📊 対象級:2級 ・ 準1級 | 重要度:A(頻出)
要点(BLUF)
分散分析(ANOVA, Analysis of Variance)は、3群以上の母平均が等しいかどうかを、データのばらつき(分散)を分解して検定する手法です。名前は「分散」分析ですが、調べているのは平均の差です。核心は、全体のばらつきを「群間のばらつき」と「群内のばらつき」に分解し、その比をF統計量で評価する、という一点に集約されます。
要するに「群と群の差が、群の内側のバラつきに比べてどれだけ大きいか」を比で測り、その比が大きすぎれば「平均に差がある」と判断する、ということです。
- 2級:一元配置分散分析(1因子)。平方和分解とF検定、分散分析表が書けるか。
- 準1級:二元配置分散分析(2因子)。主効果・交互作用への分解、交互作用の解釈まで。
2級レベル(一元配置分散分析)
ここで問われるのは「1つの因子について、群間平方和・群内平方和を分解し、分散分析表を埋めてF検定を行う」までです。平方和分解の恒等式の考え方はこの級で身につけます。
1. 設定と仮説
因子(要因)が1つで、その水準が 個あるとします。各水準 から 個ずつ観測したとします(つり合い型・各群の標本数が等しい場合)。
| 記号 | 意味 |
|---|---|
| 水準(群)の数 | |
| 各水準の観測数(全体で ) | |
| 第 水準・第 番目の観測値 | |
| 第 水準の標本平均(群平均) | |
| 全データの標本平均(総平均) |
検定する仮説は次の通りです。
⚠️ 対立仮説は「すべて違う」ではなく「少なくとも1つ違う」です。だから有意になっても「どの群とどの群が違うか」までは分かりません(→ 多重比較 へ)。
2. なぜ「平均の差」を「分散」で検定するのか(直観)
下の2つの状況を比べてください。どちらも群平均は同じ位置関係ですが、群の内側のばらつきが違います。
- 左:群内のばらつきが小さい → 群平均の差は「本物の差」に見える。
- 右:群内のばらつきが大きい → 群平均の差は「たまたまのブレ」かもしれない。
xychart-beta
title "群間の差を群内のばらつきと比べる"
x-axis ["群1", "群2", "群3"]
y-axis "観測値" 0 --> 10
bar [3, 5, 7]
bar [3, 5, 7]
つまり「群平均の差(群間のばらつき)」を、それ単独で見るのではなく、「群内のばらつきを物差しにして」相対評価するのが分散分析の発想です。群間が群内に比べて十分大きければ「差は誤差では説明できない」と結論します。この比こそがF統計量です。
3. 平方和分解の恒等式 (クロス項が消えることの導出)
総平方和 (全データの総平均まわりのばらつき)を考えます。
ここで、各観測の偏差 を、群平均 を経由して2つに分けます。これが分解の出発点です。
要するに「全体平均からのズレ」を「自分の群平均からのズレ(誤差)」+「群平均が全体平均からどれだけズレているか(要因効果)」に分けた、ということです。これを2乗して総和を取ります。
2乗を展開すると、群内偏差の2乗・群間偏差の2乗・そして**クロス項(積の2倍)**の3つが出ます。
