🎓 レベル:標準 | 重要度:B(標準)
📎 前提:評価指標(分類)とROC・AUC(評価)
要点(BLUF)
- 不均衡データでは 精度(accuracy)は無意味になる。99%が陰性なら「全部陰性」と予測するだけで精度99%だが、肝心の陽性を一件も当てていない。
- 対処は 4方向:評価指標を変える(PR-AUC・F1・再現率)/データを変える(リサンプリング・SMOTE)/アルゴリズムを変える(クラス重み)/閾値を動かす。
- リサンプリングは 訓練データだけ に適用する。検証・テストは本来の分布のまま評価しないと、性能を錯覚する。
1. 何が問題なのか
不均衡データ(imbalanced data)とは、クラスの出現割合が大きく偏ったデータです。典型例は不正検知・故障予測・希少疾患の診断で、陽性(正例)が全体の数%〜0.1%しかないことも珍しくありません。
このとき何が起きるか。陽性が1%しかないデータで「常に陰性と予測する」だけのモデルを考えます。
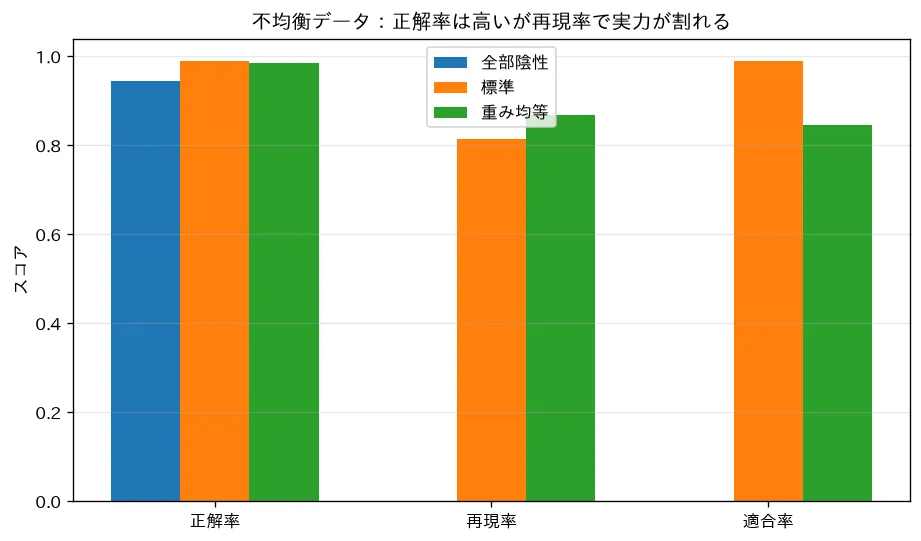
精度99%です。一見すばらしいですが、このモデルは陽性を 一件も 見つけていません。不正検知なら不正をすべて見逃し、疾患診断なら患者を全員「健康」と判定しています。精度が高いのに完全に無価値 —— これが accuracy paradox(精度の罠)です。
これは 評価指標(分類)とROC・AUC で見た「精度だけ見てはいけない」理由そのものであり、異常検知 が向き合う「異常=少数派をどう拾うか」という構造とまったく同じ問題です。多数派に最適化すれば全体の損失は小さくなるので、何も対処しないモデルは自然と多数派へ倒れます。
2. 評価:精度ではなく PR-AUC・F1・再現率
不均衡では、少数派(陽性)をどれだけ拾えているか を測る指標を主役に据えます。指標の定義そのものは 評価指標(分類)とROC・AUC に譲り、ここでは「不均衡で何を使うか」の差分を述べます。
再現率(recall)と適合率(precision)
- 再現率(recall) = 実際の陽性のうち、当てられた割合。見逃しの少なさ。
- 適合率(precision) = 陽性と予測したもののうち、本当に陽性だった割合。誤報の少なさ。
不正検知では「見逃し(FN)を減らす」=再現率が重視されがちですが、誤報(FP)を増やしすぎると現場が回りません。両者はトレードオフなので、調和平均である F1 でバランスを見ます。
見逃しのコストが特に高い(疾患の見逃しなど)なら、再現率を重く扱う Fβ(β>1) を使います。
なぜ ROC-AUC より PR-AUC か
ROC 曲線は「真陽性率(recall)」対「偽陽性率」で描きます。偽陽性率の分母は 陰性の総数(TN+FP) で、不均衡では陰性が膨大です。すると FP が多少増えても偽陽性率はほとんど動かず、ROC-AUC は楽観的に高く出やすい。陰性が大量にあるおかげで「FPの痛み」が薄まってしまうのです。
一方 PR 曲線は「recall」対「precision」で描き、precision の分母は 陽性と予測した数(TP+FP) です。誤報 FP が増えれば precision は即座に下がるので、PR 曲線は 少数派を拾う難しさ を正直に反映します。だから不均衡では PR-AUC を主指標にします。
ただし注意点があります(要確認の論点)。PR-AUC の「ランダム予測のベースライン」は 陽性の割合そのもの に等しく、データの不均衡度で値が動きます。
