📊 対象級:2級 ・ 準1級 | 重要度:A(頻出)
t分布・カイ二乗分布・F分布(標本分布の三役)
要点(BLUF)
- この3分布は正規母集団から標本を取ったときに、検定統計量が従う分布です。すべて標準正規 から組み立てられます。
- カイ二乗分布 :標準正規を 個独立にとって2乗和したもの。。自由度 =足した個数。分散・適合度・独立性の検定に使う。
- t分布 :標準正規を「カイ二乗を自由度で割って平方根を取ったもの」で割る。。**母平均の検定(母分散 未知のとき)**に使う。
- F分布 :独立な2つのカイ二乗を各々の自由度で割り、その比を取る。。分散比の検定・分散分析に使う。
- 要するに: が「素材」。2乗和すると 、 を で割ると 、2つの の比が 。3つとも自由度というパラメータで形が決まります。
- 試験での要点:2級は分布表を読んで検定値と比較するところまで(定義は使える程度に)。準1級は3分布の定義・導出・相互関係・平均分散まで問われます。
本文
0. なぜ3つも分布が必要なのか(全体像)
統計の検定は「データから作った統計量が、帰無仮説のもとでどんな分布に従うか」を知って初めて成立します。正規母集団 から 個の標本 を取ったとき、何を推定・検定したいかで必要な分布が変わります。
| 知りたいこと | 使う統計量 | 従う分布 | 主な検定 |
|---|---|---|---|
| 母分散 | 母分散の検定、適合度、独立性 | ||
| 母平均 ( 既知) | z検定 | ||
| 母平均 ( 未知) | t検定 | ||
| 2つの母分散の比 | 等分散性の検定、分散分析 |
要するに、「分散を見たい→χ²」「平均を見たい(σ未知)→t」「分散を比べたい→F」。そしてこの3つは独立した発明ではなく、すべて標準正規 から派生する一族です。下の関係図がこのノートの背骨になります。
graph TD
Z["標準正規 Z ~ N(0,1)<br/>(すべての素材)"]
Z -->|"k個を2乗して足す"| CHI["カイ二乗分布<br/>χ²_k = Z₁²+...+Z_k²"]
Z -->|"Z を √(χ²/k) で割る"| T["t分布<br/>t_k = Z ÷ √(χ²_k/k)"]
CHI -.->|"分母に使う"| T
CHI -->|"2つの χ² の比 ÷ 自由度"| F["F分布<br/>F = (χ²₁/k₁) ÷ (χ²₂/k₂)"]
GAMMA["ガンマ分布<br/>Γ(k/2, 1/2)"] -.->|"χ²はガンマの特別な場合"| CHI
T -->|"自由度 k→∞"| Z
T -.->|"t を2乗すると F(1,k)"| F
図の読み方:実線は「この変換で作る」、点線は「内部で使う/極限で一致する」関係。 は の分母にも の分子分母にも現れる「ハブ」です。
1. カイ二乗分布
1-1. 定義
が独立に標準正規分布 に従うとき、その2乗和
が従う分布を、自由度 のカイ二乗分布といいます。要するに「標準正規を 本そろえて、それぞれ2乗して足したもの」。2乗和なので必ず非負()で、左に0という壁がある非対称な分布です。
1-2. PDF(準1級)
これはガンマ分布 そのものです(指数分布・ガンマ分布・ベータ分布)。要するに:カイ二乗分布はガンマ分布の特別な場合(形状 、率 )に過ぎません。だからガンマの性質(再生性・平均・分散)がそのまま流用できます。
1-3. 「 が になる」ことの導出(準1級)
最小単位 、つまり の分布が自由度1のカイ二乗になることを変数変換で示します(確率変数の変換・モーメント母関数・積率)。 に対し の2つの枝があるので、累積分布関数から攻めます。
両辺を で微分(ライプニッツ則、)すると:
を使うと なので、これは上のPDFで とした形にぴったり一致します。要するに:標準正規を1つ2乗しただけで、もう自由度1のカイ二乗が出来上がる。
1-4. 再生性で自由度が足し算される(準1級)
は「 を 個足したもの」です。独立なガンマ(同じ率)は形状が足し算される再生性を持つので、
要するに:カイ二乗どうしを足すと自由度が足される。これが「2乗和の個数=自由度」という直観の数理的裏付けです。
1-5. 平均・分散(準1級)
ガンマ分布 の平均は 、分散は 。 を代入して:
別証(定義から直接): なので 。また (標準正規の4次モーメントは3)なので、独立和で 。要するに:平均は自由度そのもの、分散はその2倍。
1-6. 自由度が形に与える効果(文章+数値表)
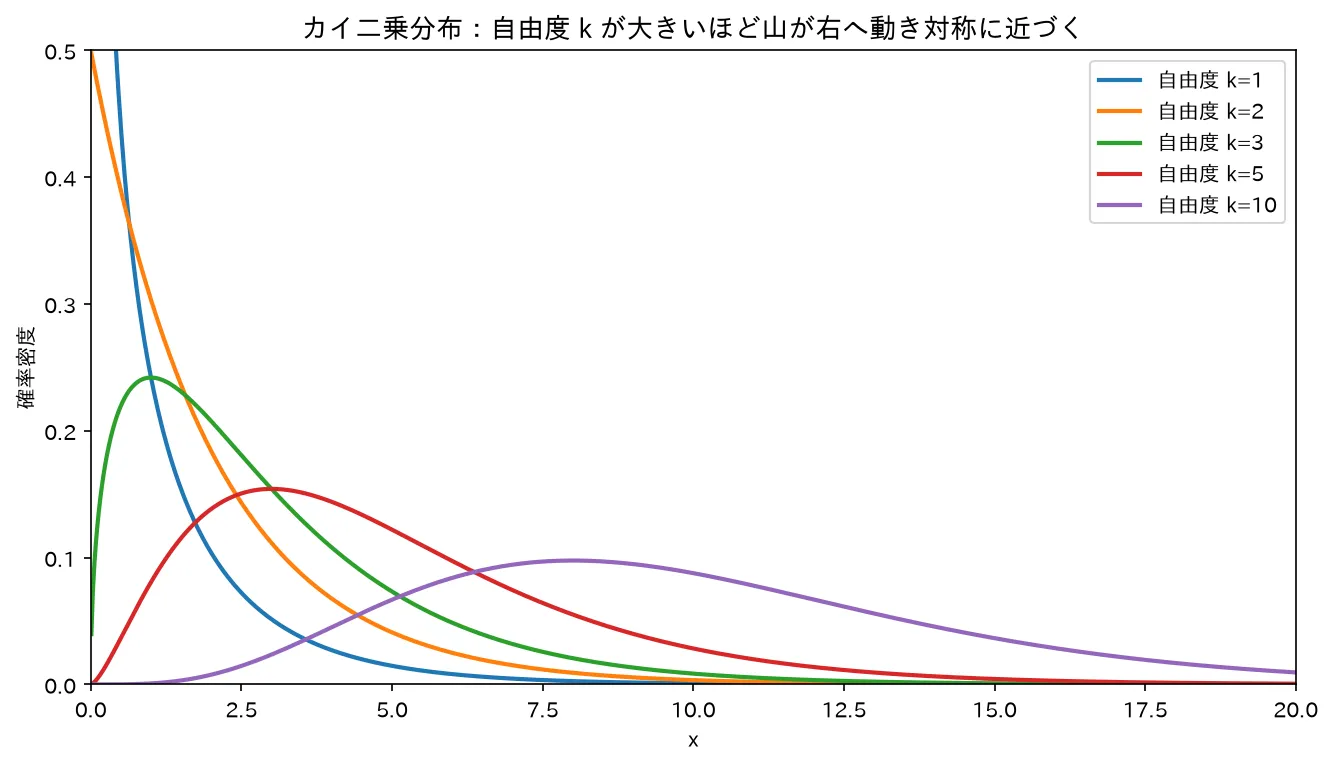
図は simulations/chi2_bunpu_keijou.py で生成。
- :原点付近で密度が無限大に発散・単調減少(右肩下がり)。
- :山ができ、ピーク(最頻値)は の位置。右に長い裾を引く非対称形。
- が大きい:平均 のあたりに山が移り、左右対称に近づく。実際 は で平均 ・分散 の正規分布に近づきます(中心極限定理。2乗和は独立変数の和だから)。
代表的な上側確率の臨界値(試験の分布表で引く値の感覚):
| 自由度 | 平均 | 上側5%点 | 上側1%点 |
|---|---|---|---|
| 1 | 1 | 3.84 | 6.63 |
| 5 | 5 | 11.07 | 15.09 |
| 10 | 10 | 18.31 | 23.21 |
| 20 | 20 | 31.41 | 37.57 |
自由度1の上側5%点 は に一致します( だから、)。
1-7. なぜ「標本分散」がカイ二乗に化けるのか(準1級・最重要)
検定で実際に使うのは「 を 個足す」形ではなく、標本分散 です。正規母集団 からの標本に対し、
が成り立ちます。自由度が ではなく になるのが急所。導出の骨子(コクランの定理の特別な場合):
恒等式 を考えます。
- 左辺は を 個2乗和したものなので (自由度 )。
- 右辺第2項は標本平均を標準化した の2乗なので (自由度1)。
- 正規分布のもとでは標本平均 と標本分散 は独立(正規母集団特有の性質)。よって右辺の2項も独立。
- 再生性は逆向きにも使える: で右の2項が独立なら、 は自由度 のカイ二乗でなければ自由度が合いません()。
要するに:データの散らばり (自由度 )のうち、 という1個の量を推定に使った分(自由度1)が引かれ、残り が分散の情報として になる。「平均を1つ推定したから自由度が1減る」── これが自由度 の正体です。
⚠️ ステップ3「 と の独立」は正規分布だからこそ成り立つ特殊性質。一般の分布では成り立ちません。
1-8. 用途
- 母分散の検定・区間推定: を使う。
- 適合度検定(goodness of fit):観測度数と期待度数のズレ が近似的に 。
- 独立性の検定(分割表):カイ二乗検定(適合度・独立性)。
2. t分布
2-1. 定義
と が独立のとき、
