← 統計検定テキスト 一覧
📊 対象級:2級 ・ 準1級 | 重要度:A(頻出)
ポアソン分布
要点(BLUF)
ポアソン分布 P o i s s o n ( λ ) \mathrm{Poisson}(\lambda) Poisson ( λ ) λ \lambda λ 稀な事象の回数 の分布。PMF
P ( X = k ) = λ k e − λ k ! ( k = 0 , 1 , 2 , … ) . \boxed{\,P(X=k)=\dfrac{\lambda^k e^{-\lambda}}{k!}\,}\quad(k=0,1,2,\dots). P ( X = k ) = k ! λ k e − λ ( k = 0 , 1 , 2 , … ) . ∑ k λ k / k ! = e λ \sum_k \lambda^k/k!=e^\lambda ∑ k λ k / k ! = e λ e − λ e λ = 1 e^{-\lambda}e^\lambda=1 e − λ e λ = 1 λ \lambda λ 二項からの極限 (本トピックの山):B i n ( n , p ) \mathrm{Bin}(n,p) Bin ( n , p ) λ = n p \lambda=np λ = n p n → ∞ , p → 0 n\to\infty,p\to0 n → ∞ , p → 0 p = λ / n p=\lambda/n p = λ / n λ k e − λ k ! \dfrac{\lambda^k e^{-\lambda}}{k!} k ! λ k e − λ e − λ e^{-\lambda} e − λ ( 1 − λ / n ) n → e − λ (1-\lambda/n)^n\to e^{-\lambda} ( 1 − λ / n ) n → e − λ ベルヌーイ分布・二項分布 の「p p p 期待値・分散 :E [ X ] = λ , V [ X ] = λ \boxed{E[X]=\lambda,\ V[X]=\lambda} E [ X ] = λ , V [ X ] = λ 平均=分散 がポアソンの指紋)。二項極限(n p → λ , n p ( 1 − p ) → λ np\to\lambda,\ np(1-p)\to\lambda n p → λ , n p ( 1 − p ) → λ M X ( t ) = e λ ( e t − 1 ) M_X(t)=e^{\lambda(e^t-1)} M X ( t ) = e λ ( e t − 1 ) 確率変数の変換・モーメント母関数・積率 )。再生性 :独立な P o i s s o n ( λ 1 ) + P o i s s o n ( λ 2 ) = P o i s s o n ( λ 1 + λ 2 ) \mathrm{Poisson}(\lambda_1)+\mathrm{Poisson}(\lambda_2)=\mathrm{Poisson}(\lambda_1+\lambda_2) Poisson ( λ 1 ) + Poisson ( λ 2 ) = Poisson ( λ 1 + λ 2 ) 無条件 、λ \lambda λ p p p ポアソン過程(準1級) :単位時間平均 λ \lambda λ t t t N t ∼ P o i s s o n ( λ t ) N_t\sim\mathrm{Poisson}(\lambda t) N t ∼ Poisson ( λ t ) 待ち時間は平均 1 / λ 1/\lambda 1/ λ (P ( T > t ) = P ( N t = 0 ) = e − λ t P(T>t)=P(N_t=0)=e^{-\lambda t} P ( T > t ) = P ( N t = 0 ) = e − λ t 指数分布・ガンマ分布・ベータ分布 へ)。
本文
0. ポアソン分布が活躍する場面
ポアソン分布が当てはまるのは、次のような状況です。
1時間あたり平均3人が来店する店で、ある1時間にちょうど5人 来る確率は?
1日平均0.5件の事故が起きる交差点で、ある1日に事故が0件 の確率は?
不良率が非常に低い製造ラインで、製品1000個中に不良品が2個 含まれる確率は?
共通点は「起こる確率は低いが、機会(試行)は非常に多い 」こと。1回あたりの確率 p p p n n n
二項分布との関係(おさらい) :ベルヌーイ分布・二項分布 (二項分布)は「成功確率 p p p n n n 特別な極限 です。
二項分布:n n n p p p n n n k k k
ポアソン分布:n n n p p p n n n p p p λ = n p \lambda=np λ = n p
「1日に何人来店するか」を考えるとき、「1日の中に試行が何回あるか(n n n p p p n n n p p p λ \lambda λ
1. ポアソン分布とは ── 稀な事象の回数
適用条件 :起こる確率 p p p n n n 計数データ 。例:1日の交通事故件数、1時間の来客数、製品1000個あたりの不良品数、単位面積あたりの粒子数。
二項分布 ベルヌーイ分布・二項分布 が「n n n k k k n , p n,p n , p 平均 λ = n p \lambda=np λ = n p で考える。k k k
PMF:
P ( X = k ) = λ k e − λ k ! ( k = 0 , 1 , 2 , … ) . P(X=k)=\frac{\lambda^k e^{-\lambda}}{k!}\qquad(k=0,1,2,\dots). P ( X = k ) = k ! λ k e − λ ( k = 0 , 1 , 2 , … ) . 総和=1の確認 (指数関数のテイラー展開):
