🎓 レベル:標準 | 重要度:B(標準)
📎 前提:混合ガウスモデルとEM(密度ベース) | 数理:多変量正規分布(統計, マハラノビス距離)
要点(BLUF)
- 異常検知(anomaly / outlier detection)は、「正常な構造」をモデル化し、そこから外れたサンプルを検出するタスクです。正常データが圧倒的多数で、異常がごく稀という設定が前提になります。
- 異常には3類型あります。点異常(単独で外れている)・文脈異常(文脈に照らすと外れている)・集団異常(個々は正常だが集まると異常)。どれを狙うかでモデルが変わります。
- アプローチは「正常らしさをどう測るか」で4系統に整理できます。(1) 密度・尤度ベース(マハラノビス距離・GMM)、(2) 距離/近傍ベース(k-NN・LOF)、(3) 分離ベース(Isolation Forest・One-Class SVM)、(4) 再構成誤差(PCA・オートエンコーダ)。
1. 異常検知とは
異常検知は「大多数の正常サンプルとは振る舞いが異なる、稀なサンプルを見つける」問題です。不正検知・故障予知・センサ監視・ネットワーク侵入検知など、応用は「正常がほとんどで異常がたまにしか起きない」状況に集中します。
ここで難しいのは、異常そのものを直接学習できないことが多い点です。異常は稀で、形も多様で、しかも未知の異常(まだ一度も観測していないタイプ)を当てたいことすらあります。そこで多くの手法は、発想を裏返して 「正常な構造をモデル化し、そこから外れる度合いを異常スコアにする」 という戦略を取ります。
flowchart LR
Data["観測データ<br/>(大多数が正常)"] --> Model["正常の構造を学習<br/>(密度 / 近傍 / 分離 / 再構成)"]
Model --> Score["各サンプルに<br/>異常スコアを付与"]
Score --> Th["閾値で判定"]
Th --> Normal["正常"]
Th --> Anom["異常"]
要するに:異常検知は「異常を覚える」のではなく「正常を覚えて、そこからの外れ具合を測る」のが基本戦略です。
2. 異常の3類型
「異常」とひとくくりにできません。何を異常とみなすかで3つに分かれ、使う手法も変わります([Chandola et al., Anomaly Detection: A Survey, 2009] の分類が標準)。
graph TB
Anom["異常の3類型"]
Anom --> P["点異常<br/>(point anomaly)"]
Anom --> C["文脈異常<br/>(contextual anomaly)"]
Anom --> Coll["集団異常<br/>(collective anomaly)"]
P --> P1["単独のサンプルが<br/>全体から外れている"]
C --> C1["ある文脈の中でだけ外れる<br/>(文脈が変われば正常)"]
Coll --> Coll1["個々は正常だが<br/>並び/集合として異常"]
- 点異常(point anomaly):1つのサンプルが、それ単体でデータ全体から外れているもの。最も基本的で、本ノートの手法は主にこれを狙います。例:通常 1万円前後のカード決済に突然 300万円の取引が1件。
- 文脈異常(contextual anomaly):値そのものは取りうる範囲でも、文脈(時刻・季節・場所など)に照らすと外れているもの。例:気温 30℃ は夏なら正常だが冬の文脈では異常。文脈を表す変数(context attribute)と振る舞いを表す変数(behavioral attribute)を分けて扱う必要があります。時系列でよく現れます。
- 集団異常(collective anomaly):個々のサンプルは正常だが、集まり(並び・部分集合)として異常なもの。例:心電図の一拍一拍は正常範囲でも、その並びのパターンが不整脈を示す。系列・グラフなど構造を持つデータで問題になります。
要するに:点異常は「値が外れている」、文脈異常は「文脈に対して外れている」、集団異常は「並びが外れている」。狙う異常の型を最初に決めないと、手法選びを誤ります。
