← 統計検定テキスト 一覧
📊 対象級:準1級 ・ 1級 | 重要度:A(頻出)
要点(BLUF)
多変量正規分布 N p ( μ , Σ ) N_p(\boldsymbol\mu,\Sigma) N p ( μ , Σ ) 正規分布(標準正規・標準化) )を p p p 平均ベクトル μ \boldsymbol\mu μ Σ \Sigma Σ で完全に決まります。密度は次の一行に集約されます。
f ( x ) = 1 ( 2 π ) p / 2 ∣ Σ ∣ 1 / 2 exp ( − 1 2 ( x − μ ) ⊤ Σ − 1 ( x − μ ) ) \boxed{\;f(\mathbf x)=\dfrac{1}{(2\pi)^{p/2}\lvert\Sigma\rvert^{1/2}}\exp\!\left(-\tfrac12(\mathbf x-\boldsymbol\mu)^\top\Sigma^{-1}(\mathbf x-\boldsymbol\mu)\right)\;} f ( x ) = ( 2 π ) p /2 ∣ Σ ∣ 1/2 1 exp ( − 2 1 ( x − μ ) ⊤ Σ − 1 ( x − μ ) ) 要するに「指数の肩に乗っているのは中心 μ \boldsymbol\mu μ マハラノビス距離の2乗 で、分母の ∣ Σ ∣ \lvert\Sigma\rvert ∣ Σ ∣ (1) 線形変換に閉じる、(2) 周辺・条件付き分布も正規、(3) 同時正規なら無相関 ⇔ 独立 で、いずれも準1級・1級で頻出です。
1. 密度関数:1変量正規からの自然な拡張
1.1 1変量との対応
まず1変量正規分布の密度を思い出します(正規分布(標準正規・標準化) )。
f ( x ) = 1 2 π σ exp ( − ( x − μ ) 2 2 σ 2 ) = 1 ( 2 π ) 1 / 2 ( σ 2 ) 1 / 2 exp ( − 1 2 ( x − μ ) ( σ 2 ) − 1 ( x − μ ) ) f(x)=\frac{1}{\sqrt{2\pi}\,\sigma}\exp\!\left(-\frac{(x-\mu)^2}{2\sigma^2}\right)
=\frac{1}{(2\pi)^{1/2}(\sigma^2)^{1/2}}\exp\!\left(-\frac12\,(x-\mu)\,(\sigma^2)^{-1}\,(x-\mu)\right) f ( x ) = 2 π σ 1 exp ( − 2 σ 2 ( x − μ ) 2 ) = ( 2 π ) 1/2 ( σ 2 ) 1/2 1 exp ( − 2 1 ( x − μ ) ( σ 2 ) − 1 ( x − μ ) ) 右側のように書き直すと、多変量版との対応が一目で見えます。
1変量 p p p 役割 x , μ x,\ \mu x , μ x , μ \mathbf x,\ \boldsymbol\mu x , μ p p p 値・中心 σ 2 \sigma^2 σ 2 Σ \Sigma Σ p × p p\times p p × p 散らばり ( x − μ ) 2 / σ 2 (x-\mu)^2/\sigma^2 ( x − μ ) 2 / σ 2 ( x − μ ) ⊤ Σ − 1 ( x − μ ) (\mathbf x-\boldsymbol\mu)^\top\Sigma^{-1}(\mathbf x-\boldsymbol\mu) ( x − μ ) ⊤ Σ − 1 ( x − μ ) 中心からの距離の2乗 ( 2 π ) 1 / 2 ( σ 2 ) 1 / 2 (2\pi)^{1/2}(\sigma^2)^{1/2} ( 2 π ) 1/2 ( σ 2 ) 1/2 ( 2 π ) p / 2 ∣ Σ ∣ 1 / 2 (2\pi)^{p/2}\lvert\Sigma\rvert^{1/2} ( 2 π ) p /2 ∣ Σ ∣ 1/2 正規化定数
要するに「割り算 / σ 2 /\sigma^2 / σ 2 Σ − 1 \Sigma^{-1} Σ − 1 σ \sigma σ ∣ Σ ∣ 1 / 2 \lvert\Sigma\rvert^{1/2} ∣ Σ ∣ 1/2 p = 1 p=1 p = 1 Σ = σ 2 \Sigma=\sigma^2 Σ = σ 2 ∣ Σ ∣ = σ 2 \lvert\Sigma\rvert=\sigma^2 ∣ Σ ∣ = σ 2 Σ \Sigma Σ 分散共分散行列・相関行列 を参照してください。
1.2 指数部はマハラノビス距離
密度の指数の肩にある二次形式
D 2 ( x ) = ( x − μ ) ⊤ Σ − 1 ( x − μ ) D^2(\mathbf x)=(\mathbf x-\boldsymbol\mu)^\top\Sigma^{-1}(\mathbf x-\boldsymbol\mu) D 2 ( x ) = ( x − μ ) ⊤ Σ − 1 ( x − μ ) を マハラノビス距離(の2乗) と呼びます。ユークリッド距離 ( x − μ ) ⊤ ( x − μ ) (\mathbf x-\boldsymbol\mu)^\top(\mathbf x-\boldsymbol\mu) ( x − μ ) ⊤ ( x − μ ) Σ − 1 \Sigma^{-1} Σ − 1