∑ k = 0 ∞ λ k e − λ k ! = e − λ ∑ k = 0 ∞ λ k k ! = e − λ ⋅ e λ = 1. \sum_{k=0}^{\infty}\frac{\lambda^k e^{-\lambda}}{k!}=e^{-\lambda}\sum_{k=0}^{\infty}\frac{\lambda^k}{k!}=e^{-\lambda}\cdot e^{\lambda}=1. k = 0 ∑ ∞ k ! λ k e − λ = e − λ k = 0 ∑ ∞ k ! λ k = e − λ ⋅ e λ = 1. ∑ k λ k / k ! = e λ \sum_k \lambda^k/k!=e^\lambda ∑ k λ k / k ! = e λ e x = ∑ k x k / k ! e^x=\sum_k x^k/k! e x = ∑ k x k / k ! e − λ e^{-\lambda} e − λ e − λ e^{-\lambda} e − λ
2. 二項分布からの極限導出(山場・準1級)
ポアソン分布の式は天下りに見えますが、二項分布から自然に導けます 。
主張 :B i n ( n , p ) \mathrm{Bin}(n,p) Bin ( n , p ) p = λ / n p=\lambda/n p = λ / n λ = n p \lambda=np λ = n p n → ∞ n\to\infty n → ∞ P ( X = k ) → λ k e − λ k ! P(X=k)\to\dfrac{\lambda^k e^{-\lambda}}{k!} P ( X = k ) → k ! λ k e − λ ポアソンの少数の法則 (law of rare events)と呼びます。
二項PMFに p = λ / n p=\lambda/n p = λ / n
P ( X = k ) = n ! k ! ( n − k ) ! ( λ n ) k ( 1 − λ n ) n − k . P(X=k)=\frac{n!}{k!\,(n-k)!}\left(\frac{\lambda}{n}\right)^{k}\left(1-\frac{\lambda}{n}\right)^{n-k}. P ( X = k ) = k ! ( n − k )! n ! ( n λ ) k ( 1 − n λ ) n − k . k k k n → ∞ n\to\infty n → ∞ 4つに分解 (( λ / n ) k = λ k / n k (\lambda/n)^k=\lambda^k/n^k ( λ / n ) k = λ k / n k ( 1 − λ / n ) n − k (1-\lambda/n)^{n-k} ( 1 − λ / n ) n − k n n n − k -k − k
P ( X = k ) = λ k k ! ⏟ ( A ) ⋅ n ! ( n − k ) ! n k ⏟ ( B ) ⋅ ( 1 − λ n ) n ⏟ ( C ) ⋅ ( 1 − λ n ) − k ⏟ ( D ) . P(X=k)=\underbrace{\frac{\lambda^k}{k!}}_{(A)}\cdot\underbrace{\frac{n!}{(n-k)!\,n^k}}_{(B)}\cdot\underbrace{\left(1-\frac{\lambda}{n}\right)^{n}}_{(C)}\cdot\underbrace{\left(1-\frac{\lambda}{n}\right)^{-k}}_{(D)}. P ( X = k ) = ( A ) k ! λ k ⋅ ( B ) ( n − k )! n k n ! ⋅ ( C ) ( 1 − n λ ) n ⋅ ( D ) ( 1 − n λ ) − k .
(A) λ k k ! \dfrac{\lambda^k}{k!} k ! λ k :n n n (B) n ! ( n − k ) ! n k → 1 \dfrac{n!}{(n-k)!\,n^k}\to1 ( n − k )! n k n ! → 1 :分子 n ! ( n − k ) ! = n ( n − 1 ) ⋯ ( n − k + 1 ) \dfrac{n!}{(n-k)!}=n(n-1)\cdots(n-k+1) ( n − k )! n ! = n ( n − 1 ) ⋯ ( n − k + 1 ) k k k n k n^k n k n n n − 1 n ⋯ n − k + 1 n = 1 ⋅ ( 1 − 1 n ) ⋯ ( 1 − k − 1 n ) → 1 \dfrac{n}{n}\dfrac{n-1}{n}\cdots\dfrac{n-k+1}{n}=1\cdot(1-\tfrac1n)\cdots(1-\tfrac{k-1}{n})\to1 n n n n − 1 ⋯ n n − k + 1 = 1 ⋅ ( 1 − n 1 ) ⋯ ( 1 − n k − 1 ) → 1 1 1 1 k k k k k k n − i n \frac{n-i}{n} n n − i n n n 1 1 1 (C) ( 1 − λ n ) n → e − λ \left(1-\dfrac{\lambda}{n}\right)^{n}\to e^{-\lambda} ( 1 − n λ ) n → e − λ :有名な極限 lim n ( 1 + x / n ) n = e x \lim_n(1+x/n)^n=e^x lim n ( 1 + x / n ) n = e x x = − λ x=-\lambda x = − λ ここで e − λ e^{-\lambda} e − λ (PMFの e − λ e^{-\lambda} e − λ (D) ( 1 − λ n ) − k → 1 \left(1-\dfrac{\lambda}{n}\right)^{-k}\to1 ( 1 − n λ ) − k → 1 :中身 1 − λ / n → 1 1-\lambda/n\to1 1 − λ / n → 1 − k -k − k 1 − k = 1 1^{-k}=1 1 − k = 1
掛けて
