🎓 レベル:基礎 | 重要度:A(必須)
📎 前提:次元の呪い | 数理:クラスター分析(統計)・分散共分散行列・相関行列(統計)
要点(BLUF)
- k-means は、ラベルなしのデータを k 個のクラスタに分け、各クラスタの**重心(平均ベクトル)**を代表点とする最も基本的な教師なし手法です。
- やっていることはただ一つ、クラスタ内平方和(SSE / inertia) の最小化。これを Lloyd アルゴリズム(割り当て↔更新の交互最適化)で解きます。
- 各ステップで は必ず減るので局所最適に収束しますが、大域最適は保証されません。初期値依存を抑える k-means++ と、k の選び方(エルボー法・シルエット)まで押さえれば実務で使えます。
概念:教師なしクラスタリングとは
教師あり学習(回帰・分類)は「入力 と正解ラベル のペア」から を学びました。教師なし学習には がありません。データ の構造そのものを見つけにいきます。
その代表がクラスタリング:似たデータを同じグループ(クラスタ)にまとめる作業です。「似ている」を距離が近いで定義し、近いものを束ねます。
k-means の直観はシンプルです。
- データを k 個のグループに分ける。
- 各グループの「中心」を、その中の点の平均で定める。
- 「各点は一番近い中心のグループに属するべき」「中心は所属点の平均であるべき」という2条件が両立する状態を探す。
この2条件は最初は矛盾します(中心を決めると所属が変わり、所属が変わると中心が動く)。だから交互に直しながら釣り合うまで回す——これが Lloyd アルゴリズムです。
定式化:何を最小化しているのか
データを 、クラスタ数を とします。求めたいものは2つ:
- 割り当て (各点がどのクラスタか。 の分割)
- 重心
最小化する目的関数(クラスタ内平方和、SSE / inertia と呼ぶ)は:
要するに:「各点から、自分の属するクラスタの中心までの距離(の2乗)を、全点ぶん足したもの」。これが小さいほど「各クラスタがギュッとまとまっている」。k-means はこれを最小化するだけの手法です。
ここで はユークリッドノルム。距離の 2乗を使うのが本質で、後で「重心=平均」が最適になる理由に効いてきます。
なお を最小にする割り当ては、組合せが指数的に多く( オーダー)、厳密な大域最適化は NP困難であることが知られています。だから現実には反復近似——Lloyd アルゴリズムを使います。
Lloydアルゴリズム:割り当て↔更新の交互最適化
Lloyd アルゴリズムは、 を「割り当て 」と「重心 」の2変数の関数とみなし、片方を固定してもう片方を最適化することを交互に繰り返します(座標降下法の一種)。
ステップ0(初期化):重心 を何らかの方法で置く(後述の k-means++ が定番)。
ステップA(割り当て):重心を固定し、各点を最も近い重心のクラスタに割り当てる。
要するに:中心が決まっているなら、各点は一番近い中心に付くのが を最小にする。これは点ごとに独立に決まる。
ステップB(更新):割り当てを固定し、各重心を所属点の平均に更新する。
要するに:所属が決まっているなら、中心は所属点の平均に置くのが を最小にする。
ステップAとBを、割り当てが変化しなくなるまで繰り返す。
flowchart TD
Init["初期化:重心 μ_1..μ_K を配置 (k-means++ 推奨)"] --> Assign
Assign["ステップA 割り当て:各点を最近傍の重心へ c_i = argmin_k ||x_i - μ_k||^2"] --> Update
Update["ステップB 更新:各重心をクラスタ平均へ μ_k = mean(C_k)"] --> Check{"割り当てが変化したか?"}
Check -->|"変化した (J はさらに減る)"| Assign
