📊 対象級:準1級 ・ 1級 | 重要度:B(標準)
推定量の評価(MSE・フィッシャー情報量・クラメール・ラオの不等式)
要点(BLUF)
- 推定量の良さ=「真値からの平均的なズレの小ささ」。これを定量化するのが平均二乗誤差(MSE)。中心的な等式がバイアス-バリアンス分解: 要するに「外しの大きさは、ブレ(分散)と偏り(バイアス)の2成分に綺麗に割れる」。不偏推定量ならバイアス=0なので MSE=分散。
- フィッシャー情報量 :データが母数 について「どれだけ情報を持つか」の尺度。対数尤度の傾き(スコア)のバラつきで測る。2つの等価な表式がある: 要するに「対数尤度がどれだけ尖っているか」。尖っているほど を鋭く特定でき、情報量が大きい。
- クラメール・ラオの不等式(CR下限):(正則条件のもとで)任意の不偏推定量の分散は、フィッシャー情報量の逆数より小さくできない: 要するに「不偏でいる限り、分散には越えられない下限がある」。この下限に等号で到達する不偏推定量を有効推定量(最小分散不偏推定量の一種)と呼ぶ。
⚠️ 年度依存の注意:準1級・1級の出題範囲表は改訂されうる(要最新確認)。本ノートの級振り分けは現行ワークブック準拠の一般的傾向に基づく。
1. なぜ「推定量の評価」が要るのか
母数 (母平均・母分散・母比率など)を、標本から作った推定量 で当てにいきます。問題は 「良い推定量とは何か」を定義しないと、複数の候補を比べられないこと。
例えば母平均 を推定するのに、標本平均 も使えるし、中央値も、「最初の1個 」だって不偏推定量です。どれが優れているか? ──この優劣を測る共通のものさしが要る。それが本ノートの主題です。
評価軸は2層あります。
graph TD
A["推定量の評価"] --> B["有限標本での評価"]
A --> C["漸近的な評価<br/>(n→∞)"]
B --> B1["平均二乗誤差 MSE"]
B1 --> B2["バイアス(偏り)"]
B1 --> B3["バリアンス(分散・ブレ)"]
B --> B4["不偏なら MSE=分散<br/>→ 分散の下限はどこ?"]
B4 --> B5["クラメール・ラオ下限<br/>1 / I(θ)"]
B5 --> B6["フィッシャー情報量 I(θ)"]
C --> C1["一致性"]
C --> C2["漸近正規性"]
C --> C3["漸近有効性<br/>(CR下限を漸近的に達成)"]
不偏性・一致性・有効性の定義そのものは 点推定(推定量の良さ:不偏性・一致性・有効性・十分性) に置きます。本ノートはそれらを**測る道具(MSE・情報量・下限)**を深掘りします。
2. 平均二乗誤差(MSE)とバイアス-バリアンス分解
2.1 定義
推定量 の平均二乗誤差は、真値 からの二乗誤差の期待値:
要するに:何度も標本を取り直したときの「外し具合の二乗」を平均した量。小さいほど良い推定量です。
なぜ「二乗」かというと、(1) 正負のズレが打ち消し合わない、(2) 大きな外しをより重く罰する、(3) 後で分散と直結して解析が綺麗になる、の3点です。
2.2 バイアス(偏り)の定義
要するに:推定量を平均的にどれだけ的の中心からずらしているか。 なら で、これが**不偏(unbiased)**の定義です。
2.3 MSE分解の完全導出
主張:
導出。記号を軽くするため とおきます(推定量の期待値)。 に を挿入して2項に割ります:
ここで は「推定量の自分の平均からのブレ」、 は「平均と真値のズレ=バイアス(定数)」です。二乗して期待値を取ります:
第2項の中身に注目すると、 は定数なので期待値の外へ出せ、残る 。この交差項がちょうど消えるのが分解の肝です。よって
