📊 対象級:2級 ・ 準1級 | 重要度:B(標準)
要点(BLUF)
- 回帰分析は「線形性・独立性・等分散性・(推測には)正規性」という前提の上に立つ。残差分析はこの前提が崩れていないかを点検する作業です。
- 2級:残差を予測値に対してプロットし、パターン(曲がり=非線形、ラッパ型=不等分散)を目視で読む。
- 準1級:ハット行列・てこ比・Cook距離を使い、外れ値と影響点を数値的に区別する理論まで踏み込む。
回帰係数の当てはめが終わったら、それで終わりではありません。「その回帰モデルが前提としている仮定は本当に満たされているか?」を確かめるのが残差分析・回帰診断です。決定係数 が高くても前提が崩れていれば、係数の検定や予測区間は信用できません。
まず全体像をつかみましょう。診断は「どの仮定を」「何で確認し」「崩れていたらどう対処するか」の3点セットで考えます。
flowchart TD
A[回帰モデルを当てはめた] --> B{線形性は妥当か}
B -->|残差 vs 予測値プロット<br>に曲がりがある| B1[多項式項の追加<br>変数変換 log など]
B -->|曲がりなし| C{等分散性は成り立つか}
C -->|ラッパ型・<br>残差の幅が変化| C1[従属変数の変換<br>重み付き最小二乗 WLS]
C -->|幅が一定| D{誤差は独立か}
D -->|時系列で<br>残差が連なる| D1[ダービン・ワトソン比で確認<br>時系列モデルへ]
D -->|独立| E{正規性は成り立つか}
E -->|正規Q-Qが<br>直線から外れる| E1[変数変換<br>サンプル増で近似改善]
E -->|直線に乗る| F{外れ値・影響点はないか}
F -->|てこ比・Cook距離が<br>大きい点がある| F1[影響点を精査<br>除外の妥当性を検討]
F -->|なし| G[モデルは前提を満たす]
この記事では、まず全級共通の土台である「4つの仮定」を整理し、そのあと2級(目視チェック)と準1級(数値指標の理論)に分けて見ていきます。
共通の土台:回帰モデルが置く4つの仮定
線形回帰モデルを次のように書きます。
ここで が誤差項(観測できない真のズレ)です。最小二乗法(OLS)で係数を推定し、その良し悪しを保証するために、誤差項に次の仮定を置きます。これはガウス・マルコフの仮定と呼ばれる前提群です。
| 仮定 | 内容 | 数式 | 崩れると何が問題か |
|---|---|---|---|
| 線形性 | 平均構造が説明変数の線形結合 | 係数が真の関係を捉えられない(推定にバイアス) | |
| 独立性 | 誤差どうしが無相関 | 標準誤差が狂い、検定が誤る | |
| 等分散性 | 誤差の分散が一定 | 係数は不偏だが標準誤差が狂う | |
| 正規性 | 誤差が正規分布に従う | 区間推定・検定が正当化できない |
要するに:線形性は係数そのものの正しさ、等分散性と独立性は標準誤差(=検定)の正しさ、正規性は区間推定・検定の正当化に効きます。役割が違うので、どれが崩れると何が困るかをセットで覚えるのが急所です。
