← 統計検定テキスト 一覧
📊 対象級:準1級 | 重要度:B(標準)
指数分布・ガンマ分布・ベータ分布
要点(BLUF)
連続型の重要3分布をまとめて扱います。3行でいうと:
指数分布 E x p ( λ ) \mathrm{Exp}(\lambda) Exp ( λ ) 無記憶性 を持つ。E [ X ] = 1 / λ , V [ X ] = 1 / λ 2 E[X]=1/\lambda,\ V[X]=1/\lambda^2 E [ X ] = 1/ λ , V [ X ] = 1/ λ 2 ガンマ分布 G a ( α , β ) \mathrm{Ga}(\alpha,\beta) Ga ( α , β ) 和 (α \alpha α α \alpha α β \beta β χ 2 \chi^2 χ 2 ベータ分布 B e t a ( a , b ) \mathrm{Beta}(a,b) Beta ( a , b ) [ 0 , 1 ] [0,1] [ 0 , 1 ] 割合・確率そのもの をモデル化し、二項分布の共役事前分布 かつ順序統計量の分布。
f E x p ( x ) = λ e − λ x f G a ( x ) = 1 Γ ( α ) β α x α − 1 e − x / β f B e t a ( x ) = 1 B ( a , b ) x a − 1 ( 1 − x ) b − 1 \boxed{\;f_{\mathrm{Exp}}(x)=\lambda e^{-\lambda x}\quad
f_{\mathrm{Ga}}(x)=\frac{1}{\Gamma(\alpha)\beta^{\alpha}}x^{\alpha-1}e^{-x/\beta}\quad
f_{\mathrm{Beta}}(x)=\frac{1}{B(a,b)}x^{a-1}(1-x)^{b-1}\;} f Exp ( x ) = λ e − λ x f Ga ( x ) = Γ ( α ) β α 1 x α − 1 e − x / β f Beta ( x ) = B ( a , b ) 1 x a − 1 ( 1 − x ) b − 1
(要するに)3つとも「ガンマ関数 Γ \Gamma Γ χ 2 \chi^2 χ 2
分布間の関係(全体地図)
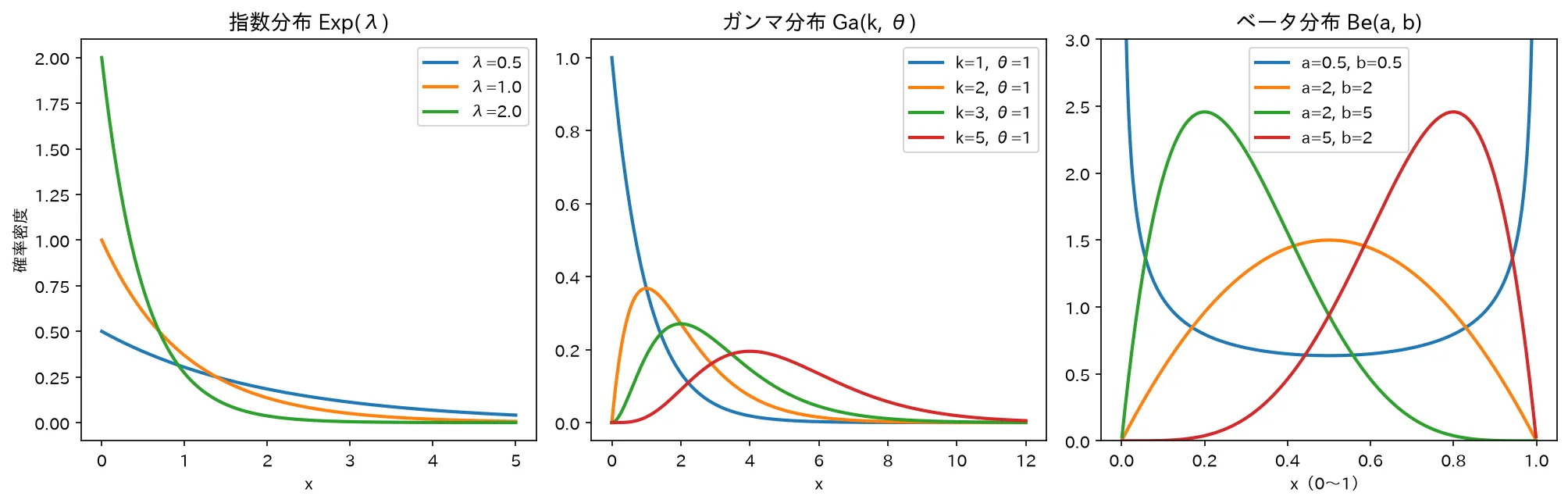
左:指数(率λ)は右下がり/中:ガンマ(形状k)はkで山が右へ/右:ベータ(a,b)はU字〜山型〜偏りと多彩。図は simulations/shisuu_gamma_beta_keijou.py で生成。
まず全体像を掴んでおくと、個々の証明が「地図のどこの話か」見失わずに済みます。
flowchart TD
P["ポアソン過程<br/>(単位時間あたり λ 回)"] -->|"事象間の待ち時間"| E["指数分布 Exp(λ)<br/>= Ga(1, 1/λ)"]
E -->|"独立な α 個の和<br/>(再生性)"| G["ガンマ分布 Ga(α, β)<br/>α 整数ならアーラン分布"]
N["標準正規 N(0,1)"] -->|"2乗の和<br/>Z₁²+…+Zₙ²"| C["カイ二乗分布 χ²(n)<br/>= Ga(n/2, 2)"]
G -->|"α=n/2, β=2"| C
G -->|"X/(X+Y) を作る<br/>X,Y は独立ガンマ"| B["ベータ分布 Beta(a, b)<br/>[0,1] 上"]
B -->|"a=b=1"| U["一様分布 U(0,1)"]
B -->|"二項の共役事前 / 順序統計量"| BAYES["ベイズ推論・順序統計量"]
(要するに)指数分布は最も単純なガンマ分布 (α = 1 \alpha=1 α = 1 カイ二乗分布もガンマ分布の特殊ケース (α = n / 2 , β = 2 \alpha=n/2,\ \beta=2 α = n /2 , β = 2 ガンマ関数 があります。
1. 指数分布 E x p ( λ ) \mathrm{Exp}(\lambda) Exp ( λ )
重要度はこの3分布の中で指数分布が最も高い(A寄り)。準1級では「無記憶性の証明」「待ち時間との対応」「中央値計算」が頻出です。
1.1 定義(PDF・CDF)
事象が単位時間あたり平均 λ \lambda λ ランダムに 起こるとき、ある事象から次の事象までの待ち時間 X X X rate型 (パラメータ λ \lambda λ
f ( x ) = λ e − λ x ( x > 0 ) , F ( x ) = P ( X ≤ x ) = 1 − e − λ x f(x)=\lambda e^{-\lambda x}\quad(x>0),\qquad
F(x)=P(X\le x)=1-e^{-\lambda x} f ( x ) = λ e − λ x ( x > 0 ) , F ( x ) = P ( X ≤ x ) = 1 − e − λ x 生存関数(その時刻まで「まだ起きていない」確率)が指数の本体です:
F ˉ ( x ) = P ( X > x ) = e − λ x \bar F(x)=P(X>x)=e^{-\lambda x} F ˉ ( x ) = P ( X > x ) = e − λ x
(要するに)λ \lambda λ 1 − e − λ x 1-e^{-\lambda x} 1 − e − λ x
1.2 期待値 E [ X ] = 1 / λ E[X]=1/\lambda E [ X ] = 1/ λ