が従う分布を自由度 のt分布といいます。要するに「標準正規 を、カイ二乗を自由度で割って平方根を取ったもの で割る」。分母は「ばらつきの推定値(標準偏差の推定)」に対応します。
2-2. なぜこの形が「σ未知のときの母平均検定」になるのか(準1級・核心)
が既知なら (正規分布表で検定できる)。しかし実際は が分からないので、 を標本標準偏差 で置き換えます。すると分布が正規からズレる。そのズレを正確に表すのがt分布です。
=\frac{\dfrac{\bar X-\mu}{\sigma/\sqrt n}}{\dfrac{S}{\sigma}} =\frac{Z_{\bar X}}{\sqrt{\dfrac{S^2}{\sigma^2}}} =\frac{Z_{\bar X}}{\sqrt{\dfrac{(n-1)S^2/\sigma^2}{n-1}}} =\frac{Z_{\bar X}}{\sqrt{\chi^2_{n-1}/(n-1)}}.$$ ここで分子 $Z_{\bar X}=\frac{\bar X-\mu}{\sigma/\sqrt n}\sim N(0,1)$、分母の中身 $\frac{(n-1)S^2}{\sigma^2}\sim\chi^2_{n-1}$(1-7で示した)。しかも正規母集団では $\bar X\perp S^2$ なので分子と分母が独立。これはまさにt分布の定義そのもの。よって $$\boxed{\;\frac{\bar X-\mu}{S/\sqrt n}\sim t_{n-1}\;}$$ **要するに**:「$\sigma$ を $S$ で代用した」というただ1点の違いが、分母にカイ二乗を呼び込み、$N(0,1)$ を $t_{n-1}$ に変える。分母 $S$ 自身がばらつく(推定誤差を持つ)ぶん、t分布は正規より**裾が重い**のです。 #### 2-3. 形と性質(文章+数値表)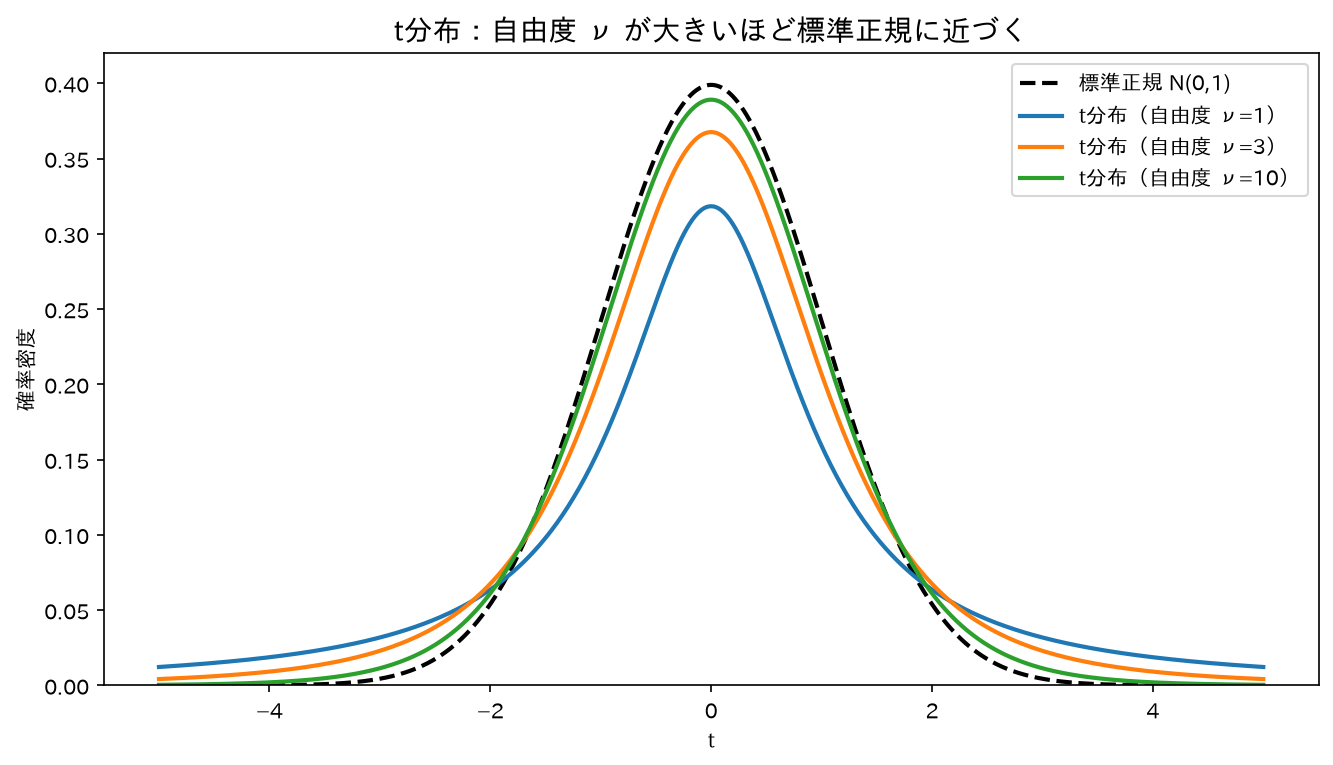 図は `simulations/t_bunpu_keijou.py` で生成。
- **左右対称**(平均0まわり)。標準正規によく似た釣鐘型。
- **正規より裾が重い(fat tail)**:中心が低く、両裾が厚い。$\sigma$ を推定で代用した不確実性が、極端な値の出やすさとして現れるため。
- **自由度が小さいほど裾が重い**。$k=1$ は**コーシー分布**で、平均すら存在しない極端な分布。
- **$k\to\infty$ で標準正規 $N(0,1)$ に一致**(下の2-5)。
代表的な**上側2.5%点 $t_{0.025}(k)$**(両側95%・信頼区間の係数。正規の1.96と比較):
| 自由度 $k$ | $t_{0.025}(k)$ | 正規との差 |
|---|---|---|
| 1 | 12.71 | 桁違いに大きい(裾が極端に重い) |
| 5 | 2.571 | まだかなり大きい |
| 10 | 2.228 | 大きめ |
| 30 | 2.042 | 1.96 に近い |
| 100 | 1.984 | ほぼ1.96 |
| $\infty$ | 1.960 | 正規と一致 |
> **要するに**:標本が小さい(自由度が小さい)ほど臨界値が大きく、信頼区間が広がる。「少ないデータでは確信を持てないから幅を広く取る」が数値に表れています。$n\gtrsim30$ で実用上は正規で代用可。
#### 2-4. 平均・分散(準1級)
$$E[t_k]=0\ (k>1),\qquad V[t_k]=\frac{k}{k-2}\ (k>2).$$
$V[t_k]=\frac{k}{k-2}>1$ なので**常に標準正規(分散1)より分散が大きい**=裾が重い。$k\to\infty$ で $\frac{k}{k-2}\to1$ となり正規の分散に一致。$k=1,2$ では分散が発散(裾が重すぎて定義されない)。
#### 2-5. $k\to\infty$ で標準正規になる理由(準1級)
定義 $t_k=\dfrac{Z}{\sqrt{\chi^2_k/k}}$ の**分母**に注目。$\chi^2_k/k=\frac{1}{k}\sum_{i=1}^k Z_i^2$ は「$Z_i^2$ の標本平均」で、$E[Z_i^2]=1$。大数の法則(大数の法則(弱法則・強法則))より $k\to\infty$ で
$$\frac{\chi^2_k}{k}=\frac1k\sum_{i=1}^k Z_i^2\ \xrightarrow{\ p\ }\ E[Z^2]=1.$$
よって分母 $\sqrt{\chi^2_k/k}\to1$ となり、$t_k\to Z\sim N(0,1)$。**要するに**:標本が増えると $S^2$ が $\sigma^2$ にほぼ等しくなり、「$\sigma$ を $S$ で代用した不確実性」が消える。だから自由度が大きいとt分布は正規に戻る。
#### 2-6. 用途
- **母平均の検定(1標本・対応のある2標本)**:$\sigma$ 未知のt検定。母平均の検定(1標本・2標本t検定)。
- **母平均の区間推定**:信頼区間の係数に $t_{n-1}$ の臨界値を使う。区間推定(母平均・母比率・母分散の信頼区間)。
- **回帰係数の検定**:分散分析 と並ぶ線形モデルの基礎。
---
### 3. F分布 $F_{k_1,k_2}$
#### 3-1. 定義
$U\sim\chi^2_{k_1}$ と $V\sim\chi^2_{k_2}$ が**独立**のとき、それぞれを自由度で割った比
$$\boxed{\;F_{k_1,k_2}=\frac{U/k_1}{V/k_2}=\frac{\chi^2_{k_1}/k_1}{\chi^2_{k_2}/k_2}\;}$$
が従う分布を**自由度 $(k_1,k_2)$ のF分布**といいます。$k_1$ を**第1自由度(分子)**、$k_2$ を**第2自由度(分母)**と呼びます。**要するに**「2つのカイ二乗を、それぞれ自由度で割って平らにしてから、比を取ったもの」。比なので**必ず非負**($F\ge0$)。
> なぜ各々を自由度で割るのか:$\chi^2_k/k$ は平均が $k/k=1$。つまり「自由度で割って基準化したカイ二乗」は平均1。その比を取ることで「2つの分散推定が同じくらいなら $F\approx1$」という直感に合う指標になります。
#### 3-2. なぜ「分散比の検定」になるのか(準1級)
2つの独立な正規母集団 $N(\mu_1,\sigma_1^2),\ N(\mu_2,\sigma_2^2)$ から標本を取り、標本分散 $S_1^2,S_2^2$ を作ると、1-7より
$$\frac{(n_1-1)S_1^2}{\sigma_1^2}\sim\chi^2_{n_1-1},\qquad\frac{(n_2-1)S_2^2}{\sigma_2^2}\sim\chi^2_{n_2-1}.$$
