{-\frac12(z-t)^2}\,dz. M Z ( t ) = e t 2 /2 ∫ − ∞ ∞ 2 π 1 e − 2 1 ( z − t ) 2 d z . 残った積分は「平均 t t t
M Z ( t ) = e t 2 / 2 . \boxed{\,M_Z(t)=e^{t^2/2}\,}. M Z ( t ) = e t 2 /2 . 一般の X = μ + σ Z ∼ N ( μ , σ 2 ) X=\mu+\sigma Z\sim N(\mu,\sigma^2) X = μ + σ Z ∼ N ( μ , σ 2 ) 変換のMGF規則 M a X + b ( t ) = E [ e t ( a X + b ) ] = e b t E [ e ( a t ) X ] = e b t M X ( a t ) M_{aX+b}(t)=E[e^{t(aX+b)}]=e^{bt}E[e^{(at)X}]=e^{bt}M_X(at) M a X + b ( t ) = E [ e t ( a X + b ) ] = e b t E [ e ( a t ) X ] = e b t M X ( a t ) X = σ Z + μ X=\sigma Z+\mu X = σ Z + μ a = σ , b = μ a=\sigma,\ b=\mu a = σ , b = μ
M X ( t ) = e μ t M Z ( σ t ) = e μ t e ( σ t ) 2 / 2 = exp ( μ t + σ 2 t 2 2 ) . ■ M_X(t)=e^{\mu t}M_Z(\sigma t)=e^{\mu t}e^{(\sigma t)^2/2}=\exp\!\Big(\mu t+\frac{\sigma^2 t^2}{2}\Big).\qquad\blacksquare M X ( t ) = e μ t M Z ( σ t ) = e μ t e ( σ t ) 2 /2 = exp ( μ t + 2 σ 2 t 2 ) . ■ 要するに「平方完成で指数を正規密度の形に戻すと、余った e t 2 / 2 e^{t^2/2} e t 2 /2 」。標準化和のMGFがこの e t 2 / 2 e^{t^2/2} e t 2 /2
⚠️ 引っかけポイント・頻出論点・級ごとの差
変数変換で絶対値を落とす :減少変換だと微分が負になる。∣ d g − 1 / d z ∣ |dg^{-1}/dz| ∣ d g − 1 / d z ∣ 密度は必ず非負 を最後の検算に。ヤコビアンは「逆向き ∂ x / ∂ z \partial x/\partial z ∂ x / ∂ z :公式の補正項は d g − 1 d z = d x d z \dfrac{dg^{-1}}{dz}=\dfrac{dx}{dz} d z d g − 1 = d z d x 元の変数を新しい変数で微分 )。d z d x \dfrac{dz}{dx} d x d z ∣ d x d z ∣ = 1 / ∣ d z d x ∣ \big|\frac{dx}{dz}\big|=1/\big|\frac{dz}{dx}\big| d z d x = 1/ d x d z 変換後の定義域(サポート)を必ず書く :例1で z > 0 z>0 z > 0 x x x z z z MGFの一意性は「存在するとき」だけ :MGFが存在しない分布(コーシーなど裾が重い)では一意性の議論に使えない。そこは特性関数の出番。「MGFはどんな分布でも存在」は誤り。独立和の積は“独立”が前提 :M X + Y = M X M Y M_{X+Y}=M_XM_Y M X + Y = M X M Y 2 C o v 2\mathrm{Cov} 2 Cov M ( k ) ( 0 ) = E [ X k ] M^{(k)}(0)=E[X^k] M ( k ) ( 0 ) = E [ X k ] E [ X k ] E[X^k] E [ X k ] M ′ ′ ( 0 ) − ( M ′ ( 0 ) ) 2 M''(0)-(M'(0))^2 M ′′ ( 0 ) − ( M ′ ( 0 ) ) 2 M ′ ′ ( 0 ) M''(0) M ′′ ( 0 ) log M \log M log M 歪度/尖度の符号と基準 :歪度 正=右に裾が長い(平均>中央値の傾向)。尖度は流儀が2つ(E [ ( X − μ ) 4 ] / σ 4 E[(X-\mu)^4]/\sigma^4 E [( X − μ ) 4 ] / σ 4 − 3 -3 − 3 MGFと確率母関数・特性関数の関係 :確率母関数 G ( s ) = E [ s X ] G(s)=E[s^X] G ( s ) = E [ s X ] s = e t s=e^t s = e t t → i t t\to it t → i t 級差 :2級=積率・歪度・尖度の定義と計算どまり(MGFは範囲外) 。準1級=MGFの定義・微分で積率・独立和の積・主要分布のMGF導出・変数変換とヤコビアン・畳み込み 。1級=多変数のヤコビアンで分布構成(ベータ/ガンマ/t/F)・特性関数・CLTの母関数証明 。同じ「積率」でも、2級は数値計算、準1級以上は母関数で生成・操作するところまで深さが上がる。