ここでクロス項が消えることを示します(これが分解が成立する核心)。 クロス項の内側の和を、まず について先に取ります。 は に依存しない(群 で固定)ので、和の外に出せます。
ここで残った は、群平均まわりの偏差の総和です。標本平均の定義 より、偏差の和は必ずゼロになります。
したがってクロス項は群ごとに となり、 について足してもゼロです。要するに「平均まわりの偏差は足すと必ず消える」という基本性質のおかげで、クロス項が落ちるわけです。よって、
ここで各平方和の名前と中身は次の通りです。
は「群平均が全体平均からどれだけ離れているか」=要因によるばらつき、 は「各観測が自分の群平均からどれだけ離れているか」=誤差によるばらつきです。
4. 自由度の分解
平方和と同じように、自由度も分解されます。
- 総自由度 : 個のデータが総平均という1個の制約を持つため。
- 群間自由度 : 個の群平均が総平均という1個の制約を持つため。
- 群内自由度 :各群で 個が群平均1個の制約を持ち、それが 群分。
要するに「各平方和を計算するのに何個の独立な偏差が使えるか」を数えたものです。 も平方和と同じく成立します。
5. 平均平方とF統計量
平方和を自由度で割って**平均平方(mean square)**にします。これは「自由度あたりのばらつき」=分散の推定量です。
F統計量はこの比です。
なぜこの比が のもとでF分布に従うのか(理論的裏付け)。 誤差が独立に に従うと仮定します。
- は、各群内の偏差平方和の合計です。正規母集団の偏差平方和は 倍のカイ二乗分布に従うので、。これは の真偽によらず成り立ちます(群内のばらつきは群平均の差とは無関係だから)。
- が真(全群の母平均が等しい)なら、群平均 は同じ母平均まわりに散らばるだけなので、 になります。
- さらに と は独立です(群平均と群内偏差は直交する。これはクロス項が消えたことと表裏一体です)。
F分布の定義は「独立な2つのカイ二乗を、それぞれの自由度で割った比」です。
分子・分母で が打ち消し合う点に注目してください。だから未知の母分散 を知らなくてもFは計算できます。これがF検定の便利さです。詳しい分布の性質は t分布・カイ二乗分布・F分布(標本分布の三役) を参照してください。
棄却のロジック(右片側検定)。 が真なら群平均が散らばるため が大きくなり、Fは大きくなります。逆に小さなFは「群間の差が誤差程度」を意味します。よってFが大きいときだけ棄却する右片側検定です。有意水準 で なら を棄却します。
⚠️ 分散分析は名前に反して両側ではなく右片側検定です。「平均に差がない」を否定したいので、Fが大きい側だけを見ます。
6. 分散分析表(一元配置)
計算結果は次の表にまとめるのが定石です。試験ではこの表の空欄を埋める問題が頻出です。
| 変動要因 | 平方和 | 自由度 | 平均平方 | F値 |
|---|---|---|---|---|
| 級間(要因 ) | ||||
| 級内(誤差 ) | ||||
| 全体() |
表の検算ポイント:平方和は縦に足すと合う()し、自由度も縦に足すと合う()。平均平方は足しても合わない(割り算したものだから)点に注意します。
7. 試験での問われ方(2級)
- 分散分析表の穴埋め:与えられた平方和や平均平方から、自由度・F値を計算する。縦の和が合うことを使って逆算する問題も多い。
