← 統計検定テキスト 一覧
📊 対象級:2級 | 重要度:A(頻出)
要点(BLUF)
単回帰分析 は、1つの説明変数 x x x y y y y = β 0 + β 1 x y=\beta_0+\beta_1 x y = β 0 + β 1 x 残差平方和を最小化 して決める(最小二乗法・OLS)。解は次の通り。S x x , S x y S_{xx},S_{xy} S xx , S x y
β ^ 1 = S x y S x x = ∑ ( x i − x ˉ ) ( y i − y ˉ ) ∑ ( x i − x ˉ ) 2 , β ^ 0 = y ˉ − β ^ 1 x ˉ \boxed{\;\hat\beta_1=\frac{S_{xy}}{S_{xx}}=\frac{\sum(x_i-\bar x)(y_i-\bar y)}{\sum(x_i-\bar x)^2},\qquad \hat\beta_0=\bar y-\hat\beta_1\bar x\;} β ^ 1 = S xx S x y = ∑ ( x i − x ˉ ) 2 ∑ ( x i − x ˉ ) ( y i − y ˉ ) , β ^ 0 = y ˉ − β ^ 1 x ˉ
あてはまりの良さは決定係数 R 2 = S S R / S S T R^2=\mathrm{SSR}/\mathrm{SST} R 2 = SSR / SST R 2 = r 2 R^2=r^2 R 2 = r 2 t = β ^ 1 / S E ( β ^ 1 ) ∼ t n − 2 t=\hat\beta_1/\mathrm{SE}(\hat\beta_1)\sim t_{n-2} t = β ^ 1 / SE ( β ^ 1 ) ∼ t n − 2
1. 単回帰モデルとは
2級で問われる単回帰は、次の母回帰モデル を前提にします。
y i = β 0 + β 1 x i + ε i , ε i ∼ iid N ( 0 , σ 2 ) ( i = 1 , … , n ) y_i=\beta_0+\beta_1 x_i+\varepsilon_i,\qquad \varepsilon_i \overset{\text{iid}}{\sim} N(0,\sigma^2)\quad(i=1,\dots,n) y i = β 0 + β 1 x i + ε i , ε i ∼ iid N ( 0 , σ 2 ) ( i = 1 , … , n )
β 0 \beta_0 β 0 x = 0 x=0 x = 0 y y y β 1 \beta_1 β 1 x x x y y y ε i \varepsilon_i ε i
要するに「y y y x x x β 0 + β 1 x \beta_0+\beta_1 x β 0 + β 1 x ε \varepsilon ε ( x i , y i ) (x_i,y_i) ( x i , y i ) β 0 , β 1 \beta_0,\beta_1 β 0 , β 1 推定値 β ^ 0 , β ^ 1 \hat\beta_0,\hat\beta_1 β ^ 0 , β ^ 1
y ^ i = β ^ 0 + β ^ 1 x i \hat y_i=\hat\beta_0+\hat\beta_1 x_i y ^ i = β ^ 0 + β ^ 1 x i とします。観測値とあてはめ値のズレ e i = y i − y ^ i e_i=y_i-\hat y_i e i = y i − y ^ i 残差 と呼びます。誤差 ε i \varepsilon_i ε i e i e_i e i
2. 最小二乗法(OLS)による係数の導出
2.1 何を最小化するのか
「良い直線」とは、全データの残差ができるだけ小さい直線です。残差は正負どちらにもなるので、2乗して足した残差平方和 を最小化します。
S ( β 0 , β 1 ) = ∑ i = 1 n ( y i − β 0 − β 1 x i ) 2 S(\beta_0,\beta_1)=\sum_{i=1}^{n}\bigl(y_i-\beta_0-\beta_1 x_i\bigr)^2 S ( β 0 , β 1 ) = i = 1 ∑ n ( y i − β 0 − β 1 x i ) 2 これを β 0 , β 1 \beta_0,\beta_1 β 0 , β 1 S S S β 0 , β 1 \beta_0,\beta_1 β 0 , β 1
2.2 正規方程式(偏微分して0と置く)
まず β 0 \beta_0 β 0
∂ S ∂ β 0 = ∑ i = 1 n 2 ( y i − β 0 − β 1 x i ) ( − 1 ) = 0 \frac{\partial S}{\partial \beta_0}=\sum_{i=1}^{n}2\bigl(y_i-\beta_0-\beta_1 x_i\bigr)(-1)=0 ∂ β 0 ∂ S = i = 1 ∑ n 2 ( y i − β 0 − β 1 x i ) ( − 1 ) = 0 要するに「残差の総和は0」という条件です。両辺を − 2 -2 − 2