これらを定義に代入すると($(n_i-1)$ が約分されて消える):
$$\frac{\chi^2_{n_1-1}/(n_1-1)}{\chi^2_{n_2-1}/(n_2-1)}=\frac{S_1^2/\sigma_1^2}{S_2^2/\sigma_2^2}\sim F_{n_1-1,\,n_2-1}.$$
帰無仮説 $\sigma_1^2=\sigma_2^2$(等分散)のもとでは $\sigma$ が約分され、
$$\boxed{\;\frac{S_1^2}{S_2^2}\sim F_{n_1-1,\,n_2-1}\quad(\sigma_1^2=\sigma_2^2\text{ のとき})\;}$$
**要するに**:2つの分散推定の比が、帰無仮説のもとでちょうどF分布に従う。だから「分散が等しいか」をFで検定できる(分散分析 の核心も、群間分散と群内分散の比=F)。
#### 3-3. 平均・分散(準1級)
$$E[F_{k_1,k_2}]=\frac{k_2}{k_2-2}\ (k_2>2),\qquad V[F_{k_1,k_2}]=\frac{2k_2^2(k_1+k_2-2)}{k_1(k_2-2)^2(k_2-4)}\ (k_2>4).$$
平均が**第2自由度だけ**で決まり、$k_2>2$ で $\frac{k_2}{k_2-2}>1$(1より少し大きい)点に注意。「分散が等しければ $F\approx1$」という直感どおり、平均は1の近くにあります。
#### 3-4. 非対称性と「逆数関係」(準1級・引っかけ)
F分布は**非対称**(左に0の壁、右に長い裾)。さらに、分子と分母を入れ替えると逆数になるので、自由度の順序を入れ替えた分布と次の関係が成り立ちます:
$$\boxed{\;F_{\alpha}(k_1,k_2)=\frac{1}{F_{1-\alpha}(k_2,k_1)}\;}$$
ここで $F_\alpha(k_1,k_2)$ は上側確率 $\alpha$ の臨界値。**要するに**:F分布表はふつう上側(右の裾)の臨界値しか載っていないので、**下側の臨界値が要るときは「自由度を入れ替えた上側臨界値の逆数」で求める**。定義 $F_{k_1,k_2}=1/F_{k_2,k_1}$(分子分母を入れ替えると逆数)から従います。
図は `simulations/t_bunpu_keijou.py` で生成。
- **左右対称**(平均0まわり)。標準正規によく似た釣鐘型。
- **正規より裾が重い(fat tail)**:中心が低く、両裾が厚い。$\sigma$ を推定で代用した不確実性が、極端な値の出やすさとして現れるため。
- **自由度が小さいほど裾が重い**。$k=1$ は**コーシー分布**で、平均すら存在しない極端な分布。
- **$k\to\infty$ で標準正規 $N(0,1)$ に一致**(下の2-5)。
代表的な**上側2.5%点 $t_{0.025}(k)$**(両側95%・信頼区間の係数。正規の1.96と比較):
| 自由度 $k$ | $t_{0.025}(k)$ | 正規との差 |
|---|---|---|
| 1 | 12.71 | 桁違いに大きい(裾が極端に重い) |
| 5 | 2.571 | まだかなり大きい |
| 10 | 2.228 | 大きめ |
| 30 | 2.042 | 1.96 に近い |
| 100 | 1.984 | ほぼ1.96 |
| $\infty$ | 1.960 | 正規と一致 |
> **要するに**:標本が小さい(自由度が小さい)ほど臨界値が大きく、信頼区間が広がる。「少ないデータでは確信を持てないから幅を広く取る」が数値に表れています。$n\gtrsim30$ で実用上は正規で代用可。
#### 2-4. 平均・分散(準1級)
$$E[t_k]=0\ (k>1),\qquad V[t_k]=\frac{k}{k-2}\ (k>2).$$
$V[t_k]=\frac{k}{k-2}>1$ なので**常に標準正規(分散1)より分散が大きい**=裾が重い。$k\to\infty$ で $\frac{k}{k-2}\to1$ となり正規の分散に一致。$k=1,2$ では分散が発散(裾が重すぎて定義されない)。
#### 2-5. $k\to\infty$ で標準正規になる理由(準1級)
定義 $t_k=\dfrac{Z}{\sqrt{\chi^2_k/k}}$ の**分母**に注目。$\chi^2_k/k=\frac{1}{k}\sum_{i=1}^k Z_i^2$ は「$Z_i^2$ の標本平均」で、$E[Z_i^2]=1$。大数の法則(大数の法則(弱法則・強法則))より $k\to\infty$ で
$$\frac{\chi^2_k}{k}=\frac1k\sum_{i=1}^k Z_i^2\ \xrightarrow{\ p\ }\ E[Z^2]=1.$$
よって分母 $\sqrt{\chi^2_k/k}\to1$ となり、$t_k\to Z\sim N(0,1)$。**要するに**:標本が増えると $S^2$ が $\sigma^2$ にほぼ等しくなり、「$\sigma$ を $S$ で代用した不確実性」が消える。だから自由度が大きいとt分布は正規に戻る。
#### 2-6. 用途
- **母平均の検定(1標本・対応のある2標本)**:$\sigma$ 未知のt検定。母平均の検定(1標本・2標本t検定)。
- **母平均の区間推定**:信頼区間の係数に $t_{n-1}$ の臨界値を使う。区間推定(母平均・母比率・母分散の信頼区間)。
- **回帰係数の検定**:分散分析 と並ぶ線形モデルの基礎。
---
### 3. F分布 $F_{k_1,k_2}$
#### 3-1. 定義
$U\sim\chi^2_{k_1}$ と $V\sim\chi^2_{k_2}$ が**独立**のとき、それぞれを自由度で割った比
$$\boxed{\;F_{k_1,k_2}=\frac{U/k_1}{V/k_2}=\frac{\chi^2_{k_1}/k_1}{\chi^2_{k_2}/k_2}\;}$$
が従う分布を**自由度 $(k_1,k_2)$ のF分布**といいます。$k_1$ を**第1自由度(分子)**、$k_2$ を**第2自由度(分母)**と呼びます。**要するに**「2つのカイ二乗を、それぞれ自由度で割って平らにしてから、比を取ったもの」。比なので**必ず非負**($F\ge0$)。
> なぜ各々を自由度で割るのか:$\chi^2_k/k$ は平均が $k/k=1$。つまり「自由度で割って基準化したカイ二乗」は平均1。その比を取ることで「2つの分散推定が同じくらいなら $F\approx1$」という直感に合う指標になります。