- F値の判定:計算したFをF分布表の臨界値と比べ、棄却するか判断する(右片側)。自由度の組 を正しく読む。
- 仮説の理解:帰無仮説が「全群の母平均が等しい」、対立仮説が「少なくとも1つ異なる」であることを選ばせる。
検定の枠組み自体は 仮説検定の枠組み(帰無仮説・対立仮説・p値・有意水準)、3群「以上」を一度に扱う動機(なぜt検定を繰り返さないか)は次の準1級・⚠️節および 多重比較 につながります。
準1級レベル(二元配置・交互作用)
ここで問われるのは「2因子のとき、主効果と交互作用に平方和を分解できるか」「交互作用の意味を解釈できるか」「ANOVAが回帰モデルの特殊形だと理解しているか」までです。一元配置の考え方を2因子へ拡張します。
8. 二元配置の設定
因子が2つ( と )あるとします。 は 水準、 は 水準、各セル(水準の組合せ)で 回ずつ繰り返し観測したとします。
| 項 | 意味 |
|---|---|
| 総平均 | |
| 因子 の主効果(第 水準の効果) | |
| 因子 の主効果(第 水準の効果) | |
| と の交互作用 | |
| 誤差( 独立) |
要するに「観測値=全体平均+Aの効果+Bの効果+AとBの組合せ特有の効果+誤差」と分解するモデルです。
9. 平方和の分解
一元配置と同じ発想で、総平方和を4つに分けます。
各平方和は次のように、対応する平均と総平均の差から作ります( は の第 水準の平均、 は の第 水準の平均、 はセル の平均、 は総平均)。
交互作用の平方和の読み方が要点です。 の中身を整理すると、
これは「セル平均が、主効果だけで説明できる値からどれだけズレているか」です。要するに、もし交互作用がなければセル平均は「総平均+Aの効果+Bの効果」で完全に表せるはずで、その当てはめ残りが交互作用です。一元配置でクロス項が消えたのと同じ直交性により、この4つの平方和も互いに重ならずに分解されます(つり合い型の場合)。
10. 交互作用の意味
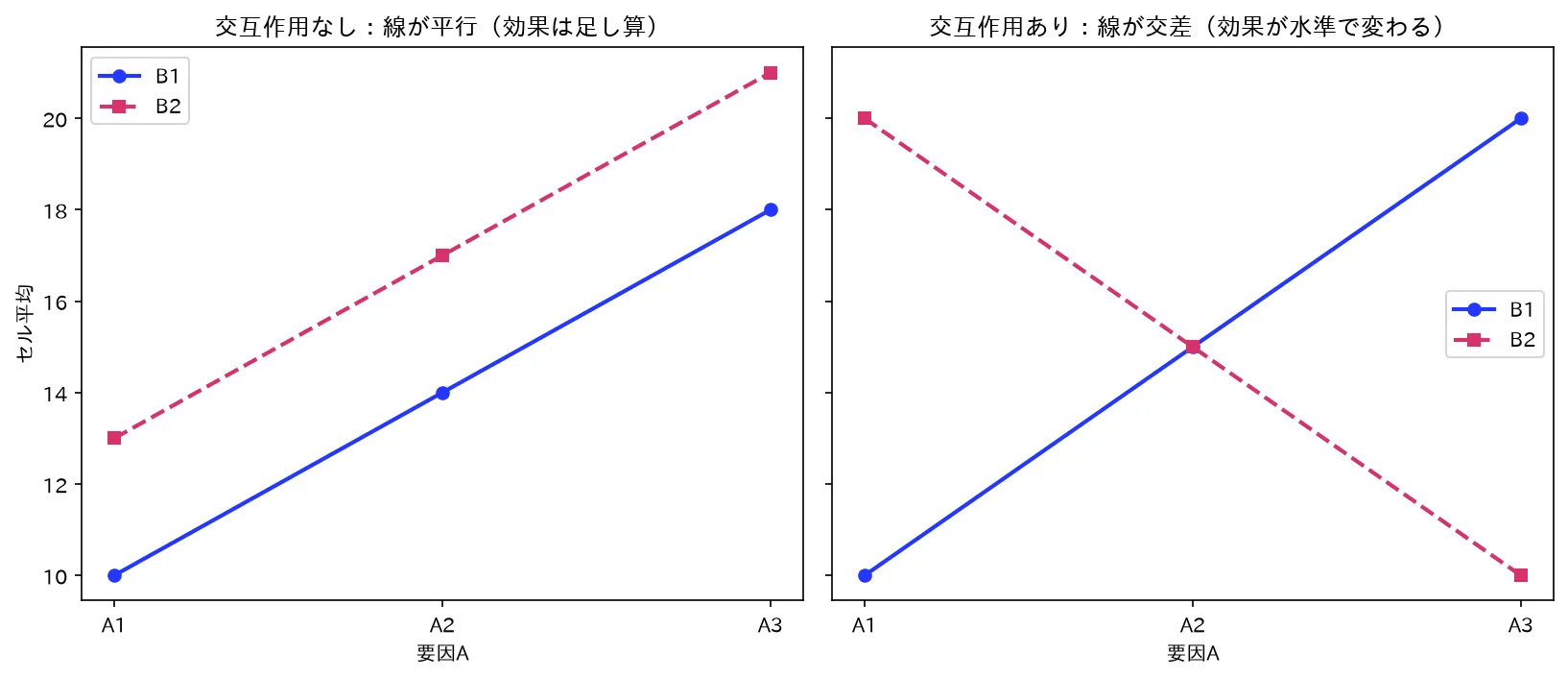
図は simulations/koshogo_plot.py で生成。
**交互作用とは「一方の因子の効果が、もう一方の因子の水準によって変わること」**です。
graph LR
subgraph "交互作用なし(線が平行)"
A1["B1での A の効果"] -.同じ傾き.- A2["B2での A の効果"]
end
subgraph "交互作用あり(線が非平行・交差)"
C1["B1での A の効果"] -.傾きが違う.- C2["B2での A の効果"]
end
例:薬の効果(因子A)が、男女(因子B)で違う、というのが交互作用です。「薬は男性には効くが女性には効かない」なら、Aの効果はBの水準に依存しています。交互作用プロット(横軸に一方の因子、折れ線で他方の水準を描く)で、線が平行なら交互作用なし、非平行・交差なら交互作用あり、と視覚的に判断します。
11. 繰り返しの有無(重要な制約)
二元配置で交互作用を検出するには、各セルで2回以上の繰り返し()が必須です。
- 繰り返しあり():交互作用 と誤差 を別々に推定できる。主効果A・主効果B・交互作用の3つを検定できる。
