🎓 レベル:基礎 | 重要度:A(必須)
📎 前提:学習問題の定式化(仮説・損失・経験リスク) | 関連:訓練・検証・テストと交差検証 | 数理:単回帰分析(統計・決定係数)
要点(BLUF)
- 回帰モデルの良さは「予測 が実測 からどれだけ外れたか」を1つの数値にまとめて測ります。代表は MSE・RMSE・MAE・MAPE・決定係数 の5つです。
- 大きな外れを重く罰したいなら RMSE/MSE、外れ値に振り回されたくないなら MAE、相対誤差(割合)で語りたいなら MAPE を選びます。
- は「モデルが平均予測よりどれだけマシか」を 0〜1(負にもなる)で示す、スケールに依らない要約指標です。
1. 記号の準備
実測値を 、予測値を 、サンプル数を とします。 番目の 残差(誤差) は
です。以下の指標はすべて、この残差をどう集計するかの違いにすぎません。
2. 各指標の定義と意味
MSE(平均二乗誤差)
要するに:残差を2乗して平均したもの。2乗するので大きな外れが効きやすく、学習時の損失関数としてそのまま使えます(微分が素直)。難点は単位が元データの2乗(例:価格が円なら円²)になり、人間が解釈しにくいこと。
RMSE(二乗平均平方根誤差)
要するに:MSE の平方根。単位が元データと同じになるので「平均してだいたい○円ずれる」と読めます。残差の標準偏差に相当します。MSE と同様に大きな外れを重く罰します。
MAE(平均絶対誤差)
要するに:残差の絶対値の平均。単位は元データと同じで、すべての誤差を等しく扱うため 外れ値に頑健です。「典型的にどれくらいずれるか」を素直に表します。
MAPE(平均絶対パーセント誤差)
要するに:誤差を実測値で割った「相対誤差」の平均(%表示)。スケールに依らず「平均○%ずれる」と言えるので非専門家への報告に向きます。ただし で割るため 0 近傍で不安定( で定義不能、近いと爆発)。さらに過大予測を過小予測より重く罰する 非対称性があり、過小予測寄りのモデルを不当に好む癖があります。
決定係数
ここで は残差平方和、 は実測値の全変動( は実測の平均)です。
要するに:「いつも平均 を答えるだけのモデルを基準に、自分のモデルがどれだけ誤差を減らせたか」の割合。 で完璧、 で平均予測と同等。モデルが平均予測より悪い()と 負にもなりえます。これは統計の 決定係数 とまったく同じ概念で、回帰の当てはまりの良さを無次元で表す共通の物差しです。
自由度調整済み
は説明変数の数です。
要するに:素の は、無意味な変数を足しても下がらず増える一方なので、変数の数 にペナルティを課したもの。変数を増やしても効果が見合わなければ下がります。説明変数の数が違うモデル同士の比較に使います。統計の重回帰でも同じ調整済み を使います(→ 重回帰分析)。
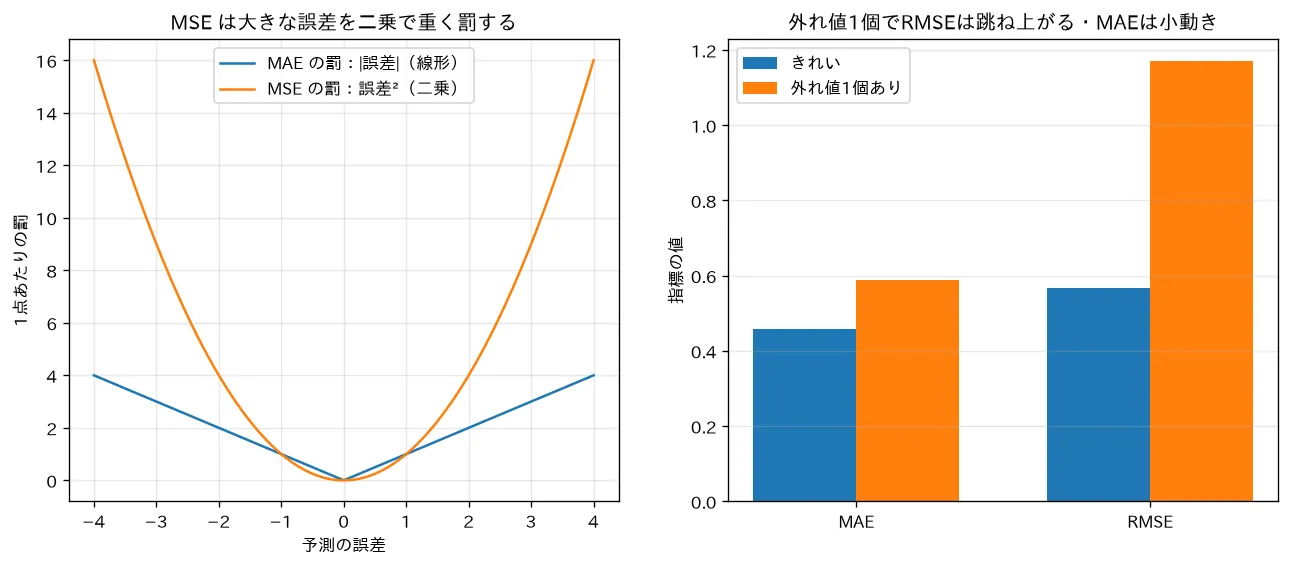
3. 外れ値への感度の違い(MAE と RMSE)
RMSE は残差を2乗するため、大きな1つの外れが結果を支配します。MAE は絶対値なので外れの影響が線形にとどまります。具体例で見ます。
5件の予測のうち4件は誤差 1、1件だけ誤差 10 とします(残差の絶対値が )。
| 指標 | 計算 | 値 |
|---|---|---|
| MAE | 2.8 | |
| RMSE | 約 4.58 |