部分積分で計算します。各ステップに意味を添えます。
E [ X ] = ∫ 0 ∞ x ⋅ λ e − λ x d x E[X]=\int_0^\infty x\cdot\lambda e^{-\lambda x}\,dx E [ X ] = ∫ 0 ∞ x ⋅ λ e − λ x d x 部分積分 ∫ u d v = u v − ∫ v d u \int u\,dv = uv-\int v\,du ∫ u d v = uv − ∫ v d u u = x , d v = λ e − λ x d x u=x,\ dv=\lambda e^{-\lambda x}dx u = x , d v = λ e − λ x d x v = − e − λ x v=-e^{-\lambda x} v = − e − λ x
E [ X ] = [ − x e − λ x ] 0 ∞ + ∫ 0 ∞ e − λ x d x = 0 + [ − 1 λ e − λ x ] 0 ∞ = 1 λ E[X]=\Big[-x e^{-\lambda x}\Big]_0^\infty+\int_0^\infty e^{-\lambda x}\,dx
=0+\left[-\frac{1}{\lambda}e^{-\lambda x}\right]_0^\infty=\frac{1}{\lambda} E [ X ] = [ − x e − λ x ] 0 ∞ + ∫ 0 ∞ e − λ x d x = 0 + [ − λ 1 e − λ x ] 0 ∞ = λ 1
(要するに)境界項 − x e − λ x -xe^{-\lambda x} − x e − λ x x → ∞ x\to\infty x → ∞ 0 0 0 x = 0 x=0 x = 0 0 0 0 1 / λ 1/\lambda 1/ λ 平均待ち時間はレートの逆数 という直観そのままです。
1.3 分散 V [ X ] = 1 / λ 2 V[X]=1/\lambda^2 V [ X ] = 1/ λ 2
まず E [ X 2 ] E[X^2] E [ X 2 ] Γ \Gamma Γ
E [ X 2 ] = ∫ 0 ∞ x 2 λ e − λ x d x = 2 λ 2 E[X^2]=\int_0^\infty x^2\lambda e^{-\lambda x}\,dx=\frac{2}{\lambda^2} E [ X 2 ] = ∫ 0 ∞ x 2 λ e − λ x d x = λ 2 2 よって
V [ X ] = E [ X 2 ] − ( E [ X ] ) 2 = 2 λ 2 − 1 λ 2 = 1 λ 2 V[X]=E[X^2]-(E[X])^2=\frac{2}{\lambda^2}-\frac{1}{\lambda^2}=\frac{1}{\lambda^2} V [ X ] = E [ X 2 ] − ( E [ X ] ) 2 = λ 2 2 − λ 2 1 = λ 2 1
(要するに)標準偏差 = 1 / λ = =1/\lambda= = 1/ λ = 指数分布は変動係数 CV = σ / μ = 1 =\sigma/\mu=1 = σ / μ = 1 が常に成り立つのが特徴です。
1.4 積率母関数(MGF)
M X ( t ) = E [ e t X ] = ∫ 0 ∞ e t x λ e − λ x d x = λ ∫ 0 ∞ e − ( λ − t ) x d x = λ λ − t ( t < λ ) M_X(t)=E[e^{tX}]=\int_0^\infty e^{tx}\lambda e^{-\lambda x}\,dx
=\lambda\int_0^\infty e^{-(\lambda-t)x}\,dx=\frac{\lambda}{\lambda-t}\quad(t<\lambda) M X ( t ) = E [ e tX ] = ∫ 0 ∞ e t x λ e − λ x d x = λ ∫ 0 ∞ e − ( λ − t ) x d x = λ − t λ ( t < λ )
(要するに)t < λ t<\lambda t < λ α = 1 \alpha=1 α = 1
1.5 無記憶性(memoryless property)の証明
指数分布の最重要性質 。「すでに s s s
P ( X > s + t ∣ X > s ) = P ( X > t ) ( s , t > 0 ) P(X>s+t \mid X>s)=P(X>t)\qquad(s,t>0) P ( X > s + t ∣ X > s ) = P ( X > t ) ( s , t > 0 ) 証明 :条件付き確率の定義から。{ X > s + t } ⊂ { X > s } \{X>s+t\}\subset\{X>s\} { X > s + t } ⊂ { X > s } { X > s + t } \{X>s+t\} { X > s + t }
P ( X > s + t ∣ X > s ) = P ( X > s + t , X > s ) P ( X > s ) = P ( X > s + t ) P ( X > s ) = e − λ ( s + t ) e − λ s = e − λ t = P ( X > t ) P(X>s+t\mid X>s)
=\frac{P(X>s+t,\ X>s)}{P(X>s)}
