← 統計検定テキスト 一覧
📊 対象級:2級 ・ 準1級 | 重要度:A(頻出)
中心極限定理(CLT)── MGFによる証明/ド・モアブル=ラプラス/連続性補正
要点(BLUF)
中心極限定理(CLT) :独立同分布 X 1 , … , X n X_1,\dots,X_n X 1 , … , X n μ \mu μ 0 < σ 2 < ∞ 0<\sigma^2<\infty 0 < σ 2 < ∞ 母分布の形は問わない )に対し、標準化した標本平均は標準正規分布に分布収束 する。
Z n = X ˉ n − μ σ / n = n ( X ˉ n − μ ) σ → d N ( 0 , 1 ) . Z_n=\frac{\bar X_n-\mu}{\sigma/\sqrt n}=\frac{\sqrt n(\bar X_n-\mu)}{\sigma}\ \xrightarrow{d}\ N(0,1). Z n = σ / n X ˉ n − μ = σ n ( X ˉ n − μ ) d N ( 0 , 1 ) . n n n 証明の山=MGF(確率変数の変換・モーメント母関数・積率 の集大成) :Y i = ( X i − μ ) / σ Y_i=(X_i-\mu)/\sigma Y i = ( X i − μ ) / σ E [ Y ] = 0 , V [ Y ] = 1 E[Y]=0,V[Y]=1 E [ Y ] = 0 , V [ Y ] = 1 Z n = 1 n ∑ Y i Z_n=\frac1{\sqrt n}\sum Y_i Z n = n 1 ∑ Y i M Z n ( t ) = [ M Y ( t / n ) ] n M_{Z_n}(t)=[M_Y(t/\sqrt n)]^n M Z n ( t ) = [ M Y ( t / n ) ] n M Y ( s ) = 1 + s 2 2 + o ( s 2 ) M_Y(s)=1+\frac{s^2}{2}+o(s^2) M Y ( s ) = 1 + 2 s 2 + o ( s 2 ) 1次項 E [ Y ] = 0 E[Y]=0 E [ Y ] = 0 )を入れて [ 1 + t 2 2 n + o ( 1 / n ) ] n → e t 2 / 2 [1+\frac{t^2}{2n}+o(1/n)]^n\to e^{t^2/2} [ 1 + 2 n t 2 + o ( 1/ n ) ] n → e t 2 /2 Z n → d N ( 0 , 1 ) Z_n\xrightarrow{d}N(0,1) Z n d N ( 0 , 1 ) 大数の法則との対比(大数の法則(弱法則・強法則) の続き) :大数の法則=X ˉ n \bar X_n X ˉ n 点 μ \mu μ (収束先は点)/CLT=n \sqrt n n 拡大 した n ( X ˉ n − μ ) \sqrt n(\bar X_n-\mu) n ( X ˉ n − μ ) 揺らぎの形が正規 (収束先は分布)。同じ標本平均の別側面。ド・モアブル=ラプラス :二項分布 B i n ( n , p ) ≈ N ( n p , n p ( 1 − p ) ) \mathrm{Bin}(n,p)\approx N(np,\,np(1-p)) Bin ( n , p ) ≈ N ( n p , n p ( 1 − p )) 連続性補正 ± 0.5 \pm0.5 ± 0.5
本文
0. まず日常のイメージ:身長の平均
クラス1人の身長は、低い人も高い人もいてバラバラ(母集団の分布は別に正規とは限らない)。ところが「ランダムに30人選んでその平均身長 」を何度も計算してみると、その平均値たちの分布は、きれいな左右対称の釣鐘型(正規分布)になる。
ポイントは2つ。
元の1人ひとりがどんな分布でも、平均をとると正規になる (CLTの普遍性)。平均値のばらつきは元のばらつきより小さい (σ / 30 \sigma/\sqrt{30} σ / 30
選挙の出口調査や工場の品質管理が「平均」を見て少ない標本から全体を語れるのは、この定理のおかげ。
1. 中心極限定理は何を言っているか
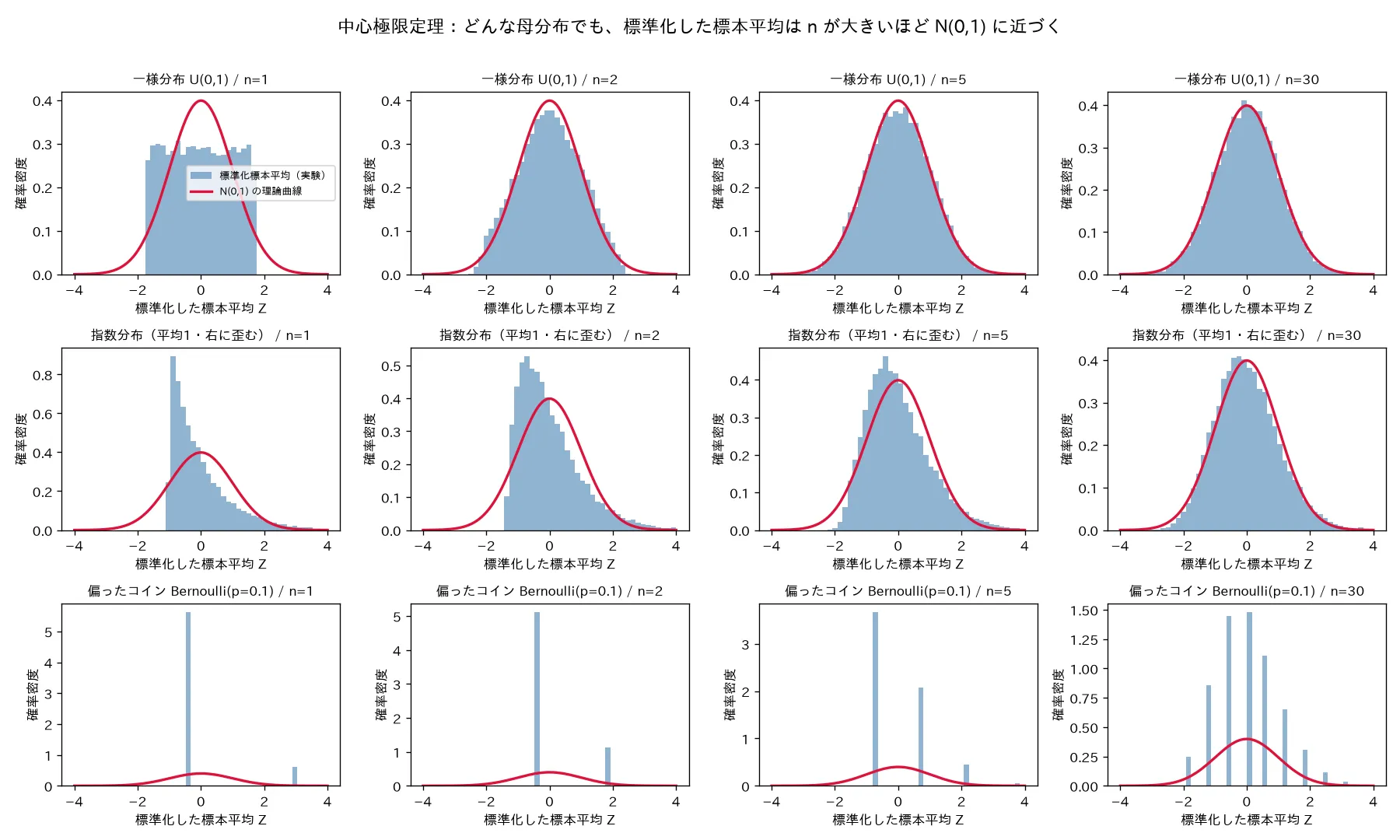
直観:「たくさんの独立な確率変数を足して平均すると、元が何であろうと、その平均は正規分布の形になる」 。サイコロの目(一様)でも、待ち時間(指数で右に歪む)でも、コインの表裏(ベルヌーイ)でも、十分多く集めて平均すれば、その標本平均の分布は釣鐘型(正規)になる。これがCLTで、統計学が正規分布を主役に据える最大の理由。
設定は大数の法則(大数の法則(弱法則・強法則) )と同じ 独立同分布(i.i.d.) X 1 , X 2 , … X_1,X_2,\dots X 1 , X 2 , … μ = E [ X i ] \mu=E[X_i] μ = E [ X i ] σ 2 = V [ X i ] \sigma^2=V[X_i] σ 2 = V [ X i ] 有限 (0 < σ 2 < ∞ 0<\sigma^2<\infty 0 < σ 2 < ∞