P ( X = k ) → λ k k ! ⋅ 1 ⋅ e − λ ⋅ 1 = λ k e − λ k ! . ■ P(X=k)\to\frac{\lambda^k}{k!}\cdot1\cdot e^{-\lambda}\cdot1=\frac{\lambda^k e^{-\lambda}}{k!}.\qquad\blacksquare P ( X = k ) → k ! λ k ⋅ 1 ⋅ e − λ ⋅ 1 = k ! λ k e − λ . ■ 何が起きたか(核心) :二項分布の3パーツ(組合せ・p k p^k p k ( 1 − p ) n − k (1-p)^{n-k} ( 1 − p ) n − k n ! n! n ! ( 1 − p ) n − k (1-p)^{n-k} ( 1 − p ) n − k e − λ e^{-\lambda} e − λ λ k / k ! \lambda^k/k! λ k / k ! e − λ e^{-\lambda} e − λ ( 1 − λ / n ) n → e − λ (1-\lambda/n)^n\to e^{-\lambda} ( 1 − λ / n ) n → e − λ ベルヌーイ分布・二項分布 で「p p p
3. 期待値・分散:どちらも λ
E [ X ] = λ , V [ X ] = λ \boxed{\,E[X]=\lambda,\qquad V[X]=\lambda\,} E [ X ] = λ , V [ X ] = λ 平均も分散も λ \lambda λ 。これがポアソン分布の指紋です。
導出(1):二項の極限から(最速・一番速い理解)
二項分布では E [ X ] = n p E[X]=np E [ X ] = n p V [ X ] = n p ( 1 − p ) V[X]=np(1-p) V [ X ] = n p ( 1 − p ) ベルヌーイ分布・二項分布 )。p = λ / n p=\lambda/n p = λ / n n → ∞ n\to\infty n → ∞
E [ X ] = n p = n ⋅ λ n = λ , V [ X ] = n p ( 1 − p ) = λ ( 1 − λ n ) → n → ∞ λ . E[X]=np=n\cdot\frac{\lambda}{n}=\lambda,\qquad
V[X]=np(1-p)=\lambda\Big(1-\frac{\lambda}{n}\Big)\xrightarrow[n\to\infty]{}\lambda. E [ X ] = n p = n ⋅ n λ = λ , V [ X ] = n p ( 1 − p ) = λ ( 1 − n λ ) n → ∞ λ . 要するに「二項の分散 n p ( 1 − p ) np(1-p) n p ( 1 − p ) ( 1 − p ) (1-p) ( 1 − p ) p → 0 p\to0 p → 0 1 1 1 λ \lambda λ 」。これがポアソンで平均と分散が一致する最も直観的な理由です。
確率変数の変換・モーメント母関数・積率 のMGFを使うと、高次モーメントもまとめて出せます。ポアソン分布のMGFは
M X ( t ) = E [ e t X ] = e λ ( e t − 1 ) . \boxed{\,M_X(t)=E[e^{tX}]=e^{\lambda(e^t-1)}\,}. M X ( t ) = E [ e tX ] = e λ ( e t − 1 ) . MGFの導出 :定義に従って計算します。
M X ( t ) = ∑ k = 0 ∞ e t k ⋅ λ k e − λ k ! = e − λ ∑ k = 0 ∞ ( λ e t ) k k ! . M_X(t)=\sum_{k=0}^{\infty}e^{tk}\cdot\frac{\lambda^k e^{-\lambda}}{k!}
=e^{-\lambda}\sum_{k=0}^{\infty}\frac{(\lambda e^t)^k}{k!}. M X ( t ) = k = 0 ∑ ∞ e t k ⋅ k ! λ k e − λ = e − λ k = 0 ∑ ∞ k ! ( λ e t ) k . ここで e t k λ k = ( λ e t ) k e^{tk}\lambda^k=(\lambda e^t)^k e t k λ k = ( λ e t ) k ∑ k x k / k ! = e x \sum_k x^k/k!=e^x ∑ k x k / k ! = e x x = λ e t x=\lambda e^t x = λ e t ∑ k ( λ e t ) k / k ! = e λ e t \sum_k (\lambda e^t)^k/k!=e^{\lambda e^t} ∑ k ( λ e t ) k / k ! = e λ e t
M X ( t ) = e − λ ⋅ e λ e t = e λ e t − λ = e λ ( e t − 1 ) . M_X(t)=e^{-\lambda}\cdot e^{\lambda e^t}=e^{\lambda e^t-\lambda}=e^{\lambda(e^t-1)}. M X ( t ) = e − λ ⋅ e λ e t = e λ e t − λ = e λ ( e t − 1 ) . 要するに「確率の合計が1になったのと同じテイラー展開のトリックを、λ \lambda λ λ e t \lambda e^t λ e t 」。
MGFから E [ X ] E[X] E [ X ] t = 0 t=0 t = 0 :合成関数の微分で d d t e λ ( e t − 1 ) = e λ ( e t − 1 ) ⋅ λ e t \dfrac{d}{dt}e^{\lambda(e^t-1)}=e^{\lambda(e^t-1)}\cdot\lambda e^t d t d e λ ( e t − 1 ) = e λ ( e t − 1 ) ⋅ λ e t
M X ′ ( t ) = λ e t e λ ( e t − 1 ) , E [ X ] = M X ′ ( 0 ) = λ ⋅ 1 ⋅ e 0 = λ . M_X'(t)=\lambda e^t\, e^{\lambda(e^t-1)},\qquad