つまり陽性1%なら PR-AUC のベースラインは 0.01 で、絶対値だけ見ても良し悪しを判断できません。「ベースライン(陽性割合)からどれだけ上にあるか」で読みます。なお ROC-AUC のランダムベースラインは不均衡によらず常に 0.5 で、この 不変性ゆえに ROC-AUC のほうが公平だ とする近年の反論もあります。実務では「PR-AUC を主、ROC-AUC を従」で両方見るのが無難です。
flowchart LR P["不均衡データ<br/>陽性が極端に少ない"] --> A["評価を変える<br/>PR-AUC・F1・recall を見る(accuracy は捨てる)"] P --> B["データを変える<br/>オーバー/アンダーサンプリング・SMOTE"] P --> C["アルゴリズムを変える<br/>クラス重み(少数派の誤りを重く罰する)"] P --> D["閾値を動かす<br/>0.5 → 業務コストに合う点へ"] A --> G["少数派を拾えるモデル"] B --> G C --> G D --> G
3. リサンプリング:データ側で釣り合いを取る
学習データのクラス比そのものを操作して、多数派へ倒れにくくする方法です。大きく3つあります。
オーバーサンプリング(少数派を増やす)
- 単純複製(random oversampling):少数派をコピーして水増しする。最も単純だが、まったく同じ点を増やすだけ なので、その点に過剰適合(過学習)しやすい。
- SMOTE(Synthetic Minority Oversampling Technique):複製でなく、近傍を補間して 新しい合成サンプル を作ります。
SMOTE の手順は次の通りです。ある少数派のサンプル を選び、同じ少数派の中での k近傍 を求め、その中から1つ を選びます。両者を結ぶ線分上のランダムな点を新サンプルにします。
要するに「既存の少数派2点の 間 に、もっともらしい架空のサンプルを置く」操作です。単純複製と違って点が散らばるので、過学習しにくくなります。
ただし SMOTE にも落とし穴があります。補間は 多数派を見ずに少数派だけ で行うため、クラスが重なり合う領域では「多数派の海の中に少数派の合成点」を作ってしまい、かえって境界を曖昧にすることがあります。境界付近だけ合成する Borderline-SMOTE や、難しいサンプル周辺を厚くする ADASYN など、これを和らげる派生も使われます。
アンダーサンプリング(多数派を減らす)
多数派を間引いてクラス比を揃えます。データ量が減るので学習は速くなりますが、捨てたデータの情報を失う のが欠点です。ランダムに捨てるのが基本ですが、境界付近の冗長なペアを除く Tomek links など、賢く間引く手法もあります。
組み合わせ(ハイブリッド)
SMOTE で少数派を合成しつつ、多数派をアンダーサンプリングで削る、という併用が実務では安定しやすいです。SMOTE 原論文でも「オーバー+アンダーの併用」が推奨されています。
| 手法 | 利点 | リスク |
|---|---|---|
| 単純複製 | 簡単・情報を捨てない | 同一点への過学習 |
| SMOTE | 点が散り過学習しにくい | 境界の曖昧化・ノイズ増幅 |
| アンダーサンプリング | 高速・メモリ節約 | 多数派の情報損失 |
| ハイブリッド | 両者の弱点を補う | パラメータ調整が増える |
4. 閾値調整:境界線を動かす
ロジスティック回帰 のような確率を出力するモデルは、内部で なら陽性、と判定するのが既定です。しかしこの 0.5 は天下りの値 であって、不均衡では最適とは限りません。
閾値 を下げれば、より弱い確信でも陽性と判定するので 再現率は上がり、適合率は下がる。上げれば逆になります。