- 繰り返しなし():各セルに1観測しかないため、交互作用と誤差が分離できない。やむを得ず「交互作用はない」と仮定し、 に相当する変動を誤差に含めて、主効果A・主効果Bだけを検定する。
要するに「セルの内側のばらつき(純粋な誤差)」を測るには各セルに複数データが要る、ということです。1個ずつでは「セル特有の効果(交互作用)」と「偶然の誤差」を区別できません。
12. 二元配置の分散分析表(繰り返しあり)
| 変動要因 | 平方和 | 自由度 | 平均平方 | F値 |
|---|---|---|---|---|
| 主効果 | ||||
| 主効果 | ||||
| 交互作用 | ||||
| 誤差 | ||||
| 全体 |
ここでも自由度は縦に足すと合います:。各効果はそれぞれ自分の平均平方を誤差平均平方 で割ったFで検定します(誤差を共通の物差しにする点は一元配置と同じ)。
⚠️ 検定の読む順序:まず交互作用を見る。交互作用が有意なら、主効果を単独で解釈してはいけません(次の⚠️節・Q&Aで詳述)。
13. 回帰モデルとの関係(ANOVAは線形モデルの特殊形)
分散分析は、ダミー変数を説明変数にした重回帰とまったく同じことをしています。一元配置( 群)なら、 個のダミー変数 (第1群を基準)を用意して、
という重回帰を立てると、 は基準群の平均、各 は「基準群との平均の差」を表します。このモデルで「全係数が0(=全群同じ平均)」を検定するのが、回帰でいう全体のF検定であり、それが分散分析のF検定と一致します。計画行列とダミー変数の扱いは 重回帰分析 の通りです。
graph TD
LM["一般線形モデル<br/>y = Xβ + ε"]
LM --> REG["回帰分析<br/>Xが連続変数"]
LM --> ANOVA["分散分析<br/>Xがダミー変数(質的)"]
LM --> ANCOVA["共分散分析<br/>連続+ダミー混在"]
ANOVA --> ONE["一元配置(1因子)"]
ANOVA --> TWO["二元配置(2因子+交互作用)"]
要するに「回帰も分散分析も、同じ線形モデル の 計画行列 の中身が違うだけ」です。説明変数が連続値なら回帰、質的(カテゴリ)ならダミーを介して分散分析になります。
特に2群のときは 。 2群の母平均の差の検定は、(a) 等分散を仮定した2標本t検定(母平均の検定(1標本・2標本t検定))でも、(b) の一元配置分散分析でもできます。両者は同じ結論を与え、統計量には次の厳密な関係があります。
自由度1のF分布は、自由度 のt分布を2乗した分布に一致するためです。t検定は方向(どちらが大きいか)を片側で見られますが、 のANOVAは右片側Fなので両側t検定と等価になります。要するに「2群の差の検定では、tでもFでも同じことをしている」わけです。
14. 多重比較との接続
分散分析が有意でも、結論は「どこかに差がある」までです。「どの群とどの群が違うか」を特定するには、分散分析の後に事後検定(多重比較, post-hoc test)を行います。
flowchart TD
START["3群以上の平均を比較したい"] --> ANOVA["分散分析(F検定)"]
ANOVA --> Q{"F検定は有意?"}