E[X]=M_X'(0)=\lambda\cdot1\cdot e^{0}=\lambda. M X ′ ( t ) = λ e t e λ ( e t − 1 ) , E [ X ] = M X ′ ( 0 ) = λ ⋅ 1 ⋅ e 0 = λ . MGFから E [ X 2 ] E[X^2] E [ X 2 ] t = 0 t=0 t = 0 :積の微分で
M X ′ ′ ( t ) = λ e t e λ ( e t − 1 ) + λ e t ⋅ λ e t e λ ( e t − 1 ) = ( λ e t + λ 2 e 2 t ) e λ ( e t − 1 ) . M_X''(t)=\lambda e^t\,e^{\lambda(e^t-1)}+\lambda e^t\cdot\lambda e^t\,e^{\lambda(e^t-1)}
=\big(\lambda e^t+\lambda^2 e^{2t}\big)e^{\lambda(e^t-1)}. M X ′′ ( t ) = λ e t e λ ( e t − 1 ) + λ e t ⋅ λ e t e λ ( e t − 1 ) = ( λ e t + λ 2 e 2 t ) e λ ( e t − 1 ) . t = 0 t=0 t = 0 E [ X 2 ] = M X ′ ′ ( 0 ) = λ + λ 2 E[X^2]=M_X''(0)=\lambda+\lambda^2 E [ X 2 ] = M X ′′ ( 0 ) = λ + λ 2
V [ X ] = E [ X 2 ] − ( E [ X ] ) 2 = ( λ + λ 2 ) − λ 2 = λ . ✓ V[X]=E[X^2]-(E[X])^2=(\lambda+\lambda^2)-\lambda^2=\lambda.\ \checkmark V [ X ] = E [ X 2 ] − ( E [ X ] ) 2 = ( λ + λ 2 ) − λ 2 = λ . ✓ 2通り(二項の極限・MGF)が同じ E = V = λ E=V=\lambda E = V = λ します。導出(1)は速く、導出(2)は歪度・尖度まで同じ枠組みで出せます(ポアソンの歪度は 1 / λ 1/\sqrt{\lambda} 1/ λ λ \lambda λ
4. 再生性(足し算しても同じ仲間)
独立な X ∼ P o i s s o n ( λ 1 ) X\sim\mathrm{Poisson}(\lambda_1) X ∼ Poisson ( λ 1 ) Y ∼ P o i s s o n ( λ 2 ) Y\sim\mathrm{Poisson}(\lambda_2) Y ∼ Poisson ( λ 2 ) X + Y ∼ P o i s s o n ( λ 1 + λ 2 ) X+Y\sim\mathrm{Poisson}(\lambda_1+\lambda_2) X + Y ∼ Poisson ( λ 1 + λ 2 ) になります。これを**再生性(加法性)**と呼びます。準1級で出題実績があります。
直観 :A店に平均 λ 1 \lambda_1 λ 1 λ 2 \lambda_2 λ 2 λ 1 + λ 2 \lambda_1+\lambda_2 λ 1 + λ 2
MGFで証明 (確率変数の変換・モーメント母関数・積率 、独立和のMGFは各MGFの積):
M X + Y ( t ) = M X ( t ) M Y ( t ) = e λ 1 ( e t − 1 ) ⋅ e λ 2 ( e t − 1 ) = e ( λ 1 + λ 2 ) ( e t − 1 ) . M_{X+Y}(t)=M_X(t)\,M_Y(t)=e^{\lambda_1(e^t-1)}\cdot e^{\lambda_2(e^t-1)}
=e^{(\lambda_1+\lambda_2)(e^t-1)}. M X + Y ( t ) = M X ( t ) M Y ( t ) = e λ 1 ( e t − 1 ) ⋅ e λ 2 ( e t − 1 ) = e ( λ 1 + λ 2 ) ( e t − 1 ) . これは P o i s s o n ( λ 1 + λ 2 ) \mathrm{Poisson}(\lambda_1+\lambda_2) Poisson ( λ 1 + λ 2 ) X + Y ∼ P o i s s o n ( λ 1 + λ 2 ) X+Y\sim\mathrm{Poisson}(\lambda_1+\lambda_2) X + Y ∼ Poisson ( λ 1 + λ 2 ) ■ \blacksquare ■
要するに「指数の肩の λ \lambda λ 」。二項分布の再生性が「p p p ポアソンは無条件(独立でさえあれば)で足せる のが強みです。λ \lambda λ
5. ポアソン過程との関係(準1級)
ポアソン分布を「時間軸」に拡張したのがポアソン過程 です。準1級ではこちらも問われます。
単位時間あたり平均 λ \lambda λ 起きる稀な事象を考えます(λ \lambda λ 強度 または到着率 と呼ぶ)。このとき、時間 t t t N t N_t N t P o i s s o n ( λ t ) \mathrm{Poisson}(\lambda t) Poisson ( λ t ) :
P ( N t = k ) = ( λ t ) k e − λ t k ! , E [ N t ] = λ t . P(N_t=k)=\frac{(\lambda t)^k e^{-\lambda t}}{k!},\qquad E[N_t]=\lambda t. P ( N t = k ) = k ! ( λ t ) k e − λ t , E [ N t ] = λ t . 要するに「平均 λ t \lambda t λ t
待ち時間が指数分布になる
ポアソン過程のもう一つの顔が「事象と事象の間隔(待ち時間)は指数分布に従う 」ことです。
なぜか:「次の事象までの待ち時間 T T T t t t t t t 1回も起きない 」なので、