要するに:誤差を「自分の平均からのブレ」と「平均の真値からのズレ」に直交分解すると、クロス項が消えて二乗の和になる。統計版のピタゴラスの定理だと思ってよい(分散がブレの脚、バイアスが偏りの脚、MSEが斜辺の二乗)。
不偏推定量なら ゆえ MSE=分散。だから「不偏推定量の中で最良」を選ぶ問題は「分散を最小にする」問題に帰着する。これが後半のクラメール・ラオ下限へ直結する論理です。
2.4 バイアス-バリアンスのトレードオフ
graph LR
A["モデルを単純に<br/>(強い仮定)"] --> A1["バイアス↑"]
A --> A2["バリアンス↓"]
B["モデルを柔軟に<br/>(弱い仮定)"] --> B1["バイアス↓"]
B --> B2["バリアンス↑"]
A1 --> C["MSE=バイアス²+分散<br/>最小化したい"]
A2 --> C
B1 --> C
B2 --> C
要するに:MSEを下げるにはバイアスと分散の両方を下げたいが、両者は多くの場合トレードオフ。少し偏らせる代わりに分散を大きく減らせるなら、わざとバイアスを入れた(不偏でない)推定量がMSEでは勝つことがある。リッジ回帰や縮小推定(最尤法・モーメント法(推定量の作り方と最尤推定量の漸近論) の先にある正則化)がこの発想です。「不偏=常に最良」ではない、という1級級の論点。
2.5 数値例①:MSEで不偏推定量を逆転する縮小推定
母分散 の推定で、(不偏)と、最尤推定 (下方バイアスあり)を正規母集団で比べます。正規分布のもとでは、MSEを最小にする分母は でも でもなく :
不偏推定量(分母 )よりMSEが小さい偏った推定量が存在する具体例です。
要するに:「不偏性」と「MSE最小」は別の最適性。試験で「不偏推定量は常に最良か?」と問われたら No(MSE基準なら偏った推定量が勝ちうる)。
3. スコア関数とフィッシャー情報量
ここから「不偏推定量の分散はどこまで小さくできるか」を測るための道具立てに入ります。鍵は対数尤度の傾きです。
3.1 尤度・対数尤度・スコア関数
確率密度(質量)関数を とし、観測 を1つ持っているとします。 の関数として見た を尤度、その対数 を対数尤度と呼びます(対数尤度の微分の扱いは 確率変数の変換・モーメント母関数・積率 と同じ計算技法)。
スコア関数は対数尤度の に関する1階微分:
最後の等号は対数微分()です。要するに:スコアは「いまの をちょっと動かすと、観測データの尤もらしさがどっちにどれだけ増えるか」を表す。最尤推定はこれを0にする を探す操作です。
3.2 スコアの期待値は0(正則条件のもとで)
主張:。
導出。連続の場合で書きます(離散は積分を和に読み替え)。密度は全空間で積分すると1:
両辺を で微分します。ここで微分と積分の順序交換ができることを使います(これが正則条件の中核。台が に依らない等が必要):
被積分を と書き直すと:
要するに:「密度の総和は常に1で に依らない」を微分しただけで、スコアの平均は0と分かる。だからスコアの分散=スコアの2乗の期待値になる(平均0なので )。これが次のフィッシャー情報量の2表式に効きます。
3.3 フィッシャー情報量の定義(2つの表式)
フィッシャー情報量は、スコアの分散(=2乗の期待値)として定義されます:
I(\theta)=V[U(\theta)]=\mathbb E\!\left[\left(\frac{\partial}{\partial\theta}\log f(X;\theta)\right)^{\!2}\right].\tag{表式A}
要するに:スコア(対数尤度の傾き)がどれだけ大きく振れるか。傾きが激しく振れる=データが に敏感=情報が多い。