リサンプリングやクラス重みを使わなくても、閾値を動かすだけ で再現率・適合率のバランスを業務要件に合わせられます。やり方は、検証データで PR 曲線(や recall-precision のトレードオフ)を描き、見逃しコストと誤報コストを踏まえて を選ぶこと。F1 を最大化する点を選ぶ、あるいは「再現率0.9を満たす中で適合率最大」のように業務制約から決めるのが定石です。
なお閾値調整は確率の 順位 を変えないので、ROC-AUC や PR-AUC の値そのものは変わりません。変わるのは「ある閾値で切ったときの recall/precision/F1」です。だからこそ AUC で全体性能を見つつ、最後に閾値で運用点を決める、という二段構えになります。
5. コスト考慮学習:クラス重みで誤りを重みづける
データを触らず、損失関数の側 で少数派を優遇する方法です。少数派の誤分類に大きな重みを掛け、「少数派を間違えると強く罰される」ようにします。
通常の損失は全サンプルを等価に扱いますが、クラス重み を入れると次のようになります(交差エントロピーの例)。
陽性に大きな を与えれば、陽性を取りこぼしたときの損失が膨らみ、モデルは少数派を無視できなくなります。重みの定番は クラス頻度の逆数 に比例させる設定です(scikit-learn の class_weight="balanced" がこれに相当)。
クラス重みの利点は、データを複製も削除もしない こと。データ量を変えずに済むので、大規模データで特に扱いやすく、リサンプリングのような情報損失・過学習のリスクを避けられます。多くのライブラリで一引数で済むのも実務的です。
⚠️ よくある誤解・落とし穴
- 精度を見て満足しない。不均衡では accuracy は飾りです。必ず recall・precision・F1・PR-AUC で評価します。
- リサンプリングは訓練データだけに適用する。検証・テストにまで SMOTE をかけると、本番には存在しない合成データで評価することになり、性能を錯覚します。検証・テストは 本来の不均衡な分布のまま 残すのが鉄則です。
- SMOTE は交差検証の「中」で行う。前処理として全データに先に SMOTE をかけてから分割すると、合成に使った近傍情報が検証分割へ漏れる(データリーク)。分割した訓練フォールドの中だけで SMOTE する(パイプライン化する)こと。
- リサンプリングで確率が歪む。クラス比を人為的に変えると、出力確率はもとの分布の確率からずれます。確率値そのものを業務に使う場合は較正(キャリブレーション)が要ります。
- SMOTE は万能ではない。クラスが大きく重なるデータや高次元データでは、補間がノイズを増幅して逆効果になることもあります。まずはクラス重み+閾値調整という「データを触らない」対処から試すのが安全です。
まとめ
不均衡データの本質は「多数派に最適化すれば全体損失は下がるが、肝心の少数派を取りこぼす」こと。対処は 評価・データ・アルゴリズム・閾値 の4方向で、どれか一つでなく組み合わせて使います。出発点としては「accuracy を捨てて PR-AUC・recall で測る」「クラス重みを入れる」「閾値を業務コストで決める」の3点を押さえれば、多くのケースで戦えます。SMOTE のようなリサンプリングは強力ですが、訓練データ限定・リーク回避という作法を守ってこそ意味を持ちます。
対応するシミュレーション
simulations/imbalanced_threshold.py:陽性5%の不均衡データで、「全部陰性と答えるだけ」の分類器でも正解率が約0.95に達してしまう accuracy paradox を示し、class_weight="balanced" で少数派を重く扱うと陽性の再現率が改善する(代わりに適合率は下がる)ことを、指標の棒グラフと混同行列で確認できます。ROC/PR の見方は 評価指標(分類)とROC・AUC と対で。