P ( T > t ) = P ( N t = 0 ) = ( λ t ) 0 e − λ t 0 ! = e − λ t . P(T>t)=P(N_t=0)=\frac{(\lambda t)^0 e^{-\lambda t}}{0!}=e^{-\lambda t}. P ( T > t ) = P ( N t = 0 ) = 0 ! ( λ t ) 0 e − λ t = e − λ t . したがって待ち時間の累積分布は P ( T ≤ t ) = 1 − e − λ t P(T\le t)=1-e^{-\lambda t} P ( T ≤ t ) = 1 − e − λ t 平均 1 / λ 1/\lambda 1/ λ そのものです。要するに「1時間に平均 λ \lambda λ 1 / λ 1/\lambda 1/ λ 」。
この「ポアソン分布(回数)」と「指数分布(待ち時間)」は表裏一体です。詳しくは 指数分布・ガンマ分布・ベータ分布 (指数分布)で扱います。準1級ではポアソン過程・M/M/1待ち行列・非定常ポアソン過程まで問われうる(要最新確認)。
6. 分布どうしの使い分け(二項・ポアソン・正規)
「いつどれを使うか」を表に整理します。λ \lambda λ
分布 使う場面 パラメータ 平均 分散 形 二項 B i n ( n , p ) \mathrm{Bin}(n,p) Bin ( n , p ) 回数 n n n n , p n,\ p n , p n p np n p n p ( 1 − p ) np(1-p) n p ( 1 − p ) p = 0.5 p=0.5 p = 0.5 ポアソン P o i s s o n ( λ ) \mathrm{Poisson}(\lambda) Poisson ( λ ) n n n p p p λ \lambda λ λ \lambda λ λ \lambda λ λ \lambda λ 正規 N ( μ , σ 2 ) N(\mu,\sigma^2) N ( μ , σ 2 ) 連続量、または λ \lambda λ n p np n p μ , σ 2 \mu,\ \sigma^2 μ , σ 2 μ \mu μ σ 2 \sigma^2 σ 2 左右対称
3つの関係 を図にすると次の通りです(条件で乗り換えていく)。
flowchart LR
B["二項分布<br/>Bin(n, p)"] -->|"p 小・n 大<br/>np=λ 一定"| P["ポアソン分布<br/>Poisson(λ)"]
B -->|"p 中庸・n 大<br/>np と n(1-p) が大"| N["正規分布<br/>N(np, np(1-p))"]
P -->|"λ 大"| N2["正規分布<br/>N(λ, λ)"]
要するに「p p p p p p n n n λ \lambda λ 分散が大きい(p p p p p p n p np n p 」です。
ポアソンの性質まとめ
項目 内容 PMF P ( X = k ) = λ k e − λ k ! ( k = 0 , 1 , 2 , … ) P(X=k)=\dfrac{\lambda^k e^{-\lambda}}{k!}\ (k=0,1,2,\dots) P ( X = k ) = k ! λ k e − λ ( k = 0 , 1 , 2 , … ) 期待値 E [ X ] = λ E[X]=\lambda E [ X ] = λ 分散 V [ X ] = λ V[X]=\lambda V [ X ] = λ 平均=分散 が特徴)MGF M X ( t ) = e λ ( e t − 1 ) M_X(t)=e^{\lambda(e^t-1)} M X ( t ) = e λ ( e t − 1 ) 再生性 独立和 P o i s s o n ( λ 1 ) + P o i s s o n ( λ 2 ) = P o i s s o n ( λ 1 + λ 2 ) \mathrm{Poisson}(\lambda_1)+\mathrm{Poisson}(\lambda_2)=\mathrm{Poisson}(\lambda_1+\lambda_2) Poisson ( λ 1 ) + Poisson ( λ 2 ) = Poisson ( λ 1 + λ 2 ) 由来 二項 B i n ( n , λ / n ) \mathrm{Bin}(n,\lambda/n) Bin ( n , λ / n ) n → ∞ n\to\infty n → ∞ 過程版 時間 t t t N t ∼ P o i s s o n ( λ t ) N_t\sim\mathrm{Poisson}(\lambda t) N t ∼ Poisson ( λ t )
7. 試験での問われ方(級ごとの差)
2級(中核) :PMF λ k e − λ k ! \dfrac{\lambda^k e^{-\lambda}}{k!} k ! λ k e − λ 確率計算 (「平均3人の店に5人来る確率」「平均0.5件の事故が0件の確率=e − 0.5 e^{-0.5} e − 0.5 E = V = λ E=V=\lambda E = V = λ λ = n p \lambda=np λ = n p 二項のポアソン近似 、λ \lambda λ 正規近似 (連続性補正 ± 0.5 \pm0.5 ± 0.5 準1級 :二項からの極限導出 、再生性 (出題実績あり)、ポアソン過程 (N t ∼ P o i s s o n ( λ t ) N_t\sim\mathrm{Poisson}(\lambda t) N t ∼ Poisson ( λ t ) e λ ( e t − 1 ) e^{\lambda(e^t-1)} e λ ( e t − 1 ) E , V E,V E , V 「平均≒分散」によるポアソン妥当性の判断 (過去問あり)。※出題範囲表は改訂されうる。ポアソン過程・再生性・MGFの級の線引きは受験前に最新の範囲表で要最新確認 。
数式の直観的意味
なぜPMFに e − λ e^{-\lambda} e − λ
