← 統計検定テキスト 一覧
📊 対象級:2級 | 重要度:A(頻出)
ベルヌーイ分布・二項分布
要点(BLUF)
ベルヌーイ分布 :成功/失敗の1回試行。X ∈ { 0 , 1 } X\in\{0,1\} X ∈ { 0 , 1 } P ( X = 1 ) = p P(X=1)=p P ( X = 1 ) = p E [ X ] = p E[X]=p E [ X ] = p V [ X ] = p ( 1 − p ) V[X]=p(1-p) V [ X ] = p ( 1 − p ) X 2 = X X^2=X X 2 = X 確率変数(離散・連続)と期待値・分散 既出)。MGF M X ( t ) = 1 − p + p e t M_X(t)=1-p+pe^t M X ( t ) = 1 − p + p e t 二項分布の構成単位 。二項分布 :成功確率 p p p n n n X ∼ B i n ( n , p ) X\sim\mathrm{Bin}(n,p) X ∼ Bin ( n , p ) P ( X = k ) = n C k p k ( 1 − p ) n − k ( k = 0 , 1 , … , n ) . \boxed{\,P(X=k)={}_nC_k\,p^k(1-p)^{n-k}\,}\quad(k=0,1,\dots,n). P ( X = k ) = n C k p k ( 1 − p ) n − k ( k = 0 , 1 , … , n ) . n C k {}_nC_k n C k n n n k k k 場所の選び方 (場合の数・順列・組合せ )、p k ( 1 − p ) n − k p^k(1-p)^{n-k} p k ( 1 − p ) n − k 条件付き確率・独立性・全確率の定理 )。総和1は二項定理 ∑ k n C k p k ( 1 − p ) n − k = ( p + ( 1 − p ) ) n = 1 \sum_k {}_nC_k p^k(1-p)^{n-k}=(p+(1-p))^n=1 ∑ k n C k p k ( 1 − p ) n − k = ( p + ( 1 − p ) ) n = 1 E [ X ] = n p E[X]=np E [ X ] = n p V [ X ] = n p ( 1 − p ) V[X]=np(1-p) V [ X ] = n p ( 1 − p ) 独立ベルヌーイ n n n X = ∑ X i X=\sum X_i X = ∑ X i 期待値・分散の性質(線形性・和の分散・共分散) の独立和、共分散0)、(2) MGF M X ( t ) = ( 1 − p + p e t ) n M_X(t)=(1-p+pe^t)^n M X ( t ) = ( 1 − p + p e t ) n 確率変数の変換・モーメント母関数・積率 、ベルヌーイMGFの n n n 再生性(加法性) :独立な B i n ( n 1 , p ) + B i n ( n 2 , p ) = B i n ( n 1 + n 2 , p ) \mathrm{Bin}(n_1,p)+\mathrm{Bin}(n_2,p)=\mathrm{Bin}(n_1+n_2,p) Bin ( n 1 , p ) + Bin ( n 2 , p ) = Bin ( n 1 + n 2 , p ) p p p 2方向の近似 :n n n p p p 正規近似 N ( n p , n p ( 1 − p ) ) N(np,np(1-p)) N ( n p , n p ( 1 − p )) 中心極限定理(CLT) のド・モアブル=ラプラス)。n n n p p p λ = n p \lambda=np λ = n p ポアソン近似 (ポアソン分布 へ)。
本文
まず日常のイメージ:10回のくじ引き
当たる確率が p = 0.3 p=0.3 p = 0.3 10回引いて、当たりが何回出るか を考えます。0回かもしれないし、3回かもしれない。この「当たりの回数」がしたがうのが二項分布 B i n ( 10 , 0.3 ) \mathrm{Bin}(10,\,0.3) Bin ( 10 , 0.3 )
平均すると何回当たる? → n p = 10 × 0.3 = 3 np=10\times0.3=3 n p = 10 × 0.3 = 3 期待値 n p np n p )。
ちょうど3回当たる確率は? → 10 C 3 ( 0.3 ) 3 ( 0.7 ) 7 {}_{10}C_3\,(0.3)^3(0.7)^7 10 C 3 ( 0.3 ) 3 ( 0.7 ) 7 PMFの式 )。
なぜ 10 C 3 {}_{10}C_3 10 C 3 当たる回の組合せが 10 C 3 {}_{10}C_3 10 C 3 あり、どれも同じ確率 ( 0.3 ) 3 ( 0.7 ) 7 (0.3)^3(0.7)^7 ( 0.3 ) 3 ( 0.7 ) 7
製品の良品率、コインの表裏、アンケートの「はい/いいえ」── 「2通りのことを何回もくりかえして、片方が何回出るか」はすべて二項分布 です。
1. ベルヌーイ分布 ── 二項分布の構成単位
ベルヌーイ試行 =結果が「成功(1)か失敗(0)」の2通りしかない1回の試行(コインの表裏、製品の良品/不良)。その結果を表す確率変数 X X X ベルヌーイ分布 B e r n o u l l i ( p ) \mathrm{Bernoulli}(p) Bernoulli ( p )