Σ = I \Sigma=I Σ = I D 2 D^2 D 2 一般の Σ \Sigma Σ ばらつきの大きい方向の差は割り引かれ、ばらつきの小さい方向の差は重く評価 されます。Σ − 1 \Sigma^{-1} Σ − 1
要するに「マハラノビス距離は、分布の広がり方を考慮した『標準化された距離』」です。中心 μ \boldsymbol\mu μ D 2 D^2 D 2 X ∼ N p ( μ , Σ ) \mathbf X\sim N_p(\boldsymbol\mu,\Sigma) X ∼ N p ( μ , Σ ) D 2 ( X ) D^2(\mathbf X) D 2 ( X ) p p p
1.3 行列式 ∣ Σ ∣ \lvert\Sigma\rvert ∣ Σ ∣
分母の ∣ Σ ∣ 1 / 2 \lvert\Sigma\rvert^{1/2} ∣ Σ ∣ 1/2 正規化定数 です。1変量で σ \sigma σ ∣ Σ ∣ 1 / 2 \lvert\Sigma\rvert^{1/2} ∣ Σ ∣ 1/2
直観的には、∣ Σ ∣ \lvert\Sigma\rvert ∣ Σ ∣ Σ \Sigma Σ ∣ Σ ∣ = λ 1 λ 2 ⋯ λ p \lvert\Sigma\rvert=\lambda_1\lambda_2\cdots\lambda_p ∣ Σ ∣ = λ 1 λ 2 ⋯ λ p ∣ Σ ∣ \lvert\Sigma\rvert ∣ Σ ∣ 1 / ∣ Σ ∣ 1 / 2 1/\lvert\Sigma\rvert^{1/2} 1/ ∣ Σ ∣ 1/2
⚠️ Σ \Sigma Σ 特異 (∣ Σ ∣ = 0 \lvert\Sigma\rvert=0 ∣ Σ ∣ = 0 Σ − 1 \Sigma^{-1} Σ − 1 ∣ Σ ∣ 1 / 2 \lvert\Sigma\rvert^{1/2} ∣ Σ ∣ 1/2 上の密度は存在しません 。これを退化した(degenerate)多変量正規分布と呼びます。確率質量が p p p
2. 等確率楕円:Σ \Sigma Σ
図は simulations/nihen_seiki_toukousen.py で生成。
密度が一定 f ( x ) = const f(\mathbf x)=\text{const} f ( x ) = const
( x − μ ) ⊤ Σ − 1 ( x − μ ) = c ( c > 0 ) (\mathbf x-\boldsymbol\mu)^\top\Sigma^{-1}(\mathbf x-\boldsymbol\mu)=c\quad(c>0) ( x − μ ) ⊤ Σ − 1 ( x − μ ) = c ( c > 0 ) です。これは中心 μ \boldsymbol\mu μ 楕円体(2次元なら楕円) を描きます。Σ \Sigma Σ Σ − 1 \Sigma^{-1} Σ − 1
楕円の 向き と 長さ は、Σ \Sigma Σ Σ \Sigma Σ
Σ = ∑ j = 1 p λ j u j u j ⊤ , Σ u j = λ j u j \Sigma=\sum_{j=1}^{p}\lambda_j\,\mathbf u_j\mathbf u_j^\top,\qquad \Sigma\mathbf u_j=\lambda_j\mathbf u_j Σ = j = 1 ∑ p λ j u j u j ⊤ , Σ u j = λ j u j と固有値分解します(λ j > 0 \lambda_j>0 λ j > 0 u j \mathbf u_j u j
軸の向き :各主軸は固有ベクトル u j \mathbf u_j u j 軸の長さ :第 j j j c λ j \sqrt{c\,\lambda_j} c λ j
graph LR
S["共分散行列 Σ"] --> ED["固有値分解 Σ=Σ λ_j u_j u_jᵀ"]
ED --> DIR["固有ベクトル u_j<br/>= 楕円の主軸の向き"]
ED --> LEN["固有値 λ_j<br/>軸の長さ ∝ √λ_j"]
DIR --> EL["等確率楕円<br/>(x-μ)ᵀΣ⁻¹(x-μ)=c"]
LEN --> EL
要するに「散らばりが大きい方向(固有値が大きい固有ベクトル方向)に楕円が長く伸びる 」ということです。固有値がすべて等しければ楕円は円(球)になり、固有値の差が大きいほど細長い楕円になります。
この固有値・固有ベクトルが楕円の主軸を決めるという事実は、主成分分析そのもの です(主成分分析(PCA) )。主成分分析は「等確率楕円の長軸=最大分散方向(第1固有ベクトル)」を順に取り出す手法と理解できます。多変量正規分布の幾何と主成分は同じ固有構造を見ています。
3. モーメント母関数(性質証明の起点)