ここでガウス・マルコフの定理を一言。前の4つのうち**線形性・独立性・等分散性の3つ(正規性は不要)**が成り立てば、OLS推定量は「線形不偏推定量の中で分散が最小」になります。これを BLUE(Best Linear Unbiased Estimator) と呼びます。正規性は BLUE には不要で、あくまで「区間推定や 検定・ 検定を正当化する」ために後から要る、という切り分けが重要です。
なぜこの切り分けが効くのか、誤差項の現れ方を図にすると分かりやすいです。
graph LR
A[誤差項 ε の仮定] --> B[線形性 E ε =0]
A --> C[等分散性 V ε =σ²]
A --> D[独立性 Cov=0]
A --> E[正規性 正規分布]
B --> F[係数の不偏性<br>= 推定値そのもの]
C --> G[標準誤差の正しさ<br>= 検定・区間の幅]
D --> G
E --> H[t/F分布の正当化<br>= 検定・区間の前提]
2級レベル
ここで問われるのは「残差を予測値に対してプロットし、パターンの有無で仮定の妥当性を目視判断する」基本まで。てこ比・Cook距離の計算は準1級。
残差とは何か
残差 は、実測値 と回帰式による予測値 の差です。
要するに:残差は「観測できない誤差 の手元での見積もり」です。誤差そのものは見えませんが、残差なら計算できる。だから残差の振る舞いを見て、誤差の仮定が崩れていないかを推測する——これが残差分析の発想の根っこです。
残差プロット:横軸に予測値、縦軸に残差
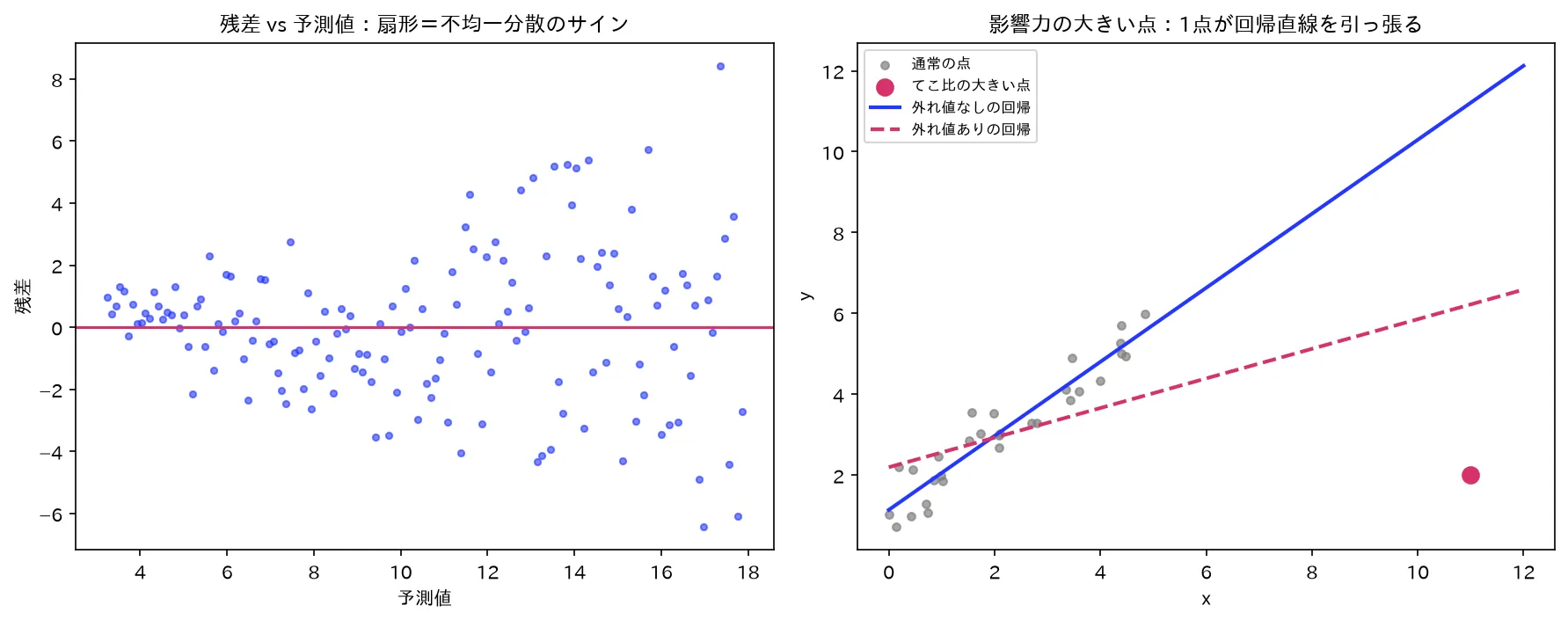
図は simulations/zansa_shindan_keijou.py で生成。
最も基本の診断図が残差プロットです。横軸に予測値 (または説明変数 )、縦軸に残差 をとった散布図です。
理想は「0を中心に、特定のパターンなく一様に散らばる」雲のような形。仮定が満たされていれば、残差は予測値と無関係(独立)で、ばらつき幅も一定(等分散)になるはずだからです。
逆に、次のようなパターンが見えたら仮定が崩れているサインです。散布図そのものは文章で説明します(点の配置を言葉でイメージしてください)。
| 残差プロットの形 | 読み取れる問題 | 崩れている仮定 |
|---|---|---|
| 0を中心にランダムな雲 | 問題なし(理想形) | — |
| U字・逆U字に曲がる | 直線では捉えきれない曲線関係がある | 線形性 |
| 右へ行くほど縦の幅が広がるラッパ型(または狭まる) | ばらつきが予測値とともに変化 | 等分散性 |
| 一定の傾向で上下に連なる(波打つ) | 隣り合う誤差が相関(特に時系列) | 独立性 |
| 1点だけ大きく飛び離れている | 外れ値の疑い | (後述:準1級で精査) |
要するに:「曲がり=線形性の崩れ」「ラッパ=等分散性の崩れ」「波打ち=独立性の崩れ」。この3対応を覚えるのが2級の最重要ポイントです。残差プロットは「モデルの定式化が合っているか」を映す鏡なので、パターンが見えたら が高くても定式化を疑います。
ラッパ型を構造で示すと、次のイメージです(点群の上端・下端の包絡線が末広がりになる)。
graph LR
A["予測値 小"] -->|残差の幅 狭い| B["予測値 中"]
B -->|残差の幅 やや広い| C["予測値 大"]
C -->|残差の幅 広い| D["= ラッパ型<br>不等分散のサイン"]