正則条件のもとで、これは2階微分を使っても書けます:
I(\theta)=-\,\mathbb E\!\left[\frac{\partial^2}{\partial\theta^2}\log f(X;\theta)\right].\tag{表式B}
要するに:対数尤度の曲率(凹み具合)の平均。対数尤度が最尤点で鋭く尖って(強く下に凸で)いるほど、 を鋭く特定でき情報量が大きい。実務では表式Bのほうが計算が楽なことが多い。
3.4 表式A=表式B の導出
スコアをもう一度 で微分します。 に商の微分(積の微分)を適用:
この両辺の期待値を取ります。第1項の期待値は
(ここでも微分と積分の順序交換=正則条件を使い、 を2回微分すると0。)よって
符号を移せば 。表式Aと表式Bが一致しました。
要するに:スコアをもう一段微分すると「曲率」と「スコアの2乗」の差になり、曲率の平均は(密度の規格化を2回微分して)0。だからスコアの2乗の平均=マイナス曲率の平均が成り立つ。等価性は正則条件に支えられている。
3.5 標本の加法性
独立同分布 の同時尤度は積 、対数尤度は和 。スコアも和になります。独立なら分散は和なので、
要するに:データを1個増やすごとにフィッシャー情報量は ずつ線形に積み上がる。標本が多いほど情報が増え、後述の下限 は で縮む(推定がだんだん精密になる)。
3.6 数値例②:代表分布のフィッシャー情報量
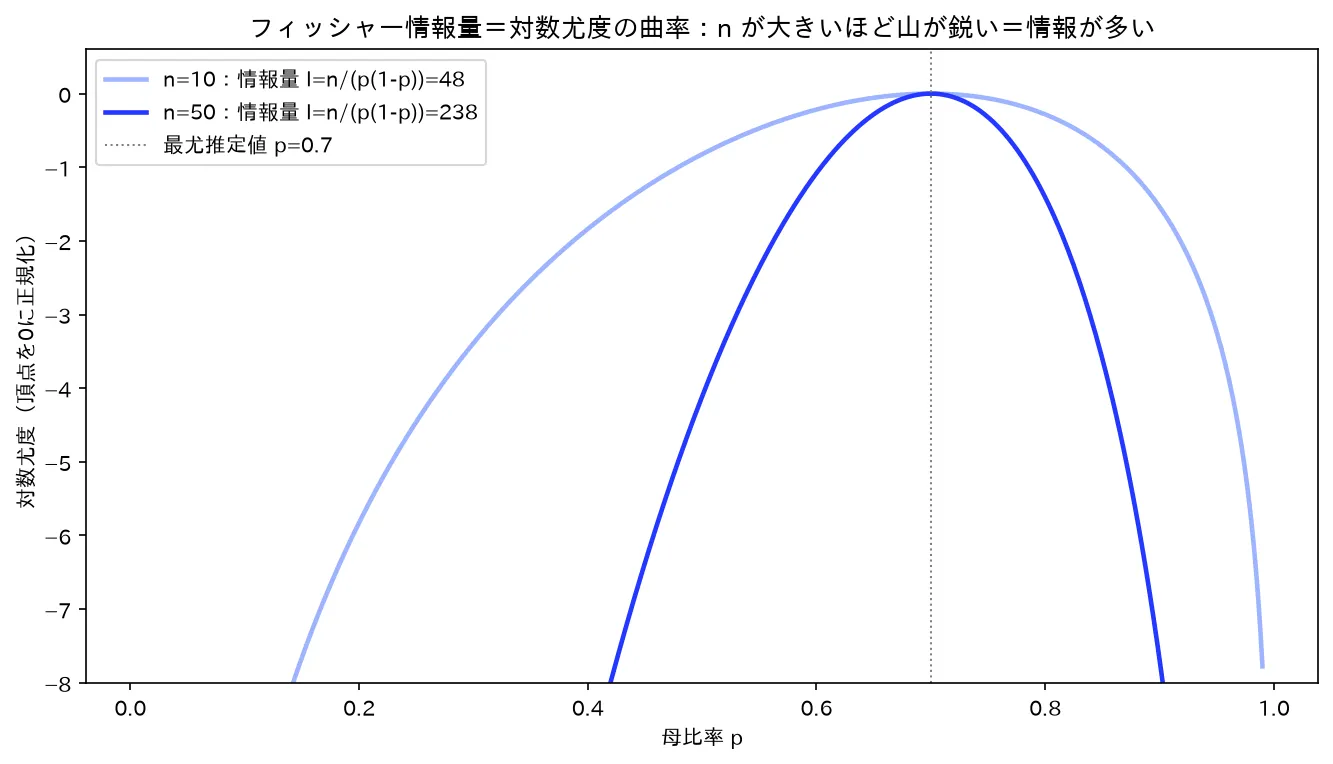
ベルヌーイ(p=0.7)の対数尤度。n=50 は n=10 より頂点が鋭い=情報量 I=n/(p(1-p)) が大きい=クラメール・ラオ下限 1/(nI) が小さい。図は simulations/fisher_jouhou_kyokuritsu.py で生成。
| 分布 | 母数 | 1標本の | CR下限 | 達成する推定量 |
|---|---|---|---|---|
| ベルヌーイ | 標本比率 | |||
| ポアソン | 標本平均 | |||
| 正規 (既知) | 標本平均 |
確認(ベルヌーイ)。、。 スコア:。2階微分:。 を入れて符号反転:
CR下限は 。一方 の分散は でぴったり一致。よって標本比率は有効推定量です。
要するに:表式Bで計算(2階微分→符号反転)が一番速い。そして標本平均・標本比率は代表分布でCR下限を達成する=有効推定量である、という結論が試験の定番。
4. クラメール・ラオの不等式
4.1 主張(正則条件つき)
正則条件のもとで、 の任意の不偏推定量 ()に対し
右辺を**クラメール・ラオ下限(CR下限)**と呼びます。
要するに:不偏でいる限り、どんなに工夫しても分散をこの値より小さくはできない。情報量 が大きいほど下限が下がり、より精密な推定が可能になる。
4.2 導出スケッチ(コーシー・シュワルツ)
個の標本のスコアを とします。、 は §3 で確認済み。
ステップ1:不偏条件を微分して共分散を1に固定する。 不偏性 、すなわち の両辺を で微分します(順序交換=正則条件):
