← 統計検定テキスト 一覧
📊 対象級:2級 | 重要度:A(頻出)
正規分布(標準正規・標準化)
要点(BLUF)
正規分布 N ( μ , σ 2 ) N(\mu,\sigma^2) N ( μ , σ 2 ) :平均 μ \mu μ σ 2 \sigma^2 σ 2 f ( x ) = 1 2 π σ exp ( − ( x − μ ) 2 2 σ 2 ) ( − ∞ < x < ∞ ) . \boxed{\,f(x)=\dfrac{1}{\sqrt{2\pi}\,\sigma}\exp\!\left(-\dfrac{(x-\mu)^2}{2\sigma^2}\right)\,}\quad(-\infty<x<\infty). f ( x ) = 2 π σ 1 exp ( − 2 σ 2 ( x − μ ) 2 ) ( − ∞ < x < ∞ ) . μ \mu μ E [ X ] = μ E[X]=\mu E [ X ] = μ V [ X ] = σ 2 V[X]=\sigma^2 V [ X ] = σ 2 標準化(z変換) :どんな N ( μ , σ 2 ) N(\mu,\sigma^2) N ( μ , σ 2 ) 平均0・分散1の標準正規分布 N ( 0 , 1 ) N(0,1) N ( 0 , 1 ) に揃う。
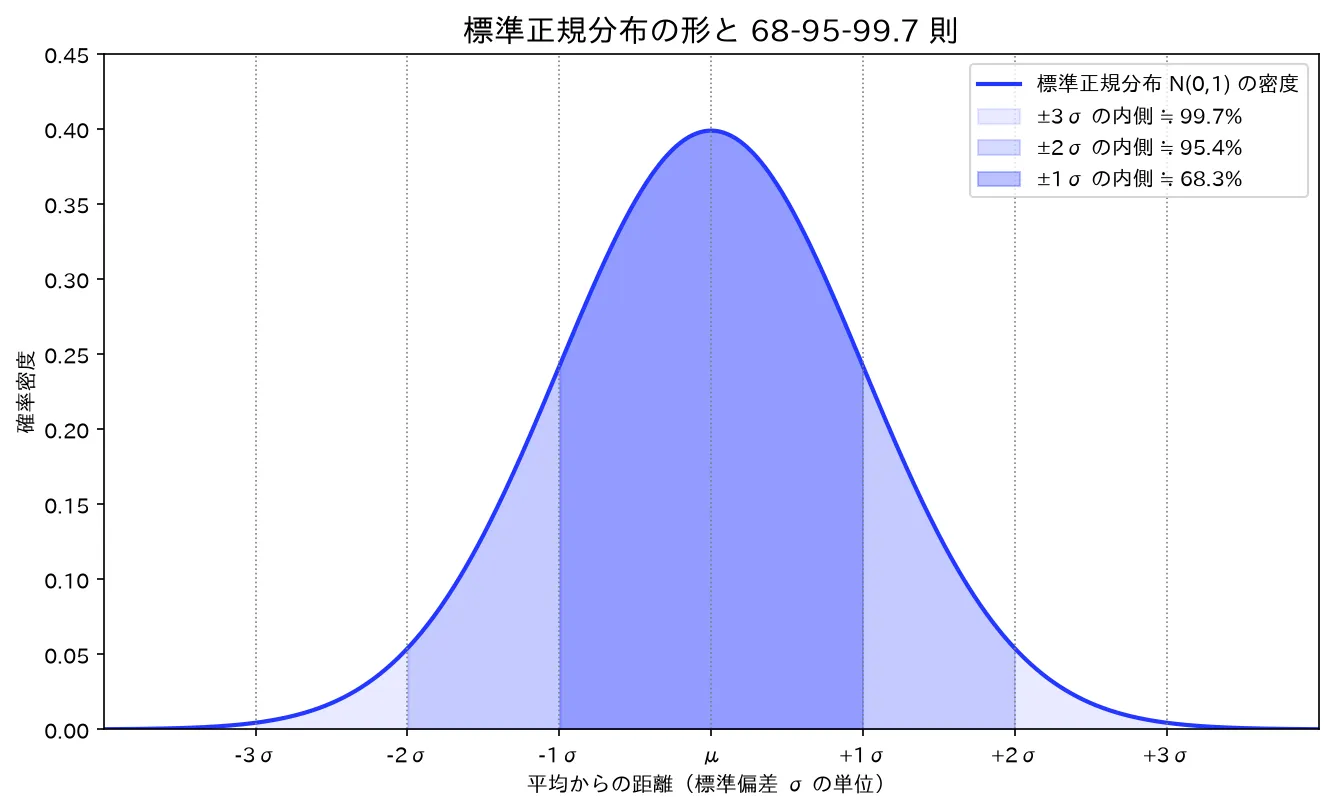
Z = X − μ σ ∼ N ( 0 , 1 ) \boxed{\,Z=\dfrac{X-\mu}{\sigma}\sim N(0,1)\,} Z = σ X − μ ∼ N ( 0 , 1 ) σ \sigma σ ただ1枚の標準正規分布表 であらゆる正規分布の確率が読める。68-95-99.7則 :± 1 σ \pm1\sigma ± 1 σ ± 2 σ \pm2\sigma ± 2 σ ± 3 σ \pm3\sigma ± 3 σ
本文
まず日常のイメージ:身長の分布
ある集団の成人男性の身長が、平均 μ = 170 \mu=170 μ = 170 σ = 6 \sigma=6 σ = 6
多くの人は170cm付近に集まり、中心から離れるほど人数が減る → 釣鐘型 。
170cmを中心に左右対称(160cmの人と180cmの人はだいたい同じくらいいる)→ 左右対称 。
「182cmより高い人は何%いるか?」のような問いに、標準化と分布表で数値で答えられる 。
身長・測定誤差・テスト得点・製品寸法のばらつき── 「中心の周りにランダムに散らばる量」は、近似的に正規分布にしたがうことが非常に多い。なぜそうなるのかは 中心極限定理(CLT) が答えます(独立な誤差がたくさん足し合わさると正規に近づく)。だから正規分布は統計学の中心にいます。
1. 確率密度関数(PDF)の形を読む
f ( x ) = 1 2 π σ exp ( − ( x − μ ) 2 2 σ 2 ) f(x)=\frac{1}{\sqrt{2\pi}\,\sigma}\exp\!\left(-\frac{(x-\mu)^2}{2\sigma^2}\right) f ( x ) = 2 π σ 1 exp ( − 2 σ 2 ( x − μ ) 2 )