多変量正規分布のモーメント母関数(MGF, 多変量版は 確率変数の変換・モーメント母関数・積率 )は次の通りです。
M X ( t ) = E [ e t ⊤ X ] = exp ( t ⊤ μ + 1 2 t ⊤ Σ t ) \boxed{\;M_{\mathbf X}(\mathbf t)=\mathbb E\!\left[e^{\mathbf t^\top\mathbf X}\right]=\exp\!\left(\mathbf t^\top\boldsymbol\mu+\tfrac12\,\mathbf t^\top\Sigma\,\mathbf t\right)\;} M X ( t ) = E [ e t ⊤ X ] = exp ( t ⊤ μ + 2 1 t ⊤ Σ t ) 要するに「指数の肩が、平均についての1次項 t ⊤ μ \mathbf t^\top\boldsymbol\mu t ⊤ μ 1 2 t ⊤ Σ t \tfrac12\mathbf t^\top\Sigma\mathbf t 2 1 t ⊤ Σ t M ( t ) = exp ( μ t + 1 2 σ 2 t 2 ) M(t)=\exp(\mu t+\tfrac12\sigma^2t^2) M ( t ) = exp ( μ t + 2 1 σ 2 t 2 )
MGFが重要なのは、分布はMGFで一意に決まる ためです。「ある量のMGFを計算したら多変量正規のMGFの形になった」と示せれば、その量は多変量正規に従うと結論できます。以下の線形変換閉性も無相関⇔独立も、この事実を使って証明できます。これが1級で性質の証明を問う際の標準的な道具立てです。
4. 線形変換に閉じる
4.1 命題
X ∼ N p ( μ , Σ ) \mathbf X\sim N_p(\boldsymbol\mu,\Sigma) X ∼ N p ( μ , Σ ) A A A m × p m\times p m × p b \mathbf b b m m m Y = A X + b \mathbf Y=A\mathbf X+\mathbf b Y = A X + b
A X + b ∼ N m ( A μ + b , A Σ A ⊤ ) \boxed{\;A\mathbf X+\mathbf b\sim N_m\!\left(A\boldsymbol\mu+\mathbf b,\ A\Sigma A^\top\right)\;} A X + b ∼ N m ( A μ + b , A Σ A ⊤ ) 要するに「正規分布を行列で線形変換しても、また正規分布のまま。平均は同じ変換で動き、共分散は A Σ A ⊤ A\Sigma A^\top A Σ A ⊤
4.2 MGFによる証明(省略しない)
Y = A X + b \mathbf Y=A\mathbf X+\mathbf b Y = A X + b
M Y ( t ) = E [ e t ⊤ ( A X + b ) ] = e t ⊤ b E [ e ( A ⊤ t ) ⊤ X ] = e t ⊤ b M X ( A ⊤ t ) = e t ⊤ b exp ( ( A ⊤ t ) ⊤ μ + 1 2 ( A ⊤ t ) ⊤ Σ ( A ⊤ t ) ) = exp ( t ⊤ ( A μ + b ) + 1 2 t ⊤ ( A Σ A ⊤ ) t ) \begin{aligned}
M_{\mathbf Y}(\mathbf t)
&=\mathbb E\!\left[e^{\mathbf t^\top(A\mathbf X+\mathbf b)}\right]
=e^{\mathbf t^\top\mathbf b}\,\mathbb E\!\left[e^{(A^\top\mathbf t)^\top\mathbf X}\right]\\[2pt]
&=e^{\mathbf t^\top\mathbf b}\,M_{\mathbf X}(A^\top\mathbf t)
=e^{\mathbf t^\top\mathbf b}\,\exp\!\left((A^\top\mathbf t)^\top\boldsymbol\mu+\tfrac12(A^\top\mathbf t)^\top\Sigma(A^\top\mathbf t)\right)\\[2pt]
&=\exp\!\left(\mathbf t^\top(A\boldsymbol\mu+\mathbf b)+\tfrac12\,\mathbf t^\top(A\Sigma A^\top)\mathbf t\right)