\ \Longrightarrow\ \int \hat\theta\,U_n\,f_n\,d\mathbf x=1 \ \Longrightarrow\ \mathbb E[\hat\theta\,U_n]=1.$$ スコアの平均は0なので $\mathrm{Cov}(\hat\theta,U_n)=\mathbb E[\hat\theta U_n]-\mathbb E[\hat\theta]\mathbb E[U_n]=1-\theta\cdot0=1$。 **要するに**:「不偏である」という条件は「推定量とスコアの共分散がちょうど1」と言い換えられる。 **ステップ2:コーシー・シュワルツ(相関は±1以内)。** 任意の2変数で $\big(\mathrm{Cov}(A,B)\big)^2\le V[A]\,V[B]$(相関係数の2乗が1以下、期待値・分散の性質(線形性・和の分散・共分散))。$A=\hat\theta,\ B=U_n$ に当てると: $$1=\big(\mathrm{Cov}(\hat\theta,U_n)\big)^2\le V[\hat\theta]\cdot V[U_n]=V[\hat\theta]\cdot I_n(\theta).$$ 両辺を $I_n(\theta)$ で割って $$V[\hat\theta]\ge\frac{1}{I_n(\theta)}.$$ $\square$ **要するに**:不偏という縛りが「推定量とスコアの共分散=1」を強制し、コーシー・シュワルツ不等式がその代償として分散に下限を課す。**等号成立は $\hat\theta$ と $U_n$ が完全に線形従属(相関±1)のとき**で、そのとき $\hat\theta$ は有効推定量です。 ### 4.3 前提(正則条件)を破ると下限は使えない CR下限の導出で2回「微分と積分の順序交換」を使いました。これが効かない状況では**下限が成り立たない/達成不能**になります。代表例: - **台(サポート)が $\theta$ に依存する分布**:一様分布 $U(0,\theta)$ など。$x$ の動く範囲の端が $\theta$ で動くので順序交換が破れる。最尤推定量 $\hat\theta=\max_i X_i$ の分散はCR下限を**下回る**(CR下限が無効)。 - 微分可能性・期待値の存在が崩れる場合。 **要するに**:CR下限は「**不偏**かつ**正則条件**」が大前提。前提を確認せずに「下限=最小分散」と断じてはいけない。1級ではこの反例(一様分布)がしばしば問われる。 --- ## 5. 有効推定量・有効性・漸近有効性 ### 5.1 有効推定量 CR下限に**等号で到達する不偏推定量**を**有効推定量(efficient estimator)**と呼びます: $$V[\hat\theta]=\frac{1}{I_n(\theta)}.$$ 有効推定量は(存在すれば)不偏推定量の中で分散が最小なので、**最小分散不偏推定量(UMVUE)**でもあります。逆は必ずしも成り立たない(UMVUEでもCR下限には届かないことがある)。 ### 5.2 有効性(efficiency) 下限を分子、実際の分散を分母に置いた比を**有効性**と定義します: $$\mathrm{eff}(\hat\theta)=\frac{1/I_n(\theta)}{V[\hat\theta]}\quad(0<\mathrm{eff}\le1).$$ **要するに**:「下限という理想に対して、何割の効率が出ているか」。$\mathrm{eff}=1$ なら有効推定量。2つの不偏推定量の優劣はこの比(相対有効性)で比べます。 ### 5.3 漸近有効性 有限標本でCR下限を厳密に達成する推定量は限られます。そこで $n\to\infty$ で評価を緩めたのが**漸近有効性**。推定量が漸近的に正規分布し、その漸近分散がCR下限に一致するとき漸近有効と言います: $$\sqrt{n}\,(\hat\theta-\theta)\ \xrightarrow{d}\ N\!\left(0,\ \frac{1}{I(\theta)}\right).