← 統計検定テキスト 一覧
📊 対象級:2級 | 重要度:A(頻出)
標本平均・標本比率の標本分布(標準誤差)
要点(BLUF)
標本平均 X ˉ \bar X X ˉ :母平均 μ \mu μ σ 2 \sigma^2 σ 2 n n n E [ X ˉ ] = μ , V [ X ˉ ] = σ 2 n , S E ( X ˉ ) = σ n \boxed{\,E[\bar X]=\mu,\qquad V[\bar X]=\dfrac{\sigma^2}{n},\qquad \mathrm{SE}(\bar X)=\dfrac{\sigma}{\sqrt n}\,} E [ X ˉ ] = μ , V [ X ˉ ] = n σ 2 , SE ( X ˉ ) = n σ X ˉ \bar X X ˉ n \sqrt n n σ / n \sigma/\sqrt n σ / n 標本比率 p ^ \hat p p ^ :母比率 p p p n n n E [ p ^ ] = p , V [ p ^ ] = p ( 1 − p ) n , S E ( p ^ ) = p ( 1 − p ) n \boxed{\,E[\hat p]=p,\qquad V[\hat p]=\dfrac{p(1-p)}{n},\qquad \mathrm{SE}(\hat p)=\sqrt{\dfrac{p(1-p)}{n}}\,} E [ p ^ ] = p , V [ p ^ ] = n p ( 1 − p ) , SE ( p ^ ) = n p ( 1 − p ) n \sqrt n n X ˉ \bar X X ˉ 正規近似 :中心極限定理(中心極限定理(CLT) )により、n n n X ˉ ≈ N ( μ , σ 2 n ) , p ^ ≈ N ( p , p ( 1 − p ) n ) . \bar X \approx N\!\Big(\mu,\ \tfrac{\sigma^2}{n}\Big),\qquad \hat p \approx N\!\Big(p,\ \tfrac{p(1-p)}{n}\Big). X ˉ ≈ N ( μ , n σ 2 ) , p ^ ≈ N ( p , n p ( 1 − p ) ) . 区間推定(母平均・母比率・母分散の信頼区間) )と仮説検定すべての出発点。最重要の区別 :標準偏差 σ \sigma σ 標準誤差 σ / n \sigma/\sqrt n σ / n X ˉ \bar X X ˉ n \sqrt n n
本文
なぜこのテーマが要なのか
統計学の中心的な仕事は「手元の標本から、見えない母集団を推測する 」ことです。その推測の主役が標本平均 X ˉ \bar X X ˉ μ \mu μ p ^ \hat p p ^ p p p
ところが標本は無作為に選ぶたびに違う顔ぶれになるので、X ˉ \bar X X ˉ p ^ \hat p p ^ 標本ごとに揺れる確率変数 です。「その揺れがどんな分布で、どれくらい大きいのか」を記述するのが標本分布(sampling distribution)であり、揺れの大きさ(標準偏差)が 標準誤差 です。
このノートが効いてくる場所を地図にすると:
graph LR
A["母集団<br/>μ, σ², p(未知)"] -->|無作為標本 n| B["標本"]
B --> C["標本平均 X̄<br/>標本比率 p̂"]
C -->|標本分布| D["E·V·標準誤差<br/>(このノート)"]
D -->|正規近似 CLT| E["区間推定<br/>仮説検定"]
E -->|推測| A
要するに、標本分布は「標本という入口」と「推定・検定という出口」をつなぐ橋です。ここを曖昧にすると、後ろの推定・検定がすべて砂上の楼閣になります。
1. 標本平均 X ˉ \bar X X ˉ
設定(前提を正確に)
母平均 μ \mu μ σ 2 \sigma^2 σ 2 n n n X 1 , X 2 , … , X n X_1, X_2, \dots, X_n X 1 , X 2 , … , X n
各 X i X_i X i 同分布 :E [ X i ] = μ E[X_i]=\mu E [ X i ] = μ V [ X i ] = σ 2 V[X_i]=\sigma^2 V [ X i ] = σ 2 i i i
互いに独立 (無作為抽出・復元抽出、または母集団が十分大きい非復元抽出で近似的に成立。後述の有限母集団修正を参照)。
標本平均は
X ˉ = 1 n ∑ i = 1 n X i = X 1 + X 2 + ⋯ + X n n . \bar X = \frac{1}{n}\sum_{i=1}^{n} X_i = \frac{X_1+X_2+\cdots+X_n}{n}. X ˉ = n 1 ∑ i = 1 n X i = n X 1 + X 2 + ⋯ + X n .
