📊 対象級:準1級 ・ 1級 | 重要度:B(標準)
要点(BLUF)
- 尤度に基づく検定は3つある。尤度比検定(LRT)=対数尤度曲線の「高さの差」、Wald検定=MLEと帰無値の「横の距離」、スコア検定(ラオ検定)=帰無値での「接線の傾き」を見る。
- 3つとも帰無仮説の下で漸近的に に従う(=制約の数)。対数尤度を2次までテイラー展開すると3統計量は同じ二次形式に一致する——これが漸近同値の正体。
- 違いは計算に必要なものだけ。LRTは両方のMLE、Waldは非制約MLEのみ、スコアは制約MLEのみで計算できる。
1. なぜ3つもあるのか
同じ帰無仮説 を、尤度の情報を使って検定する方法が3通りある、という話です。すべて「最尤推定(MLE)の漸近理論」を土台にしています。前提として 最尤法・モーメント法(推定量の作り方と最尤推定量の漸近論) の尤度・対数尤度、推定量の評価(MSE・フィッシャー情報量・クラメール・ラオの不等式) のフィッシャー情報量 を使います。
記号を先に固めます。
- :尤度、:対数尤度
- :非制約MLE(パラメータを自由に動かして を最大化した値)
- :帰無仮説で固定する値(パラメータ1個を固定するなら「制約付きMLE」は そのもの)
- :スコア関数(対数尤度の傾き)
- :フィッシャー情報量(対数尤度の曲がり具合の期待値)
直観の核を1枚の図にします。対数尤度のグラフ を頭に描いてください。山の頂点が 、横軸上のどこかに帰無値 があります。3つの検定は、この山の「どこを測るか」が違うだけです。
graph TD
LL["対数尤度曲線 ℓ(θ)<br/>頂点 = 非制約MLE θ̂"]
LL -->|"頂点と θ0 の<br/>高さの差を測る"| LRT["尤度比検定 LRT<br/>−2 ln λ = 2{ℓ(θ̂) − ℓ(θ0)}"]
LL -->|"θ̂ と θ0 の<br/>横方向の距離を測る"| WALD["Wald 検定<br/>(θ̂ − θ0)² · I(θ̂)"]
LL -->|"θ0 での<br/>接線の傾きを測る"| SCORE["スコア検定 ラオ検定<br/>U(θ0)² / I(θ0)"]
LRT -->|"漸近的に一致"| CHI["χ²_r 分布<br/>(r = 制約の数)"]
WALD -->|"漸近的に一致"| CHI
SCORE -->|"漸近的に一致"| CHI
要するに:同じ山を「縦に測る(LRT)/横に測る(Wald)/傾きで測る(スコア)」の3視点。標本が大きければ山は放物線に近づき、3つの測り方は同じ値に収束します。
2. 3統計量の定式化
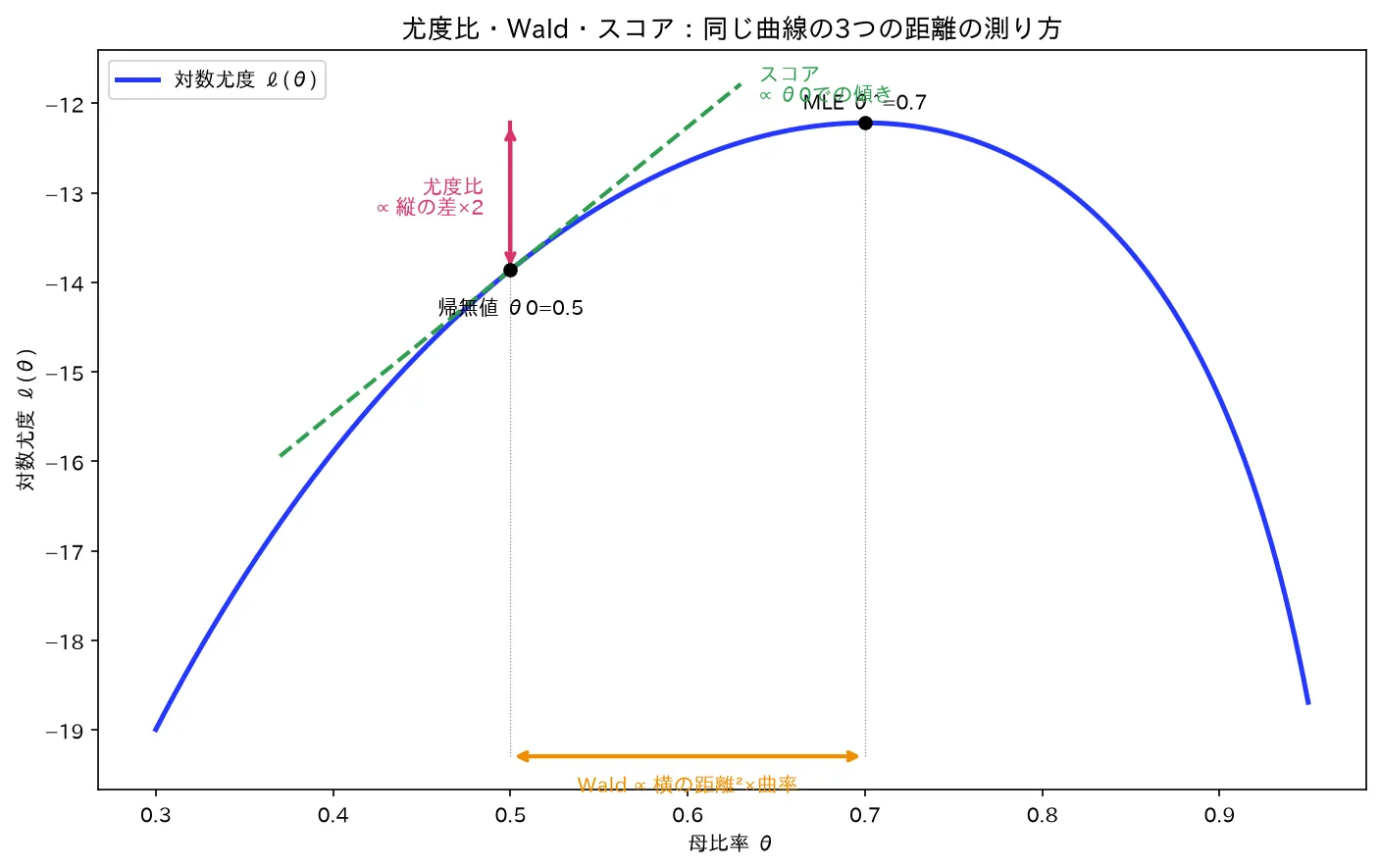
図は simulations/lr_wald_score_kika.py で生成。
ここではパラメータが1次元、制約が1個()の場合で式を書きます。多次元への一般化は後述します。