3. なぜ普通の分類で解けないのか
「異常 vs 正常の2クラス分類では?」と思うかもしれませんが、素朴な教師あり分類は破綻しがちです。理由は2つです。
- 極端なクラス不均衡:異常は全体の 0.1% や 0.01% ということが珍しくありません。「全部正常」と予測するだけで正解率 99.99% になり、精度(accuracy)はまったく当てになりません(→ 5節の評価へ)。学習も多数派の正常に引きずられます。
- 異常ラベルの希少さ・偏り:異常は集めにくく、ラベル付けも高コスト。しかも集まった異常は「過去に観測できた一部のタイプ」に偏り、未知の新種の異常(novelty)は教えられていない。教師あり分類は「学習で見た異常」しか当てられません。
そこで設定(どれだけラベルがあるか)に応じて3つに分けます。
graph LR
Set["設定 = 使えるラベル"]
Set --> U["教師なし<br/>(unsupervised)"]
Set --> Semi["半教師あり<br/>(semi-supervised)"]
Set --> Sup["教師あり<br/>(supervised)"]
U --> U1["ラベルなし<br/>大半が正常と仮定し<br/>外れ値を探す"]
Semi --> Semi1["正常データのみで学習<br/>(novelty detection)"]
Sup --> Sup1["正常/異常両方にラベル<br/>不均衡分類に帰着"]
- 教師なし(unsupervised):ラベルが一切ない。「データの大半は正常」と仮定し、構造から外れるサンプルを探します。本ノートの LOF・Isolation Forest はここが主戦場。
- 半教師あり(semi-supervised):正常データのみで学習し、そこから外れたものを異常とみなす。新規性検知(novelty detection) とも呼ばれます。One-Class SVM・正常だけで学習したオートエンコーダが代表。「正常の領域」を覚えるイメージ。
- 教師あり(supervised):正常・異常の両方にラベルがある。普通の(ただし強い不均衡の)分類問題に帰着し、リサンプリングやコスト調整で対処します。異常のタイプが既知で十分なラベルがある場合に有効。
なお scikit-learn では、訓練データに異常が混じる前提を outlier detection(教師なし)、正常のみで学習する前提を novelty detection(半教師あり)と呼び分けています([scikit-learn 2.7. Novelty and Outlier Detection])。
要するに:異常は「稀でラベルが乏しく、未知の型もある」ので、素朴な分類では解けません。だから多くの手法が「正常を覚える」教師なし/半教師ありの枠組みを取ります。
4. アプローチの体系
正常らしさを「何で測るか」で4系統に整理できます。まず全体マップを置きます。
graph TB
Root["異常検知のアプローチ"]
Root --> D["(1)密度・尤度ベース"]
Root --> Dist["(2)距離・近傍ベース"]
Root --> Sep["(3)分離・モデルベース"]
Root --> Rec["(4)再構成誤差ベース"]
D --> D1["ガウス / GMM の尤度"]
D --> D2["マハラノビス距離<br/>(共分散を考慮した距離)"]
Dist --> Dist1["k-NN 距離<br/>(k番目の近傍までの距離)"]
Dist --> Dist2["LOF<br/>(局所密度の相対比)"]
Sep --> Sep1["Isolation Forest<br/>(孤立しやすさ)"]
Sep --> Sep2["One-Class SVM<br/>(原点から分離する境界)"]
Rec --> Rec1["PCA<br/>(線形部分空間で再構成)"]
Rec --> Rec2["オートエンコーダ<br/>(非線形で再構成)"]
(1) 密度・尤度ベース:マハラノビス距離と GMM