大数の法則は「X ˉ n \bar X_n X ˉ n μ \mu μ 収束する (散らばりが消えて1点に潰れる)」までしか言わない。CLTはその先 を述べる——潰れていく途中の「揺らぎの形」が正規だ、と。だから「収束」ではなく「分布収束 (distribution convergence)」がCLTの結論。
2. CLTの3つの同値な表現
主張は次のどれで書いても同じ(n n n 使い分け が問われる。
表現 式 何を近似しているか 主な使い所 標準化形(収束の本体) X ˉ n − μ σ / n → d N ( 0 , 1 ) \dfrac{\bar X_n-\mu}{\sigma/\sqrt n}\xrightarrow{d}N(0,1) σ / n X ˉ n − μ d N ( 0 , 1 ) 標準化した標本平均 → 標準正規 証明・確率計算(z z z 標本平均の形 X ˉ n ≈ N ( μ , σ 2 n ) \bar X_n\ \approx\ N\!\left(\mu,\ \dfrac{\sigma^2}{n}\right) X ˉ n ≈ N ( μ , n σ 2 ) 標本平均そのものの分布 区間推定・標準誤差 総和の形 ∑ i = 1 n X i ≈ N ( n μ , n σ 2 ) \displaystyle\sum_{i=1}^n X_i\ \approx\ N(n\mu,\ n\sigma^2) i = 1 ∑ n X i ≈ N ( n μ , n σ 2 ) 合計値の分布 合計の確率(二項など)
3つは X ˉ n = 1 n ∑ X i \bar X_n=\frac1n\sum X_i X ˉ n = n 1 ∑ X i E [ X ˉ n ] = μ , V [ X ˉ n ] = σ 2 / n E[\bar X_n]=\mu,\ V[\bar X_n]=\sigma^2/n E [ X ˉ n ] = μ , V [ X ˉ n ] = σ 2 / n 期待値・分散の性質(線形性・和の分散・共分散) )で互いに変換できる。標準偏差 σ / n \sigma/\sqrt n σ / n (standard error, SE)と呼び、Phase 4 の推定・検定で中心的役割を果たす。
flowchart LR
A["i.i.d. の和<br/>X1, X2, ..., Xn"] --> B["標準化<br/>(平均ひいて σ/√n で割る)"]
B --> C["n を大きくする<br/>(n → ∞)"]
C --> D["標準正規分布<br/>N(0, 1)"]
注意:CLTが述べるのは標準化した Z n Z_n Z n N ( 0 , 1 ) N(0,1) N ( 0 , 1 ) X ˉ n \bar X_n X ˉ n μ \mu μ X ˉ n \bar X_n X ˉ n X ˉ n \bar X_n X ˉ n N ( μ , σ 2 / n ) N(\mu,\sigma^2/n) N ( μ , σ 2 / n )
3. MGFによるCLTの証明 ── 本トピックの山
ここは数式が続きます。証明の流れだけ知りたい方は、各ステップの太字の一言を拾って読み飛ばしてOK です。
確率変数の変換・モーメント母関数・積率 で用意した道具(MGF、独立和はMGFの積、一意性)がここで全部使われる。これがPhase 2の数理の集大成。
【設定】標準化してから足す
まず各 X i X_i X i Y i Y_i Y i
Y i = X i − μ σ ⟹ E [ Y i ] = 0 , V [ Y i ] = E [ Y i 2 ] = 1. Y_i=\frac{X_i-\mu}{\sigma}\quad\Longrightarrow\quad E[Y_i]=0,\ \ V[Y_i]=E[Y_i^2]=1. Y i = σ X i − μ ⟹ E [ Y i ] = 0 , V [ Y i ] = E [ Y i 2 ] = 1. (Y i Y_i Y i V [ Y ] = E [ Y 2 ] − ( E [ Y ] ) 2 = E [ Y 2 ] = 1 V[Y]=E[Y^2]-(E[Y])^2=E[Y^2]=1 V [ Y ] = E [ Y 2 ] − ( E [ Y ] ) 2 = E [ Y 2 ] = 1 Z n Z_n Z n
Z n = X ˉ n − μ σ / n = n ( X ˉ n − μ ) σ = 1 n ∑ i = 1 n X i − μ σ = 1 n ∑ i = 1 n Y i . Z_n=\frac{\bar X_n-\mu}{\sigma/\sqrt n}=\frac{\sqrt n(\bar X_n-\mu)}{\sigma}