P ( X = 1 ) = p , P ( X = 0 ) = 1 − p ( 0 ≤ p ≤ 1 ) . P(X=1)=p,\qquad P(X=0)=1-p\qquad(0\le p\le1). P ( X = 1 ) = p , P ( X = 0 ) = 1 − p ( 0 ≤ p ≤ 1 ) . PMFを1本の式で書くと P ( X = x ) = p x ( 1 − p ) 1 − x P(X=x)=p^x(1-p)^{1-x} P ( X = x ) = p x ( 1 − p ) 1 − x x ∈ { 0 , 1 } x\in\{0,1\} x ∈ { 0 , 1 } x = 1 x=1 x = 1 p p p x = 0 x=0 x = 0 1 − p 1-p 1 − p
期待値・分散 (確率変数(離散・連続)と期待値・分散 で導出済み、ここで再確認):
E [ X ] = 0 ⋅ ( 1 − p ) + 1 ⋅ p = p , V [ X ] = E [ X 2 ] − ( E [ X ] ) 2 . E[X]=0\cdot(1-p)+1\cdot p=p,\qquad
V[X]=E[X^2]-(E[X])^2. E [ X ] = 0 ⋅ ( 1 − p ) + 1 ⋅ p = p , V [ X ] = E [ X 2 ] − ( E [ X ] ) 2 . ここで X ∈ { 0 , 1 } X\in\{0,1\} X ∈ { 0 , 1 } X 2 = X X^2=X X 2 = X 0 2 = 0 , 1 2 = 1 0^2=0,\ 1^2=1 0 2 = 0 , 1 2 = 1 E [ X 2 ] = E [ X ] = p E[X^2]=E[X]=p E [ X 2 ] = E [ X ] = p
V [ X ] = p − p 2 = p ( 1 − p ) . V[X]=p-p^2=p(1-p). V [ X ] = p − p 2 = p ( 1 − p ) . 要するに**「ベルヌーイの分散は p ( 1 − p ) p(1-p) p ( 1 − p ) p = 0.5 p=0.5 p = 0.5 0.25 0.25 0.25 p = 0 p=0 p = 0 1 1 1 0 0 0
MGF (確率変数の変換・モーメント母関数・積率 ):
M X ( t ) = E [ e t X ] = e t ⋅ 0 ( 1 − p ) + e t ⋅ 1 p = ( 1 − p ) + p e t . M_X(t)=E[e^{tX}]=e^{t\cdot0}(1-p)+e^{t\cdot1}p=(1-p)+pe^t. M X ( t ) = E [ e tX ] = e t ⋅ 0 ( 1 − p ) + e t ⋅ 1 p = ( 1 − p ) + p e t . このMGFが二項分布のMGFの土台 (後述、独立和でこれの n n n
要するにベルヌーイ分布は「1回ぶんの成功/失敗」 。これを n n n
flowchart LR
A["ベルヌーイ分布<br/>1回の成功/失敗<br/>E=p, V=p(1-p)"] -->|"独立にn回足す"| B["二項分布<br/>n回中の成功回数<br/>E=np, V=np(1-p)"]
B -->|"n大・p中庸"| C["正規分布<br/>N(np, np(1-p))"]
B -->|"n大・p小"| D["ポアソン分布<br/>平均λ=np"]
この図の流れ(ベルヌーイ → 足して二項 → 大きくすると正規かポアソン)が、確率分布の章ぜんたいの骨組みです。
2. 二項分布 ── ベルヌーイを n n n
二項分布 B i n ( n , p ) \mathrm{Bin}(n,p) Bin ( n , p ) p p p 独立に n n n くりかえしたときの成功回数 X X X n n n p p p
PMF(確率質量関数):
P ( X = k ) = n C k p k ( 1 − p ) n − k ( k = 0 , 1 , … , n ) . P(X=k)={}_nC_k\,p^k(1-p)^{n-k}\qquad(k=0,1,\dots,n). P ( X = k ) = n C k p k ( 1 − p ) n − k ( k = 0 , 1 , … , n ) . 式の意味(3パーツに分解) :
パーツ 意味 p k p^k p k 成功 k k k ( 1 − p ) n − k (1-p)^{n-k} ( 1 − p ) n − k 失敗 n − k n-k n − k n C k {}_nC_k n C k n n n どの k k k の場所の選び方(場合の数・順列・組合せ )
たとえば n = 3 , k = 2 n=3,k=2 n = 3 , k = 2 3 C 2 = 3 {}_3C_2=3 3 C 2 = 3 p 2 ( 1 − p ) p^2(1-p) p 2 ( 1 − p ) 3 C 2 p 2 ( 1 − p ) {}_3C_2\,p^2(1-p) 3 C 2 p 2 ( 1 − p ) × \times ×
総和が1になること (確率分布の定義の確認、二項定理):