最も古典的な発想は「正常データの確率密度 を推定し、 が低い(=起こりにくい)サンプルを異常とする」です。データを多変量正規分布 で当てはめたとき、異常スコアの中心になるのが マハラノビス距離(Mahalanobis distance) です(数理は 多変量正規分布 統計)。
ユークリッド距離 と違い、共分散 の逆行列で「軸ごとのばらつき」と「軸間の相関」を割り戻しています。 を挟むことで、分散が大きい方向の差は割り引き、分散が小さい方向の差は強調する。つまり「データの広がりの形(楕円)に沿った距離」になります。
要するに:マハラノビス距離は「ばらつきと相関を考慮した、データの形に沿った正規化距離」です。等方的なユークリッド距離では見逃す“相関方向から外れた点”を捉えます。
しかもこの距離は閾値を確率で決められる点が強力です。( 次元)なら
つまりマハラノビス距離の2乗は自由度 のカイ二乗分布に従うので、たとえば「上側 1% 点 を超えたら異常」と、恣意的でない閾値が引けます。データが単峰の正規分布で近似できない(複数の塊がある)場合は、単一ガウスの代わりに GMM の尤度を使います。各サンプルの混合尤度 が低いものを異常とする発想で、密度推定そのものが 混合ガウスモデルとEM です。
(2) 距離・近傍ベース:k-NN距離と LOF
密度を陽にモデル化する代わりに、「近傍の混み具合」を異常スコアにするのが近傍ベースです。最も単純なのは k-NN距離:各サンプルから k 番目に近い近傍までの距離を測り、これが大きい(=まわりがスカスカ)サンプルを異常とします。
ただし k-NN距離には弱点があります。データの密度が場所によって違うと、密な領域の基準で全体を測ってしまい、疎な領域の正常点まで異常と誤判定します。これを解決するのが LOF(Local Outlier Factor, 局所外れ値因子) です。LOF の肝は 「自分の局所密度を、近傍たちの局所密度と比べる」 ところにあります([Breunig et al., 2000])。
LOF は3段階で組み立てます。
- 到達可能距離(reachability distance):点 から への到達可能距離を、 の k-距離で下限をかませて定義します。 のすぐ近くにある点は、実際の距離が小さくても の k-距離まで“底上げ”される。これで局所密度の推定がノイズに対して安定します。
- 局所到達可能密度(LRD, local reachability density):近傍 への到達可能距離の平均の逆数。 まわりが混んでいれば距離が小さく、逆数なので LRD は大きく(高密度)なります。
- LOF スコア:近傍たちの LRD の平均を、自分の LRD で割った比。
判定はこの比で読みます。 なら近傍と同程度の密度(正常)、 なら近傍より密(内側)、 なら近傍より明らかに疎=外れ値です。絶対的な密度ではなく比で見るので、密度がまちまちのデータでもうまく機能します。
要するに:LOF は「自分の混み具合 ÷ ご近所の混み具合」。比を取ることで、密な場所でも疎な場所でも“ご近所より浮いている点”を公平に拾えます。
(3) 分離・モデルベース:Isolation Forest と One-Class SVM
Isolation Forest(孤立森) は発想が独特です。密度も距離も測らず、「ランダムに切っていったとき、何回で孤立するか」だけで異常を測ります([Liu et al., 2008])。
手順は単純で、バギングとランダムフォレスト の木をデータのサブサンプルに対して作ります。各木では「特徴をランダムに選び、その値域の中でランダムな閾値で分割」を、点が1個に孤立するまで繰り返します。ここでの直観は 「異常は少数かつ周囲から離れているので、ランダムな分割でも早く(浅い深さで)孤立する」。逆に正常は密集地にいるので、切り分けるのに多くの分割を要します。
各点 の孤立に要した経路長(根からの分割回数)を とし、木をたくさん作って平均 を取ります。これをサンプル数 で正規化したのが異常スコアです。
ここで は「 点の二分探索木における探索失敗の平均経路長」で、 は調和数 。経路長 を「平均的な経路長 」で割って正規化し、 で 0〜1 に押し込んでいます。読み方は次のとおり。
