🎓 レベル:発展 | 重要度:A(必須)
📎 前提:k-meansクラスタリング(硬い割り当ての特殊例) | 数理:欠測データ・EMアルゴリズム(統計, EMの一般論)・多変量正規分布(統計)
要点(BLUF)
- 混合ガウスモデル(GMM)は、複数のガウス分布を混合係数 で重み付けして足した確率密度 です。「どの成分から生まれたか」という潜在変数 を導入することで、データを確率モデルとして素直に書けます。
- パラメータ の最尤推定は、対数尤度が「和の対数 」になって閉形式で解けません。そこで EMアルゴリズム(E:各点が各成分に属する確率=責任を計算 → M:責任で重み付けした最尤でパラメータ更新)を交互に回します。
- GMM は k-means の「柔らかい(確率的)」一般化です。共分散を と置いて にすると責任が 0/1 になり、EM がそのまま k-means(Lloyd 法)に一致します。
1. なぜ「柔らかい」クラスタリングなのか
k-meansクラスタリング は各点をただ1つのクラスタに硬く割り当てました。「この点はクラスタ2」と白黒つける。でも現実のデータでは、2つのクラスタの境界付近にある点を「どちらか一方」と決めつけるのは無理があります。
GMM は「点 は成分1に確率 0.7、成分2に確率 0.3 で属する」という確率的な所属(ソフトアサインメント)を許します。さらに k-means が暗黙に「等方的で同じ大きさの球状クラスタ」しか表せないのに対し、GMM は各成分が自前の共分散 を持つので、楕円形・向き・大きさの異なるクラスタを表現できます。
graph LR
KM["k-means<br/>硬い割り当て・球状・等サイズ"] -->|"確率的所属を許す"| Soft["ソフトアサインメント"]
KM -->|"成分ごとに共分散 Σ_k"| Shape["楕円・任意の向き・サイズ"]
Soft --> GMM["混合ガウスモデル + EM"]
Shape --> GMM
GMM -.->|"Σ_k = εI, ε → 0 の極限"| KM
要するに:GMM は k-means に「所属の確率」と「クラスタの形」という2つの自由度を足したものです。そして後で見るように、自由度を削っていくと k-means に戻ります(双方向の矢印が本質)。
2. モデル定義:ガウス分布の重み付き和
GMM はデータの密度を 個のガウス分布の凸結合で表します:
ここで は平均 ・共分散 の多変量正規分布(→ 多変量正規分布)、 は **混合係数(mixing coefficient)**で、次の制約を満たします:
要するに: は「成分 が全体に占める割合(重み)」です。確率の公理(非負・総和1)を満たすので、 自体を確率分布として読めます。 は単峰ではなく、 個の山を持つ多峰の密度を表現できます。
なぜ「凸結合なら密度になるか」も確認しておきます。各 で積分すると 1 なので、
となり、 はちゃんと正規化された確率密度になっています。
3. 潜在変数 の導入と完全データ尤度
GMM の核心は、「この点はどの成分から生成されたか」を表す潜在変数 を導入することです。 は 次元の one-hot ベクトルで、点が成分 から生まれたなら 、他は 0 とします(、これを 1-of-K 表現と呼びます)。
潜在変数の確率を、混合係数そのものとして定めます:
成分が に決まったときの の条件付き分布は、その成分のガウスです:
これで の周辺分布を計算すると、潜在変数を「足して消す(周辺化)」ことで元の GMM が再現されます:
要するに:GMM は「まず確率 でサイコロを振って成分 を選び、選んだガウスから を1点サンプルする」という二段階の生成過程です。 はそのサイコロの目で、観測できない(=潜在)。 を周辺化すると最初の混合密度に戻ります。
graph TB
Pi["混合係数 π で成分を選ぶ<br/>p(z_k=1)= π_k"] --> Comp["選ばれた成分 k のガウス<br/>N(x | μ_k, Σ_k)"]
Comp --> X["観測データ点 x を生成"]
