📊 対象級:準1級 | 重要度:B(標準)
要点(BLUF)
判別分析は「群(クラス)があらかじめ分かっているデータから判別ルールを学習し、新しいデータをどの群に属するか分類する」教師ありの手法です。準1級では「マハラノビス距離による分類」「Fisherの線形判別の導出(群間変動と群内変動の比の最大化)」「ベイズ判別から LDA・QDA がどう出てくるか」が問われます。中心となる距離はこの一行に集約されます。
要するに「群の中心からの距離を、その群のばらつき(共分散)で割り引いて測り、一番近い群に割り当てる」ということです。
0. 問題設定:判別分析とは何か
個の群(クラス) があり、どのデータがどの群に属するか分かっている学習データが与えられているとします。判別分析の目的は、この学習データから判別ルール(判別関数)を作り、群が未知の新しい観測 を適切な群に割り当てることです。
ここで決定的に重要なのが「群が既知」という点です。これが**教師あり(supervised)**学習であることを意味します。群が未知のままデータをグループ化する手法は別物(クラスター分析)であり、混同が頻出の引っかけです(クラスター分析、後述の ⚠️ 節)。
graph LR
subgraph 判別分析["判別分析(教師あり)"]
A["学習データ<br/>群ラベルが既知"] --> B["判別ルールを学習"]
B --> C["新しいデータ x を<br/>既知の群へ分類"]
end
subgraph クラスター分析["クラスター分析(教師なし)"]
D["ラベルなしデータ"] --> E["似たもの同士を<br/>グループ化"]
end
判別の戦略には大きく2系統あり、結論から言うと両者は等分散正規のもとで一致します。
- 距離ベース:各群の中心への「距離」を測り、最も近い群へ割り当てる(マハラノビス距離)。
- 確率ベース:各群に属する確率(事後確率)を計算し、最も高い群へ割り当てる(ベイズ判別)。
Fisherの線形判別はこれらとは別の動機(射影軸の最適化)から出発しますが、2群・等分散のもとでは同じ線形境界に行き着きます。以下、順に見ます。
1. マハラノビス距離
1.1 定義
群の平均(中心)を 、共分散行列を とするとき、観測 から群中心までの**マハラノビス距離(の二乗)**は
です。各群について を計算し、 が最も小さい群へ を割り当てる、というのが距離ベースの判別の基本形です。共分散行列・相関行列の基礎は 分散共分散行列・相関行列 を参照してください。
1.2 なぜ共分散の逆行列を挟むのか
中心からの「素朴な距離」はユークリッド距離 です。マハラノビス距離はこれに を挟んだものです。意味を分解します。
(単位行列)なら、マハラノビス距離はユークリッド距離に一致します。
要するに「各変数が分散1で互いに無相関なら、両者は同じもの」です。つまりマハラノビス距離はユークリッド距離の一般化です。
ではなぜ を挟むのか。理由は変数ごとのばらつき・相関で正規化するためです。
- 分散による正規化:ある変数の分散が大きければ、その方向の「同じ生の距離」は統計的には大したズレではありません。 で割ることで、ばらつきの大きい方向の距離を縮め、小さい方向の距離を伸ばします。
- 相関による回転:変数間に相関があると等距離線は傾いた楕円になります。 はこの相関を「ほどいて」軸に沿った標準化された空間で距離を測ることに相当します。
幾何的には、 一定 の点の集合は を中心とする楕円体( の固有ベクトルが軸、固有値の平方根が軸長)になります。 ならこれが球面(ユークリッド)に戻ります。
直観:「同じcmだけ中心から離れていても、その方向に普段からデータが大きくばらついているなら、それは“普通の範囲内”。逆にめったに動かない方向に少し離れただけなら、それは“異常”」。この“ばらつきで割り引く”操作が です。
1.3 群ごとに共分散が同じか違うか
各群が固有の共分散 を持つと考えるか、全群で共通の を使うかで、後述の LDA / QDA が分岐します。実務では群ごとの共分散をまとめた併合(プール)共分散行列