正規Q-Qプロット:正規性の目視チェック
誤差の正規性を確かめるには正規Q-Qプロット(正規確率プロット)を使います。残差を小さい順に並べた分位点(縦軸)と、標準正規分布の理論分位点(横軸)を対にしてプロットします。
正規性が成り立っていれば、点はほぼ一直線(傾き1の直線)に乗ります。 両端が直線から大きく反れていれば、裾が重い・歪んでいるなど正規分布からのズレを示します。
要するに:Q-Qプロットは「残差の分布が正規分布とどれだけ似ているか」を直線への乗り具合で見る図です。直線に乗れば正規、外れれば非正規。
2級での問われ方
- 残差プロットの図を見せて「どの仮定が崩れているか」を選ばせる(曲がり/ラッパ型/波打ちの判別)。
- 「残差プロットにラッパ型のパターンがある。これは何を示すか」→ 等分散性の崩れ(不均一分散)。
- 正規Q-Qプロットが直線に乗るかどうかで正規性を判断させる。
- 残差の定義 、残差の和が(切片ありモデルで)0になることの確認。
準1級レベル
ここから加わるのは、外れ値と影響点を数値で区別する理論。ハット行列・てこ比・標準化残差・Cook距離を、なぜその式になるかまで掘り下げます。
なぜ生の残差をそのまま使えないのか
2級では残差プロットを目視しました。しかし生の残差 は、点ごとに分散が違うという厄介な性質を持ちます。これを示すのが次の式です(導出は後述)。
要するに:残差の分散は一定の ではなく、(てこ比)が大きい点ほど小さくなる。つまり「データの端にある点ほど、回帰直線が無理にその点へ寄ってしまい、見かけの残差が小さく出る」。生の残差の大小だけで外れ値を判定すると、端の点を見逃します。だから分散を揃える標準化が必要になります。
この を理解するために、まずハット行列を導入します。
ハット行列の導出と性質
重回帰を行列で書きます。 は の観測ベクトル、 は の計画行列( はパラメータ総数。切片があれば1列目が全部1の列で、それも に含めて数える)、 は の係数ベクトルです。
最小二乗推定量は次で与えられます(導出は重回帰分析に譲ります)。
予測値ベクトル は、これを に代入すると
となります。ここで現れた
が**ハット行列(hat matrix)**です。
要するに: は観測ベクトル に掛けると予測値 を作り出す行列。「 に帽子(ハット)をかぶせて にする」のでハット行列と呼びます。 は「予測値は観測値の線形結合(重み付き平均)である」ことを意味します。
ハット行列の3つの性質(準1級頻出)を導出します。
性質1:対称性
は対称行列なのでその逆行列も対称、つまり 。よって 。
要するに: は左右対称。これは が「ある部分空間への直交射影」であることの現れです。
性質2:冪等性
途中で とその逆行列が打ち消し合って単位行列 になる点がカギです。
要するに:「2回射影しても1回と同じ」。 をもう一度射影しても動かない=すでに の張る空間の上にいる、ということ。 は** の列空間への直交射影行列**です。
性質3:トレース (=てこ比の和)
トレースの循環性 を使います。
ここで は 単位行列( はパラメータ総数)。トレースは対角成分の和なので