∑ y i − n β 0 − β 1 ∑ x i = 0 ⟹ n β 0 + β 1 ∑ x i = ∑ y i (1) \sum y_i-n\beta_0-\beta_1\sum x_i=0
\quad\Longrightarrow\quad
n\beta_0+\beta_1\sum x_i=\sum y_i \tag{1} ∑ y i − n β 0 − β 1 ∑ x i = 0 ⟹ n β 0 + β 1 ∑ x i = ∑ y i ( 1 ) 次に β 1 \beta_1 β 1
∂ S ∂ β 1 = ∑ i = 1 n 2 ( y i − β 0 − β 1 x i ) ( − x i ) = 0 \frac{\partial S}{\partial \beta_1}=\sum_{i=1}^{n}2\bigl(y_i-\beta_0-\beta_1 x_i\bigr)(-x_i)=0 ∂ β 1 ∂ S = i = 1 ∑ n 2 ( y i − β 0 − β 1 x i ) ( − x i ) = 0 要するに「残差と x x x
β 0 ∑ x i + β 1 ∑ x i 2 = ∑ x i y i (2) \beta_0\sum x_i+\beta_1\sum x_i^2=\sum x_i y_i \tag{2} β 0 ∑ x i + β 1 ∑ x i 2 = ∑ x i y i ( 2 ) (1)(2) を連立したものを正規方程式 と呼びます。未知数2つ・式2本の連立1次方程式です。
2.3 傾き β ^ 1 \hat\beta_1 β ^ 1
(1) の両辺を n n n β 0 + β 1 x ˉ = y ˉ \beta_0+\beta_1\bar x=\bar y β 0 + β 1 x ˉ = y ˉ
β ^ 0 = y ˉ − β ^ 1 x ˉ (3) \hat\beta_0=\bar y-\hat\beta_1\bar x \tag{3} β ^ 0 = y ˉ − β ^ 1 x ˉ ( 3 ) これを (2) に代入して β 0 \beta_0 β 0
( y ˉ − β 1 x ˉ ) ∑ x i + β 1 ∑ x i 2 = ∑ x i y i (\bar y-\beta_1\bar x)\sum x_i+\beta_1\sum x_i^2=\sum x_i y_i ( y ˉ − β 1 x ˉ ) ∑ x i + β 1 ∑ x i 2 = ∑ x i y i ∑ x i = n x ˉ \sum x_i=n\bar x ∑ x i = n x ˉ β 1 \beta_1 β 1
β 1 ( ∑ x i 2 − n x ˉ 2 ) = ∑ x i y i − n x ˉ y ˉ \beta_1\Bigl(\sum x_i^2-n\bar x^2\Bigr)=\sum x_i y_i-n\bar x\,\bar y β 1 ( ∑ x i 2 − n x ˉ 2 ) = ∑ x i y i − n x ˉ y ˉ ここで、偏差平方和・偏差積和の展開公式 を使います(証明は補足を参照)。
S x x = ∑ ( x i − x ˉ ) 2 = ∑ x i 2 − n x ˉ 2 , S x y = ∑ ( x i − x ˉ ) ( y i − y ˉ ) = ∑ x i y i − n x ˉ y ˉ S_{xx}=\sum (x_i-\bar x)^2=\sum x_i^2-n\bar x^2,\qquad
S_{xy}=\sum (x_i-\bar x)(y_i-\bar y)=\sum x_i y_i-n\bar x\,\bar y S xx = ∑ ( x i − x ˉ ) 2 = ∑ x i 2 − n x ˉ 2 , S x y = ∑ ( x i − x ˉ ) ( y i − y ˉ ) = ∑ x i y i − n x ˉ y ˉ したがって、
β ^ 1 = S x y S x x = ∑ ( x i − x ˉ ) ( y i − y ˉ ) ∑ ( x i − x ˉ ) 2 \boxed{\;\hat\beta_1=\frac{S_{xy}}{S_{xx}}=\frac{\sum(x_i-\bar x)(y_i-\bar y)}{\sum(x_i-\bar x)^2}\;} β ^ 1 = S xx S x y = ∑ ( x i − x ˉ ) 2 ∑ ( x i − x ˉ ) ( y i − y ˉ ) 要するに「傾き=(x x x y y y S x y S_{xy} S x y x x x S x x S_{xx} S xx x x x y y y x x x