=\frac{1}{\sqrt n}\sum_{i=1}^n \frac{X_i-\mu}{\sigma}
=\frac{1}{\sqrt n}\sum_{i=1}^n Y_i. Z n = σ / n X ˉ n − μ = σ n ( X ˉ n − μ ) = n 1 i = 1 ∑ n σ X i − μ = n 1 i = 1 ∑ n Y i . 要するに**「標準化した変数を n n n n \sqrt n n Z n Z_n Z n
【道具1】独立和のMGFは積 (確率変数の変換・モーメント母関数・積率 )
独立な確率変数の和のMGFは各MGFの積。さらに定数倍 a Y aY aY M a Y ( t ) = M Y ( a t ) M_{aY}(t)=M_Y(at) M aY ( t ) = M Y ( a t ) Z n = ∑ ( Y i / n ) Z_n=\sum (Y_i/\sqrt n) Z n = ∑ ( Y i / n )
M Z n ( t ) = E [ e t Z n ] = E [ exp ( t n ∑ i Y i ) ] = ∏ i = 1 n E [ e ( t / n ) Y i ] = [ M Y ( t n ) ] n . M_{Z_n}(t)=E\!\left[e^{t Z_n}\right]
=E\!\left[\exp\!\Big(\tfrac{t}{\sqrt n}\textstyle\sum_i Y_i\Big)\right]
=\prod_{i=1}^n E\!\left[e^{(t/\sqrt n)Y_i}\right]
=\Big[M_Y\!\Big(\tfrac{t}{\sqrt n}\Big)\Big]^{n}. M Z n ( t ) = E [ e t Z n ] = E [ exp ( n t ∑ i Y i ) ] = i = 1 ∏ n E [ e ( t / n ) Y i ] = [ M Y ( n t ) ] n . (Y i Y_i Y i M Y ( t / n ) M_Y(t/\sqrt n) M Y ( t / n ) n n n
【道具2】M Y M_Y M Y
MGFのテイラー展開は M Y ( s ) = ∑ k s k k ! E [ Y k ] M_Y(s)=\sum_k \frac{s^k}{k!}E[Y^k] M Y ( s ) = ∑ k k ! s k E [ Y k ] 確率変数の変換・モーメント母関数・積率 )。Y Y Y E [ Y 0 ] = 1 , E [ Y ] = 0 , E [ Y 2 ] = 1 E[Y^0]=1,\ E[Y]=0,\ E[Y^2]=1 E [ Y 0 ] = 1 , E [ Y ] = 0 , E [ Y 2 ] = 1 s → 0 s\to0 s → 0
M Y ( s ) = 1 + E [ Y ] ⏟ = 0 s + E [ Y 2 ] 2 s 2 + o ( s 2 ) = 1 + s 2 2 + o ( s 2 ) . M_Y(s)=1+\underbrace{E[Y]}_{=0}\,s+\frac{E[Y^2]}{2}s^2+o(s^2)
=1+\frac{s^2}{2}+o(s^2). M Y ( s ) = 1 + = 0 E [ Y ] s + 2 E [ Y 2 ] s 2 + o ( s 2 ) = 1 + 2 s 2 + o ( s 2 ) . ここが核心 :標準化したおかげで1次の項 E [ Y ] s E[Y]\,s E [ Y ] s s 2 2 \frac{s^2}{2} 2 s 2 。正規分布のMGF e t 2 / 2 e^{t^2/2} e t 2 /2 t 2 t^2 t 2
【合流】s = t / n s=t/\sqrt n s = t / n n n n
s = t / n s=t/\sqrt n s = t / n s 2 = t 2 / n s^2=t^2/n s 2 = t 2 / n
M Y ( t n ) = 1 + t 2 2 n + o ( 1 n ) . M_Y\!\Big(\tfrac{t}{\sqrt n}\Big)=1+\frac{t^2}{2n}+o\!\Big(\frac1n\Big). M Y ( n t ) = 1 + 2 n t 2 + o ( n 1 ) . これを n n n
M Z n ( t ) = [ 1 + t 2 2 n + o ( 1 n ) ] n → n → ∞ e t 2 / 2 . M_{Z_n}(t)=\Big[\,1+\frac{t^2}{2n}+o\!\big(\tfrac1n\big)\Big]^{n}\ \xrightarrow[n\to\infty]{}\ e^{t^2/2}. M Z n ( t ) = [ 1 + 2 n t 2 + o ( n 1 ) ] n n → ∞ e t 2 /2 . 極限の根拠は ( 1 + a n ) n → e a \big(1+\frac{a}{n}\big)^n\to e^{a} ( 1 + n a ) n → e a a = t 2 / 2 a=t^2/2 a = t 2 /2 o ( 1 / n ) o(1/n) o ( 1/ n ) n n n n ⋅ o ( 1 / n ) → 0 n\cdot o(1/n)\to0 n ⋅ o ( 1/ n ) → 0