\end{aligned} M Y ( t ) = E [ e t ⊤ ( A X + b ) ] = e t ⊤ b E [ e ( A ⊤ t ) ⊤ X ] = e t ⊤ b M X ( A ⊤ t ) = e t ⊤ b exp ( ( A ⊤ t ) ⊤ μ + 2 1 ( A ⊤ t ) ⊤ Σ ( A ⊤ t ) ) = exp ( t ⊤ ( A μ + b ) + 2 1 t ⊤ ( A Σ A ⊤ ) t ) 途中、t ⊤ A X = ( A ⊤ t ) ⊤ X \mathbf t^\top A\mathbf X=(A^\top\mathbf t)^\top\mathbf X t ⊤ A X = ( A ⊤ t ) ⊤ X X \mathbf X X A ⊤ t A^\top\mathbf t A ⊤ t A μ + b A\boldsymbol\mu+\mathbf b A μ + b A Σ A ⊤ A\Sigma A^\top A Σ A ⊤ Y ∼ N m ( A μ + b , A Σ A ⊤ ) \mathbf Y\sim N_m(A\boldsymbol\mu+\mathbf b,\,A\Sigma A^\top) Y ∼ N m ( A μ + b , A Σ A ⊤ )
要するに「正規のMGFは指数の肩が1次+2次形式なので、線形変換しても肩の次数が増えず、また正規のMGFの形に収まる」のが閉性の本質です。
4.3 重要な帰結
任意の線形結合 a ⊤ X \mathbf a^\top\mathbf X a ⊤ X :A = a ⊤ A=\mathbf a^\top A = a ⊤ 1 × p 1\times p 1 × p a ⊤ X ∼ N ( a ⊤ μ , a ⊤ Σ a ) \mathbf a^\top\mathbf X\sim N(\mathbf a^\top\boldsymbol\mu,\ \mathbf a^\top\Sigma\mathbf a) a ⊤ X ∼ N ( a ⊤ μ , a ⊤ Σ a ) 定義 に採用することもあります(「すべての線形結合が1変量正規 ⇔ 多変量正規」)。退化した場合まで含めて扱えるので、こちらを定義とする教科書も多いです。成分の和や差 :X 1 + X 2 X_1+X_2 X 1 + X 2 X 1 − X 2 X_1-X_2 X 1 − X 2 標準化 :Σ \Sigma Σ Σ = L L ⊤ \Sigma=LL^\top Σ = L L ⊤ Z = L − 1 ( X − μ ) \mathbf Z=L^{-1}(\mathbf X-\boldsymbol\mu) Z = L − 1 ( X − μ ) Z ∼ N p ( 0 , I ) \mathbf Z\sim N_p(\mathbf 0,I) Z ∼ N p ( 0 , I ) X = L Z + μ \mathbf X=L\mathbf Z+\boldsymbol\mu X = L Z + μ
5. 周辺分布・条件付き分布も正規
ベクトルを2つのブロックに分割します。
X = ( X 1 X 2 ) , μ = ( μ 1 μ 2 ) , Σ = ( Σ 11 Σ 12 Σ 21 Σ 22 ) \mathbf X=\begin{pmatrix}\mathbf X_1\\ \mathbf X_2\end{pmatrix},\quad
\boldsymbol\mu=\begin{pmatrix}\boldsymbol\mu_1\\ \boldsymbol\mu_2\end{pmatrix},\quad
\Sigma=\begin{pmatrix}\Sigma_{11}&\Sigma_{12}\\ \Sigma_{21}&\Sigma_{22}\end{pmatrix} X = ( X 1 X 2 ) , μ = ( μ 1 μ 2 ) , Σ = ( Σ 11 Σ 21 Σ 12 Σ 22 ) ここで Σ 12 = Σ 21 ⊤ \Sigma_{12}=\Sigma_{21}^\top Σ 12 = Σ 21 ⊤ 同時分布・周辺分布・条件付き分布 を参照してください。
5.1 周辺分布
X 1 \mathbf X_1 X 1 そのまま抜き出すだけ です。
X 1 ∼ N ( μ 1 , Σ 11 ) \boxed{\;\mathbf X_1\sim N\!\left(\boldsymbol\mu_1,\ \Sigma_{11}\right)\;} X 1 ∼ N ( μ 1 , Σ 11 ) 要するに「興味のある成分の平均と共分散の該当ブロックだけ取り出せば、それが周辺分布」です。証明は線形変換閉性で済みます。X 1 = [ I 0 ] X \mathbf X_1=[\,I\ \ 0\,]\mathbf X X 1 = [ I 0 ] X N ( [ I 0 ] μ , [ I 0 ] Σ [ I 0 ] ⊤ ) = N ( μ 1 , Σ 11 ) N([\,I\,0\,]\boldsymbol\mu,\ [\,I\,0\,]\Sigma[\,I\,0\,]^\top)=N(\boldsymbol\mu_1,\Sigma_{11}) N ([ I 0 ] μ , [ I 0 ] Σ [ I 0 ] ⊤ ) = N ( μ 1 , Σ 11 )
5.2 条件付き分布
X 2 = x 2 \mathbf X_2=\mathbf x_2 X 2 = x 2 X 1 \mathbf X_1 X 1