=\frac{P(X>s+t)}{P(X>s)}
=\frac{e^{-\lambda(s+t)}}{e^{-\lambda s}}
=e^{-\lambda t}=P(X>t) P ( X > s + t ∣ X > s ) = P ( X > s ) P ( X > s + t , X > s ) = P ( X > s ) P ( X > s + t ) = e − λ s e − λ ( s + t ) = e − λ t = P ( X > t )
(要するに)生存関数が指数関数 だから e − λ ( s + t ) / e − λ s = e − λ t e^{-\lambda(s+t)}/e^{-\lambda s}=e^{-\lambda t} e − λ ( s + t ) / e − λ s = e − λ t
逆も真 :連続型分布で無記憶性を持つのは指数分布のみ です。生存関数 g ( x ) = P ( X > x ) g(x)=P(X>x) g ( x ) = P ( X > x ) g ( s + t ) = g ( s ) g ( t ) g(s+t)=g(s)g(t) g ( s + t ) = g ( s ) g ( t ) g ( x ) = e − λ x g(x)=e^{-\lambda x} g ( x ) = e − λ x
(要するに)「連続で無記憶 ⇒ 指数」は一意。離散版では幾何分布が唯一の無記憶分布で、指数分布はその連続極限です。
1.6 ポアソン過程との関係(待ち時間)
ポアソン分布 と表裏一体です。単位時間あたり平均 λ \lambda λ ポアソン過程 を考えると:
区間 [ 0 , t ] [0,t] [ 0 , t ] N ( t ) ∼ P o i s s o n ( λ t ) N(t)\sim \mathrm{Poisson}(\lambda t) N ( t ) ∼ Poisson ( λ t )
「時刻 t t t ⟺ \iff ⟺ X > t X>t X > t
これを使って指数分布の CDF が直接出ます:
P ( X > t ) = P ( N ( t ) = 0 ) = ( λ t ) 0 e − λ t 0 ! = e − λ t P(X>t)=P(N(t)=0)=\frac{(\lambda t)^0 e^{-\lambda t}}{0!}=e^{-\lambda t} P ( X > t ) = P ( N ( t ) = 0 ) = 0 ! ( λ t ) 0 e − λ t = e − λ t
(要するに)回数を数えればポアソン、間隔を測れば指数 。同じ現象の2つの見方です。λ \lambda λ
2. ガンマ分布 G a ( α , β ) \mathrm{Ga}(\alpha,\beta) Ga ( α , β )
準1級では「指数の和=ガンマ」「再生性」「カイ二乗との対応」が問われます。パラメータ化の流派に注意(後述)。
2.1 ガンマ関数の準備
ガンマ分布の前に、正規化に使うガンマ関数を確認します:
Γ ( α ) = ∫ 0 ∞ t α − 1 e − t d t ( α > 0 ) \Gamma(\alpha)=\int_0^\infty t^{\alpha-1}e^{-t}\,dt\qquad(\alpha>0) Γ ( α ) = ∫ 0 ∞ t α − 1 e − t d t ( α > 0 ) 重要な性質:
Γ ( α + 1 ) = α Γ ( α ) \Gamma(\alpha+1)=\alpha\,\Gamma(\alpha) Γ ( α + 1 ) = α Γ ( α ) Γ ( n ) = ( n − 1 ) ! \Gamma(n)=(n-1)! Γ ( n ) = ( n − 1 )! n n n Γ ( 1 / 2 ) = π \Gamma(1/2)=\sqrt{\pi} Γ ( 1/2 ) = π
(要するに)ガンマ関数は階乗を実数に拡張したもの 。これが分布の「分母(正規化定数)」になります。
2.2 定義(scale型のPDF)── 本ノートの採用流派
本ノートでは α \alpha α β \beta β 尺度 (scale)の scale型 を主に使います:
f ( x ) = 1 Γ ( α ) β α x α − 1 e − x / β ( x > 0 ) , α > 0 , β > 0 f(x)=\frac{1}{\Gamma(\alpha)\,\beta^{\alpha}}\,x^{\alpha-1}e^{-x/\beta}\quad(x>0),\qquad \alpha>0,\ \beta>0 f ( x ) = Γ ( α ) β α 1 x α − 1 e − x / β ( x > 0 ) , α > 0 , β > 0 このとき:
E [ X ] = α β , V [ X ] = α β 2 E[X]=\alpha\beta,\qquad V[X]=\alpha\beta^2 E [ X ] = α β , V [ X ] = α β 2 指数分布との接続 :α = 1 \alpha=1 α = 1 Γ ( 1 ) = 1 \Gamma(1)=1 Γ ( 1 ) = 1 f ( x ) = 1 β e − x / β f(x)=\frac{1}{\beta}e^{-x/\beta} f ( x ) = β 1 e − x / β = β = 1 / λ =\beta=1/\lambda = β = 1/ λ