を共通の の推定として使うのが等分散(LDA)の立場です。この は次の Fisher判別の群内変動行列と本質的に同じものです。
2. Fisherの線形判別(導出・省略しない)
2.1 アイデア:射影してから1次元で分ける
Fisherの線形判別(Linear Discriminant, LDA の原型)は、多次元データ を方向ベクトル に射影した1次元のスコア を作り、その軸上で群がいちばんよく分かれる方向 を選ぶという発想です。
「よく分かれる」を数式にするため、射影後の2種類のばらつきを考えます。
- 群間変動(between-class):群の中心どうしがどれだけ離れているか。大きいほど良い。
- 群内変動(within-class):各群の内部がどれだけ散らばっているか。小さいほど良い。
flowchart LR X["多次元データ x"] -->|"y = aᵀx に射影"| Y["1次元スコア y"] Y --> B["群間変動 S_B<br/>(中心の隔たり)大きくしたい"] Y --> W["群内変動 S_W<br/>(群内の散らばり)小さくしたい"] B & W --> J["比 J(a)=aᵀS_B a / aᵀS_W a を最大化"]
2.2 群間変動・群内変動の定義(多次元・ 群)
各群の標本平均を 、全体平均を 、群 の標本数を とします。
要するに は「群の中心が全体平均からどれだけ離れているか」、 は「各データが自分の群の中心からどれだけ離れているか」を行列で測ったものです。
方向 に射影したスコア の群間・群内変動は、それぞれ と (いずれもスカラー)になります。
2.3 Fisherの判別比とその最大化
「群間を大きく、群内を小さく」を1つの比にまとめたのがFisherの判別比です。
これを最大にする が、群を最もよく分離する射影方向です。
スケール不変性に注意。 を に変えても分子・分母がともに 倍されて は不変です。つまり の「長さ」には意味がなく「向き」だけが問題です。そこで分母を固定する制約 を課し、その下で分子 を最大化する問題に言い換えます。
2.4 ラグランジュ未定乗数法 → 一般化固有値問題
制約付き最大化なのでラグランジュ未定乗数 を導入します。
で微分してゼロと置きます。二次形式 の微分は が対称なら (重回帰分析 の行列微分公式と同じ)で、 はともに対称行列です。
これが**一般化固有値問題(generalized eigenvalue problem)**です。要するに「Fisher判別比を最大化する方向 は、 を満たす固有ベクトルである」ということです。
が正則なら左から を掛けて、
という通常の固有値問題になります。 ならただの固有値問題 (主成分分析と同形)に退化する点が、マハラノビス距離が でユークリッド距離に戻るのと同じ構図です。
なお、固有値 そのものが判別比 の値です。実際 の両辺に左から を掛けると となり、 が出ます。だから最大固有値に対応する固有ベクトルが最良の判別方向です。 群では 本までの固有ベクトル(正の固有値を持つもの)を判別軸として使えます( のランクが のため)。
2.5 2群の場合:判別方向が に比例
では群間変動行列がランク1の特別な形になります。2群の平均差を と置くと、 は本質的に
と書けます(外積なのでランク1)。これを一般化固有値問題に入れると、
ここで はスカラーです。すると左辺は「 という固定ベクトルのスカラー倍」なので、 も必ず の向きを向きます。固有ベクトルは向きだけが意味を持つ(2.3)ので、結論は
要するに「2群の判別方向は、2群の平均の差を群内共分散で正規化したベクトル」です。 なら単純な平均差 の方向(2群の中点を結ぶ向き)になりますが、群内に相関やばらつきの偏りがあれば がそれを補正して向きを傾けます。判別の境界はこの に直交する超平面(線形境界)になります。
3. ベイズ判別と LDA・QDA
3.1 事後確率最大の群へ割り当てる