【結論】一意性で締める (確率変数の変換・モーメント母関数・積率 )
e t 2 / 2 e^{t^2/2} e t 2 /2 標準正規 N ( 0 , 1 ) N(0,1) N ( 0 , 1 ) 。MGFが(0の近傍で)一致すれば分布が一致する(一意性)ので
Z n → d N ( 0 , 1 ) . ■ \boxed{\ Z_n\ \xrightarrow{d}\ N(0,1).\ }\qquad\blacksquare Z n d N ( 0 , 1 ) . ■ 要するに証明の骨は3行:「独立和でMGFが [ M Y ( t / n ) ] n [M_Y(t/\sqrt n)]^n [ M Y ( t / n ) ] n t 2 2 n \frac{t^2}{2n} 2 n t 2 n n n e t 2 / 2 e^{t^2/2} e t 2 /2 。母分布の形(3次以上のモーメント)は o ( 1 / n ) o(1/n) o ( 1/ n ) 結論が母分布によらない 。これがCLTの普遍性の数理的な理由。
厳密には「MGFが存在する」前提が要る(裾の重い分布だとMGFが無い)。MGFを使わず特性関数 φ Y ( t ) = E [ e i t Y ] \varphi_Y(t)=E[e^{itY}] φ Y ( t ) = E [ e i t Y ] 確率変数の変換・モーメント母関数・積率 、常に存在)で同じ計算をすれば、分散有限という条件だけで証明できる(リンドバーグ=レヴィの定理)。準1級ではMGF版で筋を理解すれば十分。
4. 大数の法則 vs 中心極限定理(潰す vs 拡大する)
同じ i.i.d. の標本平均 X ˉ n \bar X_n X ˉ n 見る倍率 が違う。大数の法則(弱法則・強法則) で予告した対比をここで確定させる。
大数の法則(LLN) 中心極限定理(CLT) 主張 X ˉ n → μ \bar X_n\to\mu X ˉ n → μ X ˉ n − μ σ / n → N ( 0 , 1 ) \dfrac{\bar X_n-\mu}{\sigma/\sqrt n}\to N(0,1) σ / n X ˉ n − μ → N ( 0 , 1 ) 収束の種類 確率収束 / 概収束 分布収束 → d \xrightarrow{d} d 収束先 点 μ \mu μ (散らばりが消える)分布の形(正規) 何を見ているか X ˉ n \bar X_n X ˉ n n \sqrt n n 拡大 した揺らぎ → 形が正規倍率 拡大しない n \sqrt n n 必要な仮定 μ \mu μ σ 2 < ∞ \sigma^2<\infty σ 2 < ∞ μ , σ 2 \mu,\sigma^2 μ , σ 2 役割 「平均は真の値に近づく」 「近づくときの速さと揺らぎの形 」
直観:X ˉ n \bar X_n X ˉ n σ / n \sigma/\sqrt n σ / n μ \mu μ 潰れる (LLN)。潰れた後は形が見えない。そこで n \sqrt n n 拡大 して見ると、n ( X ˉ n − μ ) \sqrt n(\bar X_n-\mu) n ( X ˉ n − μ ) n ⋅ σ 2 n = σ 2 n\cdot\frac{\sigma^2}{n}=\sigma^2 n ⋅ n σ 2 = σ 2 N ( 0 , σ 2 ) N(0,\sigma^2) N ( 0 , σ 2 ) 形 に落ち着く(CLT)。さらに σ \sigma σ N ( 0 , 1 ) N(0,1) N ( 0 , 1 ) LLNは「点に潰れる」を、CLTは「n \sqrt n n 。
5. ド・モアブル=ラプラスの定理(二項分布の正規近似)
CLTの歴史的に最初の特殊例 (1733年ド・モアブル p = 1 / 2 p=1/2 p = 1/2 p p p
二項分布 X ∼ B i n ( n , p ) X\sim\mathrm{Bin}(n,p) X ∼ Bin ( n , p ) p p p n n n 独立な指示変数(ベルヌーイ)の和 X = ∑ i = 1 n X i X=\sum_{i=1}^n X_i X = ∑ i = 1 n X i X i ∈ { 0 , 1 } , P ( X i = 1 ) = p X_i\in\{0,1\},\ P(X_i=1)=p X i ∈ { 0 , 1 } , P ( X i = 1 ) = p E [ X i ] = p , V [ X i ] = p ( 1 − p ) E[X_i]=p,\ V[X_i]=p(1-p) E [ X i ] = p , V [ X i ] = p ( 1 − p ) 期待値・分散の性質(線形性・和の分散・共分散) )なので、総和の形(第2節)より