E x p ( λ ) = G a ( 1 , 1 λ ) \mathrm{Exp}(\lambda)=\mathrm{Ga}\!\left(1,\ \tfrac{1}{\lambda}\right) Exp ( λ ) = Ga ( 1 , λ 1 )
(要するに)形状 α \alpha α β \beta β α \alpha α アーラン分布 です。
2.3 期待値・分散の導出(scale型)
n n n y = x / β y=x/\beta y = x / β
E [ X n ] = ∫ 0 ∞ x n x α − 1 e − x / β Γ ( α ) β α d x = β n Γ ( α ) ∫ 0 ∞ y α + n − 1 e − y d y = β n Γ ( α + n ) Γ ( α ) E[X^n]=\int_0^\infty x^n\frac{x^{\alpha-1}e^{-x/\beta}}{\Gamma(\alpha)\beta^\alpha}dx
=\frac{\beta^n}{\Gamma(\alpha)}\int_0^\infty y^{\alpha+n-1}e^{-y}\,dy
=\frac{\beta^n\,\Gamma(\alpha+n)}{\Gamma(\alpha)} E [ X n ] = ∫ 0 ∞ x n Γ ( α ) β α x α − 1 e − x / β d x = Γ ( α ) β n ∫ 0 ∞ y α + n − 1 e − y d y = Γ ( α ) β n Γ ( α + n ) 漸化式 Γ ( α + 1 ) = α Γ ( α ) \Gamma(\alpha+1)=\alpha\Gamma(\alpha) Γ ( α + 1 ) = α Γ ( α )
E [ X ] = β Γ ( α + 1 ) Γ ( α ) = α β , E [ X 2 ] = β 2 Γ ( α + 2 ) Γ ( α ) = α ( α + 1 ) β 2 E[X]=\frac{\beta\,\Gamma(\alpha+1)}{\Gamma(\alpha)}=\alpha\beta,\qquad
E[X^2]=\frac{\beta^2\,\Gamma(\alpha+2)}{\Gamma(\alpha)}=\alpha(\alpha+1)\beta^2 E [ X ] = Γ ( α ) β Γ ( α + 1 ) = α β , E [ X 2 ] = Γ ( α ) β 2 Γ ( α + 2 ) = α ( α + 1 ) β 2 V [ X ] = α ( α + 1 ) β 2 − ( α β ) 2 = α β 2 V[X]=\alpha(\alpha+1)\beta^2-(\alpha\beta)^2=\alpha\beta^2 V [ X ] = α ( α + 1 ) β 2 − ( α β ) 2 = α β 2
(要するに)置換でガンマ関数の積分(値は Γ ( α + n ) \Gamma(\alpha+n) Γ ( α + n ) α = 1 \alpha=1 α = 1 E = β , V = β 2 E=\beta,\ V=\beta^2 E = β , V = β 2
2.4 「指数の和=ガンマ」の証明(MGF)
主張 :X 1 , … , X α X_1,\dots,X_\alpha X 1 , … , X α X i ∼ E x p ( λ ) = G a ( 1 , 1 / λ ) X_i\sim\mathrm{Exp}(\lambda)=\mathrm{Ga}(1,1/\lambda) X i ∼ Exp ( λ ) = Ga ( 1 , 1/ λ ) S = ∑ i = 1 α X i S=\sum_{i=1}^{\alpha}X_i S = ∑ i = 1 α X i G a ( α , 1 / λ ) \mathrm{Ga}(\alpha,\,1/\lambda) Ga ( α , 1/ λ )
証明 :MGF は独立なら積になる性質を使います。指数分布の MGF は §1.4 より M X i ( t ) = λ λ − t = 1 1 − β t M_{X_i}(t)=\dfrac{\lambda}{\lambda-t}=\dfrac{1}{1-\beta t} M X i ( t ) = λ − t λ = 1 − β t 1 β = 1 / λ \beta=1/\lambda β = 1/ λ
M S ( t ) = ∏ i = 1 α M X i ( t ) = ( 1 1 − β t ) α = ( 1 − β t ) − α ( t < 1 / β ) M_S(t)=\prod_{i=1}^{\alpha}M_{X_i}(t)=\left(\frac{1}{1-\beta t}\right)^{\alpha}=(1-\beta t)^{-\alpha}\quad(t<1/\beta) M S ( t ) = i = 1 ∏ α M X i ( t ) = ( 1 − β t 1 ) α = ( 1 − β t ) − α ( t < 1/ β ) 一方、scale型ガンマ G a ( α , β ) \mathrm{Ga}(\alpha,\beta) Ga ( α , β ) ∫ 0 ∞ e t x f ( x ) d x = ( 1 − β t ) − α \int_0^\infty e^{tx}f(x)dx=(1-\beta t)^{-\alpha} ∫ 0 ∞ e t x f ( x ) d x = ( 1 − β t ) − α S ∼ G a ( α , β ) S\sim\mathrm{Ga}(\alpha,\beta) S ∼ Ga ( α , β )