二項の極限 ( 1 − λ / n ) n → e − λ (1-\lambda/n)^n\to e^{-\lambda} ( 1 − λ / n ) n → e − λ ∑ k λ k / k ! = e λ \sum_k \lambda^k/k!=e^\lambda ∑ k λ k / k ! = e λ 確率の総和を1にする規格化定数 でもある。e e e
なぜ平均=分散なのか
二項の分散 n p ( 1 − p ) np(1-p) n p ( 1 − p ) p → 0 p\to0 p → 0 ( 1 − p ) → 1 (1-p)\to1 ( 1 − p ) → 1 n p = λ np=\lambda n p = λ ( 1 − p ) (1-p) ( 1 − p ) 幾何分布・超幾何分布・負の二項分布 )。
なぜ再生性が無条件なのか
ポアソンはパラメータが λ \lambda λ e λ ( e t − 1 ) e^{\lambda(e^t-1)} e λ ( e t − 1 ) λ \lambda λ ( 1 − p + p e t ) (1-p+pe^t) ( 1 − p + p e t ) p p p
なぜ待ち時間が指数分布になるのか
「次まで t t t [ 0 , t ] [0,t] [ 0 , t ] P ( N t = 0 ) = e − λ t P(N_t=0)=e^{-\lambda t} P ( N t = 0 ) = e − λ t P ( T > t ) = e − λ t P(T>t)=e^{-\lambda t} P ( T > t ) = e − λ t 回数のポアソンと間隔の指数は同じ過程の2つの見方 。
⚠️ 引っかけポイント・頻出論点・級ごとの差
λ \lambda λ k k k λ \lambda λ 2.5 2.5 2.5 k k k 0 , 1 , 2 , … 0,1,2,\dots 0 , 1 , 2 , … λ \lambda λ k k k 「ちょうど」「以上」「少なくとも1回」 :P ( X = k ) P(X=k) P ( X = k ) P ( X ≥ k ) P(X\ge k) P ( X ≥ k ) = 1 − P ( X = 0 ) = 1 − e − λ =1-P(X=0)=1-e^{-\lambda} = 1 − P ( X = 0 ) = 1 − e − λ = P ( 0 ) + P ( 1 ) + P ( 2 ) =P(0)+P(1)+P(2) = P ( 0 ) + P ( 1 ) + P ( 2 ) 二項のどっちの近似か :p p p n p , n ( 1 − p ) ≥ 5 np,n(1-p)\ge5 n p , n ( 1 − p ) ≥ 5 p p p n p np n p p = 0.5 p=0.5 p = 0.5 p = 0.001 p=0.001 p = 0.001 ベルヌーイ分布・二項分布 と対)。ポアソン近似に連続性補正は不要/正規近似には必要 :二項→ポアソンは離散→離散で補正なし。二項→正規・ポアソン→正規は離散→連続で ± 0.5 \pm0.5 ± 0.5 再生性は無条件(独立だけ) :二項は同じ p p p λ \lambda λ λ 1 + λ 2 \lambda_1+\lambda_2 λ 1 + λ 2 平均=分散はポアソンの診断基準 :実データで分散が平均と大きくズレ(特に分散≫平均=過分散)ならポアソン不適。準1級でこの妥当性判断が問われた(負の二項分布などを使う)。ポアソン過程の時間スケール :時間 t t t λ t \lambda t λ t λ \lambda λ N t ∼ P o i s s o n ( λ t ) N_t\sim\mathrm{Poisson}(\lambda t) N t ∼ Poisson ( λ t ) t t t λ t \lambda t λ t 級差 :2級=PMF計算・E = V = λ E=V=\lambda E = V = λ
よくある疑問
Q1. なぜ確率の式に e e e
二項分布の極限を取るときに ( 1 − λ n ) n → e − λ \left(1-\dfrac{\lambda}{n}\right)^n\to e^{-\lambda} ( 1 − n λ ) n → e − λ e − λ e^{-\lambda} e − λ ∑ k λ k / k ! = e λ \sum_k \lambda^k/k!=e^{\lambda} ∑ k λ k / k ! = e λ e e e
Q2. λ \lambda λ
はい。λ \lambda λ 平均回数 なので、λ = 2.5 \lambda=2.5 λ = 2.5 回数 k k k (事象が2.5回起きることはない)。λ \lambda λ k k k
Q3. 二項分布とポアソン分布、結局どっちを使えばいいの?
n n n p p p n n n p p p n ≥ 50 n\ge50 n ≥ 50 p ≤ 0.1 p\le0.1 p ≤ 0.1 λ = n p \lambda=np λ = n p n , p n,p n , p
Q4. 平均と分散が等しいって、本当に成り立つの?実データでズレてたら?
理論上は厳密に E [ X ] = V [ X ] = λ E[X]=V[X]=\lambda E [ X ] = V [ X ] = λ 実データで分散が平均よりかなり大きい 場合は「過分散(overdispersion)」と呼ばれ、ポアソン分布が不適なサインです(負の二項分布などを使う)。「平均≒分散か?」はポアソンが妥当かを診断する目安 になり、準1級ではこの妥当性判断が問われた例があります。
Q5. ポアソン分布に正規近似はできる?連続性補正は?
λ \lambda λ λ ≥ 10 \lambda\ge10 λ ≥ 10 P o i s s o n ( λ ) ≈ N ( λ , λ ) \mathrm{Poisson}(\lambda)\approx N(\lambda,\lambda) Poisson ( λ ) ≈ N ( λ , λ ) λ = 10 \lambda=10 λ = 10 連続性補正 ± 0.5 \pm0.5 ± 0.5 を入れます。2級でポアソンの正規近似を使う問題が出た実績があります。
Q6. 再生性は二項と何が違うの?