X = ∑ i = 1 n X i ≈ N ( n p , n p ( 1 − p ) ) ( n 大 ) . X=\sum_{i=1}^n X_i\ \approx\ N\big(np,\ np(1-p)\big)\qquad(n\ \text{大}). X = i = 1 ∑ n X i ≈ N ( n p , n p ( 1 − p ) ) ( n 大 ) . 要するに**「二項分布は n n n n p np n p n p ( 1 − p ) np(1-p) n p ( 1 − p )
P ( a ≤ X ≤ b ) ≈ Φ ( b − n p n p ( 1 − p ) ) − Φ ( a − n p n p ( 1 − p ) ) P(a\le X\le b)\ \approx\ \Phi\!\left(\frac{b-np}{\sqrt{np(1-p)}}\right)-\Phi\!\left(\frac{a-np}{\sqrt{np(1-p)}}\right) P ( a ≤ X ≤ b ) ≈ Φ ( n p ( 1 − p ) b − n p ) − Φ ( n p ( 1 − p ) a − n p ) (Φ \Phi Φ
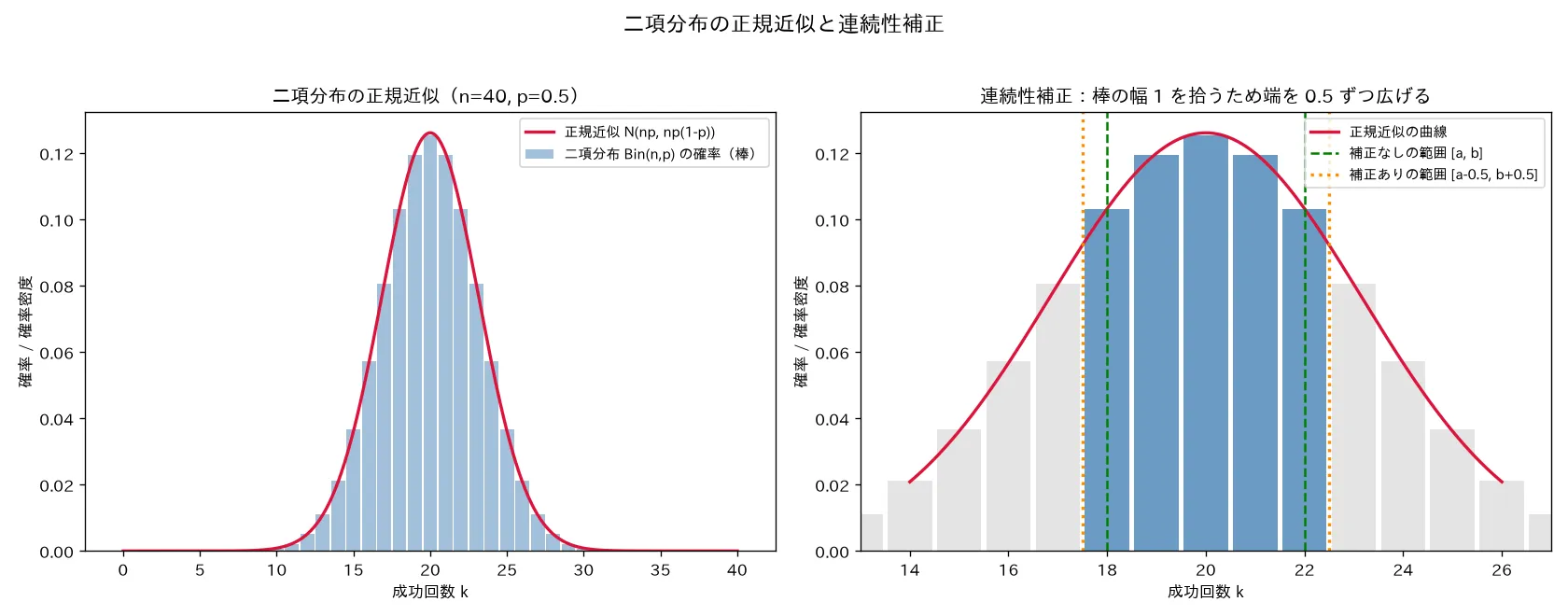
6. 連続性補正(continuity correction)
離散分布(二項・ポアソンなど)を連続分布(正規)で近似するとき、区間の端を外側に ± 0.5 \pm0.5 ± 0.5 。
なぜ要るか:二項分布は X = a , a + 1 , … , b X=a,a+1,\dots,b X = a , a + 1 , … , b 棒の集まり 。各棒を「幅1の長方形」とみなすと、k k k [ k − 0.5 , k + 0.5 ] [k-0.5,\ k+0.5] [ k − 0.5 , k + 0.5 ] a a a b b b 面積 で拾うには、[ a , b ] [a,b] [ a , b ] 両端の半分の棒まで含めた [ a − 0.5 , b + 0.5 ] [a-0.5,\ b+0.5] [ a − 0.5 , b + 0.5 ]
P ( a ≤ X ≤ b ) ≈ Φ ( b + 0.5 − n p n p ( 1 − p ) ) − Φ ( a − 0.5 − n p n p ( 1 − p ) ) . P(a\le X\le b)\ \approx\ \Phi\!\left(\frac{b+0.5-np}{\sqrt{np(1-p)}}\right)-\Phi\!\left(\frac{a-0.5-np}{\sqrt{np(1-p)}}\right). P ( a ≤ X ≤ b ) ≈ Φ ( n p ( 1 − p ) b + 0.5 − n p ) − Φ ( n p ( 1 − p ) a − 0.5 − n p ) . 要するに**「棒の幅1を区間で拾うための ±0.5」**。不等号の向きで補正の向きが変わる(下表)。
求めたい確率(離散) 連続性補正した区間 P ( X = k ) P(X=k) P ( X = k ) [ k − 0.5 , k + 0.5 ] [\,k-0.5,\ k+0.5\,] [ k − 0.5 , k + 0.5 ] P ( a ≤ X ≤ b ) P(a\le X\le b) P ( a ≤ X ≤ b ) [ a − 0.5 , b + 0.5 ] [\,a-0.5,\ b+0.5\,] [ a − 0.5 , b + 0.5 ] P ( X ≤ b ) P(X\le b) P ( X ≤ b ) ( − ∞ , b + 0.5 ] (-\infty,\ b+0.5\,] ( − ∞ , b + 0.5 ] P ( X ≥ a ) P(X\ge a) P ( X ≥ a ) [ a − 0.5 , ∞ ) [\,a-0.5,\ \infty) [ a − 0.5 , ∞ ) P ( X < b ) = P ( X ≤ b − 1 ) P(X<b)=P(X\le b-1) P ( X < b ) = P ( X ≤ b − 1 ) ( − ∞ , b − 0.5 ] (-\infty,\ b-0.5\,] ( − ∞ , b − 0.5 ] 等号なしは先に整数へ直す )
補正の効果は数値で大きい。本ノートのシミュ②では B i n ( 40 , 0.5 ) \mathrm{Bin}(40,0.5) Bin ( 40 , 0.5 ) P ( 18 ≤ X ≤ 22 ) P(18\le X\le 22) P ( 18 ≤ X ≤ 22 ) 約155倍 になる。
7. 正規近似の実用と注意(n ≥ 30 n\ge30 n ≥ 30