∑ k = 0 n n C k p k ( 1 − p ) n − k = ( p + ( 1 − p ) ) n = 1 n = 1. \sum_{k=0}^{n}{}_nC_k\,p^k(1-p)^{n-k}=\big(p+(1-p)\big)^n=1^n=1. k = 0 ∑ n n C k p k ( 1 − p ) n − k = ( p + ( 1 − p ) ) n = 1 n = 1. 二項定理 ( a + b ) n = ∑ k n C k a k b n − k (a+b)^n=\sum_k {}_nC_k a^k b^{n-k} ( a + b ) n = ∑ k n C k a k b n − k a = p , b = 1 − p a=p,\ b=1-p a = p , b = 1 − p 二項定理がそのまま「確率の総和=1」を保証する (場合の数・順列・組合せ の二項展開)。これが「二項分布」という名前の由来。
3. 期待値 E [ X ] = n p E[X]=np E [ X ] = n p V [ X ] = n p ( 1 − p ) V[X]=np(1-p) V [ X ] = n p ( 1 − p )
本トピックの数理の山。Phase 2 で用意した2つの道具(独立和・MGF)で同じ答えに到達する。数式が苦手なら結論「E = n p , V = n p ( 1 − p ) E=np,\ V=np(1-p) E = n p , V = n p ( 1 − p )
i i i X i ∈ { 0 , 1 } X_i\in\{0,1\} X i ∈ { 0 , 1 }
X = X 1 + X 2 + ⋯ + X n = ∑ i = 1 n X i , X i ∼ i.i.d. B e r n o u l l i ( p ) . X=X_1+X_2+\cdots+X_n=\sum_{i=1}^n X_i,\qquad X_i\overset{\text{i.i.d.}}{\sim}\mathrm{Bernoulli}(p). X = X 1 + X 2 + ⋯ + X n = i = 1 ∑ n X i , X i ∼ i.i.d. Bernoulli ( p ) . 期待値 は線形性(独立不要、常に成立、期待値・分散の性質(線形性・和の分散・共分散) ):
E [ X ] = ∑ i = 1 n E [ X i ] = ∑ i = 1 n p = n p . E[X]=\sum_{i=1}^n E[X_i]=\sum_{i=1}^n p=np. E [ X ] = i = 1 ∑ n E [ X i ] = i = 1 ∑ n p = n p . 分散 は独立和(共分散0)なので加法的:
V [ X ] = ∑ i = 1 n V [ X i ] = ∑ i = 1 n p ( 1 − p ) = n p ( 1 − p ) . V[X]=\sum_{i=1}^n V[X_i]=\sum_{i=1}^n p(1-p)=np(1-p). V [ X ] = i = 1 ∑ n V [ X i ] = i = 1 ∑ n p ( 1 − p ) = n p ( 1 − p ) . X i X_i X i C o v ( X i , X j ) = 0 \mathrm{Cov}(X_i,X_j)=0 Cov ( X i , X j ) = 0 期待値・分散の性質(線形性・和の分散・共分散) の「分散の加法性は無相関が必要」)。要するに**「ベルヌーイ1個の E = p , V = p ( 1 − p ) E=p,V=p(1-p) E = p , V = p ( 1 − p ) n n n
ポイント:期待値の足し算は独立でなくても成り立ちますが、分散の足し算は独立(無相関)のときだけ です。二項分布は「各試行が独立」が前提なので分散がきれいに n p ( 1 − p ) np(1-p) n p ( 1 − p ) 期待値・分散の性質(線形性・和の分散・共分散) )。
独立和のMGFは各MGFの積(確率変数の変換・モーメント母関数・積率 )。X = ∑ X i X=\sum X_i X = ∑ X i X i X_i X i 1 − p + p e t 1-p+pe^t 1 − p + p e t
M X ( t ) = ∏ i = 1 n M X i ( t ) = ( 1 − p + p e t ) n . M_X(t)=\prod_{i=1}^n M_{X_i}(t)=\big(1-p+pe^t\big)^n. M X ( t ) = i = 1 ∏ n M X i ( t ) = ( 1 − p + p e t ) n . 要するに**「二項のMGF=ベルヌーイMGFの n n n M ′ ( 0 ) = E [ X ] , M ′ ′ ( 0 ) = E [ X 2 ] M'(0)=E[X],\ M''(0)=E[X^2] M ′ ( 0 ) = E [ X ] , M ′′ ( 0 ) = E [ X 2 ]
1階微分(合成関数、d d t ( 1 − p + p e t ) = p e t \frac{d}{dt}(1-p+pe^t)=pe^t d t d ( 1 − p + p e t ) = p e t