補足:偏差平方和の展開公式 ∑ ( x i − x ˉ ) 2 = ∑ ( x i 2 − 2 x ˉ x i + x ˉ 2 ) = ∑ x i 2 − 2 x ˉ ∑ x i + n x ˉ 2 = ∑ x i 2 − 2 x ˉ ( n x ˉ ) + n x ˉ 2 = ∑ x i 2 − n x ˉ 2 \sum(x_i-\bar x)^2=\sum(x_i^2-2\bar x x_i+\bar x^2)=\sum x_i^2-2\bar x\sum x_i+n\bar x^2=\sum x_i^2-2\bar x(n\bar x)+n\bar x^2=\sum x_i^2-n\bar x^2 ∑ ( x i − x ˉ ) 2 = ∑ ( x i 2 − 2 x ˉ x i + x ˉ 2 ) = ∑ x i 2 − 2 x ˉ ∑ x i + n x ˉ 2 = ∑ x i 2 − 2 x ˉ ( n x ˉ ) + n x ˉ 2 = ∑ x i 2 − n x ˉ 2 S x y S_{xy} S x y
2.4 回帰直線が必ず ( x ˉ , y ˉ ) (\bar x,\bar y) ( x ˉ , y ˉ )
式 (3) を変形すると y ˉ = β ^ 0 + β ^ 1 x ˉ \bar y=\hat\beta_0+\hat\beta_1\bar x y ˉ = β ^ 0 + β ^ 1 x ˉ ( x ˉ , y ˉ ) (\bar x,\bar y) ( x ˉ , y ˉ ) y ^ = β ^ 0 + β ^ 1 x \hat y=\hat\beta_0+\hat\beta_1 x y ^ = β ^ 0 + β ^ 1 x
つまり最小二乗回帰直線は必ずデータの重心 ( x ˉ , y ˉ ) (\bar x,\bar y) ( x ˉ , y ˉ ) 。根っこは正規方程式 (1)(残差の総和が0)にあります。これは2級で頻出の知識です。
3. 決定係数 R 2 R^2 R 2
3.1 平方和の3分解(SST = SSR + SSE)
あてはまりの良さを測るため、y y y y i y_i y i
y i − y ˉ = ( y ^ i − y ˉ ) ⏟ 回帰で説明 + ( y i − y ^ i ) ⏟ 残差 y_i-\bar y=\underbrace{(\hat y_i-\bar y)}_{\text{回帰で説明}}+\underbrace{(y_i-\hat y_i)}_{\text{残差}} y i − y ˉ = 回帰で説明 ( y ^ i − y ˉ ) + 残差 ( y i − y ^ i ) 両辺を2乗して総和を取ると、
∑ ( y i − y ˉ ) 2 = ∑ ( y ^ i − y ˉ ) 2 + ∑ ( y i − y ^ i ) 2 + 2 ∑ ( y ^ i − y ˉ ) ( y i − y ^ i ) \sum(y_i-\bar y)^2=\sum(\hat y_i-\bar y)^2+\sum(y_i-\hat y_i)^2+2\sum(\hat y_i-\bar y)(y_i-\hat y_i) ∑ ( y i − y ˉ ) 2 = ∑ ( y ^ i − y ˉ ) 2 + ∑ ( y i − y ^ i ) 2 + 2 ∑ ( y ^ i − y ˉ ) ( y i − y ^ i ) ここで交差項が消える のが要点です。y ^ i − y ˉ = β ^ 1 ( x i − x ˉ ) \hat y_i-\bar y=\hat\beta_1(x_i-\bar x) y ^ i − y ˉ = β ^ 1 ( x i − x ˉ ) y ^ i = y ˉ + β ^ 1 ( x i − x ˉ ) \hat y_i=\bar y+\hat\beta_1(x_i-\bar x) y ^ i = y ˉ + β ^ 1 ( x i − x ˉ )
2 β ^ 1 ∑ ( x i − x ˉ ) e i = 2 β ^ 1 ( ∑ x i e i ⏟ = 0 − x ˉ ∑ e i ⏟ = 0 ) = 0 2\hat\beta_1\sum(x_i-\bar x)\,e_i
=2\hat\beta_1\Bigl(\underbrace{\textstyle\sum x_i e_i}_{=0}-\bar x\underbrace{\textstyle\sum e_i}_{=0}\Bigr)=0 2 β ^ 1 ∑ ( x i − x ˉ ) e i = 2 β ^ 1 ( = 0 ∑ x i e i − x ˉ = 0 ∑ e i ) = 0 正規方程式から ∑ e i = 0 \sum e_i=0 ∑ e i = 0 ∑ x i e i = 0 \sum x_i e_i=0 ∑ x i e i = 0 x x x
∑ ( y i − y ˉ ) 2 ⏟ S S T = ∑ ( y ^ i − y ˉ ) 2 ⏟ S S R + ∑ ( y i − y ^ i ) 2 ⏟ S S E \boxed{\;\underbrace{\sum(y_i-\bar y)^2}_{\mathrm{SST}}
=\underbrace{\sum(\hat y_i-\bar y)^2}_{\mathrm{SSR}}