#### 3-2. なぜ「分散比の検定」になるのか(準1級)
2つの独立な正規母集団 $N(\mu_1,\sigma_1^2),\ N(\mu_2,\sigma_2^2)$ から標本を取り、標本分散 $S_1^2,S_2^2$ を作ると、1-7より
$$\frac{(n_1-1)S_1^2}{\sigma_1^2}\sim\chi^2_{n_1-1},\qquad\frac{(n_2-1)S_2^2}{\sigma_2^2}\sim\chi^2_{n_2-1}.$$
これらを定義に代入すると($(n_i-1)$ が約分されて消える):
$$\frac{\chi^2_{n_1-1}/(n_1-1)}{\chi^2_{n_2-1}/(n_2-1)}=\frac{S_1^2/\sigma_1^2}{S_2^2/\sigma_2^2}\sim F_{n_1-1,\,n_2-1}.$$
帰無仮説 $\sigma_1^2=\sigma_2^2$(等分散)のもとでは $\sigma$ が約分され、
$$\boxed{\;\frac{S_1^2}{S_2^2}\sim F_{n_1-1,\,n_2-1}\quad(\sigma_1^2=\sigma_2^2\text{ のとき})\;}$$
**要するに**:2つの分散推定の比が、帰無仮説のもとでちょうどF分布に従う。だから「分散が等しいか」をFで検定できる(分散分析 の核心も、群間分散と群内分散の比=F)。
#### 3-3. 平均・分散(準1級)
$$E[F_{k_1,k_2}]=\frac{k_2}{k_2-2}\ (k_2>2),\qquad V[F_{k_1,k_2}]=\frac{2k_2^2(k_1+k_2-2)}{k_1(k_2-2)^2(k_2-4)}\ (k_2>4).$$
平均が**第2自由度だけ**で決まり、$k_2>2$ で $\frac{k_2}{k_2-2}>1$(1より少し大きい)点に注意。「分散が等しければ $F\approx1$」という直感どおり、平均は1の近くにあります。
#### 3-4. 非対称性と「逆数関係」(準1級・引っかけ)
F分布は**非対称**(左に0の壁、右に長い裾)。さらに、分子と分母を入れ替えると逆数になるので、自由度の順序を入れ替えた分布と次の関係が成り立ちます:
$$\boxed{\;F_{\alpha}(k_1,k_2)=\frac{1}{F_{1-\alpha}(k_2,k_1)}\;}$$
ここで $F_\alpha(k_1,k_2)$ は上側確率 $\alpha$ の臨界値。**要するに**:F分布表はふつう上側(右の裾)の臨界値しか載っていないので、**下側の臨界値が要るときは「自由度を入れ替えた上側臨界値の逆数」で求める**。定義 $F_{k_1,k_2}=1/F_{k_2,k_1}$(分子分母を入れ替えると逆数)から従います。
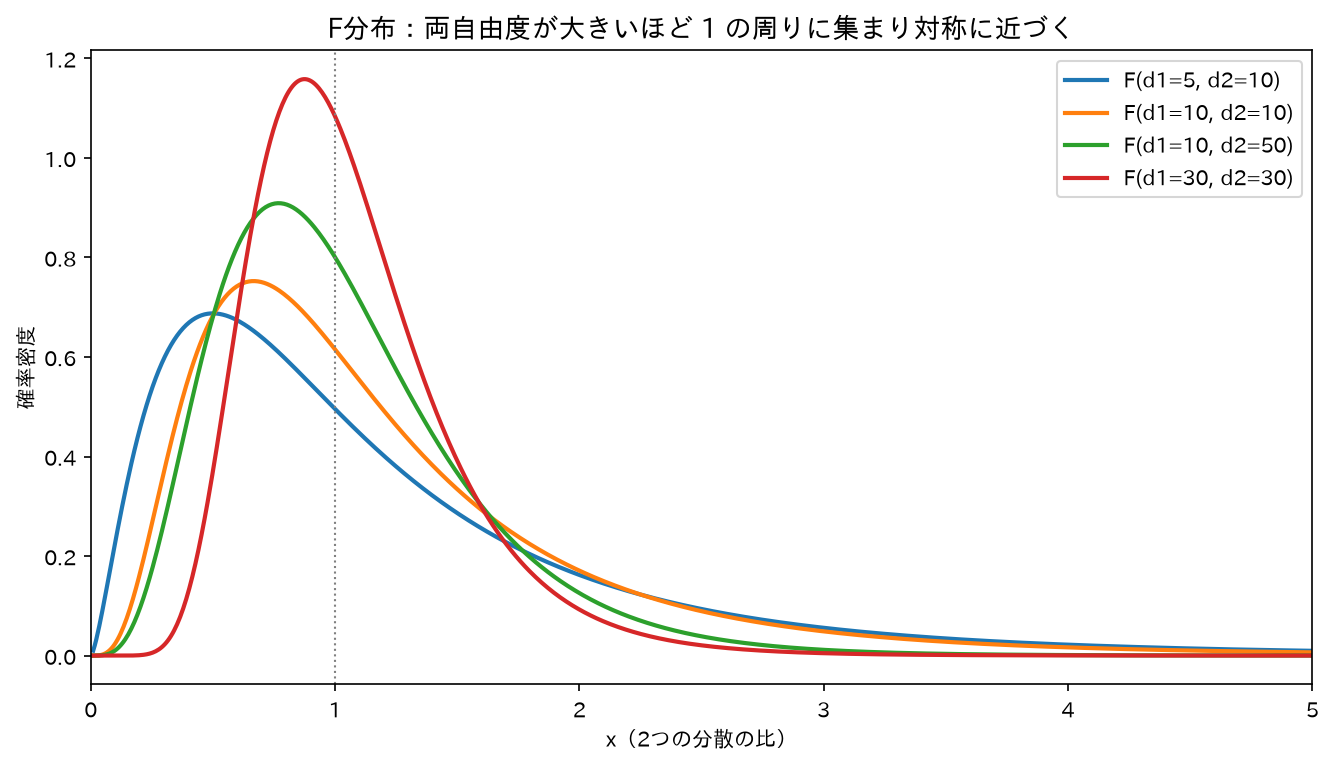 図は `simulations/f_bunpu_keijou.py` で生成。
代表的な**上側5%点 $F_{0.05}(k_1,k_2)$**(分子自由度×分母自由度で変わる):
| $k_1\backslash k_2$ | 5 | 10 | 20 |
|---|---|---|---|
| 1 | 6.61 | 4.96 | 4.35 |
| 5 | 5.05 | 3.33 | 2.71 |
| 10 | 4.74 | 2.98 | 2.35 |
> 自由度の順序が変わると値が変わる($F_{0.05}(1,10)=4.96\ne F_{0.05}(10,1)$)。**分子・分母を取り違えない**こと。
#### 3-5. 用途
- **2標本の等分散性の検定**:$S_1^2/S_2^2$。
- **分散分析(ANOVA)**:群間変動と群内変動の比=F。分散分析。
- **回帰の有意性検定**:説明された変動と残差変動の比=F。
---
### 4. 3分布の相互関係(まとめ図)
3つは独立ではなく、互いに**特別な場合で重なり合います**。
```mermaid
graph LR
subgraph 素材
Z["Z ~ N(0,1)"]
end
Z -->|"2乗和 k個"| C["χ²_k"]
Z -->|"Z÷√(χ²/k)"| T["t_k"]
C -->|"比 ÷自由度"| F["F(k1,k2)"]
T -->|"t を2乗"| F1["= F(1, k)"]
C -->|"k1=1, k2→∞"| Z2["Z²と一致"]
T -->|"k→∞"| Z3["→ N(0,1)"]
C -->|"k→∞"| N2["→ 正規(平均k,分散2k)"]
```
押さえるべき重なり:
| 関係 | 式 | 意味 |
|---|---|---|
| $Z^2=\chi^2_1$ | 標準正規の2乗=自由度1のカイ二乗 | χ²の最小単位 |
| $t_k^2=F_{1,k}$ | t分布を2乗するとF分布(分子自由度1) | t検定と2群の分散分析が一致する理由 |
| $t_\infty=N(0,1)$ | 自由度大でtは正規 | $n\gtrsim30$ で正規近似 |
| $\chi^2_k\to N(k,2k)$ | 自由度大でχ²は正規 | 2乗和への中心極限定理 |
| $k_1F_{k_1,k_2}\to\chi^2_{k_1}$ | $k_2\to\infty$ でF×自由度はカイ二乗 | 分母の分散推定が真値に収束 |
**$t_k^2=F_{1,k}$ の確認**:$t_k=\dfrac{Z}{\sqrt{\chi^2_k/k}}$ を2乗すると $t_k^2=\dfrac{Z^2}{\chi^2_k/k}=\dfrac{\chi^2_1/1}{\chi^2_k/k}=F_{1,k}$。$Z^2=\chi^2_1$ を使うだけ。**要するに**:t統計量を2乗すればF統計量になる。だから「2群の平均の差のt検定」と「2水準の一元配置分散分析(F検定)」は同じ結論を出します。
---
### 5. 数値例
#### 例1:χ²で母分散を検定(2級〜準1級)
ある工程の製品重量が正規分布に従うとされ、母分散 $\sigma^2=4$(仕様)。$n=11$ 個を測ったら標本分散 $S^2=7.2$ だった。「分散が仕様より大きいか」を上側5%で検定する。
- 検定統計量 $\displaystyle\frac{(n-1)S^2}{\sigma^2}=\frac{10\times7.2}{4}=18.0$。
- 帰無仮説 $\sigma^2=4$ のもとで $\chi^2_{10}$ に従う。上側5%点 $\chi^2_{0.05}(10)=18.31$。
- $18.0<18.31$ なので**棄却できない**(5%水準では「分散が大きい」とは言えない)。
> 自由度は $n-1=10$(標本平均を1つ使うので10)。これを $n=11$ にしない。
#### 例2:tで母平均を区間推定(2級〜準1級)
母標準偏差 $\sigma$ 未知。$n=16$ の標本で $\bar X=52.0$、標本標準偏差 $S=8.0$。母平均の95%信頼区間は?
