📊 対象級:準1級 | 重要度:B(標準)
要点(BLUF)
クラスター分析は正解ラベルを使わずに、似たデータ同士を自動でグループ(クラスター)にまとめる教師なし分類です。準1級では「階層的(デンドログラムを作る)と非階層的(k-means)の使い分け」「クラスター間距離の定義(特にウォード法)」「k-means が何を最小化して収束するのか」が問われます。中心となる2つの考え方はこれです。
要するに「階層的は併合のルールでグループの木を作る」「k-means は各クラスター内のバラつき(重心までの二乗距離の和)を一番小さくするように 個に分ける」ということです。
1. 教師なし分類とは(判別分析との違い)
最初に位置づけを固めます。クラスター分析は 教師なし学習(unsupervised learning) です。つまり「このデータはグループA」という正解ラベルが与えられていない状態で、データの構造だけからグループを発見します。
ここが 判別分析(教師あり)との決定的な違いです。両者は「データを群に分ける」点は似ていますが、入力が根本的に違います。
graph TD
D["分類したいデータ"] --> Q{"正解ラベルが<br/>あるか?"}
Q -- "ある(教師あり)" --> H["判別分析<br/>既知の群に新しい点を割り当てる<br/>境界を学習"]
Q -- "ない(教師なし)" --> C["クラスター分析<br/>群そのものをデータから発見する"]
| 観点 | クラスター分析(教師なし) | 判別分析(教師あり) |
|---|---|---|
| 正解ラベル | ない | ある(既知の群に属するサンプルで学習) |
| 目的 | 群を発見する | 新しい点を既知の群へ割り当てる |
| 評価 | 正解がないので「良さ」の定義が難しい | 誤判別率で評価できる |
| 代表手法 | 階層的法・k-means | 線形判別・マハラノビス距離による判別 |
要するに「正解を知っていて当てに行く」のが判別分析、「正解を知らずにグループを切り出す」のがクラスター分析です。
⚠️ 準1級の引っかけ頻出:「クラスター分析は教師あり学習である」は誤り。また「判別分析とクラスター分析は同じ」も誤り。両者を区別できるかが必ず問われます。
2. 距離・非類似度
クラスター分析の出発点は「2つのデータ点(または2つのクラスター)がどれだけ似ているか/離れているか」を測る 距離(distance)・非類似度(dissimilarity) です。距離の選び方で結果が変わるため、ここを理解するのが本質です。
2.1 主な距離尺度
次元の点 と について。
ユークリッド距離(最も標準)
要するに「定規でまっすぐ測った直線距離」です。
マンハッタン距離(L1 距離、市街地距離)
要するに「碁盤の目の道を縦横にだけ動いて測った距離」です。各座標の差の絶対値を足すので、外れ値の影響がユークリッド距離より小さくなります。
マハラノビス距離(相関・スケールを補正)
ここで は分散共分散行列です(分散共分散行列・相関行列 を参照)。 を挟むことで、各変数の分散の違い(スケール)と変数間の相関を同時に補正します。要するに「分散が大きい方向では距離を縮め、相関のある方向を立て直して、楕円状の広がりを真円に直してから測った距離」です。