M X ′ ( t ) = n ( 1 − p + p e t ) n − 1 ⋅ p e t . M_X'(t)=n(1-p+pe^t)^{n-1}\cdot pe^t. M X ′ ( t ) = n ( 1 − p + p e t ) n − 1 ⋅ p e t . t = 0 t=0 t = 0 e 0 = 1 , 1 − p + p = 1 e^0=1,\ 1-p+p=1 e 0 = 1 , 1 − p + p = 1
E [ X ] = M X ′ ( 0 ) = n ⋅ 1 n − 1 ⋅ p = n p . ✓ E[X]=M_X'(0)=n\cdot1^{n-1}\cdot p=np.\ \checkmark E [ X ] = M X ′ ( 0 ) = n ⋅ 1 n − 1 ⋅ p = n p . ✓ 2階微分(積の微分):
M X ′ ′ ( t ) = n ( n − 1 ) ( 1 − p + p e t ) n − 2 ( p e t ) 2 + n ( 1 − p + p e t ) n − 1 p e t . M_X''(t)=n(n-1)(1-p+pe^t)^{n-2}(pe^t)^2+n(1-p+pe^t)^{n-1}pe^t. M X ′′ ( t ) = n ( n − 1 ) ( 1 − p + p e t ) n − 2 ( p e t ) 2 + n ( 1 − p + p e t ) n − 1 p e t . t = 0 t=0 t = 0
E [ X 2 ] = M X ′ ′ ( 0 ) = n ( n − 1 ) p 2 + n p . E[X^2]=M_X''(0)=n(n-1)p^2+np. E [ X 2 ] = M X ′′ ( 0 ) = n ( n − 1 ) p 2 + n p . よって
V [ X ] = E [ X 2 ] − ( E [ X ] ) 2 = n ( n − 1 ) p 2 + n p − ( n p ) 2 = n p − n p 2 = n p ( 1 − p ) . ✓ V[X]=E[X^2]-(E[X])^2=n(n-1)p^2+np-(np)^2
=np-np^2=np(1-p).\ \checkmark V [ X ] = E [ X 2 ] − ( E [ X ] ) 2 = n ( n − 1 ) p 2 + n p − ( n p ) 2 = n p − n p 2 = n p ( 1 − p ) . ✓ (n ( n − 1 ) p 2 − n 2 p 2 = − n p 2 n(n-1)p^2-n^2p^2=-np^2 n ( n − 1 ) p 2 − n 2 p 2 = − n p 2 + n p +np + n p n p − n p 2 = n p ( 1 − p ) np-np^2=np(1-p) n p − n p 2 = n p ( 1 − p )
2つの道筋が一致 することで、「独立和」「MGF」という Phase 2 の2系統の道具が同じ結論に至ることを確認できる。導出(1)は速く、導出(2)は高次モーメント(歪度・尖度)も同じ枠組みで出せる汎用性がある。
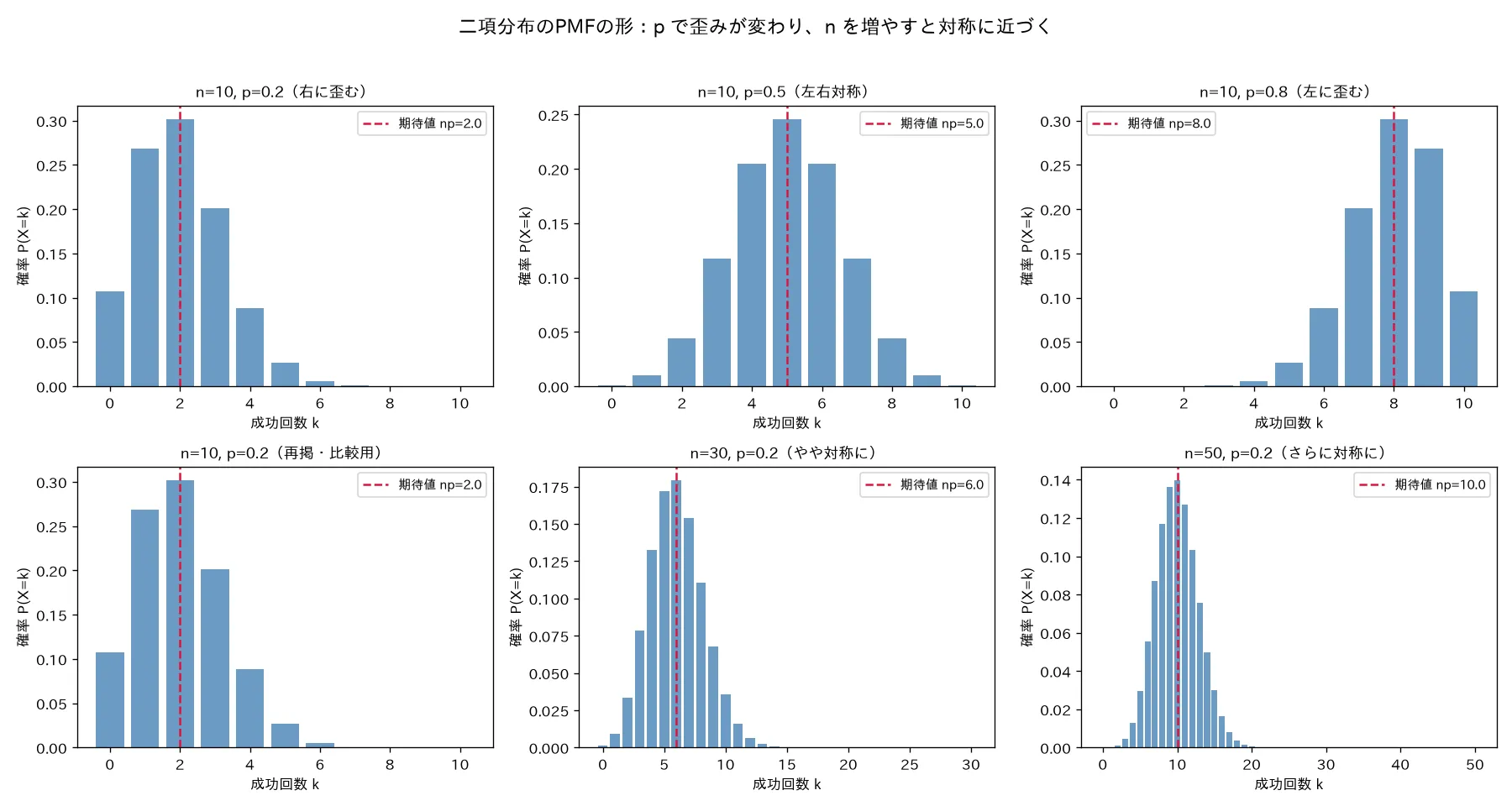
4. 分布の形状とパラメータ
PMFの形(棒グラフの形)は p p p n n n
p p p 形 p = 0.5 p=0.5 p = 0.5 左右対称(山が真ん中、P ( X = k ) = P ( X = n − k ) P(X=k)=P(X=n-k) P ( X = k ) = P ( X = n − k ) p < 0.5 p<0.5 p < 0.5 右に裾を引く(右に歪む、ピークが左寄り。失敗が出やすいので小さい k k k p > 0.5 p>0.5 p > 0.5 左に裾を引く(左に歪む、ピークが右寄り)
n n n p p p 中心極限定理(CLT) )。最頻値(モード) :⌊ ( n + 1 ) p ⌋ \lfloor(n+1)p\rfloor ⌊( n + 1 ) p ⌋ ( n + 1 ) p (n+1)p ( n + 1 ) p n p np n p
歪みの符号は歪度 1 − 2 p n p ( 1 − p ) \dfrac{1-2p}{\sqrt{np(1-p)}} n p ( 1 − p ) 1 − 2 p p < 0.5 p<0.5 p < 0.5 p = 0.5 p=0.5 p = 0.5 p > 0.5 p>0.5 p > 0.5 n → ∞ n\to\infty n → ∞ → 0 \to0 → 0 確率変数の変換・モーメント母関数・積率 の歪度)。
5. 再生性(加法性)── 同じ p p p
独立な X ∼ B i n ( n 1 , p ) X\sim\mathrm{Bin}(n_1,p) X ∼ Bin ( n 1 , p ) Y ∼ B i n ( n 2 , p ) Y\sim\mathrm{Bin}(n_2,p) Y ∼ Bin ( n 2 , p ) p p p X + Y ∼ B i n ( n 1 + n 2 , p ) X+Y\sim\mathrm{Bin}(n_1+n_2,p) X + Y ∼ Bin ( n 1 + n 2 , p ) 。
直観:n 1 n_1 n 1 n 2 n_2 n 2 n 1 + n 2 n_1+n_2 n 1 + n 2 p p p B i n ( n 1 + n 2 , p ) \mathrm{Bin}(n_1+n_2,p) Bin ( n 1 + n 2 , p )