これは「データの和を n n n X i X_i X i X ˉ \bar X X ˉ
(A) 期待値の導出 E [ X ˉ ] = μ E[\bar X]=\mu E [ X ˉ ] = μ
期待値の線形性 E [ a X + b Y ] = a E [ X ] + b E [ Y ] E[aX+bY]=aE[X]+bE[Y] E [ a X + bY ] = a E [ X ] + b E [ Y ] 期待値・分散の性質(線形性・和の分散・共分散) )を使います。これは独立でなくても 成り立つ性質です。
E [ X ˉ ] = E [ 1 n ∑ i = 1 n X i ] = 1 n E [ ∑ i = 1 n X i ] (定数 1 / n を外に出す) = 1 n ∑ i = 1 n E [ X i ] (期待値の線形性:和の期待値=期待値の和) = 1 n ∑ i = 1 n μ (各 E [ X i ] = μ ) = 1 n ⋅ n μ = μ . \begin{aligned}
E[\bar X]
&= E\!\left[\frac{1}{n}\sum_{i=1}^{n} X_i\right] \\
&= \frac{1}{n}\,E\!\left[\sum_{i=1}^{n} X_i\right] && \text{(定数 }1/n\text{ を外に出す)}\\
&= \frac{1}{n}\sum_{i=1}^{n} E[X_i] && \text{(期待値の線形性:和の期待値=期待値の和)}\\
&= \frac{1}{n}\sum_{i=1}^{n} \mu && \text{(各 }E[X_i]=\mu\text{)}\\
&= \frac{1}{n}\cdot n\mu = \mu.
\end{aligned} E [ X ˉ ] = E [ n 1 i = 1 ∑ n X i ] = n 1 E [ i = 1 ∑ n X i ] = n 1 i = 1 ∑ n E [ X i ] = n 1 i = 1 ∑ n μ = n 1 ⋅ n μ = μ . (定数 1/ n を外に出す) (期待値の線形性:和の期待値=期待値の和) (各 E [ X i ] = μ ) 要するに :μ \mu μ n n n n n n μ \mu μ X ˉ \bar X X ˉ 母平均 μ \mu μ します。標本サイズ n n n X ˉ \bar X X ˉ μ \mu μ 不偏推定量 」と呼びます(中心がズレない=偏りがない。推定量の評価(MSE・フィッシャー情報量・クラメール・ラオの不等式) )。
(B) 分散の導出 V [ X ˉ ] = σ 2 / n V[\bar X]=\sigma^2/n V [ X ˉ ] = σ 2 / n
分散には2つの公式を使います(期待値・分散の性質(線形性・和の分散・共分散) ):
定数倍:V [ a X ] = a 2 V [ X ] V[aX]=a^2V[X] V [ a X ] = a 2 V [ X ]
和の分散:独立なら V [ X + Y ] = V [ X ] + V [ Y ] V[X+Y]=V[X]+V[Y] V [ X + Y ] = V [ X ] + V [ Y ]
V [ X ˉ ] = V [ 1 n ∑ i = 1 n X i ] = 1 n 2 V [ ∑ i = 1 n X i ] (定数倍: 1 / n は2乗されて 1 / n 2 に) = 1 n 2 ∑ i = 1 n V [ X i ] (独立性:和の分散=分散の和) = 1 n 2 ∑ i = 1 n σ 2 (各 V [ X i ] = σ 2 ) = 1 n 2 ⋅ n σ 2 = σ 2 n . \begin{aligned}
V[\bar X]
&= V\!\left[\frac{1}{n}\sum_{i=1}^{n} X_i\right] \\
&= \frac{1}{n^2}\,V\!\left[\sum_{i=1}^{n} X_i\right] && \text{(定数倍:}1/n\text{ は2乗されて }1/n^2\text{ に)}\\
&= \frac{1}{n^2}\sum_{i=1}^{n} V[X_i] && \text{(独立性:和の分散=分散の和)}\\
&= \frac{1}{n^2}\sum_{i=1}^{n} \sigma^2 && \text{(各 }V[X_i]=\sigma^2\text{)}\\
&= \frac{1}{n^2}\cdot n\sigma^2 = \frac{\sigma^2}{n}.
\end{aligned} V [ X ˉ ] = V [ n 1 i = 1 ∑ n X i ] = n 2 1 V [ i = 1 ∑ n X i ] = n 2 1 i = 1 ∑ n V [ X i ] = n 2 1 i = 1 ∑ n σ 2 = n 2 1 ⋅ n σ 2 = n σ 2 . (定数倍: 1/ n は 2 乗されて 1/ n 2 に) (独立性:和の分散=分散の和) (各 V [ X i ] = σ 2 ) 要するに :和の分散は n σ 2 n\sigma^2 n σ 2 1 / n 1/n 1/ n 1 / n 2 1/n^2 1/ n 2 σ 2 / n \sigma^2/n σ 2 / n 縮む 。ここで独立性が決定的 です。もし X i X_i X i
(C) 標準誤差の定義
V [ X ˉ ] = σ 2 / n V[\bar X]=\sigma^2/n V [ X ˉ ] = σ 2 / n 標準誤差 :
S E ( X ˉ ) = V [ X ˉ ] = σ 2 n = σ n . \mathrm{SE}(\bar X)=\sqrt{V[\bar X]}=\sqrt{\frac{\sigma^2}{n}}=\frac{\sigma}{\sqrt n}. SE ( X ˉ ) = V [ X ˉ ] = n σ 2 = n σ .