理論的裏付け:もし (全変数が分散1・無相関)なら となり、マハラノビス距離はユークリッド距離に一致します。つまりマハラノビス距離はユークリッド距離を相関・分散で一般化したものです。この による正規化は判別分析(判別分析)でも中心的役割を果たします。
2.2 標準化の必要性
ユークリッド距離・マンハッタン距離は変数の単位(スケール)に強く依存します。たとえば「年収(円、桁が大きい)」と「年齢(歳、桁が小さい)」を一緒に使うと、年収の差だけで距離がほぼ決まってしまい、年齢は無視されます。
そこで各変数を 標準化(平均0・分散1に変換)してから距離を測るのが定石です。
要するに「単位の大きい変数に距離を支配されないよう、全変数を同じ土俵に揃える」ということです。マハラノビス距離は がこの標準化(と相関補正)を内蔵しているので、別途の標準化が不要、と理解できます。
⚠️ 「距離尺度を変える」「標準化するかしないか」でクラスタリング結果は変わります。これも頻出論点です。
3. 階層的クラスタリング
3.1 基本アルゴリズム(凝集型)
階層的クラスタリング(hierarchical clustering) は、似た者同士を1つずつ併合していき、最終的に全体が1つになるまでの過程を木構造に記録する手法です。最も普及しているのは下から積み上げる 凝集型(agglomerative) です。
flowchart TD
S["各データ点を<br/>1個のクラスターとする<br/>(n個のクラスター)"] --> L["全クラスター対の<br/>距離を計算"]
L --> M["最も近い<br/>2クラスターを併合"]
M --> U["併合後の新クラスターと<br/>残りの距離を更新"]
U --> Q{"クラスターが<br/>1個になった?"}
Q -- いいえ --> M
Q -- はい --> E["デンドログラム完成"]
ポイントは「点と点の距離は決まっても、クラスターとクラスターの距離をどう定義するか」が手法によって違うことです。この定義(連結法、linkage)の違いがクラスター分析の核心です。
3.2 クラスター間距離の定義(連結法)
クラスター と の距離 の定義を4つ挙げます。 は点間距離です。
最短距離法(単連結, single linkage)
要するに「2つのクラスターの中で一番近いペアの距離をクラスター間距離とする」。鎖状に細長く伸びたクラスターを作りやすく(鎖効果、chaining)、外れ値に弱いです。
最長距離法(完全連結, complete linkage)
要するに「一番遠いペアの距離を採用する」。コンパクトで球状のクラスターを作りやすい一方、外れ値の影響を受けます。
群平均法(group average, UPGMA)
要するに「全ペアの距離の平均を採用する」。最短・最長の中間的な性質で、バランスの良い結果になりやすいです。
ウォード法(Ward’s method)
ウォード法だけは距離の min/max/平均ではなく、併合によってクラスター内のバラつき(平方和)がどれだけ増えるかで測ります。クラスター の内部平方和(重心 までの二乗距離の和)を