確率ベースの判別では、観測 が与えられたときに各群に属する事後確率 を計算し、これが最大の群へ割り当てます。事後確率はベイズの定理(ベイズの定理)で書けます。
- :群 の事前確率(その群がどれくらいの割合で現れるか)。
- :群 における の確率密度(クラス条件付き密度)。
- 分母は全群で共通の正規化定数なので、 を取る分には無視できます。
したがって判別ルールは「 を最大にする を選ぶ」に帰着します。この事後確率最大化による判別は、後述のとおり誤判別確率を最小にするという意味で最適です(ベイズ最適)。
3.2 多変量正規を仮定する → 判別関数
各群が多変量正規分布(多変量正規分布)に従うと仮定します。
を最大化するのは、その対数を最大化するのと同じです。 から に依らない定数 を落とすと、群 の判別関数
が得られ、 が最大の群へ割り当てます。第2項にマハラノビス距離 がそのまま現れている点に注目してください。事前確率が等しく共分散も等しいなら、ベイズ判別はマハラノビス距離最小の群を選ぶことと完全に一致します(1節と3節がつながる)。
3.3 等分散なら線形(LDA)、異分散なら二次(QDA)
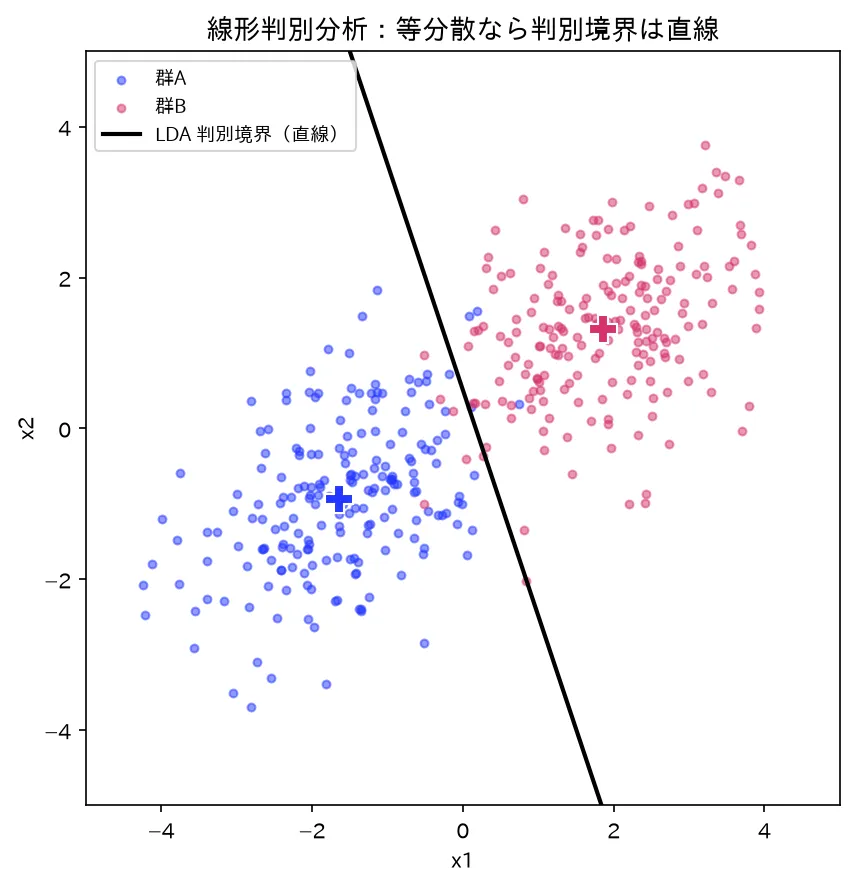
2群が等分散なら判別境界は直線(黒)。境界は平均差をプール共分散の逆行列で重み付けた向きに垂直。異分散だと QDA で曲線になる。図は simulations/hanbetsu_lda_kyoukai.py で生成。
判別の境界が線形か二次曲面かは、群ごとの共分散が共通か否かだけで決まります。ここが準1級最頻出の論点です。
等分散 (共通)の場合 → LDA(線形判別分析)。 全群で が同じだと、判別関数の二次項を展開したとき
の が全群共通なので では相殺します。 も共通で消えます。残るのは について1次の項だけです。
判別関数が の1次式なので、2群の境界 は**超平面(直線・線形境界)**になります。これが LDA です。そしてこの境界の法線方向は で、2節の Fisher の判別方向 と一致します( を で推定すれば同一)。距離ベース・確率ベース・Fisher の3つが等分散正規のもとで合流するわけです。
異分散 が群ごとに異なる場合 → QDA(二次判別分析)。 が群ごとに違うと、二次項 の が群ごとに違うので相殺しません。 も残ります。判別関数は について2次のまま。
境界 は の2次方程式なので**二次曲面(放物線・楕円・双曲線などの曲線境界)**になります。これが QDA です。
flowchart TD
S["各群が多変量正規と仮定<br/>ベイズ判別(事後確率最大)"] --> Q{"群ごとの共分散 Σ_k は<br/>共通か(等分散か)?"}
Q -- "等分散 Σ_k = Σ(共通)" --> L["二次項が相殺 → 判別関数は x の1次式<br/><b>LDA:線形境界(超平面)</b>"]
Q -- "異分散 Σ_k が群ごとに異なる" --> QD["二次項が残る → 判別関数は x の2次式<br/><b>QDA:二次境界(曲面)</b>"]
| LDA(線形判別分析) | QDA(二次判別分析) | |
|---|---|---|
| 共分散の仮定 | 全群共通 (等分散) | 群ごとに (異分散) |
| 判別関数 | の1次式 | の2次式 |
| 判別境界 | 超平面(線形) | 二次曲面(曲線) |
| 推定パラメータ数 | 少ない( は1個) | 多い( を群数だけ) |
| 向く状況 | 標本が少ない・群の散らばりが似ている | 標本が多い・群で散らばりが大きく違う |
要するに「等分散を仮定すると二次項が消えて直線、異分散を許すと二次項が残って曲線」です。QDA は柔軟ですが群ごとに共分散を推定する分パラメータが多く、標本が少ないと過学習しやすい(推定が不安定)というトレードオフがあります。
3.4 事前確率と誤判別コスト
事前確率 は判別関数に として入ります。ある群の事前確率が大きいほど、その群へ割り当てられやすくなる(境界がその群から遠ざかる)方向に効きます。実務では学習データ中の各群の出現割合 を の推定に使うのが標準です。