X 1 ∣ X 2 = x 2 ∼ N ( μ 1 + Σ 12 Σ 22 − 1 ( x 2 − μ 2 ) ⏟ 条件付き平均 , Σ 11 − Σ 12 Σ 22 − 1 Σ 21 ⏟ 条件付き共分散 ) \boxed{\;\mathbf X_1\mid \mathbf X_2=\mathbf x_2\ \sim\ N\!\left(\ \underbrace{\boldsymbol\mu_1+\Sigma_{12}\Sigma_{22}^{-1}(\mathbf x_2-\boldsymbol\mu_2)}_{\text{条件付き平均}},\ \ \underbrace{\Sigma_{11}-\Sigma_{12}\Sigma_{22}^{-1}\Sigma_{21}}_{\text{条件付き共分散}}\ \right)\;} X 1 ∣ X 2 = x 2 ∼ N 条件付き平均 μ 1 + Σ 12 Σ 22 − 1 ( x 2 − μ 2 ) , 条件付き共分散 Σ 11 − Σ 12 Σ 22 − 1 Σ 21 それぞれの意味は次の通りです。
条件付き平均 μ 1 ∣ 2 = μ 1 + Σ 12 Σ 22 − 1 ( x 2 − μ 2 ) \boldsymbol\mu_{1\mid2}=\boldsymbol\mu_1+\Sigma_{12}\Sigma_{22}^{-1}(\mathbf x_2-\boldsymbol\mu_2) μ 1 ∣ 2 = μ 1 + Σ 12 Σ 22 − 1 ( x 2 − μ 2 ) x 2 \mathbf x_2 x 2 μ 2 \boldsymbol\mu_2 μ 2 Σ 12 Σ 22 − 1 \Sigma_{12}\Sigma_{22}^{-1} Σ 12 Σ 22 − 1 X 1 \mathbf X_1 X 1 x 2 \mathbf x_2 x 2 X 1 \mathbf X_1 X 1 条件付き共分散 Σ 1 ∣ 2 = Σ 11 − Σ 12 Σ 22 − 1 Σ 21 \Sigma_{1\mid2}=\Sigma_{11}-\Sigma_{12}\Sigma_{22}^{-1}\Sigma_{21} Σ 1 ∣ 2 = Σ 11 − Σ 12 Σ 22 − 1 Σ 21 Σ 22 \Sigma_{22} Σ 22 シューア補行列(Schur complement) と呼ばれます。元の不確かさ Σ 11 \Sigma_{11} Σ 11 X 2 \mathbf X_2 X 2 Σ 12 Σ 22 − 1 Σ 21 \Sigma_{12}\Sigma_{22}^{-1}\Sigma_{21} Σ 12 Σ 22 − 1 Σ 21 条件付き共分散は x 2 \mathbf x_2 x 2 である点が要注意(情報を得て減る不確かさは、観測値そのものではなく相関構造で決まる)。
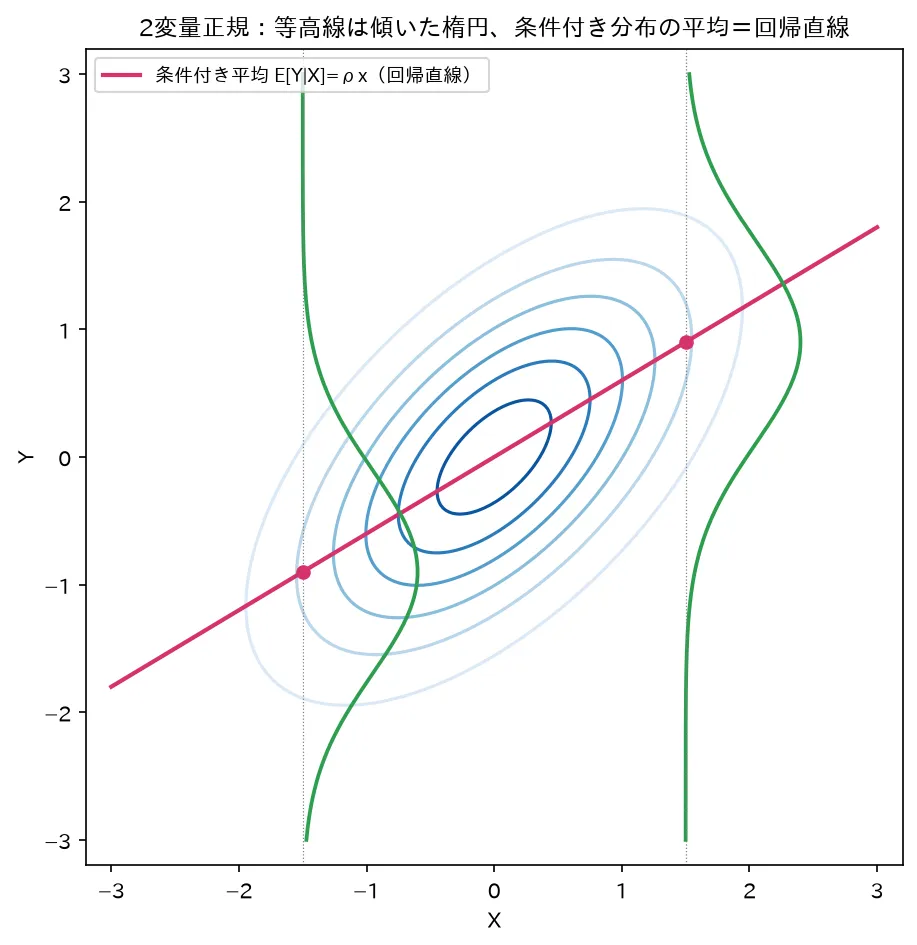
5.3 条件付き期待値は「回帰式」の形
条件付き平均を x 2 \mathbf x_2 x 2
E [ X 1 ∣ X 2 = x 2 ] = ( μ 1 − Σ 12 Σ 22 − 1 μ 2 ) ⏟ 切片 + Σ 12 Σ 22 − 1 ⏟ 回帰係数行列 x 2 \mathbb E[\mathbf X_1\mid \mathbf X_2=\mathbf x_2]
=\underbrace{\big(\boldsymbol\mu_1-\Sigma_{12}\Sigma_{22}^{-1}\boldsymbol\mu_2\big)}_{\text{切片}}
+\underbrace{\Sigma_{12}\Sigma_{22}^{-1}}_{\text{回帰係数行列}}\mathbf x_2 E [ X 1 ∣ X 2 = x 2 ] = 切片 ( μ 1 − Σ 12 Σ 22 − 1 μ 2 ) + 回帰係数行列 Σ 12 Σ 22 − 1 x 2 これは x 2 \mathbf x_2 x 2 線形(アフィン)な式 、すなわち回帰式そのものです。係数行列 Σ 12 Σ 22 − 1 \Sigma_{12}\Sigma_{22}^{-1} Σ 12 Σ 22 − 1 回帰係数行列 と呼ばれます。実際、最小二乗回帰の母数版を計算すると、説明変数を X 2 \mathbf X_2 X 2 X 1 \mathbf X_1 X 1 重回帰分析 の β ^ = ( X ⊤ X ) − 1 X ⊤ y \hat{\boldsymbol\beta}=(X^\top X)^{-1}X^\top\mathbf y β ^ = ( X ⊤ X ) − 1 X ⊤ y Σ 12 Σ 22 − 1 \Sigma_{12}\Sigma_{22}^{-1} Σ 12 Σ 22 − 1
要するに「正規分布のもとでは、条件付き期待値が自動的に線形回帰の形になる 」ということです。線形回帰モデルがなぜあれほど自然に使えるのか、その理論的根拠の一つがこれです。
1次元同士の場合(X 1 = X , X 2 = Y \mathbf X_1=X,\ \mathbf X_2=Y X 1 = X , X 2 = Y ρ \rho ρ