尤度比検定(LRT, Likelihood Ratio Test)
尤度比 を「制約付き尤度 ÷ 非制約尤度」で定義します。
分子は帰無仮説の枠 の中での最大尤度、分母は全空間 での最大尤度です。 なので必ず 。 が正しければ は1に近く、外れているほど0に近づきます。
検定統計量は対数を取って 倍します。
要するに:頂点の高さ と帰無値での高さ の差を2倍したもの。 が外れているほど頂点との段差が大きくなり、統計量が大きくなって棄却に向かいます。この 収束が Wilksの定理です。
Wald検定
MLEの漸近正規性を使います。正則条件の下で
が成り立つので、 を からの「ずれ」で測り、その分散 で標準化して2乗します。
要するに:頂点の位置 が帰無値 から横にどれだけ離れているかを、情報量で重みづけして測る。 と だけで計算できるのが利点(帰無仮説の下の再推定が要らない)。
スコア検定(ラオ検定, Score / Rao Test)
帰無値 における**スコア(傾き)**を見ます。 が真値に近ければ (頂点では傾き0)ですが、 が頂点から外れていれば 。この傾きの大きさを、スコアの分散 で標準化して2乗します。
要するに:頂点(非制約MLE)を一切計算せず、帰無値 での接線の急さだけで「 は頂点からどれくらいズレているか」を測る。 での評価だけで済むのが利点。
多次元(制約 )への一般化
パラメータが 次元ベクトル 、 個の等式制約を置く場合、上の3式はベクトル・行列版になります( はフィッシャー情報行列)。
いずれも自由度 の へ収束します。 分布そのものは t分布・カイ二乗分布・F分布(標本分布の三役) を参照。
3. 導出:なぜ3つとも漸近 χ² で一致するのか
ここが1級の核心です。「対数尤度を頂点まわりで2次までテイラー展開する」——この一手で3統計量が同じ二次形式に潰れる、という筋を追います。
ステップ1:対数尤度を まわりで2次展開する
を非制約MLE のまわりでテイラー展開し、 を代入します。
要するに:頂点では傾き なので1次の項が消える。残るのは「定数項+2次の項」だけ。これが「標本が大きいと対数尤度は放物線に見える」の数式的な中身です。
ステップ2:曲率をフィッシャー情報量に置き換える
2階微分 は観測情報量で、大数の法則により期待値であるフィッシャー情報量に近づきます。
( は一致推定量なので 、よって と は漸近的に同じ。)これをステップ1に入れて整理すると、
要するに:左辺はLRT統計量、右辺はWald統計量そのもの。2次展開しただけで が出ました。Waldは「対数尤度を放物線で近似したときのLRT」と言えます。
ステップ3:スコアを線形化して結びつける
次にスコア を のまわりで1次展開します( を使う)。
これがスコアとずれを結ぶ要の関係式です。両辺を2乗して で割ると、
要するに:左辺はスコア統計量 、右辺はWald統計量 (情報量を で評価した版)。つまり 。ステップ2と合わせて が示せました。