Pi -.->|"z は観測できない潜在変数"| Hidden["どの成分か(サイコロの目)は隠れている"]
完全データ尤度
もし潜在変数 まで観測できたとすると(=完全データ )、その同時尤度は簡単な積の形になります:
対数を取ると、 が「選択スイッチ」として効いて、和の対数が消えて対数の和になります:
要するに: さえ分かれば、各点がどの成分のものか確定するので、成分ごとに普通のガウスの最尤推定をするだけ(標本平均・標本共分散を計算するだけ)で済みます。問題は が観測できないこと。ここが次節の動機です。
4. なぜ直接の最尤が難しいか:和の対数の壁
潜在変数を周辺化した観測データの対数尤度は、こうなります:
完全データ尤度(前節)と見比べてください。 の中に が入っているのが致命的です。対数が和の外に出せないので、 と指数(ガウス)が打ち消し合ってくれません。
で微分して 0 と置くと、
となり、 の解の中に「 を含む比(後で責任と呼ぶもの)」が入り込んでしまいます。 について解こうとすると右辺にまた が出てくるので、閉形式で解けません。 も同様です。
graph TB
Direct["観測データの対数尤度<br/>Σ_n log 「 Σ_k π_k N(...) 」"] -->|"log の中に Σ_k"| Stuck["対数が和を貫通できない"]
Stuck -->|"∂/∂μ_k = 0 を解くと"| Self["解の中に解自身が現れる<br/>(不動点方程式)"]
Self -->|"閉形式で解けない"| EM["反復で解く<br/>= EM アルゴリズム"]
要するに:完全データなら一発で解けるのに、潜在変数が見えないせいで「和の対数」が現れ、方程式が**自己参照(不動点)**になってしまう。これを「 を確率的に補い、補った状態で最尤、を交互に繰り返す」ことで突破するのが EM です。
5. EMアルゴリズム:E-step と M-step
EM(Expectation–Maximization)は、上の不動点方程式を交互更新で解きます。直観はシンプルです:
- E-step:今のパラメータを使って「各点が各成分に属する確率(責任)」を計算する。=潜在変数 を期待値で埋める。
- M-step:その責任を「ソフトなラベル」とみなして、成分ごとに重み付き最尤でパラメータを更新する。
これを対数尤度が収束するまで繰り返します。
flowchart TB
Init["初期化:π_k, μ_k, Σ_k を設定<br/>(k-means の結果で初期化することが多い)"] --> Estep
Estep["【E-step】各点の責任を計算<br/>γ(z_nk)= π_k N(x_n | μ_k, Σ_k) / Σ_j π_j N(x_n | μ_j, Σ_j)"] --> Mstep
Mstep["【M-step】責任で重み付けして更新<br/>N_k = Σ_n γ(z_nk)<br/>μ_k, Σ_k, π_k を再計算"] --> Eval
Eval["対数尤度 log p(X | θ)を評価"] --> Check{"収束した ?<br/>(尤度の増分が閾値以下)"}
Check -->|"No"| Estep
Check -->|"Yes"| Done["パラメータ確定・各点はソフトに所属"]
E-step:責任 の導出(事後確率=ベイズ)
責任(responsibility) は「点 を見たとき、それが成分 から生成された事後確率」です。ベイズの定理で素直に出ます:
分子は「事前 × 尤度 」、分母は全成分にわたる正規化(=ちょうど )です。
要するに:責任は「事前の割合 と、その成分から がどれだけありそうか を掛け、全成分で正規化した割合」です。 が成分 の中心に近く、かつ が大きいほど責任は大きくなる。 は で、 について足すと 1()になります。これが k-means の「最も近い1つに割り当て」を確率に緩めたものです。