よくある疑問
Q. 変数変換公式の絶対値はどこから来るのですか? なぜ密度が負にならないのですか?
A. CDF(累積分布関数)から導くと自然に出ます。Z = g ( X ) Z=g(X) Z = g ( X ) g g g
g g g 増加 なら g ( X ) ≤ z ⟺ X ≤ g − 1 ( z ) g(X)\le z \iff X\le g^{-1}(z) g ( X ) ≤ z ⟺ X ≤ g − 1 ( z ) F Z ( z ) = F X ( g − 1 ( z ) ) F_Z(z)=F_X(g^{-1}(z)) F Z ( z ) = F X ( g − 1 ( z )) f Z ( z ) = f X ( g − 1 ( z ) ) ⋅ d g − 1 d z f_Z(z)=f_X(g^{-1}(z))\cdot\frac{dg^{-1}}{dz} f Z ( z ) = f X ( g − 1 ( z )) ⋅ d z d g − 1 g g g 減少 なら g ( X ) ≤ z ⟺ X ≥ g − 1 ( z ) g(X)\le z \iff X\ge g^{-1}(z) g ( X ) ≤ z ⟺ X ≥ g − 1 ( z ) 不等号が逆転 するので F Z ( z ) = 1 − F X ( g − 1 ( z ) ) F_Z(z)=1-F_X(g^{-1}(z)) F Z ( z ) = 1 − F X ( g − 1 ( z )) f Z ( z ) = − f X ( g − 1 ( z ) ) ⋅ d g − 1 d z f_Z(z)=-f_X(g^{-1}(z))\cdot\frac{dg^{-1}}{dz} f Z ( z ) = − f X ( g − 1 ( z )) ⋅ d z d g − 1
どちらの場合も結局「f X ( g − 1 ( z ) ) f_X(g^{-1}(z)) f X ( g − 1 ( z ))
Q. MGFを2回微分した M ′ ′ ( 0 ) M''(0) M ′′ ( 0 )
A. 違います。M ′ ′ ( 0 ) = E [ X 2 ] M''(0)=E[X^2] M ′′ ( 0 ) = E [ X 2 ] V [ X ] = E [ X 2 ] − ( E [ X ] ) 2 = M ′ ′ ( 0 ) − ( M ′ ( 0 ) ) 2 V[X]=E[X^2]-(E[X])^2=M''(0)-(M'(0))^2 V [ X ] = E [ X 2 ] − ( E [ X ] ) 2 = M ′′ ( 0 ) − ( M ′ ( 0 ) ) 2 E [ X k ] E[X^k] E [ X k ]
Q. 「独立和はMGFの積」は、従属でも成り立ちますか?
A. 成り立ちません。M X + Y = M X M Y M_{X+Y}=M_XM_Y M X + Y = M X M Y E [ e t X e t Y ] = E [ e t X ] E [ e t Y ] E[e^{tX}e^{tY}]=E[e^{tX}]E[e^{tY}] E [ e tX e t Y ] = E [ e tX ] E [ e t Y ]
Q. MGFと特性関数、確率母関数はどう違うのですか?
A. どれも「分布の指紋」で、E [ 指数っぽいもの ] E[\text{指数っぽいもの}] E [ 指数っぽいもの ] E [ e t X ] E[e^{tX}] E [ e tX ] E [ e i t X ] E[e^{itX}] E [ e i tX ] 必ず存在 します。確率母関数 E [ s X ] E[s^X] E [ s X ] s = e t s=e^t s = e t