と定義すると、 と を併合するときのウォード距離は
すなわち「併合で増えるクラスター内平方和」です。要するに「合体させたときに一番バラつきが増えにくい=一番まとまりを崩さないペアから併合していく」ということです。これは整理すると
とも書けます(重心間距離をクラスターサイズで重み付けした形)。ウォード法はコンパクトで同程度の大きさのクラスターを作りやすく、実務で最もよく使われます。
| 連結法 | クラスター間距離 | 特徴 |
|---|---|---|
| 最短距離法(単連結) | 最も近いペア | 鎖状になりやすい・外れ値に弱い |
| 最長距離法(完全連結) | 最も遠いペア | 球状でコンパクト・外れ値の影響大 |
| 群平均法 | 全ペアの平均 | バランス型・中間的 |
| ウォード法 | 内部平方和の増加 | コンパクト・最も普及 |
3.3 デンドログラム
階層的クラスタリングの結果は デンドログラム(樹形図、dendrogram) という木で表します。縦軸が「併合したときの距離(高さ)」、葉が個々のデータです。任意の高さで横線を引いて切ると、その時点でのクラスター分割が得られます。
要するに「どこで木を切るかでクラスター数を後から自由に決められる」のが階層的法の強みです。事前にクラスター数を決めなくてよいので、構造が未知の探索的分析に向きます。
3.4 Lance-Williams の漸化式(距離更新の効率化)
毎回すべてのペアの距離を測り直すのは大変です。実は最短・最長・群平均・ウォードの主要な連結法は、併合後の新クラスターと既存クラスターの距離を、併合前の距離から定数時間で更新できる漸化式にまとめられます。これが Lance-Williams の更新式 です。
クラスター を併合して を作ったとき、別のクラスター との距離は
という形で書け、係数 を変えるだけで各連結法を表現できます。
| 連結法 | ||||
|---|---|---|---|---|
| 最短距離法 | ||||
| 最長距離法 | ||||
| 群平均法 | ||||
| ウォード法 |
( などはクラスターのサイズ。距離はウォード法では平方距離ベースで扱う。)
要するに「点間距離さえ最初に計算しておけば、あとは元の数値を取り出して足し引きするだけで併合のたびにクラスター間距離を更新できる」という効率化の枠組みです。準1級では係数を丸暗記する必要はありませんが、「主要な連結法が1本の漸化式で統一的に書ける」という事実と、 の符号で min()と max()が切り替わる仕組みは押さえておくと理解が深まります。
4. 非階層的クラスタリング(k-means)
4.1 目的関数
k-means 法(k平均法) は、あらかじめ決めた クラスター数 に、各クラスター内のバラつきが最小になるようデータを分割する非階層的手法です。最小化する目的関数は クラスター内平方和(within-cluster sum of squares, WCSS) です。
ここで は第 クラスター、 はそのクラスターの重心(平均ベクトル)です。要するに「各点から、自分が属するクラスターの中心までの二乗距離を全部足したもの」を最小化します。この は SSE(sum of squared errors)や inertia とも呼ばれます。