ステップ4:漸近分布を確定する
ずれ は、 の下でMLEの漸近正規性により
に従います。これを2乗したものが なので、標準正規の2乗=自由度1のカイ二乗として
制約が 個なら、独立な標準正規 個の2乗和になるので 。 に漸近同値だった LRT・スコアも同じ に収束します。
まとめると導出の骨は3つだけ:(1) 対数尤度を2次展開すると1次項が消える、(2) 曲率=フィッシャー情報量、(3) スコア ずれ。この3つで「高さ・横距離・傾き」が同じ二次形式に化けます。
graph LR
A["対数尤度 ℓ を θ̂ まわりで<br/>2次テイラー展開<br/>(1次項は U(θ̂)=0 で消える)"] --> B["LRT = 2{ℓ(θ̂)−ℓ(θ0)}<br/>≈ (θ̂−θ0)² I"]
A --> C["スコアを線形化<br/>U(θ0) ≈ −I(θ0)(θ̂−θ0)"]
C --> D["S = U(θ0)²/I(θ0)<br/>≈ (θ̂−θ0)² I"]
B --> E["3統計量が同じ二次形式<br/>(θ̂−θ0)² I に一致"]
D --> E
E --> F["√I (θ̂−θ0) → N(0,1)<br/>その2乗 → χ²_r"]
4. 具体例
例1:正規分布の母平均(分散既知)
、 既知。 を検定します。対数尤度から
3統計量を計算すると、いずれも
になり、完全に一致します( は標準正規検定統計量)。
要するに:正規・分散既知では対数尤度が厳密に放物線なので、2次展開が近似でなく等式になり、3検定が一致します。3検定がズレるのは対数尤度が非対称(歪んでいる)ときだけです。
例2:二項分布の成功確率
、観測値 、。 を検定します。
各統計量は次の形になります。
要するに:Waldは分母に (推定値で分散を見積もる)、スコアは分母に (帰無値で分散を見積もる)。ここが両者の決定的な違いで、 が0や1に近いとWaldの分散がほぼ0になり統計量が暴れます。比率の検定で「スコア型(Wilson)信頼区間の方が安定」と言われる理由です。
5. 試験での問われ方(級ごとの差)
このトピックは導出が準1級・1級で共通のため級セクションでは切らず、ここで級差をまとめます。
準1級:概念・使い分けが中心。「3検定がそれぞれ対数尤度の何(高さ/横距離/傾き)を見ているか」「どの検定がどのMLEだけで計算できるか」「自由度=制約の数」を問う選択・空欄補充レベル。 の事実(Wilksの定理)と自由度の決め方を答えられれば十分なことが多いです。年度により出題比重は変わるため要最新確認。
1級:導出・漸近論まで。対数尤度の2次展開から3統計量の漸近同値を示す、特定分布(正規・二項・ポアソン・指数など)で3統計量を具体的に計算させる、尤度比統計量の分布を導く、といった記述が問われます。スコア の線形化や、正則条件への言及まで踏み込めると安全です。
graph TD
Q["手元にあるMLEは?"]