E [ X ∣ Y = y ] = μ X + ρ σ X σ Y ( y − μ Y ) , V a r ( X ∣ Y = y ) = σ X 2 ( 1 − ρ 2 ) \mathbb E[X\mid Y=y]=\mu_X+\rho\frac{\sigma_X}{\sigma_Y}(y-\mu_Y),\qquad
\mathrm{Var}(X\mid Y=y)=\sigma_X^2(1-\rho^2) E [ X ∣ Y = y ] = μ X + ρ σ Y σ X ( y − μ Y ) , Var ( X ∣ Y = y ) = σ X 2 ( 1 − ρ 2 ) 条件付き分散 σ X 2 ( 1 − ρ 2 ) \sigma_X^2(1-\rho^2) σ X 2 ( 1 − ρ 2 ) Y Y Y 1 − ρ 2 1-\rho^2 1 − ρ 2 ∣ ρ ∣ → 1 \lvert\rho\rvert\to1 ∣ ρ ∣ → 1
6. 無相関 ⇔ 独立(同時正規という前提あってこそ)
6.1 命題
一般の確率変数では「独立 ⇒ 無相関」は成り立ちますが、逆「無相関 ⇒ 独立」は 成り立ちません 。ところが、
X ∼ N p ( μ , Σ ) が同時に多変量正規なら 無相関 ⟺ 独立 \boxed{\;\mathbf X\sim N_p(\boldsymbol\mu,\Sigma)\ \text{が同時に多変量正規なら}\quad \text{無相関}\ \Longleftrightarrow\ \text{独立}\;} X ∼ N p ( μ , Σ ) が同時に多変量正規なら 無相関 ⟺ 独立 具体的には、共分散行列 Σ \Sigma Σ 対角行列 (非対角成分=共分散がすべて0)であることと、各成分が互いに独立であることが同値です。
6.2 なぜ成り立つか(密度の積分解)
Σ \Sigma Σ Σ = d i a g ( σ 1 2 , … , σ p 2 ) \Sigma=\mathrm{diag}(\sigma_1^2,\dots,\sigma_p^2) Σ = diag ( σ 1 2 , … , σ p 2 ) Σ − 1 = d i a g ( 1 / σ 1 2 , … , 1 / σ p 2 ) \Sigma^{-1}=\mathrm{diag}(1/\sigma_1^2,\dots,1/\sigma_p^2) Σ − 1 = diag ( 1/ σ 1 2 , … , 1/ σ p 2 ) ∣ Σ ∣ = ∏ j σ j 2 \lvert\Sigma\rvert=\prod_j\sigma_j^2 ∣ Σ ∣ = ∏ j σ j 2
( x − μ ) ⊤ Σ − 1 ( x − μ ) = ∑ j = 1 p ( x j − μ j ) 2 σ j 2 (\mathbf x-\boldsymbol\mu)^\top\Sigma^{-1}(\mathbf x-\boldsymbol\mu)=\sum_{j=1}^{p}\frac{(x_j-\mu_j)^2}{\sigma_j^2} ( x − μ ) ⊤ Σ − 1 ( x − μ ) = j = 1 ∑ p σ j 2 ( x j − μ j ) 2 すると指数関数は積に分かれ、正規化定数も分かれて、密度が 各成分の周辺密度の積 になります。
f ( x ) = ∏ j = 1 p 1 2 π σ j exp ( − ( x j − μ j ) 2 2 σ j 2 ) = ∏ j = 1 p f j ( x j ) f(\mathbf x)=\prod_{j=1}^{p}\frac{1}{\sqrt{2\pi}\,\sigma_j}\exp\!\left(-\frac{(x_j-\mu_j)^2}{2\sigma_j^2}\right)=\prod_{j=1}^{p}f_j(x_j) f ( x ) = j = 1 ∏ p 2 π σ j 1 exp ( − 2 σ j 2 ( x j − μ j ) 2 ) = j = 1 ∏ p f j ( x j ) 同時密度が周辺密度の積に分解する、これが独立の定義そのものです。要するに「対角共分散 ⇒ 指数の和分解 ⇒ 密度の積分解 ⇒ 独立」という流れです。逆向き(独立 ⇒ 無相関)は一般の確率変数でも常に成り立つので、同値になります。
⚠️ この同値が成り立つのは 同時に多変量正規である という前提のもとだけです。各成分が(周辺的に)正規であっても、同時分布が多変量正規でないなら「無相関でも独立とは限らない」に逆戻りします(次節の引っかけ)。
7. ⚠️ 引っかけポイント(級共通で頻出)
7.1 「各成分が正規」≠「同時に多変量正規」
最大の誤解 です。X X X Y Y Y ( X , Y ) (X,Y) ( X , Y )
具体的な反例:X ∼ N ( 0 , 1 ) X\sim N(0,1) X ∼ N ( 0 , 1 ) c > 0 c>0 c > 0