+\underbrace{\sum(y_i-\hat y_i)^2}_{\mathrm{SSE}}\;} SST ∑ ( y i − y ˉ ) 2 = SSR ∑ ( y ^ i − y ˉ ) 2 + SSE ∑ ( y i − y ^ i ) 2 記号 名前 意味 SST 全平方和(Total) y y y = S y y =S_{yy} = S y y SSR 回帰平方和(Regression) 直線で説明できたばらつき SSE 残差平方和(Error) 直線で説明できなかったばらつき
表記注意:教科書によって SSR と SSE の R/E を逆の意味(SSR を residual=残差)に使う流儀があります。2級の文脈では「Regression=回帰=説明できた分」「Error=残差」で統一して覚えるのが安全です。要するにどちらが分子で全変動に近づくほど良いか で判別すれば取り違えません。
3.2 決定係数の定義
y y y 決定係数 R 2 R^2 R 2
R 2 = S S R S S T = 1 − S S E S S T R^2=\frac{\mathrm{SSR}}{\mathrm{SST}}=1-\frac{\mathrm{SSE}}{\mathrm{SST}} R 2 = SST SSR = 1 − SST SSE 要するに「R 2 R^2 R 2 y y y x x x 0 ≤ R 2 ≤ 1 0\le R^2\le 1 0 ≤ R 2 ≤ 1 R 2 = 0.8 R^2=0.8 R 2 = 0.8 y y y x x x
3.3 単回帰では R 2 = r 2 R^2=r^2 R 2 = r 2
単回帰に限り、決定係数は相関係数 r r r に一致します。導出します。SSR を β ^ 1 \hat\beta_1 β ^ 1 y ^ i − y ˉ = β ^ 1 ( x i − x ˉ ) \hat y_i-\bar y=\hat\beta_1(x_i-\bar x) y ^ i − y ˉ = β ^ 1 ( x i − x ˉ )
S S R = ∑ ( y ^ i − y ˉ ) 2 = β ^ 1 2 ∑ ( x i − x ˉ ) 2 = β ^ 1 2 S x x \mathrm{SSR}=\sum(\hat y_i-\bar y)^2=\hat\beta_1^2\sum(x_i-\bar x)^2=\hat\beta_1^2\,S_{xx} SSR = ∑ ( y ^ i − y ˉ ) 2 = β ^ 1 2 ∑ ( x i − x ˉ ) 2 = β ^ 1 2 S xx ここに β ^ 1 = S x y / S x x \hat\beta_1=S_{xy}/S_{xx} β ^ 1 = S x y / S xx
S S R = ( S x y S x x ) 2 S x x = S x y 2 S x x \mathrm{SSR}=\left(\frac{S_{xy}}{S_{xx}}\right)^2 S_{xx}=\frac{S_{xy}^2}{S_{xx}} SSR = ( S xx S x y ) 2 S xx = S xx S x y 2 S S T = S y y \mathrm{SST}=S_{yy} SST = S y y
R 2 = S S R S S T = S x y 2 / S x x S y y = S x y 2 S x x S y y = ( S x y S x x S y y ) 2 = r 2 R^2=\frac{\mathrm{SSR}}{\mathrm{SST}}=\frac{S_{xy}^2/S_{xx}}{S_{yy}}=\frac{S_{xy}^2}{S_{xx}S_{yy}}=\left(\frac{S_{xy}}{\sqrt{S_{xx}S_{yy}}}\right)^2=r^2 R 2 = SST SSR = S y y S x y 2 / S xx = S xx S y y S x y 2 = ( S xx S y y S x y ) 2 = r 2 最後の括弧の中は相関係数 r = S x y S x x S y y r=\dfrac{S_{xy}}{\sqrt{S_{xx}S_{yy}}} r = S xx S y y S x y
R 2 = r 2 ( 単回帰のみ ) \boxed{\;R^2=r^2\quad(\text{単回帰のみ})\;} R 2 = r 2 ( 単回帰のみ ) 要するに「単回帰なら、決定係数は相関係数を2乗するだけで出る」。相関係数 r = 0.9 r=0.9 r = 0.9 R 2 = 0.81 R^2=0.81 R 2 = 0.81 R 2 R^2 R 2 y y y 重回帰分析 で扱います)。
4. 回帰係数の検定(t検定)
4.1 何を検定するのか
傾き β ^ 1 \hat\beta_1 β ^ 1 x x x y y y β 1 ≠ 0 \beta_1\neq 0 β 1 = 0