MGFで証明 (確率変数の変換・モーメント母関数・積率 、独立和はMGFの積):
M X + Y ( t ) = M X ( t ) M Y ( t ) = ( 1 − p + p e t ) n 1 ( 1 − p + p e t ) n 2 = ( 1 − p + p e t ) n 1 + n 2 . M_{X+Y}(t)=M_X(t)M_Y(t)=(1-p+pe^t)^{n_1}(1-p+pe^t)^{n_2}=(1-p+pe^t)^{n_1+n_2}. M X + Y ( t ) = M X ( t ) M Y ( t ) = ( 1 − p + p e t ) n 1 ( 1 − p + p e t ) n 2 = ( 1 − p + p e t ) n 1 + n 2 . これは B i n ( n 1 + n 2 , p ) \mathrm{Bin}(n_1+n_2,p) Bin ( n 1 + n 2 , p ) X + Y ∼ B i n ( n 1 + n 2 , p ) X+Y\sim\mathrm{Bin}(n_1+n_2,p) X + Y ∼ Bin ( n 1 + n 2 , p ) ■ \blacksquare ■
要するに 「同じ p p p p p p ( 1 − p + p e t ) (1-p+pe^t) ( 1 − p + p e t ) p p p p p p
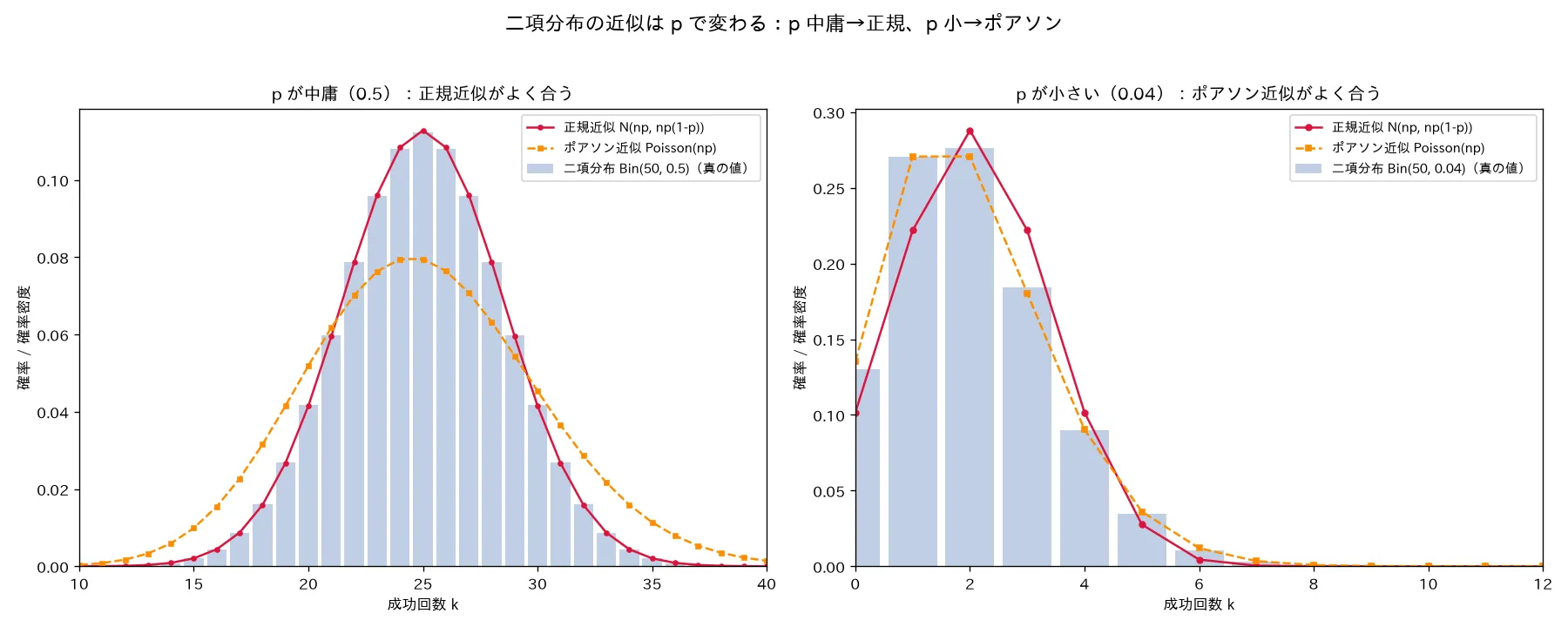
6. 近似の2方向 ── 次トピックへの布石
二項分布の確率計算は n n n n C k {}_nC_k n C k どちらに近似するかは p p p 。
近似先 条件 近似式 補正 正規分布 n n n p p p n p ≥ 5 np\ge5 n p ≥ 5 n ( 1 − p ) ≥ 5 n(1-p)\ge5 n ( 1 − p ) ≥ 5 B i n ( n , p ) ≈ N ( n p , n p ( 1 − p ) ) \mathrm{Bin}(n,p)\approx N(np,\,np(1-p)) Bin ( n , p ) ≈ N ( n p , n p ( 1 − p )) 連続性補正 ± 0.5 \pm0.5 ± 0.5 ポアソン分布 n n n p p p λ = n p \lambda=np λ = n p n → ∞ , p → 0 n\to\infty,p\to0 n → ∞ , p → 0 B i n ( n , p ) ≈ P o i s s o n ( λ = n p ) \mathrm{Bin}(n,p)\approx \mathrm{Poisson}(\lambda=np) Bin ( n , p ) ≈ Poisson ( λ = n p ) 補正不要(離散→離散)
正規近似(ド・モアブル=ラプラス) :中心極限定理(CLT) で詳述済み。二項=独立ベルヌーイ和だからCLTで N ( n p , n p ( 1 − p ) ) N(np,np(1-p)) N ( n p , n p ( 1 − p )) p p p 連続性補正 が要る。ポアソン近似 :p p p n p = λ np=\lambda n p = λ n → ∞ , p → 0 n\to\infty,p\to0 n → ∞ , p → 0 P o i s s o n ( λ ) \mathrm{Poisson}(\lambda) Poisson ( λ ) ポアソン分布 で導出)。離散→離散なので補正不要。
判定の勘どころ:分散 n p ( 1 − p ) np(1-p) n p ( 1 − p ) p p p p p p n p np n p 。
7. 試験での問われ方(級ごとの差)
3級(確率計算) :二項分布のPMF P ( X = k ) = n C k p k ( 1 − p ) n − k P(X=k)={}_nC_k p^k(1-p)^{n-k} P ( X = k ) = n C k p k ( 1 − p ) n − k 具体的な確率計算 (「コインを8回投げて表がちょうど3回」「不良率0.1で5個中2個が不良」など)。ベルヌーイ試行の意味、二項分布の適用条件の判定。2級(中核) :期待値 n p np n p n p ( 1 − p ) np(1-p) n p ( 1 − p ) 計算と利用 、n p ( 1 − p ) \sqrt{np(1-p)} n p ( 1 − p ) 正規近似 N ( n p , n p ( 1 − p ) ) N(np,np(1-p)) N ( n p , n p ( 1 − p )) p ^ = X / n \hat p=X/n p ^ = X / n p p p p ( 1 − p ) / n p(1-p)/n p ( 1 − p ) / n 2級の発展/準1級 :連続性補正 ± 0.5 \pm0.5 ± 0.5 中心極限定理(CLT) )、再生性 (同じ p p p E , V E,V E , V ポアソン分布 )。※公式の出題範囲表は改訂されうる。二項分布は3級(確率計算)と2級(期待値・分散・正規近似)にまたがるが、級ごとの深さの線引き・連続性補正や再生性の扱いは受験前に最新の範囲表で要最新確認 。
数式の直観的意味