- 自由度 $n-1=15$、両側95%の臨界値 $t_{0.025}(15)=2.131$。
- 区間 $\displaystyle\bar X\pm t_{0.025}(15)\frac{S}{\sqrt n}=52.0\pm2.131\times\frac{8.0}{\sqrt{16}}=52.0\pm2.131\times2.0=52.0\pm4.26$。
- よって **$[47.74,\ 56.26]$**。
> もし $\sigma$ 既知で正規を使えば係数は1.96で幅が狭くなる。$\sigma$ 未知ぶん t の2.131で幅が広がる=推定の不確実性が幅に反映される。
#### 例3:Fで等分散を検定(準1級)
2工程の分散を比較。工程A:$n_1=8,\ S_1^2=25$。工程B:$n_2=11,\ S_2^2=10$。等分散を上側5%で検定($H_1:\sigma_1^2>\sigma_2^2$)。
- 検定統計量 $\displaystyle F=\frac{S_1^2}{S_2^2}=\frac{25}{10}=2.5$。
- 帰無仮説のもとで $F_{n_1-1,\,n_2-1}=F_{7,10}$ に従う。上側5%点 $F_{0.05}(7,10)\approx3.14$。
- $2.5<3.14$ なので**棄却できない**。
> 自由度の順序は(分子の自由度, 分母の自由度)=$(7,10)$。大きい分散を分子に置く慣習。
---
### 6. 試験での問われ方(級ごとの差)
| 観点 | 2級 | 準1級 |
|---|---|---|
| 分布の定義 | 「χ²=正規の2乗和」程度を知っていればよい | $\chi^2,t,F$ を $Z$ から組み立てる定義式を書ける |
| 導出 | 不要(結果を使う) | $Z^2=\chi^2_1$、$\frac{(n-1)S^2}{\sigma^2}\sim\chi^2_{n-1}$、t・Fの構成を導出 |
| 自由度 | $n-1$ などの値を正しく使える | なぜ $n-1$ かをコクラン/独立性で説明できる |
| 分布表 | **読んで検定値と比較するのが主**(最頻出) | 同左+逆数関係・近似 |
| 平均・分散 | 暗記レベル($E[\chi^2]=k$ 等) | 導出・$F,t$ の平均分散まで |
| 相互関係 | $t\to$正規(大標本でzで代用)程度 | $t^2=F_{1,k}$、$\chi^2\to$正規 など |
```mermaid
flowchart TD
Q["何を検定する?"] --> V{"対象は?"}
V -->|"1つの母分散"| CHI["χ²検定<br/>(n−1)S²÷σ² を χ²(n−1) と比較"]
V -->|"母平均 σ未知"| TT["t検定<br/>(X̄−μ)÷(S÷√n) を t(n−1) と比較"]
V -->|"2つの母分散の比"| FF["F検定<br/>S₁²÷S₂² を F(n₁−1, n₂−1) と比較"]
V -->|"3群以上の平均"| AN["分散分析(F検定)<br/>群間÷群内 を F と比較"]
```
---
## ⚠️ 引っかけポイント
1. **自由度の取り違え(最頻出)**。標本分散から作る χ² は自由度 $n-1$($n$ ではない)。t検定も自由度 $n-1$。F検定は $(n_1-1,\ n_2-1)$ の**2つ**。「平均を推定した数だけ自由度が減る」が原則。例1で $\chi^2_{11}$ としない、例2で $t_{16}$ としない。
2. **σ既知(z)とσ未知(t)の使い分け**。母分散が分かっている/大標本なら $z$(正規)、母分散未知の小〜中標本は $t$。「$S$ を使ったら $t$」が合図。$n$ が大きければ $t\approx z$ なので近似的に正規でよいが、小標本で正規を使うと区間が狭すぎて**過信**になる。
3. **F分布の非対称・自由度の順序**。F は左右非対称(χ²やtと違い、tのような対称性はない)。$F_{0.05}(7,10)\ne F_{0.05}(10,7)$。分子・分母の自由度を入れ替えてはいけない。下側臨界値は逆数関係 $F_\alpha(k_1,k_2)=1/F_{1-\alpha}(k_2,k_1)$ で求める。
4. **「自由度」を「標本サイズ」と混同**。自由度は「自由に動ける成分の数」であって標本数そのものではない。χ²の自由度=2乗和した独立な標準正規の本数。標本分散では制約 $\sum(X_i-\bar X)=0$ が1本入るので $n-1$。
5. **t分布の裾が重いことを忘れる**。t分布は正規より裾が重く、臨界値が大きい($t_{0.025}(5)=2.571>1.96$)。「正規と同じ1.96」で小標本の信頼区間を作るのは誤り。自由度が小さいほど差が大きい。
6. **χ²・F は非負、t は実数全体**。χ²(2乗和)と F(比)は $\ge0$。「χ²検定統計量が負になった」は計算ミス。t は正負どちらも取りうる(対称)。
7. **3分布の独立性条件を忘れる**。t の定義は「$Z$ と $\chi^2$ が独立」、F の定義は「2つの $\chi^2$ が独立」が前提。標本分散の χ² 化で $\bar X\perp S^2$(正規母集団でのみ成立)を使っていることに注意。一般の分布ではこの綺麗な分布論は崩れる。
---
## よくある疑問
**Q1. なぜカイ二乗・t・F の自由度は $n-1$ になるのですか? $n$ ではダメなのですか?**
A. 自由度=「自由に動ける独立な成分の数」です。$\sum(X_i-\bar X)^2$ を作るとき、$\bar X$ を使った時点で制約 $\sum(X_i-\bar X)=0$ が1本入ります。$n$ 個の偏差のうち $n-1$ 個を決めれば残り1個は自動的に決まる(自由に動けない)ので、独立な成分は $n-1$ 個。数理的には恒等式 $\chi^2_n=\chi^2_{n-1}+\chi^2_1$(標本平均ぶんの $\chi^2_1$ を分離)で出ます(本文1-7)。「$\mu$ が既知なら $\sum(X_i-\mu)^2/\sigma^2$ は自由度 $n$」になる点と対比すると腑に落ちます。
**Q2. t分布と正規分布、結局いつどっちを使うのですか?**
A. 母標準偏差 $\sigma$ を**知っているか**で決まります。$\sigma$ 既知 → $\frac{\bar X-\mu}{\sigma/\sqrt n}\sim N(0,1)$(正規)。$\sigma$ 未知で $S$ で代用 → $\frac{\bar X-\mu}{S/\sqrt n}\sim t_{n-1}$(t)。実務では $\sigma$ はまず未知なので t が基本。ただし $n$ が大きい(目安30以上)と t はほぼ正規なので、近似的に正規(z)で済ませることも多い。「$S$ を使ったら t、$\sigma$ を使えるなら z」と覚えると確実です。