Q -->|"両方のMLEがある"| L["尤度比検定 LRT<br/>(最も信頼できる・不変)"]
Q -->|"非制約MLE θ̂ だけ"| W2["Wald 検定<br/>(モデルを1回だけ当てはめ)"]
Q -->|"制約MLE θ0 だけ"| S2["スコア検定<br/>(帰無の下だけで済む)"]
⚠️ 引っかけ・頻出論点
- 自由度=制約の数 。(非制約モデルの自由パラメータ数)−(制約モデルの自由パラメータ数)。「パラメータの総数」ではなく「固定した(潰した)パラメータの数」。ここを取り違えると の自由度を誤る。
- Waldだけ再パラメータ化で不変でない。 で検定するか (例:)で検定するかでWald統計量の値が変わる。LRTとスコアは単調変換に対して不変(同じ値)。1級の頻出論点。
- 分母の評価点が違う。Waldは (推定値で評価)、スコアは (帰無値で評価)。LRTはそもそも情報量を陽に使わない。二項・ポアソンの例でこの差が効く。
- 有限標本では一致しない。漸近的に同値というだけで、サンプルが小さいと3つはズレる。一般に対数尤度が歪むときWaldが最も不安定(境界近くで分散推定が壊れる)、LRTが比較的頑健、スコアは帰無の下の評価なので堅実。
- Wilksの定理の正則条件。 がパラメータ空間の内点にある(境界にない)こと、フィッシャー情報量が正則であること等が必要。 が境界(例:分散 、混合比 )だと は標準の にならず、 の混合などになる。
- 尤度比は1以下。 で 。 を逆向き(非制約÷制約)に定義する流儀もあり、符号・向きの取り違えに注意。
よくある疑問(Q&A)
Q1. 3つはどう使い分ける? 計算量の観点で。 A. 必要なMLEが違うのが本質です。LRTは制約付き・非制約の両方のMLEが要る(最も手間だが最も信頼できる)。Waldは非制約MLE だけで済む(モデルを1回当てはめれば良い)。スコアは制約MLE(=帰無の下の推定)だけで済み、非制約MLEを一切計算しなくてよい。だから「複雑なフルモデルを当てはめたくない」場面ではスコア、「制約モデルが解けない」場面ではWaldが選ばれます。
Q2. なぜWaldだけ再パラメータ化で答えが変わるの? A. Waldは「 を頂点とする放物線近似の上で横距離を測る」検定だからです。 を に変換すると尤度の形(曲がり方)が変わり、放物線近似も別物になるため、 の値が変わります。一方LRTは尤度の比そのもの(高さの差)なので、軸の取り替えで高さは変わらず不変。スコアも不変( と が変換に整合して打ち消し合う)。実務的含意:Waldで非有意でもLRTでは有意、ということが起こり得ます。
Q3. 自由度はどう決まる? なぜ「制約の数」なの? A. 帰無仮説で固定したパラメータの数が自由度です。導出ステップ4で見たように、各制約が1個の標準正規を生み、その2乗が 。独立な制約 個なら が 個足されて になります。「自由パラメータをいくつ潰したか」=失った自由度の数、と理解すると直観的です。総パラメータ数ではない点に注意。
Q4. 有限標本ではどれが保守的(厳しめ)? A. 一概には言えませんが、傾向としてWaldは尤度が歪むと不安定で、信頼区間が広がりすぎたり(保守的)狭まりすぎたり(リベラル)します。特に二項で が0/1付近のとき分散推定 がほぼ0になり統計量が暴走します。LRTは比較的頑健、スコアは帰無の下で分散を評価するぶん境界付近でも安定しやすい。小標本ではLRTかスコアを優先するのが定石です。
Q5. Wilksの定理が成り立たないのはどんなとき? A. 正則条件が崩れるときです。代表例は がパラメータ空間の境界にある場合(分散が0、混合モデルで一成分の混合比が0、など)。このとき がその境界に張り付くので漸近正規性が崩れ、 は標準の ではなく の混合分布(例:)などになります。他にも、真の分布がモデル族に入っていない(誤特定)、情報量が特異、サンプルに依存して台が変わる(一様分布の端点など)場合も標準理論が使えません。
まとめ
- 尤度に基づく3検定は、対数尤度曲線の 高さ(LRT)/横距離(Wald)/傾き(スコア) という3視点。漸近的には同じ に収束する(=制約の数)。
- 漸近同値の正体は対数尤度の2次テイラー展開。1次項が で消え、曲率がフィッシャー情報量に化け、スコアは で線形化される。結果、3統計量が同じ二次形式 に潰れる。
- 使い分けは必要なMLEで決まる:LRT=両方、Wald=非制約のみ、スコア=制約のみ。Waldだけ再パラメータ化で不変でない。有限標本では3つはズレ、一般にLRT・スコアが頑健。
- 準1級は概念と使い分け、1級は導出と具体計算・漸近論まで。
関連ノート
- 最尤法・モーメント法(推定量の作り方と最尤推定量の漸近論) 尤度・対数尤度・MLEの土台
- 推定量の評価(MSE・フィッシャー情報量・クラメール・ラオの不等式) フィッシャー情報量・推定量の漸近分散
- 仮説検定の枠組み(帰無仮説・対立仮説・p値・有意水準) 帰無仮説・棄却域・有意水準の枠組み
- 第一種の過誤・第二種の過誤・検出力(2種類の誤りとトレードオフ・サンプルサイズ設計) 3検定の検出力比較の前提
- 点推定(推定量の良さ:不偏性・一致性・有効性・十分性) 点推定とMLEの位置づけ
- t分布・カイ二乗分布・F分布(標本分布の三役) 収束先の 分布