式を3つの部品に分けて読みます。
部品 役割 要するに − ( x − μ ) 2 -(x-\mu)^2 − ( x − μ ) 2 中心 μ \mu μ μ \mu μ exp ( ⋅ ) \exp(\,\cdot\,) exp ( ⋅ ) そのずれを指数で減衰 裾が指数的に 薄くなる(外れ値が出にくい) 1 2 π σ \dfrac{1}{\sqrt{2\pi}\,\sigma} 2 π σ 1 全体の面積を1にするための定数 確率分布として成立させる「正規化定数」
x = μ x=\mu x = μ f f f 山の頂点は μ \mu μ 。( x − μ ) (x-\mu) ( x − μ ) − ( x − μ ) -(x-\mu) − ( x − μ ) μ \mu μ σ \sigma σ 低く広く なる。σ \sigma σ 高く狭く なる(全面積1は保たれる)。
⚠️ σ \sigma σ σ 2 \sigma^2 σ 2 σ \sigma σ 2 σ 2 2\sigma^2 2 σ 2 N ( μ , σ 2 ) N(\mu,\sigma^2) N ( μ , σ 2 ) 第2引数が分散 (標準偏差ではない)。N ( 170 , 36 ) N(170,36) N ( 170 , 36 ) σ = 6 \sigma=6 σ = 6
標準正規 N ( 0 , 1 ) N(0,1) N ( 0 , 1 ) z z z
z z z − 3 -3 − 3 − 2 -2 − 2 − 1 -1 − 1 0 0 0 1 1 1 2 2 2 3 3 3 密度 φ ( z ) \varphi(z) φ ( z ) 0.004 0.054 0.242 0.399 0.242 0.054 0.004
z = 0 z=0 z = 0 ± 1 σ \pm1\sigma ± 1 σ 68% 、± 2 σ \pm2\sigma ± 2 σ 95% 、± 3 σ \pm3\sigma ± 3 σ 99.7% が入ります(68-95-99.7則)。
上の曲線は数値表を滑らかにつないだもの。塗り分けた面積が確率に対応し、内側ほど濃い領域が ± 1 σ \pm1\sigma ± 1 σ ± 2 σ \pm2\sigma ± 2 σ ± 3 σ \pm3\sigma ± 3 σ simulations/seiki_bunpu_keijou.py で生成しています。
2. 標準化:なぜ Z = ( X − μ ) / σ Z=(X-\mu)/\sigma Z = ( X − μ ) / σ N ( 0 , 1 ) N(0,1) N ( 0 , 1 )
正規分布は μ , σ \mu,\sigma μ , σ ただ1つの基準分布 に変換します。それが標準正規分布 N ( 0 , 1 ) N(0,1) N ( 0 , 1 )