なぜ「E-step」と呼ぶか:完全データ対数尤度(第3節)に出てくる を、現在のパラメータのもとでの条件付き期待値 で置き換えているからです。one-hot の期待値はちょうど事後確率になります。EM の一般形ではこの期待値で作る関数 (期待完全データ対数尤度)を最大化します。一般論の詳細は 欠測データ・EMアルゴリズム(統計)へ。
M-step:パラメータ更新の導出(責任で重み付けした最尤)
M-step は、E-step で求めた責任 を固定した定数とみなして、期待完全データ対数尤度
を について最大化します。 が定数なので、今度は和の対数の壁がない(各 が外に出ている)ことに注目してください。ここが EM の妙です。各パラメータについて偏微分して 0 と置きます。
まず便宜のため、成分 の 実効データ数(ソフトな所属数) を定義します:
平均 : の 微分は なので、
要するに:新しい平均は「責任で重み付けしたデータの平均」。k-means が「割り当てられた点の単純平均」だったのが、重みが 0/1 から の連続値に変わっただけです。
共分散 : を (あるいは精度行列 )で微分して 0 と置くと、標本共分散の重み付き版が出ます:
要するに:各点の外積 を責任で重み付けして平均したもの。これも k-means にはない「クラスタの広がり・向き」を担う部分です。
混合係数 : には という制約があるので、ラグランジュ未定乗数 を導入して
を で微分します。 の 依存部分は なので、
両辺を で足し、 と を使うと 、よって
要するに:新しい混合係数は「成分 のソフトな所属数を全体で割った割合」。ラグランジュ乗数は「総和1」という確率の制約を効かせるために必要で、解いてみると という綺麗な値になります。
| パラメータ | 更新式 | k-means での対応 |
|---|---|---|
| 平均 | クラスタ重心(割り当て点の平均) | |
| 共分散 | (なし。k-means は 固定) | |
| 混合係数 | (なし。等重みと等価) |
EM は対数尤度を単調増加させる(収束)
EM の最も重要な性質は、E→M の1サイクルごとに観測データの対数尤度 が必ず増加(少なくとも非減少)することです:
直観はこうです。EM は対数尤度そのものを直接上げる代わりに、下界(ELBO)を構成して、E-step でその下界を現在の点で対数尤度に接するよう持ち上げ、M-step で下界を最大化する、という二段で動きます。下界を上げれば、それを上回る本物の対数尤度も必ず上がる、という仕組みです。
この「下界が単調に上がるから本体も上がる」という一般論の完全証明(ELBO の構成・Jensen の不等式・KL 項が消えること)は 欠測データ・EMアルゴリズム(統計)に譲ります。本ノートでは「GMM の E/M 更新が、その一般論の具体例になっている」と理解すれば十分です。
⚠️ 注意:単調増加が保証するのは局所最適への収束だけです。GMM の対数尤度は多峰(複数の山)なので、初期値次第で別の局所解に落ちます。だから複数の初期値で回して最良を選ぶ、k-means で初期化する、といった工夫が要ります。
6. k-means との関係: で
GMM が k-means の一般化であることを、数式で確かめます。すべての成分の共分散を 共通の等方行列 に固定し( も等しいとする)、 を 0 に近づけます。
ガウスの指数部だけ見ると、 です。これを責任の式に代入すると、
これは 温度 の softmax です。(温度を下げる)と、分母は最も近い中心( が最小の )の項だけが指数的に支配的になり、
責任が 0/1 にスナップします。これはまさに k-means の「最も近い重心へ硬く割り当て」です。すると M-step の 更新は責任が 0/1 なので「割り当てられた点の単純平均」になり、Lloyd 法の重心更新に一致します。
graph TB
GMM["GMM + EM<br/>責任 γ は 0〜1 の連続値(ソフト)"] -->|"Σ_k = εI に固定"| Iso["等方・共通分散に制約"]
Iso -->|"ε → 0(温度を下げる)"| Hard["責任が 0/1 にスナップ<br/>= 最近傍への硬い割り当て"]