「n ≥ 30 n\ge30 n ≥ 30 。母分布が対称・なだらかなら小さい n n n 強く歪んでいる ほど大きな n n n p = 0.1 p=0.1 p = 0.1 二項では p p p 。経験則として n p ≥ 5 np\ge5 n p ≥ 5 n ( 1 − p ) ≥ 5 n(1-p)\ge5 n ( 1 − p ) ≥ 5 ≥ 10 \ge10 ≥ 10 p = 0.01 p=0.01 p = 0.01 ポアソン近似 の出番)。標準誤差 σ / n \sigma/\sqrt n σ / n がCLTの実用の核。n n n 1 / 10 1/10 1/10 n \sqrt n n 期待値・分散の性質(線形性・和の分散・共分散) )。CLTは Phase 4 の区間推定・仮説検定の正規近似の土台 。標本平均の信頼区間 X ˉ ± z ⋅ σ n \bar X\pm z\cdot\frac{\sigma}{\sqrt n} X ˉ ± z ⋅ n σ
8. 試験での問われ方
2級(中核) :CLTの主張 (母分布の形によらず標本平均が正規に近づく)、X ˉ n ≈ N ( μ , σ 2 / n ) \bar X_n\approx N(\mu,\sigma^2/n) X ˉ n ≈ N ( μ , σ 2 / n ) 標準化して確率計算 (z = X ˉ − μ σ / n z=\frac{\bar X-\mu}{\sigma/\sqrt n} z = σ / n X ˉ − μ σ / n \sigma/\sqrt n σ / n N ( n p , n p ( 1 − p ) ) N(np,np(1-p)) N ( n p , n p ( 1 − p )) n n n 2級の発展/準1級 :連続性補正 ± 0.5 \pm0.5 ± 0.5 区別 (点への収束 vs 分布への収束)、分布収束の意味。準1級(応用) :MGFによるCLTの証明 (標準化和のMGF [ M Y ( t / n ) ] n → e t 2 / 2 [M_Y(t/\sqrt n)]^n\to e^{t^2/2} [ M Y ( t / n ) ] n → e t 2 /2 g ( X ˉ n ) g(\bar X_n) g ( X ˉ n ) ※公式の出題範囲表は改訂されうる。とくに2級の「発展的事項」の扱い・準1級範囲は受験前に最新の範囲表で要最新確認 。
数式の直観的意味
なぜ「1次が消えて2次だけ残る」と正規になるのか
正規分布 N ( 0 , 1 ) N(0,1) N ( 0 , 1 ) e t 2 / 2 e^{t^2/2} e t 2 /2 指数部が t t t 。一方、任意の平均0・分散1の分布のMGFは M Y ( s ) = 1 + s 2 2 + ( 3次以上 ) M_Y(s)=1+\frac{s^2}{2}+(\text{3次以上}) M Y ( s ) = 1 + 2 s 2 + ( 3 次以上 ) 最低次の生きた項が2次 (1次は平均0で消える)。Z n = 1 n ∑ Y i Z_n=\frac1{\sqrt n}\sum Y_i Z n = n 1 ∑ Y i s = t / n s=t/\sqrt n s = t / n s 2 = t 2 / n s^2=t^2/n s 2 = t 2 / n n n n n n n ( 1 + t 2 / 2 n ) n → e t 2 / 2 (1+\frac{t^2/2}{n})^n\to e^{t^2/2} ( 1 + n t 2 /2 ) n → e t 2 /2 3次以上は s 3 = t 3 / n 3 / 2 s^3=t^3/n^{3/2} s 3 = t 3 / n 3/2 n n n n n n (n ⋅ n − 3 / 2 = n − 1 / 2 → 0 n\cdot n^{-3/2}=n^{-1/2}\to0 n ⋅ n − 3/2 = n − 1/2 → 0
なぜ n \sqrt n n
X ˉ n − μ \bar X_n-\mu X ˉ n − μ σ / n \sigma/\sqrt n σ / n 期待値・分散の性質(線形性・和の分散・共分散) )。これを「形が見える一定サイズ」に保つには、n \sqrt n n n ⋅ σ n = σ \sqrt n\cdot\frac{\sigma}{\sqrt n}=\sigma n ⋅ n σ = σ n \sqrt n n n 1 / 3 n^{1/3} n 1/3 n n n n \sqrt n n n \sqrt n n n \sqrt n n
なぜ連続性補正は 0.5 0.5 0.5
整数 k k k k − 1 , k + 1 k-1,k+1 k − 1 , k + 1 中点 が境界になる。k k k k + 1 k+1 k + 1 k + 0.5 k+0.5 k + 0.5 k k k k − 1 k-1 k − 1 k − 0.5 k-0.5 k − 0.5 k k k [ k − 0.5 , k + 0.5 ] [k-0.5,k+0.5] [ k − 0.5 , k + 0.5 ] 0.5 0.5 0.5 0.5 0.5 0.5