要するに:てこ比の合計はパラメータ数 に等しい。 個の点で を分け合うので、てこ比の平均は 。ある点の がこの平均 より際立って大きければ「てこ比が高い点」です。
⚠️ 記法注意:教科書によっては「説明変数の個数 +切片」を分けて書き、 と表記します。これは (切片込みのパラメータ総数)という意味で、本記事の と同じです。混乱しやすいので、 が切片を含むのかどうかを問題文ごとに確認してください。
てこ比(leverage)
ハット行列の対角成分 を**てこ比(leverage、梃子比)**と呼びます。 番目の点の説明変数ベクトルを ( の第 行)とすると
と書けます。性質として 、和は 。
の意味: より、 は「自分の予測値 が、自分自身の観測値 にどれだけ引っ張られるか」の重みです。
要するに:てこ比が高い点とは「説明変数の値が他の点から離れた、データ空間の端っこにある点」。端の点は回帰直線を梃子(てこ)のように大きく動かす力を持つので「てこ比」と呼びます。 の値が外れているかどうかとは無関係で、 側の位置だけで決まるのがポイントです。判定の目安は (または )。
標準化残差・スチューデント化残差
生の残差は分散 が点ごとに違うので、これを割って分散を揃えます。
まず を導出します。残差ベクトルは 。 を代入すると、( は が を動かさないこと、性質2の射影性から)なので
誤差の分散共分散行列は (等分散・独立の仮定)だから
ここで も対称かつ冪等( がそうだから もそう)であることを使いました。対角成分を取り出すと
要するに:上の式変形のキモは「残差は誤差を で射影したもの」「 も射影行列なので2乗しても変わらない」の2点。これでてこ比が大きい点ほど残差の分散が小さくなることが数式で確定します。
そこで分散を揃えた残差を作ります。 は未知なので、その推定量 (残差の標準偏差)で置き換えます。
内部スチューデント化残差(標準化残差):
これで各残差はおよそ分散1に揃い、点どうしを同じ物差しで比較できます。 あたりが外れ値の目安です。
外部スチューデント化残差(スチューデント化削除残差):分散の推定にその点 自身を除いた推定量 を使うバージョンです。
この は自由度 の 分布に従うため、外れ値かどうかを 検定で正式に判定できます。
要するに:内部版は「全データで測った物差し」、外部版は「その点を抜いて測った物差し」。外れ値の点が物差し()自体を膨らませてしまうと、その点の異常さが薄まって見える。外部版はその点を除いて物差しを作るので、本物の外れ値をより鋭く検出できます。準1級では「外部スチューデント化残差は 分布に従い外れ値検出の感度が高い」がポイント。
Cook の距離:影響点の検出
外れ値( が外れている)でも、てこ比が低ければ回帰係数はあまり動きません。逆にてこ比が高い点が外れていると、係数が大きく動きます。「その1点を除いたら回帰の予測がどれだけ動くか」を1つの数値にまとめたのがCook の距離です。
( は内部スチューデント化残差、 はパラメータ数)。
要するに:Cook距離は**「残差の大きさ 」と「てこ比 」の掛け算**。残差が大きいほど、かつてこ比が高いほど大きくなる。外れ値とてこ比の両方が揃って初めて大きくなる——これが「影響点」の数学的定義です。目安は (または )で影響が大きいと判断。