**Q3. なぜt分布は正規分布より裾が重い(広がっている)のですか?**
A. t の分母 $\sqrt{\chi^2_k/k}=S/\sigma$ 自体が**ばらつく確率変数**だからです。正規(z)の分母 $\sigma$ は固定値ですが、t の分母 $S$ は標本ごとに変動します。$S$ がたまたま小さく出ると比が大きく跳ね、極端な値が出やすくなる。この「分母も揺れる」ぶんが裾の重さです。自由度が大きくなると $S$ が $\sigma$ にほぼ一致して揺れが消え、t は正規に戻ります(本文2-5)。
**Q4. F分布の自由度はなぜ2つあるのですか? どちらが分子ですか?**
A. F は2つのカイ二乗の比なので、分子側の自由度 $k_1$ と分母側の自由度 $k_2$ が独立に効きます。$F_{k_1,k_2}=\frac{\chi^2_{k_1}/k_1}{\chi^2_{k_2}/k_2}$ で、**第1引数が分子、第2引数が分母**。順序を入れ替えると別の分布(逆数関係 $F_{k_1,k_2}=1/F_{k_2,k_1}$)になり臨界値も変わります。等分散検定では大きいほうの分散を分子に置く慣習があり、分散分析では「群間(分子)/群内(分母)」と決まっています。
**Q5. χ²・t・F は正規分布とどう関係しているのですか? 丸暗記すべきですか?**
A. 暗記ではなく**1本の系統樹で理解**できます。すべての素材は標準正規 $Z$ です。$Z$ を $k$ 個2乗和すれば $\chi^2_k$、$Z$ を $\sqrt{\chi^2_k/k}$ で割れば $t_k$、2つの $\chi^2$ の比が $F$。さらに $Z^2=\chi^2_1$、$t_k^2=F_{1,k}$、自由度を大きくすると $t\to$正規・$\chi^2\to$正規、と互いに地続きです(本文4の図)。「正規から派生した3兄弟」と捉えれば、定義式も用途も芋づる式に出てきます。これが準1級で問われる「分布間の関係」の正体です。
---
## まとめ
- **3分布はすべて標準正規 $Z$ から作られる標本分布**。χ²=$Z$ の2乗和(自由度=個数)、t=$Z\div\sqrt{\chi^2/k}$、F=2つのχ²の比(各自由度で割る)。
- **使い分け**:分散を見る→χ²、平均を見る(σ未知)→t、分散を比べる→F。検定統計量はそれぞれ $\frac{(n-1)S^2}{\sigma^2}\sim\chi^2_{n-1}$、$\frac{\bar X-\mu}{S/\sqrt n}\sim t_{n-1}$、$\frac{S_1^2}{S_2^2}\sim F_{n_1-1,n_2-1}$。
- **自由度は「平均を推定した数だけ減る」**。標本分散の χ² 化は $n-1$、その裏付けは恒等式 $\chi^2_n=\chi^2_{n-1}+\chi^2_1$ と正規母集団での $\bar X\perp S^2$。
- **平均・分散**:$E[\chi^2_k]=k,\ V=2k$。$E[t_k]=0,\ V=\frac{k}{k-2}$。$E[F]=\frac{k_2}{k_2-2}$。t は常に正規より裾が重く、自由度大で正規に収束。
- **相互関係**:$Z^2=\chi^2_1$、$t_k^2=F_{1,k}$(t検定と2群分散分析の一致)、$t_\infty=N(0,1)$、$\chi^2_k\to N(k,2k)$。
- **引っかけ**:自由度の取り違え、σ既知/未知(z/t)の混同、F の非対称・自由度の順序、t の裾の重さ。2級は表を読んで検定、準1級は定義と導出まで。
---
## 関連ノート
- 正規分布(標準正規・標準化) … 3分布の素材=標準正規 $N(0,1)$。標準化 $Z=(X-\mu)/\sigma$ とMGF・再生性の土台
- 指数分布・ガンマ分布・ベータ分布 … χ²はガンマ $\mathrm{Ga}(k/2,1/2)$ の特別な場合。Fのベータ関数表現とも接続
- 確率変数の変換・モーメント母関数・積率 … $Z^2=\chi^2_1$ の変数変換・ヤコビアンの計算根拠
- 大数の法則(弱法則・強法則) … $t_k\to N(0,1)$(分母 $\chi^2_k/k\to1$)の根拠
- 区間推定(母平均・母比率・母分散の信頼区間) … t分布による母平均の信頼区間、χ²による母分散の信頼区間(前方リンク)
- 母平均の検定(1標本・2標本t検定) … σ未知のt検定(前方リンク)
- カイ二乗検定(適合度・独立性) … 適合度・独立性の検定(前方リンク)
- 分散分析 … F分布の本丸。群間/群内の分散比(前方リンク)
図は `simulations/f_bunpu_keijou.py` で生成。
代表的な**上側5%点 $F_{0.05}(k_1,k_2)$**(分子自由度×分母自由度で変わる):
| $k_1\backslash k_2$ | 5 | 10 | 20 |
|---|---|---|---|
| 1 | 6.61 | 4.96 | 4.35 |
| 5 | 5.05 | 3.33 | 2.71 |
| 10 | 4.74 | 2.98 | 2.35 |
> 自由度の順序が変わると値が変わる($F_{0.05}(1,10)=4.96\ne F_{0.05}(10,1)$)。**分子・分母を取り違えない**こと。
#### 3-5. 用途
- **2標本の等分散性の検定**:$S_1^2/S_2^2$。
- **分散分析(ANOVA)**:群間変動と群内変動の比=F。分散分析。
- **回帰の有意性検定**:説明された変動と残差変動の比=F。
---
### 4. 3分布の相互関係(まとめ図)
3つは独立ではなく、互いに**特別な場合で重なり合います**。
```mermaid
graph LR
subgraph 素材
Z["Z ~ N(0,1)"]
end
Z -->|"2乗和 k個"| C["χ²_k"]
Z -->|"Z÷√(χ²/k)"| T["t_k"]
C -->|"比 ÷自由度"| F["F(k1,k2)"]
T -->|"t を2乗"| F1["= F(1, k)"]
C -->|"k1=1, k2→∞"| Z2["Z²と一致"]
T -->|"k→∞"| Z3["→ N(0,1)"]
C -->|"k→∞"| N2["→ 正規(平均k,分散2k)"]
```
押さえるべき重なり:
| 関係 | 式 | 意味 |
|---|---|---|
| $Z^2=\chi^2_1$ | 標準正規の2乗=自由度1のカイ二乗 | χ²の最小単位 |
| $t_k^2=F_{1,k}$ | t分布を2乗するとF分布(分子自由度1) | t検定と2群の分散分析が一致する理由 |