⚠️ 引っかけポイント・頻出論点・級ごとの差
「X ˉ n \bar X_n X ˉ n :X ˉ n \bar X_n X ˉ n 点 μ \mu μ 。正規に収束するのは標準化した X ˉ n − μ σ / n \frac{\bar X_n-\mu}{\sigma/\sqrt n} σ / n X ˉ n − μ X ˉ n \bar X_n X ˉ n N ( μ , σ 2 / n ) N(\mu,\sigma^2/n) N ( μ , σ 2 / n ) CLT ≠ 大数の法則(収束先が点か形か) :大数の法則=点 μ \mu μ n n n 母分布の分散が無いとCLTは成り立たない :σ 2 = ∞ \sigma^2=\infty σ 2 = ∞ 確率変数の変換・モーメント母関数・積率 )ではCLTは適用できない(コーシーの標本平均はまたコーシーで、正規に近づかない)。「どんな分布でも標本平均は正規に近づく」は誤り——分散有限が前提 。n ≥ 30 n\ge30 n ≥ 30 n = 30 n=30 n = 30 p = 0.1 p=0.1 p = 0.1 n n n n ≥ 30 n\ge30 n ≥ 30 連続性補正の向きを間違える :P ( a ≤ X ≤ b ) P(a\le X\le b) P ( a ≤ X ≤ b ) [ a − 0.5 , b + 0.5 ] [a-0.5,b+0.5] [ a − 0.5 , b + 0.5 ] P ( X ≤ b ) P(X\le b) P ( X ≤ b ) b + 0.5 b+0.5 b + 0.5 P ( X ≥ a ) P(X\ge a) P ( X ≥ a ) a − 0.5 a-0.5 a − 0.5 等号の有無で整数がずれる (P ( X < b ) = P ( X ≤ b − 1 ) P(X<b)=P(X\le b-1) P ( X < b ) = P ( X ≤ b − 1 ) b − 0.5 b-0.5 b − 0.5 不要 (補正は離散を連続で近似するときだけ)。二項の正規近似 vs ポアソン近似 :n n n p p p n p , n ( 1 − p ) ≥ 5 np,n(1-p)\ge5 n p , n ( 1 − p ) ≥ 5 正規近似 。n n n p p p n p np n p λ = n p \lambda=np λ = n p ポアソン近似 。p p p 標準化の分母は σ / n \sigma/\sqrt n σ / n σ \sigma σ :標本平均の確率計算で z = X ˉ − μ σ z=\frac{\bar X-\mu}{\sigma} z = σ X ˉ − μ σ / n \sigma/\sqrt n σ / n σ / n \sigma/\sqrt n σ / n X X X σ \sigma σ 証明で1次項を残してしまう(準1級) :MGF証明の肝は標準化で E [ Y ] = 0 E[Y]=0 E [ Y ] = 0 こと。標準化せずに 1 n ∑ X i \frac1n\sum X_i n 1 ∑ X i μ \mu μ e t 2 / 2 e^{t^2/2} e t 2 /2 μ \mu μ Y i = ( X i − μ ) / σ Y_i=(X_i-\mu)/\sigma Y i = ( X i − μ ) / σ 級差 :2級=主張・N ( μ , σ 2 / n ) N(\mu,\sigma^2/n) N ( μ , σ 2 / n ) /2級発展・準1級=連続性補正・大数の法則との区別・分布収束 /準1級=MGFによる証明・収束の精緻化・デルタ法への接続 。
よくある疑問
Q. 「標本平均が正規分布に収束する」と覚えていたのですが、違うのですか?
不正確です。X ˉ n \bar X_n X ˉ n 点 μ \mu μ 。正規分布に収束するのは標準化した X ˉ n − μ σ / n \frac{\bar X_n-\mu}{\sigma/\sqrt n} σ / n X ˉ n − μ X ˉ n \bar X_n X ˉ n N ( μ , σ 2 / n ) N(\mu,\sigma^2/n) N ( μ , σ 2 / n ) X ˉ n \bar X_n X ˉ n N ( 0 , 1 ) N(0,1) N ( 0 , 1 )
Q. 大数の法則とCLTは何が違うのですか?両方「標本平均」の話に見えます。
収束先が違います。 大数の法則は「標本平均が点 μ \mu μ に近づく」(散らばりが消える)。CLTは「n \sqrt n n 正規分布の形 になる」(散らばりの形が分かる)。大数の法則は形を言わず、CLTはその先の形まで言う、という関係です。