誤判別の重大さが群によって違う場合(例:病気を見逃すコストと健康を病気と誤るコストが非対称)、誤判別コスト (真は なのに と判定する損失)を重みとして導入し、期待損失を最小にする群へ割り当てるよう判別ルールを修正します。事前確率もコストも「どちらの群に倒すか」の重み付けという意味では同じ働きをします。
4. 誤判別率の評価
作った判別ルールがどれくらい当たるかを**誤判別率(misclassification rate)**で測ります。評価の仕方で見かけの性能が大きく変わるのが注意点です。
- 再代入誤り(resubstitution error):学習に使った同じデータをそのまま判別し、間違えた割合。実装が簡単だが、誤判別率を過小評価する(楽観的)。ルールはそのデータに合わせて作られているので、自分自身を当てるのは有利だからです。
- 交差確認(cross-validation):データを学習用と検証用に分け、学習に使っていないデータで誤判別率を測る。過小評価を避けられます。極端な形が**1個抜き交差確認(leave-one-out, LOO)**で、「1個を除いて残り 個で判別ルールを作り、除いた1個を判定する」を全 個について繰り返し、誤った割合を平均します。
要するに「再代入は身内びいきで甘い評価、交差確認は他人の目で見た公正な評価」です。準1級では「再代入誤りは真の誤判別率を過小評価する/だから交差確認を使う」という対比が論点になります。
⚠️ 引っかけポイント・頻出論点
- LDA と QDA の分かれ目は「等分散か異分散か」だけ。 等分散(共通の )を仮定すると二次項が相殺して線形境界(LDA)、群ごとに が違うと二次項が残って二次境界(QDA)。「LDA=線形・QDA=二次」と境界の形まで対応させて覚えること。
- マハラノビス距離 vs ユークリッド距離。 マハラノビスは で共分散正規化した距離。 ならユークリッドに一致。「群の中心に近い方へ」をユークリッド距離で判定するのは、群のばらつきや相関を無視しており誤り(等分散かつ無相関でない限り)。
- 判別分析(教師あり)とクラスター分析(教師なし)の混同。 判別分析は群ラベルが既知の学習データから判別ルールを作る教師あり手法。群が未知のままグループ化するのはクラスター分析(クラスター分析)で別物。「あらかじめ群が分かっているか」で見分ける。
- ロジスティック回帰との関係。 ロジスティック回帰(一般化線形モデル(ロジスティック・ポアソン回帰))も2値・多値の分類を行うが、アプローチが違う。判別分析(LDA)は「各群の分布 を正規分布でモデル化してベイズの定理で事後確率を出す」**生成的(generative)**手法。ロジスティック回帰は「事後確率 を直接ロジスティック関数でモデル化する」識別的(discriminative)手法。LDA は正規性の仮定が当たれば効率的だが、外れに弱い。ロジスティック回帰は分布を仮定しない分頑健。実は等分散正規のもとでは両者とも事後確率が線形ロジットになり、推定法だけが違う(LDA は正規分布のパラメータ推定、ロジスティック回帰は最尤)という関係です。
- Fisher判別と LDA の関係。 Fisher の線形判別(群間/群内変動比の最大化)と、等分散正規を仮定したベイズ判別(LDA)は、2群では同じ判別方向 に行き着く。出発点(射影軸の最適化 vs 確率モデル)は違うが結論が一致する点を問われることがある。
- 再代入誤りの過小評価。 学習データそのもので測った誤判別率は甘い(楽観的)。真の性能は交差確認で測る。
よくある疑問(Q&A)
Q1. なぜ距離をわざわざマハラノビス距離にするのですか。ユークリッド距離ではだめですか。