ϕ ( z ) = 1 2 π exp ( − z 2 2 ) . \phi(z)=\frac{1}{\sqrt{2\pi}}\exp\!\left(-\frac{z^2}{2}\right). ϕ ( z ) = 2 π 1 exp ( − 2 z 2 ) .
変換は Z = X − μ σ Z=\dfrac{X-\mu}{\sigma} Z = σ X − μ 中心を引いて(平行移動)、σ \sigma σ 」だけの線形変換です。この Z Z Z N ( 0 , 1 ) N(0,1) N ( 0 , 1 )
(A) 期待値0・分散1(線形変換の公式から一発)
期待値・分散の性質(線形性・和の分散・共分散) の E [ a X + b ] = a E [ X ] + b E[aX+b]=aE[X]+b E [ a X + b ] = a E [ X ] + b V [ a X + b ] = a 2 V [ X ] V[aX+b]=a^2V[X] V [ a X + b ] = a 2 V [ X ] Z = 1 σ X − μ σ Z=\frac1\sigma X-\frac\mu\sigma Z = σ 1 X − σ μ a = 1 / σ , b = − μ / σ a=1/\sigma,\ b=-\mu/\sigma a = 1/ σ , b = − μ / σ
E [ Z ] = 1 σ E [ X ] − μ σ = μ σ − μ σ = 0 , E[Z]=\frac{1}{\sigma}E[X]-\frac{\mu}{\sigma}=\frac{\mu}{\sigma}-\frac{\mu}{\sigma}=0, E [ Z ] = σ 1 E [ X ] − σ μ = σ μ − σ μ = 0 , V [ Z ] = 1 σ 2 V [ X ] = σ 2 σ 2 = 1. V[Z]=\frac{1}{\sigma^2}V[X]=\frac{\sigma^2}{\sigma^2}=1. V [ Z ] = σ 2 1 V [ X ] = σ 2 σ 2 = 1.
要するに :平均を引けば中心が0に、σ \sigma σ X X X μ \mu μ σ 2 \sigma^2 σ 2 「平均0・分散1」は標準化の効果であって、正規性とは無関係 ── これが後述の「標準化≠正規化」の核心です。
(B) 形まで N ( 0 , 1 ) N(0,1) N ( 0 , 1 )
(A) は数値(平均・分散)の話。「形まで標準正規になる」のは X X X もともと正規だから です。連続確率変数の変数変換の公式(確率変数の変換・モーメント母関数・積率 )を使います。単調変換 z = g ( x ) z=g(x) z = g ( x )
f Z ( z ) = f X ( g − 1 ( z ) ) ∣ d x d z ∣ . f_Z(z)=f_X\big(g^{-1}(z)\big)\left|\frac{dx}{dz}\right|. f Z ( z ) = f X ( g − 1 ( z ) ) d z d x .