H 0 : β 1 = 0 ( x は y の説明に寄与しない) H 1 : β 1 ≠ 0 H_0:\beta_1=0\quad\text{($x$ は $y$ の説明に寄与しない)}\qquad
H_1:\beta_1\neq 0 H 0 : β 1 = 0 ( x は y の説明に寄与しない) H 1 : β 1 = 0 を検定します。β 1 = 0 \beta_1=0 β 1 = 0 x x x y ˉ \bar y y ˉ
4.2 β ^ 1 \hat\beta_1 β ^ 1
β ^ 1 \hat\beta_1 β ^ 1
V a r ( β ^ 1 ) = σ 2 S x x \mathrm{Var}(\hat\beta_1)=\frac{\sigma^2}{S_{xx}} Var ( β ^ 1 ) = S xx σ 2 となります(β ^ 1 = ∑ w i y i , w i = ( x i − x ˉ ) / S x x \hat\beta_1=\sum w_i y_i,\ w_i=(x_i-\bar x)/S_{xx} β ^ 1 = ∑ w i y i , w i = ( x i − x ˉ ) / S xx y i y_i y i ∑ w i 2 = 1 / S x x \sum w_i^2=1/S_{xx} ∑ w i 2 = 1/ S xx σ 2 \sigma^2 σ 2
σ ^ 2 = S S E n − 2 = ∑ ( y i − y ^ i ) 2 n − 2 \hat\sigma^2=\frac{\mathrm{SSE}}{n-2}=\frac{\sum(y_i-\hat y_i)^2}{n-2} σ ^ 2 = n − 2 SSE = n − 2 ∑ ( y i − y ^ i ) 2 で置き換えます(分母が n − 2 n-2 n − 2
S E ( β ^ 1 ) = σ ^ S x x \mathrm{SE}(\hat\beta_1)=\frac{\hat\sigma}{\sqrt{S_{xx}}} SE ( β ^ 1 ) = S xx σ ^ 要するに「傾きの推定のブレ」は、ノイズの大きさ σ ^ \hat\sigma σ ^ x x x S x x \sqrt{S_{xx}} S xx します。x x x
4.3 検定統計量と自由度 n − 2 n-2 n − 2
β ^ 1 \hat\beta_1 β ^ 1 σ ^ \hat\sigma σ ^
t = β ^ 1 − 0 S E ( β ^ 1 ) = β ^ 1 σ ^ / S x x ∼ t n − 2 ( H 0 のもと ) t=\frac{\hat\beta_1-0}{\mathrm{SE}(\hat\beta_1)}=\frac{\hat\beta_1}{\hat\sigma/\sqrt{S_{xx}}}\ \sim\ t_{n-2}\quad(H_0\text{ のもと}) t = SE ( β ^ 1 ) β ^ 1 − 0 = σ ^ / S xx β ^ 1 ∼ t n − 2 ( H 0 のもと ) この t t t t分布・カイ二乗分布・F分布(標本分布の三役) と 母平均の検定(1標本・2標本t検定) と同じ構造です(正規 ÷ 推定した標準偏差 → t分布)。
自由度がなぜ n − 2 n-2 n − 2 残差 e i e_i e i n n n ∑ e i = 0 \sum e_i=0 ∑ e i = 0 ∑ x i e i = 0 \sum x_i e_i=0 ∑ x i e i = 0 n − 2 n-2 n − 2 β 0 , β 1 \beta_0,\beta_1 β 0 , β 1 n − 2 n-2 n − 2 σ ^ 2 \hat\sigma^2 σ ^ 2 n − 2 n-2 n − 2 E [ σ ^ 2 ] = σ 2 E[\hat\sigma^2]=\sigma^2 E [ σ ^ 2 ] = σ 2
判定は通常の両側検定と同じ。∣ t ∣ > t n − 2 , α / 2 \lvert t\rvert>t_{n-2,\,\alpha/2} ∣ t ∣ > t n − 2 , α /2 H 0 H_0 H 0 β 0 \beta_0 β 0 t = β ^ 0 / S E ( β ^ 0 ) ∼ t n − 2 t=\hat\beta_0/\mathrm{SE}(\hat\beta_0)\sim t_{n-2} t = β ^ 0 / SE ( β ^ 0 ) ∼ t n − 2
5. 回帰の分散分析(F検定)と F = t 2 F=t^2 F = t 2
平方和分解を使うと、回帰全体の有意性をF検定 でも調べられます。各平方和を自由度で割った平均平方を比にします。