Y = { X ( ∣ X ∣ > c ) − X ( ∣ X ∣ ≤ c ) Y=\begin{cases}\ \ X & (\lvert X\rvert>c)\\[-2pt] -X & (\lvert X\rvert\le c)\end{cases} Y = { X − X (∣ X ∣ > c ) (∣ X ∣ ≤ c ) と定めます。対称性から Y Y Y N ( 0 , 1 ) N(0,1) N ( 0 , 1 ) ( X , Y ) (X,Y) ( X , Y ) y = x y=x y = x y = − x y=-x y = − x c c c X , Y X,Y X , Y Y Y Y X X X
同時正規であることの正しい特徴づけ :「任意の線形結合 a X + b Y aX+bY a X + bY a , b a,b a , b
7.2 無相関⇔独立は「多変量正規」という前提つき
6節の同値は同時正規が前提です。7.1の反例のように、周辺が正規でも同時正規でなければ「無相関なのに独立でない」が起こります。「正規分布なら無相関と独立は同じ」と無条件に覚えるのは誤り。同時に多変量正規 という条件を必ずセットで思い出してください。
7.3 Σ \Sigma Σ
∣ Σ ∣ = 0 \lvert\Sigma\rvert=0 ∣ Σ ∣ = 0 Σ − 1 \Sigma^{-1} Σ − 1 X 2 = 2 X 1 X_2=2X_1 X 2 = 2 X 1 Σ \Sigma Σ 正定値性 (フルランク)が必要です。
8. 試験での問われ方(級ごとの差)
多変量正規分布は判別分析・主成分分析・回帰の土台で、準1級・1級とも頻出です。級で問われる深さが異なります。
準1級
密度の意味 :指数部がマハラノビス距離であること、∣ Σ ∣ \lvert\Sigma\rvert ∣ Σ ∣ 周辺・条件付き分布 :2変量正規で、Y Y Y X X X μ X + ρ σ X σ Y ( y − μ Y ) \mu_X+\rho\frac{\sigma_X}{\sigma_Y}(y-\mu_Y) μ X + ρ σ Y σ X ( y − μ Y ) σ X 2 ( 1 − ρ 2 ) \sigma_X^2(1-\rho^2) σ X 2 ( 1 − ρ 2 ) 計算問題として頻出 )。成分の和 X 1 + X 2 X_1+X_2 X 1 + X 2 X 1 − X 2 X_1-X_2 X 1 − X 2 等確率楕円 :楕円の主軸が Σ \Sigma Σ 主成分分析(PCA) と接続。判別分析での利用 :2群がともに多変量正規で共分散が等しいと仮定したときの線形判別関数の導出根拠(マハラノビス距離が小さい群へ分類)。詳細は 判別分析 。
1級
性質の証明 :線形変換閉性・無相関⇔独立・条件付き分布の正規性を、MGFや密度の分解から 証明 させる。シューア補行列としての条件付き共分散。標本分布 :多変量正規からの標本に基づく標本平均ベクトルと標本共分散行列の分布。標本共分散行列が従う ウィシャート分布 、平均ベクトルの検定に使う ホテリングの T 2 T^2 T 2 は名称・役割レベルで押さえる(1変量のカイ二乗・t t t 要最新確認 。漸近論 :中心極限定理の多変量版(標本平均ベクトルが漸近的に多変量正規)、最尤推定量の漸近正規性の基盤として多変量正規が現れる。
よくある疑問(Q&A)
Q1. X X X Y Y Y ( X , Y ) (X,Y) ( X , Y )
いいえ、それが最大の落とし穴です。各成分(周辺分布)が正規でも、同時分布が2変量正規とは限りません。7.1の反例(∣ X ∣ \lvert X\rvert ∣ X ∣ Y Y Y X , Y X,Y X , Y N ( 0 , 1 ) N(0,1) N ( 0 , 1 ) 任意の線形結合 a X + b Y aX+bY a X + bY 」という、もっと強い条件が必要です。要するに「周辺が正規」は「同時が正規」の必要条件にすぎず、十分条件ではありません。
Q2. 「正規分布では無相関なら独立」と習いました。常に正しいですか?
条件付きで正しい、が答えです。正しくは「同時に多変量正規であれば 、無相関 ⇔ 独立」です。前提の「同時正規」が抜けると成り立ちません。Q1の反例は周辺が正規でも同時正規でないため、X , Y X,Y X , Y
Q3. 条件付き分散 Σ 11 − Σ 12 Σ 22 − 1 Σ 21 \Sigma_{11}-\Sigma_{12}\Sigma_{22}^{-1}\Sigma_{21} Σ 11 − Σ 12 Σ 22 − 1 Σ 21 x 2 \mathbf x_2 x 2
正規分布の特殊性です。条件付き分散は 相関構造(Σ \Sigma Σ で決まり、観測した x 2 \mathbf x_2 x 2 X 2 \mathbf X_2 X 2 X 1 \mathbf X_1 X 1 X 2 \mathbf X_2 X 2 平均 の方は x 2 \mathbf x_2 x 2 x 2 \mathbf x_2 x 2
Q4. 条件付き期待値がなぜ回帰式になるのですか?回帰は別のモデルでは?