二項の再生性は「p p p ベルヌーイ分布・二項分布 )。ポアソンは λ \lambda λ 独立でさえあれば無条件で足せます 。λ 1 + λ 2 \lambda_1+\lambda_2 λ 1 + λ 2
まとめ
ポアソン分布は「稀な事象が一定の時間・空間で何回起きるか 」を表す。PMFは P ( X = k ) = λ k e − λ k ! P(X=k)=\dfrac{\lambda^k e^{-\lambda}}{k!} P ( X = k ) = k ! λ k e − λ λ \lambda λ
二項 B i n ( n , λ / n ) \mathrm{Bin}(n,\lambda/n) Bin ( n , λ / n ) n → ∞ , p → 0 n\to\infty,p\to0 n → ∞ , p → 0 がポアソン。e − λ e^{-\lambda} e − λ ( 1 − λ / n ) n → e − λ (1-\lambda/n)^n\to e^{-\lambda} ( 1 − λ / n ) n → e − λ E [ X ] = V [ X ] = λ E[X]=V[X]=\lambda E [ X ] = V [ X ] = λ M X ( t ) = e λ ( e t − 1 ) M_X(t)=e^{\lambda(e^t-1)} M X ( t ) = e λ ( e t − 1 ) 再生性 :独立なポアソンの和はポアソン(無条件、λ \lambda λ ポアソン過程 :時間 t t t P o i s s o n ( λ t ) \mathrm{Poisson}(\lambda t) Poisson ( λ t ) 待ち時間は指数分布 (次の 指数分布・ガンマ分布・ベータ分布 へ)。級の目安:2級 =PMF計算・E = V = λ E=V=\lambda E = V = λ 準1級 =極限導出・再生性・ポアソン過程・MGF。出題範囲は要最新確認 。
対応するシミュレーション
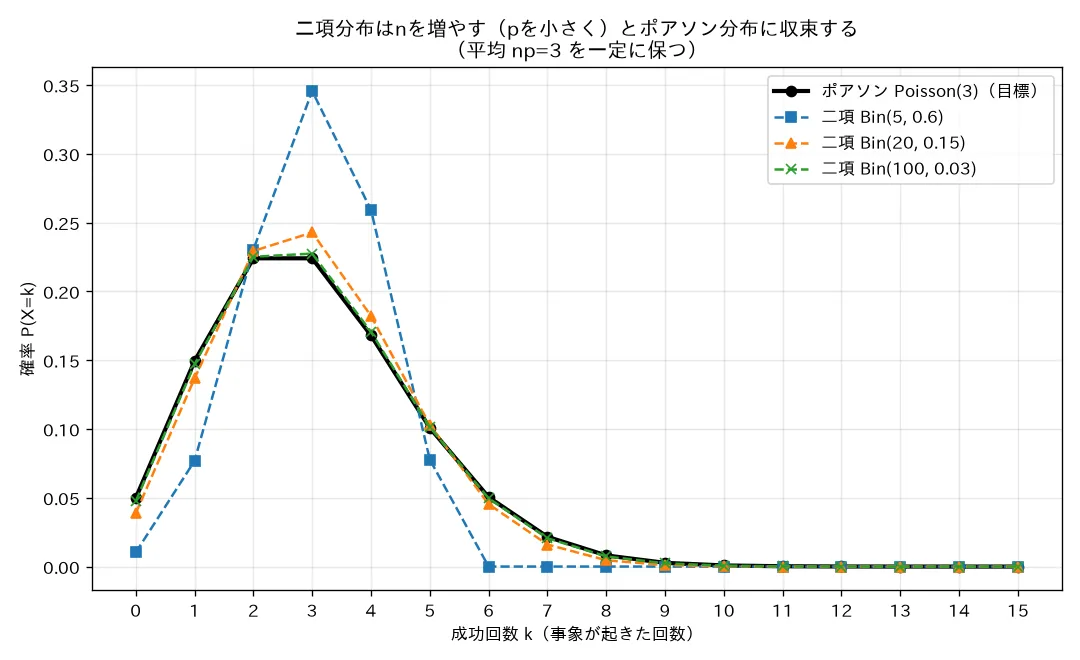
simulations/poisson_bunpu_nikou_shuusoku.py
何を示すか :λ = 3 \lambda=3 λ = 3 B i n ( n , 3 / n ) \mathrm{Bin}(n,3/n) Bin ( n , 3/ n ) n = 5 , 20 , 100 n=5,20,100 n = 5 , 20 , 100 P o i s s o n ( 3 ) \mathrm{Poisson}(3) Poisson ( 3 ) math.factorial+math.exp で手計算(scipy不使用)。最大誤差を出力。