要するに :X ˉ \bar X X ˉ n n n n \sqrt n n 精度を2倍にするにはサンプルを4倍 集める必要がある── これが「n \sqrt n n
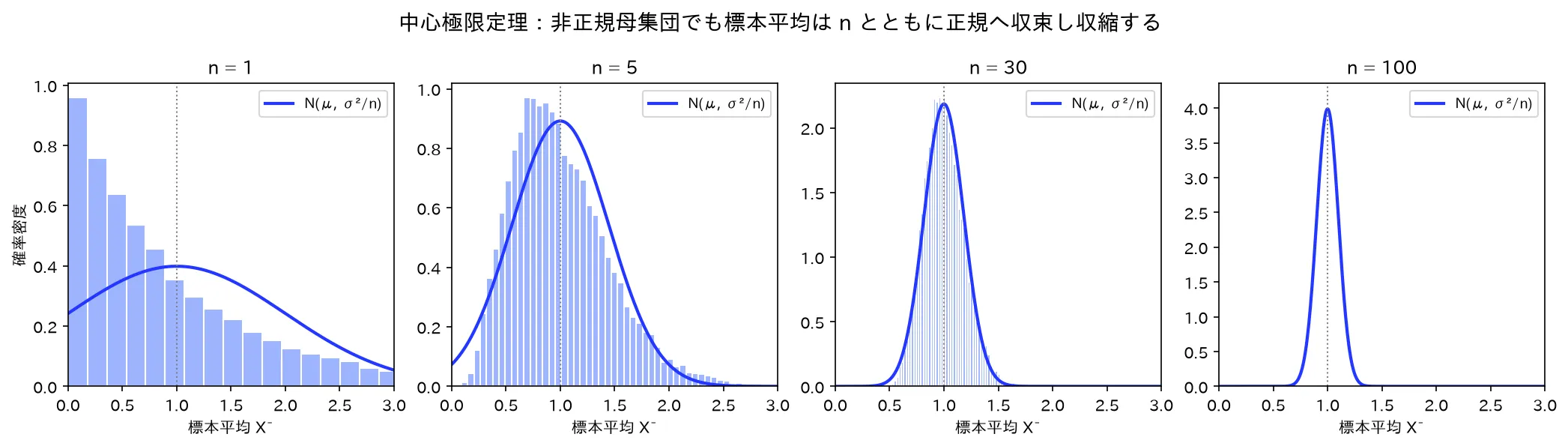
母集団が歪んだ指数分布でも、n=1→5→30→100 と増やすと標本平均X̄の分布は正規(青曲線 N(μ, σ²/n))に近づき、μ周りに標準誤差σ/√nで収縮する。図は simulations/hyohon_heikin_clt_keijou.py で生成。
μ = 50 , σ = 10 \mu=50,\ \sigma=10 μ = 50 , σ = 10
標本サイズ n n n n \sqrt n n S E = σ / n \mathrm{SE}=\sigma/\sqrt n SE = σ / n X ˉ \bar X X ˉ μ ± 2 S E \mu\pm 2\,\mathrm{SE} μ ± 2 SE 1 1.00 10.00 30.0 〜 70.0 4 2.00 5.00 40.0 〜 60.0 25 5.00 2.00 46.0 〜 54.0 100 10.00 1.00 48.0 〜 52.0 400 20.00 0.50 49.0 〜 51.0
n n n X ˉ \bar X X ˉ μ = 50 \mu=50 μ = 50 大数の法則(弱法則・強法則) の定量版)。ただし n n n
(D) 形まで正規になるのは? — 中心極限定理
(A)(B) は期待値と分散(数値)の話で、母集団がどんな形でも 成り立ちます。では X ˉ \bar X X ˉ 分布の形 はどうなるか。
母集団がもともと正規 N ( μ , σ 2 ) N(\mu,\sigma^2) N ( μ , σ 2 ) 正規分布(標準正規・標準化) )により X ˉ \bar X X ˉ 厳密に N ( μ , σ 2 / n ) N(\mu,\sigma^2/n) N ( μ , σ 2 / n )
母集団が正規でなくても、n n n 中心極限定理 (中心極限定理(CLT) )により X ˉ \bar X X ˉ 近似的に N ( μ , σ 2 / n ) N(\mu,\sigma^2/n) N ( μ , σ 2 / n )
X ˉ ≈ N ( μ , σ 2 n ) ⟺ Z = X ˉ − μ σ / n ≈ N ( 0 , 1 ) . \bar X \approx N\!\left(\mu,\ \frac{\sigma^2}{n}\right) \quad\Longleftrightarrow\quad Z=\frac{\bar X-\mu}{\sigma/\sqrt n}\approx N(0,1). X ˉ ≈ N ( μ , n σ 2 ) ⟺ Z = σ / n X ˉ − μ ≈ N ( 0 , 1 ) .