(要するに)独立な指数の和は MGF がべき乗 になり、それがちょうどガンマの MGF。「待ち時間を α \alpha α α \alpha α
2.5 再生性
ガンマ分布は尺度 β \beta β なら和について閉じています:
X ∼ G a ( α 1 , β ) , Y ∼ G a ( α 2 , β ) , 独立 ⟹ X + Y ∼ G a ( α 1 + α 2 , β ) X\sim\mathrm{Ga}(\alpha_1,\beta),\ Y\sim\mathrm{Ga}(\alpha_2,\beta),\ \text{独立}
\ \Longrightarrow\ X+Y\sim\mathrm{Ga}(\alpha_1+\alpha_2,\beta) X ∼ Ga ( α 1 , β ) , Y ∼ Ga ( α 2 , β ) , 独立 ⟹ X + Y ∼ Ga ( α 1 + α 2 , β ) MGF で ( 1 − β t ) − α 1 ⋅ ( 1 − β t ) − α 2 = ( 1 − β t ) − ( α 1 + α 2 ) (1-\beta t)^{-\alpha_1}\cdot(1-\beta t)^{-\alpha_2}=(1-\beta t)^{-(\alpha_1+\alpha_2)} ( 1 − β t ) − α 1 ⋅ ( 1 − β t ) − α 2 = ( 1 − β t ) − ( α 1 + α 2 )
(要するに)形状パラメータが足し算される。§2.4 の「指数の和」はこの再生性の特殊例(α i = 1 \alpha_i=1 α i = 1 α \alpha α ただし β \beta β (後述の引っかけ)。
2.6 カイ二乗分布との関係
カイ二乗分布はガンマ分布の特殊ケースです(t分布・カイ二乗分布・F分布(標本分布の三役) へ接続):
χ 2 ( n ) = G a ( n 2 , 2 ) \chi^2(n)=\mathrm{Ga}\!\left(\frac{n}{2},\ 2\right) χ 2 ( n ) = Ga ( 2 n , 2 ) scale型の PDF に α = n / 2 , β = 2 \alpha=n/2,\ \beta=2 α = n /2 , β = 2 n n n 1 2 n / 2 Γ ( n / 2 ) x n / 2 − 1 e − x / 2 \dfrac{1}{2^{n/2}\Gamma(n/2)}x^{n/2-1}e^{-x/2} 2 n /2 Γ ( n /2 ) 1 x n /2 − 1 e − x /2
E [ χ 2 ( n ) ] = α β = n 2 ⋅ 2 = n E[\chi^2(n)]=\alpha\beta=\frac{n}{2}\cdot 2=n E [ χ 2 ( n )] = α β = 2 n ⋅ 2 = n V [ χ 2 ( n ) ] = α β 2 = n 2 ⋅ 4 = 2 n V[\chi^2(n)]=\alpha\beta^2=\frac{n}{2}\cdot 4=2n V [ χ 2 ( n )] = α β 2 = 2 n ⋅ 4 = 2 n
(要するに)カイ二乗の「平均=自由度 n n n 2 n 2n 2 n α β , α β 2 \alpha\beta,\ \alpha\beta^2 α β , α β 2 Z ∼ N ( 0 , 1 ) Z\sim N(0,1) Z ∼ N ( 0 , 1 ) Z 2 ∼ χ 2 ( 1 ) = G a ( 1 / 2 , 2 ) Z^2\sim\chi^2(1)=\mathrm{Ga}(1/2,2) Z 2 ∼ χ 2 ( 1 ) = Ga ( 1/2 , 2 )
3. ベータ分布 B e t a ( a , b ) \mathrm{Beta}(a,b) Beta ( a , b )
準1級では「ベイズの共役事前分布」「事後分布の計算」「順序統計量との関係」「期待値・分散の公式」が問われます。
3.1 定義(PDF・定義域)
[ 0 , 1 ] [0,1] [ 0 , 1 ] a > 0 , b > 0 a>0,\ b>0 a > 0 , b > 0
f ( x ) = 1 B ( a , b ) x a − 1 ( 1 − x ) b − 1 ( 0 < x < 1 ) f(x)=\frac{1}{B(a,b)}\,x^{a-1}(1-x)^{b-1}\quad(0<x<1) f ( x ) = B ( a , b ) 1 x a − 1 ( 1 − x ) b − 1 ( 0 < x < 1 ) ここで B ( a , b ) B(a,b) B ( a , b ) ベータ関数 で、ガンマ関数と次の関係を持ちます(これがガンマとベータの接続点):
B ( a , b ) = ∫ 0 1 x a − 1 ( 1 − x ) b − 1 d x = Γ ( a ) Γ ( b ) Γ ( a + b ) B(a,b)=\int_0^1 x^{a-1}(1-x)^{b-1}\,dx=\frac{\Gamma(a)\Gamma(b)}{\Gamma(a+b)} B ( a , b ) = ∫ 0 1 x a − 1 ( 1 − x ) b − 1 d x = Γ ( a + b ) Γ ( a ) Γ ( b ) 統計量は:
E [ X ] = a a + b , V [ X ] = a b ( a + b ) 2 ( a + b + 1 ) E[X]=\frac{a}{a+b},\qquad V[X]=\frac{ab}{(a+b)^2(a+b+1)} E [ X ] = a + b a , V [ X ] = ( a + b ) 2 ( a + b + 1 ) ab
(要するに)x x x 確率や割合そのもの (0〜1の値)を取るときに使う分布。a = b = 1 a=b=1 a = b = 1 U ( 0 , 1 ) U(0,1) U ( 0 , 1 ) a , b a,b a , b
3.2 期待値の導出
ベータ関数とガンマ関数の関係 B ( a , b ) = Γ ( a ) Γ ( b ) Γ ( a + b ) B(a,b)=\dfrac{\Gamma(a)\Gamma(b)}{\Gamma(a+b)} B ( a , b ) = Γ ( a + b ) Γ ( a ) Γ ( b )
E [ X ] = ∫ 0 1 x ⋅ x a − 1 ( 1 − x ) b − 1 B ( a , b ) d x = 1 B ( a , b ) ∫ 0 1 x a ( 1 − x ) b − 1 d x = B ( a + 1 , b ) B ( a , b ) E[X]=\int_0^1 x\cdot\frac{x^{a-1}(1-x)^{b-1}}{B(a,b)}dx
=\frac{1}{B(a,b)}\int_0^1 x^{a}(1-x)^{b-1}dx
=\frac{B(a+1,b)}{B(a,b)} E [ X ] = ∫ 0 1 x ⋅ B ( a , b ) x a − 1 ( 1 − x ) b − 1 d x = B ( a , b ) 1 ∫ 0 1 x a ( 1 − x ) b − 1 d x = B ( a , b ) B ( a + 1 , b ) B ( a + 1 , b ) = Γ ( a + 1 ) Γ ( b ) Γ ( a + b + 1 ) B(a+1,b)=\dfrac{\Gamma(a+1)\Gamma(b)}{\Gamma(a+b+1)} B ( a + 1 , b ) = Γ ( a + b + 1 ) Γ ( a + 1 ) Γ ( b ) Γ ( a + 1 ) = a Γ ( a ) \Gamma(a+1)=a\Gamma(a) Γ ( a + 1 ) = a Γ ( a )
E [ X ] = Γ ( a + 1 ) Γ ( b ) / Γ ( a + b + 1 ) Γ ( a ) Γ ( b ) / Γ ( a + b ) = a Γ ( a ) Γ ( a + b ) Γ ( a ) ( a + b ) Γ ( a + b ) = a a + b E[X]=\frac{\Gamma(a+1)\Gamma(b)/\Gamma(a+b+1)}{\Gamma(a)\Gamma(b)/\Gamma(a+b)}
=\frac{a\,\Gamma(a)\,\Gamma(a+b)}{\Gamma(a)\,(a+b)\Gamma(a+b)}=\frac{a}{a+b} E [ X ] = Γ ( a ) Γ ( b ) /Γ ( a + b ) Γ ( a + 1 ) Γ ( b ) /Γ ( a + b + 1 ) = Γ ( a ) ( a + b ) Γ ( a + b ) a Γ ( a ) Γ ( a + b ) = a + b a
(要するに)積分が「形状を1つずらしたベータ関数」になり、Γ \Gamma Γ a / ( a + b ) a/(a+b) a / ( a + b ) 「成功 a a a b b b a / ( a + b ) a/(a+b) a / ( a + b ) と読めて直観的です。
3.3 用途その1:二項分布の共役事前分布(ベイズ)
ベータ分布の最重要用途。二項分布(コイン投げ等)の成功確率 p p p (共役性)。
成功確率 p p p p ∼ B e t a ( a , b ) p\sim\mathrm{Beta}(a,b) p ∼ Beta ( a , b ) n n n k k k ∝ \propto ∝ × \times ×
π ( p ∣ k ) ∝ p k ( 1 − p ) n − k ⏟ 尤度 ⋅ p a − 1 ( 1 − p ) b − 1 ⏟ 事前 = p ( a + k ) − 1 ( 1 − p ) ( b + n − k ) − 1 \pi(p\mid k)\ \propto\ \underbrace{p^{k}(1-p)^{n-k}}_{\text{尤度}}\cdot\underbrace{p^{a-1}(1-p)^{b-1}}_{\text{事前}}
= p^{(a+k)-1}(1-p)^{(b+n-k)-1} π ( p ∣ k ) ∝ 尤度 p k ( 1 − p ) n − k ⋅ 事前 p a − 1 ( 1 − p ) b − 1 = p ( a + k ) − 1 ( 1 − p ) ( b + n − k ) − 1 右辺は B e t a ( a + k , b + n − k ) \mathrm{Beta}(a+k,\ b+n-k) Beta ( a + k , b + n − k )