- (すぐ孤立する=異常)なら
- (平均的)なら
- が大きい(なかなか孤立しない=正常)なら
スコアが 1 に近いほど異常です。距離計算が不要で計算が軽く、高次元・大規模データに強いのが実務での人気の理由です。
もう一つの代表が One-Class SVM(一クラスSVM) で、これは半教師あり(正常のみで学習) の代表格です。サポートベクターマシン(SVM) のマージン最大化を1クラス用に作り替えたもので、カーネルで写した特徴空間で、データを原点からできるだけ大きなマージンで隔てる超平面を引きます。「原点側=異常領域」と見立て、原点と正常データ群を最大マージンで分離する境界を学習する、という発想です。
学習後、 となる点(境界の原点側に落ちる点)を異常と判定します。パラメータ が要で、異常とみなす割合の上限かつサポートベクター比率の下限を制御します( を小さくするほど判定が厳しくなる)。RBF カーネルを使えば非線形で複雑な正常領域も囲えますが、 と の調整に敏感で、高次元・大規模ではやや扱いにくいのが難点です。
(4) 再構成誤差ベース:PCA とオートエンコーダ
最後は 「正常は再構成できるが、異常は再構成できない」 ことを使う系統です。正常データだけで「低次元に圧縮 → 復元」する写像を学習し、復元のズレ(再構成誤差)が大きいサンプルを異常とします。
線形版が PCA(多変量正規分布 と表裏一体)。正常データの主要な分散を張る部分空間に射影して戻すと、正常点はほぼ元に戻りますが、その部分空間から外れた方向に乗った異常点は戻りきらず、誤差が残ります。
非線形版が オートエンコーダ(深層モデル。詳細は後の Phase)。エンコーダで潜在表現に圧縮し、デコーダで復元する。正常データだけで学習すると「正常のパターン」だけを再現できる圧縮器になり、未知の異常は再現できず誤差が跳ね上がります。実際、正常で学習したオートエンコーダは異常入力で再構成誤差が桁違いに大きくなることが知られています。なお線形のオートエンコーダは PCA と数学的に等価で、非線形にして初めて PCA を超える表現が得られます。
要するに:再構成誤差ベースは「正常の圧縮・復元器を作り、復元しきれない=学習した正常パターンに当てはまらない、を異常の証拠にする」。正常が低次元の構造(多様体)に乗っている高次元データで特に有効です。
5. 評価の難しさ
異常検知の評価は、普通の分類より厄介です。原因は 極端なクラス不均衡 にあります。
まず 精度(accuracy)は使い物になりません。異常が 0.1% なら「全部正常」と答えるだけで accuracy は 99.9%。何も検知していないのに高得点に見えてしまいます。そこで異常検知では、スコアに閾値を引く前のランキング性能を評価する、面積系の指標が標準です。
- ROC-AUC:真陽性率(TPR=再現率)と偽陽性率(FPR)の関係。閾値に依存せず全体の弁別力を測れます。ただし強い不均衡では楽観的になりがち:正常(負例)が大量にあると、多少の誤検知では FPR がほとんど上がらず、AUC が高く出てしまいます。
- PR-AUC(適合率-再現率曲線の面積):適合率(precision)と再現率(recall)の関係。多数の真陰性(正常)を分母に含めないので、不均衡下の「検知できているか」をより厳しく・正直に反映します。異常検知では PR-AUC を主指標にするのが安全です(評価指標の整理は 評価指標(分類)とROC・AUC)。
graph LR
Eval["不均衡下の評価"]
Eval --> Acc["accuracy<br/>使えない<br/>(全部正常で高得点)"]
Eval --> ROC["ROC-AUC<br/>楽観的になりやすい<br/>(負例が多くFPR上がりにくい)"]
Eval --> PR["PR-AUC<br/>不均衡に厳しく正直<br/>(主指標に推奨)"]
もう一つの難所が 閾値の決め方 です。多くの手法は連続的な異常スコアを返すだけで、「どこから異常か」は別途決めねばなりません。ラベルが乏しいので「検証データで最適化」も難しい。実務では次のような決め方を取ります。