F = S S R / 1 S S E / ( n − 2 ) = 回帰の平均平方 残差の平均平方 ∼ F 1 , n − 2 ( H 0 : β 1 = 0 ) F=\frac{\mathrm{SSR}/1}{\mathrm{SSE}/(n-2)}=\frac{\text{回帰の平均平方}}{\text{残差の平均平方}}\ \sim\ F_{1,\,n-2}\quad(H_0:\beta_1=0) F = SSE / ( n − 2 ) SSR /1 = 残差の平均平方 回帰の平均平方 ∼ F 1 , n − 2 ( H 0 : β 1 = 0 )
分子の自由度1:説明変数が1つ(推定した傾きの数)
分母の自由度 n − 2 n-2 n − 2
要因 平方和 自由度 平均平方 回帰 SSR 1 1 1 S S R / 1 \mathrm{SSR}/1 SSR /1 残差 SSE n − 2 n-2 n − 2 S S E / ( n − 2 ) \mathrm{SSE}/(n-2) SSE / ( n − 2 ) 全体 SST n − 1 n-1 n − 1 —
自由度は 回帰1 + 残差 ( n − 2 ) (n-2) ( n − 2 ) ( n − 1 ) (n-1) ( n − 1 ) と足し算で整合します(全体の自由度が n − 1 n-1 n − 1 y ˉ \bar y y ˉ
単回帰では F = t 2 F=t^2 F = t 2 確認します。
F = S S R S S E / ( n − 2 ) = β ^ 1 2 S x x σ ^ 2 = β ^ 1 2 σ ^ 2 / S x x = ( β ^ 1 σ ^ / S x x ) 2 = t 2 F=\frac{\mathrm{SSR}}{\mathrm{SSE}/(n-2)}=\frac{\hat\beta_1^2\,S_{xx}}{\hat\sigma^2}
=\frac{\hat\beta_1^2}{\hat\sigma^2/S_{xx}}
=\left(\frac{\hat\beta_1}{\hat\sigma/\sqrt{S_{xx}}}\right)^2=t^2 F = SSE / ( n − 2 ) SSR = σ ^ 2 β ^ 1 2 S xx = σ ^ 2 / S xx β ^ 1 2 = ( σ ^ / S xx β ^ 1 ) 2 = t 2 途中で S S R = β ^ 1 2 S x x \mathrm{SSR}=\hat\beta_1^2 S_{xx} SSR = β ^ 1 2 S xx σ ^ 2 = S S E / ( n − 2 ) \hat\sigma^2=\mathrm{SSE}/(n-2) σ ^ 2 = SSE / ( n − 2 ) 単回帰では「傾きのt検定」と「回帰のF検定」は完全に同じ結論 を出します(t n − 2 t_{n-2} t n − 2 F 1 , n − 2 F_{1,n-2} F 1 , n − 2 分散分析 )。
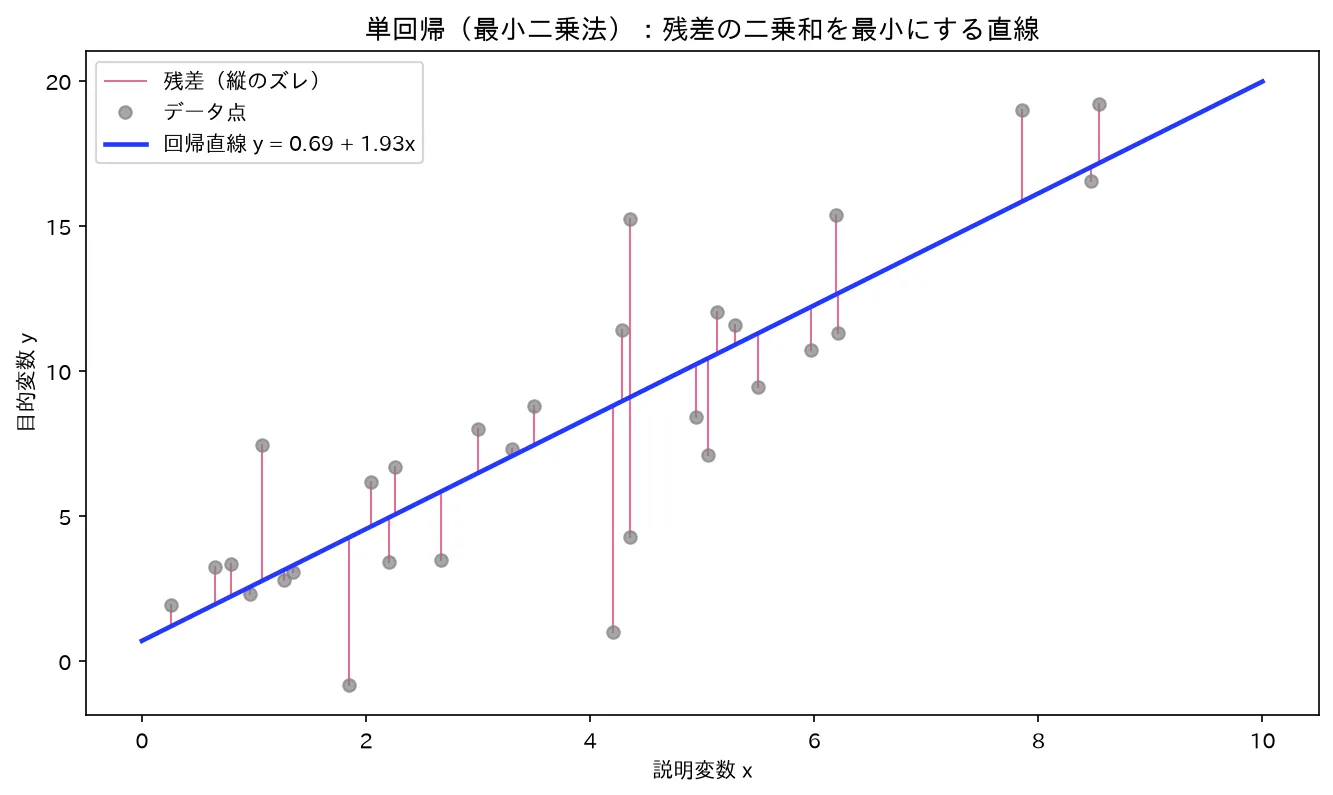
6. 図解
散布図・回帰直線・残差の関係(構造)
真の関係 y=2+1.5x のデータに最小二乗で直線を当てた様子。赤い縦線が残差で、その二乗和を最小化する直線が回帰直線。図は simulations/tankaiki_ols_zansa.py で生成。
各データ点の y y y
graph LR
X["説明変数 x_i"] --> PRED["あてはめ値<br/>ŷ_i = β̂₀ + β̂₁ x_i<br/>(回帰直線上の点)"]
OBS["観測値 y_i<br/>(実データ点)"] --> RES["残差<br/>e_i = y_i − ŷ_i"]
PRED --> RES
RES --> OBJ["残差平方和 Σe_i²<br/>を最小化 → β̂₀, β̂₁"]
平方和分解の構造(SST = SSR + SSE)
総変動が「説明できた分」と「できなかった分」に割れ、その比が決定係数になります。
graph TD
SST["SST 全平方和<br/>Σ(y_i − ȳ)²<br/>自由度 n−1"]
SST --> SSR["SSR 回帰平方和<br/>Σ(ŷ_i − ȳ)²<br/>自由度 1<br/>=説明できた分"]
SST --> SSE["SSE 残差平方和<br/>Σ(y_i − ŷ_i)²<br/>自由度 n−2<br/>=説明できない分"]
SSR --> R2["決定係数<br/>R² = SSR / SST = 1 − SSE/SST<br/>(単回帰では R² = r²)"]
SSE --> R2
SSR --> FTEST["F = (SSR/1) / (SSE/(n−2))<br/>~ F(1, n−2)<br/>単回帰では F = t²"]
SSE --> FTEST
7. 具体例(手計算)
次の5点で傾き・切片・決定係数を求めます。
x i x_i x i 1 2 3 4 5 y i y_i y i 2 4 5 4 5
ステップ1:平均 x ˉ = 1 + 2 + 3 + 4 + 5 5 = 3 \bar x=\dfrac{1+2+3+4+5}{5}=3 x ˉ = 5 1 + 2 + 3 + 4 + 5 = 3 y ˉ = 2 + 4 + 5 + 4 + 5 5 = 4 \bar y=\dfrac{2+4+5+4+5}{5}=4 y ˉ = 5 2 + 4 + 5 + 4 + 5 = 4