要するに :標準化の分母が「標準偏差 σ \sigma σ 標準誤差 σ / n \sigma/\sqrt n σ / n 」になる。この Z Z Z
2. 標本比率 p ^ \hat p p ^
設定と「比率は平均の特殊ケース」
母集団のうち「ある性質を持つ割合」が p p p n n n Y Y Y Y ∼ B ( n , p ) Y\sim B(n,p) Y ∼ B ( n , p ) ベルヌーイ分布・二項分布 )。標本比率は
p ^ = Y n . \hat p = \frac{Y}{n}. p ^ = n Y .
ここで鍵になる見方:各個体が性質を持つかどうかを X i X_i X i X i X_i X i ベルヌーイ試行 で
E [ X i ] = p , V [ X i ] = p ( 1 − p ) . E[X_i]=p,\qquad V[X_i]=p(1-p). E [ X i ] = p , V [ X i ] = p ( 1 − p ) .
すると Y = ∑ X i Y=\sum X_i Y = ∑ X i p ^ = 1 n ∑ X i = X ˉ \hat p = \frac1n\sum X_i = \bar X p ^ = n 1 ∑ X i = X ˉ 標本比率は「0/1データの標本平均」にすぎません 。だから前節の X ˉ \bar X X ˉ μ → p \mu\to p μ → p σ 2 → p ( 1 − p ) \sigma^2\to p(1-p) σ 2 → p ( 1 − p )
(A) 期待値 E [ p ^ ] = p E[\hat p]=p E [ p ^ ] = p
E [ p ^ ] = E [ Y n ] = 1 n E [ Y ] (定数 1 / n を外へ) = 1 n ⋅ n p (二項分布の期待値 E [ Y ] = n p ) = p . \begin{aligned}
E[\hat p]
&= E\!\left[\frac{Y}{n}\right]
= \frac{1}{n}E[Y] && \text{(定数 }1/n\text{ を外へ)}\\
&= \frac{1}{n}\cdot np && \text{(二項分布の期待値 }E[Y]=np\text{)}\\
&= p.
\end{aligned} E [ p ^ ] = E [ n Y ] = n 1 E [ Y ] = n 1 ⋅ n p = p . (定数 1/ n を外へ) (二項分布の期待値 E [ Y ] = n p ) 要するに :p ^ \hat p p ^ p p p p ^ \hat p p ^ p p p
(B) 分散 V [ p ^ ] = p ( 1 − p ) / n V[\hat p]=p(1-p)/n V [ p ^ ] = p ( 1 − p ) / n
V [ p ^ ] = V [ Y n ] = 1 n 2 V [ Y ] (定数倍は2乗で外へ: 1 / n 2 ) = 1 n 2 ⋅ n p ( 1 − p ) (二項分布の分散 V [ Y ] = n p ( 1 − p ) ) = p ( 1 − p ) n . \begin{aligned}
V[\hat p]
&= V\!\left[\frac{Y}{n}\right]
= \frac{1}{n^2}V[Y] && \text{(定数倍は2乗で外へ:}1/n^2\text{)}\\
&= \frac{1}{n^2}\cdot np(1-p) && \text{(二項分布の分散 }V[Y]=np(1-p)\text{)}\\
&= \frac{p(1-p)}{n}.
\end{aligned} V [ p ^ ] = V [ n Y ] = n 2 1 V [ Y ] = n 2 1 ⋅ n p ( 1 − p ) = n p ( 1 − p ) . (定数倍は 2 乗で外へ: 1/ n 2 ) (二項分布の分散 V [ Y ] = n p ( 1 − p ) ) 要するに :X ˉ \bar X X ˉ σ 2 / n \sigma^2/n σ 2 / n σ 2 = p ( 1 − p ) \sigma^2=p(1-p) σ 2 = p ( 1 − p )
S E ( p ^ ) = p ( 1 − p ) n . \mathrm{SE}(\hat p)=\sqrt{\frac{p(1-p)}{n}}. SE ( p ^ ) = n p ( 1 − p ) .