別の見方として、Cook距離は「点 を除いて推定し直した予測値 が、全データでの予測値 からどれだけずれるか」を標準化した量でもあります。
この2つの式が一致することが、Cook距離が「影響度=予測の動き」を測っている根拠です。
外れ値 vs 影響点(準1級の核心)
混同しやすい2つを整理します。
| 概念 | 定義 | 検出指標 | 係数への影響 |
|---|---|---|---|
| 外れ値(outlier) | が回帰の傾向から大きく外れる点 | スチューデント化残差 大 | てこ比が低ければ小さい |
| てこ比の高い点(high leverage) | が他の点から離れた端の点 | 大 | が傾向どおりなら小さい |
| 影響点(influential point) | 除くと係数・予測が大きく変わる点 | Cook距離 大 | 大きい |
要するに:「外れ値」と「影響点」は別物。影響点は「外れ値である(残差大)」かつ「てこ比が高い( が端)」の両方が揃った点。てこ比が低い外れ値は係数をあまり動かさない(影響点ではない)し、傾向どおりの位置にあるてこ比の高い点も係数を動かさない。Cook距離はこの両条件を1つの式で掛け合わせているのが美しい点です。
ダービン・ワトソン比:誤差の自己相関の検出
時系列データなどで「隣り合う誤差が相関していないか(独立性)」を調べる統計量が**ダービン・ワトソン比(Durbin-Watson statistic)**です。
- 値の範囲は 。
- :自己相関なし(独立性OK)。
- (0に近い):正の自己相関(残差が同じ符号で連なる)。
- (4に近い):負の自己相関(残差が符号を交互に変える)。
要するに: は「隣り合う残差の差の2乗和」を「残差の2乗和」で割ったもの。残差が正の相関を持つ(似た値が連なる)と分子 が小さくなり は0寄りに、交互に振れると分子が大きくなり は4寄りになります。標本での自己相関係数 を使うと という近似関係があり、 で になることが見て取れます。
⚠️ 引っかけポイント・頻出論点
- 外れ値 ≠ 影響点。「残差が大きい点は必ず係数を歪める」は誤り。てこ比が低ければ影響は小さい。Cook距離で初めて影響点と判定する。(準1級最頻出の引っかけ)
- 等分散性が崩れても係数は不偏。不均一分散があっても OLS 推定量 自体は不偏のまま。狂うのは標準誤差であり、その結果 検定・区間推定が誤る(しばしば標準誤差を過小評価し、有意でないものを有意と判定してしまう)。「不均一分散だと係数推定がバイアスを持つ」は誤り。
- 正規性は係数推定には不要。ガウス・マルコフの定理(BLUE)は正規性を仮定しない。正規性が要るのは 検定・ 検定・区間推定の正当化のみ。「正規性がないと最小二乗推定ができない」は誤り。
- 残差プロットのパターン=定式化ミスのサイン。 が高くても残差に曲がりがあれば線形モデルが不適切。「決定係数が高ければ残差診断は不要」は誤り。 は当てはまりの良さであって、前提の妥当性は別問題。
- てこ比は だけで決まる。 に は登場しない。「 が外れているとてこ比が高い」は誤り。てこ比は説明変数空間での位置の話。
- の の数え方。切片を含めるか否かで と の表記が揺れる。問題文の定義を必ず確認。
よくある疑問(Q&A)
Q1. 外れ値があったら必ず除外すべきですか?