4.2 アルゴリズム(割当 → 重心更新の反復)
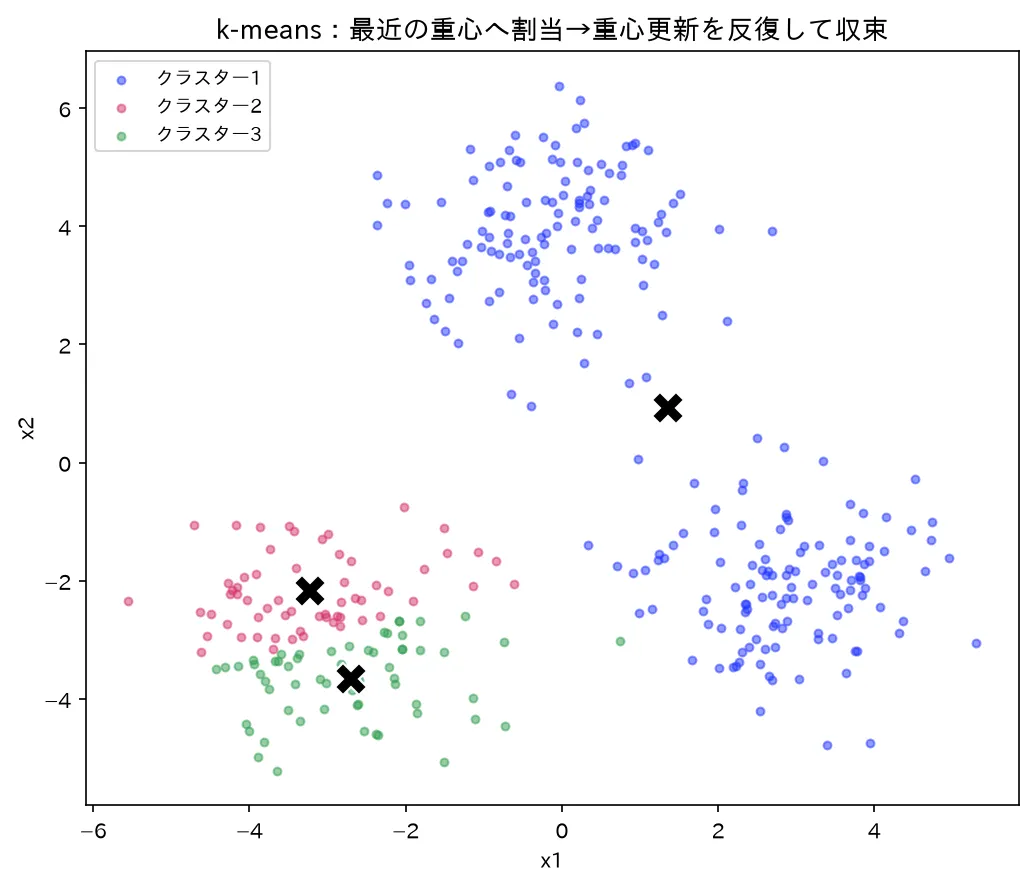
k-means の結果(色=クラスター、×=重心)。各点を最近の重心へ割当→重心更新を反復し、クラスター内平方和を下げて収束する。図は simulations/kmeans_cluster_keijou.py で生成。
flowchart TD
S["クラスター数 k を決める"] --> I["初期の重心 μ₁..μ_k を<br/>適当に置く"]
I --> A["【割当ステップ】<br/>各点を最も近い重心の<br/>クラスターに割り当てる"]
A --> U["【更新ステップ】<br/>各クラスターの重心を<br/>所属点の平均に更新する"]
U --> Q{"割当が<br/>変化したか?"}
Q -- "変化あり" --> A
Q -- "変化なし" --> E["収束・終了"]
2つのステップを交互に繰り返します(Lloyd のアルゴリズム)。
- 割当ステップ:重心 を固定し、各点を最も近い重心のクラスターへ割り当てる。
- 更新ステップ:割当を固定し、各クラスターの重心を所属点の平均に更新する。。
4.3 なぜ収束するのか(目的関数の単調減少)
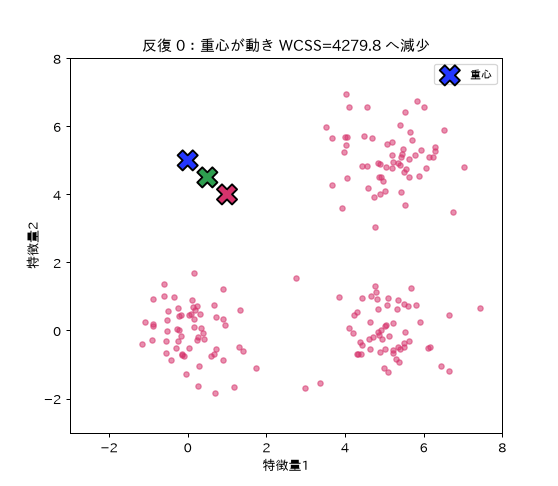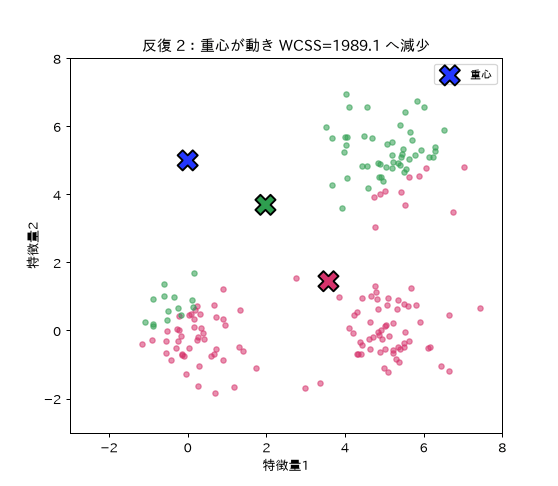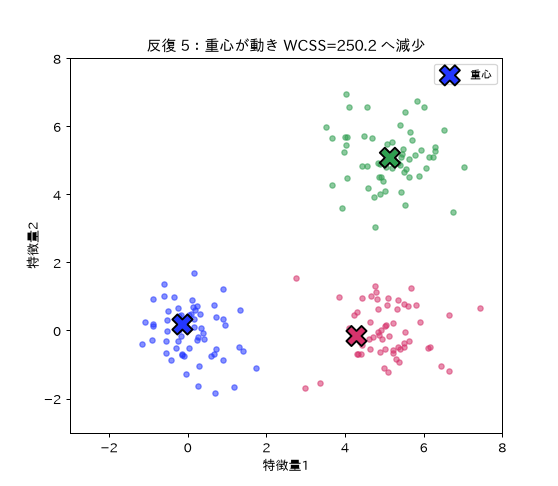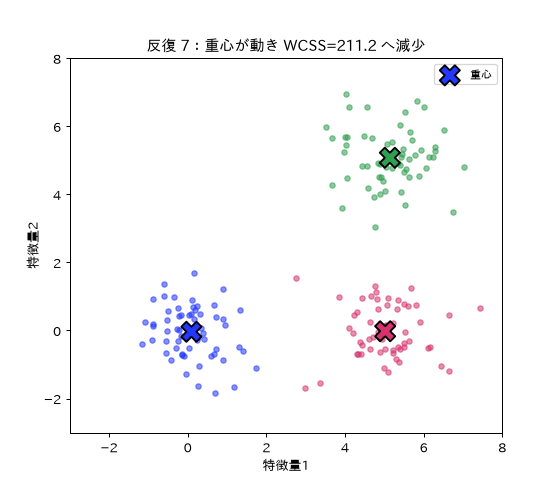
図(アニメ)は simulations/kmeans_iter_anim.py で生成。重心(×)が移動し点の色分け(所属クラスター)が変わりながら、クラスター内平方和(WCSS)が反復ごとに必ず下がって収束する様子を動きで示す。
k-means が必ず止まる理由は、**2つのステップがどちらも目的関数 を増やさない(単調減少させる)**からです。理論的裏付けを示します。
割当ステップで は減るか同じ。 各点を「最も近い重心」へ割り当てるのですから、その点が に寄与する は、どの重心に付けるかの選択肢の中で最小値を選んでいることになります。だから は増えません。
更新ステップで は減るか同じ。 割当を固定したとき、クラスター内平方和 を最小化する点 は、微分してゼロと置くと
すなわち 重心(平均)がクラスター内平方和を最小にする点です。だから重心へ更新すると は増えません。
要するに「割当も重心更新も、どちらも を悪くしない方向にしか動かない」ので、 は単調に減少します。 で下に有界、かつ点の割当パターンは有限通り( 通り以下)なので、有限回で必ず収束します。
⚠️ ただし収束するのは 局所最適(local minimum) であって、大域最適は保証されません。実際、一般の と次元で最適な k-means 分割を求める問題は NP困難です。
4.4 初期値依存への対処
局所最適に落ちる以上、初期重心の置き方で結果が変わります(初期値依存)。対策は2つ。