| $t_\infty=N(0,1)$ | 自由度大でtは正規 | $n\gtrsim30$ で正規近似 |
| $\chi^2_k\to N(k,2k)$ | 自由度大でχ²は正規 | 2乗和への中心極限定理 |
| $k_1F_{k_1,k_2}\to\chi^2_{k_1}$ | $k_2\to\infty$ でF×自由度はカイ二乗 | 分母の分散推定が真値に収束 |
**$t_k^2=F_{1,k}$ の確認**:$t_k=\dfrac{Z}{\sqrt{\chi^2_k/k}}$ を2乗すると $t_k^2=\dfrac{Z^2}{\chi^2_k/k}=\dfrac{\chi^2_1/1}{\chi^2_k/k}=F_{1,k}$。$Z^2=\chi^2_1$ を使うだけ。**要するに**:t統計量を2乗すればF統計量になる。だから「2群の平均の差のt検定」と「2水準の一元配置分散分析(F検定)」は同じ結論を出します。
---
### 5. 数値例
#### 例1:χ²で母分散を検定(2級〜準1級)
ある工程の製品重量が正規分布に従うとされ、母分散 $\sigma^2=4$(仕様)。$n=11$ 個を測ったら標本分散 $S^2=7.2$ だった。「分散が仕様より大きいか」を上側5%で検定する。
- 検定統計量 $\displaystyle\frac{(n-1)S^2}{\sigma^2}=\frac{10\times7.2}{4}=18.0$。
- 帰無仮説 $\sigma^2=4$ のもとで $\chi^2_{10}$ に従う。上側5%点 $\chi^2_{0.05}(10)=18.31$。
- $18.0<18.31$ なので**棄却できない**(5%水準では「分散が大きい」とは言えない)。
> 自由度は $n-1=10$(標本平均を1つ使うので10)。これを $n=11$ にしない。
#### 例2:tで母平均を区間推定(2級〜準1級)
母標準偏差 $\sigma$ 未知。$n=16$ の標本で $\bar X=52.0$、標本標準偏差 $S=8.0$。母平均の95%信頼区間は?
- 自由度 $n-1=15$、両側95%の臨界値 $t_{0.025}(15)=2.131$。
- 区間 $\displaystyle\bar X\pm t_{0.025}(15)\frac{S}{\sqrt n}=52.0\pm2.131\times\frac{8.0}{\sqrt{16}}=52.0\pm2.131\times2.0=52.0\pm4.26$。
- よって **$[47.74,\ 56.26]$**。
> もし $\sigma$ 既知で正規を使えば係数は1.96で幅が狭くなる。$\sigma$ 未知ぶん t の2.131で幅が広がる=推定の不確実性が幅に反映される。
#### 例3:Fで等分散を検定(準1級)
2工程の分散を比較。工程A:$n_1=8,\ S_1^2=25$。工程B:$n_2=11,\ S_2^2=10$。等分散を上側5%で検定($H_1:\sigma_1^2>\sigma_2^2$)。
- 検定統計量 $\displaystyle F=\frac{S_1^2}{S_2^2}=\frac{25}{10}=2.5$。
- 帰無仮説のもとで $F_{n_1-1,\,n_2-1}=F_{7,10}$ に従う。上側5%点 $F_{0.05}(7,10)\approx3.14$。
- $2.5<3.14$ なので**棄却できない**。
> 自由度の順序は(分子の自由度, 分母の自由度)=$(7,10)$。大きい分散を分子に置く慣習。
---
### 6. 試験での問われ方(級ごとの差)
| 観点 | 2級 | 準1級 |
|---|---|---|
| 分布の定義 | 「χ²=正規の2乗和」程度を知っていればよい | $\chi^2,t,F$ を $Z$ から組み立てる定義式を書ける |
| 導出 | 不要(結果を使う) | $Z^2=\chi^2_1$、$\frac{(n-1)S^2}{\sigma^2}\sim\chi^2_{n-1}$、t・Fの構成を導出 |
| 自由度 | $n-1$ などの値を正しく使える | なぜ $n-1$ かをコクラン/独立性で説明できる |
| 分布表 | **読んで検定値と比較するのが主**(最頻出) | 同左+逆数関係・近似 |
| 平均・分散 | 暗記レベル($E[\chi^2]=k$ 等) | 導出・$F,t$ の平均分散まで |
| 相互関係 | $t\to$正規(大標本でzで代用)程度 | $t^2=F_{1,k}$、$\chi^2\to$正規 など |
```mermaid
flowchart TD
Q["何を検定する?"] --> V{"対象は?"}
V -->|"1つの母分散"| CHI["χ²検定<br/>(n−1)S²÷σ² を χ²(n−1) と比較"]
V -->|"母平均 σ未知"| TT["t検定<br/>(X̄−μ)÷(S÷√n) を t(n−1) と比較"]
V -->|"2つの母分散の比"| FF["F検定<br/>S₁²÷S₂² を F(n₁−1, n₂−1) と比較"]
V -->|"3群以上の平均"| AN["分散分析(F検定)<br/>群間÷群内 を F と比較"]
```
---
## ⚠️ 引っかけポイント
1. **自由度の取り違え(最頻出)**。標本分散から作る χ² は自由度 $n-1$($n$ ではない)。t検定も自由度 $n-1$。F検定は $(n_1-1,\ n_2-1)$ の**2つ**。「平均を推定した数だけ自由度が減る」が原則。例1で $\chi^2_{11}$ としない、例2で $t_{16}$ としない。
2. **σ既知(z)とσ未知(t)の使い分け**。母分散が分かっている/大標本なら $z$(正規)、母分散未知の小〜中標本は $t$。「$S$ を使ったら $t$」が合図。$n$ が大きければ $t\approx z$ なので近似的に正規でよいが、小標本で正規を使うと区間が狭すぎて**過信**になる。
3. **F分布の非対称・自由度の順序**。F は左右非対称(χ²やtと違い、tのような対称性はない)。$F_{0.05}(7,10)\ne F_{0.05}(10,7)$。分子・分母の自由度を入れ替えてはいけない。下側臨界値は逆数関係 $F_\alpha(k_1,k_2)=1/F_{1-\alpha}(k_2,k_1)$ で求める。
4. **「自由度」を「標本サイズ」と混同**。自由度は「自由に動ける成分の数」であって標本数そのものではない。χ²の自由度=2乗和した独立な標準正規の本数。標本分散では制約 $\sum(X_i-\bar X)=0$ が1本入るので $n-1$。
5. **t分布の裾が重いことを忘れる**。t分布は正規より裾が重く、臨界値が大きい($t_{0.025}(5)=2.571>1.96$)。「正規と同じ1.96」で小標本の信頼区間を作るのは誤り。自由度が小さいほど差が大きい。