なぜ P ( X = k ) = n C k p k ( 1 − p ) n − k P(X=k)={}_nC_k p^k(1-p)^{n-k} P ( X = k ) = n C k p k ( 1 − p ) n − k
二項分布の確率を作る手順を分解すると2段階。(段1) 1つの具体的な並びの確率 :たとえば「成功・成功・…(k k k n − k n-k n − k p k ( 1 − p ) n − k p^k(1-p)^{n-k} p k ( 1 − p ) n − k 成功 k k k n − k n-k n − k (掛け算は順序によらない)。(段2) そういう並びが何通りあるか :n n n k k k n C k {}_nC_k n C k 場合の数・順列・組合せ の組合せ。順序は問わず「どの枠が成功か」だけ)。確率はどれも同じ p k ( 1 − p ) n − k p^k(1-p)^{n-k} p k ( 1 − p ) n − k 1 1 1 × \times × n C k p k ( 1 − p ) n − k {}_nC_k\,p^k(1-p)^{n-k} n C k p k ( 1 − p ) n − k
なぜ E [ X ] = n p E[X]=np E [ X ] = n p
期待値の線形性 E [ X + Y ] = E [ X ] + E [ Y ] E[X+Y]=E[X]+E[Y] E [ X + Y ] = E [ X ] + E [ Y ] 独立を一切仮定せず常に成立 する(期待値・分散の性質(線形性・和の分散・共分散) )。成功回数 X X X X = ∑ X i X=\sum X_i X = ∑ X i X i X_i X i p p p n n n n p np n p p p p n n n n p np n p E [ X ] = n p E[X]=np E [ X ] = n p
なぜ V [ X ] = n p ( 1 − p ) V[X]=np(1-p) V [ X ] = n p ( 1 − p )
分散の加法性 V [ X + Y ] = V [ X ] + V [ Y ] V[X+Y]=V[X]+V[Y] V [ X + Y ] = V [ X ] + V [ Y ] 無相関(独立)のときだけ 成立する(一般には + 2 C o v +2\mathrm{Cov} + 2 Cov 期待値・分散の性質(線形性・和の分散・共分散) )。二項分布は各試行が独立 という前提があるので C o v ( X i , X j ) = 0 \mathrm{Cov}(X_i,X_j)=0 Cov ( X i , X j ) = 0 V [ X ] = ∑ V [ X i ] = n p ( 1 − p ) V[X]=\sum V[X_i]=np(1-p) V [ X ] = ∑ V [ X i ] = n p ( 1 − p ) もし試行が独立でなければ(例:くじを戻さず引く=超幾何分布)、分散は n p ( 1 − p ) np(1-p) n p ( 1 − p ) (共分散が負に効いて分散が小さくなる)。だから「二項分布の分散 n p ( 1 − p ) np(1-p) n p ( 1 − p )
なぜ V [ X ] V[X] V [ X ] p = 0.5 p=0.5 p = 0.5
V [ X ] = n p ( 1 − p ) V[X]=np(1-p) V [ X ] = n p ( 1 − p ) p p p f ( p ) = p ( 1 − p ) = p − p 2 f(p)=p(1-p)=p-p^2 f ( p ) = p ( 1 − p ) = p − p 2 f ′ ( p ) = 1 − 2 p = 0 f'(p)=1-2p=0 f ′ ( p ) = 1 − 2 p = 0 p = 0.5 p=0.5 p = 0.5 f ( 0.5 ) = 0.25 f(0.5)=0.25 f ( 0.5 ) = 0.25 「結果が五分五分のときが最も予測しづらい(ばらつき最大)、確率が0や1に寄るほど結果が確定してばらつき0」 。標本比率の標準誤差 p ( 1 − p ) / n \sqrt{p(1-p)/n} p ( 1 − p ) / n p = 0.5 p=0.5 p = 0.5 p = 0.5 p=0.5 p = 0.5
⚠️ 引っかけポイント・頻出論点・級ごとの差
n C k {}_nC_k n C k k k k p k ( 1 − p ) n − k p^k(1-p)^{n-k} p k ( 1 − p ) n − k だけでは不足 。