Q. 「どんな分布でも」と言いますが、本当に例外はないのですか?
母分散が有限であることが必要 です。コーシー分布のように分散が無限大(確率変数の変換・モーメント母関数・積率 )だとCLTは成り立ちません(コーシーの標本平均はまたコーシーで、正規に近づきません)。「分散が有限な i.i.d. なら」という条件付きの「どんな分布でも」です。
Q. なぜ補正値は 0.5 0.5 0.5
整数 k k k 中点 が境界になります。k k k k + 1 k+1 k + 1 k + 0.5 k+0.5 k + 0.5 [ k − 0.5 , k + 0.5 ] [k-0.5,k+0.5] [ k − 0.5 , k + 0.5 ] 0.5 0.5 0.5 0.5 0.5 0.5
Q. 標準化の分母は σ \sigma σ
標本平均の確率計算では分母は σ / n \sigma/\sqrt n σ / n σ \sigma σ σ / n \sigma/\sqrt n σ / n X X X σ \sigma σ
まとめ
CLT :分散が有限な i.i.d. なら、標準化した標本平均は n → ∞ n\to\infty n → ∞ N ( 0 , 1 ) N(0,1) N ( 0 , 1 ) 分布収束 する。実用形は X ˉ n ≈ N ( μ , σ 2 / n ) \bar X_n\approx N(\mu,\sigma^2/n) X ˉ n ≈ N ( μ , σ 2 / n ) 大数の法則との違い :大数の法則=点 μ \mu μ n \sqrt n n 証明(準1級) :標準化和のMGFが [ M Y ( t / n ) ] n → e t 2 / 2 [M_Y(t/\sqrt n)]^n\to e^{t^2/2} [ M Y ( t / n ) ] n → e t 2 /2 標準化で1次が消え2次だけ残る から正規になる。ド・モアブル=ラプラス :B i n ( n , p ) ≈ N ( n p , n p ( 1 − p ) ) \mathrm{Bin}(n,p)\approx N(np,np(1-p)) Bin ( n , p ) ≈ N ( n p , n p ( 1 − p )) 連続性補正 ± 0.5 \pm0.5 ± 0.5 。n ≥ 30 n\ge30 n ≥ 30 p p p n n n σ / n \sigma/\sqrt n σ / n
対応するシミュレーション
simulations/chuushin_kyokugen.py
何を示すか :正規分布ではない3つの母分布(一様 U ( 0 , 1 ) U(0,1) U ( 0 , 1 ) B e r n o u l l i ( 0.1 ) \mathrm{Bernoulli}(0.1) Bernoulli ( 0.1 ) Z = X ˉ − μ σ / n Z=\frac{\bar X-\mu}{\sigma/\sqrt n} Z = σ / n X ˉ − μ n = 1 , 2 , 5 , 30 n=1,2,5,30 n = 1 , 2 , 5 , 30 N ( 0 , 1 ) N(0,1) N ( 0 , 1 ) 1 2 π e − z 2 / 2 \frac1{\sqrt{2\pi}}e^{-z^2/2} 2 π 1 e − z 2 /2 実行結果(seed=0) :どの母分布でも n = 1 n=1 n = 1 n = 30 n=30 n = 30 N ( 0 , 1 ) N(0,1) N ( 0 , 1 ) n = 5 n=5 n = 5 n = 30 n=30 n = 30 n n n 全12マスで実測平均がほぼ0・実測分散がほぼ1 (例:指数 n = 30 n=30 n = 30 n = 30 n=30 n = 30 平均・分散は n n n n n n ——CLTが「平均・分散の話」ではなく「分布収束の話」であることを対比で示す。
simulations/chuushin_kyokugen_nikou_seiki.py
何を示すか :二項分布 B i n ( 40 , 0.5 ) \mathrm{Bin}(40,0.5) Bin ( 40 , 0.5 ) N ( n p , n p ( 1 − p ) ) = N ( 20 , 10 ) N(np,np(1-p))=N(20,10) N ( n p , n p ( 1 − p )) = N ( 20 , 10 ) P ( 18 ≤ X ≤ 22 ) P(18\le X\le 22) P ( 18 ≤ X ≤ 22 ) [ 18 , 22 ] [18,22] [ 18 , 22 ] [ 17.5 , 22.5 ] [17.5,22.5] [ 17.5 , 22.5 ] 実行結果 :厳密値 0.570409 /補正なし 0.473117 (誤差 0.097292 )/補正あり 0.571036 (誤差 0.000626 )。補正ありの誤差は補正なしの約155分の1 。連続性補正を入れるべきことを数値で裏づけ。左の図では二項の棒が正規曲線にほぼ一致(ド・モアブル=ラプラス)。
関連ノート
確率変数の変換・モーメント母関数・積率 (変換・モーメント母関数 ── CLTの証明の道具 。独立和はMGFの積・M Y ( s ) = 1 + s 2 2 + o ( s 2 ) M_Y(s)=1+\frac{s^2}{2}+o(s^2) M Y ( s ) = 1 + 2 s 2 + o ( s 2 ) e t 2 / 2 e^{t^2/2} e t 2 /2 大数の法則(弱法則・強法則) (大数の法則 ── 「点 μ \mu μ n \sqrt n n 期待値・分散の性質(線形性・和の分散・共分散) (期待値・分散の性質 ── V [ X ˉ n ] = σ 2 / n V[\bar X_n]=\sigma^2/n V [ X ˉ n ] = σ 2 / n σ / n \sigma/\sqrt n σ / n = = = n p ( 1 − p ) np(1-p) n p ( 1 − p ) 標準化(z得点)・偏差値・チェビシェフの不等式 ── 標準化≠正規化/偏差値に上限なし/どんな分布でも成り立つ歯止め (標準化・正規分布 ── 標準化 z = x − μ σ z=\frac{x-\mu}{\sigma} z = σ x − μ N ( 0 , 1 ) N(0,1) N ( 0 , 1 ) z z z 確率変数(離散・連続)と期待値・分散 (確率変数・期待値・分散 ── 期待値・分散の定義と標本平均。CLTの前提となる μ , σ 2 \mu,\sigma^2 μ , σ 2 ベルヌーイ分布・二項分布 (二項分布 ── ド・モアブル=ラプラスの近似対象。E = n p , V = n p ( 1 − p ) E=np,\ V=np(1-p) E = n p , V = n p ( 1 − p )