p ∣ data ∼ B e t a ( a + k , b + n − k ) p\mid \text{data}\ \sim\ \mathrm{Beta}(a+k,\ b+n-k) p ∣ data ∼ Beta ( a + k , b + n − k )
(要するに)事前の a , b a,b a , b k k k n − k n-k n − k で事後分布が得られる。a , b a,b a , b
3.4 用途その2:順序統計量の分布
互いに独立で一様分布 U ( 0 , 1 ) U(0,1) U ( 0 , 1 ) n n n 第 k k k X ( k ) X_{(k)} X ( k )
X ( k ) ∼ B e t a ( k , n − k + 1 ) X_{(k)}\sim\mathrm{Beta}(k,\ n-k+1) X ( k ) ∼ Beta ( k , n − k + 1 ) 期待値は §3.2 より E [ X ( k ) ] = k n + 1 E[X_{(k)}]=\dfrac{k}{n+1} E [ X ( k ) ] = n + 1 k
(要するに)一様乱数を n n n k k k n + 1 n+1 n + 1 k k k k / ( n + 1 ) k/(n+1) k / ( n + 1 ) B e t a ( 1 , n ) \mathrm{Beta}(1,n) Beta ( 1 , n ) B e t a ( n , 1 ) \mathrm{Beta}(n,1) Beta ( n , 1 )
4. 試験での問われ方(準1級)
トピック 典型的な問われ方 指数分布 無記憶性の証明・適用、中央値 ln 2 / λ \ln 2/\lambda ln 2/ λ ガンマ分布 指数の和であることの証明(MGF)、E = α β , V = α β 2 E=\alpha\beta,\ V=\alpha\beta^2 E = α β , V = α β 2 χ 2 ( n ) = G a ( n / 2 , 2 ) \chi^2(n)=\mathrm{Ga}(n/2,2) χ 2 ( n ) = Ga ( n /2 , 2 ) ベータ分布 ベイズ事後分布の計算(共役)、E = a / ( a + b ) E=a/(a+b) E = a / ( a + b )
出題範囲・配点の細部は年度で変わるため要最新確認 。ワークブックの章立て(連続型分布・ベイズ法の章)では3分布がまとめて扱われる傾向があります。
5. 数式の直観的意味(まとめ)
指数の無記憶性 :生存関数が e − λ x e^{-\lambda x} e − λ x 指数の和=ガンマ :MGF が ( 1 − β t ) − α (1-\beta t)^{-\alpha} ( 1 − β t ) − α α \alpha α α \alpha α ガンマ⊃カイ二乗 :α = n / 2 , β = 2 \alpha=n/2,\ \beta=2 α = n /2 , β = 2 χ 2 \chi^2 χ 2 n n n 2 n 2n 2 n ベータの共役性 :尤度(二項)と事前(ベータ)が同じ p ∙ ( 1 − p ) ∙ p^{\bullet}(1-p)^{\bullet} p ∙ ( 1 − p ) ∙
⚠️ 引っかけポイント・頻出論点
無記憶性は「故障率一定」と同義 。指数分布は経年劣化(時間が経つほど壊れやすい/壊れにくい)を表現できない 。ワイブル分布など他分布が必要。「使い込んだ部品の残り寿命=新品と同じ」は反直観なので狙われます。ガンマのパラメータ化は2流派あり 。混同が最大の落とし穴:
scale型 (本ノート):G a ( α , β ) \mathrm{Ga}(\alpha,\beta) Ga ( α , β ) β \beta β E = α β E=\alpha\beta E = α β e − x / β e^{-x/\beta} e − x / β rate型 :G a ( α , λ ) \mathrm{Ga}(\alpha,\lambda) Ga ( α , λ ) λ \lambda λ = 1 / β =1/\beta = 1/ β E = α / λ E=\alpha/\lambda E = α / λ e − λ x e^{-\lambda x} e − λ x β \beta β 期待値が α β \alpha\beta α β α / β \alpha/\beta α / β になります(要最新確認:使用テキストの定義に合わせること)。
カイ二乗との対応は β = 2 \beta=2 β = 2 G a ( n / 2 , 2 ) \mathrm{Ga}(n/2,2) Ga ( n /2 , 2 ) 。rate型なら G a ( n / 2 , 1 / 2 ) \mathrm{Ga}(n/2,\,1/2) Ga ( n /2 , 1/2 ) ガンマの再生性は「尺度 β \beta β 。β \beta β λ \lambda λ ベータ分布の定義域は [ 0 , 1 ] [0,1] [ 0 , 1 ] 。確率・割合のモデルであり、待ち時間([ 0 , ∞ ) [0,\infty) [ 0 , ∞ ) ベータの a , b a,b a , b :事後は a → a + k a\to a+k a → a + k b → b + n − k b\to b+n-k b → b + n − k a a a n n n
よくある疑問
Q1. 「無記憶性」って結局どういう状態を指すの?