結論(seed=0) :最大誤差は n = 5 n=5 n = 5 p = 0.6 p=0.6 p = 0.6 0.12156 、n = 20 n=20 n = 20 p = 0.15 p=0.15 p = 0.15 0.01879 、n = 100 n=100 n = 100 p = 0.03 p=0.03 p = 0.03 0.00343 と単調減少。グラフでも n = 100 n=100 n = 100 二項→ポアソン極限を誤差の数値で裏づけ 。
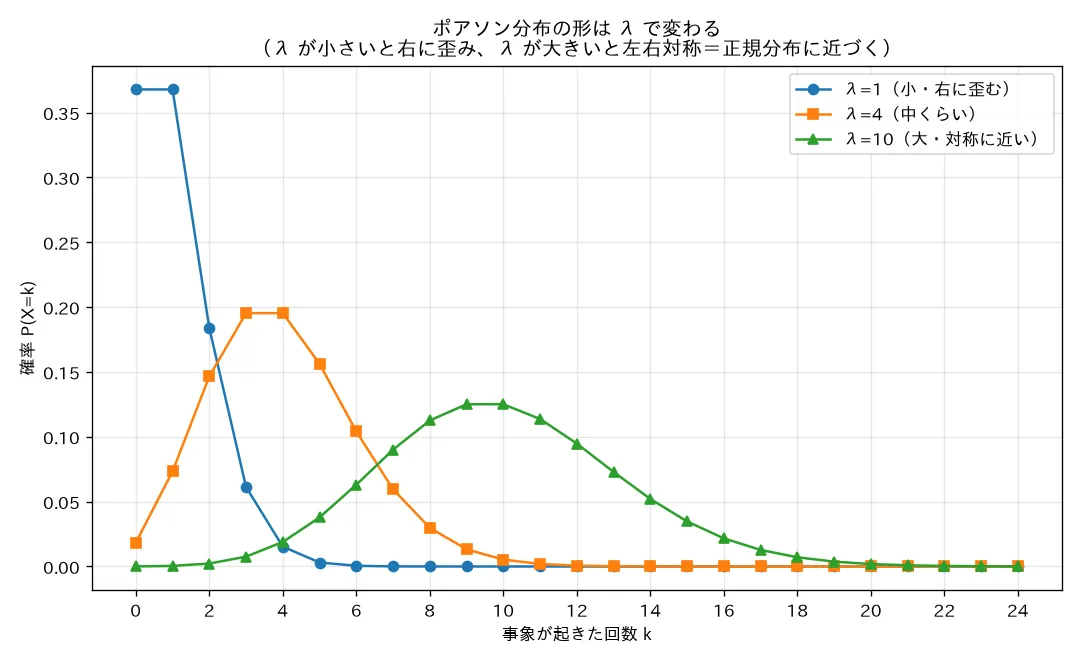
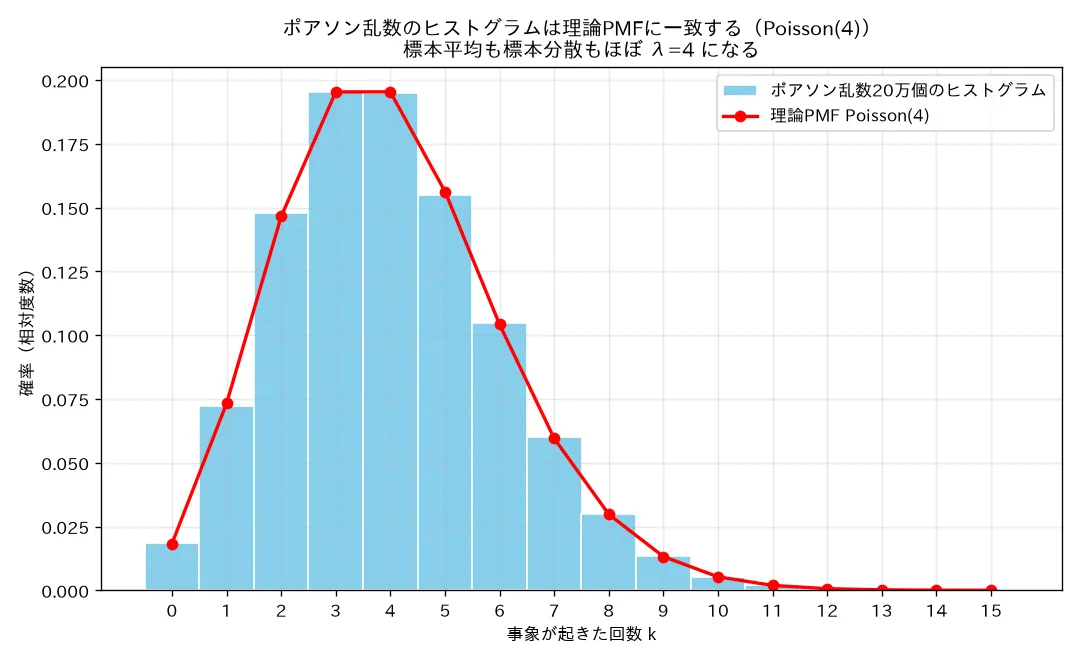
simulations/poisson_bunpu_keijou.py
何を示すか :λ = 1 , 4 , 10 \lambda=1,4,10 λ = 1 , 4 , 10 P o i s s o n ( 4 ) \mathrm{Poisson}(4) Poisson ( 4 ) np.random.poisson)20万個で平均・分散が λ \lambda λ 結論(seed=0) :P o i s s o n ( 4 ) \mathrm{Poisson}(4) Poisson ( 4 ) 標本平均 4.0018・標本分散 3.9983 (理論 λ = 4 \lambda=4 λ = 4 λ = 1 \lambda=1 λ = 1 λ = 10 \lambda=10 λ = 10 E [ X ] = V [ X ] = λ E[X]=V[X]=\lambda E [ X ] = V [ X ] = λ
関連ノート
ベルヌーイ分布・二項分布 (二項分布 ── ポアソンは B i n ( n , λ / n ) \mathrm{Bin}(n,\lambda/n) Bin ( n , λ / n ) n → ∞ n\to\infty n → ∞ p p p 確率変数の変換・モーメント母関数・積率 (変換・モーメント母関数 ── ポアソンMGF e λ ( e t − 1 ) e^{\lambda(e^t-1)} e λ ( e t − 1 ) E , V E,V E , V 確率変数(離散・連続)と期待値・分散 (確率変数・期待値・分散 ── E , V E,V E , V λ \lambda λ 中心極限定理(CLT) (中心極限定理 ── λ \lambda λ N ( λ , λ ) N(\lambda,\lambda) N ( λ , λ ) 幾何分布・超幾何分布・負の二項分布 (幾何・負の二項・超幾何分布 ── 過分散時の負の二項など他の離散分布。前方リンク・Phase 3③)指数分布・ガンマ分布・ベータ分布 (指数分布 ── ポアソン過程の待ち時間。回数=ポアソン/間隔=指数の表裏。前方リンク・Phase 3⑥)