Check -->|"変化なし (収束)"| Done["停止:局所最適に到達"]
なぜ収束するのか(理論的裏付け)
ポイントは **「A も B も を増やさない」**ことです。
- ステップAで は増えない:各点 について、項 が最小になる を選んでいる。点ごとに最小化しているので、和である も減る(少なくとも増えない)。
- ステップBで は増えない:割り当てを固定すると は重心ごとに分離でき、 を について最小化する問題になる。これを で微分して 0 と置くと
つまり**「重心=クラスタ平均」は偶然ではなく、平方和を最小化する点が平均になる**から。これが距離の2乗を使う理由です(1乗=マンハッタン距離なら最適点は中央値になり、それが k-medians)。
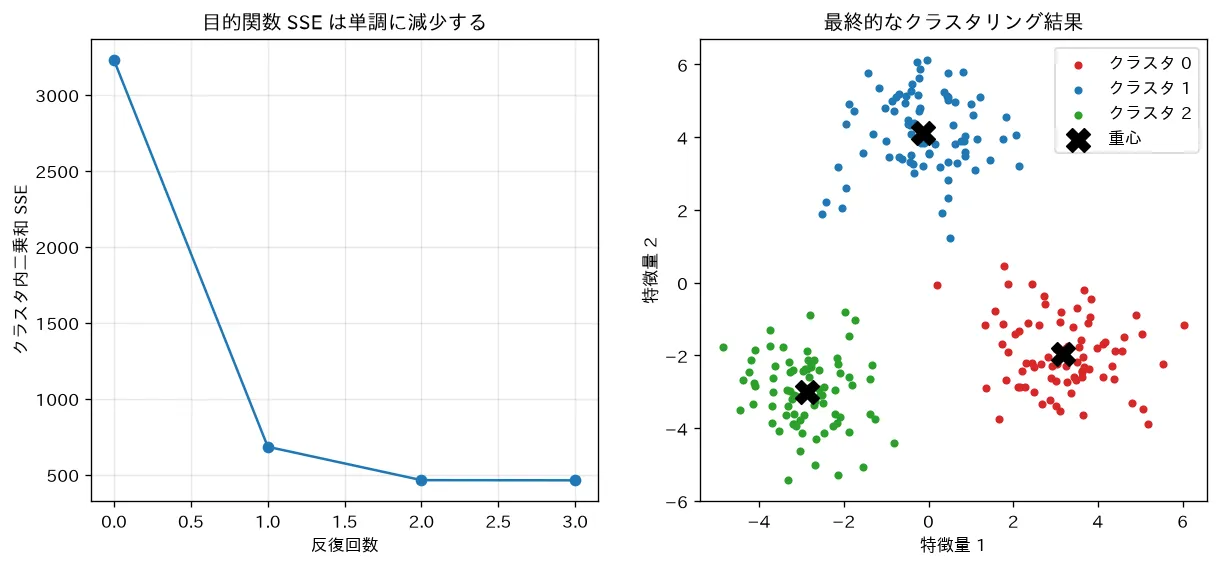
この2つから、反復のたびに は単調非増加。さらに (下に有界)で、割り当ての組合せは有限通りしかありません。単調減少する数列が同じ割り当てを2度取ることはないので、有限回で割り当てが固定して停止します。
要するに:「毎回必ず良くなる(悪くならない)」+「下限がある」+「状態は有限」だから、いつか必ず止まる。
ただし大域最適は保証されない
収束するのは局所最適であって、 を全分割の中で最小にする大域最適ではありません。座標降下は「今いる谷」を下るだけで、初期値が違えば違う谷に落ちます。だから初期化が決定的に重要になります。
初期値依存と k-means++
ランダムに初期重心を置くと、たまたま近い場所に重心が固まり、質の悪い局所解に落ちることがよくあります。素朴な対策は「複数回ランダムに試して が一番小さい結果を採用」(scikit-learn の n_init)。
より賢いのが k-means++(初期重心をわざと散らす確率的な選び方):
- 最初の重心 をデータ点から一様ランダムに1つ選ぶ。
- 残りの各点 について、既に選ばれた重心までの最短距離の2乗 を計算する。
- 次の重心を、確率 に比例して選ぶ(遠い点ほど選ばれやすい)。
- K 個選ぶまで 2〜3 を繰り返す。
要するに:「今ある中心から遠い点ほど、次の中心に選ばれやすくする」。結果として初期重心が空間に散らばり、悪い局所解を避けやすくなる。
理論的にも、k-means++ は得られる解の期待値が最適値の 倍以内に収まるという近似保証があり、素朴なランダム初期化に比べて結果が安定し収束も速くなることが多いです。実装上のデフォルト(scikit-learn の init="k-means++")になっています。
kの選び方
k-means は K を自分で決める必要があります(手法は K を教えてくれません)。代表的な決め方は2つ。
エルボー法
K を増やしながら、最適化後の (inertia)をプロットします。K を増やせば は必ず下がりますが(究極は各点が自分だけのクラスタで )、ある K を境に下がり方が鈍る「肘(elbow)」が現れます。その肘を K に選びます。
要するに:**「これ以上クラスタを増やしても説明力があまり増えない折れ目」**を K にする。ただし肘が曖昧なことも多く、主観が残ります。
シルエット係数
各点 について、
- =同じクラスタ内の他点との平均距離(小さいほど良い、まとまり)
- =最も近い別クラスタの点との平均距離(大きいほど良い、分離)
として、
要するに:**「自分のクラスタにどれだけしっくり来て、隣のクラスタからどれだけ離れているか」**の指標。 に近い=良い、=境界上、負=割り当てが疑わしい。
全点の平均シルエットが最大になる K を選びます。エルボーより定量的で、クラスタごとの質も見えるのが利点です。
暗黙の仮定と限界
k-means は「平均と球状のまとまり」を前提にしています。目的関数が等方ユークリッド距離の2乗である以上、避けられない前提があります。