⚠️ コードが読めない読者向けに言い換えると「変換後の密度=変換前の密度に、伸び縮みの倍率 ∣ d x / d z ∣ |dx/dz| ∣ d x / d z ∣
いま z = x − μ σ z=\dfrac{x-\mu}{\sigma} z = σ x − μ x = μ + σ z x=\mu+\sigma z x = μ + σ z d x d z = σ \dfrac{dx}{dz}=\sigma d z d x = σ
f Z ( z ) = f X ( μ + σ z ) ⋅ ∣ σ ∣ = 1 2 π σ exp ( − ( μ + σ z − μ ) 2 2 σ 2 ) ⋅ σ . f_Z(z)=f_X(\mu+\sigma z)\cdot|\sigma|
=\frac{1}{\sqrt{2\pi}\,\sigma}\exp\!\left(-\frac{(\mu+\sigma z-\mu)^2}{2\sigma^2}\right)\cdot\sigma. f Z ( z ) = f X ( μ + σ z ) ⋅ ∣ σ ∣ = 2 π σ 1 exp ( − 2 σ 2 ( μ + σ z − μ ) 2 ) ⋅ σ . 指数の中身は ( σ z ) 2 2 σ 2 = z 2 2 \dfrac{(\sigma z)^2}{2\sigma^2}=\dfrac{z^2}{2} 2 σ 2 ( σ z ) 2 = 2 z 2 1 σ ⋅ σ = 1 \dfrac{1}{\sigma}\cdot\sigma=1 σ 1 ⋅ σ = 1
f Z ( z ) = 1 2 π exp ( − z 2 2 ) = ϕ ( z ) . f_Z(z)=\frac{1}{\sqrt{2\pi}}\exp\!\left(-\frac{z^2}{2}\right)=\phi(z). f Z ( z ) = 2 π 1 exp ( − 2 z 2 ) = ϕ ( z ) .
要するに :σ \sigma σ σ \sigma σ σ \sigma σ N ( 0 , 1 ) N(0,1) N ( 0 , 1 ) だから「正規→標準化→標準正規」が厳密に成り立つ 。逆に、X X X
3. 標準正規分布表の読み方
標準正規分布表は「Z Z Z z z z 確率は面積 なので、まず図を描いて「どの面積を読むのか」を確定させるのが鉄則。
⚠️ 表には2種類の慣習がある。上側確率の表 (P ( Z ≥ z ) P(Z\ge z) P ( Z ≥ z ) 下側確率の表 (P ( Z ≤ z ) P(Z\le z) P ( Z ≤ z ) 上側確率 P ( Z ≥ z ) P(Z\ge z) P ( Z ≥ z ) を載せる形式が標準(要最新確認:年度・配布版で体裁が変わりうるので、本番の表が上側か下側かを最初に確認する)。
対称性(ϕ ( − z ) = ϕ ( z ) \phi(-z)=\phi(z) ϕ ( − z ) = ϕ ( z ) I ( z ) = P ( Z ≥ z ) I(z)=P(Z\ge z) I ( z ) = P ( Z ≥ z )
求めたい確率 表(上側)からの読み替え 図のイメージ 上側 P ( Z ≥ z ) P(Z\ge z) P ( Z ≥ z ) I ( z ) I(z) I ( z ) 右の裾 下側 P ( Z ≤ z ) P(Z\le z) P ( Z ≤ z ) 1 − I ( z ) 1-I(z) 1 − I ( z ) 左から z z z 左の裾 P ( Z ≤ − z ) P(Z\le -z) P ( Z ≤ − z ) I ( z ) I(z) I ( z ) 左の裾=右の裾と同面積 区間 P ( a ≤ Z ≤ b ) P(a\le Z\le b) P ( a ≤ Z ≤ b ) I ( a ) − I ( b ) I(a)-I(b) I ( a ) − I ( b ) a < b a<b a < b 2つの上側確率の差 両側 $P( Z \ge z)$