Hard -->|"M-step が単純平均に"| Lloyd["k-means(Lloyd 法)"]
要するに:k-means は「GMM を等方・等分散・ゼロ温度に絞った極限」です。E-step が「最近傍割り当て」、M-step が「重心更新」に化けます。逆に言えば GMM は、k-means に「楕円の形()・成分の重み()・確率的所属(有限の )」を解放した一般化です。 は統計力学でいう温度で、EM はその意味で k-means の「焼きなまし版」とも読めます。
7. 共分散の型と自由度
各成分が持つ共分散 をどこまで自由にするかで、表現力とパラメータ数(過学習しやすさ)が変わります。実務ではこの「型」を選ぶのが重要なチューニングです。
| 共分散の型 | の形 | クラスタの形 | 1成分あたりの共分散パラメータ数( 次元) |
|---|---|---|---|
| 球状(spherical) | 等方の球 | ||
| 対角(diagonal) | 軸に平行な楕円 | ||
| フル(full) | 任意の対称正定値行列 | 任意の向きの楕円 | |
| 共有(tied) | 全成分で同じ | 同じ形の楕円が並ぶ | (全体で1つ) |
要するに:球状 → 対角 → フル の順に表現力が上がりますが、パラメータ数も増えて過学習・特異点のリスクが上がります。データが少ない・次元が高いときは対角や球状に落とすのが安全。フルは向きの傾いた楕円まで表せる代わりに のパラメータを抱えます。
なお、GMM 全体の自由パラメータ数は次節のモデル選択で使うので押さえておきます(フル共分散・ 成分・ 次元の場合):
8. 特異点問題:尤度が無限大に発散する病理
GMM の最尤推定には深刻な病理があります。フル(または対角)共分散を許すと、対数尤度が上に有界でなく、無限大に発散しうるのです。
シナリオはこうです。ある成分 の平均 が、たまたま1つのデータ点 とぴったり一致したとします()。このとき、その成分の共分散を として に縮めると、その点での密度は
と発散します(正規化定数の が爆発)。つまり1つの成分が1点に潰れて、その点に無限の確率密度を載せると、対数尤度がいくらでも大きくなってしまう。これが特異点(singularity)問題です。
graph TB
Sing["ある成分が1点に潰れる<br/>μ_k = x_n, σ_k → 0"] -->|"密度 1/σ_k^d → ∞"| Div["その点の尤度が発散"]
Div -->|"対数尤度が上に有界でない"| Bad["最尤解が壊れる<br/>(意味のない退化解)"]
Bad --> Fix["対処:共分散に下限・正則化・<br/>事前分布(MAP/ベイズ)・型の制約"]
要するに:最尤を素朴に追うと、「クラスタ」ではなく「1点に張り付いた針のような成分」へ逃げる退化解が存在します。k-means にはこの病理がありません( を持たないので密度が発散しない)。GMM 特有の落とし穴です。
主な対処:
- 共分散に下限を設ける: の対角に小さな値 を足す(正則化/分散フロア)。scikit-learn の
reg_covarがこれ。 - MAP 推定/ベイズ化: に逆ウィシャート事前を置くと、対数尤度に「共分散が小さすぎると罰する項( ペナルティ)」が加わり、潰れが防げます。変分ベイズ GMM はこの発想です。
- 型を制約する:球状・対角・tied にすると自由度が減り、特異点に落ちにくくなります。
- 潰れた成分のリセット:実装上、 が極端に小さくなった成分を再初期化する。
- 複数初期値で回し、退化解を捨てて妥当な解を選ぶ。
9. モデル選択:成分数 をどう決めるか
(成分数)はデータからは自動で決まりません。 を増やすほど対数尤度は単調に上がる(複雑なモデルほどデータに合う)ので、対数尤度だけで を選ぶと際限なく増えてしまう。そこで「適合度」と「複雑さの罰則」をバランスさせる情報量規準を使います。
ここで は最尤での対数尤度、 は自由パラメータ数(第7節の式)、 はサンプル数です。どちらも小さいほど良いモデルです。候補 (と共分散の型)で GMM を当てはめ、AIC/BIC が最小の組み合わせを選びます。