- 球状・等方:各クラスタが**球状(どの方向にも同じ広がり)**だと仮定。細長い・曲がった形は苦手。
- 等サイズ・等密度:クラスタの大きさや密度が大きく違うと、大きいクラスタが小さいクラスタを飲み込みやすい。
- ユークリッド距離前提:距離の2乗で測るので、スケールの大きい特徴量が支配的になる。→ 事前の標準化がほぼ必須(分散共分散行列・相関行列)。
- 外れ値に弱い:平均は外れ値に引っ張られる(重心がズレる)。
- 凸クラスタしか作れない:決定境界は重心間の垂直二等分線(ボロノイ境界)になり、非凸な形は表現できない。
- K を与える必要:データから K は決まらない。
非球状・密度差・任意形状を扱いたいなら、密度ベースの DBSCAN や、形を共分散で表せる混合ガウス(次節)、つながりで切る階層的クラスタリングを検討します。
他手法との関係:GMM の「硬い割り当て」特殊例
k-means は 混合ガウスモデルとEM(GMM)の特別な場合として理解できます。これは丸暗記ではなく構造的な関係です。
GMM は各クラスタをガウス分布 とし、各点が各クラスタに属する確率(責任度)を EM で推定します(ソフトな割り当て)。ここで共分散を 等方かつ共通に固定し()、 とすると:
- E ステップの責任度は、最も近い重心に確率1・他は0へ収束(ソフト→ハード)。これが k-means の割り当てステップ。
- M ステップの 更新は、責任度で重み付けた平均=所属点の単純平均に一致。これが k-means の更新ステップ。
要するに:k-means =「クラスタはぜんぶ同じ大きさの球」「各点はどれか1つに100%所属」と決め打ちした GMM。逆に GMM は k-means を、確率と任意形状(共分散)に柔らかく一般化したもの。だから楕円・重なり・所属確率が欲しいなら GMM へ進みます。
両者が同じ EM 系の交互最適化(割り当て↔パラメータ更新)で、同じく局所最適にしか収束しないのも、この対応から納得できます。
⚠️ よくある誤解・落とし穴
- 「k-means は大域最適を出す」→ 誤り。 局所最適です。初期値で結果が変わるので、k-means++ + 複数回試行が前提。
- 「inertia()でクラスタの良さを比べられる」→ 注意。 は K を増やせば必ず下がるので、異なる K の比較には使えない(だからエルボー/シルエット)。
- 標準化を忘れる → 失敗の定番。 距離の2乗で測るため、単位の大きい特徴量だけでクラスタが決まる。前処理でスケールを揃える。
- 「クラスタは必ず意味を持つ」→ 違う。 ランダムなデータでも k-means は必ず K 個に割る。クラスタが構造を反映しているかは別途検証が要る(シルエット、可視化、ドメイン知識)。
- 形状の決め打ち:三日月形や同心円、密度の違う塊では破綻する。形が球でないと気づいたら DBSCAN / GMM / 階層型へ。
- 空クラスタ:割り当てステップで所属0のクラスタが出ることがある(実装側で再初期化などの対処が必要)。
対応するシミュレーション
simulations/kmeans_convergence.py:3つの塊データに Lloyd のアルゴリズムを自前実装で適用し、割り当てステップと更新ステップを繰り返します。目的関数 SSE(クラスタ内平方和)が反復のたびに単調減少して有限回で収束する様子と、最終的なクラスタリング結果を可視化します。さらに発展として、(1) 異なる初期値で と収束先が変わること、(2) エルボー/シルエットでの 選択、(3) 三日月形データでの破綻と DBSCAN、を追加する候補とします。
関連ノート
- 教師なし学習 目次
- 階層的クラスタリング
- 混合ガウスモデルとEM(柔らかい一般化)
- 次元の呪い
- クラスター分析(統計)
- 機械学習テキスト 全体目次