ステップ2:偏差積和・偏差平方和
項目 i = 1 i=1 i = 1 i = 2 i=2 i = 2 i = 3 i=3 i = 3 i = 4 i=4 i = 4 i = 5 i=5 i = 5 x i − x ˉ x_i-\bar x x i − x ˉ − 2 -2 − 2 − 1 -1 − 1 0 0 0 1 1 1 2 2 2 y i − y ˉ y_i-\bar y y i − y ˉ − 2 -2 − 2 0 0 0 1 1 1 0 0 0 1 1 1 積 4 4 4 0 0 0 0 0 0 0 0 0 2 2 2 ( x i − x ˉ ) 2 (x_i-\bar x)^2 ( x i − x ˉ ) 2 4 4 4 1 1 1 0 0 0 1 1 1 4 4 4
S x y = 4 + 0 + 0 + 0 + 2 = 6 , S x x = 4 + 1 + 0 + 1 + 4 = 10 S_{xy}=4+0+0+0+2=6,\qquad S_{xx}=4+1+0+1+4=10 S x y = 4 + 0 + 0 + 0 + 2 = 6 , S xx = 4 + 1 + 0 + 1 + 4 = 10 ステップ3:係数
β ^ 1 = S x y S x x = 6 10 = 0.6 , β ^ 0 = y ˉ − β ^ 1 x ˉ = 4 − 0.6 × 3 = 2.2 \hat\beta_1=\frac{S_{xy}}{S_{xx}}=\frac{6}{10}=0.6,\qquad
\hat\beta_0=\bar y-\hat\beta_1\bar x=4-0.6\times 3=2.2 β ^ 1 = S xx S x y = 10 6 = 0.6 , β ^ 0 = y ˉ − β ^ 1 x ˉ = 4 − 0.6 × 3 = 2.2 回帰直線は y ^ = 2.2 + 0.6 x \hat y=2.2+0.6x y ^ = 2.2 + 0.6 x ( x ˉ , y ˉ ) = ( 3 , 4 ) (\bar x,\bar y)=(3,4) ( x ˉ , y ˉ ) = ( 3 , 4 ) 2.2 + 0.6 × 3 = 4 2.2+0.6\times3=4 2.2 + 0.6 × 3 = 4
ステップ4:決定係数 S y y = ∑ ( y i − y ˉ ) 2 = 4 + 0 + 1 + 0 + 1 = 6 S_{yy}=\sum(y_i-\bar y)^2=4+0+1+0+1=6 S y y = ∑ ( y i − y ˉ ) 2 = 4 + 0 + 1 + 0 + 1 = 6
R 2 = S x y 2 S x x S y y = 6 2 10 × 6 = 36 60 = 0.6 R^2=\frac{S_{xy}^2}{S_{xx}S_{yy}}=\frac{6^2}{10\times 6}=\frac{36}{60}=0.6 R 2 = S xx S y y S x y 2 = 10 × 6 6 2 = 60 36 = 0.6 相関係数は r = 0.6 ≈ 0.775 r=\sqrt{0.6}\approx0.775 r = 0.6 ≈ 0.775 R 2 = r 2 R^2=r^2 R 2 = r 2 y y y x x x
8. ⚠️ 引っかけ・頻出論点
回帰直線は重心 ( x ˉ , y ˉ ) (\bar x,\bar y) ( x ˉ , y ˉ ) (正規方程式の帰結)。これを問う択一が出ます。単回帰では R 2 = r 2 R^2=r^2 R 2 = r 2 。「r = − 0.8 r=-0.8 r = − 0.8 R 2 R^2 R 2 0.64 0.64 0.64 R 2 R^2 R 2 r r r x x x y y y y y y x x x S x y / S x x S_{xy}/S_{xx} S x y / S xx x x x y y y S x y / S y y S_{xy}/S_{yy} S x y / S y y r 2 r^2 r 2 自由度は n − 2 n-2 n − 2 。母平均の検定(n − 1 n-1 n − 1 F = t 2 F=t^2 F = t 2 F \sqrt{F} F ∣ t ∣ \lvert t\rvert ∣ t ∣ σ ^ 2 \hat\sigma^2 σ ^ 2 n n n n − 1 n-1 n − 1 n − 2 n-2 n − 2 標準誤差 S E ( β ^ 1 ) = σ ^ / S x x \mathrm{SE}(\hat\beta_1)=\hat\sigma/\sqrt{S_{xx}} SE ( β ^ 1 ) = σ ^ / S xx :x x x
9. よくある疑問(Q&A)
Q1. 相関分析と回帰分析は何が違うのですか。