- 複数の初期値で実行し、 が最小の解を採用する。
- k-means++:初期重心を互いに離れるように確率的に選ぶ改良。質の良い初期化で局所最適のリスクを下げます。
5. クラスター数の決定
階層的法はデンドログラムを切る高さで、k-means は を事前に決める必要があります。「最適なクラスター数」を決める代表的な目安を挙げます(基準値・推奨は文献により異なるため要最新確認)。
エルボー法(Elbow method)
クラスター数 を増やしながらクラスター内平方和 をプロットします。 を増やせば は必ず下がりますが、ある を境に**下がり方が急に緩やかになる「肘(elbow)」**が現れます。その肘の を採用します。要するに「これ以上クラスターを増やしても改善が乏しくなる折れ目」を探します。
シルエット係数(silhouette)
各点について「自分のクラスター内の平均距離 」と「最も近い他クラスターまでの平均距離 」から
を計算します。 が1に近いほど「自分のクラスターにしっかり収まり、他クラスターから離れている」良いクラスタリングです。全点の平均シルエットが最大になる を選びます。
ギャップ統計量(gap statistic) など他の基準もあります。要するに「クラスター内のまとまり具合を数値化して、最もよい を選ぶ」という発想です。いずれも唯一の正解を与えるものではなく、複数の基準とドメイン知識を併用するのが実務です。
6. 試験での問われ方(準1級)
クラスター分析は多変量解析の標準トピックとして出題されます。準1級では次の角度で問われます。
- 教師あり/なしの区別:クラスター分析が教師なし、判別分析が教師ありであること。両者の混同を突く(判別分析 と対比)。
- 連結法の性質:最短距離法は鎖状、最長距離法は球状、ウォード法はコンパクト——どの手法がどんなクラスターを作るか。ウォード法がクラスター内平方和の増加最小であること。
- k-means の目的関数と収束:何(WCSS)を最小化するか、割当と更新で単調減少して収束するが局所最適・初期値依存であること。
- 距離尺度と標準化:ユークリッド/マンハッタン/マハラノビス( で正規化)の違い、標準化の必要性。
- デンドログラムの読み取り:併合の順序や、ある高さで切ったときのクラスター数。
主成分分析による次元削減(主成分分析(PCA))と組み合わせて「前処理してからクラスタリング」という文脈で出ることもあります。各ドメインの全体像は 多変量解析(Phase 6 目次) を参照してください。
よくある疑問(Q&A)
Q1. クラスター分析と判別分析は何が違うのですか?どちらも群に分けますよね。
決定的な違いは正解ラベルの有無です。判別分析は「群A・群Bに属するサンプル」という正解付きデータで学習し、新しい点をどちらの群に割り当てるかを当てる教師あり手法です。クラスター分析は正解ラベルがない状態で、データの構造だけから群そのものを発見する教師なし手法です。要するに「答えを知って当てに行く」のが判別分析、「答えを知らずにグループを切り出す」のがクラスター分析。準1級ではこの区別がそのまま選択肢になります。
Q2. 階層的クラスタリングと k-means、どちらを使えばよいですか?