Q -- "いいえ(p ≥ α)" --> STOP["差があるとは言えない<br/>(多重比較に進まない)"]
Q -- "はい(p < α)" --> POST["事後検定(多重比較)"]
POST --> P1["Tukey法(全ペア比較)"]
POST --> P2["Bonferroni法(有意水準を分割)"]
POST --> P3["Dunnett法(対照群との比較)"]
P1 --> RESULT["どの群間に差があるか特定"]
P2 --> RESULT
P3 --> RESULT
なぜ最初から全ペアをt検定で比べないのか――それが次の⚠️節と 多重比較 の主題です。多重比較は第一種の過誤を制御する仕組みを持っています。
⚠️ 引っかけポイント・頻出論点
(1) 「分散分析」という名前だが平均の差を見ている。 調べているのは群の母平均の差です。「分散の差を検定するもの」と誤解しがちですが、分散(ばらつき)は平均の差を測るための物差しとして使っているだけです。
(2) なぜ多重t検定ではダメか(第一種過誤の膨張)。 ← 多重比較の動機 3群を「1-2」「1-3」「2-3」と総当たりでt検定すると、検定を繰り返すたびに「本当は差がないのに差ありと誤る」確率(第一種過誤 )が積み重なります。各検定を で行っても、 回の独立な検定で少なくとも1回誤る確率は
3ペア()なら と、名目の5%を大きく超えて**約14%**まで膨らみます。分散分析は「全群一括で1回だけ」検定するので、この膨張を起こさずに済みます。第一種・第二種の過誤の一般論は 第一種の過誤・第二種の過誤・検出力(2種類の誤りとトレードオフ・サンプルサイズ設計) を参照してください。
(3) 前提(正規性・等分散性・独立性)。 分散分析はパラメトリック検定であり、次の3つを仮定します。
- 正規性:各群の母集団が正規分布。
- 等分散性:全群の母分散が等しい( 共通)。これがF統計量で が打ち消せる前提でした。
- 独立性:観測値が互いに独立。
頑健性の目安:正規性は中心極限定理のおかげで標本サイズが大きければ比較的崩れに強い。等分散性も各群の標本数が等しければ(つり合い型なら)ある程度頑健。一方、独立性の崩れには非常に弱く、崩れると第一種過誤が大きく狂います(同じ被験者を繰り返し測るなど)。等分散の確認にはルビーン検定やバートレット検定が使われます。崩れているときはウェルチの分散分析やノンパラメトリック法(クラスカル・ウォリス検定)に切り替えます。
(4) 交互作用が有意なとき、主効果を単独で解釈する誤り。 二元配置で交互作用が有意なら、「Aの効果」を一言で語ることはできません。Aの効果はBの水準ごとに違う(それが交互作用の意味)からです。この場合は、Bの水準を固定したうえでAの効果を見る(単純主効果の分析)のが正しい読み方です。「交互作用が有意だったのに、主効果Aだけ取り出して『Aには効果がある』と結論する」のは典型的な誤りです。
(5) 自由度の取り違え(右片側・分子分母の順)。 F分布の自由度は (分子の自由度, 分母の自由度) = (要因の自由度, 誤差の自由度) の順です。一元配置なら 。逆に書くと臨界値が変わります。また分散分析は常に右片側で読みます。
よくある疑問(Q&A)
Q1. なぜ3群の比較でt検定を3回繰り返してはいけないのですか?