ユークリッド距離は「全方向に同じものさし」を当てますが、現実のデータは方向によってばらつきが違い、変数間に相関もあります。例えば身長と体重は相関しており、散布図の点群は斜めの楕円状に広がります。この楕円の長軸方向に少し離れても「よくあること」、短軸方向に同じだけ離れると「珍しいこと」です。ユークリッド距離はこの差を無視してしまいます。マハラノビス距離は でばらつきと相関を割り引き、「統計的に見てどれくらい珍しい離れ方か」を測ります。(分散1・無相関)の特別な場合だけ両者は一致します。
Q2. LDA と QDA はどちらを使えばよいですか。
群ごとの散らばり(共分散)が似ているなら LDA、明らかに違うなら QDA が原則です。ただし QDA は群ごとに共分散行列を推定するためパラメータが多く、標本数が少ないと推定が不安定になり、かえって性能が落ちます(過学習)。そのため「異分散っぽいが標本が少ない」ときは、あえて等分散を仮定する LDA の方が安定して良い結果を出すことがよくあります。要するに「QDA は柔軟だがデータを食う」ので、標本数と相談して選びます。
Q3. 判別分析とクラスター分析は何が違うのですか。どちらもグループ分けに見えます。
決定的な違いは「正解の群ラベルが最初から分かっているか」です。判別分析は、群が既知の学習データ(例:合格者/不合格者がラベル付きで揃っている)からルールを学び、新しい人を分類する教師あり手法。クラスター分析は、ラベルのないデータ(例:顧客データに分類は付いていない)を、似たもの同士で新たにグループ化する教師なし手法です。「分ける基準(群)が与えられているか/自分で見つけるか」で見分けます。クラスター分析は クラスター分析 で扱います。
Q4. 判別分析とロジスティック回帰はどちらも分類です。使い分けは?
両方とも「どの群か」を当てる手法ですが、考え方が逆向きです。LDA は各群のデータ分布を正規分布で表し、ベイズの定理で「この はどの群らしいか」を逆算します(生成的)。ロジスティック回帰は群の分布を仮定せず、「群に属する確率」を直接モデル化します(識別的)。正規分布の仮定が妥当なら LDA が効率的ですが、仮定が外れる(外れ値・非正規)とロジスティック回帰の方が頑健です。実用上は、分布の仮定を置きたくない・解釈しやすいオッズ比が欲しい場面でロジスティック回帰、群が正規でデータが少ない場面で LDA、という使い分けが目安です。
Q5. 学習データで測った誤判別率が低いのに、新しいデータでは当たりません。なぜですか。
それは再代入誤りを見ているからです。判別ルールはその学習データに合わせて作られているので、同じデータを当てるのは有利で、誤判別率を実際より低く(楽観的に)見積もります。真の性能を知るには、学習に使っていないデータで評価する交差確認(特に1個抜き交差確認)を使ってください。再代入誤りと交差確認による誤判別率の差が大きいほど、そのモデルは過学習している、という診断にもなります。
まとめ
- 判別分析は群が既知の学習データから判別ルールを作る教師あり分類。群が未知のクラスター分析(教師なし)とは別物。
- マハラノビス距離 は共分散で正規化した距離。 でユークリッド距離に一致。一番近い群へ割り当てる。
- Fisherの線形判別は群間変動と群内変動の比 を最大化。ラグランジュ未定乗数法で一般化固有値問題 に帰着し、2群では判別方向 。
- ベイズ判別は事後確率 最大の群へ。各群が多変量正規で等分散なら LDA(線形境界)、異分散なら QDA(二次境界)。距離ベース・Fisher・ベイズが等分散正規で合流する。
- 事前確率・誤判別コストは「どちらの群に倒すか」の重み。誤判別率は再代入誤り(甘い)でなく交差確認で測る。
関連ノート
- 分散共分散行列・相関行列 マハラノビス距離・群内変動の土台
- 多変量正規分布 LDA・QDA が前提とするクラス条件付き分布
- ベイズの定理 事後確率最大化(ベイズ判別)の基礎
- クラスター分析 教師なしのグループ化。判別分析との対比
- 一般化線形モデル(ロジスティック・ポアソン回帰) ロジスティック回帰(識別的アプローチ)との関係
- 重回帰分析 二次形式のベクトル微分・最小化の手筋を共有
- 多変量解析(Phase 6 目次) 多変量解析ドメインの全体像