場所の選び方 n C k {}_nC_k n C k p k ( 1 − p ) n − k p^k(1-p)^{n-k} p k ( 1 − p ) n − k 「以上・以下・ちょうど」の取り違え :「3回以上成功」は P ( X ≥ 3 ) = ∑ k ≥ 3 P ( X = k ) P(X\ge3)=\sum_{k\ge3}P(X=k) P ( X ≥ 3 ) = ∑ k ≥ 3 P ( X = k ) 1 − P ( X ≤ 2 ) 1-P(X\le2) 1 − P ( X ≤ 2 ) P ( X = 3 ) P(X=3) P ( X = 3 ) = 1 − P ( X = 0 ) = 1 − ( 1 − p ) n =1-P(X=0)=1-(1-p)^n = 1 − P ( X = 0 ) = 1 − ( 1 − p ) n 分散と標準偏差の混同 :V [ X ] = n p ( 1 − p ) V[X]=np(1-p) V [ X ] = n p ( 1 − p ) n p ( 1 − p ) \sqrt{np(1-p)} n p ( 1 − p ) z = X − n p n p ( 1 − p ) z=\frac{X-np}{\sqrt{np(1-p)}} z = n p ( 1 − p ) X − n p 再生性は同じ p p p :B i n ( n 1 , p ) + B i n ( n 2 , p ) = B i n ( n 1 + n 2 , p ) \mathrm{Bin}(n_1,p)+\mathrm{Bin}(n_2,p)=\mathrm{Bin}(n_1+n_2,p) Bin ( n 1 , p ) + Bin ( n 2 , p ) = Bin ( n 1 + n 2 , p ) p p p p p p 独立性の前提を忘れる(超幾何との混同) :二項分布は「復元抽出 (毎回 p p p 非復元 )と p p p n p ( 1 − p ) np(1-p) n p ( 1 − p ) 幾何分布・超幾何分布・負の二項分布 )。「箱から不良品を取り出す」系は復元か非復元かを必ず確認。正規近似 vs ポアソン近似の選択(2級) :p p p n p , n ( 1 − p ) ≥ 5 np,n(1-p)\ge5 n p , n ( 1 − p ) ≥ 5 p p p n p np n p p = 0.5 p=0.5 p = 0.5 p = 0.001 p=0.001 p = 0.001 正規近似に連続性補正(2級発展) :二項(離散)を正規(連続)で近似するときは ± 0.5 \pm0.5 ± 0.5 中心極限定理(CLT) )。ポアソン近似(離散→離散)には補正不要。n p np n p n p np n p n p > 1 np>1 n p > 1 級差 :3級=PMFでの確率計算 (n C k p k ( 1 − p ) n − k {}_nC_k p^k(1-p)^{n-k} n C k p k ( 1 − p ) n − k E = n p , V = n p ( 1 − p ) E=np,V=np(1-p) E = n p , V = n p ( 1 − p ) 連続性補正・再生性・MGF導出・ポアソン近似との使い分け 。
よくある疑問
Q1. n C k {}_nC_k n C k
「ちょうど k k k p k ( 1 − p ) n − k p^k(1-p)^{n-k} p k ( 1 − p ) n − k だけでは足りません 。これは「1回目から k k k 特定の1つの順番 の確率にすぎないからです。成功する回の組合せが n C k {}_nC_k n C k n C k {}_nC_k n C k 3級でいちばん多いミス なので、二項分布の確率を出すときは必ず組合せを掛ける、と意識してください。
Q2. 「3回以上成功」の確率はどう求める?
P ( X ≥ 3 ) = P ( X = 3 ) + P ( X = 4 ) + ⋯ + P ( X = n ) P(X\ge3)=P(X=3)+P(X=4)+\cdots+P(X=n) P ( X ≥ 3 ) = P ( X = 3 ) + P ( X = 4 ) + ⋯ + P ( X = n ) 余事象 を使うと速いです。P ( X ≥ 3 ) = 1 − P ( X ≤ 2 ) = 1 − { P ( X = 0 ) + P ( X = 1 ) + P ( X = 2 ) } P(X\ge3)=1-P(X\le2)=1-\{P(X=0)+P(X=1)+P(X=2)\} P ( X ≥ 3 ) = 1 − P ( X ≤ 2 ) = 1 − { P ( X = 0 ) + P ( X = 1 ) + P ( X = 2 )} P ( X ≥ 1 ) = 1 − P ( X = 0 ) = 1 − ( 1 − p ) n P(X\ge1)=1-P(X=0)=1-(1-p)^n P ( X ≥ 1 ) = 1 − P ( X = 0 ) = 1 − ( 1 − p ) n
Q3. 「袋から戻さずに引く」場合も二項分布ですか?
いいえ、それは超幾何分布 になります。二項分布は「毎回 p p p 復元抽出 )。袋から玉を戻さずに 引くと、引くたびに残りの比率が変わって p p p n p ( 1 − p ) np(1-p) n p ( 1 − p ) 幾何分布・超幾何分布・負の二項分布 )。「箱から不良品を取り出す」系の問題は、戻すのか戻さないのか を必ず確認してください。
Q4. 正規近似とポアソン近似、どっちを使えばいい?
p p p p p p n p ≥ 5 np\ge5 n p ≥ 5 n ( 1 − p ) ≥ 5 n(1-p)\ge5 n ( 1 − p ) ≥ 5 正規近似 、p p p n p np n p ポアソン近似 です。p = 0.5 p=0.5 p = 0.5 p = 0.001 p=0.001 p = 0.001 n p ( 1 − p ) np(1-p) n p ( 1 − p )
Q5. 二項分布どうしは足せますか?