(C) 比率の標準誤差は p = 0.5 p=0.5 p = 0.5
p ( 1 − p ) p(1-p) p ( 1 − p ) p = 0.5 p=0.5 p = 0.5 0.25 0.25 0.25 p = 0.5 p=0.5 p = 0.5
母比率 p p p p ( 1 − p ) p(1-p) p ( 1 − p ) n = 100 n=100 n = 100 S E ( p ^ ) \mathrm{SE}(\hat p) SE ( p ^ ) 0.1 0.09 0.030 0.3 0.21 0.046 0.5 0.25 0.050 0.7 0.21 0.046 0.9 0.09 0.030
要するに :「半々(p = 0.5 p=0.5 p = 0.5 p = 0.5 p=0.5 p = 0.5 S E = 0.5 / n \mathrm{SE}=0.5/\sqrt n SE = 0.5/ n
(D) 正規近似とその条件
p ^ = X ˉ \hat p = \bar X p ^ = X ˉ n n n
p ^ ≈ N ( p , p ( 1 − p ) n ) , Z = p ^ − p p ( 1 − p ) / n ≈ N ( 0 , 1 ) . \hat p \approx N\!\left(p,\ \frac{p(1-p)}{n}\right),\qquad Z=\frac{\hat p - p}{\sqrt{p(1-p)/n}}\approx N(0,1). p ^ ≈ N ( p , n p ( 1 − p ) ) , Z = p ( 1 − p ) / n p ^ − p ≈ N ( 0 , 1 ) .
ただし p ^ \hat p p ^ p p p 正規近似が使える目安 があります(二項分布の正規近似 ):
n p ≥ 5 かつ n ( 1 − p ) ≥ 5 ( 文献により ≥ 10 とするものもある。要最新確認 ) \boxed{\,np\ge 5 \ \text{かつ}\ n(1-p)\ge 5\,}\quad(\text{文献により }\ge 10\ \text{とするものもある。要最新確認}) n p ≥ 5 かつ n ( 1 − p ) ≥ 5 ( 文献により ≥ 10 とするものもある。要最新確認 )
要するに :「成功も失敗も最低5個ずつは期待される」くらい n n n p p p p = 0.5 p=0.5 p = 0.5 n ≥ 10 n\ge 10 n ≥ 10 p = 0.05 p=0.05 p = 0.05 n p ≥ 5 np\ge5 n p ≥ 5 n ≥ 100 n\ge100 n ≥ 100 p p p n n n
3. 標準偏差と標準誤差の違い(最重要・暗記)
ここが2級で最も混同されるポイントです。名前が似ているだけで測っている対象が違う 。
標準偏差 SD 標準誤差 SE 何のばらつきか データ1個1個 X i X_i X i 推定量 X ˉ \bar X X ˉ p ^ \hat p p ^ 記号・式 σ \sigma σ s s s σ / n \sigma/\sqrt n σ / n p ( 1 − p ) / n \sqrt{p(1-p)/n} p ( 1 − p ) / n n n n 変わらない(母集団の性質) 1 / n 1/\sqrt n 1/ n 小さくなる 何に使うか データの散らばりの記述 推定の精度 ・信頼区間の幅 関係 S E = S D n \mathrm{SE}=\dfrac{\mathrm{SD}}{\sqrt n} SE = n SD
graph TD
A["母標準偏差 σ<br/>=データ1個のばらつき<br/>(n に依存しない)"] -->|÷√n| B["標準誤差 σ/√n<br/>=標本平均 X̄ のばらつき<br/>(n を増やすと縮む)"]
要するに :「データの散らばり」と「平均値の信頼できなさ」は別物。n n n σ \sigma σ σ / n \sigma/\sqrt n σ / n
⚠️ 母 σ \sigma σ s s s 1 n − 1 ∑ ( X i − X ˉ ) 2 \sqrt{\frac{1}{n-1}\sum(X_i-\bar X)^2} n − 1 1 ∑ ( X i − X ˉ ) 2 S E ^ = s / n \widehat{\mathrm{SE}}=s/\sqrt n SE = s / n 自由度 n − 1 n-1 n − 1 t t t にしたがう(t分布・カイ二乗分布・F分布(標本分布の三役) )。σ \sigma σ z z z t t t
4. 有限母集団修正(参考・2級では軽め)
ここまでの V [ X ˉ ] = σ 2 / n V[\bar X]=\sigma^2/n V [ X ˉ ] = σ 2 / n X i X_i X i 復元抽出 (同じ個体を選び直しうる)か、母集団 N N N n n n
母集団が有限 N N N 非復元抽出 (同じ個体は二度取らない)だと、取るほど残りの選択肢が減って X i X_i X i 少し小さく なります。これを補正するのが有限母集団修正係数(fpc) :
V [ X ˉ ] = σ 2 n ⋅ N − n N − 1 ⏟ fpc , S E ( X ˉ ) = σ n N − n N − 1 . V[\bar X]=\frac{\sigma^2}{n}\cdot\underbrace{\frac{N-n}{N-1}}_{\text{fpc}},\qquad \mathrm{SE}(\bar X)=\frac{\sigma}{\sqrt n}\sqrt{\frac{N-n}{N-1}}. V [ X ˉ ] = n σ 2 ⋅ fpc N − 1 N − n , SE ( X ˉ ) = n σ N − 1 N − n .