相関は2変数の「連動の強さ」を対称に測るもの(x x x y y y r r r x x x y y y 非対称 です(y y y x x x x x x y y y r r r − 1 ≤ r ≤ 1 -1\le r\le1 − 1 ≤ r ≤ 1 β ^ 1 \hat\beta_1 β ^ 1 y y y x x x 2変数の記述(散布図・共分散・相関係数)── 相関≠因果/rは直線関係しか測れない/外れ値1点で激変 。
Q2. R 2 R^2 R 2
言えません。R 2 R^2 R 2 y y y x x x R 2 R^2 R 2 R 2 R^2 R 2 残差分析・回帰診断 )。
Q3. R 2 R^2 R 2 x x x y y y
言えません。回帰は予測の道具であって、因果の証明ではありません。x x x y y y y y y x x x
Q4. データの範囲外の x x x
危険です。回帰直線は観測した x x x x x x
Q5. 回帰係数 β ^ 1 \hat\beta_1 β ^ 1
そのままでは比較しにくいです。β ^ 1 \hat\beta_1 β ^ 1 x x x y y y x x x x , y x,y x , y 標準化した単回帰の傾きは相関係数 r r r (x , y x,y x , y S x x = S y y = n − 1 S_{xx}=S_{yy}=n-1 S xx = S y y = n − 1 β ^ 1 = S x y / S x x = r \hat\beta_1=S_{xy}/S_{xx}=r β ^ 1 = S x y / S xx = r
10. まとめ
単回帰は y = β 0 + β 1 x + ε y=\beta_0+\beta_1 x+\varepsilon y = β 0 + β 1 x + ε 最小二乗法 で推定する。正規方程式を解いて β ^ 1 = S x y / S x x \hat\beta_1=S_{xy}/S_{xx} β ^ 1 = S x y / S xx β ^ 0 = y ˉ − β ^ 1 x ˉ \hat\beta_0=\bar y-\hat\beta_1\bar x β ^ 0 = y ˉ − β ^ 1 x ˉ ( x ˉ , y ˉ ) (\bar x,\bar y) ( x ˉ , y ˉ )
あてはまりは平方和分解 SST = SSR + SSE と決定係数 R 2 = S S R / S S T = 1 − S S E / S S T R^2=\mathrm{SSR}/\mathrm{SST}=1-\mathrm{SSE}/\mathrm{SST} R 2 = SSR / SST = 1 − SSE / SST R 2 = r 2 R^2=r^2 R 2 = r 2
傾きの有意性は t = β ^ 1 / S E ( β ^ 1 ) ∼ t n − 2 t=\hat\beta_1/\mathrm{SE}(\hat\beta_1)\sim t_{n-2} t = β ^ 1 / SE ( β ^ 1 ) ∼ t n − 2 σ ^ / S x x \hat\sigma/\sqrt{S_{xx}} σ ^ / S xx n − 2 n-2 n − 2
回帰全体は F = ( S S R / 1 ) / ( S S E / ( n − 2 ) ) ∼ F 1 , n − 2 F=(\mathrm{SSR}/1)/(\mathrm{SSE}/(n-2))\sim F_{1,n-2} F = ( SSR /1 ) / ( SSE / ( n − 2 )) ∼ F 1 , n − 2 F = t 2 F=t^2 F = t 2
R 2 R^2 R 2
関連ノート
2変数の記述(散布図・共分散・相関係数)── 相関≠因果/rは直線関係しか測れない/外れ値1点で激変 相関係数 r r r S x y S_{xy} S x y 正規分布(標準正規・標準化) 誤差項 ε ∼ N ( 0 , σ 2 ) \varepsilon\sim N(0,\sigma^2) ε ∼ N ( 0 , σ 2 ) t分布・カイ二乗分布・F分布(標本分布の三役) t検定・F検定の分布、t 2 ∼ F ( 1 , ν ) t^2\sim F(1,\nu) t 2 ∼ F ( 1 , ν ) 点推定(推定量の良さ:不偏性・一致性・有効性・十分性) β ^ 0 , β ^ 1 , σ ^ 2 \hat\beta_0,\hat\beta_1,\hat\sigma^2 β ^ 0 , β ^ 1 , σ ^ 2 区間推定(母平均・母比率・母分散の信頼区間) 回帰係数・予測値の信頼区間の土台仮説検定の枠組み(帰無仮説・対立仮説・p値・有意水準) 帰無仮説・棄却の一般論母平均の検定(1標本・2標本t検定) 同じ「正規÷推定標準偏差→t分布」の構造残差分析・回帰診断 モデルの妥当性チェック(R 2 R^2 R 2 重回帰分析 説明変数を複数にした拡張(R 2 R^2 R 2 分散分析 平方和分解とF検定の一般論