データ量と目的次第です。階層的法は事前にクラスター数を決めなくてよく、デンドログラムで構造を可視化できるので、データが少なく・構造を探索したいときに向きます。ただし全ペアの距離を扱うため計算量が大きく、大規模データには不利です。k-meansは事前に を決める必要がありますが計算が速く、大規模データに向きます。要するに「探索的に木を見たいなら階層的、件数が多くて速さが要るなら k-means」が目安です。
Q3. k-means は実行するたびに結果が変わります。バグですか?
バグではなく仕様です。k-means は初期重心の置き方に依存し、収束先は局所最適であって大域最適は保証されません。初期値が違えば違う局所最適に落ちるので結果が変わります。対策は「複数の初期値で回して目的関数 が最小の解を選ぶ」か「k-means++ で初期化する」ことです。要するに「ランダムな初期化+局所最適」という性質上、再現性を持たせたいなら初期値を固定するか複数試行から最良を選びます。
Q4. 距離は何を使っても同じですか?標準化は必要ですか?
同じではありません。距離尺度を変えるとクラスタリング結果は変わります。特にユークリッド距離・マンハッタン距離は変数の単位(スケール)に依存するため、桁の大きい変数(例:年収)が距離を支配し、桁の小さい変数(例:年齢)が無視されます。これを避けるため、通常は各変数を標準化(平均0・分散1)してから距離を測ります。変数間の相関も補正したいならマハラノビス距離( で正規化)を使います。要するに「単位の違いに結果を振り回されないよう、標準化または相関補正が必要」です。
Q5. ウォード法は「距離」と言われますが、最短距離法のように点同士の距離を測っていないのはなぜですか?
ウォード法のクラスター間「距離」は、点間距離の min/max/平均ではなく、2つのクラスターを併合したときに増えるクラスター内平方和 で定義されるからです。発想が違うのです。「合体させたときに**一番まとまりが崩れない(バラつきの増加が小さい)**ペアから併合する」という基準なので、結果的にコンパクトで同程度の大きさのクラスターができます。要するにウォード法の「距離」は幾何的な隔たりではなく「併合コスト(分散の増加量)」だと理解すると腑に落ちます。
まとめ
- クラスター分析は教師なし分類(正解ラベルなしで群を発見)。正解ラベルで学習して割り当てる判別分析(教師あり)とは別物。
- 距離尺度:ユークリッド・マンハッタン・マハラノビス( で相関・スケールを補正)。ユークリッド系は単位に依存するので標準化が要る。
- 階層的法は似た者同士を逐次併合してデンドログラムを作る。連結法は最短(鎖状)・最長(球状)・群平均(中間)・ウォード(内部平方和の増加最小・最も普及)。主要な連結法は Lance-Williams の漸化式で統一的に距離更新できる。
- k-means はクラスター内平方和 を最小化。割当と重心更新を反復し、両ステップが を単調減少させるので有限回で収束するが、局所最適・初期値依存(大域最適は保証されない)。
- クラスター数はエルボー法・シルエットなどで決める(基準は要最新確認)。
- 引っかけ:教師あり/なしの混同、k-means の局所最適性、距離尺度・標準化で結果が変わること。
関連ノート
- 判別分析 正解ラベルありで群へ割り当てる教師あり手法。クラスター分析と対をなす
- 分散共分散行列・相関行列 マハラノビス距離の の土台
- 主成分分析(PCA) 次元削減。クラスタリングの前処理に併用される教師なし手法
- 多変量解析(Phase 6 目次) 多変量解析ドメインの全体像