状況 fpc = N − n N − 1 =\frac{N-n}{N-1} = N − 1 N − n 効果 n = N n=N n = N 0 SE=0(全部調べたので誤差なし) n ≪ N n \ll N n ≪ N ≒1 補正ほぼ不要 n n n N N N 明確に1未満 SEを下げる補正が効く
要するに :「母集団のかなりの割合を調べたなら、推定はその分だけ正確になる」。n / N n/N n / N σ / n \sigma/\sqrt n σ / n n / N n/N n / N
5. 具体例
例1:標本平均の確率(正規母集団)
ある工場の製品重量が N ( μ = 200 g , σ 2 = 8 2 ) N(\mu=200\,\text{g},\ \sigma^2=8^2) N ( μ = 200 g , σ 2 = 8 2 ) n = 16 n=16 n = 16 X ˉ \bar X X ˉ
X ˉ \bar X X ˉ X ˉ ∼ N ( 200 , 8 2 16 ) = N ( 200 , 4 ) \bar X\sim N\!\big(200,\ \frac{8^2}{16}\big)=N(200,\ 4) X ˉ ∼ N ( 200 , 16 8 2 ) = N ( 200 , 4 ) S E = 8 16 = 8 4 = 2 \mathrm{SE}=\frac{8}{\sqrt{16}}=\frac{8}{4}=2 SE = 16 8 = 4 8 = 2 標準化:z = 203 − 200 2 = 3 2 = 1.5 z=\dfrac{203-200}{2}=\dfrac{3}{2}=1.5 z = 2 203 − 200 = 2 3 = 1.5 分母は σ = 8 \sigma=8 σ = 8 S E = 2 \mathrm{SE}=2 SE = 2 (ここが最頻ミス)。
上側確率:P ( X ˉ ≥ 203 ) = P ( Z ≥ 1.5 ) ≈ 0.0668 P(\bar X\ge 203)=P(Z\ge 1.5)\approx 0.0668 P ( X ˉ ≥ 203 ) = P ( Z ≥ 1.5 ) ≈ 0.0668 約6.7% 。
比較:もし「製品1個」が203g以上の確率なら分母は σ = 8 \sigma=8 σ = 8 z = 3 / 8 = 0.375 z=3/8=0.375 z = 3/8 = 0.375 P ≈ 0.354 P\approx0.354 P ≈ 0.354 16 = 4 \sqrt{16}=4 16 = 4
例2:標本比率の確率(正規近似)
母比率 p = 0.4 p=0.4 p = 0.4 n = 100 n=100 n = 100 p ^ \hat p p ^
近似条件:n p = 100 × 0.4 = 40 ≥ 5 np=100\times0.4=40\ge5 n p = 100 × 0.4 = 40 ≥ 5 n ( 1 − p ) = 60 ≥ 5 n(1-p)=60\ge5 n ( 1 − p ) = 60 ≥ 5
p ^ \hat p p ^ p ^ ≈ N ( 0.4 , 0.4 × 0.6 100 ) = N ( 0.4 , 0.0024 ) \hat p\approx N\!\big(0.4,\ \frac{0.4\times0.6}{100}\big)=N(0.4,\ 0.0024) p ^ ≈ N ( 0.4 , 100 0.4 × 0.6 ) = N ( 0.4 , 0.0024 ) S E = 0.0024 = 0.04899 ≈ 0.049 \mathrm{SE}=\sqrt{0.0024}=0.04899\approx0.049 SE = 0.0024 = 0.04899 ≈ 0.049 標準化:z = 0.5 − 0.4 0.049 = 0.1 0.049 ≈ 2.04 z=\dfrac{0.5-0.4}{0.049}=\dfrac{0.1}{0.049}\approx2.04 z = 0.049 0.5 − 0.4 = 0.049 0.1 ≈ 2.04
P ( p ^ ≥ 0.5 ) = P ( Z ≥ 2.04 ) ≈ 0.0207 P(\hat p\ge 0.5)=P(Z\ge 2.04)\approx 0.0207 P ( p ^ ≥ 0.5 ) = P ( Z ≥ 2.04 ) ≈ 0.0207 約2.1% 。
要するに :比率の問題も「E E E V V V X ˉ \bar X X ˉ S E ( p ^ ) = p ( 1 − p ) / n \mathrm{SE}(\hat p)=\sqrt{p(1-p)/n} SE ( p ^ ) = p ( 1 − p ) / n