要するに :表は「右の裾の面積」だけ。あとは「全体は1」「左右対称」の2つで、欲しい面積を足し引きするだけです。
覚えておく代表値(2級頻出)
z z z 上側確率 P ( Z ≥ z ) P(Z\ge z) P ( Z ≥ z ) 用途 1.645 0.05 上側5%点(片側検定・90%CI の片側) 1.96 0.025 上側2.5%点(95%信頼区間 の係数) 2.576 0.005 上側0.5%点(99%信頼区間の係数) 2.33 0.01 上側1%点
これらは 区間推定(母平均・母比率・母分散の信頼区間) や仮説検定でそのまま使う「定数」です。± 1.96 \pm1.96 ± 1.96
4. 具体例:標準化して確率を読む
例 :身長 X ∼ N ( 170 , 6 2 ) X\sim N(170,\,6^2) X ∼ N ( 170 , 6 2 )
標準化:z = 182 − 170 6 = 12 6 = 2.0 z=\dfrac{182-170}{6}=\dfrac{12}{6}=2.0 z = 6 182 − 170 = 6 12 = 2.0
求めるのは上側確率 P ( X ≥ 182 ) = P ( Z ≥ 2.0 ) P(X\ge182)=P(Z\ge2.0) P ( X ≥ 182 ) = P ( Z ≥ 2.0 )
表より P ( Z ≥ 2.0 ) ≈ 0.0228 P(Z\ge2.0)\approx0.0228 P ( Z ≥ 2.0 ) ≈ 0.0228 約2.3% 。
68-95-99.7則でも検算できます。182 182 182 μ + 2 σ \mu+2\sigma μ + 2 σ ± 2 σ \pm2\sigma ± 2 σ
例(パーセント点を逆に求める) :「上位5%に入るのは何cm以上か?」
上側5%点は z = 1.645 z=1.645 z = 1.645 x = μ + σ z = 170 + 6 × 1.645 = 179.87 x=\mu+\sigma z=170+6\times1.645=179.87 x = μ + σ z = 170 + 6 × 1.645 = 179.87 約180cm以上 。
5. 正規分布の再生性(加法性)
2級では「独立な正規どうしの和も正規」という事実と、平均・分散の足し算ができれば十分。
独立な X ∼ N ( μ 1 , σ 1 2 ) X\sim N(\mu_1,\sigma_1^2) X ∼ N ( μ 1 , σ 1 2 ) Y ∼ N ( μ 2 , σ 2 2 ) Y\sim N(\mu_2,\sigma_2^2) Y ∼ N ( μ 2 , σ 2 2 )
X + Y ∼ N ( μ 1 + μ 2 , σ 1 2 + σ 2 2 ) , X − Y ∼ N ( μ 1 − μ 2 , σ 1 2 + σ 2 2 ) . X+Y\sim N(\mu_1+\mu_2,\ \sigma_1^2+\sigma_2^2),\qquad X-Y\sim N(\mu_1-\mu_2,\ \sigma_1^2+\sigma_2^2). X + Y ∼ N ( μ 1 + μ 2 , σ 1 2 + σ 2 2 ) , X − Y ∼ N ( μ 1 − μ 2 , σ 1 2 + σ 2 2 ) .
要するに :和でも差でも平均は足し引き、分散は必ず足す (分散は引かない。期待値・分散の性質(線形性・和の分散・共分散) の V [ X − Y ] = V [ X ] + V [ Y ] V[X-Y]=V[X]+V[Y] V [ X − Y ] = V [ X ] + V [ Y ] 再生性 と呼びます。
MGFによる証明
正規分布のモーメント母関数(確率変数の変換・モーメント母関数・積率 )は
M X ( t ) = exp ( μ t + σ 2 t 2 2 ) . M_X(t)=\exp\!\left(\mu t+\frac{\sigma^2 t^2}{2}\right). M X ( t ) = exp ( μ t + 2 σ 2 t 2 ) .