要するに:第1項 は「データへの当てはまり(小さいほど良い)」、第2項は「パラメータ数のペナルティ」。 を増やすと は上がる(第1項は下がる)が、 も増える(第2項は上がる)。両者が釣り合う が選ばれます。
- BIC はペナルティ係数が で、 が大きいほど複雑なモデルを強く罰します。**真のモデルを当てる(一致性がある)**性質があり、「いくつの成分か」を知りたいときはこちらが定番。
- AIC はペナルティが で固定。予測性能重視のときに使われますが、成分数を過大に選びがちです。
- 交差検証でホールドアウトの対数尤度を直接比べる方法もあります(情報量規準の近似に頼らない代わりに計算コストが高い)。
xychart-beta
title "成分数 K と情報量規準(概念図・BIC が最小の K を選ぶ)"
x-axis "成分数 K" [1, 2, 3, 4, 5, 6]
y-axis "BIC(小さいほど良い)" 0 --> 100
line "BIC" [90, 55, 35, 38, 48, 62]
⚠️ よくある誤解・落とし穴
- 「責任は所属確率だから、最大の責任のクラスタに割り当てれば k-means と同じ」ではない。GMM の本質は責任をソフトな重みのまま M-step に使うことです。硬く割り当ててしまうと(=ハード EM/CEM)情報が落ち、k-means 寄りの別物になります。
- 「EM は対数尤度を最大化する(最適解に達する)」は言い過ぎ。EM が保証するのは単調増加と局所最適への収束だけです。対数尤度は多峰なので、初期値次第で劣った局所解に落ちます。複数初期値・k-means 初期化が定石です。
- 「フル共分散にすれば常に表現力が上がって得」ではない。フルは パラメータを抱え、データが足りないと**特異点(1点潰れ)**に落ちて尤度が発散します。次元が高い・データが少ないときは対角や球状、正則化(分散フロア)が必須です。
- 「 は 1 だから も 1」ではない。 について足すと 1 になるのは1つの点 の中での話です。 は点 にわたる和で、成分 の実効データ数(0〜)。混同しやすいので添字に注意。
- 「混合係数 は成分の確率だから、推定後にクラスタの大きさそのもの」ではない。 は事前の重みで、実際に各成分が抱えるソフトな点数は (推定後)。 が小さい成分は responsibilty が小さく、消えかかることもあります。
- 「GMM は k-means より常に良い」ではない。GMM は仮定(各クラスタがガウス)が合っているときに強いですが、合わないと逆効果。計算も重く、初期化・特異点・ 選択に敏感です。素早く頑健に欲しいときは k-means が依然有効です。
- 「AIC でも BIC でも同じ が選ばれる」ではない。AIC は成分数を過大評価しがちです。「いくつの成分か」を知りたいなら一致性のある BIC を基本にします。
対応するシミュレーション
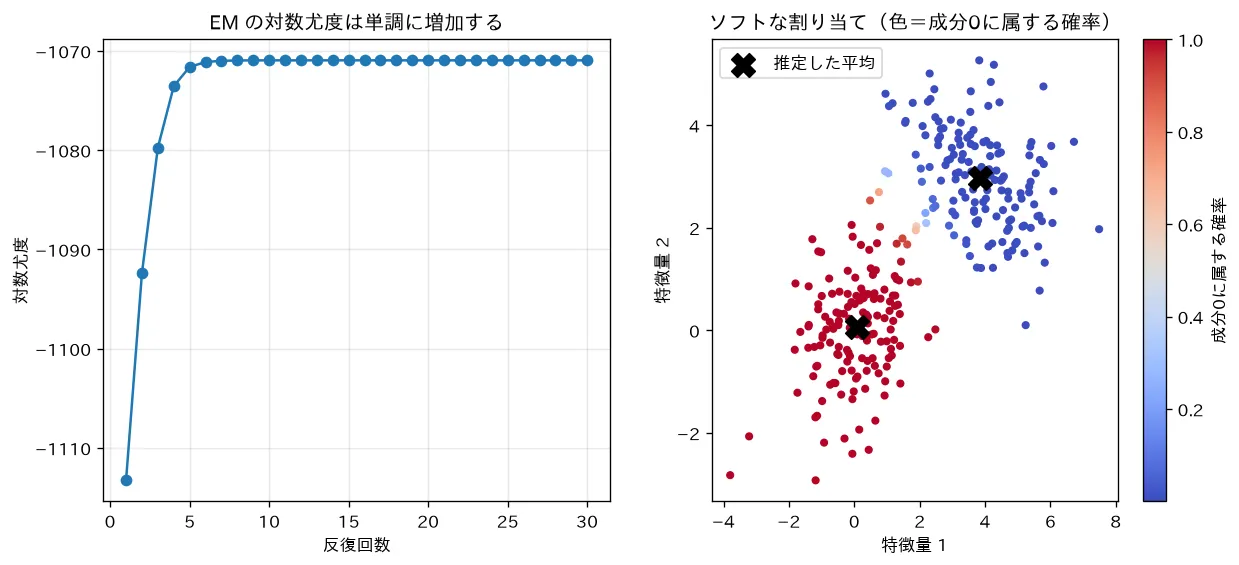
simulations/gmm_em.py:2つのガウス分布から生成したデータに EM を自前実装で適用します。E ステップ(責任の計算)と M ステップ( の更新)を繰り返すと、対数尤度が反復のたびに単調増加して収束する様子と、各点が確率的に(ソフトに)クラスタへ割り当てられる様子(境界付近の点ほど中間色になる)を可視化します。
関連ノート
- 教師なし学習 目次
- k-meansクラスタリング(GMM の硬い割り当ての特殊例。, で一致)
- 異常検知(GMM を密度推定に使い、低密度の点を異常とみなす密度ベース手法)
- 欠測データ・EMアルゴリズム(統計。EM の一般論・ELBO・Jensen 不等式・単調増加の証明)
- 多変量正規分布(統計。各成分の土台となる多変量正規分布)
- 生成モデル 目次(潜在変数モデルの発展。VAE は連続潜在変数版の確率的生成モデル)
- 機械学習テキスト 全体目次