Q. 結局どの級で何を覚えればいいですか?
A. 2級 は積率・歪度・尖度の計算まで(MGFは出ません)。準1級 はMGFの定義・微分で積率・独立和の積・主要分布のMGF導出・変数変換とヤコビアン・畳み込み。1級 はさらに多変数のヤコビアンで分布を作る・特性関数・中心極限定理のMGF証明、まで深掘りします。同じ「積率」でも級が上がると、数値計算から母関数での生成・操作へと深さが増します。
まとめ
変数変換公式 f Z ( z ) = f X ( g − 1 ( z ) ) ∣ d g − 1 / d z ∣ f_Z(z)=f_X(g^{-1}(z))|dg^{-1}/dz| f Z ( z ) = f X ( g − 1 ( z )) ∣ d g − 1 / d z ∣ 積率 :1次=平均、2次=分散、3次=歪度、4次=尖度。MGF M X ( t ) = E [ e t X ] M_X(t)=E[e^{tX}] M X ( t ) = E [ e tX ] M ( k ) ( 0 ) = E [ X k ] M^{(k)}(0)=E[X^k] M ( k ) ( 0 ) = E [ X k ] M X + Y = M X M Y M_{X+Y}=M_XM_Y M X + Y = M X M Y 特性関数 はMGFが存在しないときの頑健な代役(1級)。
対応するシミュレーション
simulations/henkan_gyakukansuuhou_shisuu.py
何を示すか :一様乱数 U ∼ U ( 0 , 1 ) U\sim U(0,1) U ∼ U ( 0 , 1 ) X = − ln ( U ) / λ X=-\ln(U)/\lambda X = − ln ( U ) / λ X X X λ e − λ x \lambda e^{-\lambda x} λ e − λ x 変数変換公式 f Z ( z ) = f X ( g − 1 ( z ) ) ∣ d g − 1 / d z ∣ f_Z(z)=f_X(g^{-1}(z))|dg^{-1}/dz| f Z ( z ) = f X ( g − 1 ( z )) ∣ d g − 1 / d z ∣ であり、逆関数法(一様乱数から任意分布を生成)の原理そのもの。結論(seed=0, λ=1.5, n=20万) :ヒストグラム(青)が理論PDF λ e − λ x \lambda e^{-\lambda x} λ e − λ x 0.6652 (理論 1 / λ 1/\lambda 1/ λ 0.4436 (理論 1 / λ 2 1/\lambda^2 1/ λ 2 g ( u ) = − ln u / λ g(u)=-\ln u/\lambda g ( u ) = − ln u / λ e − λ x e^{-\lambda x} e − λ x λ e − λ x \lambda e^{-\lambda x} λ e − λ x f U = 1 f_U=1 f U = 1
simulations/moment_bokansuu_seishitsu.py
何を示すか :(1) MGF M ( t ) = m e a n ( e t X ) M(t)=\mathrm{mean}(e^{tX}) M ( t ) = mean ( e tX ) t = 0 t=0 t = 0 M ′ ( 0 ) ≈ E [ X ] M'(0)\approx E[X] M ′ ( 0 ) ≈ E [ X ] M ′ ′ ( 0 ) ≈ E [ X 2 ] M''(0)\approx E[X^2] M ′′ ( 0 ) ≈ E [ X 2 ] M ( k ) ( 0 ) = E [ X k ] M^{(k)}(0)=E[X^k] M ( k ) ( 0 ) = E [ X k ] M X + Y ( t ) = M X ( t ) M Y ( t ) M_{X+Y}(t)=M_X(t)M_Y(t) M X + Y ( t ) = M X ( t ) M Y ( t ) t t t 結論(seed=0, λ=2.0, n=50万) :(1) M ( 0 ) = M(0)= M ( 0 ) = 1.0000 (定義どおり)、M ′ ( 0 ) = M'(0)= M ′ ( 0 ) = 0.4997 (理論 1 / λ 1/\lambda 1/ λ E [ X ] E[X] E [ X ] M ′ ′ ( 0 ) = M''(0)= M ′′ ( 0 ) = 0.5000 (理論 2 / λ 2 2/\lambda^2 2/ λ 2 E [ X 2 ] E[X^2] E [ X 2 ] t = 0 t=0 t = 0 E [ X ] E[X] E [ X ] t t t t = − 0.5 t=-0.5 t = − 0.5 t = 0.5 t=0.5 t = 0.5
関連ノート
確率変数(離散・連続)と期待値・分散 (確率変数・期待値・分散・積率 E [ X k ] E[X^k] E [ X k ] 期待値・分散の性質(線形性・和の分散・共分散) (期待値・分散の性質・独立和の分散 ── MGFの2性質の母集団版の出発点。期待値の線形性(MGFのテイラー展開で使用)と独立なら E [ X Y ] = E [ X ] E [ Y ] E[XY]=E[X]E[Y] E [ X Y ] = E [ X ] E [ Y ] 同時分布・周辺分布・条件付き分布 (同時分布・周辺分布・条件付き分布 ── 畳み込み f X + Y = ∫ f X ( x ) f Y ( z − x ) d x f_{X+Y}=\int f_X(x)f_Y(z-x)dx f X + Y = ∫ f X ( x ) f Y ( z − x ) d x f X f Y f_Xf_Y f X f Y x + y = z x+y=z x + y = z 2変数の記述(散布図・共分散・相関係数)── 相関≠因果/rは直線関係しか測れない/外れ値1点で激変 (2変数の記述・共分散 ── 和の挙動の標本版。後方リンク)ベルヌーイ分布・二項分布 (二項分布 ── そのMGF ( 1 − p + p e t ) n (1-p+pe^t)^n ( 1 − p + p e t ) n n n n 大数の法則(弱法則・強法則) (大数の法則 ── 独立同分布和の挙動。前方リンク・次トピック)中心極限定理(CLT) (中心極限定理 ── 標準化和のMGFが標準正規のMGF e t 2 / 2 e^{t^2/2} e t 2 /2
※Phase 3 の各分布(ポアソン・指数・正規・ガンマ・ベータなど)のMGF・変数変換が頻出だが、それらのファイル名(nikou_bunpu 以外)は未確定のため、ここではテキスト言及に留める。多変数のヤコビアン(PCA・多変量正規)はPhase 6 で再登場するが、該当ノート名が未確定のためテキスト言及に留める。