同じデータでも RMSE は MAE の約1.6倍に膨らみました。1件の大外れ(誤差10)が2乗で100に化け、RMSE を押し上げたわけです。一般に外れ値が混じると で、その差が開くほど「誤差のばらつきが大きい=大外れがある」サインになります。
xychart-beta
title "外れ値1件でRMSEだけが跳ね上がる"
x-axis ["MAE", "RMSE"]
y-axis "誤差の大きさ" 0 --> 6
bar [2.8, 4.58]
4. 使い分け
flowchart TD
Q1{"大きな外れを<br/>重く罰したい?"}
Q1 -- "はい" --> RMSE["RMSE / MSE<br/>(2乗で大外れを強調)"]
Q1 -- "いいえ(外れに頑健に)" --> MAE["MAE<br/>(誤差を等価に扱う)"]
Q2{"誤差を割合(%)で<br/>語りたい?"}
Q2 -- "はい・0近傍なし" --> MAPE["MAPE<br/>(相対誤差・報告向き)"]
Q3{"モデルの説明力を<br/>無次元で比べたい?"}
Q3 -- "変数数が同じ" --> R2["R²"]
Q3 -- "変数数が違う" --> AR2["自由度調整済みR²"]
- RMSE/MSE:大外れが致命的な場面(在庫の大量欠品など)、学習の損失関数。単位は元データと同じ(RMSE)。
- MAE:外れ値が多い・典型誤差を素直に知りたい場面。頑健。
- MAPE:スケールの異なる系列を横並びで比べたい・割合で報告したい場面。ただし実測が 0 を含む/0 近傍では使わない。
- /自由度調整済み :モデルの説明力を無次元で要約・比較したいとき。変数数が違うモデルの比較は調整済みを使う。
実務では 1つに絞らず複数を併記するのが定石です(例:RMSE で大外れ、MAE で典型誤差、 で説明力)。
⚠️ よくある誤解
- は必ず 0〜1、ではない。テストデータや非線形モデルでは、平均予測に負ける場合に負の値を取りえます()。負=「平均を答えた方がマシ」のサイン。
- が高い=予測が当たる、ではない。 は分散の説明割合であって、絶対的な誤差の大きさ(RMSE/MAE)とは別物。スケールを知るには誤差系の指標が要る。
- MAPE は万能ではない。0 近傍で発散し、過大予測を過小予測より重く罰する非対称性がある。需要0が混じる予測などでは破綻する。
- 指標と損失関数を混同しない。学習では微分しやすい MSE を最小化し、報告は RMSE や で行う、という使い分けが普通(→ 学習問題の定式化(仮説・損失・経験リスク))。
- 素の で変数数の違うモデルを比べない。変数を足すほど上がる性質があるので、比較には自由度調整済み を使う。
対応するシミュレーション
simulations/regression_metrics.py:MAE・RMSE・R² を計算し、予測に大きな外れ値を1個だけ混ぜたときに各指標がどう動くかを比べます。RMSE は誤差を二乗するため外れ値1個で大きく跳ね上がる(0.57→1.17)のに対し、MAE は線形なので小動き(0.46→0.59)という頑健性の違いを、1点あたりの罰の曲線(線形 vs 放物線)とあわせて可視化します。
関連ノート
- 学習問題の定式化(仮説・損失・経験リスク)
- 訓練・検証・テストと交差検証
- 評価指標(分類)とROC・AUC
- 単回帰分析(統計・決定係数の定義)
- 重回帰分析(統計・自由度調整済み )
- 機械学習の基礎枠組み 目次
- 機械学習テキスト 全体目次