実は同じものを別角度から見ています。X \mathbf X X E [ X 1 ∣ X 2 = x 2 ] = μ 1 + Σ 12 Σ 22 − 1 ( x 2 − μ 2 ) \mathbb E[\mathbf X_1\mid\mathbf X_2=\mathbf x_2]=\boldsymbol\mu_1+\Sigma_{12}\Sigma_{22}^{-1}(\mathbf x_2-\boldsymbol\mu_2) E [ X 1 ∣ X 2 = x 2 ] = μ 1 + Σ 12 Σ 22 − 1 ( x 2 − μ 2 ) x 2 \mathbf x_2 x 2 自動的に 出てきます。係数 Σ 12 Σ 22 − 1 \Sigma_{12}\Sigma_{22}^{-1} Σ 12 Σ 22 − 1 β ^ = ( X ⊤ X ) − 1 X ⊤ y \hat{\boldsymbol\beta}=(X^\top X)^{-1}X^\top\mathbf y β ^ = ( X ⊤ X ) − 1 X ⊤ y 重回帰分析 )。要するに「線形回帰モデルは、説明変数と目的変数が同時に正規分布する状況での条件付き期待値を推定している」と解釈でき、これが線形回帰の自然さの理論的根拠になっています。
Q5. 行列式 ∣ Σ ∣ \lvert\Sigma\rvert ∣ Σ ∣ σ \sigma σ
はい、同じ役割(正規化)です。1変量では σ \sigma σ ∣ Σ ∣ 1 / 2 \lvert\Sigma\rvert^{1/2} ∣ Σ ∣ 1/2 ∣ Σ ∣ = λ 1 ⋯ λ p \lvert\Sigma\rvert=\lambda_1\cdots\lambda_p ∣ Σ ∣ = λ 1 ⋯ λ p ∣ Σ ∣ \lvert\Sigma\rvert ∣ Σ ∣ 1 / ∣ Σ ∣ 1 / 2 1/\lvert\Sigma\rvert^{1/2} 1/ ∣ Σ ∣ 1/2 ∣ Σ ∣ = 0 \lvert\Sigma\rvert=0 ∣ Σ ∣ = 0 Σ \Sigma Σ
まとめ
多変量正規 N p ( μ , Σ ) N_p(\boldsymbol\mu,\Sigma) N p ( μ , Σ ) f ( x ) = 1 ( 2 π ) p / 2 ∣ Σ ∣ 1 / 2 exp ( − 1 2 ( x − μ ) ⊤ Σ − 1 ( x − μ ) ) f(\mathbf x)=\dfrac{1}{(2\pi)^{p/2}\lvert\Sigma\rvert^{1/2}}\exp\!\big(-\tfrac12(\mathbf x-\boldsymbol\mu)^\top\Sigma^{-1}(\mathbf x-\boldsymbol\mu)\big) f ( x ) = ( 2 π ) p /2 ∣ Σ ∣ 1/2 1 exp ( − 2 1 ( x − μ ) ⊤ Σ − 1 ( x − μ ) ) ∣ Σ ∣ 1 / 2 \lvert\Sigma\rvert^{1/2} ∣ Σ ∣ 1/2 正規分布(標準正規・標準化) )の自然な拡張。
等確率楕円 ( x − μ ) ⊤ Σ − 1 ( x − μ ) = c (\mathbf x-\boldsymbol\mu)^\top\Sigma^{-1}(\mathbf x-\boldsymbol\mu)=c ( x − μ ) ⊤ Σ − 1 ( x − μ ) = c Σ \Sigma Σ 主成分分析(PCA) と同じ固有構造)。
線形変換に閉じる:A X + b ∼ N ( A μ + b , A Σ A ⊤ ) A\mathbf X+\mathbf b\sim N(A\boldsymbol\mu+\mathbf b,\,A\Sigma A^\top) A X + b ∼ N ( A μ + b , A Σ A ⊤ ) exp ( t ⊤ μ + 1 2 t ⊤ Σ t ) \exp(\mathbf t^\top\boldsymbol\mu+\tfrac12\mathbf t^\top\Sigma\mathbf t) exp ( t ⊤ μ + 2 1 t ⊤ Σ t )
周辺分布は該当ブロックの抜き出し N ( μ 1 , Σ 11 ) N(\boldsymbol\mu_1,\Sigma_{11}) N ( μ 1 , Σ 11 ) μ 1 + Σ 12 Σ 22 − 1 ( x 2 − μ 2 ) \boldsymbol\mu_1+\Sigma_{12}\Sigma_{22}^{-1}(\mathbf x_2-\boldsymbol\mu_2) μ 1 + Σ 12 Σ 22 − 1 ( x 2 − μ 2 ) Σ 11 − Σ 12 Σ 22 − 1 Σ 21 \Sigma_{11}-\Sigma_{12}\Sigma_{22}^{-1}\Sigma_{21} Σ 11 − Σ 12 Σ 22 − 1 Σ 21 x 2 \mathbf x_2 x 2
同時正規なら無相関 ⇔ 独立 (Σ \Sigma Σ Σ \Sigma Σ
関連ノート