独立なら和のMGFは積(M X + Y ( t ) = M X ( t ) M Y ( t ) M_{X+Y}(t)=M_X(t)M_Y(t) M X + Y ( t ) = M X ( t ) M Y ( t )
M X + Y ( t ) = exp ( μ 1 t + σ 1 2 t 2 2 ) exp ( μ 2 t + σ 2 2 t 2 2 ) = exp ( ( μ 1 + μ 2 ) t + ( σ 1 2 + σ 2 2 ) t 2 2 ) . M_{X+Y}(t)=\exp\!\left(\mu_1 t+\frac{\sigma_1^2 t^2}{2}\right)\exp\!\left(\mu_2 t+\frac{\sigma_2^2 t^2}{2}\right)=\exp\!\left((\mu_1+\mu_2)t+\frac{(\sigma_1^2+\sigma_2^2)t^2}{2}\right). M X + Y ( t ) = exp ( μ 1 t + 2 σ 1 2 t 2 ) exp ( μ 2 t + 2 σ 2 2 t 2 ) = exp ( ( μ 1 + μ 2 ) t + 2 ( σ 1 2 + σ 2 2 ) t 2 ) .
これは平均 μ 1 + μ 2 \mu_1+\mu_2 μ 1 + μ 2 σ 1 2 + σ 2 2 \sigma_1^2+\sigma_2^2 σ 1 2 + σ 2 2 要するに :MGFが「指数の肩で平均と分散を足すだけ」の形だから、独立和も同じ形に閉じる。標準化 Z = ( X − μ ) / σ Z=(X-\mu)/\sigma Z = ( X − μ ) / σ a = 1 / σ , b = − μ / σ a=1/\sigma,\ b=-\mu/\sigma a = 1/ σ , b = − μ / σ M Z ( t ) = e b t M X ( a t ) = e t 2 / 2 M_Z(t)=e^{bt}M_X(at)=e^{t^2/2} M Z ( t ) = e b t M X ( a t ) = e t 2 /2 N ( 0 , 1 ) N(0,1) N ( 0 , 1 )
6. 68-95-99.7則の根拠
この「経験則」は標準正規分布表から直接出る厳密な値です。標準化すれば ± k σ \pm k\sigma ± k σ ± k \pm k ± k
P ( ∣ Z ∣ ≤ 1 ) = 1 − 2 P ( Z ≥ 1 ) = 1 − 2 ( 0.1587 ) = 0.6826 ≈ 68 % , P(|Z|\le 1)=1-2P(Z\ge1)=1-2(0.1587)=0.6826\approx68\%, P ( ∣ Z ∣ ≤ 1 ) = 1 − 2 P ( Z ≥ 1 ) = 1 − 2 ( 0.1587 ) = 0.6826 ≈ 68% , P ( ∣ Z ∣ ≤ 2 ) = 1 − 2 ( 0.0228 ) = 0.9544 ≈ 95 % , P(|Z|\le 2)=1-2(0.0228)=0.9544\approx95\%, P ( ∣ Z ∣ ≤ 2 ) = 1 − 2 ( 0.0228 ) = 0.9544 ≈ 95% , P ( ∣ Z ∣ ≤ 3 ) = 1 − 2 ( 0.00135 ) = 0.9973 ≈ 99.7 % . P(|Z|\le 3)=1-2(0.00135)=0.9973\approx99.7\%. P ( ∣ Z ∣ ≤ 3 ) = 1 − 2 ( 0.00135 ) = 0.9973 ≈ 99.7%.