- 分位点(quantile)で切る:スコア分布の上位 q%(例:上位 1%)を異常とする。
- コンタミネーション率(contamination)を仮定:「データに含まれる異常の割合は概ね α」と事前に見積もり、その割合だけ異常と判定する(scikit-learn の
contaminationパラメータがこれ)。 - 確率的な閾値:密度・尤度ベースなら、前述のカイ二乗分布の上側点のように、理論分布の分位点で閾値を引ける(恣意性が小さい)。
要するに:不均衡ゆえ accuracy も ROC-AUC も油断ならず、PR-AUC を主軸にするのが安全。そして閾値は「正解で最適化」が効きにくいので、分位点・コンタミネーション率・理論分布のいずれかで決めるのが定石です。
⚠️ よくある誤解・落とし穴
- 「正常データはきれいに正常」と思い込む。教師なし手法は「訓練データの大半は正常」と仮定しますが、実際は正常データに異常が混入していたり、正常の代表性が足りなかったり(観測していない正常パターンがある)します。正常データの代表性が崩れると、正常を異常と誤検知します。何を正常とみなすかの定義が結果を左右します。
- スケール依存を忘れる。距離・近傍・密度ベース(k-NN, LOF, マハラノビス, One-Class SVM)は特徴のスケールに敏感です。単位が違う特徴をそのまま使うと、値域の大きい特徴だけで距離が決まります。標準化(あるいはマハラノビスのように共分散で割り戻す)が前提。一方 Isolation Forest は各軸を独立にランダム分割するため、比較的スケールに頑健です。
- 閾値の恣意性を軽視する。「上位 1% を異常」「contamination=0.05」といった設定は、ほぼそのまま検知数を決めてしまいます。AUC系で“スコアの良さ”を測れても、最終的な検知数・適合率は閾値次第。閾値は運用コスト(誤検知の許容量)と一緒に決めるべきで、根拠なく決めると過検知・見逃しを招きます。
- 高次元での距離の劣化(次元の呪い)。次元が上がると、点と点の距離が互いに近づき**「最も近い点と最も遠い点の差」が消えていきます**(次元の呪い)。すると k-NN距離・LOF・マハラノビス( の推定も不安定化)といった距離・密度ベースは弁別力を失います。高次元では、再構成誤差ベース(低次元多様体を仮定)や Isolation Forest のように、距離に直接依存しない手法が相対的に有利になります。
- ROC-AUC を鵜呑みにする。前節のとおり、強い不均衡では ROC-AUC が高く出やすい。PR-AUC を併記しないと「実は全然検知できていない」を見逃します。
- 「点異常の手法で文脈・集団異常を狙う」ミスマッチ。本ノートの手法は主に点異常向けです。時系列の文脈異常・系列の集団異常には、文脈変数を分けた設計や系列モデルが要ります(型を取り違えると、そもそも検知できません)。
対応するシミュレーション
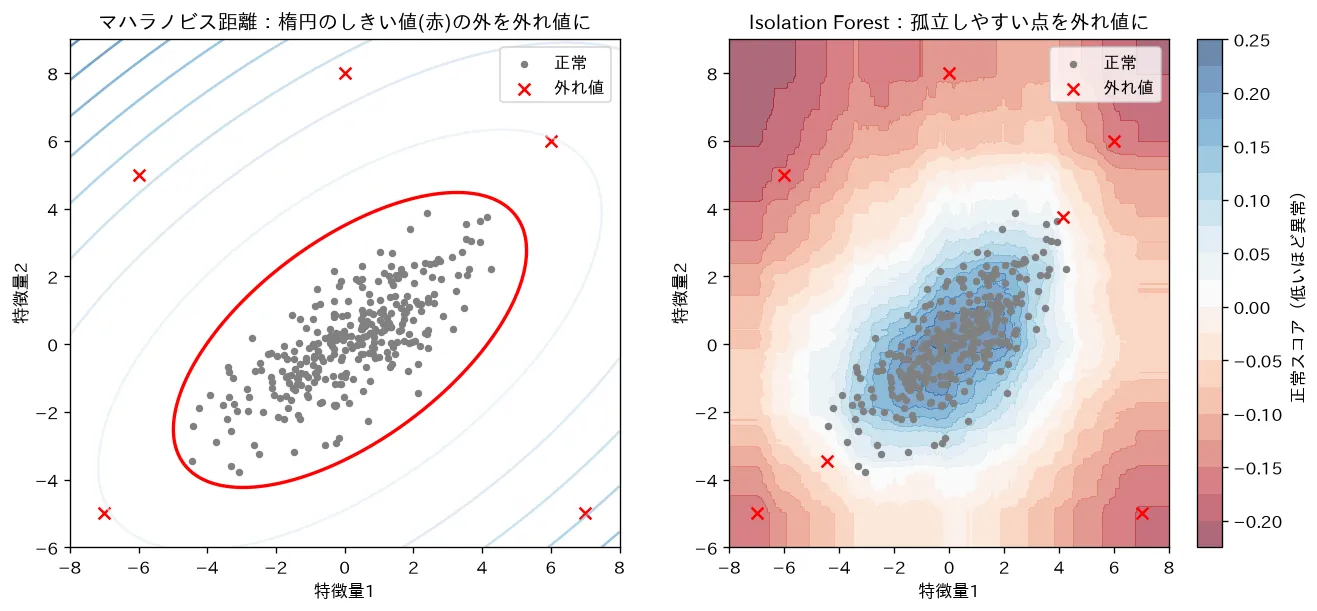
simulations/anomaly_detection.py:正常データの塊に少数の外れ値を混ぜ、(1) 分布を正規分布とみなし「平均からのマハラノビス距離の二乗」が のしきい値(97.5%点)を超える点を外れ値とする方法(楕円のしきい値)、(2) ランダムな分割で“少ない回数で孤立する”点を外れ値とする Isolation Forest を比べます。どちらも外れ値を検出できること、正規を仮定できるか否かで使い分けることを可視化します。
関連ノート
- 教師なし学習 目次
- 混合ガウスモデルとEM(密度・尤度ベースの土台。GMM の尤度で異常を測る)
- バギングとランダムフォレスト(Isolation Forest が使うランダムな木)
- サポートベクターマシン(SVM)(One-Class SVM の母体。マージン最大化を1クラス化)
- 評価指標(分類)とROC・AUC(不均衡下の評価:ROC-AUC と PR-AUC)
- 次元の呪い(高次元での距離・密度ベースの劣化)
- 多変量正規分布(統計:マハラノビス距離・カイ二乗・PCA の数理)
- 機械学習テキスト 全体目次