6. **χ²・F は非負、t は実数全体**。χ²(2乗和)と F(比)は $\ge0$。「χ²検定統計量が負になった」は計算ミス。t は正負どちらも取りうる(対称)。
7. **3分布の独立性条件を忘れる**。t の定義は「$Z$ と $\chi^2$ が独立」、F の定義は「2つの $\chi^2$ が独立」が前提。標本分散の χ² 化で $\bar X\perp S^2$(正規母集団でのみ成立)を使っていることに注意。一般の分布ではこの綺麗な分布論は崩れる。
---
## よくある疑問
**Q1. なぜカイ二乗・t・F の自由度は $n-1$ になるのですか? $n$ ではダメなのですか?**
A. 自由度=「自由に動ける独立な成分の数」です。$\sum(X_i-\bar X)^2$ を作るとき、$\bar X$ を使った時点で制約 $\sum(X_i-\bar X)=0$ が1本入ります。$n$ 個の偏差のうち $n-1$ 個を決めれば残り1個は自動的に決まる(自由に動けない)ので、独立な成分は $n-1$ 個。数理的には恒等式 $\chi^2_n=\chi^2_{n-1}+\chi^2_1$(標本平均ぶんの $\chi^2_1$ を分離)で出ます(本文1-7)。「$\mu$ が既知なら $\sum(X_i-\mu)^2/\sigma^2$ は自由度 $n$」になる点と対比すると腑に落ちます。
**Q2. t分布と正規分布、結局いつどっちを使うのですか?**
A. 母標準偏差 $\sigma$ を**知っているか**で決まります。$\sigma$ 既知 → $\frac{\bar X-\mu}{\sigma/\sqrt n}\sim N(0,1)$(正規)。$\sigma$ 未知で $S$ で代用 → $\frac{\bar X-\mu}{S/\sqrt n}\sim t_{n-1}$(t)。実務では $\sigma$ はまず未知なので t が基本。ただし $n$ が大きい(目安30以上)と t はほぼ正規なので、近似的に正規(z)で済ませることも多い。「$S$ を使ったら t、$\sigma$ を使えるなら z」と覚えると確実です。
**Q3. なぜt分布は正規分布より裾が重い(広がっている)のですか?**
A. t の分母 $\sqrt{\chi^2_k/k}=S/\sigma$ 自体が**ばらつく確率変数**だからです。正規(z)の分母 $\sigma$ は固定値ですが、t の分母 $S$ は標本ごとに変動します。$S$ がたまたま小さく出ると比が大きく跳ね、極端な値が出やすくなる。この「分母も揺れる」ぶんが裾の重さです。自由度が大きくなると $S$ が $\sigma$ にほぼ一致して揺れが消え、t は正規に戻ります(本文2-5)。
**Q4. F分布の自由度はなぜ2つあるのですか? どちらが分子ですか?**
A. F は2つのカイ二乗の比なので、分子側の自由度 $k_1$ と分母側の自由度 $k_2$ が独立に効きます。$F_{k_1,k_2}=\frac{\chi^2_{k_1}/k_1}{\chi^2_{k_2}/k_2}$ で、**第1引数が分子、第2引数が分母**。順序を入れ替えると別の分布(逆数関係 $F_{k_1,k_2}=1/F_{k_2,k_1}$)になり臨界値も変わります。等分散検定では大きいほうの分散を分子に置く慣習があり、分散分析では「群間(分子)/群内(分母)」と決まっています。
**Q5. χ²・t・F は正規分布とどう関係しているのですか? 丸暗記すべきですか?**
A. 暗記ではなく**1本の系統樹で理解**できます。すべての素材は標準正規 $Z$ です。$Z$ を $k$ 個2乗和すれば $\chi^2_k$、$Z$ を $\sqrt{\chi^2_k/k}$ で割れば $t_k$、2つの $\chi^2$ の比が $F$。さらに $Z^2=\chi^2_1$、$t_k^2=F_{1,k}$、自由度を大きくすると $t\to$正規・$\chi^2\to$正規、と互いに地続きです(本文4の図)。「正規から派生した3兄弟」と捉えれば、定義式も用途も芋づる式に出てきます。これが準1級で問われる「分布間の関係」の正体です。
---
## まとめ
- **3分布はすべて標準正規 $Z$ から作られる標本分布**。χ²=$Z$ の2乗和(自由度=個数)、t=$Z\div\sqrt{\chi^2/k}$、F=2つのχ²の比(各自由度で割る)。
- **使い分け**:分散を見る→χ²、平均を見る(σ未知)→t、分散を比べる→F。検定統計量はそれぞれ $\frac{(n-1)S^2}{\sigma^2}\sim\chi^2_{n-1}$、$\frac{\bar X-\mu}{S/\sqrt n}\sim t_{n-1}$、$\frac{S_1^2}{S_2^2}\sim F_{n_1-1,n_2-1}$。
- **自由度は「平均を推定した数だけ減る」**。標本分散の χ² 化は $n-1$、その裏付けは恒等式 $\chi^2_n=\chi^2_{n-1}+\chi^2_1$ と正規母集団での $\bar X\perp S^2$。
- **平均・分散**:$E[\chi^2_k]=k,\ V=2k$。$E[t_k]=0,\ V=\frac{k}{k-2}$。$E[F]=\frac{k_2}{k_2-2}$。t は常に正規より裾が重く、自由度大で正規に収束。
- **相互関係**:$Z^2=\chi^2_1$、$t_k^2=F_{1,k}$(t検定と2群分散分析の一致)、$t_\infty=N(0,1)$、$\chi^2_k\to N(k,2k)$。
- **引っかけ**:自由度の取り違え、σ既知/未知(z/t)の混同、F の非対称・自由度の順序、t の裾の重さ。2級は表を読んで検定、準1級は定義と導出まで。
---
## 関連ノート
- 正規分布(標準正規・標準化) … 3分布の素材=標準正規 $N(0,1)$。標準化 $Z=(X-\mu)/\sigma$ とMGF・再生性の土台
- 指数分布・ガンマ分布・ベータ分布 … χ²はガンマ $\mathrm{Ga}(k/2,1/2)$ の特別な場合。Fのベータ関数表現とも接続
- 確率変数の変換・モーメント母関数・積率 … $Z^2=\chi^2_1$ の変数変換・ヤコビアンの計算根拠
- 大数の法則(弱法則・強法則) … $t_k\to N(0,1)$(分母 $\chi^2_k/k\to1$)の根拠
- 区間推定(母平均・母比率・母分散の信頼区間) … t分布による母平均の信頼区間、χ²による母分散の信頼区間(前方リンク)
- 母平均の検定(1標本・2標本t検定) … σ未知のt検定(前方リンク)
- カイ二乗検定(適合度・独立性) … 適合度・独立性の検定(前方リンク)
- 分散分析 … F分布の本丸。群間/群内の分散比(前方リンク)