要するに :表の上側確率を2倍して1から引いただけ。「ルール」と呼ばれるが暗記の便宜であって、出どころは分布表の積分値です。なお95%の係数を厳密に取ると z = 1.96 z=1.96 z = 1.96 ± 2 σ \pm2\sigma ± 2 σ z = 2.0 z=2.0 z = 2.0
7. 試験での問われ方(2級)
flowchart TD
A["正規分布の問題"] --> B{"何を求める?"}
B -->|確率| C["X を標準化 z=(X−μ)÷σ"]
C --> D["図を描き上側か下側か確定"]
D --> E["分布表で面積を読む"]
B -->|パーセント点| F["表から z を引く"]
F --> G["逆変換 x=μ+σz"]
B -->|和差の分布| H["再生性: 平均は足し引き 分散は足す"]
H --> I["新しい正規を再び標準化"]
2級での典型出題は次の4パターン。
確率計算 :N ( μ , σ 2 ) N(\mu,\sigma^2) N ( μ , σ 2 ) P ( X ≥ a ) P(X\ge a) P ( X ≥ a ) P ( a ≤ X ≤ b ) P(a\le X\le b) P ( a ≤ X ≤ b ) パーセント点(逆問題) :「上位○%の境界値」を、表で z z z x = μ + σ z x=\mu+\sigma z x = μ + σ z 和・差の分布 :独立な正規変数の和差の分布を再生性で求め、さらに確率計算へつなぐ(標本平均 X ˉ ∼ N ( μ , σ 2 / n ) \bar X\sim N(\mu,\sigma^2/n) X ˉ ∼ N ( μ , σ 2 / n ) 中心極限定理(CLT) )。68-95-99.7則の暗算 :± 1 σ , ± 2 σ \pm1\sigma,\pm2\sigma ± 1 σ , ± 2 σ
⚠️ 引っかけポイント
標準化 ≠ 正規化(最重要) 。「標準化」は平均0・分散1に揃える線形変換(z変換)。機械学習で言う「正規化(normalization)」は最小0・最大1に揃える min-max スケーリングで別物 。さらに「正規化」という語は確率を1にする正規化定数を指すこともあり多義的。試験文脈の標準化はz変換 を指す。標準化しても分布の形は変わらない 。標準化は平行移動+拡大縮小の線形変換なので、もとが正規でないものは標準化しても正規にならない 。「平均0・分散1になった」と「正規分布になった」は別。Z = ( X − μ ) / σ Z=(X-\mu)/\sigma Z = ( X − μ ) / σ N ( 0 , 1 ) N(0,1) N ( 0 , 1 ) X X X 確率=面積 。正規分布は連続分布なので P ( X = a ) = 0 P(X=a)=0 P ( X = a ) = 0 P ( X ≤ a ) P(X\le a) P ( X ≤ a ) P ( X < a ) P(X<a) P ( X < a ) ベルヌーイ分布・二項分布 )との違いに注意。上側確率と下側確率の取り違え 。配布される分布表が上側 P ( Z ≥ z ) P(Z\ge z) P ( Z ≥ z ) P ( Z ≤ z ) P(Z\le z) P ( Z ≤ z ) 必ず図を描いて、塗る面積を目で確認してから表を引く 。N ( μ , σ 2 ) N(\mu,\sigma^2) N ( μ , σ 2 ) N ( 170 , 36 ) N(170,36) N ( 170 , 36 ) σ = 6 \sigma=6 σ = 6 σ = 36 \sigma=36 σ = 36 σ \sigma σ σ 2 \sigma^2 σ 2 負の z z z 。多くの表は z ≥ 0 z\ge0 z ≥ 0 P ( Z ≤ − 1.5 ) = P ( Z ≥ 1.5 ) P(Z\le-1.5)=P(Z\ge1.5) P ( Z ≤ − 1.5 ) = P ( Z ≥ 1.5 )
よくある疑問
Q1. 標準化と正規化、どう違うんですか?
A. 標準化(standardization)は Z = ( X − μ ) / σ Z=(X-\mu)/\sigma Z = ( X − μ ) / σ 平均0・分散1 に揃える変換。正規化(normalization)は文脈で2つの意味があり、(1) 機械学習では min-max で最小0・最大1 に揃える変換、(2) 確率論では密度の面積を1にする正規化定数 で割る操作。統計検定で「標準化」と言えば必ず z変換のこと。名前が似ているだけで操作も目的も違うので、混同は致命的です。
Q2. データを標準化すれば正規分布になりますか?