検定を繰り返すたびに第一種の過誤(本当は差がないのに差ありと誤る確率)が積み上がるからです。各回 でも、3ペアでは少なくとも1回誤る確率が まで膨らみます。分散分析は「全群まとめて1回だけ」検定するのでこの膨張を防ぎます。要するに「検定の回数を増やすほど偶然のアタリを引きやすくなる」のを避ける仕組みです。
Q2. 分散分析で有意になりました。これで『どの群が高い/低い』と言えますか?
言えません。分散分析の対立仮説は「少なくとも1組の母平均が異なる」なので、有意でも「どこかに差がある」までしか分かりません。どの群間に差があるかを特定するには、分散分析の後に多重比較(Tukey法・Bonferroni法など)を行います。順序は「ANOVAでゲートを開け→多重比較で犯人を特定」です。
Q3. 名前が「分散」分析なのに、なぜ平均の差を調べるのですか?
「群間のばらつき(=群平均の散らばり)」を「群内のばらつき(=誤差)」と比べることで、平均の差を検出しているからです。群平均がよく散らばっている(群間が大きい)のに群内が小さければ、その散らばりは偶然では説明できない=平均に差がある、と判断します。分散は平均の差を測るための物差しであって、調べたい対象はあくまで平均です。
Q4. 二元配置で「交互作用が有意」とは結局どういう状態ですか?
「一方の因子の効果が、もう一方の因子の水準によって変わる」状態です。例:肥料(因子A)の効き方が、土の種類(因子B)によって違う。交互作用プロットで折れ線が**平行でない(交差する)**ときに交互作用ありです。このとき「肥料の効果」を一言では語れず、土の種類ごとに分けて見る必要があります。検出には各セルで繰り返し()が必要です。
Q5. 分散分析と回帰分析は別物ですか?
別物ではなく、同じ線形モデルの2つの顔です。説明変数が連続値なら回帰、カテゴリ(質的変数)ならダミー変数を介した分散分析になります。実際、2群の比較では分散分析のF統計量とt検定のt統計量の間に という厳密な関係が成り立ちます。「回帰も分散分析も の計画行列の中身が違うだけ」と理解すると、両者が一本につながります。
まとめ
- 分散分析は3群以上の母平均の差を、ばらつきの分解とF検定で調べる手法。名前は分散だが調べるのは平均。
- 一元配置:総平方和が (群間+群内)に分解される。クロス項は「平均まわりの偏差の和=0」により消える。
- 自由度も と分解。平均平方 , 、F値 。
- のもとで と が独立なカイ二乗に従い、その比が 。 が打ち消すので未知でも検定できる。右片側検定。
- 二元配置:。交互作用は「セル平均が主効果だけで説明できる値からのズレ」。検出には繰り返し が必須。
- ANOVAはダミー変数回帰の特殊形。2群なら 。
- 有意でも「どこかに差がある」まで→多重比較で群間を特定。多重t検定は第一種過誤を膨張させる(これが多重比較の動機)。
- 前提は正規性・等分散性・独立性。独立性の崩れに最も弱い。交互作用が有意なら主効果の単独解釈は禁物。
関連ノート
- 重回帰分析 分散分析はダミー変数を入れた重回帰の特殊形。計画行列の考え方が共通
- 単回帰分析 線形モデルの基本形。回帰と分散分析の出発点
- 母平均の検定(1標本・2標本t検定) 2群の平均の差の検定。 の分散分析と等価()
- 多重比較 分散分析の後にどの群間に差があるかを特定する事後検定
- 第一種の過誤・第二種の過誤・検出力(2種類の誤りとトレードオフ・サンプルサイズ設計) 多重比較が必要な理由(過誤の膨張)の土台
- 仮説検定の枠組み(帰無仮説・対立仮説・p値・有意水準) 帰無仮説・対立仮説・棄却域など検定の基本
- t分布・カイ二乗分布・F分布(標本分布の三役) F統計量が従う分布。平方和の比がF分布になる根拠