$$ **最尤推定量(MLE)は、正則条件のもとで漸近有効**です(漸近分散がCR下限 $1/I(\theta)$ に一致)。これがMLEを使う最大の理論的根拠の1つで、詳細は 最尤法・モーメント法(推定量の作り方と最尤推定量の漸近論) に置きます。 **要するに**:有限標本では届かなくても、データを増やせばMLEはCR下限という最良効率に漸近する。「大標本では最尤推定がベスト」の数理的裏付け。 --- ## 6. 級ごとの問われ方の差 > 準1級は「定義・計算・1段の導出」、1級は「導出の細部・正則条件・反例・MSE最適性の議論」まで踏み込む、と捉えるとよい(要最新確認:範囲表は改訂されうる)。 | 観点 | 準1級での問われ方 | 1級での問われ方 | |---|---|---| | MSE分解 | 公式を使い分散・バイアスからMSEを計算 | 分解の導出、MSE最適な偏り推定量の議論(縮小推定) | | フィッシャー情報量 | 代表分布の $I(\theta)$ を表式Bで計算 | 表式A=Bの導出、多母数(情報行列)への拡張 | | CR下限 | 下限を計算し、与えられた推定量が達成するか判定 | 不等式の導出、正則条件の役割、一様分布の反例 | | 有効性 | 標本平均・標本比率の有効性確認 | 有効性比・漸近有効性・MLEとの接続の論証 | --- ## ⚠️ 引っかけポイント - **MSEと分散の混同**。MSE=分散+バイアス²であって、MSE=分散ではない。**MSE=分散が成り立つのは不偏推定量のときだけ**。偏った推定量で「分散が小さいからMSEも小さい」と即断しない(バイアス²を足し忘れる典型ミス)。 - **CR下限の前提=不偏**。クラメール・ラオ不等式は**不偏推定量にのみ**適用される下限。偏った推定量の分散はCR下限を平気で下回る(例:分母 $n$ の最尤分散)。「分散がCR下限より小さい→計算ミス」と早合点しない。まず不偏かを確認する。 - **正則条件を無視しない**。台が $\theta$ に依存する分布(一様 $U(0,\theta)$ など)ではCR下限の導出が破れ、下限が無効になる。「最尤推定量の分散がCR下限より小さい」反例はここから来る。下限を使う前に正則条件(特に微分と積分の順序交換)を確認。 - **情報量の「向き」の取り違え**。$I(\theta)$ は**大きいほど良い**(推定が精密)。一方その逆数であるCR下限は**小さいほど良い**。「情報量が大きい=分散が大きい」と取り違えない。情報量大 → 下限小 → 精密、が正しい向き。 - **表式Bの符号忘れ**。$I(\theta)=-\mathbb E[\partial^2\log f/\partial\theta^2]$ の**マイナス**を落とすと情報量が負になり破綻する。対数尤度は最尤点で上に凸(2階微分が負)なので、符号反転して初めて正の情報量になる。 --- ## よくある疑問 **Q1. MSEと分散は何が違うんですか? 不偏なら同じと聞きましたが。** A. MSE=分散+バイアス²です。バイアス(偏り)がある推定量では、ブレ(分散)が小さくても的の中心からズレていれば誤差は大きい。そのズレの分を二乗して足したのがMSE。**不偏(バイアス=0)のときに限り MSE=分散**になります。だから「不偏推定量どうしの比較」では分散だけ見れば十分ですが、偏った推定量が混ざる比較ではMSEで見ないと不公平です。 **Q2. フィッシャー情報量はなぜ「情報」なんですか? 直観が掴めません。** A. スコア(対数尤度の傾き)がデータごとに大きく振れる分布ほど、$\theta$ を少し動かしただけで「データの説明のうまさ」が大きく変わる=**$\theta$ を鋭く見分けられる**ということです。