A. なりません。標準化は線形変換(ずらして・割るだけ)なので分布の形は一切変えません 。歪んだデータは標準化しても歪んだまま、平均0・分散1になるだけです。「z変換すると正規分布になる」は誤解。正規分布になるのは「もともと正規だったものを標準化したとき」だけ(本文2-(B)の証明)。データを正規に近づけたいなら対数変換やBox-Cox変換など非線形 変換が要ります(標準化では無理)。
Q3. なぜわざわざ標準化するんですか?元の分布のまま計算できないのですか?
A. 原理的には元の N ( μ , σ 2 ) N(\mu,\sigma^2) N ( μ , σ 2 ) 数値表(分布表)に頼る しかありません。μ , σ \mu,\sigma μ , σ N ( 0 , 1 ) N(0,1) N ( 0 , 1 ) ただ1枚の標準正規分布表 で済ませる── これが標準化の実利です。
Q4. 「確率」と「確率密度」は同じものですか?f ( x ) f(x) f ( x )
A. 違います。連続分布では f ( x ) f(x) f ( x ) 確率密度 であって確率そのものではありません。確率は「密度を区間で積分した面積」P ( a ≤ X ≤ b ) = ∫ a b f ( x ) d x P(a\le X\le b)=\int_a^b f(x)\,dx P ( a ≤ X ≤ b ) = ∫ a b f ( x ) d x P ( X = a ) = 0 P(X=a)=0 P ( X = a ) = 0 N ( 0 , 1 ) N(0,1) N ( 0 , 1 ) f ( 0 ) = 1 / 2 π ≈ 0.399 f(0)=1/\sqrt{2\pi}\approx0.399 f ( 0 ) = 1/ 2 π ≈ 0.399 ありません 。「確率=面積」を徹底してください。
Q5. 標準正規分布表で、表に載っていない負の z z z z = − 1.96 z=-1.96 z = − 1.96
A. 左右対称性 ϕ ( − z ) = ϕ ( z ) \phi(-z)=\phi(z) ϕ ( − z ) = ϕ ( z ) z ≥ 0 z\ge0 z ≥ 0 P ( Z ≤ − 1.96 ) = P ( Z ≥ 1.96 ) P(Z\le-1.96)=P(Z\ge1.96) P ( Z ≤ − 1.96 ) = P ( Z ≥ 1.96 ) P ( − 1.96 ≤ Z ≤ 1.96 ) = 1 − 2 P ( Z ≥ 1.96 ) = 1 − 2 ( 0.025 ) = 0.95 P(-1.96\le Z\le1.96)=1-2\,P(Z\ge1.96)=1-2(0.025)=0.95 P ( − 1.96 ≤ Z ≤ 1.96 ) = 1 − 2 P ( Z ≥ 1.96 ) = 1 − 2 ( 0.025 ) = 0.95
まとめ
正規分布 N ( μ , σ 2 ) N(\mu,\sigma^2) N ( μ , σ 2 ) μ \mu μ σ 2 \sigma^2 σ 2 1 2 π σ exp ( − ( x − μ ) 2 2 σ 2 ) \dfrac{1}{\sqrt{2\pi}\,\sigma}\exp\!\big(-\frac{(x-\mu)^2}{2\sigma^2}\big) 2 π σ 1 exp ( − 2 σ 2 ( x − μ ) 2 )
標準化 Z = ( X − μ ) / σ Z=(X-\mu)/\sigma Z = ( X − μ ) / σ で N ( 0 , 1 ) N(0,1) N ( 0 , 1 ) 形まで標準正規になるのは元が正規のときだけ (変数変換でヤコビアン σ \sigma σ σ \sigma σ 確率は面積 。標準正規分布表(上側/下側の慣習に注意)と対称性で、足し引きして読む。± 1.96 \pm1.96 ± 1.96 1.645 1.645 1.645
68-95-99.7則 は表の積分値そのもの。再生性により独立な正規の和差も正規(平均は足し引き・分散は足す)。引っかけの筆頭は標準化≠正規化 と非正規データは標準化しても正規にならない 。次いで上側/下側の取り違えと「確率=面積」。
関連ノート