A. いいえ。まず外れ値が「影響点かどうか」をCook距離で確かめます。てこ比が低い外れ値なら係数をほとんど動かさないので、無理に除く必要はありません。さらに、外れ値が測定ミスなのか本質的に重要な稀なケースなのかも区別が要ります。後者を機械的に除くとモデルが現実を見落とします。除外は「理由を示して慎重に」が原則です。
Q2. 等分散性が崩れているのに「係数は不偏」とはどういう意味ですか? 何が困るのですか?
A. の期待値が真の に一致する(平均的には正しい)という意味で、これは不均一分散があっても保たれます。困るのは標準誤差です。OLS の標準誤差の公式は「等分散」を前提に導かれているので、不均一分散だと標準誤差の計算式が間違った値を返します。多くの場合標準誤差を過小評価し、その結果 値が過大になって「本当は有意でない係数を有意と誤判定」します。つまり点推定は信じてよいが、検定・区間推定は信じられない、という状態です。
Q3. 標準化残差とスチューデント化残差はどう違うのですか?
A. どちらも残差を分散で割って揃えたものですが、分散の推定に使うデータが違います。内部スチューデント化残差(標準化残差) は全データで を推定します。外部スチューデント化残差 はその点 を除いて を推定します。外れ値はそれ自身が の推定値(残差の散らばり)を膨らませるので、内部版だと自分の異常さが薄まる。外部版はその点を抜いて物差しを作るので外れ値に鋭敏で、しかも 分布に従うので正式な検定ができます。準1級では外部版の「 分布に従う・感度が高い」が問われます。
Q4. 正規Q-Qプロットが直線から外れたら、回帰分析はやり直しですか?
A. 状況次第です。正規性は係数の点推定(不偏性・BLUE)には不要なので、点推定だけが目的なら大きな問題にはなりません。困るのは区間推定・検定で、これらは誤差の正規性を前提にしています。ただしサンプルサイズが大きければ中心極限定理により の分布は正規に近づくので、軽い非正規性の影響は薄まります。対処としては従属変数の変換(対数変換など)で正規に近づける、サンプルを増やす、などがあります。
Q5. 決定係数 が0.95と高ければ、残差分析はしなくてよいですか?
A. いいえ、 が高くても残差分析は必須です。 は「当てはまりの良さ(予測値が観測値をどれだけ説明したか)」を測るだけで、仮定の妥当性とは別物です。たとえば真の関係が曲線なのに直線を当てても が高く出ることがありますが、残差プロットには明確なU字が現れます。この場合、線形モデルは不適切で、予測区間も信用できません。 の高さと残差診断は独立にチェックすべき2つの観点です。
まとめ
- 残差分析・回帰診断は「回帰モデルが置く4つの仮定(線形性・独立性・等分散性・正規性)が崩れていないか」を点検する作業。
- 2級:残差プロット(横軸=予測値、縦軸=残差)の形を読む。曲がり=線形性、ラッパ型=等分散性、波打ち=独立性の崩れ。正規Q-Qプロットで正規性を目視。
- 準1級:ハット行列 から、てこ比 ( の端っこ度、)、標準化/スチューデント化残差(残差の分散 を揃える)、Cook距離 (外れ値×てこ比=影響度)を導出して数値判定する。
- 急所は**「外れ値 ≠ 影響点」と「等分散性が崩れても係数は不偏、狂うのは標準誤差」**という2つの切り分け。役割(係数の正しさ/標準誤差の正しさ/検定の正当化)でどの仮定が効くかを整理しておくと、引っかけに強くなります。
関連ノート
- 単回帰分析 残差・予測値の定義はここから
- 重回帰分析 最小二乗推定量 の導出と計画行列
- 正規分布(標準正規・標準化) 誤差項の正規性の前提
- t分布・カイ二乗分布・F分布(標本分布の三役) スチューデント化残差が従う 分布
- 仮説検定の枠組み(帰無仮説・対立仮説・p値・有意水準) 係数の検定が標準誤差の正しさに依存する理由
- 2変数の記述(散布図・共分散・相関係数)── 相関≠因果/rは直線関係しか測れない/外れ値1点で激変 相関と回帰の関係、散布図の見方