表式B(曲率の平均)で言えば、対数尤度の山が尖っているほど最尤点がピンポイントで定まる。尖り具合=情報量。逆に対数尤度が平坦だと、$\theta$ を動かしても尤度がほとんど変わらず「どの $\theta$ も同じくらい尤もらしい」=情報が乏しい。 **Q3. 表式Aと表式B、どちらで計算すればいいですか?** A. 多くの分布で**表式B(2階微分して符号反転)が速い**です。1階微分のスコアを2乗して期待値を取る表式Aは、2乗の期待値($\mathbb E[X^2]$ など)の計算が要って面倒なことが多い。一方、表式Bは2階微分すると $X$ が線形(1次)で残る分布(指数型分布族)が多く、$\mathbb E[X]$ を入れるだけで済みます。両者は正則条件のもとで厳密に等しいので、計算しやすい方を選んでよい。 **Q4. クラメール・ラオ下限を下回る推定量を作ったら、それは間違いですか?** A. 状況によります。(1) その推定量が**不偏でない**なら、CR下限は適用外なので下回って当然(縮小推定など)。間違いではありません。(2) その推定量が不偏で、かつ**正則条件が成り立つ**のに下回ったなら、計算ミスです。(3) 一様分布 $U(0,\theta)$ のように**正則条件が破れる**分布なら、不偏推定量でも下限を下回りえます(CR下限がそもそも無効)。「下回った=即ミス」ではなく、まず不偏性と正則条件を確認するのが正解です。 **Q5. 有効推定量と最小分散不偏推定量(UMVUE)は同じものですか?** A. 同じではありません。有効推定量は「CR下限に等号で到達する不偏推定量」、UMVUEは「不偏推定量の中で分散が最小のもの」。有効推定量は(存在すれば)必ずUMVUEですが、逆は必ずしも真ではありません。UMVUEであってもCR下限には届かない(=有効でない)ことがあります。CR下限は「達成できれば最小」を保証する**十分条件**ですが、最小分散であるための必要条件ではない、という関係です。 --- ## まとめ - 推定量の有限標本での良さは**MSE=分散+バイアス²**で測る。交差項が消える直交分解(統計版ピタゴラス)。**不偏なら MSE=分散**。 - バイアスと分散はトレードオフ。**わざと偏らせてMSEを下げる**縮小推定が存在する(不偏が常に最良ではない)。 - **フィッシャー情報量** $I(\theta)$=スコアの分散=対数尤度の曲率の平均。表式A(傾きの2乗の期待値)と表式B(−2階微分の期待値)は正則条件のもとで等価。標本で $I_n(\theta)=nI(\theta)$ と線形に積み上がる。 - **クラメール・ラオ不等式**:不偏推定量の分散は $1/I_n(\theta)$ 未満にできない。導出は「不偏条件の微分で共分散を1に固定→コーシー・シュワルツ」。**前提は不偏+正則条件**。 - 下限に等号到達する不偏推定量が**有効推定量**。有効性=下限/分散。**MLEは漸近有効**(大標本でCR下限を達成)。 --- ## 関連ノート - 点推定(推定量の良さ:不偏性・一致性・有効性・十分性) … 不偏性・一致性・有効性の定義(本ノートはそれらを測る道具を深掘り) - 最尤法・モーメント法(推定量の作り方と最尤推定量の漸近論) … 最尤推定量の漸近有効性(CR下限を漸近的に達成する根拠。前方リンク) - 期待値・分散の性質(線形性・和の分散・共分散) … 分散・共分散の計算とコーシー・シュワルツ不等式(CR下限導出の土台) - 確率変数の変換・モーメント母関数・積率 … 対数尤度の微分・期待値計算の技法