6. 試験での問われ方(2級)
flowchart TD
A["標本分布の問題"] --> B{"平均か比率か"}
B -->|平均 X̄| C["E=μ V=σ²÷n を立てる"]
B -->|比率 p̂| D["E=p V=p(1−p)÷n を立てる"]
C --> E["標準誤差で標準化<br/>z=(X̄−μ)÷(σ÷√n)"]
D --> F["近似条件 np≥5 n(1−p)≥5 を確認"]
F --> G["標準化 z=(p̂−p)÷√(p(1−p)÷n)"]
E --> H["分布表で面積を読む"]
G --> H
H --> I["区間推定・検定へ接続"]
2級での典型出題:
標準誤差の計算 :σ \sigma σ s s s n n n σ / n \sigma/\sqrt n σ / n σ \sigma σ 標本平均の確率 :X ˉ ∼ N ( μ , σ 2 / n ) \bar X\sim N(\mu,\sigma^2/n) X ˉ ∼ N ( μ , σ 2 / n ) P ( X ˉ ≥ a ) P(\bar X\ge a) P ( X ˉ ≥ a ) 標本比率の確率・近似条件 :p ^ \hat p p ^ n p , n ( 1 − p ) np,n(1-p) n p , n ( 1 − p ) n n n n n n n \sqrt n n 推定・検定への接続 :この標準誤差が信頼区間 X ˉ ± 1.96 σ / n \bar X\pm 1.96\,\sigma/\sqrt n X ˉ ± 1.96 σ / n 区間推定(母平均・母比率・母分散の信頼区間) )、検定統計量の分母そのもの(母平均の検定(1標本・2標本t検定) 母比率・母分散の検定 )になる。
⚠️ 引っかけポイント
標準誤差 ≠ 標準偏差(最重要) 。標準偏差 σ \sigma σ σ / n \sigma/\sqrt n σ / n X ˉ \bar X X ˉ S E = σ / n \mathrm{SE}=\sigma/\sqrt n SE = σ / n σ \sigma σ X ˉ \bar X X ˉ σ \sigma σ V [ X ˉ ] = σ 2 / n V[\bar X]=\sigma^2/n V [ X ˉ ] = σ 2 / n σ 2 \sigma^2 σ 2 σ \sigma σ σ / n \sigma/\sqrt n σ / n σ 2 / n \sigma^2/\sqrt n σ 2 / n σ / n \sigma/n σ / n σ 2 / n = σ / n \sqrt{\sigma^2/n}=\sigma/\sqrt n σ 2 / n = σ / n n n n σ \sigma σ n n n 平均値の ばらつき(SE)。比率の正規近似には条件がある 。n p ≥ 5 np\ge5 n p ≥ 5 n ( 1 − p ) ≥ 5 n(1-p)\ge5 n ( 1 − p ) ≥ 5 ≥ 10 \ge10 ≥ 10 p p p n n n p ^ ≈ \hat p\approx p ^ ≈ 独立性(無作為抽出)が分散の式の前提 。V [ X ˉ ] = σ 2 / n V[\bar X]=\sigma^2/n V [ X ˉ ] = σ 2 / n X i X_i X i σ \sigma σ σ \sigma σ z = ( X ˉ − μ ) / ( σ / n ) ∼ N ( 0 , 1 ) z=(\bar X-\mu)/(\sigma/\sqrt n)\sim N(0,1) z = ( X ˉ − μ ) / ( σ / n ) ∼ N ( 0 , 1 ) σ \sigma σ s s s t = ( X ˉ − μ ) / ( s / n ) ∼ t n − 1 t=(\bar X-\mu)/(s/\sqrt n)\sim t_{n-1} t = ( X ˉ − μ ) / ( s / n ) ∼ t n − 1 t分布・カイ二乗分布・F分布(標本分布の三役) )。σ \sigma σ z z z 「標本分散」と「標本平均の分散」は別物 。標本分散 s 2 s^2 s 2 σ 2 \sigma^2 σ 2 V [ X ˉ ] = σ 2 / n V[\bar X]=\sigma^2/n V [ X ˉ ] = σ 2 / n
よくある疑問
Q1. 標準偏差と標準誤差、結局どう違うんですか?