成功確率 p p p 。B i n ( n 1 , p ) + B i n ( n 2 , p ) = B i n ( n 1 + n 2 , p ) \mathrm{Bin}(n_1,p)+\mathrm{Bin}(n_2,p)=\mathrm{Bin}(n_1+n_2,p) Bin ( n 1 , p ) + Bin ( n 2 , p ) = Bin ( n 1 + n 2 , p ) n 1 n_1 n 1 n 2 n_2 n 2 n 1 + n 2 n_1+n_2 n 1 + n 2 p p p p p p
まとめ
ベルヌーイ分布 =1回の成功/失敗。E = p , V = p ( 1 − p ) E=p,\ V=p(1-p) E = p , V = p ( 1 − p ) n n n 二項分布 B i n ( n , p ) \mathrm{Bin}(n,p) Bin ( n , p ) P ( X = k ) = n C k p k ( 1 − p ) n − k P(X=k)={}_nC_k\,p^k(1-p)^{n-k} P ( X = k ) = n C k p k ( 1 − p ) n − k n C k {}_nC_k n C k 期待値 n p np n p n p ( 1 − p ) np(1-p) n p ( 1 − p ) 。ベルヌーイの足し算で導けます(分散の足し算には独立が必要)。p = 0.5 p=0.5 p = 0.5 確率の合計が1になるのは二項定理 から。これが名前の由来。
n n n p p p 正規近似 、p p p ポアソン近似 。p p p 再生性 は同じ p p p
対応するシミュレーション
simulations/nikou_bunpu_keijou.py
何を示すか :二項分布のPMF n C k p k ( 1 − p ) n − k {}_nC_k p^k(1-p)^{n-k} n C k p k ( 1 − p ) n − k ( n , p ) (n,p) ( n , p ) p = 0.5 p=0.5 p = 0.5 p ≠ 0.5 p\neq0.5 p = 0.5 p < 0.5 p<0.5 p < 0.5 p > 0.5 p>0.5 p > 0.5 n n n np.random.binomial)のヒストグラムが理論PMFに重なること、標本平均 ≈ n p \approx np ≈ n p ≈ n p ( 1 − p ) \approx np(1-p) ≈ n p ( 1 − p ) 結論(seed=0) :PMF形状は p = 0.2 p=0.2 p = 0.2 p = 0.5 p=0.5 p = 0.5 p = 0.8 p=0.8 p = 0.8 n = 10 → 50 n=10\to50 n = 10 → 50 p = 0.2 p=0.2 p = 0.2 B i n ( 20 , 0.3 ) \mathrm{Bin}(20,0.3) Bin ( 20 , 0.3 ) 5.9972 (理論 n p = 6.0 np=6.0 n p = 6.0 4.2065 (理論 n p ( 1 − p ) = 4.2 np(1-p)=4.2 n p ( 1 − p ) = 4.2
simulations/nikou_bunpu_kinji.py
何を示すか :近似の2方向を1枚で対比。左=B i n ( 50 , 0.5 ) \mathrm{Bin}(50,0.5) Bin ( 50 , 0.5 ) p p p 正規近似 N ( n p , n p ( 1 − p ) ) N(np,np(1-p)) N ( n p , n p ( 1 − p )) B i n ( 50 , 0.04 ) \mathrm{Bin}(50,0.04) Bin ( 50 , 0.04 ) λ = n p = 2 \lambda=np=2 λ = n p = 2 p p p ポアソン近似 P o i s s o n ( λ = n p ) \mathrm{Poisson}(\lambda=np) Poisson ( λ = n p ) k k k p p p p p p 結論(scipy不使用、正規PDF・ポアソンPMFは自前計算) :B i n ( 50 , 0.5 ) \mathrm{Bin}(50,0.5) Bin ( 50 , 0.5 ) 0.00056 に対しポアソン近似は 0.03275 (正規が約58倍精確)。B i n ( 50 , 0.04 ) \mathrm{Bin}(50,0.04) Bin ( 50 , 0.04 ) 0.00556 に対し正規近似は 0.04869 (ポアソンが約9倍精確、p p p p p p
関連ノート
場合の数・順列・組合せ (場合の数・順列・組合せ ── PMFの n C k {}_nC_k n C k ( p + ( 1 − p ) ) n (p+(1-p))^n ( p + ( 1 − p ) ) n 条件付き確率・独立性・全確率の定理 (条件付き確率・独立性 ── 独立反復試行 p k ( 1 − p ) n − k p^k(1-p)^{n-k} p k ( 1 − p ) n − k 確率変数(離散・連続)と期待値・分散 (確率変数・期待値・分散 ── ベルヌーイの E [ X ] = p , V [ X ] = p ( 1 − p ) E[X]=p,\ V[X]=p(1-p) E [ X ] = p , V [ X ] = p ( 1 − p ) X 2 = X X^2=X X 2 = X 期待値・分散の性質(線形性・和の分散・共分散) (期待値・分散の性質 ── E , V E,V E , V 確率変数の変換・モーメント母関数・積率 (変換・モーメント母関数 ── ベルヌーイMGF 1 − p + p e t 1-p+pe^t 1 − p + p e t n n n = = = 中心極限定理(CLT) (中心極限定理 ── 二項の正規近似 N ( n p , n p ( 1 − p ) ) N(np,np(1-p)) N ( n p , n p ( 1 − p )) ポアソン分布 (ポアソン分布 ── 二項の λ = n p \lambda=np λ = n p n → ∞ , p → 0 n\to\infty,p\to0 n → ∞ , p → 0 p p p 幾何分布・超幾何分布・負の二項分布 (幾何・負の二項・超幾何分布 ── 非復元抽出の超幾何は「独立でない二項」、分散が n p ( 1 − p ) np(1-p) n p ( 1 − p )