A. **「これまでどれだけ待ったかが、これから先の待ち時間の分布に一切影響しない」**状態です。式で言えば P ( X > s + t ∣ X > s ) = P ( X > t ) P(X>s+t\mid X>s)=P(X>t) P ( X > s + t ∣ X > s ) = P ( X > t )
Q2. ガンマ分布の β \beta β
A. パラメータ化の流派が2つある ためで、数学的にはどちらも正しいです。scale型は β \beta β E = α β E=\alpha\beta E = α β β \beta β λ \lambda λ E = α / β E=\alpha/\beta E = α / β β scale = 1 / λ rate \beta_{\text{scale}}=1/\lambda_{\text{rate}} β scale = 1/ λ rate scipy.stats.gamma は scale 引数、R の dgamma は rate と scale の両方を受けるなど実装でも分かれます。試験では問題文の PDF の指数部(e − x / β e^{-x/\beta} e − x / β e − β x e^{-\beta x} e − β x してください。
Q3. ベータ分布は何を表す分布だと思えばいい?
A. 「割合・確率そのもの」の分布 です。指数・ガンマが「時間(0 0 0 0 0 0 1 1 1 p p p 確率の確率 を表現するのにぴったりで、ベイズ統計で二項分布の事前分布として多用されます。形状も a , b a,b a , b
Q4. なぜベータ分布が二項分布の「共役」事前分布になるの?
A. 尤度と事前が同じ関数形 p ∙ ( 1 − p ) ∙ p^{\bullet}(1-p)^{\bullet} p ∙ ( 1 − p ) ∙ です。二項分布の尤度は p k ( 1 − p ) n − k p^k(1-p)^{n-k} p k ( 1 − p ) n − k p a − 1 ( 1 − p ) b − 1 p^{a-1}(1-p)^{b-1} p a − 1 ( 1 − p ) b − 1 p ( a + k ) − 1 ( 1 − p ) ( b + n − k ) − 1 p^{(a+k)-1}(1-p)^{(b+n-k)-1} p ( a + k ) − 1 ( 1 − p ) ( b + n − k ) − 1
Q5. 指数・ガンマ・カイ二乗・ベータ、頭の中でどう整理すればいい?
A. **「ガンマ分布を親に置く」と整理できます。指数分布は α = 1 \alpha=1 α = 1 α = n / 2 , β = 2 \alpha=n/2,\beta=2 α = n /2 , β = 2 X , Y X,Y X , Y X / ( X + Y ) X/(X+Y) X / ( X + Y ) 「ガンマ関数を骨格に持つ一族」**として束ねるのが、暗記でなく理解で覚えるコツです。
まとめ
指数分布 E x p ( λ ) \mathrm{Exp}(\lambda) Exp ( λ ) E = 1 / λ , V = 1 / λ 2 E=1/\lambda,\ V=1/\lambda^2 E = 1/ λ , V = 1/ λ 2 = 1 =1 = 1 ガンマ分布 G a ( α , β ) \mathrm{Ga}(\alpha,\beta) Ga ( α , β ) α \alpha α E = α β , V = α β 2 E=\alpha\beta,\ V=\alpha\beta^2 E = α β , V = α β 2 χ 2 ( n ) = G a ( n / 2 , 2 ) \chi^2(n)=\mathrm{Ga}(n/2,2) χ 2 ( n ) = Ga ( n /2 , 2 ) パラメータ化の流派(scale / rate)に最大注意 。ベータ分布 B e t a ( a , b ) \mathrm{Beta}(a,b) Beta ( a , b ) [ 0 , 1 ] [0,1] [ 0 , 1 ] E = a / ( a + b ) E=a/(a+b) E = a / ( a + b ) B e t a ( a + k , b + n − k ) \mathrm{Beta}(a+k,b+n-k) Beta ( a + k , b + n − k ) X ( k ) ∼ B e t a ( k , n − k + 1 ) X_{(k)}\sim\mathrm{Beta}(k,n-k+1) X ( k ) ∼ Beta ( k , n − k + 1 ) 3分布すべてガンマ関数 を骨格に持つ親戚で、ガンマを中心に階層的につながっている。
関連ノート