A. 「何のばらつきを測っているか」が違います。標準偏差 σ \sigma σ データ1個1個 の散らばり(母集団そのものの性質)。標準誤差 σ / n \sigma/\sqrt n σ / n n n n 推定量 X ˉ \bar X X ˉ の散らばりです。たとえば身長データなら、標準偏差は「人によって身長がどれだけ違うか」、標準誤差は「100人の平均身長を何度も測り直したらその平均値がどれだけブレるか」。後者は平均する人数 n n n n \sqrt n n
Q2. なぜ分散が σ 2 / n \sigma^2/n σ 2 / n σ 2 n \sigma^2 n σ 2 n σ 2 \sigma^2 σ 2
A. 平均は「足して n n n ∑ X i \sum X_i ∑ X i n σ 2 n\sigma^2 n σ 2 増えます (n n n X ˉ \bar X X ˉ n n n V [ a X ] = a 2 V [ X ] V[aX]=a^2V[X] V [ a X ] = a 2 V [ X ] 1 n 2 \frac{1}{n^2} n 2 1 1 n 2 ⋅ n σ 2 = σ 2 n \frac{1}{n^2}\cdot n\sigma^2=\frac{\sigma^2}{n} n 2 1 ⋅ n σ 2 = n σ 2 n n n
Q3. 標本サイズ n n n
A. なりません。標準誤差は σ / n \sigma/\sqrt n σ / n n n n n \sqrt n n n n n 2 ≈ 1.41 \sqrt 2\approx1.41 2 ≈ 1.41 1 / 1.41 ≈ 0.71 1/1.41\approx0.71 1/1.41 ≈ 0.71 SEを半分にするには n n n 、1 / 3 1/3 1/3 n \sqrt n n
Q4. 標本比率 p ^ \hat p p ^
A. いつでもではありません。p ^ \hat p p ^ p p p n n n n p ≥ 5 np\ge5 n p ≥ 5 n ( 1 − p ) ≥ 5 n(1-p)\ge5 n ( 1 − p ) ≥ 5 ≥ 10 \ge10 ≥ 10 n n n p p p p = 0.02 p=0.02 p = 0.02 n = 50 n=50 n = 50 n p = 1 < 5 np=1<5 n p = 1 < 5 ポアソン分布 )。
Q5. 母分散 σ 2 \sigma^2 σ 2
A. 標本から推定します。標本標準偏差 s = 1 n − 1 ∑ ( X i − X ˉ ) 2 s=\sqrt{\frac{1}{n-1}\sum(X_i-\bar X)^2} s = n − 1 1 ∑ ( X i − X ˉ ) 2 σ \sigma σ S E ^ = s / n \widehat{\mathrm{SE}}=s/\sqrt n SE = s / n σ \sigma σ s s s 自由度 n − 1 n-1 n − 1 t t t にしたがいます(s s s σ \sigma σ z z z t t t σ \sigma σ t t t n n n t t t z z z t分布・カイ二乗分布・F分布(標本分布の三役) で扱います。
まとめ
標本平均 X ˉ \bar X X ˉ :E [ X ˉ ] = μ E[\bar X]=\mu E [ X ˉ ] = μ V [ X ˉ ] = σ 2 / n V[\bar X]=\sigma^2/n V [ X ˉ ] = σ 2 / n 標準誤差 σ / n \sigma/\sqrt n σ / n 。導出は期待値の線形性(E E E V V V 標本比率 p ^ \hat p p ^ :X ˉ \bar X X ˉ E [ p ^ ] = p E[\hat p]=p E [ p ^ ] = p V [ p ^ ] = p ( 1 − p ) / n V[\hat p]=p(1-p)/n V [ p ^ ] = p ( 1 − p ) / n p ( 1 − p ) / n \sqrt{p(1-p)/n} p ( 1 − p ) / n p = 0.5 p=0.5 p = 0.5 正規近似 :CLT(中心極限定理(CLT) )により X ˉ ≈ N ( μ , σ 2 / n ) \bar X\approx N(\mu,\sigma^2/n) X ˉ ≈ N ( μ , σ 2 / n ) p ^ ≈ N ( p , p ( 1 − p ) / n ) \hat p\approx N(p,p(1-p)/n) p ^ ≈ N ( p , p ( 1 − p ) / n ) n p ≥ 5 , n ( 1 − p ) ≥ 5 np\ge5,\ n(1-p)\ge5 n p ≥ 5 , n ( 1 − p ) ≥ 5 標準偏差 ≠ 標準誤差 :SDはデータ1個のばらつき(n n n σ / n \sigma/\sqrt n σ / n n n n n \sqrt n n 精度は n \sqrt n n n \sqrt n n σ \sigma σ s s s t t t 区間推定(母平均・母比率・母分散の信頼区間) )・検定統計量の分母そのものになる。
関連ノート